
基于数据挖掘的通信网络故障分类研究
2023-01-14 14:49朱圳刘立芳齐小刚
智能系统学报 2022年6期
朱圳,刘立芳,齐小刚
(1.西安电子科技大学 计算机科学与技术学院,陕西 西安 710071;2.西安电子科技大学 数学与统计学院,陕西 西安 710071)
随社会的快速发展,对于网络的需求也越来越大。智能手机、智能设备、智能家居等的出现,增大了网络的使用。传统通信网络面临着前所未有的增长,对网络的需求和使用也在增大,导致网络负担变大。因此通信网络经常发生故障,故障以告警的形式进行上报,一旦某处发生网络故障,网络中就会产生大量告警信息,如何快速定位网络故障类型是一个难题,而传统研究基本都在关注告警之间的关联规则。在文献[1]中将群智能算法用于关联规则的挖掘,并应用于通信领域。文献[2]同样利用群智能算法中的蚁群算法进行告警的关联分析。文献[3-5]都是基于频繁模式树的关联规则方法,该方法提高了算法的运行效率。除关联规则模式挖掘之外,序列模式也频繁地应用在通信告警领域,序列模式挖掘考虑时间上的顺序,从而效果更佳。文献[6]使用的是序列模式挖掘。文献[7-8]都是基于序列模式挖掘的实际应用。除研究通信网络的告警关联和序列模式,还有一些国内外的研究学者研究网络的故障定位,也取得了一些不错的成果。2002 年Steinder 等[9]提出一种基于贝叶斯网络的故障定位技术,贝叶斯网络根据网络拓扑和通信协议构建,并使用Pearl’s iterative 算法进行概率推理,但该方法只能用于单连通网络。许多学者引入贝叶斯网络为网络故障事件的关系建立模型[10]。王开选等[11]指出了故障传播模型下的故障定位问题是NP 困难(non-deterministic polynomial)问题,并提出一种启发式的最小损失故障定位算法。同时故障诊断系统也被开发和使用,华为诺亚方舟实验室开发了诊断系统,通过对历史数据的分析和构建知识图谱,并根据知识图谱进行推理,可以以问答的形式辅助工程师找到故障根因[12]。王迎春等[13]使用规则进行故障定位,规则使用条件-结果的语句形式表示,该定位方法主要需要解决规则知识库构建的问题。初始进行故障诊断多数依赖专家,根据专家经验和网络资源等关联性建立故障推理树,并完成故障定位[13]。赵灿明等[14]采用二分图模型考虑了通信网络中故障位置对告警信息的影响,旨在解决大范围的故障告警下故障定位问题。
为实现通信网络故障分类,本文提出基于数据挖掘的通信网络告警分类算法。首先,针对干净的告警数据和故障数据,对其进行特征工程,将挖掘到的特征与原数据合并,得到便于模型训练的数据集;然后,基于集成学习模型对数据集进行模型训练与预测,并与文献[15]中的基于卷积神经网络故障分类进行对比实验,最终获得通信网络故障类型。
1 相关概念
1.1 数据挖掘
数据挖掘[16]是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘分为有标签和无标签挖掘两大类。有标签数据可以用来进行分类或者预测任务,无标签数据可以用来进行聚类或者关联分析等。
1.2 特征工程
特征工程[17]是指将数据转换为能更好地表示潜在问题的特征的方法,从而提升机器学习的性能。特征工程就是对数据的特征或者数据进行分析,将数据转换成可以更好地表示问题的潜在特征,从而提高机器学习的性能。特征工程主要包括以下几个重要的作用。
1)转换数据格式。这也是数据预处理中一个重要的环节,但这里的转换数据不仅仅针对干净数据,也针对脏数据。有些数据以表格为主,无法直接拿来预处理,需要转换数据格式,这也属于特征工程的范畴。
2)确定特征。原始的数据中可能存在多列属性,但并非所有的属性都可以用作模型训练的特征,特征是可以标识问题的重要属性,而不能标识问题的属性称为普通属性。
3)提高学习性能。特征工程最大的作用就是获取最佳的数据,最佳的数据可以更好地标识问题,进行机器学习训练时可以得到更好的效果。
1.3 集成学习
集成学习[18]是将若干个基学习器(分类器、回归器)组合之后产生一个新的学习器。相比单一模型,集成学习模型在准确性、稳定性、鲁棒性和泛化能力上都有很好的效果。一般来说,集成学习可以分为3 类:1)减少方差(Bagging),即防止过拟合;2)减少偏差(Boosting),即提高训练样本正确率;3)提升预测结果(Stacking),即提高验证精度。
1) Bagging:通过对样本数据集进行有放回地重复采样,生成多个采样子集,并行地训练出多个模型,测试阶段集成多个模型的泛化输出,常常采样直接平均的做法。Bagging 执行流程如图1所示。

图1 Bagging 执行流程Fig.1 Bagging execution process
2) Boosting:其思想是采用串行训练过程来训练模型。同样是利用数据集来训练多个模型,但Boosting 的最大特征是后训练的模型会考虑前训练模型的误差,具体做法就是对于前训练模型中出错的样本加大权重,称为赋权法。赋权法的应用使得每个样本对于训练模型的误差起到的作用是不同的,而后训练模型会采用贪心算法去不断适应训练集,力争将每个训练样本的误差都尽量降低。Boosting 执行流程如图2 所示。
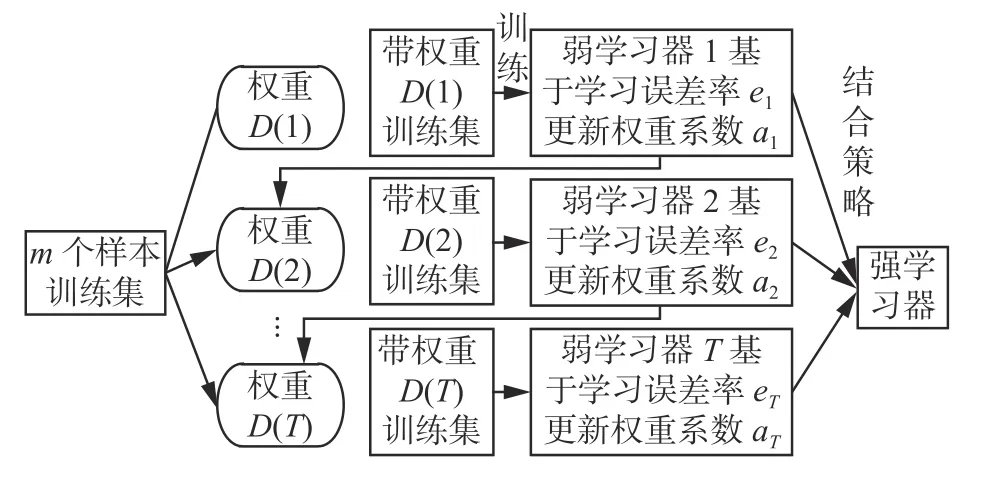
图2 Boosting 执行流程Fig.2 Boosting execution process
3) Stacking: 该方法是将多个不同基学习器得到的输出作为输入,训练一个新模型,得到最终结果。具体过程如下:
①将训练数据集随机划分为两个数据集;
②一个用于训练多个基学习器,一个用于测试这几个基学习器;
③将②得到的预测结果作为输入,训练1 个更好的分类器。在第2 个集合上测试这几个学习器。
2 基于数据挖掘的特征构造法
2.1 数据处理与特征构造
从数据中提取出可以用于模型训练的数据特征,比如将时间做处理,时间可以提取出年、月、日等,并且还可以根据时间来判断当前是工作日还是休息日,不同的时间点网络的负担情况是不一样的,这些因素都可能影响网络的质量情况。分析网络告警标题,由于标题是文本数据,可以对其进行文本的提取处理,可能某些告警标题就是对应着相关的故障类型,这样的告警标题更能表征故障类型。还可以根据告警或者故障发生的基站或小区名称进行分组处理,得到一些其他的特征信息[19-24],比如某个小区出现故障或者告警的频率、故障发生的时间等。
1)针对告警标题做TF-IDF
告警标题:故障发生时所上报的告警名称,不同的告警标题表示不同的告警类型,如ETH_LOS表示端口接收不到信号、RHUB 与pRRU 间链路异常告警和用户面故障告警表示接口异常。
TF-IDF:一种用于信息检索与数据挖掘的常用加权技术,TF 表示某个词出现的频率,IDF 表示逆文本频率指数。IDF 的主要思想是:如果包含某个词的文档越少,IDF 越大,则说明该词具有很好的类别区分能力。
使用TF-IDF 对告警标题进行转换,对每个告警标题中的词统计,将文本信息换为数值信息。处理后的告警数据变成表1 的形式。为了方便记录生成的词特征,用 idf_i表示第i个词。

表1 TF-IDF 处理后新增的特征Table 1 New features after TF-IDF processing
2)处理告警的时间特征
告警数据的时间特征主要是考虑告警的发生时间信息,将告警的发生时间进行处理,提取出告警发生时所在的月份、是在工作日还是周末等。处理后的告警时间特征如表2 所示。

表2 告警数据时间处理后特征Table 2 Characteristics of alarm data after time processing
3)处理故障时间特征
当网络发生故障时,统计故障发生日期、故障发生的时间是否在周末、故障发生的所在的时间段、是否在工作日和故障持续时间等特征。处理后的故障时间特征如表3 所示。

表3 网络故障时间处理后特征据Table 3 Characteristics after network fault time processing
4)比率特征
比率特征是将前面处理后得到的特征进行求比例,比如:求每个告警标题出现的次数,当前故障中告警标题的种类,求告警标题在每个小区的比例情况,求解每个小时发生告警的比例情况等。处理后的特征如表4 所示。

表4 相关特征的比例特征Table 4 Proportional features of related features
将上述这些经过特征处理后的所有特征进行合并,得到最终的训练集数据,并将得到的最新数据集用到集成学习模型。
2.2 特征选择
经过数据处理和特征构造后共得到183 个属性,并不能将所有的属性作为特征加入到模型中进行训练,有些属性可能会影响模型的效果。本文所使用的数据量近20 000 个样本,每个样本有83 个特征的数据量,如果全部用于训练,将对机器要求非常高,同时算法运行时间也较慢,因此需要对属性进行筛选,使用LightGBM 模型进行特征筛选。
LightGBM[25]是2017 年由微软团队开源的集成学习模型,该模型是对梯度提升树优化的模型。该模型训练速度快、内存占用小,被广泛运用在数据科学竞赛中。该模型可以用来评估特征的重要性,对数据训练后,可以通过模型的feature_importance()函数获取特征的重要性值,该函数对训练完的各特征进行重要性排序。特征筛选流程如图3 所示。

图3 特征筛选流程图Fig.3 Feature screening flow chart
经LightGBM 的重要性评估后,有24 个特征的重要性值为0,说明这些特征对最终分类结果没有作用,将这些特征剔除。通过特征重要性函数可以发现特征重要性值为0 的特征多数为时间相关的特征,如告警发生的小时、告警发生是否在周末等,说明时间特征对故障分类的重要性较低。而告警标题经过TF-IDF 处理后得到的特征,特征的重要性值较高,说明告警标题对故障分类有着重要的作用。
3 实验与分析
为验证提出算法的性能情况,本部分通过实验进行性能分析。与文献[15]中的基于卷积神经网络的故障分类算法进行对比实验,通过实验分析可以看出提出的基于数据挖掘的通信网络故障分类算法有更高的分类准确率,且时间也相对比CNN 快,因此提出的方法在故障分类的准确率上是有优势的。所有实验均在带有8RAM 和1T 硬盘的Interi(R)、Core(TM)i5-4 790 CPU@3.6 GHz 的计算机上进行,并使用Python 语言和Java 语言一起实现。
3.1 实验数据集
实验所使用的数据如表5 所示,其主要包括电力、硬件、软件、传输和动环故障五大故障。告警序列 Alarmi表示第i个告警,其中每个告警中又包含告警发生和告警清除的时间、告警标题名称、告警发生站点等信息。
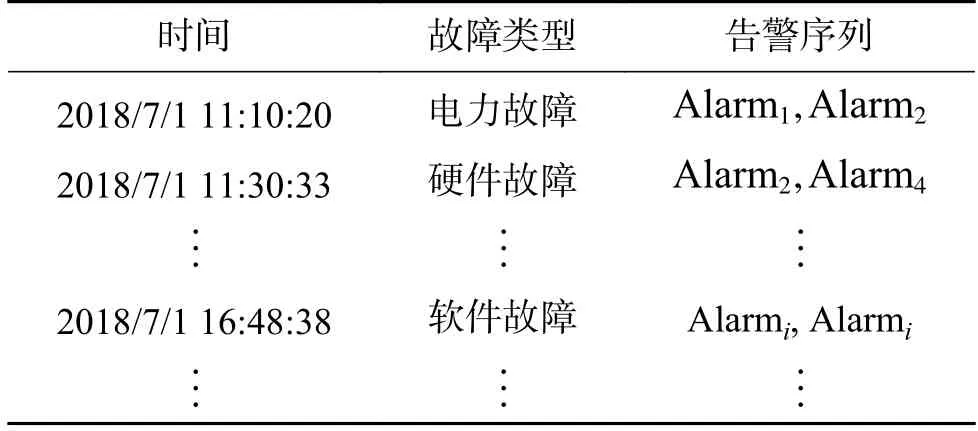
表5 实验数据Table 5 Experimental data
3.2 算法的评价指标
分类是机器学习中常见的任务,常见的评价指标有准确率、精确率、召回率、F1-score、ROC曲线等。混淆矩阵如表6 所示,其中TP (true positive)表示真正类,即样本为正且预测也为正;FN(false negative)表示假负类,即样本为正预测为负;FP (false positive)表示假正类,即样本为负预测为正;TN (true negative)表示真负类,即样本为负且预测为负。

表6 数据检测结果Table 6 Data test result
准确率为
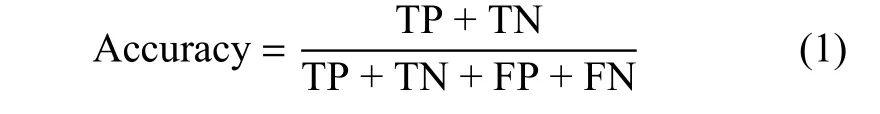
准确率是分类问题中直观的评价指标,有明显弊端,在各分类样本比重不均匀时,占比较大的分类会影响准确性的评价。
精确率为

精度率是描述分类器不将负样本预测为正样本的能力。
召回率为

召回率是描述分类器找出全部真正样本的能力。
F1-score 为

式中:P代表精准度;R代表召回率;F1-score 越大,说明模型越稳定。
3.3 算法的高效性验证
图4(a)中,对比在新数据集下3 种不同集成学习模型的分类准确率差异,可以得到在不同K折交叉验证下,每个模型的分类准确率都在提高。当K≥7时,LightGBM 和CatBoost 的分类准确率基本趋于不变,而XGBoost 的分类准确率随K值变大而变大;当K≥9时,XGBoost 的分类准确率也趋于稳定,基本都在83.50%。从图中可明显看出在新数据集下,XGBoost 的分类准确率比Light-GBM 和CatBoost 模型的分类准确率高,而Cat-Boost 的分类准确率又高于LightGBM。综上所述,3 种集成学习模型的分类准确率大小分别是XGBoot>CatBoost>LightGBM。
考虑到数据类型存在一定的不均衡性,从模型的F1-score 值来对比一下3 种集成学习模型的性能差异。在图4(b) 中可以看出在不同K值下3 种集成学习模型的F1-score 也不同,当K不断增大时只有XGBoost 模型的F1-score 在不断变化,而LightGBM 和CatBoost 模型的F1-score 没有变化。对于XGBoost 集成学习模型,随着K值的增加F1-score 越来越大,说明模型越来越稳定,当K=10 时,9=F1-score<K的值,说明模型的稳定性下降了。为了说明XGBoost 集成学习模型在K=9时的效果最佳,对XGboost 模型多做几组K>10 的实验,进一步对比K值对该模型的影响。

图4 不同K 值下的结果Fig.4 Results under different K values
从图5 可以看出,当 6 ≤K<9时,XGBoost 模型的F1-score 值越来越大;当K>9时,XGBoost 模型的F1-score 值越来越小;当K=9时,XGBoost 模型稳定性最好。

图5 不同K 值下的F1-scoreFig.5 F1-score under different K values
为了证明本文提出的基于数据挖掘的方法比文献[15]中基于卷积神经网络的网络故障分类效果好,进一步做对比实验,将新数据集在集成学习模型上的结果和文献[15]中基于CNN 的结果进行对比分析。
从图6(a)可以看出,随着训练集数据量增大,基于CNN 网络故障分类算法和本文提出的方法在不同集成学习模型下的分类准确率都在提高,在相同训练集数据量时,本文提出的方法在XGBoost 集成学习模型下的分类准确率高于CNN 算法。CNN 算法的分类准确率高于LightGBM 和CatBoost 集成学习模型,说明基于CNN 的网络故障分类算法有一定的效果。如果在数量集足够多的情况下,可能CNN 算法的分类效果会更好,但是由于数据量有限,就目前数据来看,XGBoost 集成学习模型的分类准确率更高。其主要原因是:本文提出的基于数据挖掘的网络故障分类算法考虑告警和故障之间的潜在特征,并将告警相关的特征进行了处理,挖掘到的特征可以更好地区分故障类别。而文献[15]中提出的基于卷积神经网络的故障分类算法,并没有考虑告警标题、时间等潜在信息,只是将告警和故障根据时间进行划分,所以信息挖掘不充分。
图6(b) 中,对比几种模型运行时间的差异,从图可得,随数据量增大,所有模型的运行时间都增大。4 种模型的运行时间:CatBoost>CNN>XGBoost>LightBG。虽然LightGBM 的运行时间最短,但准确率最小。而新数据集在XGBoost 集成学习模型下的运行时间小于CNN,因此,本文提出的方法所得到的新数据集在XGBoost 这种集成学习模型下的效果最好。

图6 不同数据规模下的结果Fig.6 Results under different data scales
综上所述,本文提出的基于数据挖掘方法所得到的新数据集,在XGBoost 集成学习模型上有更好的分类准确率和更快的分类结果,可以用于通信网络故障分类。但所提出的方法也存在一定的缺点,所使用的数据量有局限,未来如果可以获取到更多的有效数据集,可以再做进一步的研究。
4 结束语
本文根据通信网络告警数据和网络故障数据,进行数据挖掘和特征构造,得到一些潜在的特征信息,将潜在特征与原数据一同进行模型的训练与预测,从结果可以看出得到的新数据集在XGBoost 集成学习模型上的分类准确率更高。其次,从XGBoost 和CNN 算法的运行时间来看,XGBoost 的运行时间更短,可以在短时间内得到网络的故障类型。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
铁道通信信号(2019年12期)2019-05-21
中国交通信息化(2018年5期)2018-08-21
电子技术与软件工程(2016年24期)2017-02-23
东方教育(2016年9期)2017-01-17
