
自适应高效深度跨模态增量哈希检索算法
2023-01-29 13:14:08徐黎明郑伯川谢亦才
计算机工程与应用 2023年2期
周 坤,徐黎明,郑伯川,2,谢亦才
1.西华师范大学 计算机学院,四川 南充637009
2.物联网感知与大数据分析南充市重点实验室,四川 南充637009
3.重庆邮电大学 计算机科学与技术学院,重庆400065
随着大数据时代的到来,文本和图像等不同模态的数据日益丰富,媒体数据量呈指数型增长,这给数据检索带来了巨大挑战。同时单模态数据检索方式(即,图像检索图像)已经无法满足人们的检索需求。利用文本检索图像、图像检索文本以及跨域图像的交叉检索方式能够呈现给用户更加丰富和多元的信息。跨模态检索已被纳入国家人工智能2.0规划纲要,国内外大量学者投入到该研究中,这也使得跨模态检索算法成为近年来研究的热点问题[1]。
早期的检索算法[2]在数据相似性保持方面有良好的可解释性,较好地刻画了数据之间的相似性和非相似性。但当多模态数据量足够大时,这些算法面临着维数灾难、存储开销大、检索速度慢等问题。对此,有学者提出了基于哈希编码的跨模态检索算法,该算法存储开销小、检索速度快以及适合大规模数据的跨模态检索任务。基于哈希编码的跨模态检索算法将高维数据映射为低维的二进制表示,然后采用异或操作来进行相似性距离度量,实现高效的大规模数据检索。
尽管现阶段提出了大量的深度哈希算法,但几乎所有的哈希算法无法较好地检索训练数据类别以外的数据,当加入新类别的数据(即,训练数据类别并未完全包含查询数据类别加入)时,需要重新训练哈希函数,并为数据库中的数据生成新的哈希码,这对于大规模、多模态数据检索是不切实际的。同时,优化离散哈希码是一个可证明的NP问题,大部分算法将离散哈希码松弛为连续变量,导致了次优化问题。此外,现阶段深度哈希算法缺乏有效的复杂度评估方法。
针对以上问题,结合增量学习与潜在空间语义保持,提出了自适应高效深度跨模态增量哈希检索算法(adaptive deep incremental hashing,ADIH)。在训练过程中,以增量学习方式,直接训练新类别数据,同时在求解哈希码的过程中保持哈希码的离散化约束条件,使得学习到的哈希码更好地表征多模态数据,并将该算法扩展到任意多个模态的跨模态哈希检索。主要创新点总结如下:
(1)首次提出基于增量学习的跨模态哈希检索方法,以增量学习的方式学习新类别数据的哈希码,同时保持原有训练数据哈希码不变,更加灵活地实现了大规模数据的跨模态哈希检索。
(2)提出将多模态数据的哈希码映射到低维语义空间,保持哈希码之间的语义关系,并提出离散约束保持的跨模态优化算法来求解最优哈希码。
(3)提出基于神经网络神经元更新操作的复杂度分析方法,进一步分析和比较深度哈希算法的时间复杂度和空间复杂度。
1 相关工作
根据训练策略,现阶段的深度跨模态哈希检索算法可以大致分为基于连续松弛的方法和基于离散约束保持的方法。前者的训练速度比离散方法快,但易产生次优化哈希码。后者训练比较耗时,但能求解最优哈希码[3-4]。本文主要聚焦采用深度神经网络进行特征提取的深度跨模态哈希检索算法。
1.1 基于连续松弛的深度跨模态哈希
深度神经网络(deep neural network,DNN)的火热发展,推动了跨模态哈希检索的发展。与传统的基于手工特征的哈希算法相比,基于DNN的哈希算法的表示能力和学习能力更强。DSEH[5]构造Lab-Net和Img-Net到端到端深度模型中,使用Lab-Net来获取样本对之间丰富的语义相关性,然后使用Img-Net从语义级别和哈希码级别学习和更新哈希函数,提高检索准确率。为了充分利用具有丰富语义线索的跨模态数据,TVDB[6]引入了具有长短期记忆单元的基于区域的卷积网络来探索图像区域细节,同时构建文本卷积网络对文本的语义线索进行建模。此外,采用随机批量训练方式,交替求解高质量哈希码和哈希函数。考虑到标签信息的昂贵,SPDQ[7]利用深度神经网络分别构建一个共享子空间和两个私有子空间,其中私有子空间用于捕获各自模态的私有属性,共享子空间用于捕获多模态数据的共享属性,同时嵌入成对信息进行哈希码学习。结合典型性相关分析,康培培等[8]引入两个不同模态的哈希函数,将不同模态空间的样本映射到共同的汉明空间,同时采用图结构保持哈希码的语义判别性。针对现阶段几乎所有的跨模态哈希方法忽略了不同模态之间的异构相关性,降低检索性能的问题,PRDH[9]通过端到端的深度学习框架有效地捕获各种模态之间的内在关系,从而生成紧凑的哈希码。此外,PRDH还引入了额外的去相关约束,增强了每位哈希位的判别能力。TDH[10]引入三元组监督信息来度量查询样本,正样本和负样本之间的语义关系,并采用图正则化和线性判别保持模态内数据和模态间数据的相似性。HXMAN[11]引入注意力机制到深度跨模态哈希检索中,并采用多模态交互门实现图像和文本模态的细粒度交互,更精确地学习不同模态内的局部特征信息,进一步提高检索精度。
1.2 基于离散保持的跨模态哈希
哈希码的离散化约束保持是深度跨模态哈希检索中一项重要的研究点,早期的哈希算法采用sign符号函数或松弛策略,将离散的哈希码连续化,这类操作容易造成哈希码的次优化。对此,有学者提出了哈希码离散约束保持的跨模态哈希检索算法。SPDH[12]通过构建公共潜在子空间结构,对齐配对和未配对的样本并在子空间中构建跨视图相似图,有效地保留潜在子空间中未配对数据的相似性,从而实现跨模态哈希检索。为了获得最优的哈希码,SPDH采用基于分解的方法,逐位求解哈希码。为了保持离散优化方法的检索精度,同时减少离散方法的训练时间,DLFH[4]嵌入离散隐因子模块,直接学习离散哈希码,同时证明了该算法能够收敛并具有较低的时间复杂度。考虑到简单的相似度矩阵可能会丢失有用信息,SRDMH[13]将完整的标签信息合并到哈希函数学习中,保留原始空间中的相似性,并且提出非线性核嵌入损失,使得哈希码离散求解迭代更加灵活和容易。ALECH[14]指出,大多数现有方法主要在共享汉明子空间中保持跨模态语义相似性,并未充分挖掘多标签语义的标签信息和潜在相关性。对此,该算法自适应地利用高阶语义标签相关性来指导潜在特征学习,利用非对称策略连接潜在特征空间和汉明空间,并保留成对的语义相似性,同时以离散方式生成二进制哈希码。
考虑到深度神经网络在跨模态哈希检索中的优势,也有学者在保持哈希码离散约束的基础上,引入DNN实现高精度的跨模态哈希检索。考虑到最大似然学习的多模态受限玻尔兹曼机模型优势,DBRC[15]在保持模态间和模态内一致性的基础上,引入自适应Tanh激活函数,对网络输出的实值执行阈值策略,同时自适应地学习二进制哈希码并通过反向传播进行训练,从而学习到最优的哈希码。DCMH[16]是经典的深度跨模态哈希检索算法,该算法引入深度神经网络和全连接网络到跨模态哈希检索中,利用标签信息构造相似性矩阵,通过最大化负似然函数来保持跨模数据之间的语义相似性。此外,该算法采用离散循环坐标梯度方法获取最优哈希码。类似地,DCMH[17]在不松弛离散哈希码的前提下,利用语义相似性和二进制哈希码重建,实现分类的数据特征,同时DCMH[17]交替更新每种模态的二进制代码,逐位优化哈希码。为了克服线性投影和哈希码松弛方案无法捕获样本之间的非线性关系,DDCMH[18]定义相似度保持项,为每一位哈希位添加“位独立”和“二进制离散”约束,并充分考虑深度网络的每个隐藏层模态内相似性,使得交叉相关性能够被有效编码。
从上述讨论中可以看出,几乎所有的哈希算法没有考虑检索训练数据类别以外的数据,并且上述深度跨模态哈希算法大多采用连续松弛方式或近似离散变量的方式来解决优化哈希函数的NP难问题。同时,缺乏对深度哈希方法的复杂度评估。针对这些问题,提出自适应高效跨模态增量哈希检索算法,以增量学习方式保持训练数据的哈希码不变,直接学习新类别数据的哈希码,并将其扩展到任意多模态数据的跨模态哈希检索,进一步实现大规模数据跨模态检索。训练过程中,将哈希码映射到潜在子空间中保持多模态数据之间的相似性和非相似性,并提出离散约束保持的跨模态优化算法来求解最优哈希码。最后,提出基于神经网络神经元更新操作的复杂度分析方法,分析和比较深度哈希算法的时间复杂度和空间复杂度。
2 所提算法
2.1 符号和问题定义
加粗斜体显示的字符(如X)表示矩阵,斜体字符(如X)表示变量。对于给定图像数据集和文本数据集数据集中每一对数据都与L=类的标签关联。所提算法的第1个目标是学习图像哈希函数f(·)和文本哈希函数g(·),分别将X和Y模态原始数据映射为二进制哈希码和所提算法的第2个目标是保持原始数据集中的哈希码HX和HY不变,将新类别数据X'=
训练过程中,利用深度神经网络f(·)和g(·)分别构建图像和文本哈希函数,其参数分别为θx和θy。编码过程中,将多模数据的哈希码嵌入低维空间中,利用监督信息S与关联矩阵W保持哈希码之间的相似性。根据标签信息,可以构造对应的相似度矩阵S,表示为Sij∈{-1,+1}(m+n)×k,其中,S的前m行表示原始数据集与查询数据集的相似度,S的后n行表示新增数据集与查询数据集的相似度。
2.2 跨模态哈希检索算法
假设多模数据的哈希码之间存在共同的潜在语义空间V,并在V空间中能够对多模数据进行编码和查询[19-20]。将哈希码映射到V中,表示为:

在V空间中,根据对应的映射关系计算样本之间相似性,即:
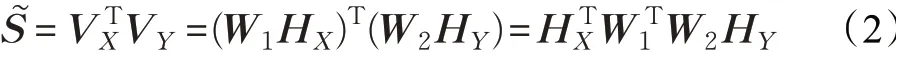
其中,H表示哈希码,并记W=WT1W2。可以看出,只需计算出该转换矩阵W便能度量多模数据哈希码之间的相似性,并不需要具体求解出多模数据在V空间中具体表示。同时,为了保持哈希码的位平衡,所提算法也引入DCMH[15]中的位平衡项,目标函数可以表示为:

其中,F∈Rm×k和G∈Rm×k分别表示原始数据在f(·)和g(·)的输出,并有F*i=f(xi,θx),G*j=g(yj,θy)。m和k分别表示样本数量和哈希码长度,α和β表示权重系数。式(3)中的第1项用于保持哈希码在潜在空间中的语义相似度,第2项将两个模态数据分别投影到各自汉明空间,最后1项是位平衡项,使得哈希码中-1和+1的数量大致相同。
2.3 跨模态哈希检索离散约束保持优化算法
为了简化哈希码求解过程,许多算法将离散型变量直接松弛为连续型变量,然后通过符号函数获得近似的哈希码,这种松弛操作导致学习到的哈希码不能充分地表示多模态数据。因此,所提算法在优化过程中,不直接连续化哈希码,始终保持哈希码的离散化二值约束,保证哈希码为最优哈希码。
不难证明式(3)是一个非凸函数,在求解目标函数时采用交叉迭代的方式,依次交替更新网络f(·),g(·)及交替迭代W,HX和HY,直至目标函数收敛。具体步骤如下:
(1)更新网络f(·)及参数θx,固定剩余变量:
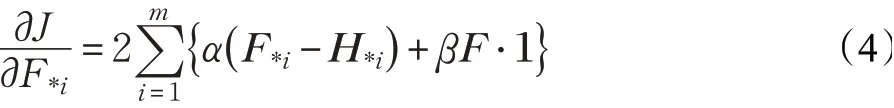
(2)更新网络g(·)及参数θy,固定剩余变量:

(3)求解W,固定剩余变量。此时,目标函数可以简化为:

式
(6)是一个双线性回归函数,其解析解为:
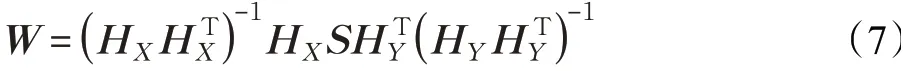
(4)求解HX,固定剩余变量。此时,目标函数可以简化为:

如前所述,由于哈希码的离散化条件约束,直接求解式(8)极难。为保证检索精度,不采用松弛策略,而是对变量HX逐行求解,即,每次迭代过程中,仅求解HX中的某一行向量,并固定该变量中剩余的行向量,然后依次迭代求解HX中的其他行向量。式(8)展开为:


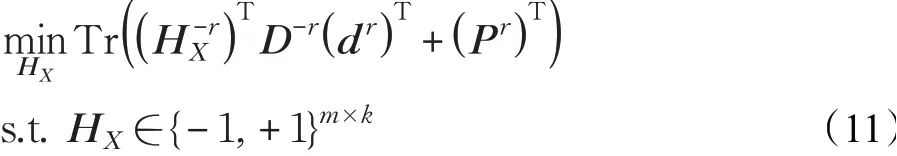
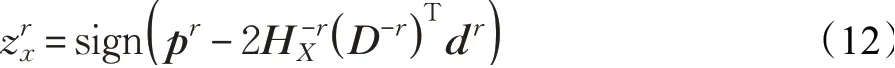
根据式(12)可以求解HX的第r行向量,然后依次求解HX剩余的其他行向量。
(5)固定其他变量,求解HY。采用类似于式(9)~(13)的方式可求解HY中的每一行向量,即:

采用式(4)~(13)进行交替训练和迭代,在保持哈希码的离散化约束条件下,能获得最优的哈希码和哈希函数。
获得了最优哈希函数后,将所有样本映射为二进制哈希码,然后再计算待检索样本(即,查询样本)与数据库中样本的汉明距离,最后对汉明距离进行升序排序,就能够在线性时间内检索出想要的样本。跨模态哈希检索学习算法的训练过程如算法1所示。
算法1跨模态哈希检索学习算法
输入:原始数据集X和Y,相似度矩阵S;哈希码长度k;迭代参数T。
输出:原始数据集哈希码HX和HY,深度神经网络f(·)和g(·),参数分别为θx和θy;关联矩阵W。
初始化:初始化哈希码HX0和HY0;初始化深度神经网络参数θx0和θy0;

2.4 增量哈希检索算法
为了更好地检索训练数据类别以外的数据,提出增量哈希检索算法,保持原始数据的哈希码不变,使学习到的哈希函数始终可用。对此,提出增量哈希保持新增数据与原始数据之间以及与查询数据之间的相似性,采用F范数形式最小化二进制哈希码的内积与相似度之间的关系,表示为:其中,Sij表示新增数据之间的相似度,λ和μ表示权重系数。K为对角矩阵,其主对角线的元素为哈希码长度。F'∈Rn×k和G′∈Rn×k表示新增数据在f(·)和g(·)的输出,有F'*i=f(x'

i,θx),G'*j=g(y'j,θy)。式(14)中的第1项(第2项)用于保持查询数据与原始图像(文本)数据及新增图像(文本)数据的相似性。式(14)中的第3项则将两个模态的数据分别投影到各自汉明空间中,最小化学习到的哈希码与深度神经网络输出的差异,式(14)中的第4项是位平衡项。
2.5 增量哈希检索离散约束保持优化
与上述的跨模态哈希检索离散约束保持优化算法相似,通过交替训练更新f(·)和g(·),便能求解增量数据的哈希码HX'和HY'。具体步骤如下:
(1)更新网络f及参数θx,固定剩余变量:
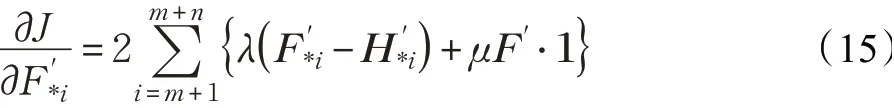
(2)更新网络g及参数θy,固定剩余变量:
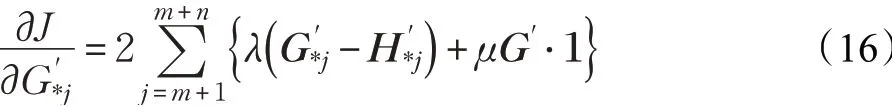
(3)求解HX',固定剩余变量。增量哈希算法保持原始数据哈希码不变,仅学习新增数据的哈希码。当其他变量固定时,目标函数可以简化为:
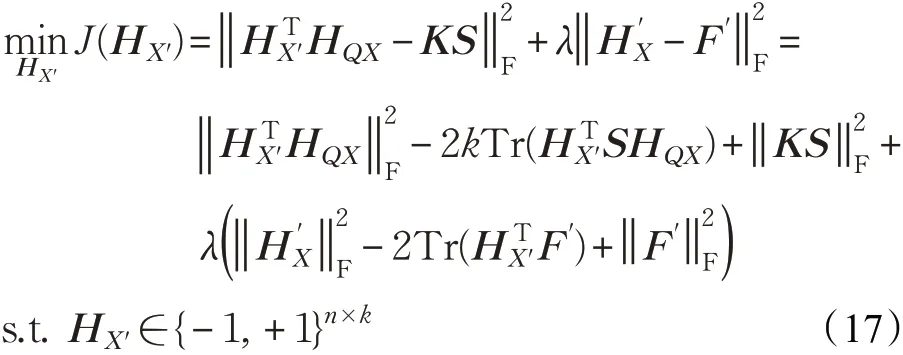
除去式(17)中的常数项及与HX'优化无关的变量,该式可以进一步简化为:
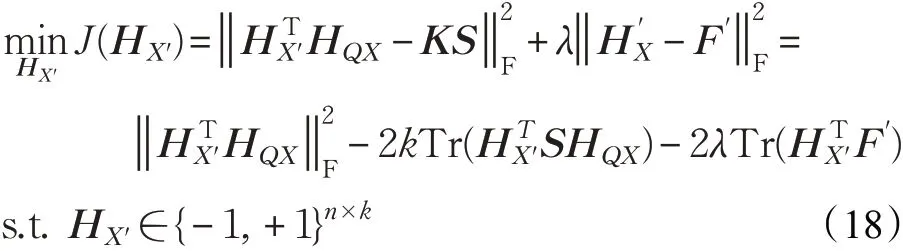
类似地,为保证检索精度,不采用松弛策略,而是采用上述的离散约束保持优化算法对HX'逐行求解。令P=-2KHQX ST-2λF',式(18)可以表示为:
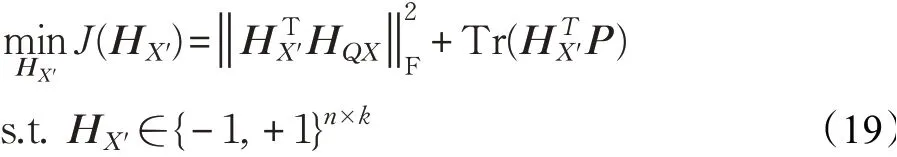
采用与式(10)相同的优化过程,在保持离散化约束下可以得到:
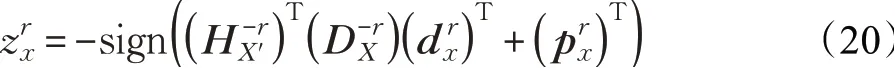
同理,根据式(20)依次求解剩余的行向量。
(4)固定其他变量,求解HY'。采用类似于式(17)~(20)的方式求解HY',即:
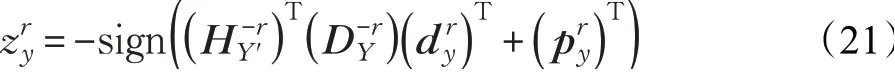
增量哈希检索算法的训练过程如算法2所示。
算法2增量哈希检索学习算法
输入:新增数据集X'和Y',相似度矩阵S;哈希码长度k;迭代参数T;深度神经网络f(·)和g(·)。
输出:新增数据集哈希码HX'和HY',更新后的深度神经网络f'(·)和g'(·)。
过程:
1.利用算法1输出原始数据集哈希码HX和HY;
2.从原始数据集和新增数据集中采样查询数据,并利用算法1输出查询样本的哈希码HQX;
3.Foriter=1 toTdo:
4. 根据式(15)、(16)更新网络参数θx和θy;
5. 根据式(17)~(21),逐行更新哈希码,最终求解HX'和HY';
6.End for
2.6 算法复杂度分析
所提算法属于深度学习算法,不同于传统数值计算或机器学习的算法,仅以迭代次数[18]为基本操作分析复杂度,结果可能过于宽泛[21]。对此,结合迭代次数[21]和深度神经网络神经元更新[22-23]来分析复杂度。跨模态哈希检索算法的时间复杂度主要由更新网络参数和计算变量组成,训练阶段每次迭代的时间消耗主要在更新哈希网络,计算关联矩阵及对应的哈希编码矩阵,可分别由式(4)、(5)、(7)、(12)和(13)求出。同理,增量哈希哈希检索算法的时间复杂度可由式(15)、(16)、(20)和(21)求出。
令M和K分别表示特征向量和卷积核的尺寸,D和C分别表示深度哈希网络的层数和通道数量。d、k、m和n分别表示数据的深度特征维度、哈希码的长度以及原始数据和增量数据的样本数量。
式(4)、(5)和(7)对 应 的 时 间 复 杂 度 分 别 为式(12)和(13)的时间复杂度均为O( )
dk2m。因此,可以估计跨模态哈希检索算法时间复杂度为:
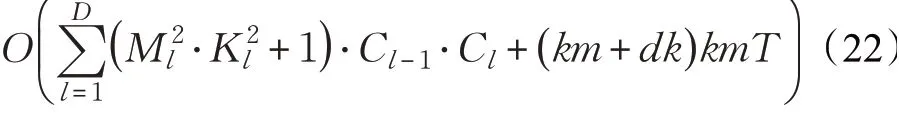
所提算法的空间复杂度主要由深度哈希网络的参数产生,以哈希网络中的一个参数更新为基本操作,可以估计所提算法的空间复杂度为:
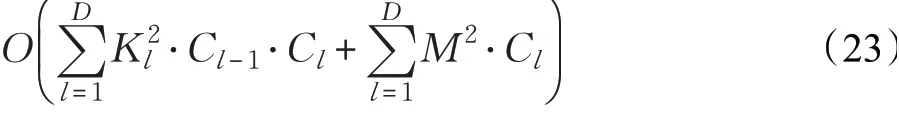
同理,可以估计增量哈希检索算法的时间复杂度为:
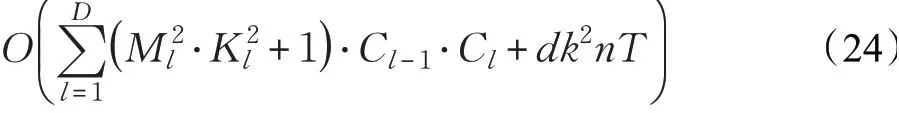
增量哈希检索算法的空间复杂度为:
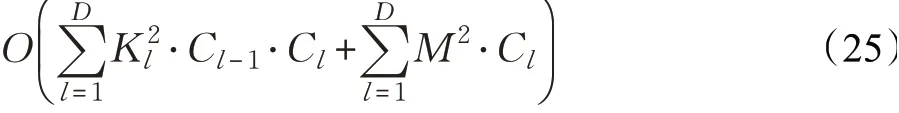
式(23)~(25)中的M、K、D和C与式(22)中对应的符号具有相同的含义。算法1和算法2训练结束后,生成查询样本哈希码的时间复杂度和空间复杂度都为O(dk)。检索是一个异或操作,时间复杂度和空间复杂度都为O(1)。
2.7 算法扩展
跨模态增量哈希检索算法能够自适应地检索3种及3种以上的模态数据,假设有a(a>2)种模态数据,深度跨模态哈希检索模型的目标函数可以表示为:
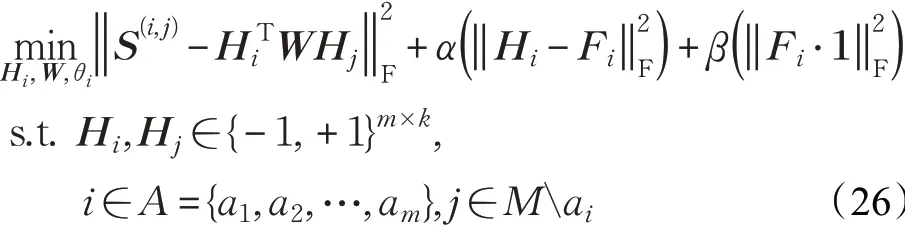
对应的深度跨模态增量哈希检索算法目标函数可以表示为:
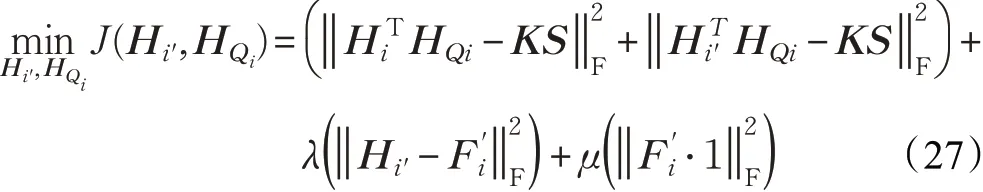
式(26)和(27)中的各项分别与式(3)和式(14)中各项具有相同的物理意义,并且a个模态数据的哈希检索模型的优化、哈希码生成、查询及检索过程与2个模态数据检索场景类似。
3 实验结果分析
为了验证所提算法的有效性,选择2个跨模态数据集(NUS-WIDE和MIRFlickr)和1个4模态医学数据集(Brain)进行仿真。实验使用Python 3.7编译语言,模型建立在“四核Intel®CoreTMi-76850K CPU@3.6 GHz”处理器和“NVIDIA GeForce RTX 3070”的硬件环境基础上。
3.1 数据集设置与对比算法
NUS-WIDE数据集是一个多标签数据集,包含269 648张图像和对应的标注。由于样本类别不平衡,参考前期算法[9]筛选出样本较多的前21类,最终组成186 577个文本-图像对。然后,随机选择5 000个样本作为训练集,选择1%的数据(约1 866)作为测试集,剩余作为查询数据集。
MIRFlickr数据集是一个包含25 000张图像和人工标注文本信息的多标签数据集,一共23类图像。为比较方便,采用文献[7]使用的数据比例划分,即,10 000条样本作为训练集,5 000条样本作为测试集,剩余样本作为查询数据集。
Brain数据集(http://www.med.harvard.edu/AANLIB/)是一个包含脑部PET、MRI和CT多模态医学图像数据,共11类图像。为方便实验对比,选择成对的CT、T1-w、T2-w和PET图像进行实验,每种模态包含6 014张图像。由于Brain数据集数据量有限,所有实验重复3次后取平均值。
为评估增量哈希的有效性,将训练数据分为原始数据集和增量数据集,每个数据集包含4种拆分设置,拆分比例如表1所示。为体现增量哈希的优越性,还设置了增量数据集类别数量大于原始数据集类别数量的比例,即,NUS-WIDE为11/10,MIRFlickr为12/11以 及Brain为6/5。
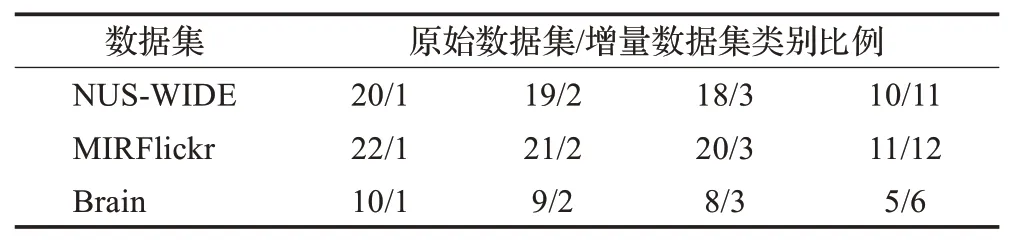
表1 原始数据集和增量数据集划分设置Table 1 Split setting of original and incremental datasets
对比实验选择6种基于深度特征的跨模态哈希算法进行,包括:TVDB[5]、SPDQ[6]、PRDH[8]、TDH[9]、DCMH[15]和DBRC[16]。所有对比算法按照原文提供的参数和源代码进行仿真,使用MAP值(mean average precision,MAP)和准确率-召回率曲线图(precision-recall,PR)进行对比。
3.2 图像-文本跨模态检索实验结果
图像和文本的跨模态检索任务包括图像检索文本(img to txt)和文本检索图像(txt to img)两种任务,前者以图像为查询样本,以文本为检索样本,后者则相反。对比算法和所提算法在NUS-WIDE和MIRFlickr增量数据集上的跨模态检索结果如表2~5所示。其中,所提算法为ADIHi,i表示新增数据的类别数量。对比算法的增量数据类别均设置为2。
表2~5显示,当i=2或i=3时,在NUS-WIDE和MIRFlickr增量数据集上,所提算法无论是利用图像检索文本还是文本检索图像,均取得了最高的检索精度,并且远高于对比算法。对于正常的增量设定,增量数据集类别数小于原始数据集的类别,即,i=1,2,3,增量哈希算法都能获得较高的检索精度。当增量数据集类别数量大于原始数据集类别数量时,检索精度低于正常增量设定下的检索精度,但也高于对比算法。

表3 NUS-WIDE增量数据集上文本检索图像的MAP值Table 3 MAP evaluation of txt to img on increment NUS-WIDE
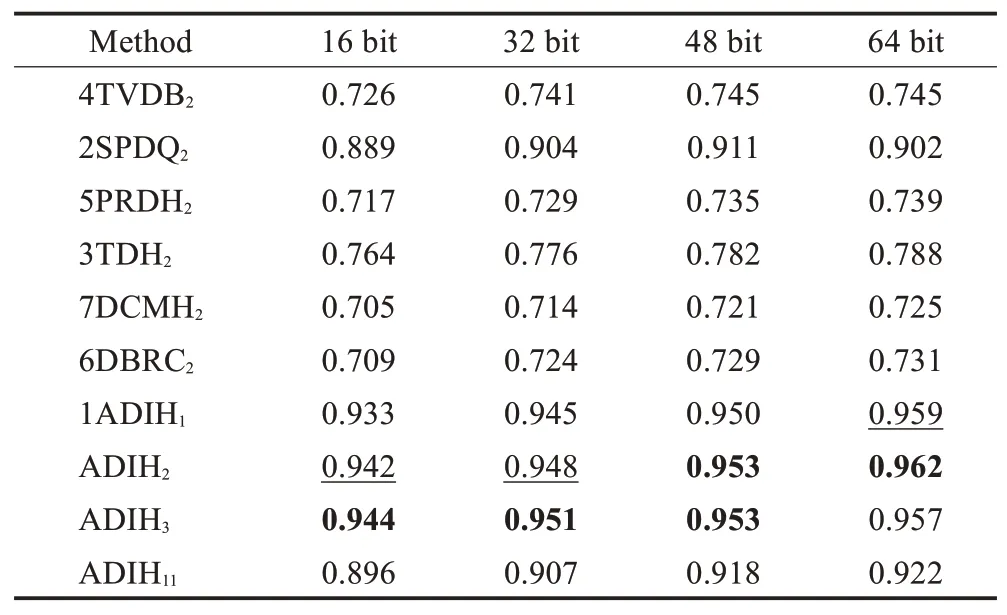
表4 MIRFlickr增量数据集上图像检索文本的MAP值Table 4 MAP evaluation of img to txt on increment MIRFlickr
3.3 四种模态检索实验结果
3.2节评估了所提算法和对比算法在图像和两种模态数据的跨模态检索结果,如2.7节所述,所提算法能够扩展到任意多种模态数据的跨模态检索。基于深度学习的对比算法[6,9,16]也表明能够扩展到多种模态的检索任务,但并没有具体的对比结果。对此,在Brain多模态医学图像数据集上进行实验,比较多种模态图像的跨模态哈希检索性能。
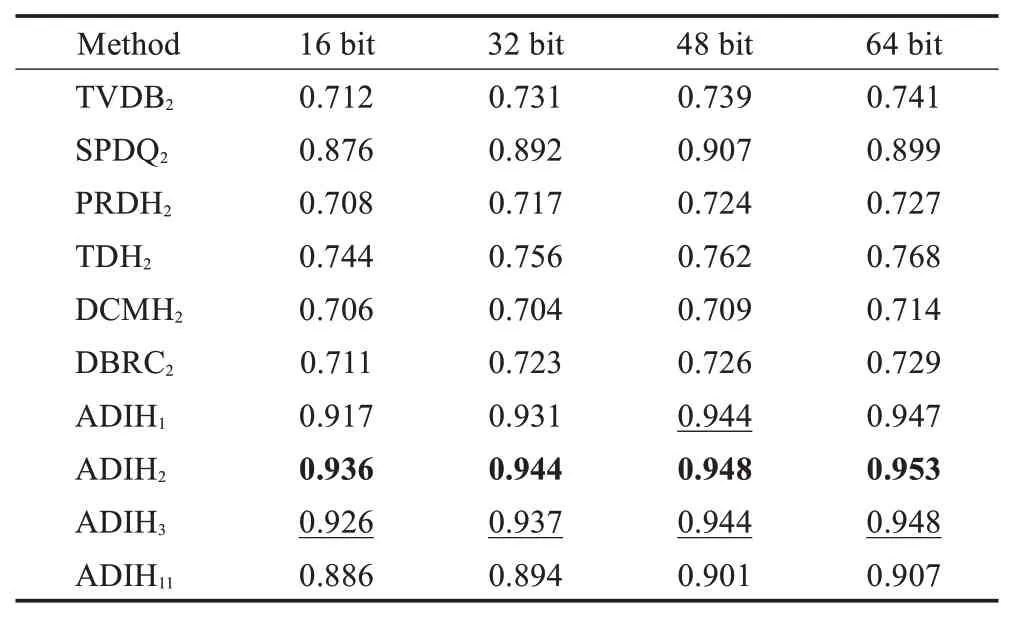
表5 MIRFlickr增量数据集上文本检索图像的MAP值Table 5 MAP evaluation of txt to img on increment MIRFlickr
由于Brain数据集模态数量较多,并且实验重复多次。因此,实验过程中采用均值和标准差形式来刻画准确率与召回率曲线。以CT作为查询图像为例,对应准确率和召回率包含3个值,即,CT to T1-w、CT to 2-w和CT to PET,最后平均所有值,得到平均PR值。考虑到增量数据集类别数为2时,检索效果最好,因此训练对比算法时设置类别数为2。哈希码长度k=16。实验结果如图1所示。
图1显示,在Brain多模态医学图像数据集上,所提算法的检索精度高于其他深度哈希算法。当增量数据集类别数量大于原始数据集类别数量时,检索精度低于正常增量设定下(即,i=1,2,3)的检索精度,这与上节实验结果一致。
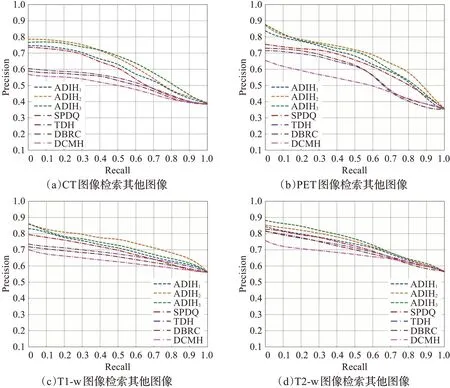
图1 Brain数据集的准确率与召回率曲线Fig.1 Precision-recall curves on Brain datasets
3.4 时间复杂度实验结果
采用相同的卷积神经网络时,即,M、D、C和K相同,由式(21)与式(23)可以得出跨模态检索算法的时间复杂度为O( (km+dk)km),增量跨模态检索算法的时间复杂度为O(dk2n)。由于d和k远小于m,因此这两种算法的复杂度可以进一步估计为O(m2)和O(n)。采用2.6节提出的复杂度分析方法,可以得出传统的深度哈希方法复杂度为O(m2),采用triplet损失函数的深度哈希方法[9]时间复杂度为O()m3。与之相比,所提算法时间复杂度低于对比算法时间复杂度。NUS-WIDE数据集上训练时间结果如表6所示。
表6显示,所提算法在训练时间方面具有明显的优势,对于训练数据类别以外的数据不需要重新训练模型,有效地降低了训练时间和训练成本。此外,在MIRFlickr和Brain数据集上也取得了相似的结果。
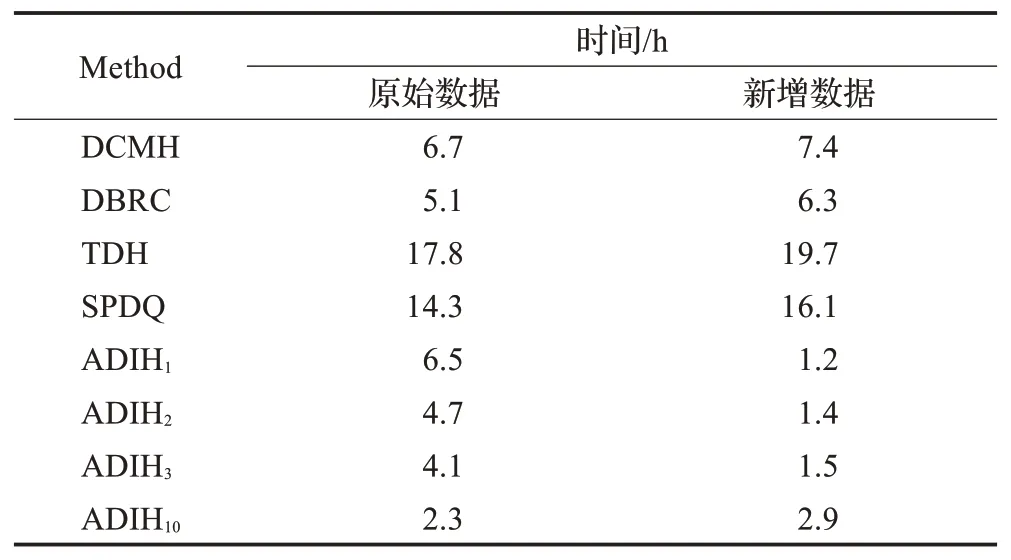
表6 NUS-WIDE数据集的训练时间结果对比Table 6 Training time comparisons on NUS-WIDE
3.5 消融实验结果
与前期的哈希算法相比,所提算法在检索精度和训练耗时两方面具有明显的优势,这主要得益于增量哈希方法和离散化约束保持。对此,本节讨论所提算法的几种变体模型,进一步分析这两项在检索精度方面的贡献。ADIH-I是没有使用增量哈希的ADIH变体,ADIH+R是直接使用连续化松弛的ADIH变体,ADIH-B是没有使用位平衡项的ADIH变体。NUS-WIDE数据集上的对比结果如表7所示,其中,增量数据的类别数量为2。
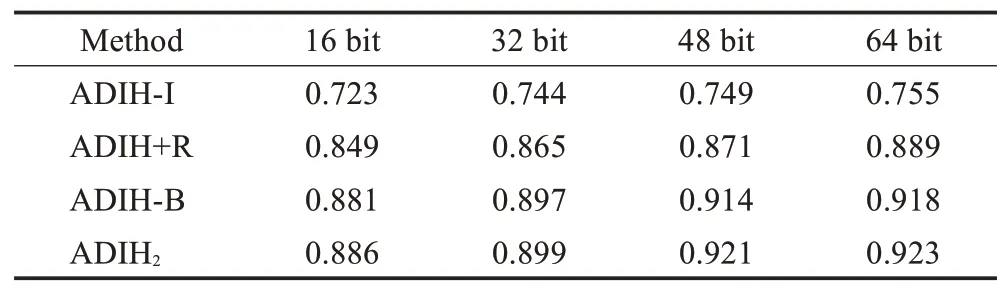
表7 NUS-WIDE数据集的变体实验结果对比Table 7 MAP comparisons of variants on NUS-WIDE
表7显示,ADIH算法获得的高精度检索结果主要得益于增量学习。对比没有使用增量学习的变体ADIH-I,所提算法在不同哈希位的检索精度提高了约22.5%、20.8%、23.0%和22.3%,这证明了增量哈希的有效性。对比没有使用离散化约束保持的变体ADIH-B,所提算法在不同哈希位的检索精度提高了约4.4%、3.9%、5.7%和3.8%,说明了提出的离散化优化方法一定程度上也提高了检索精度。
表2~5显示,在增量检索场景中,所提算法均取得了最高的检索精度,并且远高于对比算法。为了进一步探索增量哈希学习的优势,将增量学习引入到对比算法中,在MIRFlickr增量数据集上进行对比,实验结果如表8、9所示。
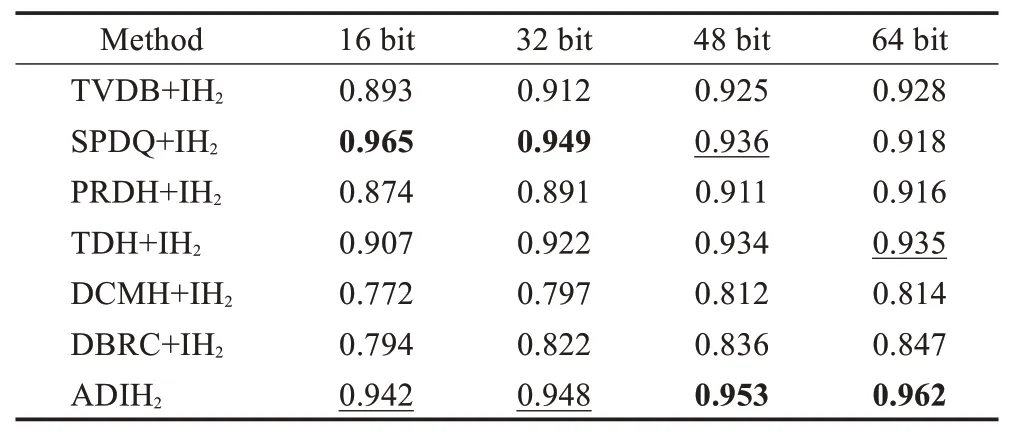
表8 MIRFlickr增量数据集上图像检索文本的MAP值Table 8 MAP evaluation of img to txt on MIRFlickr
表8、9表明,增量哈希检索的确能够提高当前跨模态检索算法的检索性能。采用增量学习方式训练对比算法,其检索结果能得到有效的提升,部分检索结果(如:16 bit和32 bit时,SPDQ方法的检索结果)甚至超过了本文所提算法的检索结果。
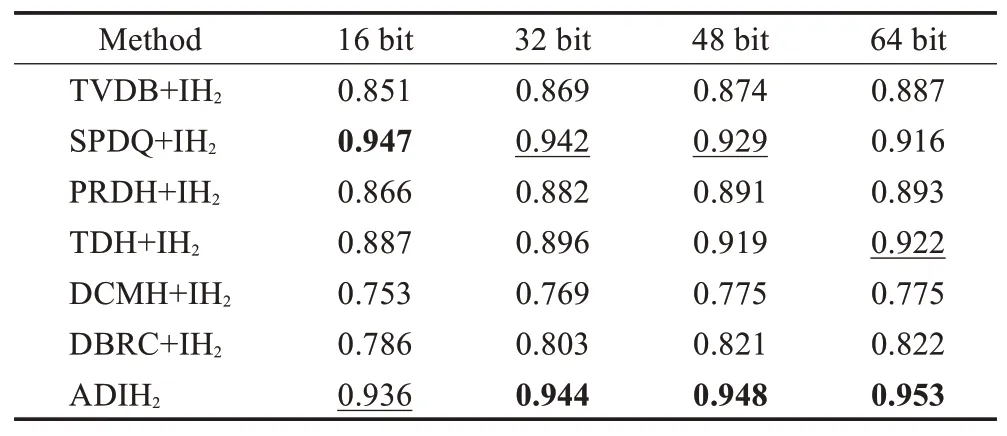
表9 MIRFlickr增量数据集上文本检索图像的MAP值Table 9 MAP evaluation of txt to img on MIRFlickr
4 结束语
针对现阶段跨模态哈希检索算法无法较好地检索训练数据类别以外的数据以及离散化哈希码造成的次优化问题,提出自适应高效深度跨模态增量哈希检索算法,以增量学习方式保持训练数据的哈希码不变,直接学习新类别数据的哈希码。训练过程中,将哈希码映射到潜在子空间中保持多模态数据之间的相似性和非相似性,并提出离散约束保持的跨模态优化算法来求解最优哈希码。最后,基于神经网络神经元更新操作分析和比较深度哈希算法的复杂度。下一步将研究多源数据(如:音频、视频和3D图形)的跨模态检索。
猜你喜欢
当代陕西(2022年6期)2022-04-19 12:12:22
中学生数理化·中考版(2019年9期)2019-11-25 09:39:44
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
电信科学(2016年9期)2016-06-15 20:27:25
工业设计(2016年8期)2016-04-16 02:43:34
火控雷达技术(2016年3期)2016-02-06 02:30:28
计算机工程(2015年8期)2015-07-03 12:20:04
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01 02:54:43
电子设计工程(2015年16期)2015-02-27 12:07:58
