
基于BiLSTM的酒店顾客满意度评价模型*
2023-01-18 10:07:42高丽君张宇涛林昀萱施慧玲
科技创新与生产力 2022年12期
高丽君,张宇涛,林昀萱,施慧玲
(1.福州大学经济与管理学院,福建 福州 350108;2.福州大学数学与计算机科学学院,福建 福州 350108;3.福州大学梅努斯国际工程学院,福建 福州 350108)
1 研究背景及意义
由于交通技术的迅速革新以及我国对基础设施建设的大力投资,如今人们交通出行变得越来越容易,自然而然对于酒店民宿等住宿场所的需求十分旺盛。根据Trustdata移动大数据监测平台统计数据显示,2019年我国在线酒店预订间夜量同比增长了26.7%,全年酒店间夜量规模超8亿[1]。可见在新冠疫情的影响下,酒店行业发展前景依旧一片大好。由于目前消费升级的趋势,人们对于在外出行十分重要的住宿酒店提出了更高的服务要求。如何高效探究顾客的满意程度从而识别其需求是当前酒店行业重点关注的问题。
酒店顾客满意度代表该酒店在房间、交通等硬环境以及员工、服务等软环境方面满足顾客期待的程度,是涉及各方面因素的综合指标。酒店满意度的研究方法目前包括传统的问卷调查法、专家法和当前大数据时代适用的在线评价分析法。刘卫铠[2]实现酒店评论文本的情感极性分析,证明酒店评论数据的有用性。
传统研究方法存在数据量较低、顾客覆盖率低、研究维度存在局限性等问题,而在线评价的海量数据能够在一定程度上避免上述问题。如今,互联网时代由顾客根据实际体验在各大网络平台发表的在线评论已经成为顾客满意度的重要载体。当前对于酒店满意度的研究,许多研究者选择以海量的在线评论作为文本数据库,并将文本数据进行整理筛选和分析后,用不同的研究方法对文本数据进行研究。
对酒店在线评论分析较为广泛应用的传统方法是定性分析和定量分析。汪家鑫等[3]用SWOT分析法对在线评论数据进行定性分析,提出酒店服务质量提升的策略;刘岩等[4]采用文本聚类方法与TF-IDF(Term Frequency-Inverse Document Frequency)算法对酒店在线评论进行定量分析,其次运用线性回归分析方法构造酒店顾客满意度评论模型。而面对在线评论数据量大、非结构性的特点,传统的模型方法如线性回归等难以获得较好的研究效果,因此学者们也利用逻辑回归、深度学习等机器学习领域技术进行满意度研究。郭庆等[5]通过Tree LSTM模型对旅游网站评论进行情感分析,以研究用户对旅游景点的满意程度;王红梅[6]提出了一种基于深度学习的满意度评估方法。可见深度学习由于其结构灵活的特性,抽取特征的高效性,能够在文本情感分析领域发挥极大的作用。
本研究基于深度学习开展,通过构建双向长短期记忆网络对酒店预订平台的在线评论进行情感分析获取顾客满意度,分别采用Word2vec,GloVe,fastText,BERT词向量训练工具预训练词向量作为模型词嵌入层,并与卷积神经网络(Convolutional Neural Networks,CNN)、长短期记忆网络(Long Short-Term Memory,LSTM)等模型进行对比分析得出最优模型。本文选取携程网站上福州市内多家知名酒店的在线评论实例论证。研究有利于顾客进行消费决策时选择更优的酒店,也有利于酒店研究顾客需求改进不足之处,从而获得更好的发展,对酒店旅游业的发展具有实际意义。
2 基于BiLSTM的酒店顾客满意度评价模型构建方法
本文的研究目标是构建一个基于BiLSTM的、能够提取在线评论信息、计算顾客满意度的酒店顾客满意度模型。首先爬取酒店在线评论作为研究数据,数据预处理后,利用词向量训练工具预训练评论语料,建立用于情感倾向分析的神经网络模型,以情感得分作为酒店顾客满意度并输出。
2.1 在线评论数据的获取与预处理
在线评论是评论主体自身体会的文本表示,一般由客观描写语句与主观感受语句两者组合。主观感受语句包含了评论主体的情感倾向与各种态度信息,是文本挖掘的主要目标对象。携程旅行网是我国主流的旅行服务公司之一,其上的用户在线评论具有数据量大、涵盖范围广、来源真实等特点,符合酒店顾客满意度研究所需数据的要求。本文通过爬虫工具爬取携程旅行网站上福州三坊七巷亚朵酒店、福州财富·品味酒店、TIME时间城市公寓(福州橘园洲店)、福建省闽江饭店和梅园·悦竹酒店(福州三坊七巷店)等酒店的顾客在线评论作为研究数据。
爬取的原始文本数据中通常会存在一定的干扰信息,并且无法直接被计算机识别处理。对数据进行预处理能够去除原始文本数据中的冗余信息,规范化数据格式,去除数据噪声,能够将原始文本数据转化成计算机可识别的可处理规范数据。在线评论数据预处理步骤如下。
1)去除原始文本数据中缺失、重复的文本数据。
2)去除无意义数据:在线评论中存在一定量的单字,或者仅有标点或者表情符号的评论。例如“?”“好”等,这些评论文本会对后续研究造成干扰,应该去除。
3)去除特殊符号及表情符号、标点及链接,繁体转简体,纠正错别字等操作规范数据格式。
4)分词:利用Python中现有的jieba工具包对评论文本数据分词。
5)去除停用词:由于语言的结构性,在线评论中存在一定量的无实际含义但是能够承接语句的词语,如“吗”“啦”等语气词以及“然而”“但是”等连接词。因此预处理时需要将停用词去除,以保证后续研究效果不受影响。基于现有的停用词库添加自定义停用词加以改进,获得酒店领域停用词表,对文本数据进行去停用词操作。
2.2 词向量预训练
上述数据预处理所获得的预料数据是词向量预训练的基础。而分词之后的文本要能够进入自然语言模型则需要词向量预训练。通过词向量预训练可以将文本语言向量化。作为词的分布式表示方法,词向量在1986年被Hinton[7]提出,而后经过几十年发展,自然语言领域涌现了Word2vec[8],GloVe[9],fastText[10],BERT[11]词向量模型。据研究表明,情感分类模型的性能得以有效提高得益于预训练模型的发展[12]。在研究酒店顾客满意度时,分别使用Word2vec,GloVe,fastText,BERT进行词向量预训练作为后续神经网络模型的词嵌入层。
2.2.1 Word2vec
Word2vec是Google开发的最流行的预训练词嵌入工具之一。它主要使用CBOW和Skip-Gram模型进行训练[13]。Word2vec还拥有负采样[14]和层序Softmax两种优化训练方式。本文选择采用基于Hierarchical Softmax优化技术的Skip-Gram模型训练预处理完成的酒店评论语料。Skip-Gram模型结构见图1。
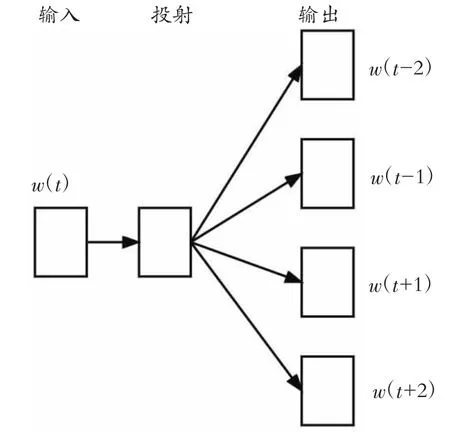
图1 Skip-Gram模型结构
2.2.2 GloVe
GloVe模型是一种基于全局词频统计的词表征工具,与WordRank[15],Word2vec等模型相似,利用语料数据库的统计信息进行词向量训练,同时捕捉词语中的相似度等语义信息。GloVe模型具备利用全局信息的能力,训练周期较Word2vec模型短且训练速度更快。
2.2.3 fastText
fastText是一个基于Skip-Gram模型的改进方法,用一组字符级别的n-grams来表示一个单词。用字符级n-gram求和表示词语。fastText能够在大型语料上达到快速训练的效果,并且可以计算出原始训练数据不包括的词语表示。
2.2.4 BERT
BERT是一种语言模型,通过调参使得模型输出结果的语义表示体现语言的真实含义。其预训练阶段包括两个任务,一个是掩码语言模型(Masked Language Model,MLM),还有一个是Next Sentence Prediction[11]。BERT在编码器和解码器上分别叠加了6层Transformer,导致其训练过程极其复杂,培训时间长且成本昂贵。本文使用Google开源的BERT预训练模型的源代码避免了上述问题。
2.3 BiLSTM模型构建
LSTM是由Hochreiter和Schmidhuber等[16]提出的,而后由Graves等[17]对其进行改进。该网络模型的目的是解决循环神经网络的梯度消失问题,因此LSTM也被认为是递归神经网络(Recursive Neural Network,RNN)的一种特例[18]。LSTM的核心思想是使用记忆单元存储输入的时序信息,而记忆单元则使用“门”结构来筛选存储至记忆单元的信息,“门”结构包括输入门、输出门和遗忘门[16]。而BiLSTM是由两个LSTM正反向组成的,将正向LSTM的输出和反向LSTM的输出简单叠加,使得模型可以同时考虑上述信息和以下信息。BiLSTM能够解决传统LSTM无法获取词语前后双向语义关系的问题[19]。
在构建基于BiLSTM酒店顾客满意度模型时,需要考虑模型结构、单元个数、网络层数、优化算法等因素。模型结构分为输入层、隐藏层和输出层3层,输入层负责对输入模型的数据处理;隐藏层则是由正向与反向LSTM细胞单元层组成的网络结构,是模型结构中的主体;输出层的作用是输出模型的分析结果。本文所构建的BiLSTM模型结构见图2。

图2 BiLSTM模型结构
本文使用Tensorflow框架,建立包含3层网络的BiLSTM顾客满意度评价模型:第一层为输入层,输入经过上述预处理的源文本数据;第二层是word embedding层,使用不同的词向量将输入的文本数据转化为词向量;第三层为神经网络预测层,通过训练BiLSTM神经网络作为分类器。选择Adam算法为模型的优化算法,tanh函数为激活函数。详细的模型建立步骤如下。
步骤一:以进行清洗后未分词的评论文本作为评论数据集,并按比例划分为训练数据集与测试数据集。将训练数据集输入模型,构建神经网络模型的数据输入层。
步骤二:基于TensorFlow构建BiLSTM模型基本结构,建立卷积层、激活层、池化层、全连接层等。本文选择使用上文预训练的词向量模型作为词嵌入层。BiLSTM层设计双向LSTM层叠加,完成词向量的拼接后输入输出层。基本结构完成后初始化参数,在后续训练中进一步调整优化模型效果。
步骤三:输出结果后根据样本的输出概率与真实值对比,得到损失率、精确值、召回率等指标。如果出现过拟合现象则考虑改变学习率,添加Batch Normalization以及在全连接层进行dropout等方法优化模型。
步骤四:达到预计效果后模型训练完成,将评论测试数据集输入模型中进行验证。将评论数据集中各句评论通过系统输出的情感值记录并且综合平均计算输出整体数值作为顾客满意度。
3 实验与结果分析
3.1 实验数据
3.1.1 数据获取
本文通过爬虫工具爬取携程旅行网站上福州三坊七巷亚朵酒店、福州财富·品味酒店、TIME时间城市公寓(福州橘园洲店)、福建省闽江饭店和梅园·悦竹酒店(福州三坊七巷店)等酒店的顾客在线评论共14 665条作为研究数据。爬取的文本数据包含用户ID、评论文本、评分星级三部分内容。爬取的部分评论数据见表1。本文研究的数据对象主要为酒店在线评论的文本内容,包括酒店顾客的好评、差评以及中性评论。
为了直观了解数据,本文在获取数据后对酒店在线评论数据进行了统计与分析。表1为评论数据的样本,表2为研究数据的描述性分析结果。由表2可知,本次爬取的酒店在线评论数据中,五星好评共11 316条,四星评论共2 511条,而一星差评共110条。依靠评论星级可以大致推测出顾客的满意度情况,但是单纯的评分计算较为简单粗暴,忽略了评论文本所蕴含的信息。因此本文对酒店在线评论文本内容作为研究数据更为细腻的探究顾客满意度具有一定意义。

表1 评论数据样本

表2 评论的描述性分析 (段)
3.1.2 数据预处理
首先对去除缺失、无意义文本数据后14 665条酒店在线评论文本数据采用Python中的jieba分词库对评论文本数据进行了分词操作,得到原始单词835 823个,再通过去除特殊符号和标签、繁体转简体、纠正错别字等操作规范数据格式。自建酒店领域停用词表去停用词,并标注文本语料中性,为后续词向量预训练打基础。经过上述数据预处理去噪后获得有效单词464 262个。上述预处理过程数据统计见表3。

表3 预处理数据统计
3.2 词向量预训练
基于上述数据处理后的语料,本文采用Word2vec,GloVe,fastText,BERT分别进行词向量预训练,作为后续神经网络模型的词嵌入层。通过不断修改模型参数,使得训练的词向量在酒店在线评论语料库上达到更好的效果,并将训练完成的词向量保存为后续模型可利用的文件。
Word2vec采用Skip-Gram模型训练参数,特征向量的维度设置为100,词最大间距为5,丢弃词频小于5的单词,采用Hierarchica Softmax技巧构建并保存模型,建立词向量词典,共计获得2 580条词向量。
GloVe参数设置中涉及的一个加权函数,用于将研讨文本序列中涉及的低频词进行衰减,以减少低频噪声带来的误差。模型作者Pennington等给出α的经验值分别为100和0.75。最小词频数为5,迭代次数50轮,词向量维度300,学习速率0.01,窗口大小5。函数的表达式为
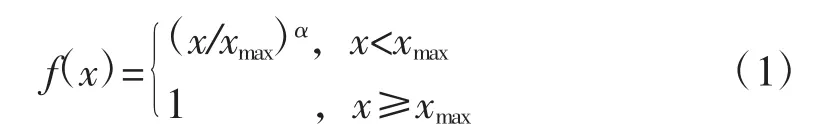
fastText在train_supervised模式下,词向量维度设置为100,上下文窗口为4,迭代次数为4,词语的最小出现次数为2,损失函数loss选用Softmax。
BERT使用谷歌开源预训练模型。该模型共有12层,768个隐藏单元,12个自注头,110万个参数。通过使用BERT下游模型能够获得高质量的词向量特征。
3.3 模型构建
将数据长度为14 665的酒店在线评论数据集输入本文构建的BiLSTM神经网络模型,使用BERT预训练词向量作为模型embedding层,进行酒店满意度模型训练。通过多次学习优化完成的最优模型超参数为:模型的LSTM隐藏向量维度均为256,batch大小为32;学习率为0.000 1,dropout率为0.4,训练200轮次。最优模型训练准确率达到了86.2%。
最后基于本文训练优化的模型,利用情感倾向值分别计算爬取的酒店在线评论所涉及的福州三坊七巷亚朵酒店、福州财富·品味酒店、TIME时间城市公寓(福州橘园洲店)、福建省闽江饭店和梅园·悦竹酒店(福州三坊七巷店)顾客满意度。各酒店满意度见表4。

表4 酒店满意度预测情况
3.4 比较
模型训练完成后,除了输出的酒店顾客满意度结果外,还应该输出准确率等评价指标,用于衡量训练模型效果的好坏。本文选择准确率、召回值、F1值作为模型的效果评价指标。需要注意的是,由于本文的情感分析任务是一个多分类任务,存在数据集不平衡的情况,评分为5的评论较多,本文需要同时关注,特别关注样本较少的类别,因此本文采用宏平均作为分类器的评价指标。
本文对比使用Word2vec,GloVe,fastText,BERT所训练的4种词向量嵌入模型的训练效果,4种模型的准确率、召回值及F1值见表5。通过指标对比,发现前3种词向量嵌入模型的效果较为接近,而BERT-BiLSTM模型能够取得大幅度升高的训练效果,准确率、召回值相比其他模型都保持在较高的水平。故而BERT-BiLSTM模型更适合本文所使用的酒店评论数据集的训练,效果最优。此外,从训练速度来看,BERT-BiLSTM模型也拥有更快的训练速度,能够减少时间的浪费。

表5 不同词向量嵌入模型准确率、召回值和F1值比较
为了对比研究本文BERT-BiLSTM顾客满意度模型的效果,本文还同时建立了使用BERT,BERT-CNN与BERT-LSTM的顾客满意度模型。二者同样采用本文爬取的14 665条酒店在线评论作为研究数据,选择效果最好的BERT预训练的词向量嵌入模型,对比4种模型的准确率、召回值和F1值见表6。
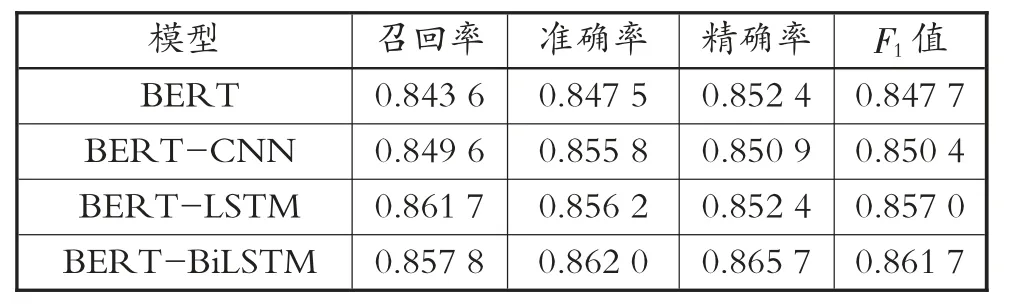
表6 4种模型的准确率、召回值和F1值比较
由表6可知,加入BERT预训练的模型均在准确率和精确率上取得了很好的精度,而且在预训练模型相同的情况下,BERT-CNN模型的准确率为84.8%,BERT-LSTM模型则取得了85.6%的准确率,模型效果较佳。而BERT-BiLSTM模型的准确率为86.2%,以微小的优势超过了比较模型。并且BERT-BiLSTM模型取得了85.8%的召回值,证明该模型在准确率、召回率以及F1值上都取得了比BERT,BERT-CNN与BERT-LSTM模型更好的效果。说明本文基于酒店在线评论语料训练的BERT-BiLSTM模型优于其他模型,能够在酒店顾客满意度评价方面发挥一定的作用。
4 结论
本文以酒店顾客在线评论为研究数据,通过文本挖掘进行酒店顾客满意度探究,建立了效果最优的BERT-BiLST模型,实现了预期研究目标。首先对用爬虫软件爬取在线评论进行数据预处理;接着采用神经网络语言模型进行训练。本文使用携程网站上福州市内多家知名酒店的在线评论进行评论挖掘,实例论证了各酒店的顾客满意度水平。探究了4种预训练词向量嵌入模型的效果,并通过与CNN,LSTM模型对比模型效果。实例表明,无论是准确率、召回率,还是F1值,本文BERT-BiLSTM的模型效果都更好、更优。
本文虽然对词向量主流模型以及神经网络模型都进行了探究,并且获得了较好的模型效果,但是本文在文本挖掘时忽略了评论文本的隐式特征分析,可能会造成信息遗漏从而影响满意度评价结果。因此下一步目标是探究如何更好地挖掘评论文本的隐性特征。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中国石油石化(2021年9期)2021-07-17 09:24:16
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中国交通信息化(2018年5期)2018-08-21 03:37:40
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
山东青年(2016年1期)2016-02-28 14:25:27
新高考·高二数学(2015年11期)2015-12-23 18:17:44
