
基于Swin Transformer的家居垃圾分类系统
2023-01-31 01:47瞿定垚王学
电子制作 2023年1期
瞿定垚,王学,
(1.河北工程大学 数理科学与工程学院,河北邯郸,056038; 2.河北省计算光学成像与光电检测技术创新中心,河北邯郸,056038)
0 引言
中国是全世界人口最多的国家,在日常生活的过程中,会制造大量垃圾。在由生态环境部所公布的《2019年全国大、中城市固体废物污染环境防治年报》中显示,在2018年里,在全国中的200个大、中城市里生活垃圾产生量为21147 3万吨,处置量为21028 9万吨,处置率达到了99 4%[1]。虽然由数据显示的处置率己经很高了,只有其中少部分未被处理。但是这并不是全国所有城市的数据,除了生态环境部统计的这200个大、中城市,还有许多城市和落后的中小城镇的数据并未被统计到,可以推断出未被处理的生活垃圾仍有很多。在年报中,2013~2018年中国200个大、中城市生活垃圾产生量统计及增长情况,可以得出生活垃圾产生量以5-10%的增长速率逐年递增[2]。在垃圾产量巨大的同时,处置垃圾的方法仍然十分落后。
我国解决垃圾分类主要依靠人工二次分拣,其弊端如下:
(1)二次分拣模式的参与主体是分类指导员,居民其实还是没有真正地参与进来,所以它解决不了居民参与率低的问题[3];要让居民真正地参与垃圾分类,从根本上还是要让他们从源头开始做好分类。
(2)二次分拣的对象是厨余垃圾,像可回收垃圾、有害垃圾等其他垃圾,分类指导员们都不分拣,所以没有真正地达到生活垃圾的减量化、资源化、无害化[4]。
(3)此模式操作简单,方法原始,效率低,安全性差,更谈不上精细化管理运营。因此靠“二次分拣”支撑的垃圾分类是走不长远的。
使用计算机视觉技术实现自动的垃圾分类识别,存在的问题是效率低,回收利用效率降低,安全性差[5]。精度差,价格昂贵。
针对居民参与率低的问题,我国应该从垃圾产生源头入手,以家居垃圾为研究环境,走出二次分拣的困境,使全民参与进来,切实解决分类问题。针对垃圾数据集数据少、质量较差、背景单一、存在标注错误的情况,神经网络无法全面、准确分析、理解分类特征的问题,构建大规模垃圾图像数据库是重要途径。同时数据量的大幅增加与计算机硬件性能的提升,使得深度学习技术开始在计算机视觉领域大放异彩。由于其速度快、准确率高的优点,使得其在各个领域都取得了一定的成果。图像分类在深度学习领域主要依靠CNN卷积神经网络和视觉Transformer图卷积神经网络,由于家居环境对分类精度要求高,对推理速度要求较低,使用单图像分类而不是目标检测。
1 系统组成
家居垃圾分类系统主要由三部分组成,构建垃圾分类数据集、设计垃圾分类网络和搭建安卓app。
首先,本文构建垃圾分类数据集。数据集来源为:网络爬虫技术爬取生活中常见的各种家居垃圾图片,将不符合要求的垃圾图片剔除[6];使用华为垃圾数据集中垃圾图片,选择符合要求的垃圾图片数据;通过摄像设备收集邯郸市河北工程大学生活中的常见家居垃圾图片。通过数据增强方式,旋转,镜像,对比度,进一步扩大数据集。其次,本文设计垃圾分类网络。比较CV领域中的CNN经典图像分类模型的优缺点,设计实验选出适用于本课题的图像分类模型[7][8][9]。通过NLP领域对CV领域的迁移,搭建了适用于本课题的图像分类模型。通过迁移学习[10],数据增强和添加全局注意力的方式,对网络进行了优化。最后,搭建了安卓端口app,对训练好了的模型成功进行了转换和量化,将自己训练好了的深度学习模型移植到了手机安卓app上。垃圾分类系统框架图如图1所示。
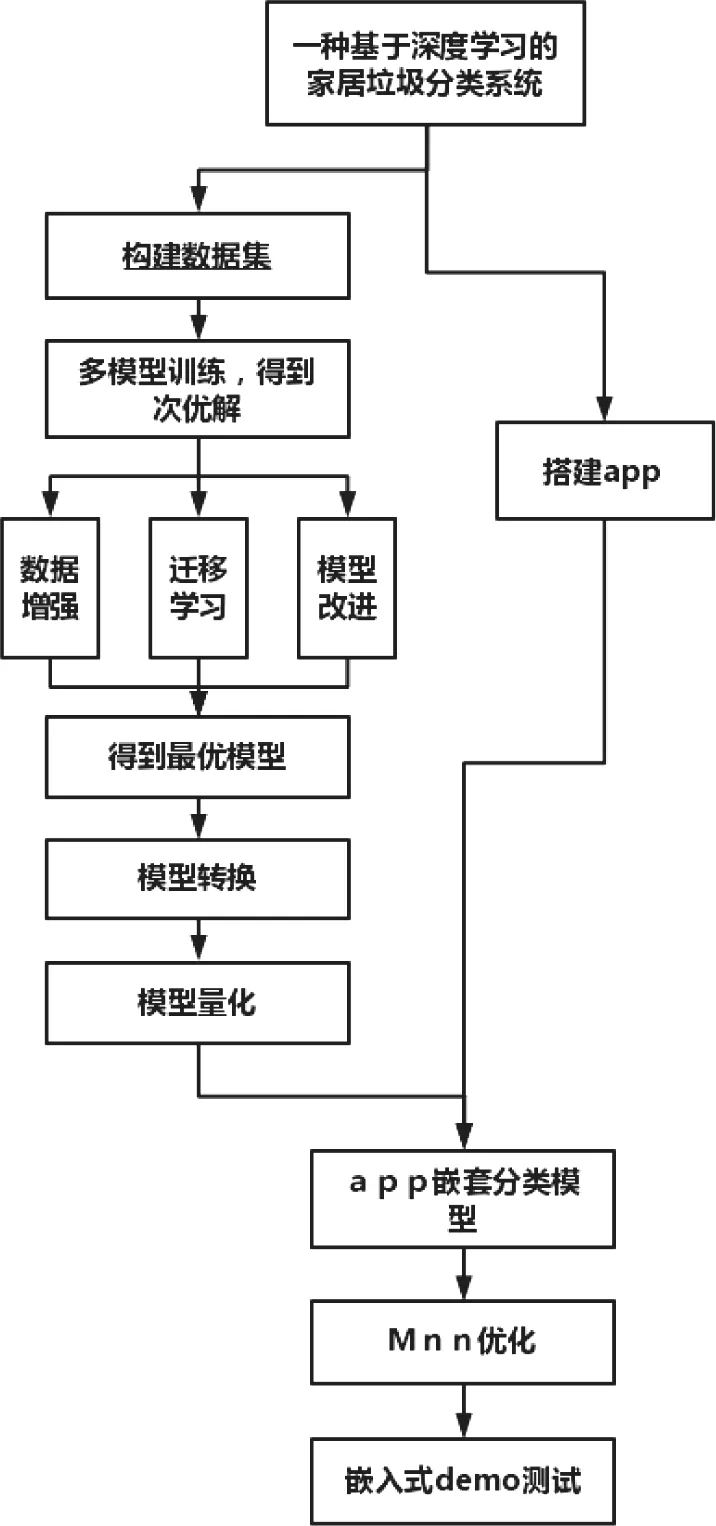
图1 垃圾分类系统框架图
■ 1.1 Swin transformer简介
Transformer在NLP领域应用十分广泛,但是在CV领域的应用存在很多困难,这源自于两类任务的本质区别,例如CV里物体尺寸变化很大,模型需要处理不同尺度的同类物体,而在NLP领域,把word tokens作为基本要素,并不存在以上问题。同时图片分辨率高,自注意力如果逐像素计算成本过高[11]。
Swin Transformer 是一种新型的transformer,可以用作视觉和语言处理的统一模型, 引出了一种具有层级的特征表达方式和具有线性的计算复杂度。Swin Transformer有两个特征: (1) 层级特征结构;(2) 线性复杂度。层级特征结构使得本模型适用于 FPN 或者 U-Net 模型;线性复杂度是因为使用local window self-attention[12]。这些特点使得本模型可以作为一种通用模型用于各种视觉任务。在目标检测、图像分割等视觉任务中,Swin Transformer 均得到了SOTA 的结果。
Swin Transformer在上游任务取得了极好的成绩,可拿来可直接做下游任务,并且效果很好。本文选择了swin_base_patch4_window12_384_in22k作为预训练模型,在保持高精度的同时推理速度也适用于家居垃圾分类任务,并在后续的任务中加速了推理速度。
■ 1.2 训练流程
首先输入像素384×384图片到Patch Partition模块中进行分块,即每4×4相邻的像素为一个Patch,然后在channel方向展平(flatten)。本文输入的是RGB三通道图片,每个patch就有4×4=16个像素,然后每个像素有R、G、B三个值,展平后是16×3=48,所以通过Patch Partition后图像shape由 [H, W, 3]变成了 [H/4, W/4, 48]。然后在通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由 [H/4, W/4, 48]变成了 [H/4, W/4, C]。其实在源码中Patch Partition和Linear Embeding就是直接通过一个卷积层实现的。
然后就是通过四个Stage构建不同大小的特征图,除了Stage1中先通过一个Linear Embeding层外,剩下三个stage都是先通过一个Patch Merging层进行下采样,然后都是重复堆叠Swin transformer Block。Swin transformer 网络结构如图2所示。

图2 Swin transformer网络结构
这里的Block有两种结构,如图3所示,这两种结构的不同之处仅在于一个使用了W-MSA结构,一个使用了SW-MSA结构[13]。而且这两个结构是成对使用的,先使用一个W-MSA结构再使用一个SW-MSA结构,堆叠Swin Transformer Block的次数都是偶数。
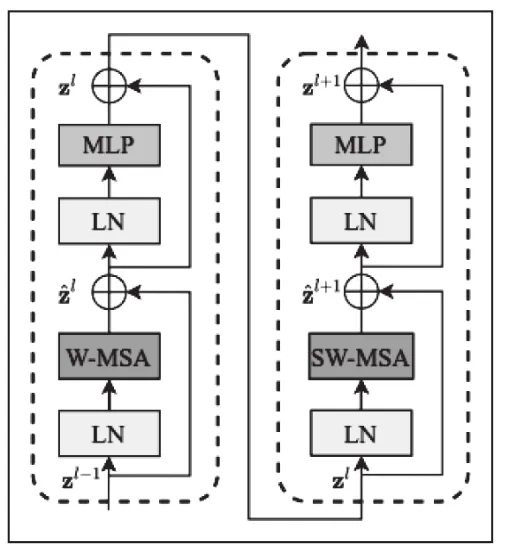
图3 Swin transformer 两种blocks结构
最后对于图像分类网络,后面还会接上一个Layer Norm层、全局池化层以及全连接层得到最终输出。
2 模型优化与算法改进
■ 2.1 模型优化
2.1.1 数据增强
数据增强:通过旋转,镜像,对比度的方法扩充了约54000张图片用于训练,对扩充后的数据集图像数据进行预处理,增加模型的鲁棒性和模型泛化能力[14]。
2.1.2 迁移学习
微调 Fine-tuning:将在大数据集上训练得到的weights作为特定任务(小数据集)的初始化权重,重新训练该网络(根据需要,修改全连接层输出)[15]。训练的方式可以是:(1)微调所有层,(2)固定网络前面几层权重,只微调网络的后面几层,这样做有两个原因:A 避免因数据量小造成过拟合现象;B CNN前几层的特征中包含更多的一般特征(比如,边缘信息,色彩信息等),这对许多任务来说是非常有用的,但是CNN后面几层的特征学习注重高层特征,也就是语义特征,这是针对于数据集而言的,不同的数据集后面几层学习的语义特征也是完全不同的[16],本文选择训练方式2。
网络微调是一项非常强大的技术,无需从头开始训练整个网络,“快速启动”学习,最终得到更高精度的迁移学习模型,同时节省了计算资源[17]。
■ 2.2 模型改进
在swin transformer基础上加入了NLP领域的全局注意力Global Attention[18~20]。Global Attention的目的:Gobal Attention的目的是为了在生成上下文向量,用来处理文本信息的,单词和句子存在联系,局部像素点也和全图存在联系[21]。transformer是用来处理文本信息的,现在可以用来处理CV领域的图像信息。swin transformer在CV领域起到了突破性的重大作用,选择在swin transformer的head前 边插 入Global Attention,经过训练,精度得到了提升。全局注意力如图4所示。

图4 全局注意力
改进实验分为三组,插入一层Gobal Attention,命名模型为Swin transformer-A;插入两层Gobal Attention,命名模型为Swin transformer-B;插入三层Gobal Attention命名为Swin transformer-C。使用基于微调的迁移学习,固定部分层数的权重,插入一层Gobal Attention模型训练层数如下代码。
“training layers 4 norm1 weight
training layers 4 norm1 bias
training layers 4 attn qkv weight
training layers 4 attn qkv bias
training layers 4 attn proj weight
training layers 4 attn proj bias
training layers 4 norm2 weight
training layers 4 norm2 bias
training layers 4 mlp fc1 weight
training layers 4 mlp fc1 bias
training layers 4 mlp fc2 weight
training layers 4 mlp fc2 bias
training head weight
training head bias”
插入两层和三层就是将代码中的layers 4进行堆叠。
3 垃圾分类实验
■ 3.1 获取数据集
实验整理的原始数据集共20022张,约13000张来自华为云比赛数据集,7022张自己收集标注。提前做好四分类,O代表other waste,H代表harm garbage,K代表kitchen waste,R 代表recyclable garbage,小类别共计40类。途径来自于拍摄,网络爬虫爬取,网上下载以及截取等方式。将其标注好,放在同一类别的文件夹中,小类别共计40类。后来考虑到部分种类垃圾数量较少,使用数据增强的手段,通过镜像,旋转,对比度三种方式,扩充了数据集约54000张用于训练。由于旋转角度有的图像会缺失信息,所以对扩充的数据进行清洗,然后重新归类,初始数据集类别和数量如图5所示。
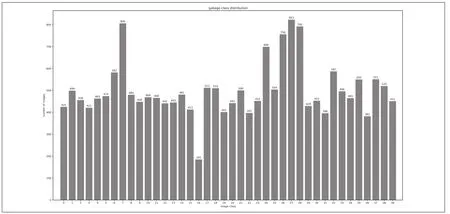
图5 初始数据集类别以及种类
■3.2 实验结果与分析
将家居垃圾数据集按照9:1的比例分为训练集和验证集,18035张用于训练,1987张用于验证。对训练集使用数据增强后,72035张用于训练,验证数量不变。使用预训练 权 重 swin_base_patch4_window12_384_in22k pth,模型准确率如表1所示。

表1 不同模型准确率

9 ConvNeXt-Base+迁移学习+数据增强 有 64 4 100 97 2%97 2%10 VIsion tranfformer-Base+迁移学习+数据增强 有 64 4 100 99 2%96 8%
通过该表,得出迁移学习和数据增强和全局注意力机制都能有效提升模型的精度。消融实验可以看出,在数据量小的时候,全局注意力提升的效果较好,使用数据增强后,仍然可以提升模型精度,提升幅度会变小。说明全局注意力和数据增强以及迁移学习改善网络性能有部分重合了,组合在一起时效果最好。实验8,9,10是和前四个实验进行对比,在同量级参数下看模型效果,Efficientnetv2选择m模型[22],pytorch架构下无预训练权重,使用工具将Tensorflow下ImageNet-21K预训练权重转换为Pytorch架构下可以使用;ConNeXt选 择 convnext_base_22k_224 pth 预 训 练权重[23];vision transformer选择vit_base_patch16_224_in21k pth作为预训练权重[24]。
垃圾40分类最优模型混淆矩阵如图6所示。
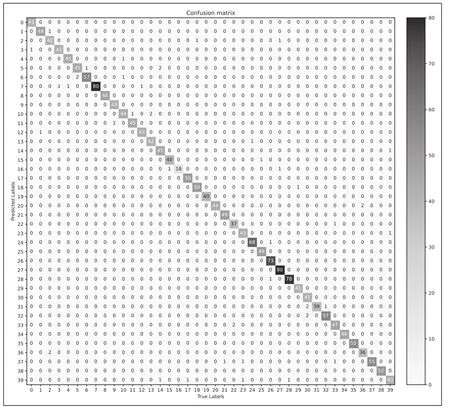
图6 垃圾40分类混淆矩阵
通过对每个类别的分析,误差主要集中在可回收物瓶罐这些物品中,实际生活中只需要一级分类标准就可以了。使用一级标准,重新训练4分类。选择上边最优模型和策略,72084张用于训练,2001张用于验证,Train acc99 8%,Val acc99 2%,再次验证模型性能很强。
垃圾40分类每个类别的精确率,召回率,特异度如表2所示。
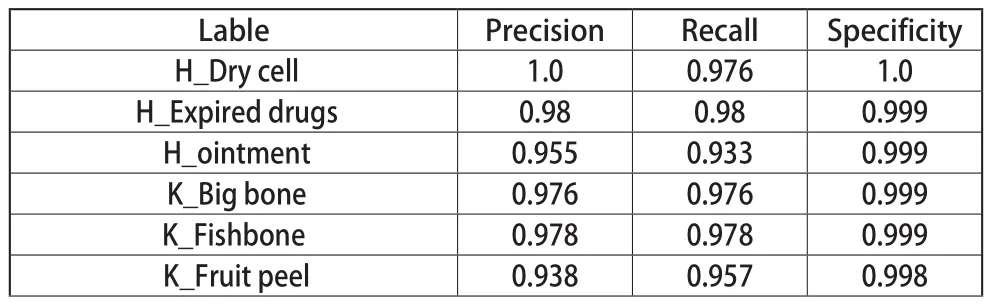
表2 每个类别的精确率、召回率、特异度

K_Fruit pulp 0 95 0 983 0 998 K_Leaves edible orange roots 0 964 1 0 0 998 K_Tea leaves 1 0 1 0 1 0 K_The shell 1 0 0 977 1 0 K_leftovers 0 936 0 957 0 998 O_Broken flowerpots and dishes 0 978 0 978 0 999 O_Cigarette butts 0 977 0 977 0 999 O_Disposable snack box 0 977 0 955 0 999 O_Stained plastic 0 978 0 938 0 999 O_chopstick 0 976 0 976 0 999 O_toothpick 0 9 1 0 0 999 R_Charging treasure 1 0 0 98 1 0 R_Cosmetics bottles 0 98 0 98 0 999 R_Courier bags 1 0 1 0 1 0 R_Edible oil drum 0 957 1 0 0 999 R_Leather shoes 1 0 0 98 1 0 R_Metal food can 0 974 0 949 0 999 R_Old clothes 0 977 0 956 0 999 R_Plastic bowl tub 0 986 0 986 0 999 R_Plastic hangers 1 0 0 98 1 0 R_Plastic toys 1 0 0 973 1 0 R_Plug wire 1 0 0 976 1 0 R_Plush toys 0 987 0 987 0 999 R_Shampoo bottle 1 0 0 976 1 0 R_Spice bottles 1 0 0 911 1 0 R_The bottle 0 929 1 0 0 998 R_The glass 0 966 0 983 0 999 R_cans 0 959 0 959 0 999 R_carton 1 0 1 0 1 0 R_cutting board 1 0 1 0 1 0 R_drink bottle 0 947 0 947 0 999 R_package 0 948 1 0 0 998 R_pan 1 0 1 0 1 0 R_pillow 0 915 0 956 0 998
40垃圾分类最优模型训练过程如图7所示。
通过迁移学习,从曲线中可以看出模型收敛的很快,损失下降的很快并且到达了较低值,验证集准确率很快得到了最优解。训练集损失稳定下降,训练集准确率稳定提升。在数据集复杂度更高的情况下,已经超过了华为2019年垃圾分类挑战杯的方案,40垃圾分类的准确率达到了97 63%,超过了它的96 96%,并且参数量只占他的14,flops只占12。
Python垃圾图片测试结果如图8所示,推理结果全部正确。

图8 python可视化测试结果
4 应用开发
■ 4.1 模型转换
4.1.1 模型转换预处理
Pytorch的模型文件一般会保存为 pth文件,C++接口一般读取的是 pt文件,因此,C++在调用Pytorch训练好的模型文件的时候就需要进行一个转换,转换为 pt文件,才能够读取。
预处理如下:
在转换的时候,首先就需要先将模型文件读取进来,然后利用pytorch提供的函数torch jit trace进行转换。PyTorch 一个算子可能会导出ONNX很多的胶水算子,计算图变复杂,导致推理效率下降。使用onnx simply库对onnx文件简化,使网络结构更加精简,消除细碎op。
4.1.2 模型转换方式以及结果
PyTorch -> ONNX -> 第三方后端(主流方式),第三方后端有 TensorRT,MNN,NCNN等,这样的优势是不同的后端在目标平台都有相对应的优化,可以获得最快的推理速度,但问题是第三方后端对onnx算子的支持优化,会有运行不了的问题[25]。
方案:Pytorch -> MNN:pytorch -> onnx -> MNN。
结果:模型转换成功,python和C++调用结果一致。
■ 4.2 模型量化
转化成mnn模型虽然可以进行推理,模型文件较大或者运行较慢的情况特别是在移动设备等边缘设备上,算力和储存空间受限因此压缩模型是一个急需的工作,本文所做的工作为离线量化[26,27]。
原模型转换后数据类型为Fp32,由于模型太大370MB,使用转换工具做了量化处理,压缩模型的大小,同时可以加速模型的推理速度。模型量化如表3所示。

表3 模型量化
使用python和c++对同一张图片进行结果测试,输出一致,说明模型转换和模型量化没有问题。Fp16量化和Int8量化后的模型可以正常推理,并且可以显示出置信度。Int2量化后的模型图像推理时候无任何反应,结构压缩太多,出现了精度失真的情况。最终量化选择Fp16量化和Int8量化。
■ 4.3 app 开发
(1)模型准备,留下以下两个模型model-87_384_sim_fp16和model-87_384_sim_int8。
(2)创建工程。创建Android工程,打开Android Studio新建一个Native C++工程,配置好JDK 、SDK 、NDK。
(3)模型导入。将步骤(1)中生成的两个文件复制到步骤(2)中的新工程中,存放的目录为“F:swintransformerappsrcmainassets”。这两个模型都可以使用,在后续的“MainActivity java”可以自由选择切换。
(4)添加标签文件。在“app”目录下创建名为“F:swintransformerappsrcmainjni”的文件,将本文需要分类的类别在这个“swimtransformer_jni cpp”文件中,共40类。编写MNN进行模型推理,根据自己的模型,编写jni调用MNN进行模型推理
(5)模型分类。在“app”目录下创建名为“swintrans former java”的文件,在里面添加模型分类的代码,主要包含了以下功能:目标图像读取、目标图像预处理、模型加载、模型前向推理、模型预测结果。在图像的预处理中,需要对图像进行归一化处理,同时统一缩放为 384×384 大小。
(6) 界面设计和操作逻辑设计。在“app”目录下创建名为“MainActivity java”的文件,写入调用相册、文件管理器、浏览器的函数以及一些操作的逻辑。创建“ xml”的文件,编辑 App 的界面显示,完成 App的开发[28,29]。
■ 4.4 app 测试
4.4.1 app 界面以及操作方式
图形界面主要分为三个按钮,选图、CPU识别、GPU识别。进入界面后,下方会弹出“Copy model to data”和“Copy model to success”。之后就可以从相册选图或者文件管理或者浏览器选择图片进行识别。
4.4.2 app 单张图片测试分析
使用单张图片测试模型量化和模型转换有无推理精度损失,选出最优搭配下的app。具体测试方案和结果如下:选取Mix2s、Note 10 pro、Redmi K40 在不同量化模型下,分别进行同一张图像用cpu 和gpu识别,评价指标分为准确率和推理速度。测试原图与python测试图如图9所示,方便与表4进行结果对比。

图9 测试原图与python测试可视化
python推理图9(a)花费时间400ms,结果如图9(b),使用设备 GPU2080TI。
App具体测试图9(a)结果如表4所示。
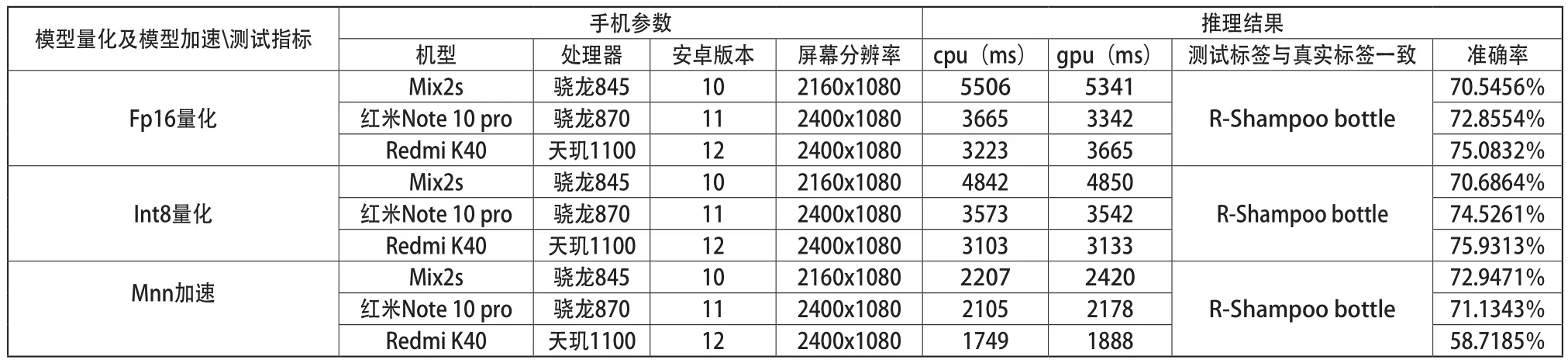
表4 APP测试图a结果
结论:
(1)在单一量化时,硬件设备越好,推理速度越快,精度越高。
(2) int8量化效果比Fp16量化效果更好,用同一款手机测试同一张图片时候,精度和推理速度都得到部分提升;相比原模型Fp32数据推理同一张图片时,无精度损失。
(3) 使用Mnn加速优化后,用同一款手机测试同一张图片时候,推理速度得到了再一次的提升,但是精度对于不同的机型表现略有不同,但总体趋势是下降的。
(4)在不同安卓版本和不同分辨率下下的不同机型,该App都能完美适用。手机移动边缘设备与显卡算力差距很大,手机推理速度经过优化满足日常操作时长需要。
4.4.3 app 可视化
本次app可视化测试选择机型Mix2s,选择模型为Int8量化,加速推理使用MNN优化,图形测试选择三张图片,分别使用cpu和gpu推理。评价指标分为准确率和推理速度,图像推理会显示出前TOP5的标签和概率,标签按照概率大小依次排列。可视化结果如图10所示。
App测试可视化推理结果全部正确,推理速度满足日常使用。
5 结论
通过对各种深度学习图像算法进行研究,加上了大量的训练策略,并且对网络进行了改进,最终得到超过现有技术的精度。在保持高精度的前提下,尽量提升推理速度,对模型进行量化,使之可以移植到安卓嵌入式设备的智能垃圾分类应用。通过模型转换,使其用手机的cpu和gpu推理,彻底摆脱通信的束缚,在深度学习的多种部署方式中具有高度便携性 、通用性 、经济适用性性的特点。除此之外,使用MNN优化加速了推理速度。由于构建并使用一个庞大的数据集进行训练,模型的泛化性能较好,适用于生活中的各种场景。
猜你喜欢
科普童话·学霸日记(2021年2期)2021-09-05
数学小灵通(1-2年级)(2021年4期)2021-06-09
幽默大师(2020年11期)2020-11-26
当代陕西(2019年24期)2020-01-18
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
摄影之友(影像视觉)(2019年3期)2019-03-30
摄影之友(影像视觉)(2019年2期)2019-03-05
摄影之友(影像视觉)(2018年12期)2019-01-28
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
小太阳画报(2018年10期)2018-05-14
