
基于多任务学习的跨语言信息检索方法研究
2023-01-19 04:04代佳洋
广西师范大学学报(自然科学版) 2022年6期
代佳洋,周 栋
(湖南科技大学 计算机科学与工程学院,湖南 湘潭 411201)
随着互联网的发展与全球化进程的推进,信息数量飞速增加,用户在非母语条件下进行检索的需求也逐渐提高。如何使用户便捷高效地获取其他语种的信息成为研究的热点[1]。借助跨语言信息检索(cross-language information retrieval, CLIR)技术,用户可以使用母语直接检索多种其他语言的信息,因而跨语言检索技术的研究有重要的现实意义。
传统的信息检索通常通过简单的关键字匹配,或是依赖人工编制特征进行检索[2-3]。前者效果较差,后者过程复杂且成本高昂。近些年,深度神经网络技术的突破使得神经检索模型在单语言信息检索领域获得了巨大的成功。例如,Pang等[4]提出MatchPyramid模型,将查询和文档交互构成一张“图”,使用多层卷积提取查询和文本的交互信息进行检索。Xiong等[5]提出KNRM模型,首先生成查询和文档的交互矩阵,然后通过不同均值的高斯核提取交互矩阵上不同级别的余弦相似度,最后汇总相似度信息进行检索。相比人工编制特征的传统方法,深度神经网络能自动提取数据特征,一方面降低了特征提取的难度,另一方面能获取人工难以提取的复杂特征[6]。
神经检索模型在单语言检索任务中取得的成功,使得一些学者开始关注其在跨语言检索领域的潜力[7-8]。例如,Yu等[7]尝试在跨语言词嵌入(cross-language word embedding, CLWE)空间中使用现有的神经检索模型执行CLIR任务,其实验结果表明,现有的神经检索模型可以不经修改,直接在CLWE空间中工作。CLWE通过将不同的语言映射到同一个向量空间中实现[9]。Bonab等[8]认为不同语种间词的不一致影响了神经检索模型在跨语言嵌入空间下的性能,因而提出一种称为Smart Shuffling的跨语言嵌入方法,以生成更高效的跨语言嵌入空间,实验结果表明,经弥合后的跨语言嵌入明显提升了神经检索模型的效果。
相关研究表明,神经检索模型的性能与文本特征提取的效果有关[10]。目前,在跨语言条件下使用神经检索模型的相关研究大多使用单任务学习,这导致模型提取的文本特征较为单一。另外,在跨语言条件下,不同语言在语法、单词等方面的差异进一步加大了文本特征提取的难度[11]。以上原因限制了神经检索模型在跨语言检索任务中的运用。
不同任务的特征提取模式、噪声形式等通常是不同的[12],通过多任务学习可以使模型获得层次更丰富、噪声更低、泛化性更强的特征,从而提升模型性能。例如,Liu等[13]构建了一个多任务神经网络,同时执行文本分类和信息检索的特征提取,然后利用提取出的文本特征进行检索,实验结果表明,多任务学习能明显增强模型的特征提取能力,从而增强检索效果。
本文提出一个结合文本分类任务与跨语言检索任务的多任务学习方法,并使用外部语料库进一步提升文本特征的丰富度。具体来说,该方法将外部语料、查询和文档通过预训练的跨语言词向量模型转换为词向量,然后将其输入到一个基于双向门控循环(bidirectional gated recurrent units, Bi-GRU)网络的文本分类模型中以提取文本特征,其中,外部语料的文本特征用于执行文本分类任务,而查询和文档的文本特征被输入到神经检索模型中用于执行跨语言检索任务。本文的主要贡献如下:
1)提出一个基于多任务学习的跨语言信息检索方法,并在CLEF 2000-2003数据集的4个语言对上进行实验,证明方法的有效性。
2)研究文本分类任务对神经匹配检索模型的辅助机制,为在CLIR模型中使用多任务学习提供一定的参考。
3)研究外部语料库对于CLIR任务的促进作用。
1 相关工作
跨语言信息检索的任务流程通常分为3步[14]:统一查询和文档的语种、提取文本特征、执行检索。根据统一查询和文档语种方法的不同,CLIR模型通常可以分为:基于翻译的CLIR模型[15-20]和基于语义的CLIR模型[7,8,21-27]。
1.1 基于翻译的CLIR模型
基于翻译的CLIR模型是目前最主流的CLIR模型[28-29],其通过对查询或文档进行翻译以进行语种统一。早期往往使用人工翻译、词典等手段,近些年,由于机器翻译领域的突破,基于翻译的CLIR模型已经逐渐转向使用机器翻译。
例如,Elayeb等[15]提出一个结合词典和机器翻译的CLIR模型,首先借助外部词典对查询中的实体词进行精确翻译,然后利用翻译后的实体词,辅助机器翻译模型对查询进行翻译。相比仅使用机器翻译,该模型的翻译精度更高,检索效果更好。黄名选等[16]提出一种结合查询扩展和查询翻译的CLIR方法,该方法使用剪枝策略挖掘加权关联规则,然后根据规则提取高质量扩展词对查询进行扩展,再翻译扩展后的查询用于CLIR任务。Ture等[17]构建一个用于CLIR任务的分层翻译系统,将翻译任务分为短语、语法、语义3个层级,然后整合3个层级的翻译结果,相比直接翻译整个句子,这个立体翻译模型输出的翻译更适用于CLIR任务。Azarbonyad等[18]提出一种通过LTR(learn to ranking)技术同时使用多个翻译资源的方法,该方法使用多个独立的翻译资源对查询进行翻译,然后通过LTR选取数个最优的翻译并将其组合以获取最终翻译结果,结果表明,LTR可成功地组合不同翻译资源以提高CLIR性能。梁少博等[19]通过抽取双语数据集中的命名实体构建双语词典,并使用提问式翻译策略实现查询和文档的统一。Chandra等[20]建立一个双向翻译系统来执行CLIR任务,这个双向翻译系统将文本翻译之后再反向翻译回原来的语种,通过反向翻译的结果对翻译系统的效果进行评估以改善其质量,结果表明,反向翻译提升了翻译的质量,从而改善了CLIR任务的表现。
1.2 基于语义的CLIR模型
基于翻译的CLIR模型的准确性依赖于翻译的准确性[30],但不同语种间的词汇通常难以完全匹配,翻译模型的性能会因词汇不匹配导致的翻译错误而受损[7],影响检索效果。而基于语义的CLIR模型在应对词汇不匹配的问题时效果更好。基于语义的CLIR技术是指通过语义模型,将2种不同的语言在语义上进行统一后再执行IR任务。由于近些年深度学习技术的发展,基于语义的CLIR模型展现出极大的发展潜力。
马路佳等[21]提出一种基于跨语言词向量和查询扩展的CLIR方法,该方法使用跨语言词向量建立汉语查询到蒙古文查询之间的映射,然后使用3种不同的查询扩展方法对翻译后的蒙古文查询进行扩展和筛选,再执行CLIR任务。Litschko等[22]提出一种使用多个单语言语料库进行无监督学习训练CLWE并进行CLIR的方法。具体来说,通过GAN诱导2个单语词向量进行对齐,弥合不同语言间的语义鸿沟以生成CLWE空间,然后通过TbT-QT和BWE-Agg模型完成CLIR任务。TbT-QT利用CLWE将每个查询词翻译成与其最接近的跨语言邻居词,然后使用查询似然模型进行单语言检索。BWE-Agg通过汇总查询和文本的CLWE获得查询和文档嵌入的余弦相似度,再使用相似度对查询和文档进行排名。
Yu等[7]利用CLWE把查询和文档映射到同一个语义空间中,再通过神经匹配模型进行检索,实验结果表明,传统的神经匹配模型能够不经过修改直接在CLWE空间中工作。Bonab等[8]提出一种称为Smart Shuffling的跨语言嵌入方法,该方法通过弥合不同语言间的差异以生成更高质量的跨语言嵌入空间,有效改善神经检索模型在CLIR中的表现。邹小芳等[23]提出借助中间语义空间对平行语料进行建模的方法,实验结果表明,在中间语义空间中对语料进行建模的稳定性较高,检索效果更好。
近些年深度学习领域的突破,使得许多新技术得以在CLIR领域中运用,但其中大部分方法都仅使用单任务学习,导致提取的文本特征较为单一,这限制了神经检索模型在CLIR任务中的效果。因而本文尝试使用多任务学习技术增强文本特征的提取,从而改善神经检索模型在CLIR任务中的表现。
2 框架与方法
首先给出CLIR任务的定义:
q=γquery(qo),
(1)
d=γdoc(do),
(2)
f(q,d)=g(ψ(q),φ(d),η(q,d))。
(3)
式中:qo和do是原始查询和文档;γquery和γdoc是转换查询和文档使其语义统一的模型;q和d是语义统一后的查询和文档;ψ和φ是提取查询和文档特征的函数;η是提取查询和文档交互的函数;g是相关性计算函数,它基于查询和文档的特征以及它们的交互关系来计算两者的相关性得分。在本文方法中:γquery和γdoc是预训练的跨语言词向量模型,通过将查询和文档映射到统一的词嵌入空间中对查询和文档进行建模;ψ和φ是文本分类模型中的Bi-GRU层;η和g是神经检索模型。
图1是本文模型的总体框架,由以下3个部分组成:
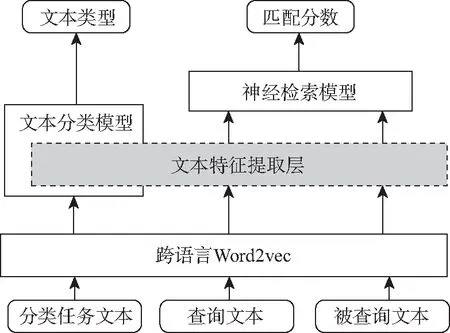
图1 总体框架Fig. 1 Overall framework
1)文本分类模型(辅助任务):该模型通过外部语料进行训练。利用预训练的跨语言词向量模型将外部语料转换为词向量后,通过神经网络提取文档的特征并进行分类。图1中的文本特征提取层本质上是一个Bi-GRU层。整个模型具体结构在2.1节给出。
2)共享的文本特征提取层:本层为文本分类模型的特征提取层,本文通过在CLIR模型中共享该层以进行多任务学习,即CLIR任务的文本特征提取工作由该层完成。查询与文档通过预训练的跨语言词向量模型转换为词向量后,使用该共享特征提取层提取文本特征,供神经检索模型使用。虽然本模型中的跨语言词向量层也是共享的,但是该层是一个固定的词向量层。
3)神经检索模型(主任务):为了验证本文提出的多任务学习方法的可靠性,使用数个不同的基于交互的神经检索模型进行实验,其计算流程基本相同。首先,利用文本分类模型提取的查询和文档特征,计算两者间的交互关系并提取信息;然后,将其输入深度神经网络中执行检索任务;最后,输出查询和文档的匹配分数。
2.1 文本分类模型
在文本分类任务上,本文使用HAN(hierarchical attention network)模型[31],其结构如图2所示。
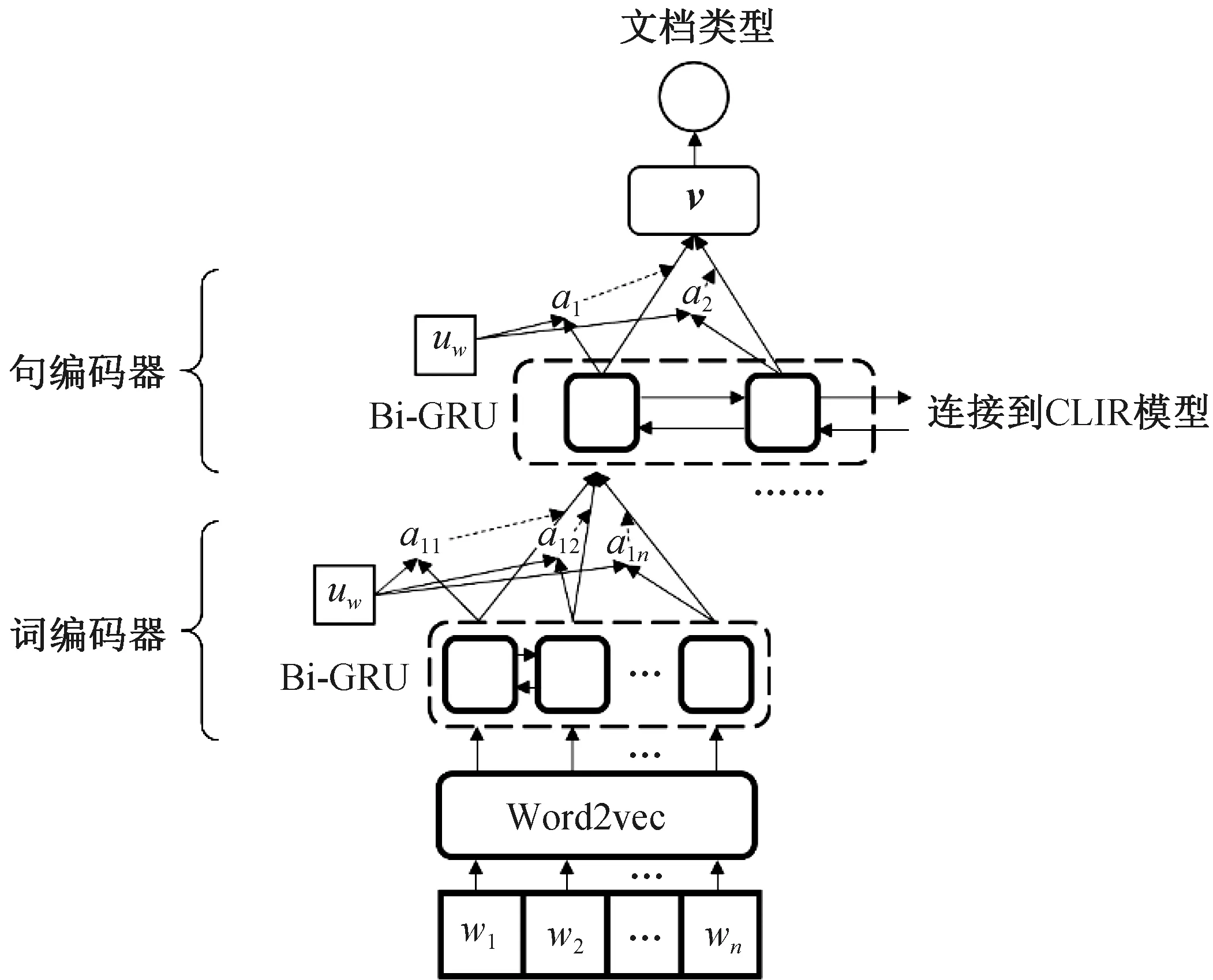
图2 HAN模型Fig. 2 HAN model
HAN是一个双层文本分类模型,第一层为词编码层,通过词编码向量计算每个句子的编码向量;第二层为句子编码层,利用每个句子的编码向量计算出整个文档的编码向量,最后通过文档编码向量预测文档的类别。具体来说,其计算流程如下:
首先,将文档每个句子中每个词转换为词向量,然后再输入到词编码层的Bi-GRU层中,获得每个单词的隐藏向量:
vij=Word2vec(wij),
(4)
sij=Bi-GRU(vij)。
(5)
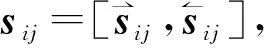
获得每个单词的隐藏状态后,通过注意力层将其整合为句子的编码向量:
uij=tanh(Wwhij+bw),
(6)
(7)
(8)
式中:Ww和bw为待学习参数;uw是一个随机初始化的向量,通过其与uij的点乘来计算对应单词的注意力权重αij;si为句子i的编码向量。
获得所有句子的编码向量后,将其逐个送入句编码层的Bi-GRU层中,获得每个句子的隐藏状态,再通过注意力层进行整合,从而获得整个文档的编码向量:
hi=Bi-GRU(si),
(9)
ui=tanh(Wshi+bs),
(10)
(11)
(12)
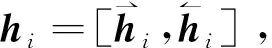
最后利用这个编码向量预测文本分类,y是文本分类任务的输出:
y=Softmax(v)。
(13)
2.2 共享的文本特征提取层
现有的神经检索模型通常利用查询和文档的文本特征来捕捉两者之间的匹配关系以进行检索,其性能与文本特征的提取效果直接相关。在单任务学习的模式下,模型只能学习一个任务的特征模式,导致提取的文本特征较为单一,从而影响对查询与文档之间匹配关系的捕捉。在跨语言环境下,不同语种间的差异进一步增加了捕捉匹配关系的难度。
为此,本文将文本分类任务和CLIR任务结合进行多任务学习,通过使用HAN模型的一个文本特征提取层进行CLIR任务的特征提取,使该层同时学习不同的特征提取模式,从而改善特征提取工作的效果。具体来说,本文使用HAN模型句编码层中的Bi-GRU模型提取文本特征,把查询和文档转换为词向量后直接送入句编码层的Bi-GRU中,不经过词编码层,获得每个词的隐藏状态后也不通过句注意力层整合。这是因为HAN模型的词编码层是独立处理每个句子的,CLIR任务的文本无法进行此处理,如果通过句注意力层整合隐藏向量,将会影响后续交互矩阵的构建。
检索任务特征提取的计算流程如下:
vqi=Wordvecquery(wqi),
(14)
sqi=Bi-GRU(vqi),
(15)
vdj=Wordvecdoc(wdj),
(16)
sdj=Bi-GRU(vdj)。
(17)

当模型进行训练时,该共享特征提取层将接受不同优化目标的训练,从而同时学习文本分类任务和CLIR任务的特征模式和噪声规律,使输出的sqi和sdj含有层次更丰富的文本特征。此外,分类文档的语料内容会沿着Bi-GRU传递,使sqi和sdj一定程度上含有了外部语料的特征信息,这进一步增加了文本特征的丰度。
2.3 神经IR模型
IR模型取得成功的原因主要归功于2点:多层次匹配模式的学习和端到端的词表征学习[7]。因此,本文选择了2种具有代表性的神经IR模型进行实验: MatchPyramid和KNRM。
MatchPyramid(MP)是一个基于交互的神经IR模型,该模型首先在单词级别上进行匹配,通过计算每个查询词和每个文档词的交互,获得一个交互矩阵。然后,将这个交互矩阵当作一张“图”,将检索任务转换为一个“图像”识别任务,对交互“图”进行多层卷积。最后,利用卷积生成的交互向量计算查询与文档的匹配程度。MP能够在短语、句子、段落等不同层级上捕捉查询与文档的匹配关系。
KNRM模型采用查询-文档的交互矩阵表征查询和文档间的交互(类似于MP),但它使用不同均值μ的高斯核将交互“分类”为不同级别的余弦相似度,然后整合不同级别的余弦相似度以计算查询和文档的相似度。KNRM允许梯度穿过高斯内核进行反向传播,因此这个模型支持端到端的词表征学习。
这2个模型的计算流程相似,如图3所示,都是首先提取文本特征,然后根据文本特征构建交互矩阵,再利用神经网络提取交互矩阵捕捉到的交互信息,最后计算查询和文档的相似度。这2个模型的计算流程可以抽象为
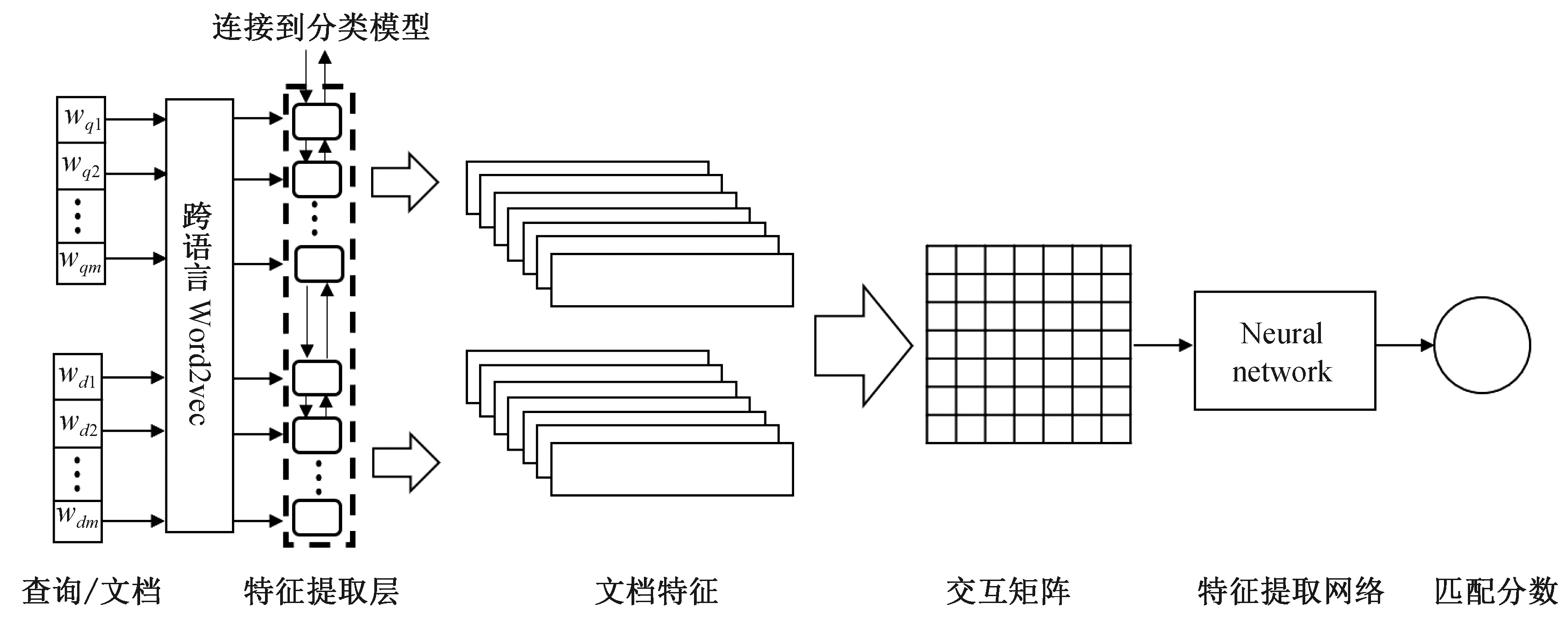
图3 神经检索模型Fig. 3 Neural retrieval model
Sscore=model(sq,sd)。
(18)
式中:
sq=[sq1,sq2,…,sqn];
(19)
sd=[sd1,sd2,…,sdm]。
(20)
sqn和sdm分别为文本特征提取层输出的查询中第n个词的状态向量和文档中第m个词的状态向量。
2.4 损失函数
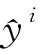
(21)
由于本文选取的数据集使用二元的相关性标记,故对CLIR任务使用Hinge loss,其具体定义为
LΘ(q,d+,d-)=max(0,1-s(q,d+)+s(q,d-))。
(22)
式中:q是查询;文档d+与查询q相关,而文档d-与查询q不相关;s(q,d)表示模型预测(q,d)间的匹配分数;Θ表示神经网络中的可学习参数。
最终,模型的损失函数为
L=LΘ+Lc。
(23)
3 实验
3.1 实验平台
本文实验的硬件平台CPU为AMD Ryzen7 3700X,GPU为NVIDIA RTX 3070;操作系统版本为Windows10 1909;使用的软件为Python 3.6,深度学习框架Pytorch 1.2.0。
3.2 实验设置
3.2.1 数据集
对于CLIR任务,本文使用CLEF 2000-2003数据集进行训练和评估,这个数据集的统计信息如表1所示。查询和文档之间的关系使用0或1进行标记,1为相关,0为不相关。本文共选用4个语言对:EN→FR、EN→ES、EN→DE、EN→RU,前者为查询的语种,后者为文档的语种。为了保证计算效率,将每个查询保留前50个词,每个训练集保留前500个词。所有的查询和文档均转换为小写,且删除了标点符号。

表1 CLEF 2000-2003数据集的基本统计数据Tab. 1 Basic statistics of CLEF 2000-2003 data set
对于文本分类任务,本文使用了XNLI-MT数据集。该数据集是一个多语种自然语言推断数据集,每条数据由一个句子对和一个真实标记构成,模型需要判断出2个句子之间的关系,可能的结果有3种:蕴含、无关、矛盾。使用该数据集的原因是其语种足够丰富,实验结果表明,文本分类模型能够在这个数据集上正常工作。XNLI-MT数据集的每个句子截断到50个词。
本文使用MUSE(multilingual unsupervised and supervised embeddings)对Wiki语料库训练出的单语言词向量进行无监督对齐以获得CLWE。
为了保证实验结果的可靠性,本文采用带有验证和测试集的5折交叉验证:将数据集划分为5组,并进行5轮实验,每轮抽取之前没有抽取过的1组数据作为验证集,1组作为测试集,剩余的3组作为训练集。最终结果取5轮实验的平均值。
3.2.2 对比算法
为了检验本文多任务学习方法对于神经检索模型的提升效果,本文按照Yu等[7]的实验设置,使用工作在跨语言词向量上的神经检索模型KNRM和MP作为对比算法,这2个模型均有一些变体。根据Yu等[7]的实验结果,在CLWE空间中,使用基于余弦相似度的版本效果最好,因而本文使用基于余弦相似度的KNRM、MP模型,并将其分别命名为MP-Cosine、KRNM-Cosine。
另外,为了证明在使用同样跨语言词向量的情况下,本文提出的多任务学习方法能使神经检索模型的性能优于目前的非神经CLIR方法,本文还使用3种基于CLWE的非神经CLIR模型作为对比算法,分别为BWE-Agg-Add、BWE-Agg-IDF和TbT-QT。这几个算法是近几年非神经检索模型的研究成果,均基于跨语言词向量对查询和文档进行统一。
MP-Cosine:该模型基于查询表征和文档表征间的相似度计算其交互,并将全部交互信息构成一张交互图,再通过多层卷积,捕捉查询和文档间多级别的交互信息,最后输出查询和文档的匹配。
KRNM-Cosine:该模型与MP模型类似,采用查询-文档的交互矩阵表征查询和文档间的交互,但它使用不同均值μ的高斯核将交互分为不同级别的余弦相似度,以获得不同级别的交互信息,然后将不同高斯核输出的向量加权,或者最终的向量交互,再通过这个向量计算出查询和文档的相似度。
BWE-Agg-Add:通过汇总查询和文档的CLWE获得查询和文档的表示向量,然后根据查询和文档向量的余弦相似度进行排序,从而获得检索结果。BWE-Agg-Add使用简单计算均值的方法汇总查询和文档的嵌入。
BWE-Agg-IDF:同BWE-Agg-Add,但BWE-Agg-IDF使用单词的TF-IDF进行加权来汇总CLWE,以获得查询和文档嵌入。
TbT-QT:该模型将CLWE作为查询翻译资源,通过CLWE将源语言转换为目标语言中最接近的单词,然后使用查询似然模型进行检索。
3.3 多任务学习模式
对于多任务学习(multi-task learning, MTL),由于CLIR任务输入的语种不同,本文使用2种辅助任务设置:一种是执行英语文本的分类任务,即与查询(Query)的语种一致;另一种是执行其他语种文本的分类任务,即与文档(Doc)语种一致。再根据使用神经检索模型的不同,将其分别命名为MP-MTL-Query、KNRM-MTL-Query、MP-MTL-Doc和KNRM-MTL-Doc。
3.4 超参数设置
对于MP模型,按照原论文的设置使用单层卷积,其内核大小设置为3×3,动态池大小设置为5×1,内核计数设置为64。对于KNRM模型,内核数设置为20,每个高斯内核的标准偏差设置为0.1。
每个正样本采样5个负样本,每次采样随机选择被标记为不相关的文档。在设置batch size为60的条件下,使用随机梯度下降法,设定初始学习率为0.001进行优化,最多训练20个epoch。为了提高训练的效率,本文使用Early Stopping。但为了优先保证CLIR任务的训练质量,Early Stopping根据CLIR任务的损失LΘ进行,而不是总损失函数L。
4 结果与分析
4.1 实验结果
实验结果如表2和表3所示,表2为CLIR任务(主任务)的MAP值,表3为文本分类任务(辅助任务)的精确度。

表2 CLEF任务的MAP值Tab. 2 MAP value of CLEF task

表3 文本分类任务的精确度Tab. 3 Accuracy of text classification tasks
4.2 结果分析
由表2可知,相比直接运行在CLWE空间中的MP和KNRM模型,使用本文提出的多任务学习方法后,除了一组实验的MAP值低于对应的单任务学习实验之外,其余各组实验均有明显提升。其中,提升幅度最大的实验分组为工作在EN→RU语对上的MP-MTL-Query分组,MAP值提高了0.188;而提升幅度最小的是工作在EN→DE语对上的MP-MTL-Doc分组,其MAP值提高了0.012。这表明本文提出的多任务学习方法是有效的。另外,无论是否使用多任务,神经检索模型的效果均优于非神经检索模型。但2种不同的多任务学习方式没有明显的性能区别,即多任务方法的提升效果没有随着辅助任务输入语料的语种变化而发生改变,这表明,外部语料对改善文本特征提取的贡献较小。
相比MP模型,本文的多任务学习方法对KNRM模型的提升更大。经过计算,使用MP模型的多任务学习实验组的总体平均提升为0.066,而使用KNRM模型的多任务实验组的总体平均提升为0.144。如前文所述,KNRM的优势在于其可以端到端地训练词表征。根据文献[5]描述,如果禁止KNRM训练词表征,则其性能会受到较大影响,即高效的词表征能更明显地增强KNRM模型的性能,这证明本文的多任务学习方法改善了文本特征提取的效果。
在4个语言对中,EN→RU语言对的提升最明显。由表1可知,CLEF 2000-2003的俄语数据集仅有37个查询,平均每个查询仅有4.08个正样本,即俄语数据集仅有151个正样本,每轮学习时为5倍负采样,并且使用五折交叉学习,这使得实际参加训练的样本仅有761条,极大地影响了神经检索模型(尤其是KNRM模型)的性能。在引入多任务学习之后,多模式特征的捕捉和外部语料起到了数据增强的作用,从而使得神经检索模型的性能获得了明显提升,表明多任务学习在低资源跨语言检索领域有着巨大潜力。
由表3可知,在使用多任务学习后,HAN模型在文本分类任务上的精度有所下降,这可能是因为CLIR任务的文本特征干扰了文本分类任务的执行,也可能是因为模型训练时的Early Stopping以CLIR任务的损失为计算标准,导致HAN模型欠拟合或过拟合。
4.3 多任务学习的提升机制研究
本节绘制各个神经检索模型在测试阶段的epoch-MAP曲线,以了解多辅助任务对于主任务的提升机制。由于使用的语言对和神经检索模型各不相同,各组实验的epoch-MAP曲线没有表现出统一的模式,但仍然可以得出以下几个结论:
与4.2的结论一致,多任务学习改善了神经检索模型的性能。由图4和图5可知,多任务学习模式的神经检索模型的epoch-MAP曲线普遍高于单任务学习模式曲线,这表明多任务学习的神经检索模型不仅在最终性能上优于单任务学习的神经检索模型,而且在整个训练期间的性能都优于单任务方法。

图4 使用MP模型时所有语言对测试的epoch-MAP曲线Fig. 4 Epoch-MAP curves of all language pairs during testing for MP model
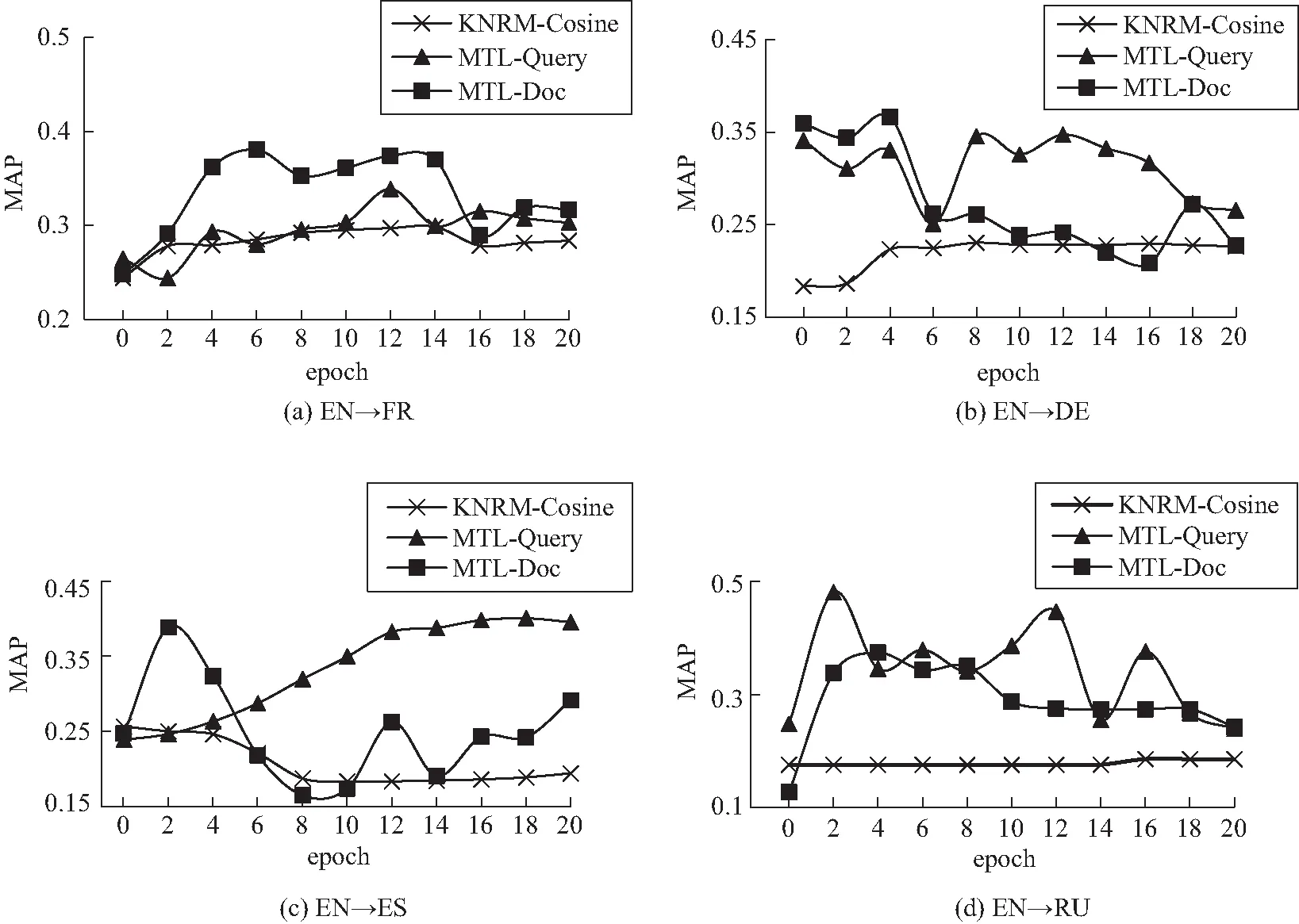
图5 使用KNRM模型时所有语言对测试的epoch-MAP曲线Fig. 5 Epoch-MAP curves of all language pairs tested for KNRM model
从图4(d)和图5(d)可以看出,由于俄语数据集的规模过小,在没有使用多任务学习时,模型的性能几乎不会随着学习的进行而获得提升,这表明神经检索模型本身很难提取小规模数据集的文本特征。而使用多任务学习方法提取文本特征之后,在不改变数据集规模的情况下,神经检索模的性能有了明显提升。这证明本文的方法对神经检索模型的提升更多来自于更高效、更精确的特征捕捉。
使用本文提出的多任务学习方法后,神经检索模型的收敛速度有明显提高,大部分多任务学习的分组在epoch 6~8即可到达较高的MAP;而单任务学习的神经检索模型通常在10个epoch的训练左右到达较高的MAP。由于使用了Early Stopping,各多任务实验组和对应的单任务学习对照组在训练中触发Early Stopping时的epoch如表4所示。由于本文使用五折交叉训练,故表4记录的epoch值为5轮训练的均值。经计算,相比单任务学习,多任务学习实验组的收敛速度平均提高了24.3%。这表明,多任务学习还提高了神经检索模型的训练效率,使其能更快训练到最佳状态,这是本文的多任务学习方法有效的另一个原因。
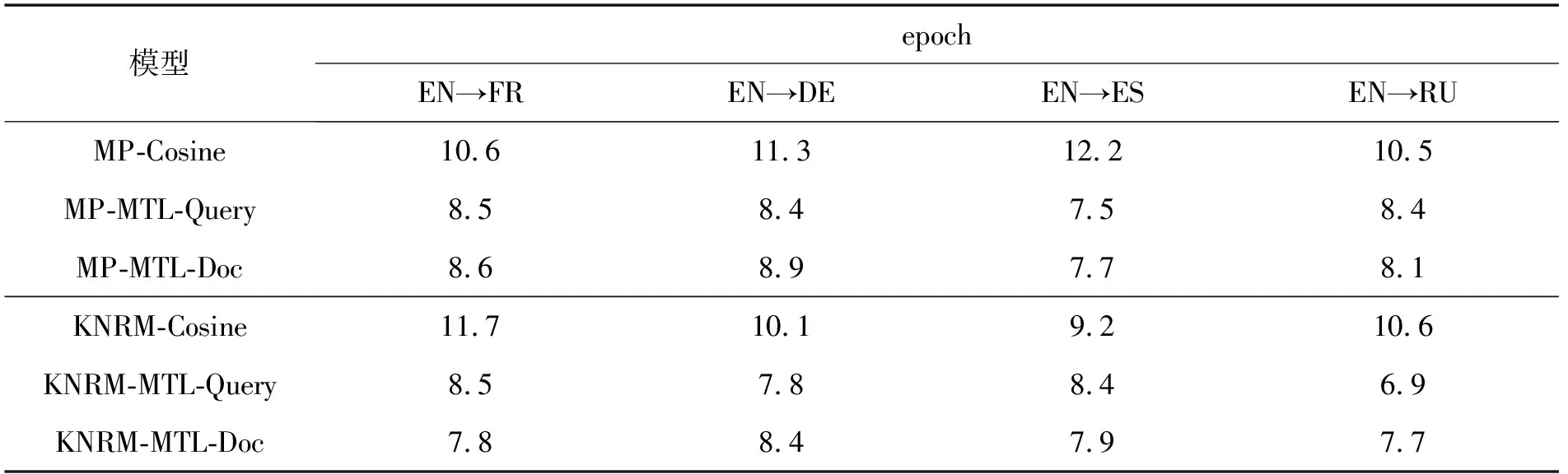
表4 提前终止训练时的epoch值Tab. 4 Epoch when training is terminated early
如4.2节所述,不同外部语料对各组实验没有展示出明显的性能影响,即外部语料的贡献有限,这个结论在epoch-MAP曲线上得到了一定程度的验证。一部分实验组的epoch-MAP曲线在MTL-Query和MTL-Doc呈现了类似的趋势,而另一部分则是完全不同的模式,即外部语料对本文的多任务学习方法没有特定的影响模式。
5 结语
本文提出一种基于多任务学习的跨语言信息检索方法,利用文本分类模型捕捉CLIR任务所需的特征,并通过外部语料对其进行补充,最后利用捕捉的特征在基于匹配的神经检索模型上执行CLIR任务。相比仅进行单任务学习的跨语言神经检索方法,多任务学习方法获取到的特征层次更加丰富,能有效地提高神经检索模型的效果。在4种不同语言对上进行的实验表明,本文提出的多任务学习方法使神经检索模型的MAP值提高0.012~0.188,并使模型的收敛速度平均提高了24.3%,证明了本文方法的有效性。
由于现阶段跨语言神经检索模型的表现欠佳,本文方法为跨语言环境下使用经典的单语神经检索模型提供了一定参考。此外,在俄语数据集上的结果表明,本文方法在数据集规模较小的情况下对神经检索模型的提升幅度更多,因此该方法在低资源跨语言检索领域存在巨大潜力,这为今后研究的方向提供了指引。另外,实验结果表明,外部语料在本文方法中的贡献有限,未来可以考虑提出一种不依赖于外部语料的多任务CLIR方法,例如使CLIR语料能同时应用于文本分类模型和神经检索模型,这将增强多任务学习在CLIR领域的实用性。
猜你喜欢
应用心理学(2022年5期)2022-11-05
客联(2022年3期)2022-05-31
北京大学学报(自然科学版)(2022年1期)2022-02-21
中国新闻周刊(2021年26期)2021-07-27
现代信息科技(2021年21期)2021-05-07
电子制作(2019年15期)2019-08-27
中国生物医学工程学报(2019年6期)2019-07-16
电子制作(2018年19期)2018-11-14
电脑爱好者(2017年7期)2017-05-06
自动化学报(2017年11期)2017-04-04
