
基于SILPDA的旋转机械故障诊断方法
2023-01-31 08:15董晓鑫赵荣珍
振动与冲击 2023年2期
董晓鑫, 赵荣珍
(兰州理工大学 机电工程学院,兰州 730050)
机械振动信号能迅速、直接地反映机械设备运行状态,已被广泛应用于旋转机械的故障诊断中[1]。为了更加准确且全面地获取机械故障状态信息,往往需要对多通道的振动信号提取时域、频域和时频域的特征信息[2],这一过程不可避免地导致了信息冗余与“维数灾难”等问题的出现,影响了故障辨识精度和效率。因此,可将高维故障特征集“去粗存精”的降维过程成为影响旋转机械故障诊断的关键。
近年来许多降维方法已被成功应用于机械故障诊断中。线性判别分析(linear discriminant analysis, LDA)[3]就是其中之一。该算法基本思想是通过最大化样本类间散度与类内散度的比值,找到最佳鉴别空间,以达到抽取分类信息和压缩特征空间维数的效果,在故障辨识中具有一定的优势[4],因此基于LDA的故障诊断方法也相继被提出。如:文献[5]将LDA用于原始数据的预处理阶段,剔除冗余信息,为后续的故障分类识别提供了便利;文献[6]针对LDA忽视样本局部结构问题,提出了一种将LDA与局部保持投影(locality preserving projections,LPP)[7]相融合的局部边缘判别投影(locality margin discriminant projection,LMDP)故障数据集降维方法,使故障分类效果有一定的提升。但文献[8]指出真实的高维非线性数据,尤其是故障类别不同的数据往往内嵌于不同的流形上,而未对该问题进行有效考虑,导致故障识别精度下降。文献[9]针对上述单一流形方法的不足,提出了一种多流形内蕴结构模型,并将其用于人脸识别,取得了良好的效果,但该模型的训练依赖大量标签样本,而现实中大量标签样本获取存在困难。
因此,针对多流形内蕴模型依赖于大量标签样本训练的问题,本研究拟将其进行改进;并将改进后的内蕴模型与样本局部结构信息嵌入LDA目标函数中,提升其挖掘敏感特征的能力。欲为旋转机械故障的智能诊断提供理论参考依据。
1 相关原理简介
1.1 LDA算法简介
LDA算法基本思想是:通过最大化样本类间散度与类内散度的比值,进而找到最佳鉴别空间,以达到抽取分类信息和压缩特征空间维数的效果。设高维特征集X=[x1,x2,…,xn]∈Rm×n,它由k个类别{X1,X2,…,Xk}组成,每类有c个样本。根据文献[10],LDA算法的类间散度Sb、类内散度Sw可分别表示为
(1)
(2)
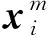
LDA算法的目标函数J为
(3)
式中,g为待求解的降维投影矩阵。
1.2 多流形内蕴模型简介
多流形内蕴模型的基本思想是:既然数据不是散乱分布于高维空间,而是聚集在几个低维流形附近,那么这些数据应该具有某些共性成分使它们能够聚合,又有某些差异使它们能相互区分。该模型将通过n个样本点张成一个不损失原始拓扑结构特征的子空间Ω,可表示为
Ω=span{x1-μ,x2-μ,…,xn-μ}
(4)
式中,μ为所有样本的均值。
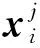
xi=pxi+(I-p)xi
(5)
(6)
(7)
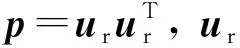
LDA算法框架利于故障分类,却忽略样本多流形与局部结构信息;内蕴模型虽然充分考虑多流形信息却受限于标签样本的数量。因此,若能将内蕴模型进行改进并将其与样本局部结构信息嵌入LDA算法框架中,将能达到高维故障特征集“去粗存精”的效果。
2 建立的强化内蕴局部保持判别分析算法
2.1 构建的强化内蕴模型
多流形内蕴模型的准确建立依赖于大量标签样本的训练,若标签样本较少则存在学习能力不强的问题。对此,本研究拟对多流形内蕴模型进行强化处理,以提高该模型的学习能力。
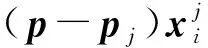
2.2 建立的目标函数
LDA算法在建立式(1)、式(2)的类间、类内散度矩阵时忽略了样本数据的多流形结构信息与局部结构信息,导致故障分类困难。针对此问题本研究欲将强化后的多流形内蕴模型与样本局部相似度函数融入LDA散度矩阵中,进而保留更多利于分类的判别信息以提升故障辨识精度。
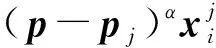
(8)
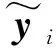
(9)
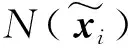
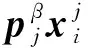
(10)
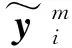
Wm为第m类样本内蕴非共性成分的相似度矩阵,其元素为
(11)
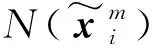
为使算法更利于故障分类,本研究依据最大化广义瑞利商思想构建目标函数如式(12)所示
(12)
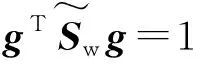
(13)
利用拉格朗日乘子法,式(13)可等价为
(14)
令∂L/∂g=0,式(14)可转化为式(15)的广义特征值求解问题
(15)
将特征值从大到小排序,取前d个特征值对应的特征向量组成投影矩阵G=[g1,g2,…,gd]。
2.3 强化内蕴局部保持判别分析算法步骤
融合多流形强化内蕴模型与局部相似度矩阵的强化内蕴局部保持判别分析(strengthened intrinsic local preserving discriminant analysis, SILPDA)算法具体实现步骤如下:
当下的学生习惯了移动终端的使用,偏爱碎片化阅读。教师可抓住这一契机,让学生的手机发挥正面作用,为己所用。针对易造成课堂进度差异的难点问题,可事先准备好微视频,课后发布在班级群或教学平台上,供课上没完全弄懂的学生消化吸收。这里的微视频在有条件有能力的情况下最好自己设计录制,可与自身的课堂教学完全同步,条件有限时也可将网上过长的讲解视频剪辑成几小段,将对应片段分享给学生。第二次上课时进行微视频难点的抽测,督促第三层次的学生课后通过微视频及时弄懂难点的同时,也起到再次回顾难点的作用。
输入原始特征数据集X,类间、类内近邻个数k1,k2,强化内蕴共性、非共性指数α,β,目标维数d;
输出投影矩阵G,低维特征集Y。
步骤1根据式(7)计算同类内蕴共性矩阵p-pi、同类非共性矩阵pi,并依据具体试验数据确定最优的强化指数α,β与目标维数d;
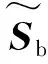
步骤3根据式(15)对目标函数进行广义特征值分解,取前d个最大的特征值对应的特征向量组成投影矩阵G;
步骤4由Y=GTX计算样本在低维空间中的投影。
3 基于SILPDA算法的转子故障诊断流程
将本研究提出的SILPDA降维算法用于旋转机械的故障诊断,具体的诊断流程如图1所示。
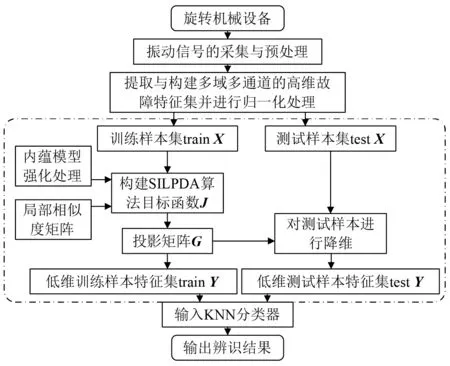
图1 故障诊断流程图Fig.1 Procedure of fault diagnosis
具体的故障诊断实施步骤如下:
步骤2将X归一化处理后,按比例划分训练集trainX与测试集testX;
步骤3设定SILPDA算法参数,如类间、类内近邻个数k1,k2、内蕴强化指数α,β及目标维数d,构建目标函数,将trainX输入算法进行训练得到投影矩阵G;
步骤4根据Y=GTX对trainX和testX分别进行映射,得到低维特征集trainY与testY;
步骤5将投影后的trainY与testY输入K近邻分类器进行故障分类,并输出辨识结果。
4 试验说明
4.1 转子试验平台
为验证SILPDA算法的有效性与可行性,本研究拟采用如图2所示的转子综合故障模拟平台进行分析。本试验用电涡流传感器共采集6个通道的振动信号,包括两个轴承座处的径向(Y)振动信号、两个质量盘处的径向(Y,X)振动信号。在采样频率为10 kHz,转速为3 000 r/min的状态下,分别模拟转子不对中、气流扰动、质量不平衡、动静碰磨、轴承座松动、正常6种不同状态。将每种状态进行采样并划分为100组样本,按照60∶40构建训练与测试数据集,再对每个通道的振动信号提取如表1所示的38个特征参数,总共得到38×6=228个特征。

图2 转子试验台Fig.2 Rotor test bench
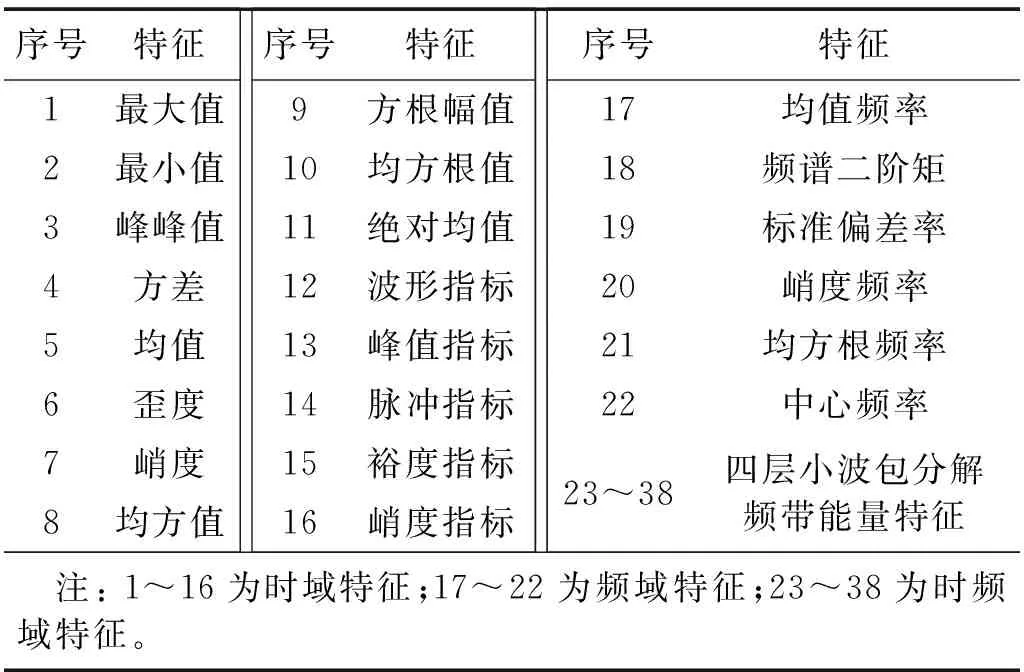
表1 特征参数Tab.1 Characteristic parameters
4.2 参数设定
本研究中需要设定的参数有:约简的目标维数d;SILPDA算法式(8)中的近邻数k1、强化指数α;式(10)中的近邻数k2、强化指数β。通常将目标维数d设定为故障的类别数减一,即d=6-1=5。近邻数k1,k2的取值范围分别为1≤k1≤6,6≤k2≤60[12],经反复试验,本研究将k1,k2分别取为3和10。强化指数α与β的设定,需要验证不同取值对故障识别率的影响,初步拟定1≤α,β≤10,并且将取值间隔设为1。识别率η随参数α与β的变化情况,如图3所示。观察图3可知,故障识别率η先快速增大后逐渐趋于稳定。另外,当α=1,β=1时,模型退化为原始内蕴模型,其准确率仅为0.44;为提升降维效果的同时保证识别准确率,选取参数为α=2与β=1。
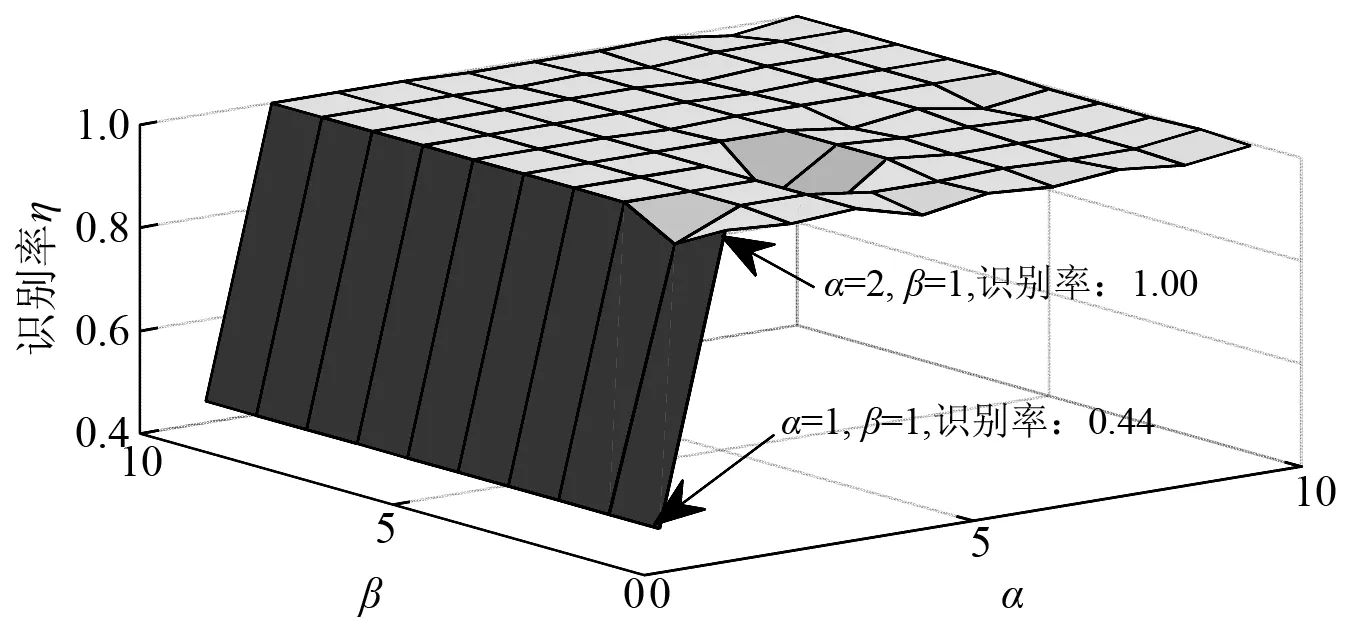
图3 参数α与β对识别准确率的影响Fig.3 Parameter α and β impact on recognition accuracy
4.3 可分性指标
为评价低维测试集各个故障类别间的可分性,根据文献[13]引入δ=Sb/Sw评价指标来量化降维效果
(16)
(17)
(18)
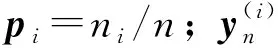
5 试验结果与分析
5.1 降维效果分析
为验证SILPDA算法的降维效果,本研究选择LPP,LDA,LMDP等算法进行对比分析。分别对降维后的测试数据集选取前3个主元进行可视化表示,如图4所示;同时本研究依据4.3节计算了各算法的降维可分性指标,结果如表2所示;最后为进一步研究各降维算法对故障辨识精度的影响,本节将各算法降维后的敏感特征子集输入K近邻分类器中进行故障分类辨识,辨识结果如表3所示。
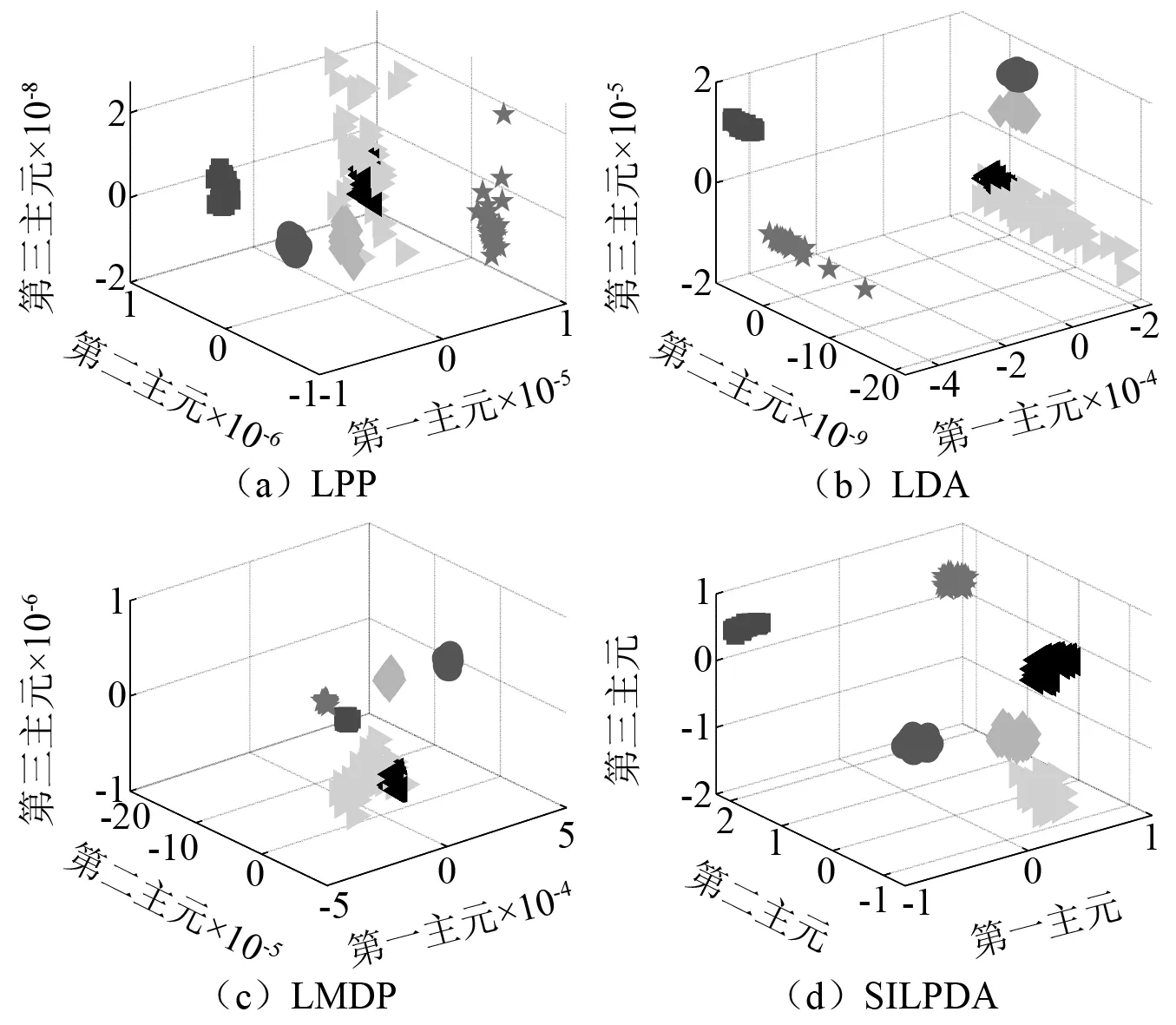
注:“◇”、“○”、“☆”、“◁”、“▷”、“□”分别代表不对中、不平衡、碰磨、气流扰动、松动、正常。图4 三维可视化Fig.4 3D visualization

表2 可分性指标Tab.2 Separability index
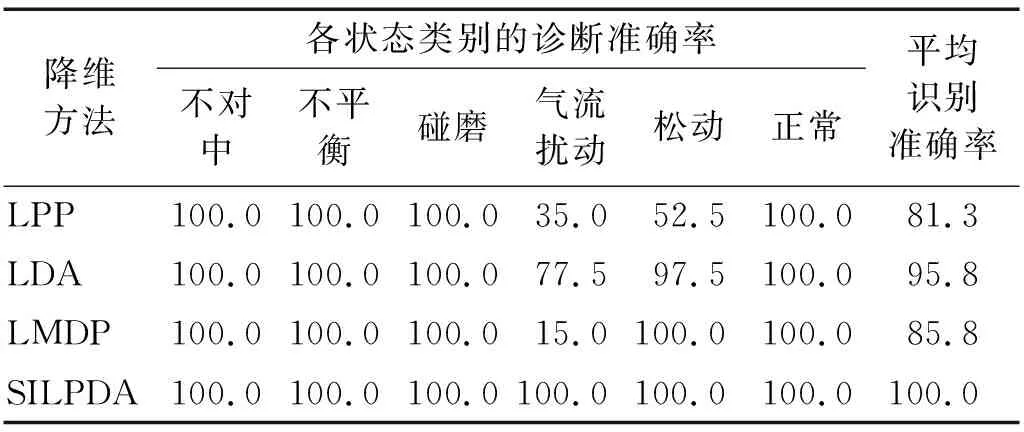
表3 不同状态识别率Tab.3 Recognition rate of different states 单位:%
观察图4,并结合表2、表3综合分析可知,LPP算法降维效果较差,同类故障样本较为分散,不同故障的样本可分性较弱,其中气流扰动样本与轴承座松动样本产生了严重的混叠现象,导致故障识别准确率在4个算法中最低,为81.3%。原因在于该算法属于无监督算法,未能有效考虑类别判别信息;LDA算法与LMDP算法的降维效果优于LPP算法,因为二者基于最大化瑞利商值构建目标函数,在故障的分类任务中有一定优势,且LMDP算法考虑了样本间相似度度量,使同类间样本聚集效果好于LDA算法,但二者也出现了不同程度的异类样本混叠现象,原因在于忽略了不同故障分布于不同流形上的本质问题;相较于上述算法,SILPDA算法的故障样本可分性最好,同类样本聚集成团,不同故障分类清晰,没有出现异类样本的混叠现象,此外该算法的识别准确率与可分性指标也最高。这得益于在构建目标函数时充分考虑了样本局部几何结构与多流形结构的多种判别信息,挖掘出具有强判别能力的敏感特征子集,使不同故障之间的边界更加清晰明了,有效降低了故障的分类难度。
5.2 不同训练比例试验
为验证所建立SILPDA算法的稳定性,本研究将训练样本与测试样本的数量分别按照10/90,20/80,30/70,40/60,50/50,60/40,70/30,80/20,90/10进行划分。将提取后的低维特征子集放入K近邻分类器中进行分类识别,各算法准确率如图5所示。观察图5可知:随着训练样本比例的上升,各算法的识别准确率呈上升趋势;LPP算法与LDA算法先后出现了较大的波动;LMDP算法虽然表现得较为稳定但在训练样本较少时,准确率下降明显;相较于上述3种算法,SILPDA在保证较高准确率的同时,算法的波动也最小,整体表现出良好的稳定性。
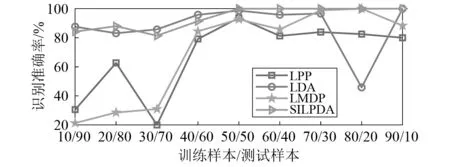
图5 不同比例对应的识别准确率Fig.5 Recognition accuracy corresponding to different proportions
5.3 速度波动试验
因旋转机械在真实工况中转速存在一定的波动,故通过速度波动试验验证本研究建立的SILPDA算法在速度波动条件下对故障辨识准确率的影响。本研究在3种转速(2 600 r/min,2 800 r/min和3 000 r/min)下的每种故障中选取20组数据(共60组),混合后作为训练样本,另取各转速下每类故障中不重复的 20 组数据(共60组),混合后作为测试样本,以模拟真实工况条件下的速度波动情况,并将各算法降维后的特征子集放入K近邻分类器中进行故障辨识结果,如表4所示。分析表4可知,LPP算法准确率最低,LDA算法与LMDP算法准确率相近且高于LPP算法,本研究提出的SILPDA算法故障识别准确率最高。说明了本算法对存在速度波动的工况适应能力更强。

表4 速度波动情况下识别准确率Tab.4 Recognition accuracy under speed fluctuation 单位:%
5.4 算法泛化性试验
为验证本研究提出的SILPDA算法的有效性与通用性,选取赵孝礼等研究中的一套双跨转子试验台作为本节的研究对象,如图6所示。该试验台选用12个电涡流传感器测取转子6个关键界面的径向(X,Y)振动信号。在采样频率为5 kHz,转速为3 000 r/min的状态下,分别模拟质量不平衡、转子不对中、轴承座松动、动静碰磨、正常5种不同状态。采样每种状态的100组样本,按照60∶40构建训练与测试数据集,再对每个通道的振动信号样本按表1提取38个特征参数,总共得到38×12=456个特征参数。

图6 双跨转子试验台Fig.6 Double span rotor test bench
算法目标函数中参数的设定需要根据具体的试验数据确立。按照4.2节的参数设定说明,将本试验参数设定为:近邻参数k1=3,k2=10;内蕴强化指数α=5,β=2;目标维数d=4。
同样选择LPP,LDA,LMDP 3个算法作为对比。将提取的原始高维特征集通过各算法进行降维,并将降维后的低维特征集选取前3个主元进行可视化绘制,结果如图7所示。此外,为使降维效果描述得更加客观与准确,本研究根据4.3节计算了各算法的降维可分性指标,如表5所示。且将各算法降维后的敏感特征子集输入K近邻分类器中进行故障辨识,结果如表6所示。
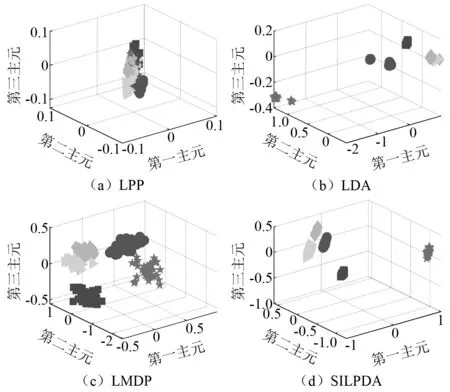
注:“◇”、“○”、“☆”、 “▷”、“□”分别代表不对中、不平衡、碰磨、松动、正常。图7 不同算法的降维效果Fig.7 Dimensionality reduction effects of different algorithms

表5 可分性指标Tab.5 Separability index
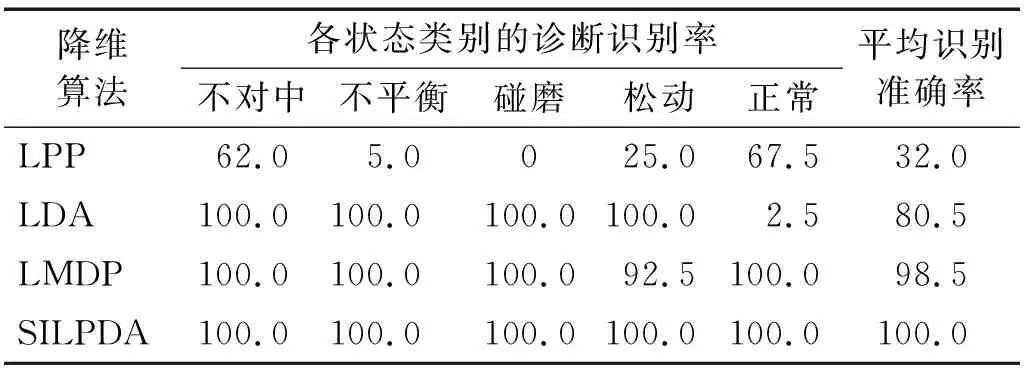
表6 不同故障识别率Tab.6 Different fault identification rates 单位:%
观察图7并结合表5、表6综合分析可知,经本研究提出的SILPDA算法降维后的低维特征子集,可视化效果良好,没有出现LPP,LDA,LMDP等算法中的样本混叠现象,且分类指标优异,使同类样本聚集较好而异类样本实现了完全分离。进一步说明了本研究的SILPDA算法具有良好的降维能力与通用性。
6 结 论
为解决故障特征集维数过高导致故障分类效果不佳的现状,提出了一种强化内蕴局部保持判别分析的故障特征集降维方法。在传统LDA的基础上融合强化的多流形内蕴判别信息,并引入样本局部几何信息,使约简后的低维特征包含更多的分类信息,进而提升故障辨识精度。最后由转子试验平台的故障特征数据集对该算法进行了验证。结果表明,该算法相较于LPP,LDA,LMDP等算法不但在降维方面具有一定的优势,而且也更为稳定可靠,有效提高了故障的辨识精度,可为旋转机械智能故障诊断提供理论参考依据。
猜你喜欢
车主之友(2022年4期)2022-08-27
数学物理学报(2020年2期)2020-06-02
海峡姐妹(2019年12期)2020-01-14
数学年刊A辑(中文版)(2019年3期)2019-10-08
红楼梦学刊(2019年2期)2019-04-12
数学物理学报(2019年1期)2019-03-21
传媒评论(2017年12期)2017-03-01
华人时刊(2016年16期)2016-04-05
火控雷达技术(2016年1期)2016-02-06
振动工程学报(2015年2期)2015-03-01
