
基于改进U-Net++和近红外光谱技术的羊毛含量快速定性分析方法研究
2023-01-31 12:21冷思雨乔嘉慧王连庆
光谱学与光谱分析 2023年1期
冷思雨,乔嘉慧,王连庆,王 军*,邹 亮
1.中国矿业大学地下空间智能控制教育部工程研究中心,江苏 徐州 221116 2.中国矿业大学信息与控制工程学院,江苏 徐州 221116 3.徐州兆恒工控科技有限公司,江苏 徐州 221008
引 言
羊毛是一种重要的纺织原料,具有手感饱满、保暖性好等优点,根据产品用途和成本需求的不同,可将羊毛和其他纺织原料进行混纺,在羊毛纺织制品领域里,羊毛成分含量是衡量相关产品质量的一项重要指标。然而目前市面上存在一些商家虚假标注羊毛含量或者使用化纤材料以次充好的情况,这些劣质产品严重损害了消费者的经济利益和身体健康。为了保障消费者的权益,加强羊毛制品的质量检测尤为重要。目前检测部门常用的羊毛制品检测方法有感官鉴别法、显微镜鉴别法、化学溶解法以及物理方法等[1],这些传统的检测方法通常存在一些弊端,如感官鉴别法过分依赖检验人员的经验和主观感受;化学检测法检测周期长,而且具有破坏性,不利于市场的快速检查,因此开发一种快速、准确检测羊毛制品质量的方法十分有必要。
近红外光谱技术是一种新兴的分析检测技术。随着计算机科学和化学计量学的发展,近红外光谱分析技术凭借其分析速度快、无试剂损耗、非破坏性等技术优势[2-3]成熟地应用于农业[4]、医疗[5]、食品[6]、石油化工与煤炭[7]等领域。一些研究人员尝试将近红外光谱分析技术用于纺织领域。Sun通过比较偏最小二乘法、极限学习机以及最小平方支持向量机的算法性能,证明了近红外光谱技术与最小平方支持向量机的结合,在混纺面料中棉花含量的检测方面具有很大潜力[8]。Liu等在采用逐次投影算法选择出有效近红外光波长的基础上,建立最小二乘支持向量机模型,实验表明该模型预测值的均方根误差为1.17%,提供了一种简单、快速且非破坏性测定棉-涤纶纺织品成分的方法[9]。Chen等利用近红外光谱分别与几种偏最小二乘法以及弹性成分回归算法相结合,模型的预测均方根误差为0.35%,证明了弹性成份回归算法与近红外光谱结合应用于羊毛含量检测的可行性[10]。Zhou等使用多元线性回归的方法实现了羊毛-羊绒混纺产品中的羊绒含量鉴定[11]。Sun等使用自适应表示学习方法对羊毛和羊绒混合物的近红外光谱数据进行鉴别分类,准确率可达96.60%[12]。现有方法用于羊毛制品质量检测方面性能仍有待提升,仍存在建模时间过长,检测精度不高以及需要对数据波段进行波段筛选等问题。
深度学习可以自动从数据中学习特征且鲁棒性极强,在智能语音[13]、图像处理[14]和生理信号分析[15]中得到了广泛的应用。然而在近红外光谱分析领域,使用的深度学习网络结构往往较为简单[16-17],相关性能指标仍有较大的提升空间。U-Net模型是近年来应用于生物医学图像分割领域的一个重要模型,该模型在下采样编码环节和上采样解码环节使用对称的网络结构,并通过下采样和上采样逐层跳跃连接的方式获得像素间的关系。U-Net++模型是在U-Net模型基础上提出的,这一模型将原网络结构中的逐层跳跃连接变为密集的跳跃短连接,实现了不同层次的特征叠加,充分使用了浅层和深层特征,减少了下采样编码器和上采样解码器之间的语义鸿沟,充分提取细节特征,从而产生更好的预测效果,本工作将U-Net++模型应用于羊毛制品的近红外光谱分析以实现羊毛含量的定性分析。为了进一步提高模型性能,在网络中加入注意力门控机制,提升了网络的特征学习能力。实验共利用5 125组羊毛制品的近红外光谱数据,经十折交叉验证后模型预测精度可达93.59%,与传统分类模型相比,分类性能得到明显提升。
1 实验部分
1.1 样本
将所收集的羊毛样本分为两部分,一部分依托专业检测机构,使用次氯酸盐检测法来检测样本真实羊毛含量;另一部分在实验室使用波长范围908.1~1 676.2 nm的MicroNIR Pro手持式光谱仪进行光谱数据采集。研究中收集的羊毛制品样本中所含羊毛量经过专业机构测量可分为5%,10%,20%,30%,40%,50%,60%,80%和100%九类。在实验室使用手持光谱仪采集样本近红外光谱数据的过程中,使用漫反射模式并每隔10分钟对背景进行校正,选择光谱探头距离羊毛样本5,6,8,9和19 mm这五个位置对每个样本进行光谱数据采集。同时,为了避免因人为操作失误等原因引起数据误差,对每一个样本在相同距离位置均采集五次数据,即每一个样本有25组光谱数据,光谱数据波段范围为908.1~1 676.2 nm,共125个波长点。不同羊毛含量的样本光谱数据如图1所示,图中的横坐标为光谱波长,纵坐标为羊毛样本对不同波段的光谱吸收率。近红外光谱信息来源于分子内部含氢基团(如C—H,N—H,O—H等)振动的倍频吸收与合频吸收。羊毛的主要成分为蛋白质,包含了大量含氢基团,在检测过程中近红外光的吸收率与羊毛制品中羊毛含量有密切联系。从图1中可以看出,不同羊毛含量的羊毛制品样本对于近红外光的吸收存在较大的差异。
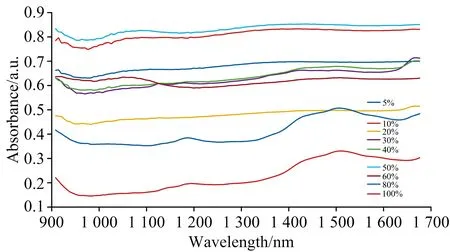
图1 羊毛样本原始光谱数据
1.2 样本标签的处理及数据集的划分
由于样本数量的限制,所采集的光谱数据数量有限,若在此基础上进行定量回归分析易造成模型过拟合,因此选择定性分类分析展开相关研究。将所采集的217个羊毛样本根据羊毛含量的不同分为高、中、低三个类别,其中标签为“羊毛含量低”的样本有73个,标签为“羊毛含量中等”的样本有93个,标签为“羊毛含量高”的样本有51个,并对所有标签进行独热编码(one-hot coding)处理。独热编码是常应用于数据标签处理中的一种方法,它可以将每一个样本标签都映射成唯一矢量。
在采集数据的过程中由于仪器、环境等原因,不可避免地会产生异常样本,因此针对每一类样本,分别采用光谱分析中常用的马氏距离法对异常值进行检测并剔除,具体过程如下:
(1)根据式(1)计算所有样本光谱的平均值,得到平均光谱,其中m代表样本数量。
(1)
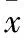
(2)
(3)
(3)设置合适的阈值dthreshold并与马氏距离d比较大小,如果被测样本的马氏距离小于阈值,则将该样本判断为正常样本,反之则为异常样本,从而实现对样本数据集的筛选。其中阈值dthreshold的计算公式如式(4)所示,式中e表示调整阈值范围参数,σd表示马氏距离的标准差见式(5)。
dthreshold=d+eσd
(4)
(5)
在实际应用中将式(4)中参数e设置为3,经过该方法共检测出12组异常样本,其中包含4组“羊毛含量低”的样本,3组“羊毛含量中等”样本以及5组“羊毛含量高”样本,因此最终用于建模分析的数据集中包含205个羊毛样本,共5 125组光谱数据。具体的分类标准以及标签的独热编码结果如表1所示。
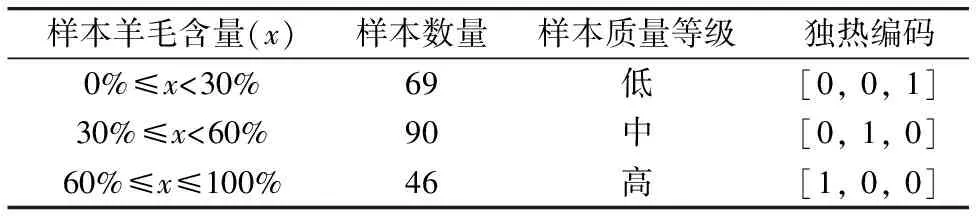
表1 羊毛样本质量等级划分
将所有样本数据划分为训练集、验证集与测试集,划分比例为8∶1∶1;同时,在模型训练中采用了十折交叉验证法,让每一个样本轮流成为训练数据和测试数据,保证了模型的准确性和鲁棒性。为了防止过拟合,将同一样本对应的所有光谱数据划入同一数据集,如训练数据或测试数据等。
1.3 U-Net++网络结构
U-Net++网络是2020年由Zhou等[18]基于U-Net网络[19]提出的一种变体结构,这一网络结构整体形似字母U,如图2所示,由一系列卷积块组成编码器和解码器。
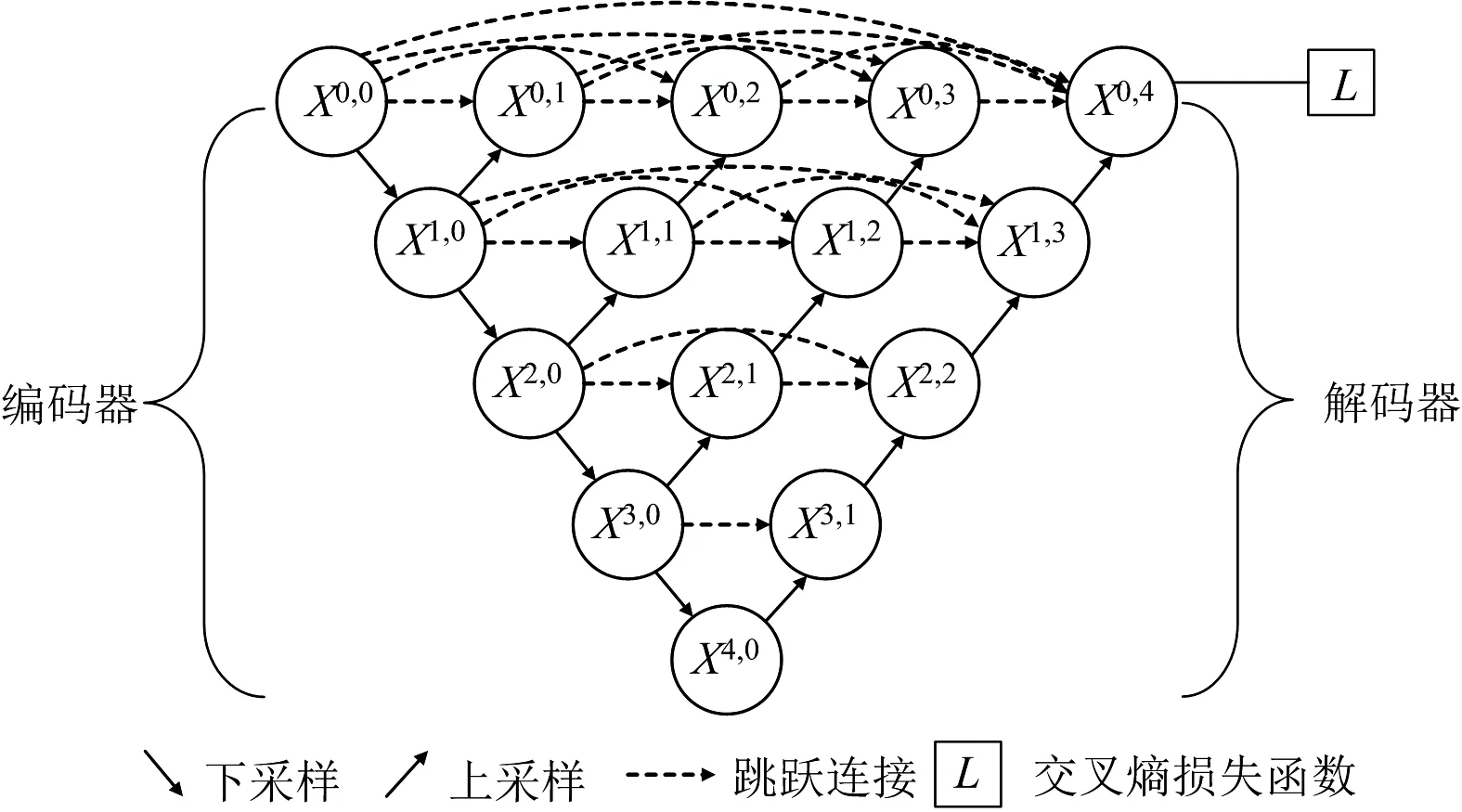
图2 U-Net++网络结构图
U-Net++网络结构整体可以看成由两部分组成,第一部分为编码器(即下采样部分),由多层卷积层和池化层搭建而成;第二部分为解码器(即上采样部分),将每次上采样得到的特征信息与对应的特征提取层进行拼接融合,并在最后一层输出分类结果。U-Net++模型与U-Net相比,最大的区别是在下采样和上采样的过程中加入了密集的跳跃短连接,以X(1, 3)节点为例,该节点是由X(1, 0),X(1, 1)以及X(1, 2)拼接而成,这种跳跃连接能够更加灵活地融合不同深度的特征,有效减小编码器与解码器之间的差距,从而更好地挖掘样本数据与标签之间的关系。
如果x(i,j)代表节点X(i, j)的节点输出特征,那么的x(i,j)如式(6)所示,其中,i表示第i个下采样层,j表示跳跃连接中第j个卷积层,H[·]表示带有激活函数的卷积运算,u(·)表示上采样,[·]表示叠加操作。即j>0时,该节点由j+1个输入构成;j=0时,该节点为下采样环节上的节点,只接受上一层的输出。
(6)
1.4 Attention U-Net++分类模型的建立
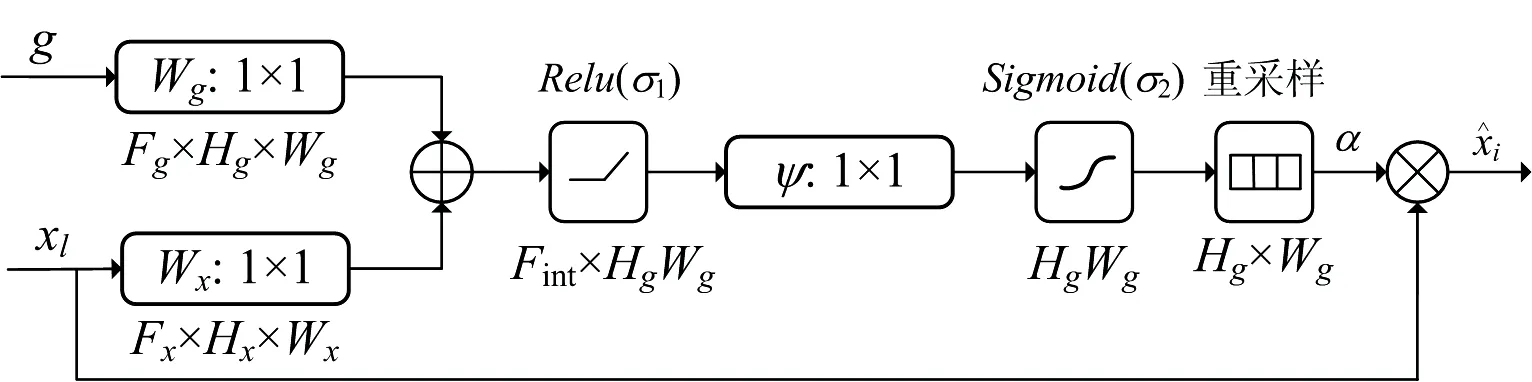
图3 注意力门控模块结构图
融合U-Net++和注意力机制使用已划分好的训练集对模型进行训练,并使用训练好的模型对测试集中的羊毛样本的羊毛含量等级进行预测。所建立的U-Net++模型主要由输入层、卷积层、标准正则化层、最大池化层、全局平均池化层、上采样层以及注意力门控模块组成。传统的U-Net++网络主要用于医学图像分割,对应的数据一般是二维数据,而本研究对不同频段的近红外光的吸收率为一维数据。为此针对原网络结构进行了一定改进:(1)不同于二维的图像数据,由于近红外光谱数据为一维向量,因此在本文的网络中将原网络结构中的二维卷积层、池化层以及上采样层均使用一维的替代。(2)为了产生更具有分辨性的特征信息,将网络结构在原网络的基础上增加上了注意力门控模块。所建立的U-Net++模型参数设置如表2所示,网络结构如图4所示。
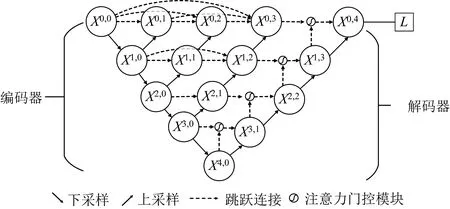
图4 Attention U-Net++结构图
建立的Attention U-Net++模型中,编码器部分通过对输入的光谱数据进行多次下采样提取数据特征,同时在解码器部分中加入了注意力门控模块。在设计网络模型时,合理设计网络结构,对模型性能的提高十分重要。本模型参考U-Net++的结构,在特征提取部分设置五层,每一层由一维卷积层、批量正则化层、最大池化层、全连接层组成,每层的具体网络参数结构如表2所示。在上采样部分同样设置为五层,每层经过上采样层之后再与前一层输出的特征向量通过注意力门控模块进行融合,以X(1, 3)为例,该节点的是由X(1, 0),X(1, 1),X(1, 2)先经过拼接生成新的特征信息,再将拼接生成的新的特征信息与X(2, 2)共同经过注意力门控模块所得;最后将融合的特征经过一维全局平均池化层、Dense层以及输出层,最终使用softmax函数得到预测分类结果。

表2 下采样部分每层网络结构参数
研究的模型运行环境为:Intel(R)Core(TM)i5-10300H CPU;16 GB计算机内存;NVDIA GeForce GTX 1650显卡;使用软件为PyCharm,并配有NumPy,Pandas,Keras等Python运算库。
1.5 模型评价指标
常用的多分类模型评价指标有准确率(Accuracy)、平均准确率、混淆矩阵等,本文选择准确率、召回率(Recall)、精确率(Precision)、F1分数(F1-Score)以及混淆矩阵作为评价指标来评价所提出的分类模型预测精度。以上所提到的评价指标计算公式如式(7)—式(10)所示。
(7)
(8)
(9)
(10)
在一般的二分类问题中,真阳性(TP)表示被模型预测为正的正样本,真阴性(TN)表示被模型预测为负的负样本,假阳性(FP)表示被模型预测为正的负样本,假阴性(FN)表示被模型预测为负的正样本。所涉及的分类问题为三分类问题,即如果将“羊毛含量低”这一类别看作正类的话,那么其他两类都属于负类,对于其他两类以此类推。一般来说,Accuracy的值越接近1,表示模型的分类预测精度越高。在计算以上几个评价指标时,将三分类问题看作三个二分类问题,分别计算每一类的各项指标,再根据每类样本占所有样本的比例分配不同的权重,最后进行加权平均计算整体样本的各项指标。混淆矩阵是评价精度的一种标准格式,用n行n列的矩阵形式来表示;每一列代表样本预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表样本实际类别,每一行的总数表示该类别样本的个数。
2 结果与讨论
2.1 Attention U-Net++分类模型预测
本工作研究的是分类问题,采用了分类问题中常用的交叉熵损失(categorical cross entropy)作为损失(loss)函数来计算预测结果与实际值之间的差值,交叉熵损失函数公式如式(11)所示,其中M代表类别的数量;yic代表指示变量,即如果样本i的真实类别相同等于c就是1,否则为0;pic代表对于观测样本i属于类别c的预测概率;同时在网络训练的过程中所选择的优化器为Adam优化器。
(11)
将训练模型中的学习率(learning rate)设置为0.001,批大小(Batchsize)设置为10,迭代次数设置为100次。图5(a—d)分别为模型在训练过程中训练集和验证集上的loss值和准确率的变化趋势,从训练集的损失函数变化趋势可以看出,loss值随着迭代次数的增加逐渐减小,其中前20次迭代过程中loss值快速下降,20次之后下降趋势逐渐平稳;验证集在前50次的迭代中还存在明显的波动,50次迭代后在验证集上的性能趋于平稳,模型达到收敛。在模型训练100次之后保存所训练的模型,对测试集中的光谱数据进行测试,并评估模型的性能。
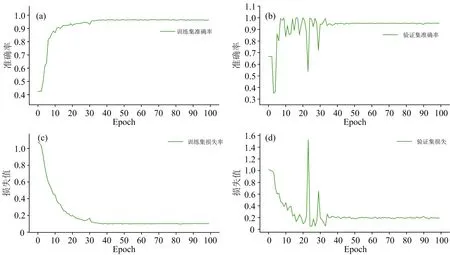
图5 训练集和验证集的损失和准确率变化趋势
在评估模型性能时采用十折交叉验证的方式,其中训练集、验证集以及测试集的比例为8∶1∶1。为避免因同一样本光谱之间的相似性造成过于乐观的评估结果,在划分数据集时将属于同一样本的光谱数据划分至同一数据子集中(如训练集、验证集或测试集)。表3为所提出的模型经过十折交叉验证之后在训练集、验证集以及测试集的平均准确率,该模型在测试集上的预测精度为93.59%,略低于在训练集上的准确率。图6为其中一次交叉验证结果绘制的混淆矩阵。可以看出,分类预测效果达到预期,尤其是对检测标签为“羊毛含量低”的样本,基本可以检测出羊毛含量低的样本;同时从表3的训练集和测试集的预测结果来看,模型未出现过拟合、欠拟合的现象,模型的性能达到理想效果。

表3 十折交叉验证平均结果
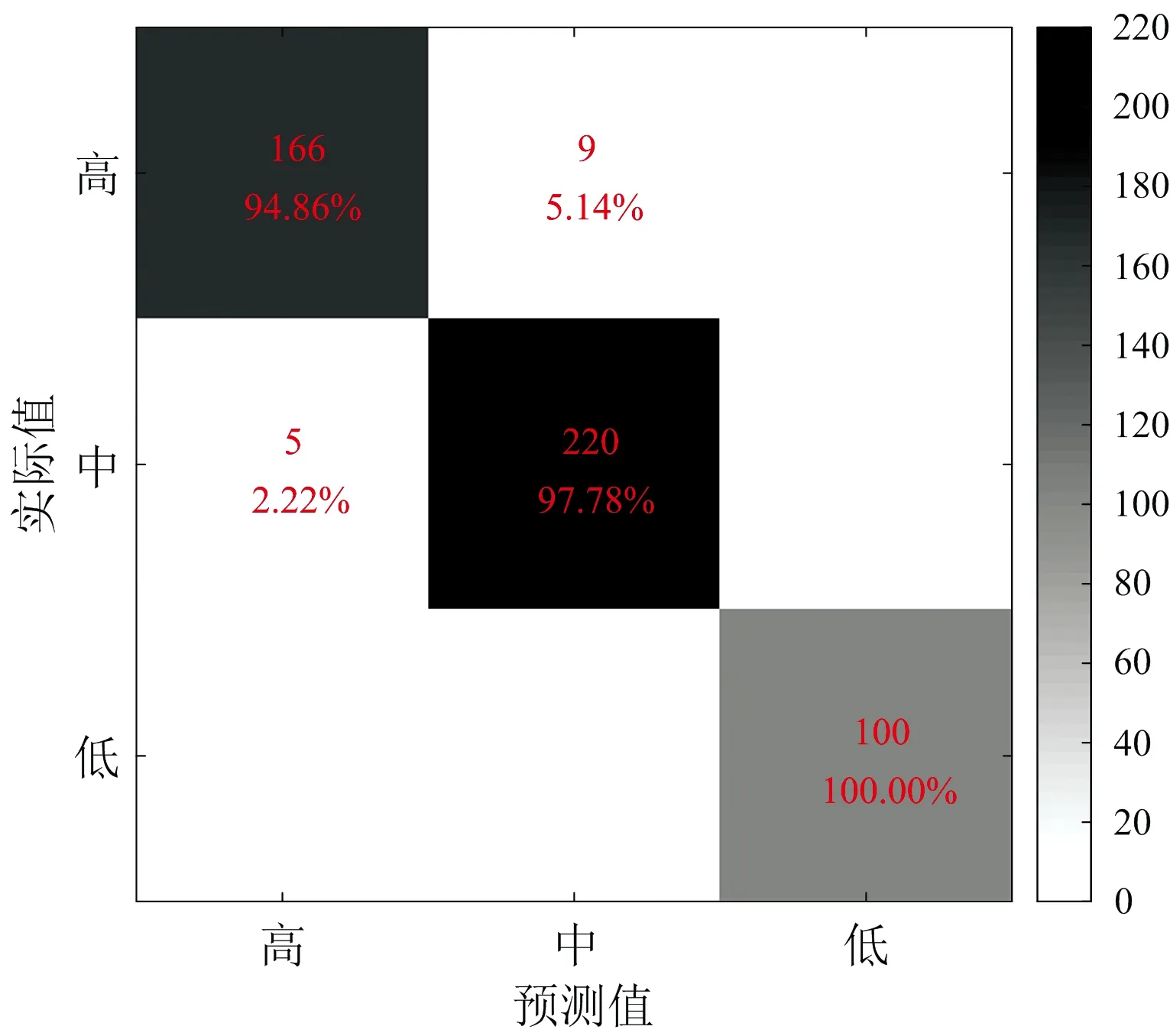
图6 Attention U-Net++模型一次预测结果混淆矩阵
2.2 不同模型预测
为了评价所采用Attention U-Net++模型的性能,选择了目前较为常用的分类模型进行对比。所选择用于对比的模型包括随机森林模型、支持向量机算法(support vector machine, SVM)模型,卷积神经网络模型(convolutional neural networks, CNN)以及卷积自编码(convolutional autoencoder,CAE)模型。进行对比实验时,随机森林决策树数目设为200,SVM模型的惩罚系数设为2,CNN网络模型使用4层卷积,输出层分类函数使用Softmax分类函数,优化器使用Adam,loss值使用交叉熵损失函数,CAE模型的编码器和解码器都使用3层卷积。几种模型的分类预测结果如表4所示,可以看出,在使用相同的羊毛制品近红外光谱数据对模型进行训练的情况下,本文提出的Attention U-Net++模型预测准确率可达到93.59%,明显优于传统的机器学习方法和神经网络模型;这是因为本文模型通过不同层次特征之间的融合,缩小了编码器和解码器之间的差距,同时注意力门控模块也可以对重要特征信息进行聚焦,从而提高模型的预测分类精度。
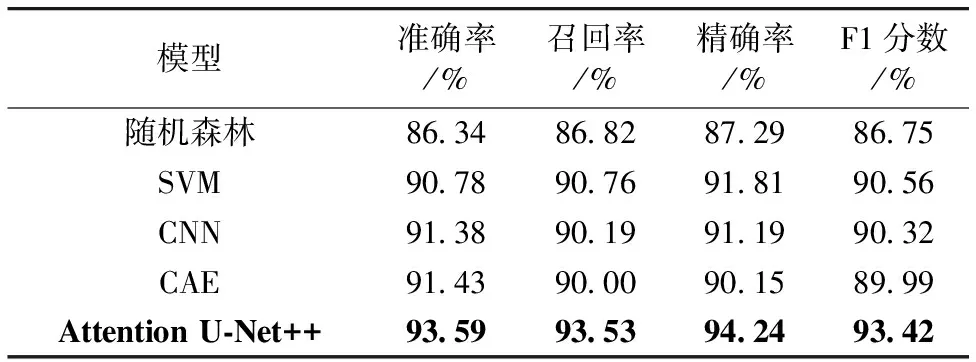
表4 不同分类模型预测结果对比
2.3 不同U-Net系列模型预测
为了验证本模型所使用的密集跳跃连接和注意力门控模块的效果,将提出的Attention U-Net++网络与其他U-Net系列网络模型(包括U-Net,Attention U-Net以及U-Net++)进行对比实验,用于进行对比实验的几个模型的数据集与参数设置均与本文模型一致,预测分类结果如表5所示。
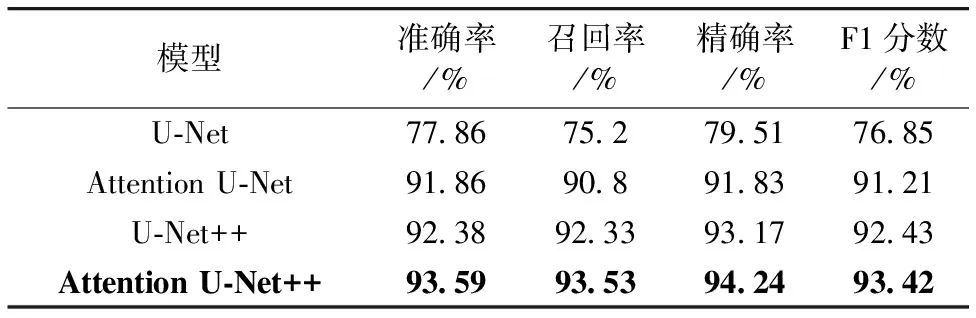
表5 不同U-Net系列模型预测结果对比
从表5可以看出,本文提出的Attention U-Net++模型预测准确率为93.59%,召回率为93.53%,精确率为94.24%,F1分数为93.42%,均高于其他三个模型。与U-Net和Attention U-Net网络模型相比,本文所使用的模型使用了密集的跳跃短连接代替了原始的简单逐层连接,实现了不同层次的U-Net网络的融合,减小了低层特征和高层特征信息之间的语义鸿沟,充分挖掘数据特征信息,因此对模型的预测精度有所提升,准确率分别从77.86%和91.86%提高到93.59%。与U-Net和U-Net++网络模型相比,本文模型加入了注意力门控模块,这一模块通过计算注意力参数对无关的特征信息在一定程度上进行抑制,对相关的特征信息进行重点关注,从而更有效地提取特征信息,实现更精确的预测分类。综上所述,所建立的算法模型通过密集的跳跃短连接以及注意力门控模块,能够实现对特征信息的有效挖掘和利用,与其他算法相比,各项评价指标均有显著提升。
3 结 论
鉴于近红外光谱技术具有效率高、样本无需预处理且可实现无损检测等优点,使用手持便携式近红外光谱仪获取羊毛制品的光谱数据并结合深度学习技术提出了一种基于融合注意力机制的改进U-Net++模型,从而实现对羊毛制品中羊毛含量的快速分析。实验结果表明所提出的Attention U-Net++模型通过下采样、跳跃连接以及上采样等过程可以有效挖掘一维光谱中蕴藏的信息,并用于准确分类。使用样本数据中10%的数据作为测试集对模型进行性能评估发现,本模型能够对羊毛样本进行分类预测,分类预测准确率可达93.59%,召回率为93.53%,精确率为94.24%,相比传统的分类模型如RF,SVM,CNN等有着更高的预测精度。研究结果也表明了深度学习与光谱数据的结合能够更有效地挖掘数据所含的深层特征信息,将设计更加精巧的深度学习网络引入近红外光谱分析领域,为检测技术提供了一种新的思路。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
空间科学学报(2021年1期)2021-05-22
纺织服装流行趋势展望(2020年4期)2020-02-01
意林·全彩Color(2019年9期)2019-10-17
汉语世界(The World of Chinese)(2019年2期)2019-04-19
作文与考试·小学高年级版(2017年23期)2017-12-14
系统工程与电子技术(2016年7期)2016-08-21
系统工程与电子技术(2016年7期)2016-08-21
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
智能系统学报(2015年4期)2015-12-27
