
集成学习结合波长选取的有机物红外光谱定量回归方法研究
2023-01-31 12:21鲁昌华张玉钧陈晓静蒋薇薇
光谱学与光谱分析 2023年1期
鞠 薇,鲁昌华,张玉钧,陈晓静,蒋薇薇
1.安徽大学互联网学院,安徽 合肥 230039 2.合肥工业大学计算机与信息学院,安徽 合肥 230009 3.中国科学院合肥物质科学研究院,安徽 合肥 230031
引 言
有机化合物中组分的种类及含量信息是决定其性质的关键因素。有机物分子在中红外波段具有发射和吸收红外辐射的能力,不同种类及含量的有机物分子的红外光谱呈现出位置及幅度不同的红外吸收峰。
红外光谱技术发展至今,已形成较为完善的理论体系,能够通过精密光谱测量仪器获取高分辨率以及宽波段的有机物红外光谱,如何利用高效分析算法快速精确地计算出光谱中包含的有机物信息是红外光谱技术领域现阶段的研究重点。红外光谱定量回归方法通过对大量红外光谱样本进行筛选及优化,提取光谱数据中的有用信息并利用该信息解析未知光谱中包含的有机物组分。常用的光谱定量回归算法为化学计量学方法中的经典最小二乘(classical least squares, CLS)、多元线性回归(multiple linear regression, MLR)、偏最小二乘(partial least squares, PLS)等。随着近年来机器学习技术的迅猛发展,研究人员尝试利用支持向量机(support vector machine, SVM)[1],随机森林(random forest, RF)[2],决策树(decision tree, DT)[3],卷积神经网络(convolutional neural networks, CNN)[4]等算法对红外光谱数据进行分类以及定量回归,与化学计量学相比,机器学习算法在处理非线性数据上表现出明显的优越性。
机器学习中不同算法在预测准确性、稳定性以及时间效率上分别有着不同的优异表现,集成学习(ensemble learning)通过融合各类机器学习算法的优点,获取更为优异的泛化性能。卢伟[5]等利用Stacking集成学习模型结合高光谱技术对黑枸杞品质进行快速无损分级。Yu[6]等将集成学习理论与神经网络算法相结合用于判断蒸汽管道红外光谱的高温区域,与其他图像分类算法相比,该方法具有更高的准确率且满足实际工程需要。与深度学习相比,集成学习的优点在于它具有对计算资源软硬件配置要求较低,且不受限于待测数据集样本数量等特点;自动化的大型集成策略可以通过添加正则项有效的对抗过拟合,且不需要太多的调参和特征选择。
高分辨率红外光谱可以精确反映出有机物分子的细微含量变化,但高分辨率也使得光谱数据量剧增,光谱中不仅包含目标组分信息,还存在干扰组分以及冗余变量信息。特征波长选取算法[7]通过筛选信息量最为丰富的波长组合,利用特征波长组合进行定量回归建模能够减少计算量、增加模型预测能力以及抗干扰能力。常用的红外光谱特征波长选取方法包括间隔偏最小二乘(interval PLS, iPLS),组合间隔偏最小二乘(synergy interval PLS, SiPLS),连续投影算法(successive projections algorithm, SPA),竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)等。
首先利用多种机器学习算法构建两层Stacking集成学习模型,对光谱数据集中的有机物含量进行定量分析。实验结果表明集成学习模型能够应用于有机物红外光谱定量分析,且预测精度高于传统光谱定量分析工具PLS模型。在此基础上,提出了一种特征波长选取结合集成学习建模的红外光谱定量回归方法,该方法通过特征波长选取方法对红外光谱进行特征降维预处理,之后利用集成学习模型对预处理后的红外光谱数据集进行回归分析,讨论特征波长选取对于集成学习模型的回归精度及效率的影响,为红外光谱定量回归分析提供创新思路和方法参考。
1 实验部分
1.1 样本数据
数据来自美国西南研究所提供的柴油红外光谱,该公开数据集旨在为红外光谱定量回归模型的研究提供数据支持。
柴油数据集中包含784条未经处理的柴油红外光谱以及所对应的七个属性值(沸点、十六烷含量、密度、闪点、冰点、总芳香烃含量和黏性),部分光谱的某些属性值缺失。实验开始前需要将属性值缺失的光谱样本剔除。光谱的波长区间为750~1 550 nm,波长间隔为2 nm,每条光谱包含401个波长。本文选取柴油的十六烷含量和总芳香烃含量作为有机物定量回归模型属性参数,剔除缺失值后十六烷值所对应的有效光谱样本为381条,总芳香烃值所对应的有效光谱样本为395条。柴油红外吸光度光谱如图1所示。

图1 柴油原始吸光度光谱
1.2 数据预处理
在进行特征波长选取以及定量回归建模之前,首先利用Kennard-Stone算法以4∶1的比例将数据集划分为训练集和预测集。Kennard-Stone算法通过计算样本间的欧氏距离,找到拥有最远及最近距离的待选样本放入训练集,该算法能够保证训练集中的样本按照空间距离分布均匀,从而增加样本间的差异性和代表性,提高回归模型的稳定性。
1.3 特征波长选取算法
特征波长选取算法能够从大量波长变量中提取出与目标参数密切相关的波长,从而优化光谱数据集,最终以尽可能少的波长变量来表征尽可能多的目标参数信息。与全光谱建模相比,利用特征波长进行建模能够有效简化模型复杂度,降低计算资源消耗,同时增加模型预测精度与抗干扰能力。
组合偏最小二乘算法(SiPLS)[8]是以PLS建模为基础的特征波段选取方法,该方法将全光谱波段划分为若干等宽的子区间,从中选取2~4个子区间进行组合,比较所有子区间组合PLS建模的预测结果,最终选取交叉验证均方根误差(RMSECV)最小的子区间组合作为特征波段。SiPLS改善了iPLS单一区间建模造成的特征信息丢失问题,同时考虑不同波段之间的相互联系以及组合建模对于定量回归模型的影响。
连续投影算法(SPA)[9]是Bregman等于1965年提出的一种循环波长选取方法,该算法通过分析波长向量的投影大小,将投影向量最大的波长作为特征波长。每次循环选取过程中将投影向量最大的单个波长加入特征波长组合中,新选入的波长与前一个选入波长之间相关度最低,重复投影循环步骤,直到选取一定数目的特征波长组合。SPA算法与其他特征波长选取算法相比,其最大优点是能够消除波长变量之间的共线性影响,提高建模速度和模型的稳定性。
1.4 Stacking集成学习模型
集成学习通过组合多个基学习器来获得一个稳定且在各方面表现都较好的强学习器。每个基学习器为解决同一个问题,分别运用各自的机器学习算法对训练数据集进行处理,之后根据融合策略将多种不同的机器学习算法进行融合以获得预测能力更好的强学习器。集成学习能够结合众多机器学习算法的优点,弥补某些算法在例如运行时间效率、准确率上的缺点,并且可以通过不同的融合策略,改进预测模型的泛化能力,在有限数据条件下提高预测能力。
集成学习的融合策略是将基学习器结合在一起的方法,例如使用投票法来求解分类问题中输出最多的类,使用平均法求解回归问题的预测值。除了投票法和平均法之外,集成学习中常用的融合策略还包括Stacking和Blending。Stacking模型是一种已被实践证明能够有效提高模型预测精度的集成学习融合策略,其利用多个基学习器对原始数据进行训练,将得到的训练集预测结果和测试集预测结果分别作为下一层学习器的输入训练集和测试集,最终训练得到预测性能更优良的强学习器。强学习器又称元学习器(meta-learner),其作用是对基学习器的预测结果进行整理融合并为基学习器分配相应的权重,最终提高模型预测精度。Stacking模型通常考虑异构弱学习器,即使用不同类型的机器学习算法训练基学习器。对比Stacking策略中基学习器采用的K折交叉验证方法进行数据训练,Blending策略只使用一部分数据集作为留出集(Hold Out)进行验证,其实现更为简单,但是模型稳健性相比于Stacking策略要差。
利用两层Stacking集成学习模型对柴油红外光谱进行有机物含量定量回归预测,其具体实现流程如图2所示:
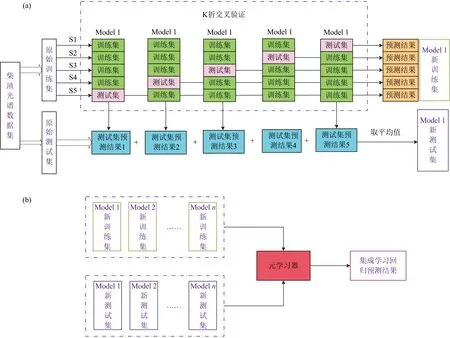
图2 柴油光谱Stacking集成学习流程图
(1)将柴油光谱数据集按照KS算法划分为训练集和测试集。Stacking模型利用K折交叉验证原理对训练集进行训练。图2(a)为基学习器的训练过程,将训练集划分为K-1个子训练集及一个子测试集,在子训练集上利用基学习器的机器学习算法训练获得预测模型,并利用该模型获取子测试集的预测结果。K交叉验证共训练K个子训练集,获得K个预测模型及子测试集预测结果,将子测试集预测结果拼接成为基学习器1的新训练集。同时使用每个子训练集的预测模型对测试集进行预测,共获得K个测试集预测结果,将K个结果取平均值,构成基学习器1的新测试集。图中以五折交叉验证为例。
(2)分别使用不同机器学习算法构成基学习器,对柴油光谱数据进行训练,获得不同基学习器的训练结果,将n个基学习器训练得到的新训练集组合生成元学习器的训练集,基学习器预测得到的新测试集组合生成元学习器的测试集,输入元学习器后获取最终集成学习预测结果。图2(b)显示了元学习器的训练过程。
1.5 基学习器模型
决策树(DT)是一种树形结构的机器学习算法,树的每个内部节点表示对某一个属性值的判断,根据判断结果对样本进行划分并分配到下一层子节点,循环进行属性值判断及样本划分,每个终端叶子节点代表一种分类结果。由定义可知,属性值的判断是构建决策树的关键因素,常用的属性值判断方法包括ID3,C4.5和CART,三种方法分别使用增熵、信息熵益率和GINI指数作为属性值的判断依据。
极端随机树(extremely randomized trees,ERT)是由随机森林算法发展而来的。随机森林是以决策树为基本单元的集成学习算法,由Breiman等于2001年提出。随机森林采用Bagging策略对训练集进行随机有放回抽样,抽样得到的数据集作为决策树的输入,最后通过平均各个决策树预测结果的方式获得随机森林模型的回归预测值。
2006年,Geurts等[10]在随机森林的基础上提出了极端随机树模型,极端随机树改进了随机森林Bagging策略获得训练集时重复采样可能造成的训练集样本重复问题,在极端随机树中,每棵决策树的训练都是基于整个数据集得到的,这样可以保证所有样本都能被学习,样本利用率提高可以减少模型的整体预测偏差。极端随机树的另一个改进表现在节点的划分上,对比随机森林的最佳属性值分裂原则,极端随机树随机选取特征属性值进行节点分裂,从而将该特征属性下训练样本随机分配到不同分支上,利用该节点分裂方法遍历节点内所有特征属性,选取GINI值最小的特征作为最优划分属性。
支持向量机(SVM)是由Cortes和Vapnik于1995年提出的一种二分类模型,其基本思想是寻找一个最大间隔超平面对样本进行分割,寻找过程可以转换为求解凸二次规划的问题,SVM模型也就是求解凸二次规划的最优化算法。对于非线性分类问题,SVM通过引入核函数(如多核聚类算法[11])和软间隔最大化将样本从原始空间非线性映射到高维空间,使样本在该高维空间线性可分,从而将原始空间的非线性分类问题转化为高维特征空间的线性SVM问题。因此SVM能够在解决小样本、非线性及高维模式识别等问题中表现出明显的优势。
1.6 模型评价指标
集成学习通过在训练集进行学习获取红外光谱定量回归模型,之后利用评价指标检验模型的预测能力,本工作使用相关系数(correlation coefficient,r),预测集均方根误差(root mean square error of prediction, RMSEP)和相对分析误差(relative percent deviation, RPD)指标对回归模型进行评价,各个指标的计算公式分别为
(1)
(2)
(3)

2 结果与讨论
2.1 基于Stacking集成学习的红外光谱定量回归模型
采用两层Stacking集成学习对柴油红外光谱进行定量回归建模,第一层使用四个基学习器[11],分别是ERT、LinearSVM、RBFSVM和polySVM。基学习器的训练结果通过LinearSVM元学习器进行数据融合获取最终预测结果。为比较Stacking集成学习模型的预测效果,分别建立PLS定量回归模型、ERT模型、LinearSVM模型、RBFSVM模型和polySVM模型作为对比模型,比较不同模型对测试集数据的预测结果,柴油十六烷和总芳香烃含量的模型预测结果列于表1中,模型预测值与测量值之间相关关系如图3和图4所示。
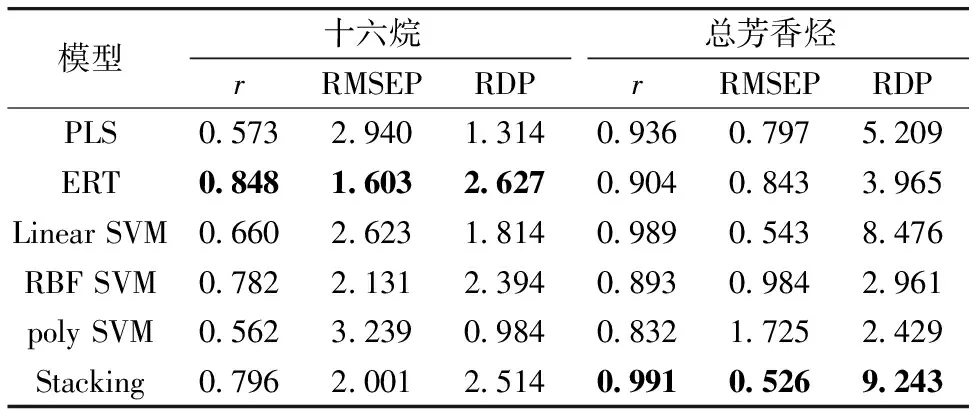
表1 柴油有机物含量模型预测结果
由表1和图3、图4可知:柴油光谱十六烷含量的预测结果中,ERT模型预测结果最优,r为0.848,RMSEP为1.603,RDP为2.627;Stacking模型次之,r为0.796,RMSEP为2.001,RDP为2.514;PLS模型的预测结果,r为0.573,RMSEP为2.940,RDP为1.314。柴油光谱总芳香烃含量的预测结果中,集成学习Stacking模型预测结果最优,r达到0.991,RMSEP为0.526,RDP达到9.243;LinearSVM模型稍次之,r为0.989,RMSEP为0.543,RDP为8.476;PLS模型的预测结果中,r为0.936,RMSEP为0.797,RDP为5.209。

图3 柴油十六烷含量预测值与测量值之间相关关系

图4 柴油总芳香烃含量预测值与测量值之间相关关系
结果表明,集成学习模型与传统光谱定量回归模型PLS相比,能够提高柴油光谱的定量回归精度。其中,柴油总芳香烃含量的PLS模型预测精度较高,集成学习Stacking模型较PLS模型的预测精度有少量提高,测试集相关系数r由0.936提高至0.991;而柴油十六烷的PLS模型预测精度较低,ERT模型有效提高了定量回归预测精度,其测试集相关系数r由PLS模型的0.573提升至0.848,模型预测能力有了较大提高。
2.2 特征波长选取结合Stacking集成学习的红外光谱定量回归模型
特征波长选取是一种有效的数据降维方法,通过搜寻光谱数据集的最优特征波长,利用少量特征波长进行建模,以达到减少运算量、提高模型预测精度的目的。分别采用SiPLS和SPA特征波长选取方法优选柴油红外光谱的十六烷及总芳香烃的特征波长,建立集成学习定量回归模型。
SiPLS方法中,将全光谱划分为相等的10个子区间,任意三个子区间进行组合建模,共120种区间组合方式,选取RMSECV最小的子区间组合作为特征波长。柴油红外光谱的两种属性特征波长选取结果如图5所示。

图5 柴油光谱SiPLS特征波长选取结果
采用SPA特征波长选取方法对柴油光谱十六烷组分和总芳香烃组分进行特征波长选取,分别获取11个和34个特征波长,波长选取结果如图6所示。

图6 柴油光谱SPA特征波长选取结果
对柴油两种有机物含量进行特征波长选取后,将筛选后的光谱数据作为输入数据集,分别建立PLS定量回归模型以及集成学习定量回归模型,各训练模型的测试集预测结果列于表2中。
对比表1与表2可以发现:SPA特征波长选取后的PLS模型预测结果明显优于全光谱PLS建模,其中,柴油十六烷的SPA-PLS模型的r为0.823,RMSEP为1.862,RDP为2.536;总芳香烃的SPA-PLS模型的r为0.982,RMSEP为0.769,RDP为6.963。然而SPA特征波长选取处理后集成学习各基学习器及融合模型的预测结果均差于全光谱建模。SiPLS特征波长选取后的各类定量回归模型预测结果均优于全光谱建模,其中柴油十六烷含量的SiPLS-ERT模型的预测结果最优,r为0.893,RMSEP为1.013,RDP为3.051;总芳香烃含量的SiPLS-Stacking模型的预测结果最优,r为0.998,RMSEP为0.354,RDP为11.475。

表2 特征波长选取后柴油有机物含量模型预测结果
结果表明,SiPLS特征波长选取方法能够有效提高集成学习定量回归模型的预测精度,SPA方法由于选取的特征波长数量较少,十六烷共选取11个特征波长,总芳香烃共选取34个特征波长,集成学习模型在利用少量特征波长数据进行训练建模时容易产生欠拟合现象,无法获得理想的预测效果。图7、图8为柴油光谱SiPLS特征波长选取后的定量回归模型对测试集进行预测的相关系数散点图。

图7 SiPLS波长选取后柴油十六烷含量测试集预测结果
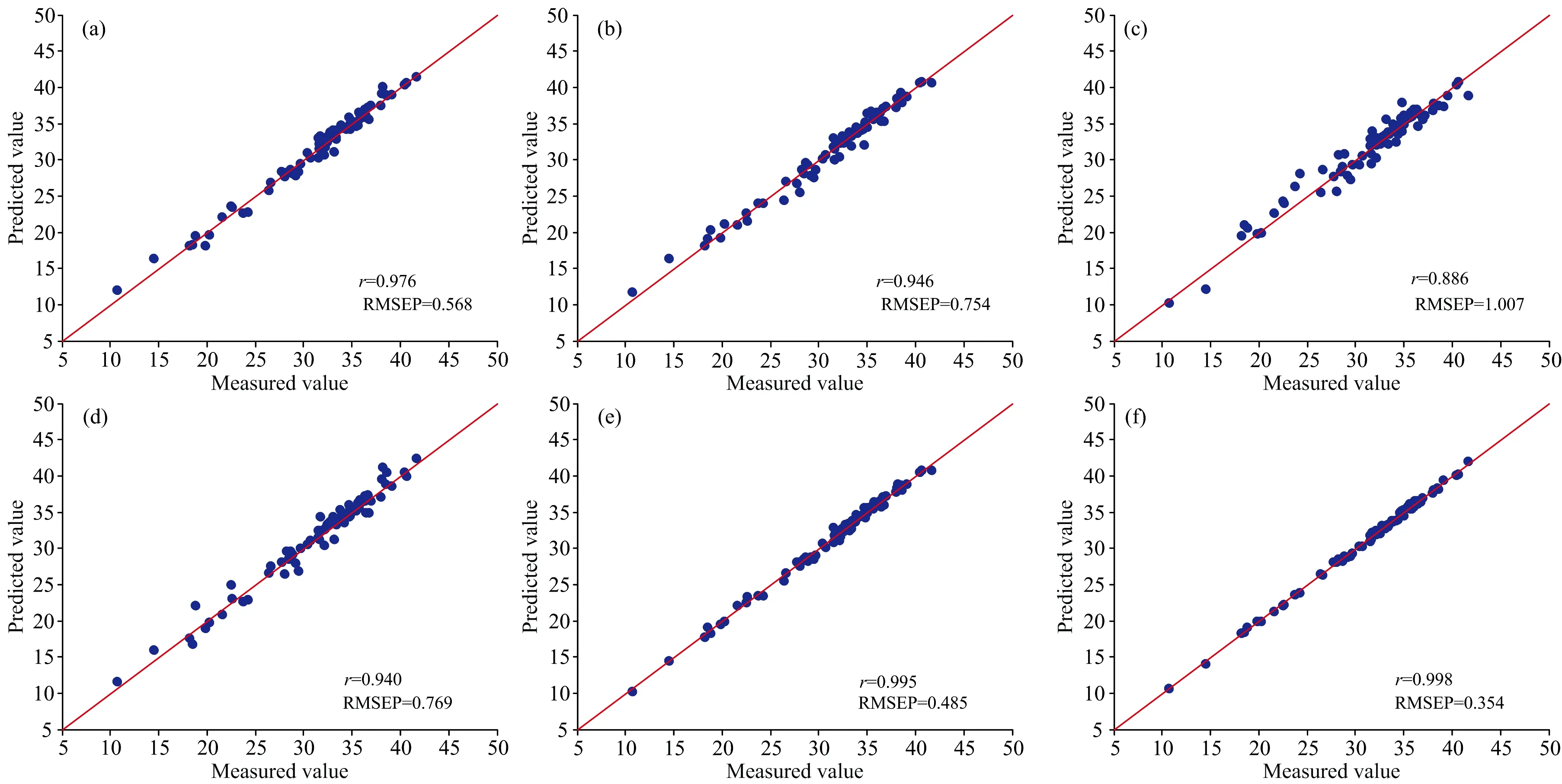
图8 SiPLS波长选取后柴油总芳香烃含量测试集预测结果
同时对比了SiPLS特征波长选取应用于集成学习定量回归模型的平均建模速度,全光谱共401个波长,SiPLS共120个特征波长,特征波长数量为全光谱的30%,结果纪录于表3中。

表3 SiPLS特征波长与全光谱建模的时间对比
由表3可以看到,经过特征波长选取后集成学习建模速度提升明显,特别是预测效果最好的ERT模型和Stacking模型,建模速度提升率都超过50%。因此,使用特征波长选取方法结合集成学习建模,不仅能够有效提高红外光谱定量回归分析的预测精度,而且可以大幅提升数据分析效率。
3 结 论
研究了集成学习结合特征波长选取方法在有机物红外光谱定量分析中的应用。首先利用ERT、LinearSVM、RBFSVM、polySVM基学习器构成Stacking两层融合模型,对比了Stacking模型与PLS模型对柴油光谱的两种有机物含量的预测结果,结果表明集成学习模型能够应用于红外光谱定量分析中且预测精度较传统方法有所提高。进一步比较特征波长选取方法作为光谱预处理对集成学习定量回归模型的影响,结果表明SiPLS特征波长选取方法能够有效提高集成学习模型的预测精度以及建模效率。现阶段集成学习领域的研究向着动态自动构建集成框架以及保持基学习器的准确性和多样性方向发展[13],在下一步的工作中,将尝试利用不同种类特征波长选取方法以及动态集成学习框架,以实测有机物红外光谱及高光谱图像为实验对象,研究集成学习在有机物光谱的定量回归分析中的普遍适用性以及最优泛化模型。
猜你喜欢
世界科学技术-中医药现代化(2020年2期)2020-07-25
石油知识(2019年1期)2019-02-26
中成药(2018年12期)2018-12-29
中成药(2017年6期)2017-06-13
中南大学学报(自然科学版)(2016年2期)2017-01-19
中国照明(2016年4期)2016-05-17
通信电源技术(2016年4期)2016-04-04
智能建筑电气技术(2015年5期)2015-12-10
医学研究杂志(2015年4期)2015-06-10
中国当代医药(2015年26期)2015-03-01
