
基于随机森林和支持向量机的森林健康情况分析
2023-01-14 09:52:10岳丽娅邓洁莹梁霄
计算机应用文摘·触控 2023年1期
岳丽娅 邓洁莹 梁霄

关键词:数据挖掘;患病树木检测;随机森林;支持向量机
1引言
如今,林木健康问题已得到社会各界前所未有的关注,而中国传统的样地检测和受控实验等方法需要耗费大量人力物力,且得出具体结论所需时间往往较长,使林业健康检测丧失时效性。故传统手段具有一定局限性。而遥感是避免接触,目标距离较远的一种探测技术,其能够为研究人员提供更高纬度的视野,可以有效收集并且处理复杂时空维度下的海量信息。本项目基于高分辨率遥感数据,结合统计学相关理论知识以及新兴的数据挖掘技术,对健康树木和患病树木的遥感图像数据进行分析研究和区别分类,旨在实现树木患病的检测与预防,且有效提升森林虫害防治的研究效率[1]。
2研究意义
理论意义:引人数据挖掘技术,丰富森林健康管理研究方法。
目前,关于林木健康的研究虽已取得丰硕成果,但森林健康相关的数据挖掘作为现实问题研究还较少。因此,本项目引入数据挖掘技术,构建科学有效的模型和算法,从而丰富森林健康管理的研究方法,为其提供一种新的研究视角。
现实意义:为相关部门对树木健康的检测监控提供参考。
基于高分辨率遥感数据,利用统计学相关理论知识以及数据挖掘技术,对健康树木和患病树木的遥感图像数据进行分析研究和区别分类,在对森林健康的保护方面有着极其重要的现实意义。
3数据导入与预处理
3.1数据集加载
本文所使用的原数来源于机器学习的加州大学数据库UCI,本文使用的则是其中一组病树研究数据。该数据集是来自Johnson等遥感研究的一些训练和测试数据的集合。该数据集由Quickbird卫星遥感图像分割组成,这些分割是通过分割全锐化图像生成的,这些数据中含有快鸟卫星遥感数据中的纹理信息以及数据的光谱信息,其数据属性信息如表1所列。
该数据集来自Quickbird卫星遥感图像。数据集中的原数据为计算过后的R,G和NIR波段的平均光谱值以及两个常用的纹理度量,标准差和灰度共生矩阵(GLCM)表示所有方向上的信息。而B波段再次被排除在分析外,因为它与绿色波段中信息高度相关,而全色波段被用作两种纹理计算,因为它包含最详细的空间信息。实验区域为约为3.0kmx2.5km,主要由落叶阔叶林和常绿针叶林组成,有较小面积的砍伐林、住宅和农业用地。又因为这个位置有许多患病的松树和一些其他树种,而且该地区有许多其他类型的土地利用和土地覆盖,从而有利于我们实验的对比分析。
3.2本文进行的数据预处理
数据处理指的是在提取数据、模型、研究和分析原始数据集的其他活动前需要进行的一些处理过程。我们获得的数据源一般都是不适合用来挖掘的。所以需要通过数据预处理使数据集变成进行数据挖掘合适的数据[2]。
原数据集划分为95%的训练集以及5%测试集,按照习惯总数据集将按照比例6:2:2划分为三类,分别是训练集、测试集、验证集。但在一些情况下,验证集并不是必要的,所以本文将原数据集合并后按照比例划分为75%的训练集以及25%测试集,用于病树检测模型的拟合和评估检测。
4病树检测模型的建立与求解
4.1随机森林分类方法
4.1.1随机森林基本原理
随机森林是用于回归与分类的一种主流集成学习方法,也是一种常见的机器学习模型。它的实质是建立在决策树基础上的分类器集成算法,属于Bagging类型[3]。随机森林中单棵树的信息增益率公式如下:
4.1.2基于随机森林的病树分类
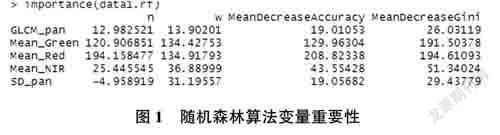
首先,对数据集进行一下处理,将类别变量转换为因子型,以便接下来的分类建模工作。然后,查看自变量的重要性程度。如图1所示。
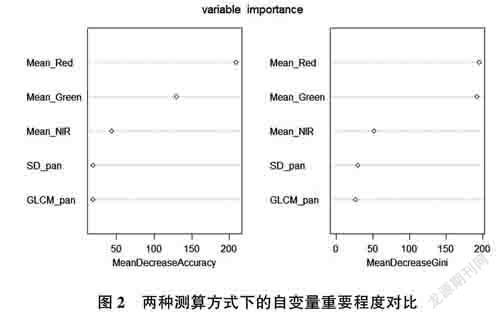
两种测算方式下分别代表换掉变量后准确率的降低程度和换掉变量后信息增益率的降低程度。而这两个的数值大小,决定了变量的重要性,值越大,则表示变量越重要[4]。从图2可以看出,Mean_Red对分类结果影响最大,是所有变量中对分类问题最重要的变量。
在使用函数randimForest()时,函数会存在默认mtry(单棵树的特征数量)与ntree(森林中树的棵数)。但是,现实中这个默认值一般情况下都不是分类效果最好的,所以我们在构建模型时,应该想办法去确定最优的参数值。
基于逐一增加变量的方法,从输出结果可以观察到,当mtry为5时,模型的误判率均值是最低的。
在确定了最优的mtry后,还需要进一步确定模型中的最优ntree。在确定该参数时,我们将应用模型的可视化分析。在之前的分析中发现,mtry为5时模型最佳,所以接下来将建立相应的模型,并对其进行可视化分析。具体结果如图3所示。
从图3可以得出,当ntree大概大于450后,模型误差便会趋于稳定,所以我们可以将模型中的ntree大致确定为450,以此来达到最优模型。
综上,在建立模型时,本文尝试了当mtry=5,ntree=500; mtry=5,ntree=450; mtry=3,ntree=450,三种不同情况下模型建立效果。发现这两个参数对分类结果影响较小。这里展示其中效果最好的mtry=5,ntree=450时的模型结果。
如表2所列,其中预测错误的仅有12个实例个数,而针对患病树木检测正确的却有52个,正确率为99 .Ogo-/o,预测结果良好,适合作为病树检测分类的建模方法。接下来绘制用于评价模型优劣的ROC曲线图[5],如图4所示,图中的AUC值为0.946。
其余两个模型的AUC值为0.945和0.937,相对来说,模型效果区别并不大。
4.2支持向量机分类方法
4.2.1支持向量机基本原理
支持向量机通常用来进行分类,回归分析及模式识别。自支持向量机算法大概原理提出后,20世纪90年代Vapnik等的研究成果又使得该法快速发展。由于其较高的正确率已成为解决多维数据预测的一种较受欢迎的工具,支持向量机种类不同可解决不同类型的问题。其基本原理是将分类点正确区分,使分隔的距离最大化,可以转化为凸二次规划问题来求解[6]。
4.2.2基于支持向量机的病树分类
在使用R语言对支持向量机算法建模的过程中,参数type是指建立模型的类别,它可以取的值有五种,分别为:C-classification,nu-classification,one-classification,eps-regression和nu-regression。其中,前3个针对的分类方式都是字符型结果变量,而且第3种方式同时还是逻辑判别:后两种则是针对数量型结果变量的分类方式。故根据用途的差异,我们选择type的取值为C-classification。
为了选择模型最优的核函数,采用了逐一实验不同核函数的建模效果的方法,并进行了比较结果,最后看预测结果最好的模型,它用什么核函数,我们就用它所使用的核函数。
观察各种分类方式的模型预测结果,所得齐次多项式核函数的建模正确率为0.9669,非齐次多项式核函数的建模正确率为0.9521,高斯核函数的建模正确率为0.9901,双曲正切核函数的正确率为0.9083。由此,故选择高斯核函数作为建模核函数。最终,我们将利用C-classification与高斯核函数结合的模型作为最优模型。并根据该模型预测,得到混淆矩阵如表3所列。
由表3可知,其中预测错误的仅有12个实例个数,而针对患病树木检测正确的却有48个,正确率为99.01%,预测结果良好,十分适合作为病树检测分类的建模方法。接下来绘制用于评价模型优劣的ROC曲线图,结果如图5所示,AUC值为0.913。
5病树检测方法结果分析对比
将本文所研究的两种模型算法进行结果对比,绘制算法结果对比表如表4所列。
由表4可以看出,兩种算法模型结果均较好,但随机森林算法比支持向量机算法的结果更好一点,正确率和作为模型的评价标准的AUC值均是更优秀的。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
电力与能源(2017年6期)2017-05-14 06:19:37
安徽农学通报(2017年1期)2017-02-15 17:49:06
软件(2016年7期)2017-02-07 15:54:01
南水北调与水利科技(2016年6期)2017-01-06 13:43:27
电子技术与软件工程(2016年20期)2016-12-21 10:21:33
价值工程(2016年32期)2016-12-20 20:36:43
价值工程(2016年29期)2016-11-14 00:13:35
电脑知识与技术(2016年23期)2016-11-02 23:25:12
科学与财富(2016年28期)2016-10-14 21:19:17
