
结合Cannikin’s Law的离线数据增广方法研究
2023-01-13 11:58梅菠萍
计算机工程与应用 2023年1期
邓 雪,赵 皓,2,张 静,2,梅菠萍,张 华
1.西南科技大学 信息工程学院,四川 绵阳 621010
2.中国科学技术大学 信息科学技术学院,合肥 230026
卷积神经网络(convolution neural network,CNN)在计算机视觉领域中的目标检测、语意分割、姿态估计等具有挑战性的任务上展现出强大性能[1]。目前,用于提升模型性能的方法主要分为三类:(1)加深网络结构。例如GGNET[2]、Inception-v4[3]等,更深的网络具有足够的复杂度和特征内部变化,随着网络层数增加,CNN分层次提取更精细的特征,从而高效进行学习。(2)优化损失函数。例如Momentum[4]、RMSprop[5]等以更有效的损失函数找到模型最优参数,加快训练速度,提高学习效率。(3)数据增广。数据作为深度学习的驱动力,对模型训练至关重要。数据增广主要用于解决样本尺寸不平衡、类别不平衡以及遮挡问题。尺寸不平衡是指小样本的检测性能总是比尺寸大的样本差。在文献[6-7]中,采用copy-paste机制和过采样来提高小目标检测精度。在文献[8-12]中,通过提高原始图片分辨率并融合来自不同分辨率级别特征以提高小目标的特征表达能力。类别不平衡,即,数量不平衡,可能导致模型过拟合,几何变换是最常用的数据增广方法,通过随机裁剪、翻转、镜像等几何变换能有效提升模型的泛化能力。对于遮挡问题,信息丢失可以显著提升模型对遮挡的鲁棒性,在文献[13-14]中,随机截取样本区域并使用随机值或均值填充,迫使模型学习图像中更宽广的具有描述性质的特征,从而防止模型过拟合于特定的视觉特征。CutMix为避免图片本身区域特征信息丢失[15],结合Mixup和Cutout将剪切区域与训练集中其他图片区域像素进行线性插值。相比于前两类方法,数据增广更具有通用性和易操作性。
上述方法均能有效提升模型的检测精度和效率,但是在其不是影响检测性能的主要因素时,始终存在某些类别的检测性能远低于平均检测水平,如图1所示(chair、potted-plant),将此现象定义为检测性能不平衡问题。受Cannikin’s Law启发,木桶的总容量会随着最短板提高而显著增加,因此,最低mAP类别的检测性能提升,整体检测性能将显著提升。推测其主要原因是其特征表达能力不平衡,遵循copy-paste机制,对特定类别实例进行分割并随机放入增广样本中,通过相似性度量机制选择需要增广的样本。由于随机粘贴导致大量目标遮挡问题以及数据集本身存在的遮挡现象,进一步采用cut-replace进行自遮挡增广,选择图像特征表达能力最显著的区域,并根据中心先验使用同一张图像左上角相同大小的区域进行替换,该步骤没有引入额外的特征信息。

图1 不同检测器对Pascal VOC数据集的检测性能对比Fig.1 Comparison of detection performance of different detectors on Pascal VOC dataset
1 数据增广的动机
在FCOS和RetinaNet检测器上对Pascal VOC数据集进行大量实验。对比、分析实验结果:始终存在检测精度远低于平均检测水平的类别。为了确定出现此现象的原因,对Pascal VOC数据集进行统计分析。首先对每个类别的数量进行统计,然后对每个类别实例的平均尺寸进行统计,如图2所示。
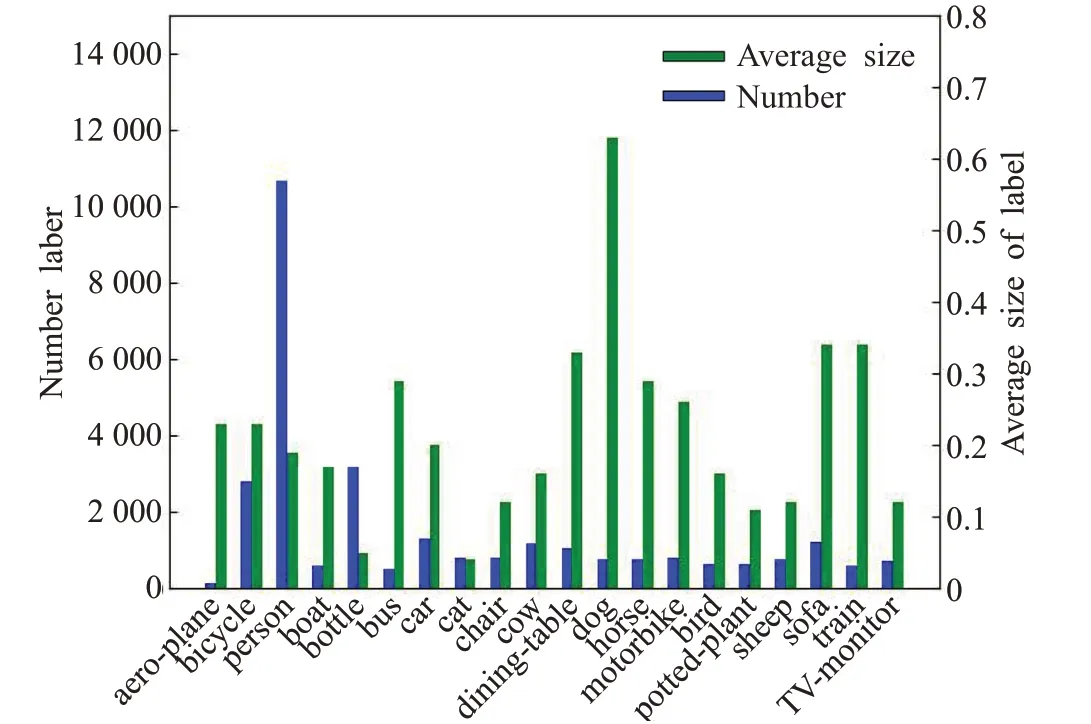
图2 对PASCAL VOC数据集的统计Fig.2 Statistics of PASCAL VOC dataset
实验结果表明,对于数量、尺寸相当的类别,其检测精度差距也很大。推测其主要原因是其特征表达能力不平衡。当物体处于背景极其复杂,或者与其特征十分相似的环境下,以及被遮挡的物体,人眼也很难一眼分辨,因此,可以通过增加目标的场景多样性来提高模型的学习能力。
2 场景多样性增广
为了提升样本数据集分布的多样性,本文采用“copy-paste”机制,首先将短板类别实例进行分割,然后通过余弦相似性度量机制确定目标增广样本,并将增广的样本扩充到训练样本集中。增广的样本数据如图3所示(蓝色框内是增广的样本实例)。

图3 对chair和potted-plant样本实例的增广图片Fig.3 Augmented images of chair and potted-plant sample examples
2.1 余弦相似性
Random-erasing方法中采用随机数进行在线数据增广,对数据集分布多样性的提升针对性不强。本文采用余弦相似性度量机制计算训练集中的样本与包含短板类别实例样本间的相似性距离,选择相似性高的样本作为目标增广样本,有利于提升检测模型在相似场景的分辨能力。图像的余弦相似性是根据像素坐标值将一维向量映射到向量空间,通过计算相同维度向量间的距离获取相似性度量,计算过程如公式(1)所示:

其中,Ai、Bi为通过直方图和灰度获得的区域矢量。
通过对内容相似以及差异较大的两组不同图片进行相似性度量测试,实验结果如图4所示。为了降低数据增广的代价,本文通过余弦相似性度量机制,在训练数据集中,获取与包含短板类别实例相似的训练样本作为增广目标样本,通过控制相似性阈值,能够获取性能提升与增广代价的平衡。

图4 余弦相似性的相似度测量结果Fig.4 Similarity measurement results by cosine similarity
2.2 实施细节
场景多样性增广的具体流程如图5所示,样本范例如图6所示。首先,通过gt-box获得包含样本的最小外接矩形,减少背景,再通过含有短板类别的分割掩码将背景变为黑色。最后,将这些实例按一定比例缩放后,通过copy-paste任意放入选择的样本中,这里的分割掩码是数据集自带的蒙版真值,也可根据成熟的数据分割方法进行获取,不需要精度很高。

图5 场景多样性增广流程Fig.5 Specific process of scene diversity augment

图6 场景多样性增广的样本范例Fig.6 Sample example of scene diversity augment
3 Cut-replace自遮挡
遮挡增广通过引入额外信息,增加数据集的场景多样性,然而,检测模型不可避免地会受到噪声信息的影响。本文提出一种自遮挡方法,通过随机剪切图像本身的区域进行增广,最大程度地降低噪声引入。同时为了避免遮挡过程中,有用信息被严重遮挡,造成检测模型性能明显下降的问题,本文采用遮挡部分特征表达显著区域,有效保护上下文信息的一致性。其增广后的样本数据示例如图7所示。

图7 Cut-replace自遮挡增广后的样本Fig.7 Sample of cut-replace self-occlusion augmentation
Cut-replace的实施细节:cut-replace自遮挡的具体实施流程如图8所示。首先,将卷积特征图resize到输入图片尺寸并获取最大特征值的位置(x,y),映射回原图;其次,以该位置为圆心,因为,cutout指出:切口大小是比形状更重要的影响因素,选择椭圆;然后,根据边界框大小设置切口尺寸,为选择最佳遮挡面积,设置长轴为其所在gt-box的h/3、h/4、h/5,短轴为w/3、w/4、w/5进行对比。若该位置在背景上,则选择图片的h和w;最后,截取图片中的patch进行遮挡。相比于random-erasing方法对样本进行随机擦除,本文主要针对特征显著区域进行擦除。该机制能提升模型从上下文信息对目标的分类与定位性能。

图8 Cut-replace自遮挡增广的流程Fig.8 Process of cut-replace self-occlusion augmentation
如图9所示,cut-replace自遮挡可使模型关注样本非显著性区域,通过目标全局特征进行类别判别与位置回归。降低模型对显著性区域特征的依赖程度,提升模型的表达能力。

图9 热力图可视化Fig.9 Heat map visualization
4 实验结果及分析
4.1 实验准备
4.1.1 实验平台
所有实验均使用PyTorch1.5框架,训练、验证和测试都在Nvidia Titan XP(12 GB)工作站上进行。
4.1.2 数据集
本次实验主要在PASCAL VOC数据集上进行训练和针对VOC数据集,训练集采用VOC(07+12),测试集采用VOC07 test。同时,为了验证该方法的有效性,还在MS-COCO数据集上进行了验证实验,训练集采用train2017,测试集采val2017。
4.1.3 数据集
为了验证提出方法的有效性,选择两个以ResNet-50为骨干网络的RetinaNet[16]和FCOS[17]无锚检测器作为基线。
4.2 在Pascal VOC数据集上的对比实验
为加快训练过程的收敛速度,采用ImageNet分类任务的预训练权重初始化backbone。采用SGD作为优化器,batch-size=6,momentum=0.9,初始学习率为2E-3,设置30个epoch。初始学习率设置为0.01,在20和25个epoch分别降低10%。输入图片尺寸调整为800×1 300。
表1展示了在FCOS检测器上,不同数据增广方法对Pascal VOC数据集检测性能的改进,主要对比Random-erasing和Cutout数据增广方法。

表1 不同数据增广方法对比实验结果Table 1 Comparison of experimental results with different data augmentation methods 单位:%
从表1中可知,基于copy-paste的场景多样性增强方法在FCOS检测器上将检测精度提升了4.04个百分点,短板类别最高提升10.04个百分点,基于cut-replace的自遮挡方法提升了4.28个百分点,短板类别最高提升了16.23个百分点,两种方法同时作用,检测性能提升了4.8个百分点,短板类别最高提升了20.80个百分点,相比于Random-erasing和Cutout对短板类别的提升效果更明显。表2列出了在本文方法下每个类别的AP值对比结果。

表2 每个类别的mAP对比Table 3 Comparison of mAP for each category单位:%
4.3 在MS-COCO上的验证实验
为了进一步验证该方法的有效性,在最典型的MS-COCO数据集上进行验证实验,采用SGD优化器。在FCOS检测器上,训练的Bach-size设为12,迭代次数设置为24个epoch,每张图片的尺寸被调整到512×512,并根据COCO数据集json文件的标注格式,对增广后的整个数据集生成新的json标注文件,并与Randomerasing进行对比,测试结果如表3所示。
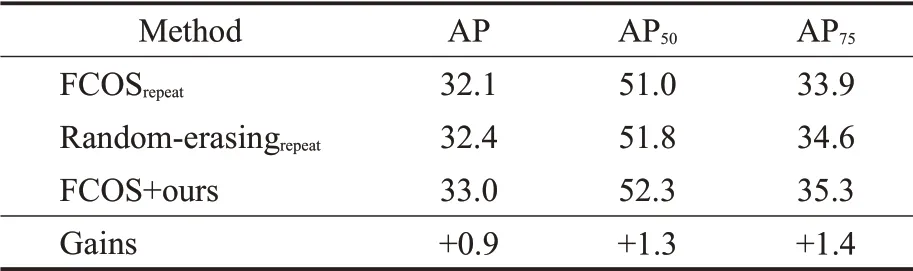
表3 MS-COCO数据集上实验结果Table 3 Experimental results on MS-COCO dataset单位:%
如表3所示,在FCOS检测框架上,可将MS-COCO数据集的平均检测精度从32.1%提升到33.0%。
4.4 消融实验
4.4.1 场景多样性增广数量的对比实验
为验证测试增广的数量对该方法的影响,设置了增广数量为100~500的等级,测试结果如表4所示。
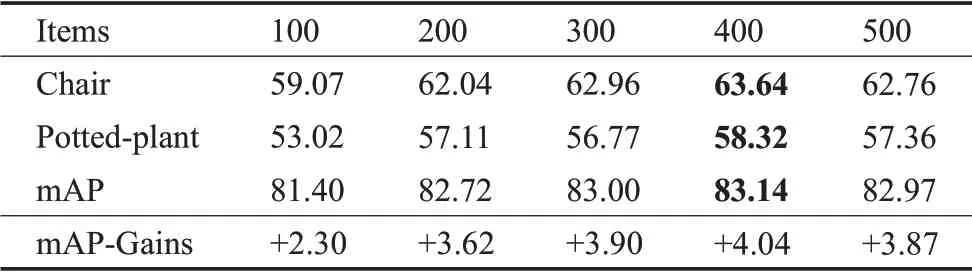
表4 PASCAL VOC数据集上的实验结果Table 4 Experimental results on PASCAL VOC dataset单位:%
从表4中可以知道,当增广数量为400,该方法达到了最好的效果,因此选择合适的增广数量,对于获得最佳检测精度至关重要。
如图10是对场景多样性增广数量消融实验的可视化对比,将特定类别实例进行随机放置时会产生遮挡现象,当增广数量达到一定程度时,检测性能的提升率反而下降。因此,利用遮挡原理可进一步提升短板类别的检测性能和对遮挡的鲁棒性。
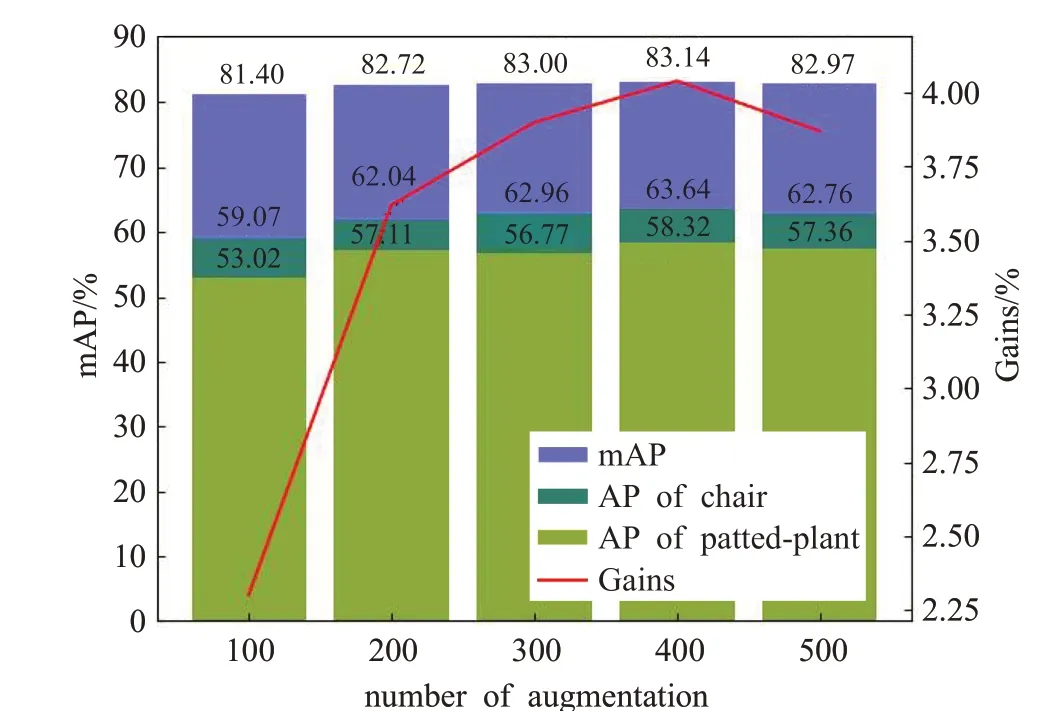
图10 不同数量等级的增广测试结果Fig.10 Augmentation test results of different quantity levels
4.4.2 相似性度量机制的消融实验
为了提升短板类别(chair、potted-plant)的检测精度,验证相似性度量机制的有效性,对随机选择和余弦相似性进行对比实验。在FCOS和RetinaNet检测器上对PASCAL VOC数据集进行测试,结果如表5所示。

表5 相似性度量机制的消融实验结果Table 5 Ablation experiment results of similarity measurement mechanism 单位:%
实验结果表明,基于copy-paste的数据增强方法在FCOS和RetinaNet检测器上对PASCAL VOC数据集的检测精度分别从79.10%和81.59%提升到83.14%和83.57%。特别对于短板类别,提升最为显著。
4.4.3 自遮挡增广的面积和数量对比实验
采用与场景多样性验证实验相同的实验设置,为了测试最佳遮挡面积,对遮挡比例为1/3、1/4、1/5进行对比,对比结果如表6所示。
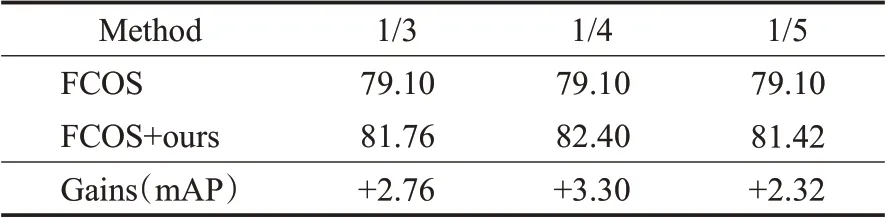
表6 不同遮挡比例的检测结果Table 6 Detection results of different occlusion ratios单位:%
从表6中数据可知,选择遮挡比例为1/4时测试效果最佳。同时为了测试遮挡数量对检测精度的影响,设置260、360、460、560实例数量等级的遮挡级别,实验结果如表7所示。设置遮挡的实例数量为560时,平均检测性能达到了83.38%,提升了4.28个百分点,短板类别(chair、potted-plant)分别提升了8.4个百分点和16.23个百分点。

表7 不同数量等级PASCAL VOC数据集的检测精度Table 7 Detection accuracy of different quantity levels PASCAL VOC dataset 单位:%
5 结束语
为解决多类别目标检测任务中检测性能不平衡问题。受Cannikin’s Law的启发,提出一种离线数据增强算法。首先,采用copy-paste增广方法对短板类别进行场景多样性增强,然后,针对copy-paste增广方法随机放置过程中产生的大量遮挡问题,采用cut-replace的自遮挡增广方法来提升短板类别对遮挡的鲁棒性。大量实验结果证明该方法的有效性,为数据增广领域提供了有用的参考价值。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
河北画报(2020年8期)2020-10-27
中华建设(2019年7期)2019-08-27
劳动保护(2019年7期)2019-08-27
汽车观察(2018年12期)2018-12-26
民族古籍研究(2018年1期)2018-05-21
中国公路(2017年17期)2017-11-09
西夏学(2016年2期)2016-10-26
浙江大学学报(工学版)(2016年2期)2016-06-05
浙江大学学报(工学版)(2015年1期)2015-03-01
