
基于网络流量的私有协议逆向技术综述
2023-01-30 10:23:54李峻辰杨刚芹
计算机研究与发展 2023年1期
李峻辰 程 光 杨刚芹
(东南大学网络空间安全学院 南京 211189)
(计算机网络和信息集成教育部重点实验室(东南大学) 南京 211189)
(网络空间国际治理研究基地(东南大学) 南京 211189)
(紫金山实验室 南京 211102)(jcli@njnet.edu.cn)
网络协议定义了2个或多个通信实体间交互报文的格式、顺序、内容以及在接收或发送这些报文时应进行的状态转换,规定了通信实体间的行为规范,保证了在极其复杂的网络环境下通信实体仍然可以进行预期准确的数据传输.随着网络应用逐步向各个领域渗透,在生产生活、工业控制、金融服务等行业的新型网络中,大量满足需求的APP应时而生.中国互联网络信息中心发布的《第48次中国互联网发展状况统计报告》[1]指出,截至2021年6月,我国市场上检测到的APP数量已达到302万款,其中游戏、日常工具、电子商务和社交通信类APP数量占比超过半数,同时物联网终端应用也在不断增长.这些APP交互所使用的通信协议,相较于RFC规定的HTTP,TLS,SMTP等公开协议来说即为私有协议,其并未公开协议格式、协议语法或协议交互实例,仅在应用内部通信、传输数据时使用,亦可称之为未知协议.应用种类的层出不穷直接造成网络私有协议的多样性,且其特殊性质使得其在工业控制、军事通信、虚拟网络和恶意软件中得到广泛应用,同时私有协议规范的未知性也给当前网络安全监管带来了极大的挑战.因此,针对私有协议的分析对保障整个网络生态环境的稳定具有重大意义.
目前对私有协议分析的主要手段是协议逆向技术,由于协议规范未知,只能结合逆向思维,基于协议交互产生的实例来逆向推断协议的运作行为以及格式规范,协助分析人员理解私有协议的功能、性能以及安全性.协议逆向技术根据其分析对象的不同主要有2种实现方法[2-3]:一是基于实现协议规范的应用程序指令来完成协议逆向分析;二是基于协议通信所产生的网络流量来完成协议逆向分析.
部分研究基于实现协议规范的应用程序指令对私有协议进行逆向分析[4-12],但该方法需要的条件较为严苛,其逆向分析的实体是应用程序.需要对采用该协议通信的应用程序进行监控,访问其运行环境,实时记录下程序运行产生的各种指令,分析指令解析报文的过程与指令间包含的协议状态转换信息等以获得协议格式的规范.一般情况下,实现私有协议的应用程序源码不易获取,也难以提供合适的环境来捕获其运行产生的指令,因此基于实现协议规范的应用程序指令的协议逆向技术不是普遍适用的.相较而言,基于协议通信产生的网络流量的私有协议逆向技术需要的条件较为简单,其逆向分析的实体是网络流量.网络流量获取手段众多且可执行性较强,如今的wireshark,tcpdump等工具均可在终端网卡或主干网路由器处截获网络流量,其大致可以分为2种:一种是已知某种应用产生的私有协议流量,可在终端主机运行应用以获取充足的流量,用于分析该应用的私有协议规范,理解协议交互行为.另一种是未知应用产生的未知流量,即全未知流量,可在主干网路由器截获,其复杂的混淆性导致无法简单地分析,但很可能包含暗网、恶意软件、恶意攻击等私有协议流量,对这部分私有协议的分析具有极高的实用性,加强网络监管人员对这部分公害信息的监管能力.
一方面,中国信息通信研究院发布的《2020年上半年工业互联网安全态势综述》[13]指出,工业互联网设备漏洞数量多、级别高,针对工业互联网的攻击方式以异常流量、僵尸网络为主,同时车联网成为网络攻击的新趋向.因此针对工业互联网设备的私有协议逆向分析必不可少,可以降低协议设计的脆弱性,发现协议漏洞,提高设备安全性.同时针对攻击的异常流量逆向分析亦具有意义,挖掘出异常流量的固有特征,更适用于对攻击流量的防御.另一方面,虽然目前协议设计与发展越来越注重用户隐私,协议加密化趋势凸显,但加密协议存在握手、密钥交换、身份认证等明文传输阶段,且协议报文中存在明文字段标识协议类型,不同协议的明文数据量并不相同[14],因此基于网络流量的私有协议逆向技术亦可挖掘出加密协议明文字段的报文格式,且这部分明文字段格式可作为私有加密协议的固有特征,用于精准识别私有加密协议流量.近些年来基于网络流量的私有协议逆向技术取得高速发展[15],从初期的人为分析到目前的自动化分析,从初期的协议规范推断到目前的协议行为理解,均有突破性的研究成果并应用于众多领域:僵尸网络通信推断与行为理解[16]、网络蜜罐协议检测和状态机模型分析[17-18]、协议漏洞挖掘以及脆弱性检测[19-20]、安卓应用协议行为分析[21]、无线自定协议理解与重构[22-23]、无人机等工控协议建模[24-26]、物联网设备安全性分析[27-28]等等.因此本文旨在对基于网络流量的私有协议逆向技术已有研究进行详细分类论述,为进一步的研究奠定基础.
1 基于网络流量的私有协议逆向技术
网络通信发送方遵守5层协议体系结构由上到下逐层封装需要传输的数据,接收方则由下到上逐层解封,得到对方发送的数据报文.每一层均由协议来规定封装与解封数据的相应规则,因此每层数据报文均为协议通信产生的实例.由于5层协议体系结构中物理层、数据链路层、网络层、传输层属于互联网基础设施建设,其遵循的协议由一套完整的RFC规定来保证全世界的互通,所以私有协议逆向技术主要面向应用层协议,基于网络流量的私有协议逆向技术所使用的实例即为协议数据单元(protocol data unit, PDU).协议逆向技术的目标是根据某协议的PDU集合推断得到协议规范,本文提出包含预推理、协议格式推断、语义分析、协议状态机推理4个步骤的基于网络流量的私有协议逆向技术框架,如图1所示.同时从研究方法的本质出发对上述4个步骤的相关工作进行梳理、分类,组织结构如图2所示.
常规而言,由于网络传输的复杂环境,使用采集工具获取到的数据均是混杂的、不完全纯净的,这就使得基于网络流量的分析均需要对直接获取的流量进行预处理:分流、去重传、会话重组等,从混杂的流量中获取目标协议的网络流量.因此,基于网络流量的私有协议逆向技术输入的是一批经过预处理的单一某协议流量.
近些年来隐私保护、安全需求受到大众的关注,TLS/SSL,SSH,QUIC等加密协议相继出现并广泛应用于各种通信领域,导致互联网上的加密流量激增[29].由于加密算法的特性,报文序列被加密为无规律的高熵序列,具有较高的离散程度,导致其无法直接分析.但加密协议报文中存在的未加密字段依然可以挖掘一些规律,因此基于网络流量的私有协议逆向技术面向的是未加密或非全加密协议的网络流量.
网络协议保证通信双方传输数据的准确性,因此一个协议的制定包含许多约束与规则,如连接的建立、传输参数的设置、数据交换等,不同约束与规则对应不同的报文格式与协议状态,即若要得到准确的协议格式与交互模型,就需要更加完整、更加全面的协议流量.因此,基于网络流量的私有协议逆向技术要求网络流量包含协议交互的各种报文格式,要有更加完整的交互.
综上所述,基于网络流量的私有协议逆向技术的分析对象具有3个特点:1)单一某协议的经过预处理的网络流量;2)未加密或非全加密协议的网络流量;3)包含全面协议交互的各种报文、行为的网络流量.
2 预推理
预推理是私有协议逆向技术必不可少的前置步骤,其立足于协议流量分析协议的固有属性,为协议逆向的后续分析提供基础知识.预推理的主要任务是:1)协议类型判断;2)协议报文聚类;3)协议报文分段.
协议类型由协议流量报文构成决定,5层协议体系结构的各层PDU构成有3种形式:1)二进制形式,即协议报文由连续比特构成,且固定长度比特组合的值即为该固定位置上的取值,具有一定语义,例如TCP,SMB协议等;2)文本形式,即协议报文由连续可读的ASCII码构成,特殊字符串具有特殊的语义,例如HTTP,SMTP协议等;3)混合形式,即协议报文使用可读ASCII码标识协议中的具有语义的字段,使用连续比特标识该协议关键词的取值,例如直播应用常使用的应用层协议HTTP-FLV、微信文件传输协议等.因此,基于报文构成协议也可以分为3种类型:1)二进制类协议;2)文本类协议;3)混合型协议.
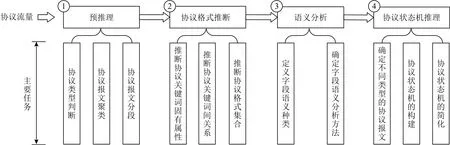
Fig.1 Architecture of private protocol reverse engineering based on network traffic图1 基于网络流量的私有协议逆向技术框架
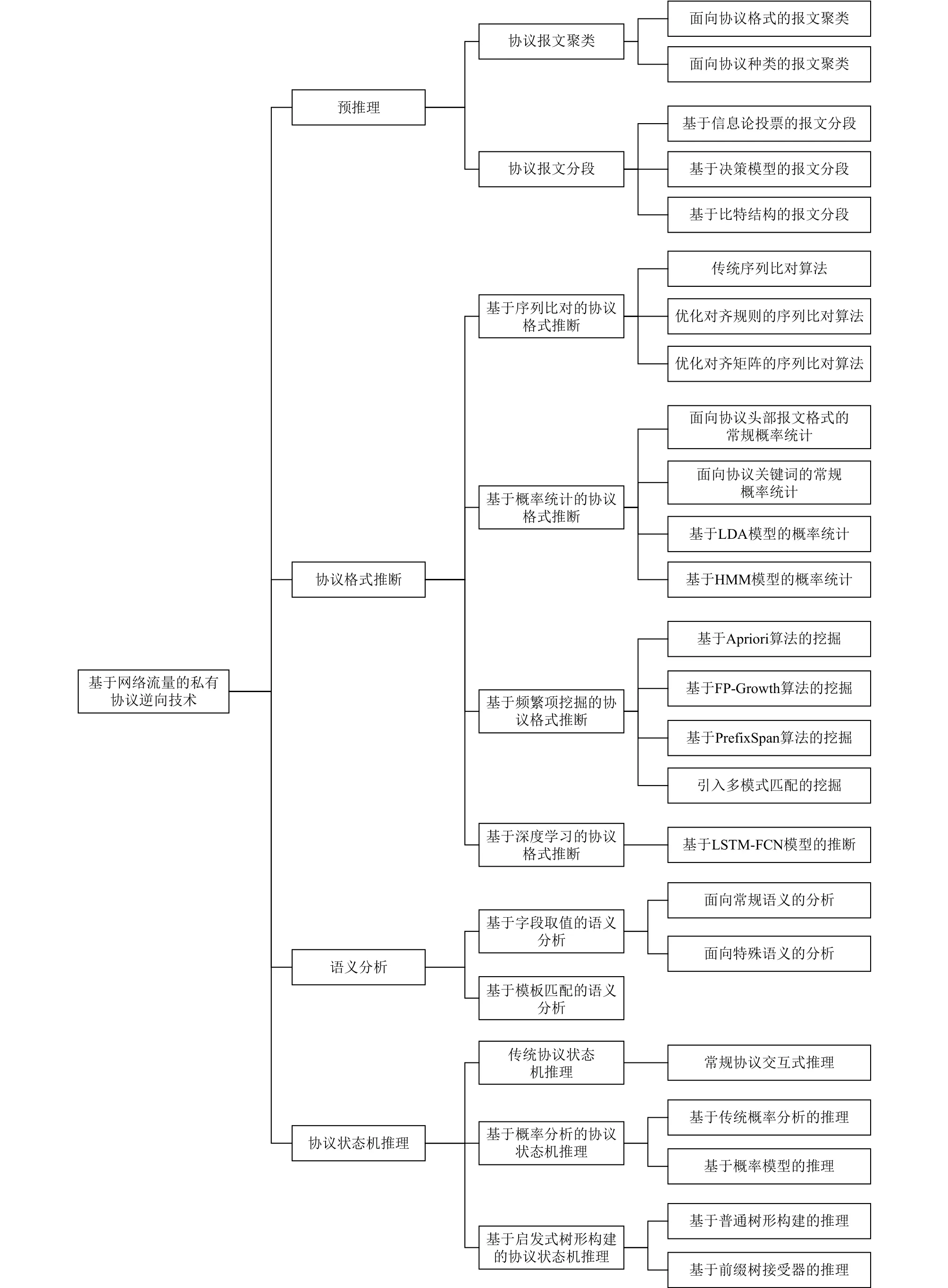
Fig.2 Classification structure of private protocol reverse engineering based on network traffic图2 现有基于网络流量的私有协议逆向技术分类结构
由于报文构成的特殊性,协议逆向技术在初期就需要明确被分析协议的类型,针对性地使用不同的方法,因此协议类型的判断为后续的分析方法奠定了基调.目前学术界仅通过报文的构成字节是否是可读ASCII码来自动化判断或在协议类型已知的先验知识下开展协议逆向技术的研究,因此本文仅对协议报文聚类与协议报文分段2方面的现有研究进行详细介绍.
2.1 协议报文聚类
高吞吐量的互联网主干流量具有极其复杂的混淆性,多种应用层协议报文混杂在一段流量中,且每种协议又包含多种协议格式.但一般情况下,所属同一协议的报文具有相同的类型且格式上具有一定的相似性,因此可以衡量协议报文间的相似度,实现协议报文的相似性聚类.具体协议报文聚类方法可以分为2类:一类面向协议格式,另一类则面向协议种类.由此对应产生不同的聚类簇:1)不同协议格式的聚类簇,用来推断协议格式,直接保证格式推断的准确性;2)不同协议种类的聚类簇,用来对未知协议混杂流量进行初分类,使每个聚类簇内包含的报文尽量同属一种协议,保证协议逆向技术输入的协议种类单一性.
协议报文聚类不但需要采用合适的方法度量协议报文之间的相似度,还需要相应的聚类算法或直接推断协议报文的标识性字段,将标记为同类的报文划分为一个类簇.大多协议逆向技术均采用常规的聚类算法进行聚类,如最近邻聚类算法[30]、非加权组平均法[31](unweighted pair-group method with arithmetic means, UPGMA)、围绕中心划分(partitioning around medoids, PAM)算法[32]、DBSCAN(density-based spatial clustering of applications with noise)算法[33]、近邻传播(affinity propagation, AP)算法[34]等.
结合常规聚类算法,研究人员重点关注采用不同方式度量协议报文间的相似度来实现面向协议格式的报文聚类.Shevertalov等人[35]在提出的协议状态机推理方法PEXT中使用最长公共子序列(longest common sub-sequence, LCSS)长度标准化度量协议报文间的相似度并采用凝聚层次聚类算法进行聚类.之后,Ji等人[25]将文献[35]所提方法应用到无人机无线控制协议逆向分析中.Bossert等人[36]提出基于语义信息的协议报文聚类算法.在收集到协议会话相关语义信息的基础上,采用3层聚类方法:首先结合报文时间戳与流向,以语义信息作为先验知识将协议会话划分为不同动作的报文类簇;之后将具有相同上下文语义信息的协议报文再聚类,并为每个协议报文生成一个上下文签名标记序列;最后采用扩展的序列比对算法计算报文间的语义相似度,生成相似度矩阵,并对UPGMA进行同样的优化使其考虑语义信息以完成对不同格式协议报文的最终聚类.Luo等人[37]对前人提出的协议关键词提取方法进行改进,在此基础上提出一种报文类型感知的协议报文聚类方法.该方法首先在N-gram分段的基础上采用TFIDF(term frequency-inverse document frequency)算法过滤不重要的候选协议字段,接着采用候选协议字段的概率分布信息来描述协议报文的类型分布,最后基于上述分布计算协议报文间的相似度矩阵,并采用UPGMA对协议报文进行聚类.Li等人[38]把模糊理论引入协议报文聚类,提出一种基于粗糙集理论的协议报文聚类方法.该方法使用ProWord方法[39]产生的连续多个分段点位置作为粗糙集中的属性集,之后基于粗糙集理论以及属性集和协议格式间的映射关系对不同格式的协议报文进行聚类,即使用分段位置衡量协议报文间的相似度,直接对协议报文集合聚类划分.
部分研究人员针对不同协议种类的报文进行研究,以合适的粒度度量未知协议报文间相似度,实现面向协议种类的报文聚类,应用于多种类协议混杂的 情 况.Sun等 人[40]引 入 ABNF(augmented Backus-Naur form)规则来计算候选协议字段间距离(token format distance, TFD),将协议报文以字节为单位划分为候选协议字段,并根据ABNF为每个候选协议字段定义一组属性,结合Jaccard指数来计算TFD.之后在TFD的基础上结合编辑距离对序列比对算法进行改进:基于报文头部前20个字节来计算协议报文间 距 离(message format distance, MFD ).最 后 基 于MFD相似度矩阵,采用DBSCAN算法对混杂协议流量进行聚类,使用轮廓系数与邓恩指数协助聚类过程中的参数选择,生成不同种类的协议报文聚类簇.
2.2 协议报文分段
网络中传输的报文是一组长度不定的连续比特,其经由各层协议逐层解析,理解比特组合含义,这就要求协议规范中必须明确规定字段分段点,将任意相邻分段点间的比特组合理解为协议规定的值.由此协议报文分段就是确定报文序列分段点的过程,其与自然语言处理里的分词(tokenization)具有相似的目标.因此自然语言处理的传统分词方法同样被引入了协议报文分段中,主要包括:N-gram分词算法与基于分隔符的分词.
除此之外,研究人员也在积极探索协议报文结构,考究协议关键词的特点,提出创新性协议报文分段方法,主要可以分为3类:基于信息论投票的报文分段、基于决策模型的报文分段与基于比特结构的报文分段.
由于协议报文的分段点是确定的,具有较低的随机性,因此部分研究将信息熵理论引入协议报文分段算法,以实现报文分段点的提取.Zhang等人[39]在提出的协议关键词提取方法ProWord中将无监督专家投票算法应用于流量分析.该方法以字节为单位,引入词内熵与词边界熵的概念作为专家值,结合专家投票算法对滑动窗口中报文序列的每个位置进行投票,最后选择投票值序列的极大值点与超过设定阈值的位置点作为协议报文的分段点.基于同样的思想,Sun等人[41]引入统计信息,亦从信息论的角度提出协议报文分段算法ProSeg.该算法以字节为单位计算单字节信息熵与相邻2个字节间的互信息,结合协议关键词的字节信息熵规律,采用专家投票算法以信息熵和互信息为专家值确定协议报文的分段点.Jiang等人[42]提出一种基于邻域信息的协议报文分段点提取算法ABInfer,提出新颖的实体距离(entry distance)来度量相邻2个字节间距离,其本质是计算单字节位字符集合的熵值,之后采用最近邻聚类算法迭代将相邻字节进行聚类合并,最终推断得到协议字段边界.
协议报文分段点的确定过程可以理解为在报文字节序列中字段边界的决策问题,因此部分研究考虑到学术界方法的积累,将一些常用模型引入协议报文分段中,以实现报文分段点的提取.黎敏等人[43]将 隐 半 马 尔 可 夫 模 型(hidden semi-Markov models,HsMM)[44]引入协议逆向分析,提出抗噪二进制协议报文最佳分段方法.该方法使用HsMM模型对协议报文进行建模,将候选协议字段作为与隐状态相关的观察状态,将字段长度作为隐状态的持续时间,因此协议报文的分段问题就转化为求解HsMM模型最大似然概率的隐状态序列问题.之后采用Baum-Welch方法对参数进行迭代估计以完善HsMM模型,并采用Viterbi算法推断得到有最大似然概率估计的隐状态序列与具有最佳隐状态持续时间的各候选协议字段长度,从而获得最佳协议报文分段点.Tao等人[45]将贝叶斯决策模型引入协议逆向分析,提出针对二进制协议的报文分段方法PRE-Bin.在采用轮廓系数指导的K-means聚类基础上结合UPGMA算法获得最优数量的协议报文聚类簇,在类簇内采用基于比特的优化序列比对算法,重新设计匹配过程与回溯规则,得到包含表示字段边界特征的空格的匹配序列.最后根据局部性原理与最大后验概率提出2个准则,并基于贝叶斯决策完成空格是否是最合适协议报文分段点的估计.Luo等人[46-47]将报文分段问题考虑为时间序列的突变点检测问题,突变点标识时间序列中一段时间的凸起与报文分段点标识字节序列的结束具有一定的相似性.该方法将协议报文序列假设为q阶马尔可夫过程以计算前缀条件概率与报文倒置后的后缀条件概率,结合协议报文分段点未知的特性,使用极大极小形式表示突变点检测问题.之后提出多累积和算法(multi-CUSUM)实现协议报文分段点检测.
协议报文由比特序列构成,比特间关系反映报文的结构信息,因此部分研究以比特为粒度,挖掘比特间的表征关系,以实现报文分段点的提取.Kleber等人[48]重点关注协议报文的内部结构,提出一种新颖的报文分段方法NEMESYS.该方法定义字节间的位一致性 (bit congruence, BC),即相邻 2 个字节间同位取值相同的个数与字节长度的比值,因此遍历报文序列任意相邻字节均可计算BC并生成位一致性值序列.在此序列基础上,任意2个连续值可得到位一致性差值,由此可将报文序列基于BC转换为位一致性差值向量,该向量仅由报文字节组成决定,文中称之为报文的内部结构特征.之后采用标准高斯滤波器对位一致性差值向量进行平滑操作消除噪声,报文分段点则由平滑后差值向量的上升边缘拐点来决定.如果平滑差值向量在某一区间内存在多个上升边,则选择对应未平滑差值向量区间内较为陡峭的上升边缘作为报文分段点.同样,Marchetti等人[49]针对汽车控制区域网络(controller area network, CAN)中的汽车通信数据帧进行分析,提出一种基于位变化率的汽车通信数据帧分段方法READ.该方法在通过ID字段进行聚类的汽车通信数据帧聚类簇上,引入位翻转速率的概念,通过时序上相邻的2个报文计算任意位的累计翻转(bit-Flip)次数序列,之后对上述序列按位除以数据负载长度并取对数得到幅度序列.最后通过以下阶段筛选协议报文分段点:首先筛选幅度序列的极大值点作为初报文分段点;之后考虑计数器以及CRC字段的幅度序列与位翻转频率特征,扩充报文分段点.
综上所述,预推理的协议报文聚类与协议报文分段2方面研究分别面向协议格式推断与协议关键词提取.协议报文聚类尽最大可能将相似格式报文或相似类型协议报文聚到同一类簇内,以提高协议格式推断的准确度.协议报文分段尽最大可能选取最合适的报文分段点,将报文序列划分为更小的子序列,以减少冗余字段对协议关键词提取的影响.但协议报文分段中可以使用协议报文聚类簇计算熵值信息,协议报文聚类中亦可使用协议报文分段点来计算报文间的相似度,因此预处理这2方面研究内容相辅相成,共同为后期推断提供精确的信息.表1和表2分类概述了预推理部分相关研究的主要内容,包括面向协议类型、方法内核与对比分析等.表1、表2中忽略了常用的协议报文聚类算法与协议报文分段算法,重点对比分析创新性研究.可以看出,协议报文聚类重点关注报文间相似度度量,采用不同的相似度计算方法就会产生不同的结果.协议报文分段重点关注二进制协议报文的分段,因为二进制协议目前广泛使用,尤其是在恶意网络、军事网络、物联网络协议中,且二进制协议报文分段具有一定的挑战性,无法通过报文数据人为分段,因此二进制协议报文分段可以很大程度上提高协议逆向技术的自动化程度,具有较高的研究价值.
3 协议格式推断
协议格式推断是私有协议逆向技术的核心步骤,其在协议预推理的基础上实现协议逆向技术的阶段性目标:协议格式集合.
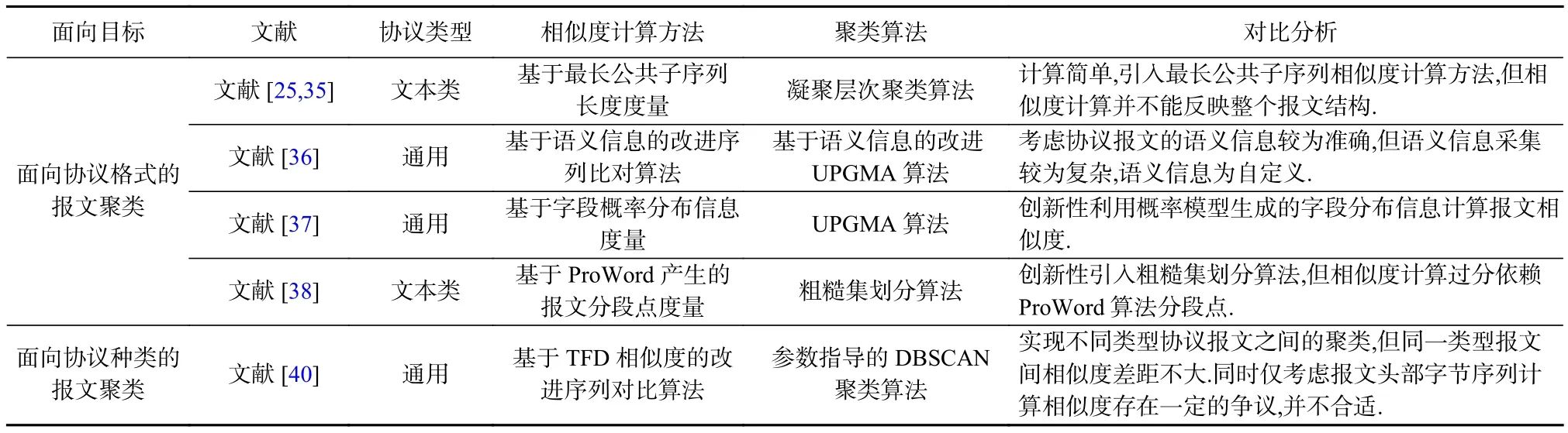
Table 1 Summary of Protocol Packets Clustering表1 协议报文聚类方法概述
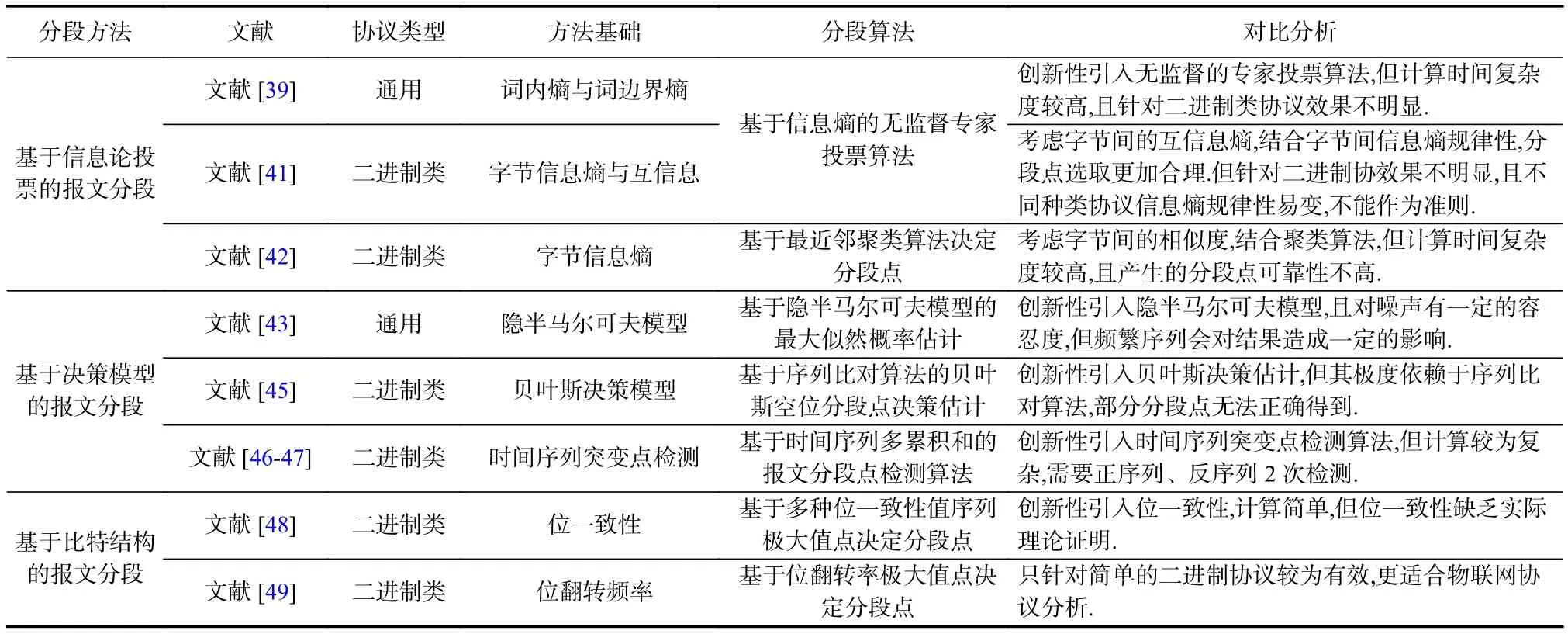
Table 2 Summary of Protocol Packets Segmentation表2 协议报文分段方法概述
对协议报文集合进行报文分段,从各候选协议字段中筛选得到协议关键词或直接采用序列比对方法将协议报文的公共对齐字段筛选为协议关键词,并描述协议关键词的属性.因此协议格式推断的第1个任务就是筛选协议关键词并推断其固有属性.在协议逆向技术中,协议关键词被定义为具有特殊语义且不可再分割的原子比特序列,每个协议关键词遵循协议规范定义的属性:位置、长度、数据类型等,数据类型可以用其值域来描述,可能是数值型、ASCII码或枚举列表(枚举列表是由协议规范预设的,即该协议关键词每次只能选择预设值中的一个出现在报文中).但由于协议报文的复杂性与报文分段的不准确性,导致协议关键词提取过程必然存在一定的冗余,尤其是文本类协议,存在大量无意义的字符串对协议关键词提取造成影响,因此如何准确删除这些冗余字段是本任务的研究重点.
协议报文由上述各个协议关键词构成,协议功能的复杂性要求协议报文具有一定的多样性,因此协议格式推断的第2个任务是推断协议关键词之间的关系,之后第3个任务便是通过实例报文将协议关键词间关系进行组合,得到复杂的协议格式.协议关键词根据其位置不同存在次序、并列、互斥与层级等结构关系.次序关系即部分协议关键词总是按顺序位置且同时出现在报文中;并列关系即部分协议关键词的位置不固定,其前后顺序并不影响协议处理的结果,此种关系多出现在文本类协议中;互斥关系即部分协议关键词在同一位置上不同时出现但总出现其中一个;层级关系即部分协议关键词可构成复合字段,该复合字段可作为具有特殊语义的高层协议关键词.多种复杂关系的组合构成了具有不同功能的协议报文,但协议关键词间的关系亦存在回路、重复等冗余,因此如何准确描述协议关键词间关系并将其合并为复杂关系组合,构成协议格式是本任务的研究重点.
为完成上述任务,研究人员开拓思路,实时跟进学术界最新理论,将序列比对、概率统计、频繁项挖掘以及深度学习引入协议格式推断中,因此协议格式推断可以相应划分为基于上述4种理论核心的推断方法.
3.1 基于序列比对的协议格式推断
序列比对是生物信息领域一个古老的课题,最早用来计算核酸序列之间的相似性,通过对齐每一位核酸确定序列间的差异量.由于构成报文的字节序列与核酸序列之间具有一定的相似性,因此序列比对算法被引入私有协议逆向分析中,其中最常用的2种序列比对算法为全局序列比对Needleman-Wunsch(NW)算法[50]和局部序列比对Smith-Waterman(SW)算法[51],均通过在合适的位置插入空格来将2个序列对齐到同样的长度,通过得分函数定义匹配、不匹配或插入空格的奖惩分数生成得分矩阵,并通过回溯得到2个序列的公共对齐序列,将序列相似度数字化以直观表示.NW算法保证找到序列间的全局最优对齐序列,而SW算法确定序列间的最长公共子序列,因此就要求采用NW算法的2个序列必须具有高度相似性,而SW算法允许将相似的一组序列聚在一起以供后续分析.NW算法更适合用来推断协议格式,而SW算法更适合用来计算报文相似度度量.
Beddoe[52]提出 PI(protocol informatics)方法,利用序列比对算法实现私有协议逆向分析.该方法首先采用SW算法根据上下文信息计算协议报文间的相似性矩阵,之后结合非加权组平均法UPGMA与NW算法将矩阵中相似度最高的2个报文进行序列对齐,并将对齐后的序列添加至相似性矩阵中并更新计算相似度,最终得到完整的协议公共报文序列,即协议格式.Gorbunov等人[53]在提出的AutoFuzz可扩展协议模糊测试框架中,同样采用NW算法将报文序列进行对齐,只不过其首先采用报文头部4个字节对协议报文进行聚类,在各个类簇内使用了NW算法得到公共报文序列,生成协议格式.之后Razo等人[54]将PI方法应用于Android应用流量上,成功识别5个固定不变的协议关键词与2个动态变化字段.而Ji等人[25]则将PI方法应用到无人机无线控制协议逆向分析中,推断无人机控制协议的报文格式.更有Zhang等人[55]考虑协议分析的实时性,提出一种增量式协议格式逆向分析方法IPFRA,其主要也使用PI方法在初步得到的协议格式上近实时地增量推断更加完善的协议格式.
基于序列比对的思想,部分研究制定新的匹配规则与得分函数,主要考虑基于字节的序列比对算法会造成误对齐的现象以及不匹配字段间可能具有一定的相似度,从2个方面对NW算法进行改进、推断协议格式.部分研究重点解决基于字节的序列比对造成的误对齐问题,Cui等人[56]在RolePlayer方法中使用序列比对算法对报文序列进行对齐以查找协议中的动态可变字段,并在Discoverer方法[57]中对序列比对算法进行改进,提出了一种基于字段类型的序列比对算法.Discoverer将序列对齐粒度转化为token,将协议报文转化为由text,binary这2类token组成的序列并划分为不同的报文簇.采用规则分析token的属性与类型,并制定3条规则筛选FD(field distinguisher)字段,之后依据FD字段将报文类簇递归聚类为多个子报文簇,采用基于token类型的NW算法将同类序列进行对齐:若存在同一位置上token具有相似的属性和类型且满足固定约束,则判断为token匹配,以推断协议格式.同样,Esoul等人[58]将基于段的序列比对算法引入协议格式推断.在使用TF-IDF算法标准化候选协议字段分布的基础上,对协议报文进行基于全链(complete-link)原则的凝聚层次聚类;之后在聚类簇内采用DIALIGN 2多序列比对算法[59]对协议报文序列对齐;最后引入位置权值矩阵,并设定阈值提取协议报文公共对齐序列,推断协议格式.
协议报文固定位置的字段取值虽然不同,但存在一定的规律,因此部分研究重点关注字段在对齐时是否具有可推断的关系,改进匹配得分函数,提高对不匹配字段的宽容度,推断更加合理的协议格式.Bossert等人[36]提出基于语义信息的协议格式推断与协议关键词关系挖掘方法Netzob,此处的语义信息具体指的是与协议会话相关的环境信息,例如协议标识、IP地址、主机地址等.Netzob在语义信息与上下文数据对协议报文聚类的基础上,对NW算法进行扩展:改进NW算法的得分函数使其对语义敏感,引入语义匹配与不匹配参数以生成NW算法的对齐矩阵,使协议报文基于语义信息完成对齐;在合并阶段采用优化的UPGMA,定义合并质量函数计算不同的得分以实现在固定阈值下的迭代合并过程,得到由语义信息标识的协议格式;最后Netzob还对协议关键词间的关系进行挖掘,利用协议关键词的长度、偏移与取值等,采用最大信息系数(maximal information coefficient, MIC)与 Pearson 系数计算其是否线性相关,以表示字段间的依赖关系.Meng等人[60]则针对二进制协议提出了一种层次聚类与概率对齐相结合的协议格式推断方法.首先采用PRE-Bin方法[45]中的聚类方式对协议报文进行聚类,在此基础上引入基于Pair-HMM的多序列比对算法.该算法采用期望精度来衡量序列间的相似性,对NW算法进行改进,对齐时空格的惩罚分数设置为0,匹配与不匹配的得分由后验概率给出.之后根据各种数据的统计特点,如变化率、均值等,将相邻的字段分开并重组以推断协议格式.Kleber等人[61]创新性地考虑候选协议字段间的不相似性,对前期的语义分析工作[62]进行扩展,提出一种二进制协议逆向方法NEMETYL.该方法考虑到候选协议字段长度并不相同,便通过将高维向量嵌入低维空间中来实现将Canberra距离的概念推广到不同长度的向量,从而计算得到候选协议字段间的Canberra不相似矩阵;之后对NW算法进行改进,即计算得分矩阵时考虑候选协议字段间的不相似性,结合Hirschberg对齐算法生成协议报文间的不相似性矩阵;最后在DBSCAN算法对协议报文聚类的基础上,选择聚类簇内与其余报文均具有最低不相似性的报文作为中心,迭代式将其余报文与中心报文对齐合并,推断得到协议格式.
3.2 基于概率统计的协议格式推断
在协议逆向分析中,如果候选协议字段经常出现在协议报文中,那么其作为协议关键词的概率就越高,因此概率统计经常被用来协助协议逆向分析的决策.同时结合协议报文的特性,部分概率统计模型也常被用来对协议格式进行建模,从中推断协议格式.
由于协议头部数据往往包含更多协议相关信息,对协议标识有很大作用,因此部分研究重点关注协议头部报文格式.Wang等人[63]在提出的状态机推理方法Veritas中,采用常规概率统计的方式推断协议格式,为协议状态机推理提供基础.其采用K-S(Kolmogorov-Smirnov)统计检验方法从N-gram算法生成的候选协议字段集合中筛选协议关键词,并采用最大化原则,尽可能长地将报文头部使用协议关键词进行重构,最终推断协议头部报文格式.同时,Wang等人[64]还提出二进制协议头部报文格式推断算法Biprominer,并创新地以状态转移概率图进行描述.该算法从高频出现的单字节出发,逐步扩展到满足阈值长度的字节序列cells,并将协议报文头部数据标记为cells序列;之后将相对位置一致的cells作为一个类簇,提取类簇内相同的字节序列作为状态,计算状态间的转移概率,从而以状态转移概率图的形式描述协议头部报文格式.
协议报文使用协议关键词标识报文类型与参数传递,协议关键词亦为协议格式的组成部分,因此部分研究重点关注协议关键词的提取.协议关键词通常从候选协议字段中产生,那么协议关键词的提取必然伴随着协议报文分段算法的研究.Zhang等人[39]将信息熵理论引入协议报文分段,提出基于专家投票的无监督协议报文分段算法,并在此基础上提出协议关键词提取方法ProWord.该方法在候选协议字段集合上提出了一种结合多维属性的候选协议字段启发式排序算法,考虑每个候选协议字段的频率、位置以及长度,定义了一个得分函数以对多维属性进行统一度量,建立一个有序结构.最后筛选得分top-K的候选协议字段作为协议关键词,并考虑协议关键词间的冗余性,结合公共子串算法与起始位置进行冗余过滤,得到最终的协议关键词.Wang等人[65]在针对工业协议提出的逆向分析方法IPART中对ProWord中的协议报文分段算法进行改进,对候选报文分段点采用了一种重新定位方法,并筛选固定阈值长度的候选协议字段作为协议关键词.Luo等人[46-47]在基于时间序列的突变点检测算法对协议报文分段的基础上,首先通过统计分析的方式对出现概率极低的字段进行过滤,之后结合协议关键词的4种位置信息,提出基于最小描述长度的MDL-PTA(minimal description length-position test analysis)算法,实现基于协议关键词位置的统计分析方法,提取协议关键词.之后文献[46−47]还对协议关键词进行细化,推断了部分语义,并将该方法应用于物联网 (Internet of things,IoT)设备传输协议的脆弱性检测中.同样,Ye等人[66]认为协议关键词可以很大程度上标识协议报文,基于正确的协议关键词对协议报文进行聚类可以得到更加简洁及准确的协议格式,并提出NETPLIER方法.提取序列比对算法产生的连续对齐字段,结合分隔符与长度阈值筛选候选协议字段;之后根据候选协议字段的不同取值对协议报文进行聚类,并定义4个可观察约束以度量聚类的效果,将聚类结果转化为直观可评价的数值,构建候选协议字段与4个可观察约束之间的联合概率分布以实现候选协议字段与聚类效果的一一对应,即根据聚类的结果评价该候选协议字段成为协议关键词的可能性.筛选后验概率最大的候选协议字段作为协议关键词,即选取产生聚类效果最好的候选协议字段.
除了常规概率统计方法之外,部分研究使用概率模型对协议报文进行建模,从而提取协议关键词或推断协议格式.目前被引入私有协议逆向分析的概率模型有潜在狄利克雷分配(latent Dirichlet allocation,LDA)模型[67]与隐马尔可夫模型(hidden Markov models,HMM)[68]及其扩展.
LDA模型是自然语言处理中常用的概率模型,用来识别大规模语料库中潜在的主题信息,简单有效.LDA认为语料库中的所有文档都是由基本单词组成,文档可以包含多个主题,因此文档可以使用主题的概率分布来形式化描述,主题可以使用基本单词的概率分布来形式化描述.因此,只要选定类似的语料库、文档与基本单词便可以通过2个概率分布来对实体进行建模,最终推断得到所需的主题信息.基于网络流量的私有协议逆向分析在形式上十分类似于自然语言处理,因此LDA模型的应用具有一定可行性.Wang等人[69]提出的ProDecoder方法基于LDA模型挖掘候选协议字段间的潜在关系,推断协议关键词,最终通过聚类得到协议格式.该方法使用协议报文集合作为语料库,将协议关键词作为需要推断的主题,同时还是N-gram候选协议字段的概率分布.为此需要确定语料库中每个报文的协议关键词的概率分布与每个协议关键词的N-gram候选协议字段的概率分布.为解决上述问题,ProDecoder结合了一种经典的马尔可夫链蒙特卡罗算法即吉布斯采样(Gibbs sampling)来有效地找到近似解,从而获得协议关键词;之后将协议报文使用相关的协议关键词与其概率进行标记,并采用层次聚类方法将报文集聚类为子类,在类簇内采用渐进式NW算法得到协议格式.同样,Li等人[70]使用上述基于LDA模型的算法提取协议关键词,结合基于FP-Growth算法的关联分析方法挖掘协议关键词间的关系,但其并没有进一步推断协议格式.
HMM是一种统计分析模型,用来描述一个含有隐状态未知参数的马尔可夫模型,并从已知的观测状态中推断未知的隐状态参数.因此只要选定类似的已知状态链,即可对实体进行HMM建模,结合算法最优化HMM模型以推断未知参数.协议会话报文序列与单一报文字节序列均可类似为HMM模型的观测状态链,报文类型与协议关键词则为对应的观测状态,因此将HMM应用至基于网络流量的协议逆向技术是可行的.Whalen等人[71]将协议视为一个随机过程,协议报文视为该随机过程的输入字符串,协议以不同概率发送不同的协议报文实现信息交互,将HMM引入协议逆向分析技术中,提出基于协议会话构建ε-machine来获得满足协议报文结构的HMM模型,并推断相应的参数.首先采用最小熵聚类算法对协议报文进行聚类,并使用PI方法[52]发现报文头部边界.在过滤掉高熵数据后,结合协议报文的时间序列与状态分类算法构建最小确定HMM模型εmachine.且该模型的状态转换以图的形式表示协议头部报文格式,并伴生出部分特有信息:信源熵率等.同样基于隐马尔可夫模型,Cai等人[72]对黎敏等人提出的基于HsMM的最佳报文分段算法[43]进行优化扩展,使用2个矩阵分别代表候选协议字段和隐状态之间的映射关系与候选协议字段间的位置关系,以完善的HsMM模型表示协议格式信息,从而得到协议关键词;之后采用协议关键词关系衡量协议报文间的相似度并基于AP聚类算法对协议报文进行聚类,为后续协议状态机推断做准备.同样,Li等人[73]将HsMM应用到协议关键词的挖掘中,根据协议关键词的特性使用统计频率度量字段成为协议关键词的可能性,筛选top-K作为协议关键词的候选集合,最后利用上述HsMM模型与Viterbi算法确定候选协议字段是否确实是协议关键词.而He等人[74]将HMM应用于工业物联网(industrial Internet of things,IIoT)协议逆向分析中,以发现IIoT网络协议的漏洞.
3.3 基于频繁项挖掘的协议格式推断
频繁项挖掘是大数据分析领域常用的分析推断数据间关系的方法,用来挖掘数据集中经常一起出现的信息.频繁项挖掘算法均需要设定支持度与置信度来衡量信息间关联规则的强度.类比到协议逆向分析中,协议报文由协议关键词构成,如果任意多个关键词经常在协议报文中同时出现且覆盖较高比例的协议报文,那么这一组协议关键词即可构成协议格式.因此频繁项挖掘经常用来提取协议关键词与协议格式,主要采用的频繁项挖掘方法有Apriori算法[75]、FP-Growth算法[76]与PrefixSpan算法[77]等.
Apriori算法是经典的数据挖掘算法,其认为频繁项集的非空子集也一定是频繁的,因此它的基本思路是采用层次搜索的迭代方式,由候选的(k−1)-项集来挖掘k-项集,并逐一判断k-项集是否频繁.部分研究重点对支持度进行创新,提出不同类型的支持度以提高Apriori算法的挖掘精准度.Luo等人[78]基于频繁项挖掘的思想提出协议逆向分析方法AutoReEngine.首先定义2个支持度,即会话支持度和特定站点会话支持度,结合约束以迭代自增式生成频繁项,并量化每个频繁项的4种位置类型,以位置方差的形式反映其位置变化,由此推断得到协议关键词;之后设置面向协议关键词组的会话支持度以及特定站点会话支持度,采用Apriori算法挖掘得到协议关键词组集合,并基于此将协议报文进行聚类.在不同聚类簇中以协议关键词组为骨架分析其余可变字段的属性,得到协议格式.Lee等人[79]对分隔符进行详细推断分析,考虑频率、偏移、熵值等特征对报文进行分段,并采用基于消息、流与服务3种支持度的Apriori算法补充候选协议字段.
部分研究重点关注对Apriori算法的改进,在改进的基础上提出相应的算法,以实现协议逆向分析.Goo等人[80]在Apriori的基础上提出基于树形结构的 CSP(contiguous sequence pattern)算法,分层使用最小支持度的概念,以挖掘协议报文的静态字段,并进行了扩展,提出相应的协议格式推断方法[81].其根据协议关键词长度是否固定以及是否可预测定义了4种协议关键词类型,利用CSP算法挖掘固定长度的可预测静态协议关键词;之后根据设定阈值与统计数据将剩余字段划分为其他3种类型,即推断得到的协议格式均由上述4种类型协议字段填充,但该协议格式并不具有代表性,在此不进行赘述.秦中元等人[82]考虑二进制协议在使用频繁项挖掘时的长度与筛选问题,对其进行改进来推断二进制协议报文格式.首先以半字节为单位,应用长度为1,2,3,4的4种N-gram算法构造候选协议字段,并同时记录候选协议字段的频率及位置信息;之后结合支持度阈值与位置熵来挖掘满足条件的频繁项,将其作为协议关键词;最后采用正向最大匹配算法与专家投票算法推断得到二进制协议的报文分段点,并基于词边界熵信息对报文分段点进一步筛选以推断正确的协议格式.
FP-Growth算法构建树形结构,每个频繁项均作为树的结点,并拥有相应的计数与关联信息;之后在树上递归挖掘出所有频繁项,并在频繁项间产生关联规则.Li等人[83]采用ProWord方法[39]生成候选协议字段,规定候选协议字段的长度范围与位置信息熵以进行预筛选;之后在候选协议字段上采用FP-Growth算法挖掘频繁项集合,并结合字段间关系过滤噪音,保留最大支持度的频繁项作为有效的协议关键词.Lin等人[84]在FP-Growth算法的基础上,提出CFSM(closed frequent sequences mining)算法来挖掘协议关键词以及位置信息,并基于这些信息提出CFGM(closed frequent groups mining)算法推断协议关键词间的关系.CFGM基于最长公共子序列长度与F-DBSCAN算法对协议报文进行聚类;之后在类簇内采用N-gram算法生成候选协议字段,以散列表(Hash table)形式存储并挖掘协议关键词;最后基于协议关键词的位置信息构建树形结构,反映协议关键词间的并列、顺序以及层次关系,从而推断协议格式.
PrefixSpan算法的目标是挖掘满足最小支持度的频繁序列模式,与FP-Growth算法的目标稍有不同,但其与Apriori算法类似,从长度为1的前缀开始挖掘序列模式,并搜索数据集合得到长度为1的前缀对应的频繁序列,之后递归挖掘长度为2的前缀对应的频繁序列,直到满足长度阈值为止.朱玉娜等人[85]提出一种面向加密协议的格式解析方法SPFPA,基于频繁序列挖掘提取加密协议中具有时序关系的协议关键词.SPFPA规定了2种频繁项:以字节为单位的固定偏移频繁单字节和满足最小长度阈值的频繁字节序列.设定支持度以实现上述频繁项的提取,并构建包含频繁项的频率、偏移、相邻与关联等信息的树形结构.最后采用PrefixSpan算法的思想构建投影库,在树上以层次顺序挖掘协议关键词序列,即可得到加密协议明文区域的报文格式.
3.4 基于深度学习的协议格式推断
深度学习重点应用于分类领域,因此基于深度学习的协议格式推断也类似地将格式推断转化为协议关键词类型的分类问题.先利用已知类型的协议关键词训练分类器,之后将协议报文分段的候选协议字段输入,从而得到协议关键词,并重构协议格式.
Zhao等人[90]结合工业控制协议的特征,将卷积神经网络引入协议逆向分析中,考虑协议会话报文集的时序关系,提出一种基于长短期记忆全卷积神经 网络 (long short-term memory fully convolutional neural, LSTM-FCN)模型[91]的私有工业控制协议的格式推断算法.首先对大量已知公开工业控制协议数据按照规范进行字段划分,将5种类型的字段结合数据时序关系生成时序集合,并输入LSTM-FCN分类模型进行训练;之后对于私有工业控制协议以字节为单位进行分段,划分为时序集合,采用训练好的模型确定上述候选协议字段的类型.以字节为单位的划分必然存在过分段的情况,因此考虑对连续类型的字节进行融合得到完整的协议关键词,最终推断出私有工业控制协议格式.之后Yang等人[92]基于同样的思想,使用已知6种类型的字段集合训练LSTMFCN模型.将协议报文按照0.5B,1B,2B,4B这4种粒度进行划分;并使用训练好的模型对所有字节序列进行分类并记录分类结果;最后使用区域划分算法,考虑字节序列分类结果的分布集中程度,以标准差来衡量,得到最佳的字节序列分类结果,推断未知协议格式.
综上所述,协议格式推断承接预推理的结果展开进一层次的私有协议逆向分析,其输出结果为协议关键词与协议报文格式集合,挖掘更多私有协议规范.表3分类概述了协议格式推断部分相关研究的主要内容,包括面向协议类型、方法基础、推断算法与对比分析等.表3中将采用了相同方法但应用场景不同的研究归为一类,与其他方法进行对比分析.由表3可知,序列比对算法打开了基于网络流量的私有协议逆向技术的大门,之后由于序列比对算法的局限性与自然语言处理的兴起,部分概率统计方法逐渐成为研究的热潮,同时数据挖掘方法的应用亦使得基于网络流量的私有协议逆向技术更加完善.
4 语义分析
语义分析是私有协议逆向技术的进阶步骤,其主要是为了推断报文字段(包括协议关键词与其余字段)或协议报文的语义信息,从而更好地理解协议.目前所有的方法均依赖于分析人员的最终解释,即由分析人员定义语义字段的种类并提出对应的分析方法.因此语义分析的第1个任务是定义报文字段的语义种类,第2个任务是针对不同种类型语义字段提出相应的分析方法.
本文把报文字段的语义信息主要分为4种:1)环境参数相关语义,其主要指的是与环境系统相关的一些设置参数,例如端口、地址、结点名、文件名以及时间戳等,这类语义信息可以通过记录传输环境相关信息,通过报文字段取值对比来进行分析;2)标识性语义,其主要指的是与类型标识相关的一些标识符,例如计数器、报文类型标识符以及会话ID、序列ID等,这类语义信息可以通过对协议不同格式报文进行对比来加以分析,判断报文字段取值是否自增或自减、是否在同类报文中保持不变等;3)指示性语义,其主要指的是反映其他字段属性或整体的报文字段,例如指示其他字段的长度、偏移量、偏移指针以及校验码(反映报文整体散列值)等,这类语义信息可以通过在报文字段的次序关系中,挖掘前字段的值是否表示后字段的某一属性,校验码则可以通过尝试各种散列算法来分析;4)特殊语义,其主要指的是部分协议特有的报文字段,例如工控协议的功能代码字段以及加密协议的加密字段等,这类语义信息需要提出针对性的方法进行检测.
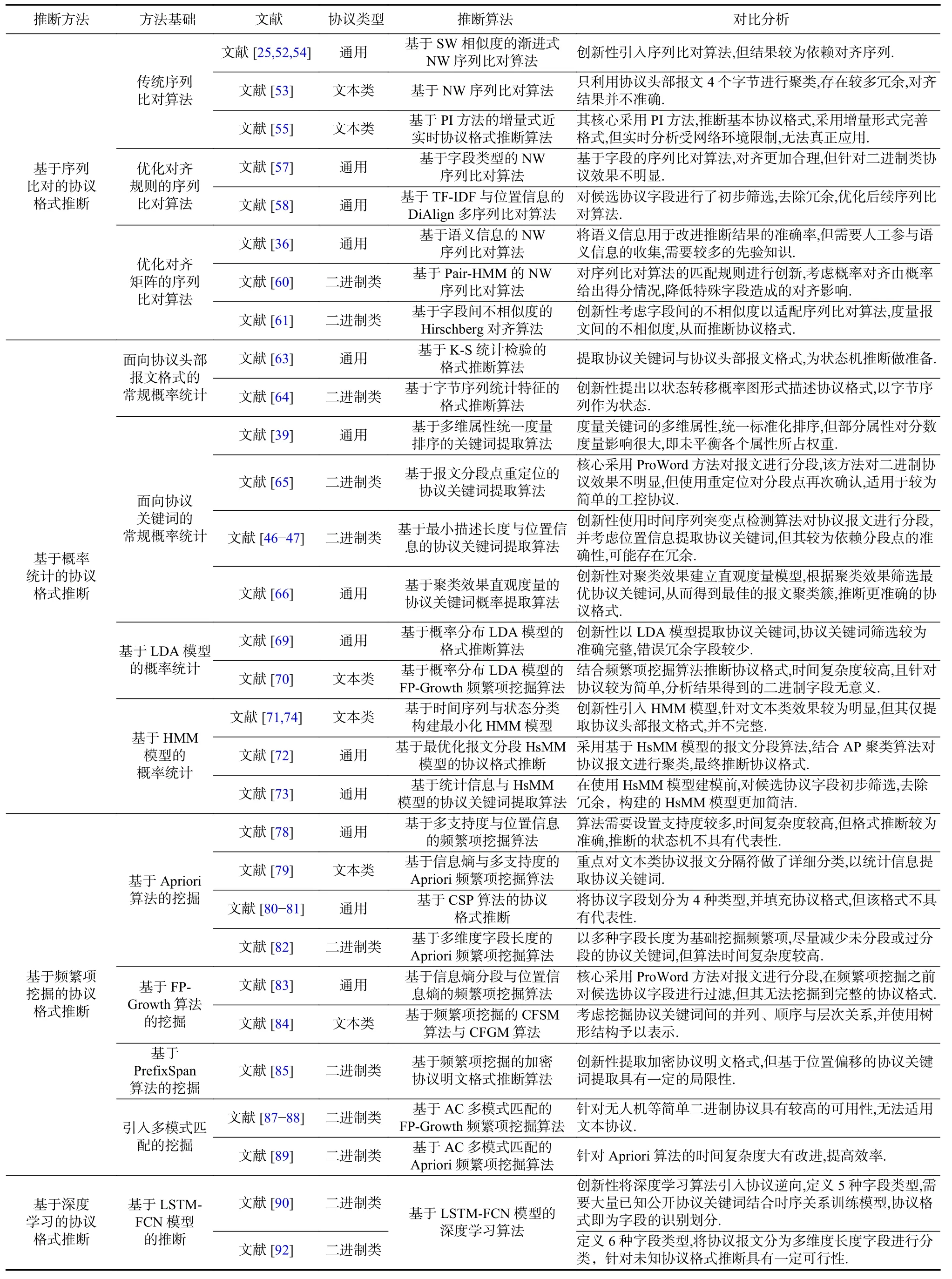
Table 3 Summary of Protocol Format Inference表3 协议格式推断方法概述
本文将现有语义分析研究方法分为2类:基于字段取值的语义分析以及基于先验知识模板匹配的语义分析.
4.1 基于字段取值的语义分析
基于字段取值的语义分析需要将同一范围的字段值生成数值集合,通过取值来判断其所属语义,同时对部分协议的特殊语义字段针对性的提出检测方法.
Cui等人[56]在RolePlayer方法中提出了4种具有语义信息的动态字段:1)端口、地址;2)长度;3)参数;4)cookie,特定于双方会话中的不透明数据,例如事务ID.该方法将端口、地址以及参数作为先验知识利用NW算法,对报文分段对齐,从协议格式的角度推断长度、参数2种语义字段.针对cookie,特殊制定了4条规则(包括前缀、后缀匹配等)进行判断.之后在提出的Discoverer方法[57]中又增加了2种字段语义:1)偏移量;2)偏移指针;并对RolePlayer方法的语义分析方法从字段取值分析的角度进行扩展:分析字段取值集合与对应后续报文字段的长度、偏移量的差 异 性.Bermudez等 人[93-94]提 出 的 FieldHunter方法,对基于字段取值的语义分析方法进行完善,针对性地提出6种字段语义与对应检测方法:1)针对报文类型,结合请求、响应报文字段具有高相关性的特点,采用信息论的方法度量报文字段间的因果关系,引入阈值进行筛选;2)针对报文长度,结合报文长度与字段取值呈线性相关的特点,使用Pearson系数与线性相关方程进行筛选;3)针对主机ID、会话ID,由于主机ID、会话ID均与IP地址强相关,因此计算字段取值与IP地址信息的联合分布,同样引入阈值进行筛选;4)针对传输ID,使用信息熵来评价字段取值的随机性,并结合请求、响应报文分析字段一致性,引入最小支持度和最小字段长度进行筛选;5)针对计数器,计算连续2个协议报文的字段差值,筛选熵值较低的字段作为计数器语义字段.
之后的基于字段取值的语义分析相关研究也多是基于FieldHunter方法,但部分研究重点关注协议的特殊语义信息,提出针对性的分析方法.Carli等人[95]针对解密后的恶意软件流量提出了一种协议逆向技术,定义了4种字段语义,并针对加密字段采用Shannon熵和N截断熵检测报文字段的随机性.Ladi等人[96]提出一种面向二进制协议的语义分析方法,定义了7种字段语义,并针对长度前缀字符串、空结尾字符串等采用指针逐字节进行分析,检测其是否满足语义的属性.Wang等人[65]在提出的IPART方法中定义了工控协议的4种字段语义.针对功能代码,提出基于字段范围内不同数值个数、字段偏移和字段条目,结合自定义公式计算得分,选择得分最高的字段作为功能代码语义.张蔚瑶等人[97]在其提出的协议模糊测试工具UPAFuzz中定义了5种字段语义,并将语义字段分为2类:一类为取值无限的字段,如序列号、文本字段等;另一类为取值有限的字段,如检验码、长度等,针对性地提出循环对比法来进行推断.
(2)浓盐酸易挥发,反应制取的氯气中含有HCl,装置B中饱和食盐水的作用是除去Cl2中的HCl;若装置C发生堵塞,装置B中的压强会增大,长颈漏斗中液面上升,形成水柱。
4.2 基于模板匹配的语义分析
基于模板匹配的语义分析方法需要正确的先验知识生成各类语义字段的统一模板,之后判断未知语义的报文字段与模板之间的关系,从而确定报文字段的所属语义.
Ji等人[25]在对无人机私有飞行控制协议分析时,提出一种分析CRC与奇偶校验码字段的方法.该方法采用PI方法[52]提取出协议的静态字段、动态字段等,考虑到校验码字段通常在协议报文数据末位且没有明显趋势特征进行过滤,并采用一系列逻辑异或公式生成模板,匹配报文字段以筛选出校验码语义字段.Kleber等人[62]在准确的已知字段语义信息作为先验知识的基础上采用聚类方法分析未知报文字段语义.该方法首先将已知语义信息的字段解释为字节值向量,通过Canberra距离定义其不相似性,并使用DBSCAN算法对字段进行聚类;之后在类簇内生成描述该语义信息的数字模板,即已知字段语义信息与数据模板一一对应;最后采用NEMESYS方法[48]对协议报文进行分段,并计算报文字段与数据模板的马氏距离(Mahalanobis distance)来确定其所属语义信息.文献[62]分析得到数据模板的语义字段类型包括:1)检验码;2)浮点型数据;3)ID;4)IPv4地址;5)时间戳等.Wang等人[98]重点关注工业控制协议逆向分析,在提出的MSERA方法中定义了7种字段语义:1)协议标识符;2)长度;3)序列号;4)CRC校验码;5)时间戳;6)功能代码;7)站点标识符,即客户端和服务器的身份标识字段.之后根据上述7个语义字段的取值特征以及位置特征生成特征模板,利用启发式方法进行字段语义的识别,并将识别的字段进行标记.然后采用基于报文长度的DBSCAN聚类算法进行聚类,并利用NW算法对齐以筛选出报文分段点,最后在动态字段上迭代挖掘上次未识别出的字段语义:协议标识符、长度等,同时对于字节取值为空的特殊情况进行了考虑.
综上所述,语义分析重点承接协议格式推断中的协议关键词提取的结果,赋予报文字段更多属性,并作为协议状态机推理的基础.同时方便分析人员构造更完整的协议报文,以实现对协议交互的测试.语义类型由人为定义,因此语义分析结果均由分析人员进行解释.表4分类概述了语义分析部分相关研究的主要内容,包括各个研究工作中定义的4种字段语义与对比分析.由表4可知,语义分析采用的方法主要是基于字段取值分析,同时针对普通语义以及部分协议的特殊语义进行分析,或基于已知语义字段生成匹配规则,从而实现对未知字段语义类型的判断.
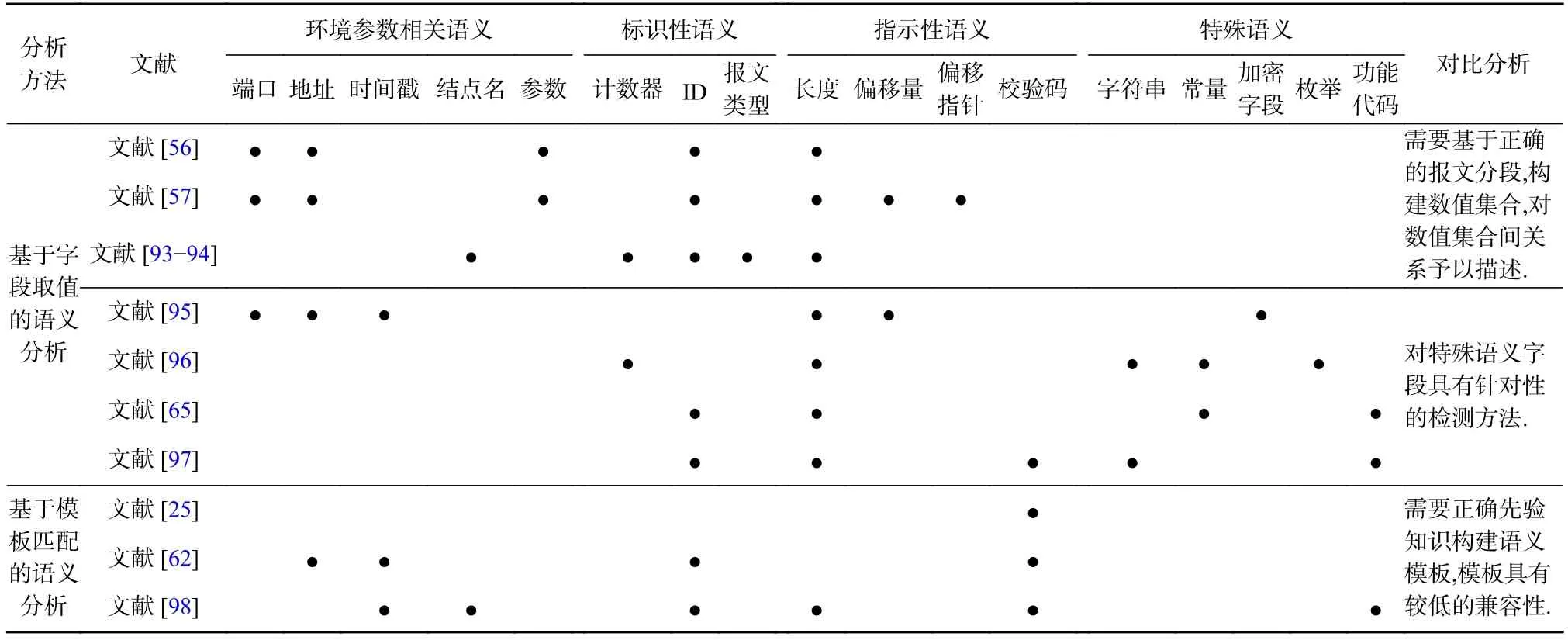
Table 4 Summary of Semantic Analysis表4 语义分析方法概述
5 协议状态机推理
协议状态机推理是私有协议逆向技术的升华步骤,其在协议逆向前3个步骤的基础上,汇总所有已知信息、分析结果推理协议逆向技术的最终目标:协议状态机.
协议状态机是协议状态之间转换的数学模型,本文将协议状态定义为在接受特定事件(收到特定类型报文)或执行相应动作(发送特定类型报文)时的状态.状态转换就是协议在执行上述操作后从一个状态转换为下一个状态的过程,即不同类型的协议报文是影响协议状态转换的主要因素.可以使用一个三元组来表示:M=(S, P, δ),其中S表示协议的有限状态集合,包括协议的初始状态与结束状态,P表示不同类型的报文集合,δ表示状态转移函数,其接受不同类型的报文实现状态的转换.报文是引起协议状态转换的主要条件,而不是状态本身.因此协议状态机推理的第1个任务就是筛选出不同类型的协议报文,并基于此完成第2个任务,即上述协议状态机的构建.如果使用图来描述协议状态机的话,那么结点即为协议的不同状态,相邻结点之间的边即为不同类型的报文引起的状态转换.
建立一个完备的协议状态机,需要协议交互时各种情况存在的会话报文序列以详尽地推断完整的状态转换,构建的状态机也十分庞大,必然存在状态冗余的情况.因此协议状态机推理的第3个任务就是协议状态机的简化.需要推理状态间存在的潜在循环,挖掘初始状态的唯一性、状态间转换的次序性以及状态接受报文类型的多样性,将状态间的转换(边)或状态(结点)进行合并化简,但需要遵循状态机的每一条从初始状态出发到结束状态的路径均为协议一次完整的会话.
由于方法的独立性,现有研究中均会提出一套完整的协议状态机推理方案,其中必然包括前3个步骤的推断方法,具有一定的共通性,因此本节会对其进行简要概述,并将重点放在状态机构建与状态机简化上.
5.1 传统协议状态机推理
协议交互报文是协议状态转换的引发条件,因此常规协议交互式是协议状态机推理的最基本方法,部分研究根据全部协议会话进行状态机推理,之后制定规则对协议状态机进行简化.
Leita等人[17]为了自动化生成蜜罐脚本,提出了名为ScriptGen的方法,针对蜜罐专有协议的网络流量进行分析,并生成蜜罐脚本部署在现网中以便分析人员测试未知的协议.ScriptGen是第一个基于报文交互流量生成协议状态机的工具,设定协议状态的最大出度阈值与最大状态数阈值控制协议状态机的上限结构,以迭代方式逐个添加所有协议会话来构建协议状态机.之后采用PI方法[52]判断2个报文是否语义上相似,并以不同字节的个数作为报文间距离进行聚类(宏聚类);在宏聚类的基础上,提出区域分析算法以不同区域的异变性作为距离再一次进行聚类(微聚类).最后根据聚类后的结果将相似类簇内的状态和转换合并,简化协议状态机.Trifilo等人[99]针对二进制协议状态机的推理进行了研究,并创新性提出状态分裂算法.首先逐字节统计分析其方差分布的变化(variance of the distribution of variances, VDV),得到标识报文不同类型的相关字段,并基于上述字段提出状态分裂算法定义协议状态并挖掘状态间的转换;之后以滑动窗口的形式遍历协议会话报文序列,得到每个窗口内的状态序列,将连续3个窗口中的任意2个状态序列进行对比以分离出不存在的状态,如此便创建了只有几个正确状态的状态转化;最后状态分裂算法导致生成的协议状态机具有多余的转换边,因此制定2个规则来对状态机进行简化.
部分研究将协议报文连续子序列作为状态,推理协议状态机.Shevertalov等人[35]提出协议状态机推理工具PEXT,首先将聚类后的报文使用簇ID进行标记,则一个会话的报文序列就生成一组编号序列,采用最长公共子串算法筛选出子序列并将其组合为状态;之后利用上述状态集合对所有协议会话进行标记,基于标记后的多个状态序列构建协议状态转换图;最后采用基于报文流向的2个转换对协议状态机进行化简,并保证每个转换的离开状态都是唯一确定的.但PEXT方法构建的仅仅是报文类型之间顺序模型,有违协议状态机原理,并不能作为常规的协议状态机来使用,之后的AutoReEngine方法[78]推理的协议状态机亦是如此.
5.2 基于概率分析的协议状态机推理
在基于协议交互的基础上,部分研究对交互的过程进行统计分析,通过概率分析方法确定状态之间的转移,并为协议状态机添加更多的信息以对其进行完善;或是采用概率模型以构建协议状态机,并基于此进行优化.
Wang等人[63]提出一种基于概率分析的状态机推理方法Veritas,并创新性地定义了一种概率协议状态机,即协议状态机的概率泛化模型.该方法以协议报文头部字节序列为基础,结合PAM算法与Jaccard指数对协议报文进行聚类,并选择聚类中心作为协议状态报文,使用协议状态报文对协议会话进行标记,得到报文状态序列.之后计算任意2个连续状态之间的频率,并构建有向图来描述每对协议状态之间的连接,最终得到自行定义的概率协议状态机.但其并没有进一步对概率协议状态机进行简化.Krueger等人[18]为分析蜜罐等恶意软件协议提出协议状态机推理方法PRISMA,其对ASAP方法[100]进行了扩展.PRISMA首先按照二进制类和文本类分别提出2种方法对协议报文进行聚类;之后采用马尔可夫模型构建协议状态机,根据聚类簇中的报文类型标签,通过最大似然估计初始概率和转换概率,直接学习生成马尔可夫模型;最后将马尔可夫模型转化为协议状态机,应用Moore状态机最小化算法进行简化.
5.3 基于启发式树形构建的协议状态机推理
树形结构由上到下展开,符合协议间状态转换的规律,同时基于启发式树形构建的过程也就是协议状态机构建的过程,当基于协议会话的树构建完整时,即可得到树形结构的协议状态机.之后考虑层次结点间的报文类型是否相似、是否有相同的输入输出等以判断结点间是否可以合并,从而简化协议状态机.
Gorbunov等人[53]提出了基于协议状态机的可扩展协议模糊测试框架AutoFuzz.该框架重点为了测试协议的安全性与可靠性,发现协议漏洞,其构造协议状态机的方法主要是Hsu等人[101]提出的.首先将协议会话中代表状态循环的循环报文删除并记下相应的位置;之后生成只有根结点(初始状态)的树形协议状态机,将所有会话序列逐步添加到树中:如果该报文没有在树中出现,则在状态结点上添加叶子结点.针对会话序列繁多导致的状态机树庞大问题,AutoFuzz提出状态等价原则对协议状态机进行剪枝化简.Lee等人[102]基于树形协议状态机提出一种基于状态兼容性原则的状态机最小化方法PRETT,在消除冗余状态的同时,推导出最小化状态机.提出2个原则测试树每层的候选状态与其他状态之间的兼容性来进行状态合并,消除冗余状态,最终得到仅由有效状态组成的最小化协议状态机.
前缀树是一种有序树形结构,每个结点的取值由该结点在树中的位置决定,一个结点的所有子孙均具有相同的前缀.部分协议会话前期交互由固定类型的报文序列完成,因此通过前缀树可以更好地构建较为简洁的协议状态机,从而减轻简化协议状态机的压力.前缀树接受器(prefix tree acceptor, PTA)正是基于前缀树而构建的接受协议会话的实例,从而实现满足多协议会话的要求.
Antunes等人[103]提出了基于网络流量的文本类协议逆向技术ReverX,主要构建2个PTA来完成协议状态机的推理.首先构造一个PTA启发式接受所有协议报文并记录转换的频数;之后采用Moore状态机最小化算法将具有类似转换的等价状态合并,以接受相同类型报文的不同实例,并区分不同的报文类型;然后将协议会话转换为报文类型序列,再构建一个PTA用来接受多个协议会话的报文类型序列,每当出现不同类型的报文时,新的状态和转换就会添加到PTA中;最后结合不同报文类型间的因果关系,使用积极状态合并算法对协议状态机进行简化.Lin等人[104]考虑协议交互传输过程中存在的数据流信息,结合控制流信息对传统的协议状态机进行扩展,提出了新型扩展协议状态机推理方法ReFSM.该方法改进Apriori算法以挖掘高频且具有稳定位置方差的闭合字节序列作为协议关键词,并使用协议关键词将协议报文标记为不同的报文类型,结合Jaccard指数与K-means算法对协议报文进行聚类确定协议报文类型数;之后通过构建PTA接受所有协议会话,并采用K-tail状态合并算法合并具有相同输入与输出的等价状态以生成传统的最小化协议状态机;最后引入数据保护(data guards)概念,其由2部分构成:协议关键词的词间约束和协议报文间与报文内的依赖关系,并将其与协议状态集合作为2部分扩展到PTA树中以实现对传统的最小化协议状态机进行扩展,得到提出的扩展协议状态机.
综上所述,协议状态机推理汇总协议格式、协议关键词以及语义信息推断协议状态,结合协议会话推理协议状态机,帮助分析人员更好地理解协议的交互行为、报文的收发规范,同时也可以协助对协议进行安全性测试,针对性地使协议转换到某一状态,测试各种输入输出,提高协议的可靠性.表5分类概述了协议状态机推理部分相关研究的主要内容,包括各个研究工作中协议状态标记方法、状态机构建方法以及简化方法.由表5可知,协议状态机推理很大程度上依赖于不同报文类型的确定,协议状态机推理越来越复杂,对协议状态机附加的相关信息也越来越完善.
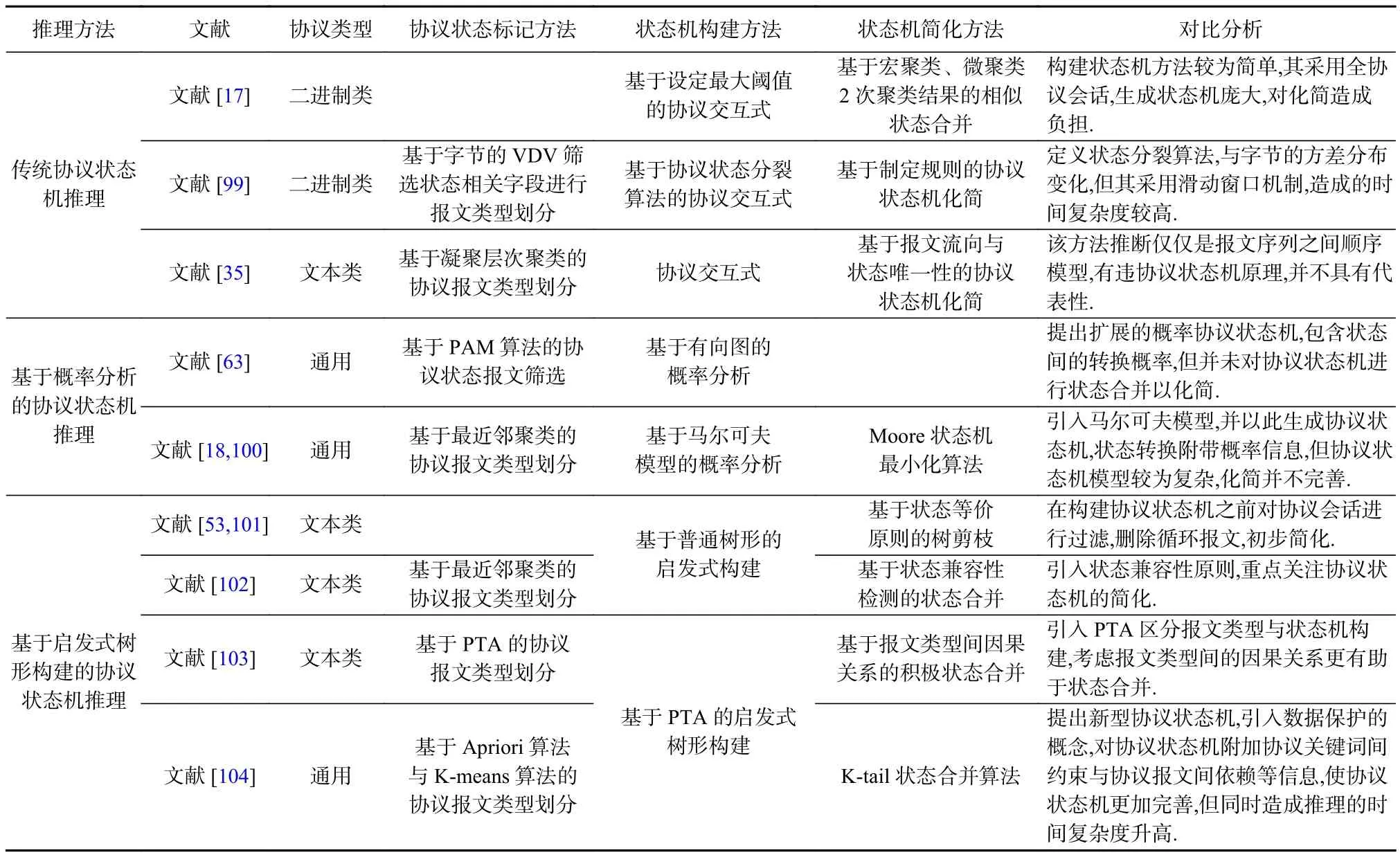
Table 5 Summary of Protocol State Machine Inference表5 协议状态机推理方法概述
6 总结与展望
经过对现有研究方法的对比分析,本节重点进行总结与展望,阐述基于网络流量的私有协议逆向技术目前存在的主要问题与影响因素,并指出未来研究方向与应用场景,最后对全文进行总结性概述.
6.1 主要问题与影响因素
基于网络流量的私有协议逆向技术目前已成为国内外研究人员的重点研究内容,具有现实的应用价值与研究意义.尽管其通过各类方法取得不少研究成果,但仍然存在4个方面的问题:
1)数据样本集匮乏.目前私有协议逆向技术尚且没有公开可用的完整标记的数据集样本,基于公开RFC协议的流量完成的协议逆向技术大多无法真正应用于对私有协议的逆向分析.公开协议大多较为简单,而私有协议为了实现应用通信的复杂功能必然与之不同,存在一定的差异.数据样本集的匮乏亦导致协议逆向技术结果的评价指标不具有统一性,缺乏可对比的标签数据.
2)协议逆向技术存在冗余性.协议逆向技术基于海量协议流量推断,推断过程必然存在冗余性,尤其是核心采用概率统计的协议逆向技术,即使采用筛选过滤也无法完全避免.同时错误、冗余的中间结果对最终的协议关键词、协议格式以及协议状态机等均存在影响,如何正确降低中间过程的冗余,减少其造成的影响,是私有协议逆向技术急需解决的主要问题.
3)协议逆向技术自动化程度较低.目前私有协议逆向技术的自动化程度并不高,部分研究甚至需要大量的先验知识才能得到较高的准确度,而基于零先验知识的研究明显没有达到理想效果,这就导致协议逆向技术难以达到较高的自动化程度.同时,语义分析很大程度上依赖于先验知识与人为解释,亦严重影响协议逆向技术的自动化程度,或将语义分析作为附加研究内容剔除逆向流程以实现自动化.
4)协议逆向技术兼容性与稳健性不足.私有协议逆向技术的目标是适用于多类型协议流量并具有较高的推断准确度.然而现有研究多是针对单一类型协议流量进行分析,即使考虑方法的通用性,仍然无法同时保证较高的推断准确度.且现有研究中提出的方法大多难以直接对私有协议进行推断,也从侧面反映现有技术兼容性与稳健性并不高.
综上所述,私有协议逆向技术存在上述问题的主要影响因素是私有协议自身的特殊性与复杂性,因此在私有协议与协议逆向技术间寻求一个平衡是解决问题的主要途径.结合私有协议相关先验知识必然会提高私有协议逆向技术的推断准确度,但这就会影响私有协议逆向技术的自动化程度,因此如何利用最少的先验知识实现最大推断准确度的半自动化私有协议逆向技术是解决问题的关键;网络应用协议、工业通信协议与无线控制协议等均具有自身的特性,结合协议特殊性同样可以提高私有协议逆向技术的推断准确度,但这就会影响私有协议逆向技术的兼容性,如何实现最大程度的协议种类划分,在不同种类内提高私有协议逆向技术的普遍适用性亦是解决问题的关键.
6.2 未来研究方向与应用场景
基于网络流量的私有协议逆向技术可以从4个方面开展未来的研究:
1)精细化私有协议逆向分析.随着互联网应用的高频涌现,私有协议广泛发展,同时恶意软件等亦使用私有协议在主干网进行通信隐藏以规避监管,因此精细化私有协议逆向技术是一个重点的研究方向.提高私有协议逆向技术的推断准确度,同时提高自动化程度与方法兼容性.应重点关注二进制协议的逆向分析,二进制协议相较于文本类协议而言具有透明序列的特性,且目前私有协议设计呈现出二进制化趋势,工业控制互联网、物联网等均采用二进制协议来通信.因此,二进制协议逆向技术使用范围会更加广泛,更符合实际应用需求,对其研究更具有意义.针对二进制协议的逆向技术,需要重点关注协议报文分段与语义分析,如何在合适的位置将报文序列分开,确定分段粒度为字节或半字节,探究字段结构从而达到精确分段.之后取出任意分段间的比特序列分析其语义,结合取值分析或模板匹配得到该字段的最近似语义,以语义信息形式描述二进制格式则为针对二进制协议逆向分析的最优结果.
2)协议报文聚类与协议状态机推理.协议报文聚类是协议逆向技术的基础,如何度量协议报文间相似度,采用合适或创新性的聚类算法得到更加紧密的聚类簇是一个重要的研究方向,可以最大化为私有协议逆向技术的推断准确度提供保障.同时在协议报文聚类时,需要关注不同协议类型的报文聚类与不同协议格式的报文聚类2方面:基于流粒度挖掘同一类协议报文的共有属性,制定合适度量与聚类算法,将相似的流聚类为协议流聚类簇;并基于报文粒度挖掘同一格式协议报文的共有属性,将相似格式的协议报文聚类为协议格式聚类簇,共同为协议格式推断做好基础.协议状态机推理的研究目前尚处于探索阶段,对传统协议状态机的扩展,使其包含更复杂的信息,是目前协议状态机推理的一个发展方向.但更应该专注于协议状态机的简化,构建协议状态机以后,如何以更加合适的算法进行状态合并,尽量降低协议状态机的冗余,更加明显地展示协议的行为交互,使分析人员更好地理解协议相关设计理念,因此也应积极探索协议状态机推理的研究.
3)私有加密协议逆向分析.越来越多的私有协议流量采用加密技术来保证用户隐私与安全,这就直接导致协议逆向技术的部分失效,但针对存在明文字段的加密协议,私有协议逆向技术依然可用.其可以推断出加密协议的明文字段,即确定加密协议的明文字段与密文字段间的分段点,提取加密协议的明文区域,并推断其字段格式.这正是目前加密协议研究的一个重点方向,即明文和密文区域的切分.因此,私有协议逆向技术对加密协议分析仍具有一定的辅助作用,同时也可以将明文字段格式作为加密协议的固有特征进行分类识别,从本质上提高加密协议流量识别准确率,而不需要训练复杂的机器学习模型,降低时间复杂度,使加密协议流量识别更加具有实际意义.因此,私有加密协议的逆向分析也是未来的研究方向之一.
4)全未知流量的逆向分析.对全未知流量的逆向分析即对主干网路由器处采集到的多种私有协议、多种格式混杂的流量进行逆向分析,针对这种混杂流量,未知其私有协议种类、私有协议格式等,这就要求私有协议逆向技术具有智能化分析能力.如何区分不同种类私有协议流量,并针对单一私有协议流量进行逆向分析;如何在某种私有协议数据量较少的情况下,智能决策保留协议流量或扩充样本,完成逆向推断;如何智能化地发现主干网中的未知私有协议,推断未知私有协议的协议格式,给予工程人员最大化的信息协助决策等.上述问题均为目前私有协议分析面临的实际需求,因此,基于网络流量的私有协议逆向技术智能化分析是一个重要的研究方向.
私有协议逆向技术面向实际问题需求,考虑落地应用实际性,尤其近些年来具有广泛的应用场景:
1)私有协议流量识别[105].协议关键词与协议格式均具有协议的标识性,属于协议的固有特征,因此协议关键词组或协议格式均可以用来精准识别私有协议流量,通过规则匹配以实现轻量化的识别,而不需要训练复杂的机器学习模型,同时针对具有明文字段的加密协议流量亦具有一定的识别能力.
2)工控协议漏洞测试[97].工业控制协议需要极其准确的数据传输与通信控制,在信息化的大时代背景下,工业控制网络的兴起对工业发展带来了极大的便利,工业控制协议也应运而生,但是工业控制协议在投入使用前必须经过严格的漏洞测试,确保不会造成机器接收指令执行误操作的现象发生,以保障工业安全.同时工业控制协议多采用二进制协议进行传输,人为对其流量进行分析难度较大,因此私有协议逆向技术可以得到广泛应用.
3)物联网分析[106].万物互联概念的出现造就了目前智能家居、车载互联网以及城市交通信息网等各种物联网均投入使用,使生活更加便捷、智能的同时带来不可避免的信息泄露、黑客攻击等一系列问题.因此对物联网通信协议的逆向分析可以最大程度上保障物联网安全,确保物联网设备不被黑客劫持,实现真正的万物互联.
6.3 结束语
私有协议逆向技术是当前协议分析领域最具有挑战的研究之一.本文首先介绍私有协议逆向技术的种类与研究背景,并重点阐述基于网络流量的私有协议逆向技术的研究意义.其次提出基于网络流量的私有协议逆向技术框架,从预推理、协议格式推断、语义分析以及协议状态机推理4个步骤细化技术框架并介绍每步骤的主要任务.之后综述现有基于网络流量的私有协议逆向技术并按照其所属研究步骤进行分类,并剖析技术采用的核心研究方法,对比叙述.最后总结当前基于网络流量的私有协议逆向技术存在的主要问题,提出问题与影响因素的实际矛盾,指出解决问题的关键,并展望基于网络流量的私有协议逆向技术未来的研究方向,指出其未来主要的应用场景,为进一步的研究奠定基础.
作者贡献声明:李峻辰为本文调研整理文献,设计本文的研究框架与撰写结构框架,把握全文思想,按照框架完成本文的撰写、修改、校对与定稿;程光为本文的研究指导方向,提供研究思路,优化本文的研究框架,对论文进行审阅与修订,提出论文的修改意见,并对整篇论文的质量进行把关;杨刚芹为本文调研整理部分文献,协助完成本文的修改,并协助对本文格式进行校正.
猜你喜欢
汽车电器(2022年9期)2022-11-07 02:16:24
音乐天地(音乐创作版)(2022年1期)2022-04-26 13:51:38
铁道通信信号(2020年4期)2020-09-21 09:15:24
北京航空航天大学学报(2019年9期)2019-10-26 02:30:04
中国外汇(2019年11期)2019-08-27 02:06:30
中学课程辅导·高考版(2017年6期)2017-06-13 07:21:57
铁道通信信号(2016年8期)2016-06-01 12:10:21
应用技术学报(2014年3期)2014-02-28 14:52:32
黑龙江科学(2011年2期)2011-03-14 00:39:36
空间控制技术与应用(2010年5期)2010-12-23 08:05:25
