
近红外和电子鼻数据融合识别不同香型风格
2023-01-31 12:20王文俊沙云菲汪阳忠刘太昂张旭峰孟祥周
光谱学与光谱分析 2023年1期
王文俊,沙云菲,汪阳忠,于 洁,刘太昂,张旭峰,孟祥周,葛 炯*
1.上海烟草集团有限责任公司技术中心,上海 200082 2.上海真谱信息科技有限公司,上海 200444 3.同济大学环境科学与工程学院,上海 200092
引 言
烤烟香型不仅是中式卷烟风格主要因素之一,也对烟叶品质的区分有着重要的参考价值。烟草著名专家朱尊权院士最早将烤烟香型分为清香型、中间香型和浓香型3大类[1]。对于不同香型烤烟的差别,人们进行了大量的研究。早期的研究人员如刘金霞、席元肖等主要考察不同香型烤烟化学成分的差异,这些化学成分主要集中在总植物碱、总糖、还原糖、总氮等常规化学成分[2-3]。有研究者尝试基于这些常规化学成分建立烤烟香型的模式识别模型。如郭东锋等基于常规化学成分建立烤烟香型机器学习分类模型[4]。烟叶中的致香成分对烤烟香型的影响更大、更直接。后续的研究人员如许永等更加深入的研究了烤烟中的茄酮、糠醛、二氢猕猴桃内酯、巨豆三烯酮共45中致香成分的差异。利用逐步回归筛选出14种致香成分,并基于这14种致香成分建立7种烤烟香型分类模型[5-6]。在进行致香成分检测时,需要复杂的化学方法,费时、费力、费钱。近红外光谱分析可以实现快速、无损检测,已经有非常多的学者进行了研究[7]。三种香型烤烟的致香成分存在差异,这些差异可以用近红外光谱分析得到。束茹欣等收集了3 914个烟叶样品的近红外光谱,并基于这些光谱数据建立了烤烟香型的分类识别模型[8]。其中清香型和浓香型的识别结果都比较高,但中间香型的识别结果偏低,可能的原因是近红外光谱包括的信息还不够全面。如果对近红外信息进行补充,可能会得到更好的烤烟香型识别结果[9]。在对烤烟粉末进行中红外扫描时,用到的量非常少,代表性不强,另外中红外光谱包含的致香成分信息也不清晰。本研究尝试利用电子鼻(electronic nose, EN)风味分析仪获取致香成分信息,然后将这些信息作为近红外光谱数据的补充,实现近红外和电子鼻数据融合,并基于新的融合数据实现烤烟香型的识别。
1 实验部分
1.1 材料
选取2018年—2019年清香型、中间香型、浓香型的烟叶样本共401个,其中清香型157个,中间香型151个,浓香型93个。401个样本中随机选取20%共80个样本作为验证集,剩余的321个样本作为建模集。
1.2 烟叶近红外光谱
收集烟叶样品,先进行去梗、切丝等预处理,然后取约40 g烟丝在40 ℃条件下烘干、磨碎、过60目筛后获得进行近红外扫描的实验样品。烟叶NIR光谱数据采集的扫描条件设置如下:仪器选择Thermo Fisher Antaris Ⅱ傅里叶变换近红外光谱仪,分辨率为4 cm-1,扫描次数64次,光谱范围为10 000~3 800 cm-1,在室温下扫描。烟叶近红外数据如图1所示。由于10 000~8 000 cm-1光谱范围对应的信息量很小,因此在数据处理中直接删除了这部分光谱数据。虽然删除了部分数据,但剩余的近红外光谱数据依然高达1 090维。
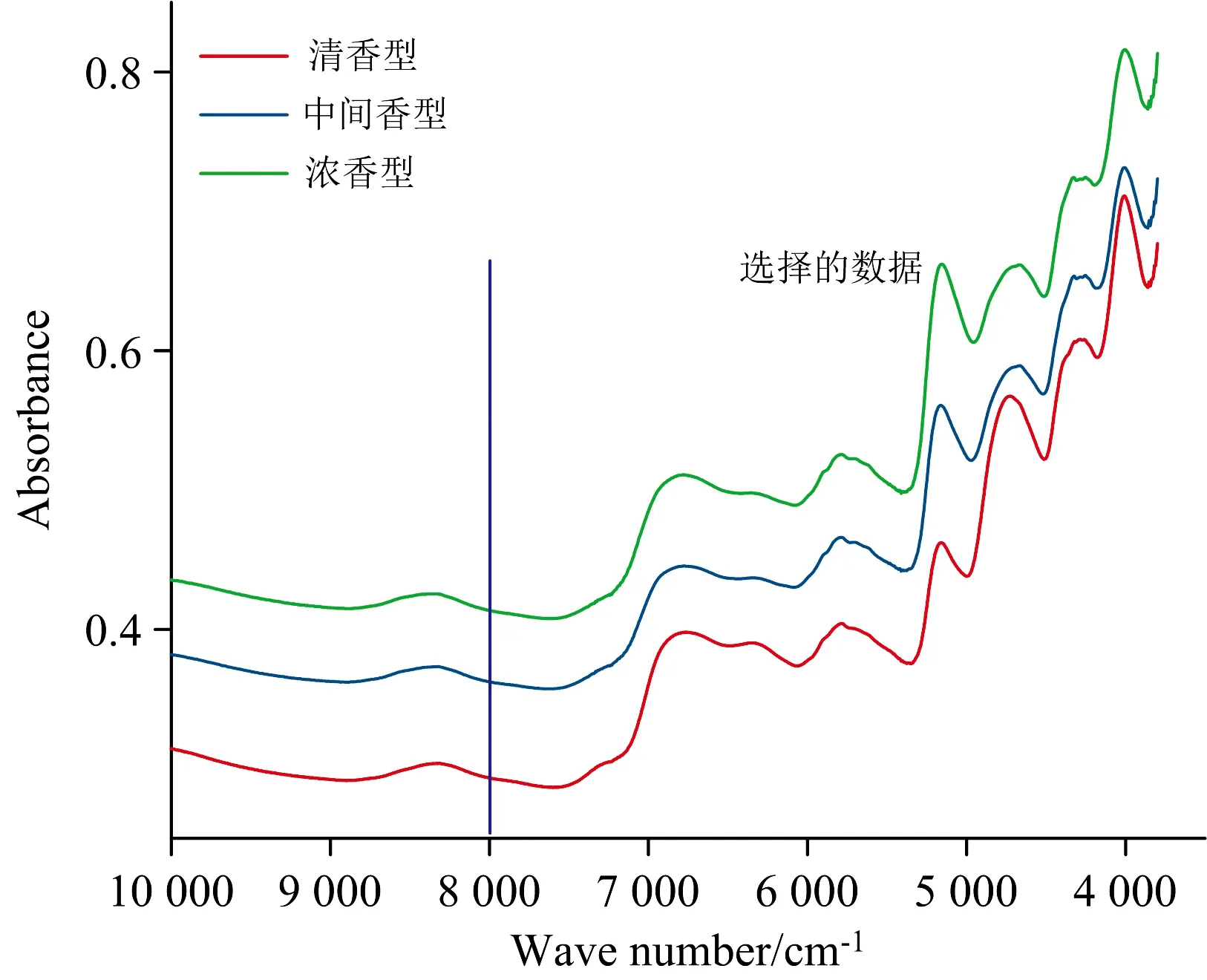
图1 近红外光谱
1.3 烟叶电子鼻数据
取3克烟叶粉末装样品瓶中,在Fox 4000电子鼻风味分析仪上进行电子鼻扫描,该传感器包含18种不同的传感器。传感器信号的测量在以下环境条件下完成:空气温度20~22 ℃,空气湿度30%~45%,单个测试测量窗口时间为120 s。烟叶电子鼻数据如图2所示。在数据处理中取对应时间为3~40 s的信息量大的数据,电子鼻仪器有18种不同的传感器,这样总的数据维数达到了666维。
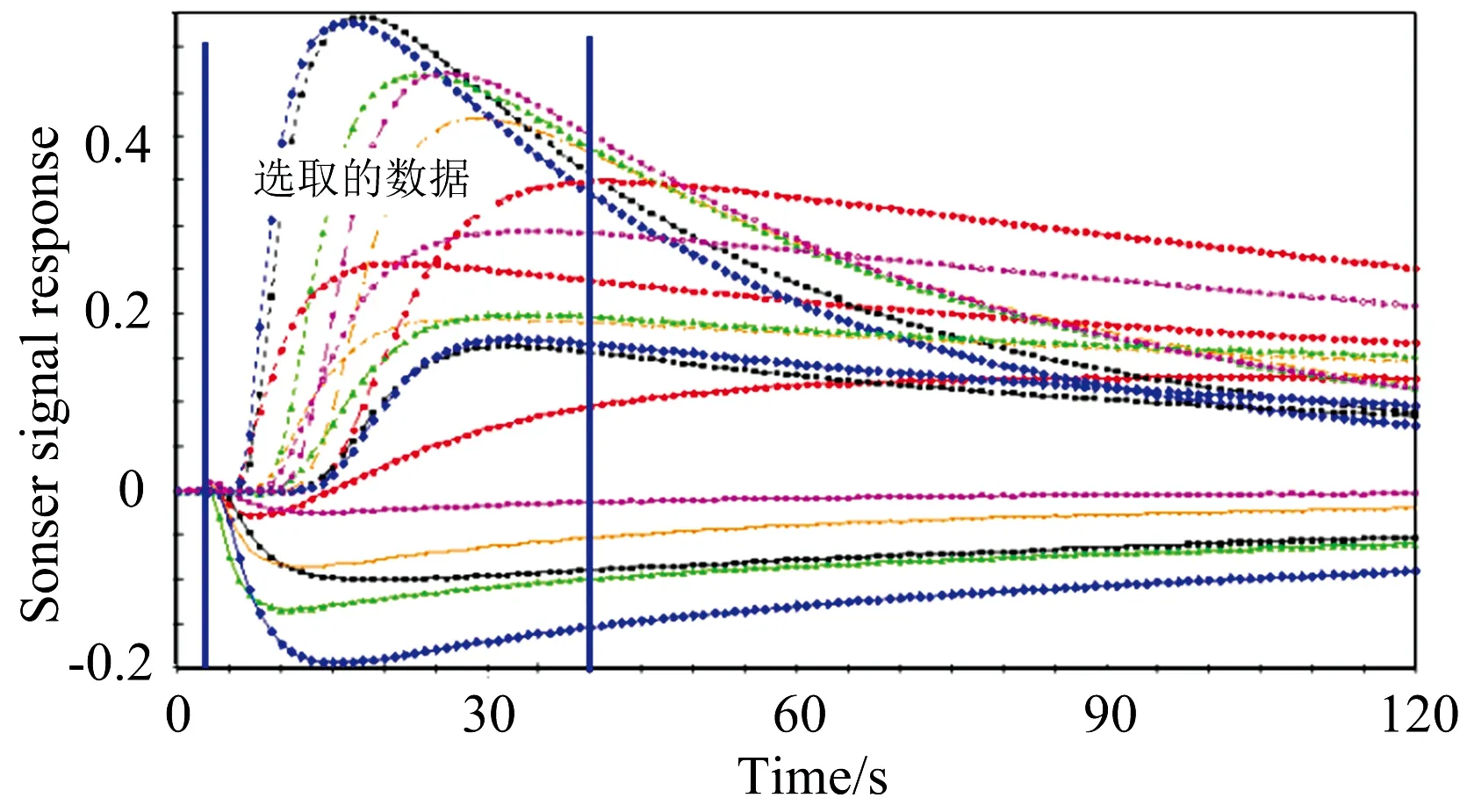
图2 烟叶电子鼻数据
1.4 化学计量学方法
主成份分析法(principal component analysis, PCA)是常用的降维方法,可以把多维变量组合为少数几维互不相关的变量,而且在降维过程,尽可能多保留了原变量的数据结构特征。由于近红外光谱数据和电子鼻数据都是高维数据,因此利用PCA进行数据降维[10]。
支持向量机分类算法(support vector classification,SVC)的核心内容是在进行建模分类过程中,构建出一个最优分类面,此最优分类面可以将样本正确分开,而且要使两类的分类空隙最大。对于构建最优分类面过程即为求函数全局最优解的过程。在利用支持向量机分类算法建立分类模型的过程中惩罚参数c是一个重要的影响参数,对于建立的分类模型的准确率和预报能力影响显著[11]。在此选用径向基核函数,惩罚因子C取18。
人工神经网络(artificial neural network,ANN)通过模拟生物神经网络信息处理机制来进行信息处理,对于输入和输出关系复杂数据,人工神经网络有比较好的非线性拟合能力。但人工神经网络在建模过程中往往出现“过拟合”,对外推预报结果不够准确[12]。
2 结果与讨论
2.1 预处理
为了提高数据信噪比,对近红外谱图数据进行一阶导数和S-G平滑预处理。预处理结果如图3所示。电子鼻数据不进行预处理。
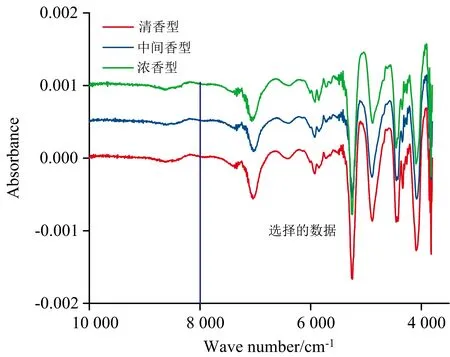
图3 近红外光谱数据一阶导数图
2.2 降维处理
在数据处理中,近红外光谱数据为1 090维,电子鼻数据为666维,两种融合后数据维数更是高达1 756位。建模样本数为321个,变量数远大于样本数。因此需要对数据进行降维。降维方法是PCA。在PCA降维过程中,前20个PCA因子的累积贡献率已经超过99.99%,选择了前20个PCA因子进行建模和预报。
2.3 基于NIR数据的烟叶香型分类模型
选取上述321个三种香型烟叶建模数据集样本,首先用PCA算法对1 090维的近红外光谱数据进行降维,然后选取降维后的PCA因子,再建立支持向量机分类判别模型,最后用该模型对80个验证集样本进行预报,验证模型的可靠性。基于降维后的前20个PCA因子建立的烟叶香型支持向量机分类模型建模和预报结果如表1所示。基于NIR数据的烟叶香型分类模型其建模准确率虽然很高,达到了99.69%,但其预报准确率偏低,只有80.00%,而且对于中间香型和浓香型的预报结果更低,只有72.14和73.33%。

表1 基于NIR数据的SVC模型准确率
2.4 基于EN数据的烟叶香型分类模型
PCA算法对666维的电子鼻数据进行降维,基于降维后的前20个PCA因子建立的烟叶香型支持向量机分类模型建模和预报结果如表2所示。基于EN数据的烟叶香型分类模型其建模准确率较高,为了89.72%,预报准确率很低,只有71.25%,和基于NIR模型的情况相似,也是对于中间香型和浓香型的预报结果差,只有68.97和53.33%。

表2 基于EN数据的SVC模型准确率
2.5 基于NIR-EN融合数据的烟叶香型分类模型
PCA算法对1756维的近红外和电子鼻融合数据进行降维,基于降维后的前20个PCA因子建立的烟叶香型支持向量机分类模型建模结果如表3所示。基于NIR+EN融合数据的烟叶香型分类模型不仅建模准确率较高,为96.26%,预报准确精度也比较高,为83.75%。特别是对于中间香型和浓香型的预报结果和单一的NIR和单一的EN模型预报结果相比有明显的提高,分别达到了82.76%和80.00%。

表3 基于NIR+EN融合数据的SVC模型准确率
2.6 不同算法的比较
为了进一步考察支持向量机算法的可行性和可靠性,进行了ANN算法,对比两者结果。基于NIR和EN融合数据降维后的前20个PCA因子建立的烟叶香型ANN分类判别模型的建模和预报结果如表4所示。ANN模型的建模准确率高,超过了99%,但预报结果明显的低,只有65%,明显低于SVC算法,这是因为ANN算法的过拟合缺点导致。

表4 基于NIR+EN融合数据的ANN模型准确率
3 结 论
利用NIR和EN融合数据建立烟叶香型分类判别研究,无论是其建模结果准确率,还是其预报结果准确率都比较高,这对烤烟香型风格的考察及对烟叶品质的区分有着重要潜在应用价值。对比基于NIR和EN融合数据的烟叶香型分类模型和仅仅基于NIE数据或仅仅基于EN数据的烟叶香型分类模型,虽然这三个模型的建模准确率基本一致,但预报准确率有这明显的差别,特别是对于中间香型和浓香型这两个类型,基于NIR和EN融合数据模型中间香型和浓香型的预报准确率分别为82.75%和80.00%,明显高于其他两个模型不到74%的预报准确率。可能的原因是:电子鼻风味分析仪对于影响中间香型和浓香型的烟叶致香成分感应更加灵敏,捕获的信息也更多,这些新的信息可以作为NIR数据信息的有利补充,可用于建立烟叶香型分类判别准确率更高的模型。ANN算法比SVC算法结果差,可能的原因是ANN算法出现了过拟合现象。研究表明对于烟叶香型的判别,EN数据可以为NIR数据补充有用的信息,从而提高烟叶香型的判别准确率,特别是判别中间香型和浓香型的准确率,这为快速鉴别烟叶香型风格提供支撑,为烟草系统的专业评吸人员提供辅助的鉴别方法。
猜你喜欢
车主之友(2022年4期)2022-08-27
休闲读品·天下(2022年2期)2022-07-13
休闲读品·天下(2022年1期)2022-05-01
现代仪器与医疗(2021年6期)2022-01-18
海峡姐妹(2019年12期)2020-01-14
中医眼耳鼻喉杂志(2019年3期)2019-04-13
中国调味品(2017年2期)2017-03-20
百科探秘·航空航天(2016年6期)2016-12-01
火控雷达技术(2016年1期)2016-02-06
食品工业科技(2014年23期)2014-03-11
