
基于Hadoop平台的交通管理数据存储系统设计分析*
2023-01-18 12:06杨岚
九江学院学报(自然科学版) 2022年4期
杨 岚
(泉州信息工程学院软件学院 福建泉州 362000)
交通采集设备随着技术的进步更迭发展,对应采集到的信息内容和数量也表现出指数形式增长的特点。各市现有的交通数据存储系统绝大部分是基于传统关系型数据库架构而成,这一类模式对于大规模数据的存储有着一定的不足,因此也不能够较好的符合社会发展需要。该模式下的存储系统普遍出现了查询效率不高、数据的分析与传输难、安全等级低等问题。为了提升交通服务的水平,推动智能化管理,降低城市交通信息存储和分析的成本、提高其效率显得极为迫切。要能够快速、准确的分析现代化交通状况,首先要能够架构除科学高效的城市交通管理体系,同时还需要构建数据处理模型、存储交通数据,另外还要能够提升交通信息获取的精准性、时效性、效率性。大数据的运用,为解决上述问题提供了技术支持。城市道路中的交通数据采集主要是通过感应线圈、卡口、浮动车、RFID系统来完成,同时汇总与上传工作仍由上述系统实现,而大数据技术则能够将处理的数据对象扩大数倍,实现大规模数据的处理与储存。Hadoop是基于互联网应用出现的一种大数据计算系统开发框架,其主要对象是计算的、开源的大数据,受到了广大用户的认可。Hadoop中,主要核心是HDFS与MapReduce编程模型,其大数据的计算效率尤其优异。Hadoop为分布式体系结构,为Apache基金会研究开发完成,用户只需要使用常用的编程语言就能够编出对应的应用程序,不再需要完全掌握体系底层的实现过程。Hadoop是通过集群的运用实现运算与储存,其中一个关键组成是分布式文件系统(distributed file system),简称为HDFS。HDFS不仅有着运算快、存储方便的特点,具备了高容错性的特点,对于硬件的性能要求不高,对应用程序数据的高数据处理速率使得其在超大数据集中方面表现不俗。文章以Hadoop中HBase分布式数据库存储的不同时段的城市道路交通流量信息为对象,运用Hadoop的MapReduce编程模型对其进行深度分析,进而得出城市各个路段在不同时间段的交通流量数据分布,从而为城市道路的规划、管理、控制提供数据基础,为城市交通的研究、规划设计、交管部门的决策提供辅助性的帮助,另外还能够在一定程度上缓解城市的交通压力。
1 Hadoop及其相关技术
并行、分布式、网络计算等技术的诞生与完善,为Hadoop的出现奠定了基础,进而实现海量数据的运算和保存,该平台由Apache公司研发,融合运用了上述技术,实现数据的处理。该框架平台对于硬件设备要求不高,一般条件下即可运行程序,Hadoop稳定的接口能够满足各类应用程序的需求,进而架构出可靠、延展性的分布式系统。Hadoop的优点明显,其成本较低、安全可靠,且具备较高的容错性和扩展性,同时高效、稳定、可移植、免费开源。Hadoop为Master/Slaves结构,具体架构模型如图1所示。
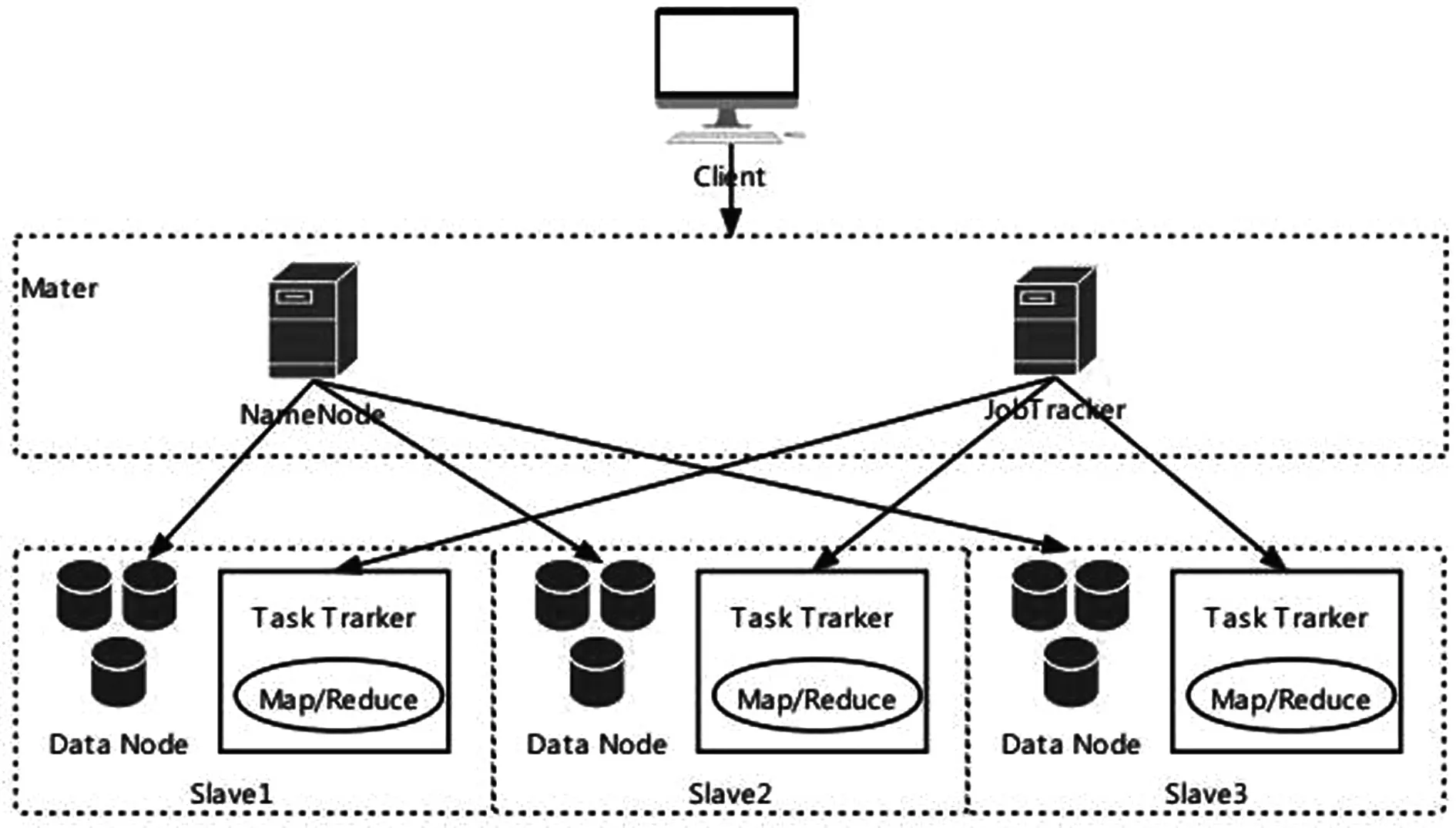
图1 基于Hadoop的云计算与存储架构模型
1.1 Hadoop分布式文件系统HDFS
HDFS对硬件要求不高,为平台中的底层文件存储系统,支持管理与储存数据,同时支持数据的访问功能。与一般分布式文件系统相比较,HDFS既有着共性也有着一定的差异性,其存在着移动计算方便、数据流形式访问、简单一致性等特点。HDFS的工作流程以及架构见图2。

图2 HDFS的工作流程及架构结构
图2显示每个HDFS集群设置单个Name Node以及多个Data Node,其中,前者为中心服务器,主要功能是对文件元数据、读写等管理,还对文件目录进行维护。此类信息通过日志文件(editlog)编辑以及空间镜像文件(fsimage)命名的方式进行保存。Name Node同时还能短时间内保存各个块(block)对应的Data Node信息。核心功能为三个方面,分别为:元数据与文件块的管理、元数据的更新、监听与处理请求。Data Node一般情况下每个集群的每个节点存在一个,功能为数据块的储存与检索,实现Name Node下达的新建、复制、删除等等指令的响应。与此同时,能够按时发送“心跳”至Name Node,从而传达负载和执行各项命令。反之,Name Node以心跳信息判定Data Node的有效性,若未能够在指定时间内接收到反馈则判定为失效节点,进而调整。每份文件都将被细分为单个或者是多个数据块且存于Data Node中,借助于互相复制完成数据的多个备份。
1.2 Map/Reduce编程框架
Hadoop是运用Map/Reduce这一编程框架实现大量数据的云计算,Map/Reduce编程框架使用简单,程序员无需了解底层实现的各项细节便可编写程序用于数据的处理,该技术能够同时在上千部服务器上满足广告与搜索等多项业务需求,与此同时还能够更为便捷的处理TB、PB以及EB级的数据。Map/Reduce框架的构成为单个JobTracker与多个TaskTracker,其中JobTracker 为主节点,主要职能是分配任务与调度,同时实现多个TaskTracker的管理。而TaskTracker则有且仅有一个存在于每个节点,主要用于接收JobTracker的指令并执行对应的任务。Mapreduce主要是对集群中的大型数据开展分布式的运算,Map与Reduce函数共同构成了这一框架,在实现数据处理时的顺序为先Map再Reduce,具体如图3所示。首先,数据被分片,随后由不同Map执行不同的分片,执行后以
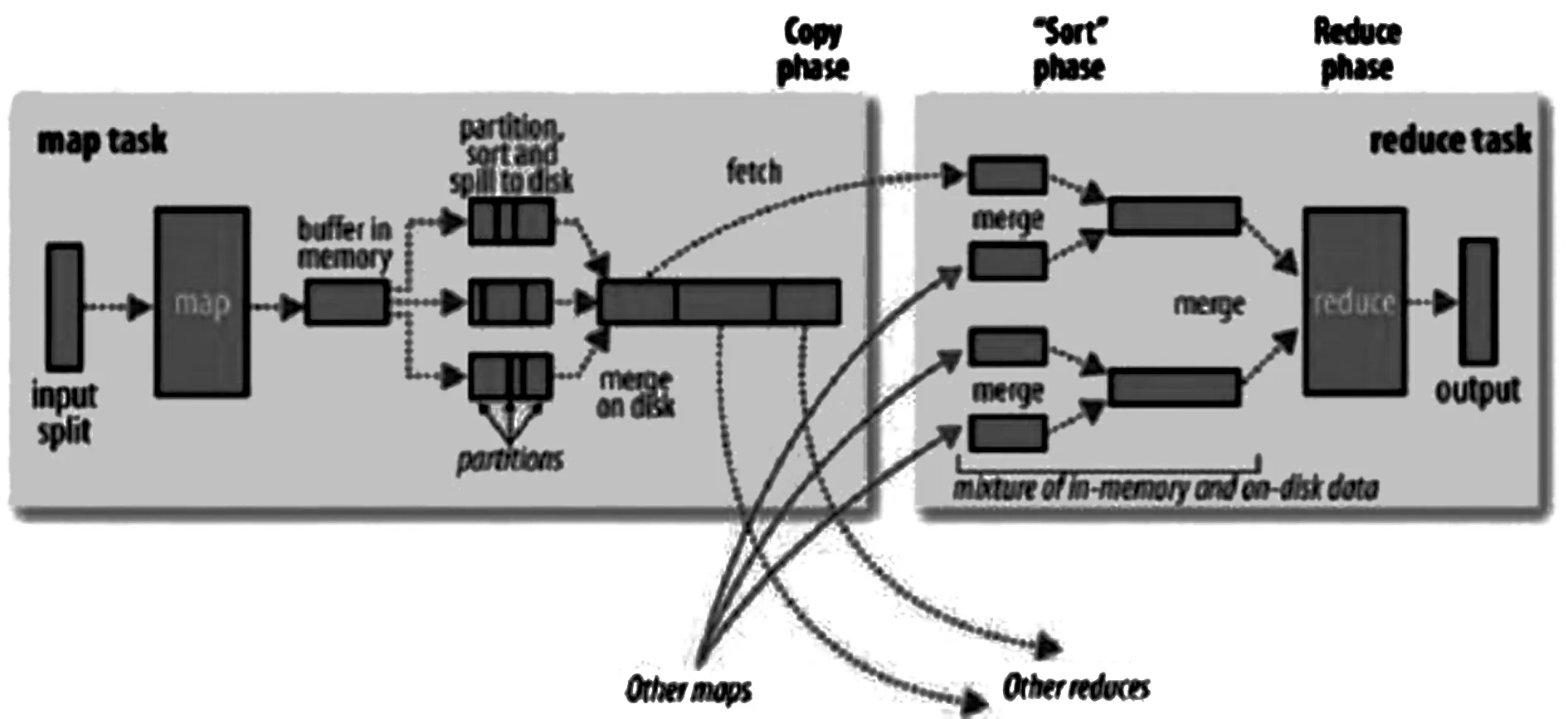
图3 Mapreduce计算过程
2基于Hadoop的交通管理数据存储系统结构及功能
结合交通流量数据的特征,基于Hadoop构建城市道路交通流量数据分布式存储与挖掘分析的总体架构,具体如图4所示。

图4 城市道路交通流量数据分布式存储与挖掘分析的总体架构
如图4所示,该架构共分为四层,分别为数据采集层、数据存储层、挖掘分析层以及应用服务层,而其中的数据存储层是研究的重点。
2.1数据采集层
数据采集层包括动态与静态两种数据采集方式,动态数据主要为线圈采集的交通流量、车型以及车速等数据信息,而卡口数据主要为车牌数据、采集时间的数据等等;静态数据主要为路段、设备等不会受到采集时间影响或变化的数据信息。采集到的动态数据在整合后储存到分布式数据库中,而静态数据则结合后期的本体模型映射成RDF数据存储。
2.2数据存储层
数据存储层的实现是借助于MapReduce数据并行存储编程模型将数据批量写入HBase分布式数据库中,此类数据主要存储于Hadoop计算机集群中。计算机集群的架构为主/从部署架构,也就是Master/Slave部署架构,Master是管理节点(Name Node),在集群中有且仅有一个,而Slave由多个数据节点(Data Node)构成且由Zoo Keeper控制保存协调。在集群中,Name Node作为核心的存在,记载了所有存储文件的切割划分情况,同时管理于维护Block存储位置等信息的元数据结构(Meta Data),数据块(Block)实际的物理存储位置是Data Node。多项进程Map执行函数能够并行地将海量数据写入到分布式文件系统中,HBase因此能够实现大型数据的便捷、有效的保存。与此同时,分布式数据库保存的每个数据Block都是遵循多个备份存储机制工作的,在实操中能够对单点故障进行有效处理,结合应用并行高效率的MapReduce计算编程模型有助于大幅提升存储的效率,进而真正的完成大型数据的保存。
2.3挖掘分析层
挖掘分析层中,结合总体框架中数据挖掘分析的要求构建出四个核心模块,分别为数据的清理、流量的计算、聚类分析、图形渲染展现。交通状况会受到车辆的速度、交通的特征、附近环境等多重因素的干扰,实际交通情况难以通过道路线圈采集到的数据进行真实的体现,因此要对采集到的交通流数据进行预先处理。数据清理模块,在模型开展计算分析前首先对采集到的数据实现清洗,将不合理的或者明显异常的数据删除,同时将空值和重复的数据剔除出去,进而实现数据的清洗。流量计算模块能够结合以往采集到的数据,且按照流量的换算系数,将一段特定时间内需流量计算统计查询的数据,分析记录的车辆进入的时间是不是在时间段范围中,进而累计在时间段范围内经过换算最终获得交通流量值。随后,按照路段的有关参数对交通的流量密度进行核算。上述数据经过统计分析后可以为交通流量的预测、交通管理与控制提供参考。在数据的挖掘分析中,聚类分析是常见的、高效的方法,能够实现数据的分类。该分析方法能够结合采集的路段交通流量密度,采取一个初始值作为计算的中心,根据算法流程进行反复迭代运算,从而找到新的合理的中心值,进而将道路的交通流量密度划分成多个等级,从而满足图形渲染展现模块对于数据的需求。图形渲染展现模块是在城市的道路网图或者是统计分析图表中将聚类分析后的数据进行渲染展现,进而得出数据的统计结果图,用于支持有关部门的决策。
2.4应用服务层
应用服务层为城市交通行业中的各类用户提供一站式的服务。结合云服务中的应用等同于服务的理念,应用服务层的设计目的是将所采集到的资源与功能通过服务的方式提供给用户,从而满足交通的预测、路网的规划、交通的管理的数据分析需求,还能够为我国城市交通管理与控制带来科学的参考,另外还能够满足城市道路交通量统计数据的下载需求。云服务平台还可以借助于城市道路交通流量的资源、数据、文档的交换框架体系,实现系统之间的数据与服务交互操作。
3交通数据存储系统实验
3.1实验环境和实验数据
3.1.1存储平台 ①分布式存储平台。分布式存储实验平台由Hadoop集群系统构成,而该系统则由同样配置的9台计算机互联构建而成。实验过程中,名为Name Node的计算机为系统的核心部分,另外8台计算机的功能是存储数据信息,其作为数据节点的形式存在。实验中,所有计算机均安装Centos6.0操作系统,成功装上Hadoop软件后,HDFS系统中shell命令能够实现数据的上传,同时还能够通过Java语言编程完成数据的挖掘算法。②传统的数据库存储。实验中,所有计算机的配置、服务器、操作系统均一致,传统数据库则搭建Oracle数据平台,实现数据的存储。两个平台的硬件配置如表1所示。

表1 两平台所需要的硬件配置
3.1.2实验数据 该实验的数据对象为苏州市RFID数据和出租车的GPS数据,时间为1个月,其中RFID数据约为2.24亿条,约67.5G。RFID数据记录了车辆的信息,涵盖种类具体如表2所示。苏州市的出租车约为19000辆,对应的GPS数据每月约为9.98亿条,约128.5G,信息种类具体如表3所示。为公平地比较数据库的情况,两个平台均不构建任何表索引。
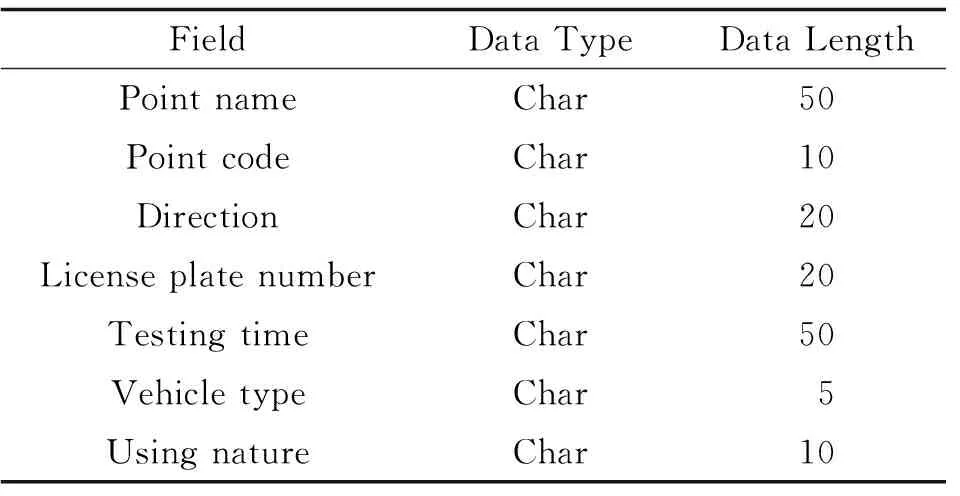
表2 苏州市RFID数据格式
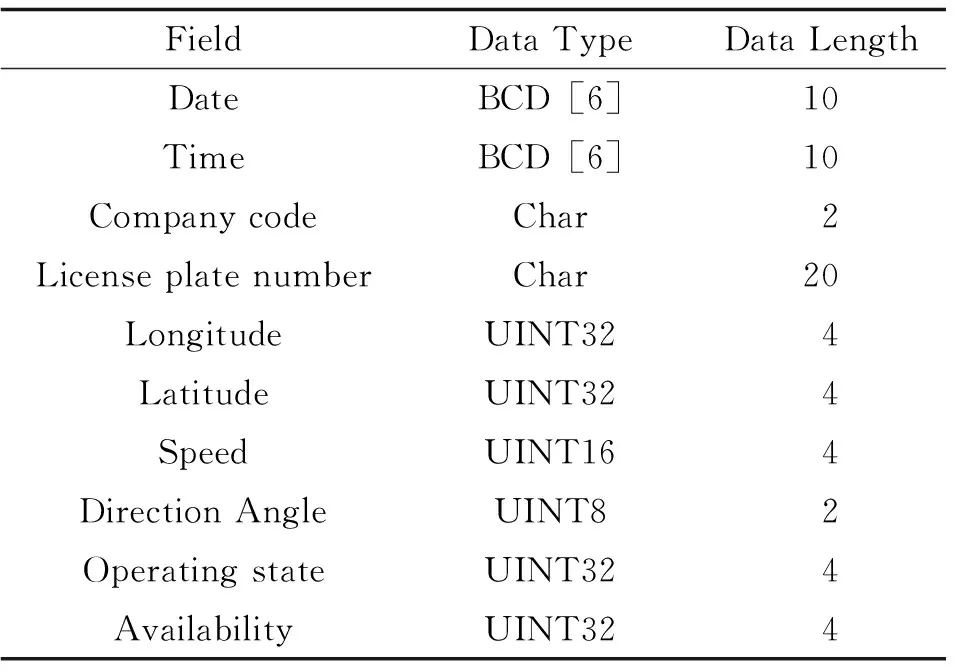
表3 苏州市出租车GPS数据格式
3.2实验步骤
3.2.1安装系统和软件 实验平台的搭建中,首先要安装系统和软件。而该实验中,两个平台构建分为系统安装与软件安装。该实验中的两个平台中,Hadoop平台集群共需要9台计算机,该平台所有计算机安装Centos6.0系统与桌面版Linux环境。第10号主机,命名为PC,安装Windowsserver2008操作系统。两种平台的安装中,Hadoop平台的安装更为复杂,且需要对环境变量进行调整。
3.2.2导入数据实验 苏州市的RFID和GPS数据根据时间段特点进行统计,进而得出该市在1小时、12小时、24小时、1周、2周、3周、1个月的RFID数据量以及GPS数据量将不同时间段内的RFID数据和GPS数据分别传输到Hadoop平台以及Oracle平台上,通过数次传输导入相对应的数据实验,进而统计传输同等数据到两个平台所耗费的时间,具体如图3所示。
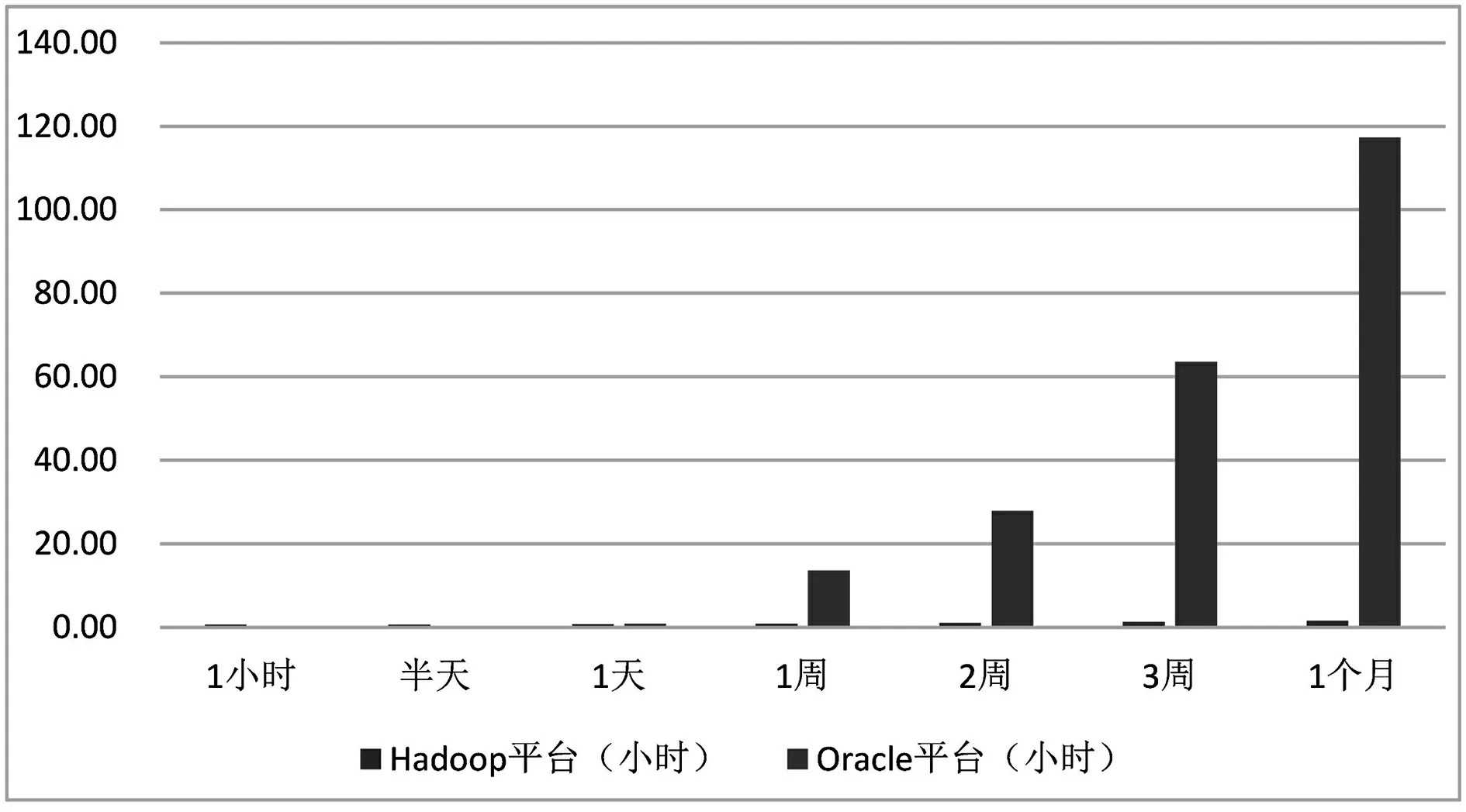
图3 导入相同数据量两种平台所需要时间
对比两个平台结果可知,当导入的数据数量相对较少时,Oracle平台的效率明显高于Hadoop平台,而如果导入的苏州市24h的数据时,两平台所耗费的时间没有太大差别,效率相似。但如果导入的数据量较大,当时间超过24h后,Oracle平台的上传效率明显降低,而如果导入数据量大小超过50G时,Oracle平台的效率将显著下降,且非常低下。但数据量的增加对于Hadoop平台的影响不大,对于导入数据量的增加,Hadoop平台的导入时间没有明显增加。由此可知,在大规模数据的传输导入中,Hadoop平台的效率更为显著。
3.2.3查询数据实验 上述内容证实了Hadoop平台在导入大规模数据时有着明显的优势,且与Oracle数据库系统相比较,效率更高。此外,Hadoop分布式系统的优势还体现在大规模数据的查询中,该平台的效率也非常显著。将苏州市1个约的RFID与GPS数据导入平台,开展查询对比实验,具体为同时在两平台上查询每周5个工作日的车辆出行分布状况,查询效率的对比情况具体如图4所示。
图4 两平台的查询过程时耗对比图
实验结果表明,两平台的对比结果非常明显,与Oracle平台的查询效率相比较,实验中搭建的Hadoop平台的查询效率更高,平均约为Oracle查询效率的5.76倍。
3.3实验结果
在完成大量交通数据导入和查询实验后,能够发现,基于大规模的交通数据背景,Hadoop平台在交通大数据的存储和处理中表现优异,与传统Oracle数据库平台相比较有着明显的优势。大数据的传输和大数据的查询方面,Hadoop平台与Oracle平台相比,优势明显。
4结论
大数据技术的应用,为大规模数据的快速存储与处理提供了可视化的管理界面,而传统方式难以对大规模数据进行分析与管理的问题也得到有效的解决。随着城市道路交通数据的迅猛增长,交通数据量非常庞大,结合城市交通的智能化、大数据化的发展需求,文章对Hadoop大数据平台开展了实验研究,搭建基于Hadoop平台,基于Hadoop构建出城市交通大规模数据的存储与分析框架,在此基础上,文章对现有的交通数据存储情况进行了分析,进而提出多类型交通数据混合存储的分布式系统,并且进行了系统设计。通过Hadoop平台与Oracle平台的对比实验,比较了两个平台在数据的导入和查询方面的效率,结论显示,对于大规模数据的存储导入和查询而言,Hadoop平台有着明显的优势,效率明显较高。
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
建材发展导向(2019年11期)2019-08-24
中国交通信息化(2018年7期)2018-09-14
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
雷达与对抗(2015年3期)2015-12-09
中国交通信息化(2014年11期)2014-06-05
中国交通信息化(2014年8期)2014-06-05
