
基于深度学习的t-fMRI脑状态解码
2023-01-13 13:33:40付佳俊卢梅丽曹一凡郭兆桦高资成
天津职业技术师范大学学报 2022年4期
付佳俊,卢梅丽,曹一凡,郭兆桦,高资成
(天津职业技术师范大学信息技术工程学院,天津 300222)
大脑是人类最复杂的器官之一,控制着人类的高级情感和复杂行为。如今人们对大脑的认知仍十分有限,相关学者一直试图解开大脑工作原理之谜。大脑会根据人执行任务的差异而产生不同的反应,任务态功能磁共振成像(task functional magnetic resonance imaging,t-fMRI)是一种通过测量血液动力学间接刻画大脑神经活动的影像数据,现已成为使用最广泛的脑功能研究手段之一。其获取方式为先对信号去噪[1],再使用多层同时扫描技术[2]快速采集功能磁共振全脑影像。功能磁共振成像能对特定的大脑活动皮层区域进行精准定位,且能实时跟踪信号的改变,其空间分辨率和时间分辨率分别可以达到2 mm和1 s。多年来,研究人员一直试图通过功能磁共振成像解码识别人脑功能。其中,多体素模式分析(multi-voxel pattern analysis,MVPA)[3]是最常用的方法之一。MVPA的核心原理是在不同认知状态下,利用独立的实验数据测试由多个体素信号形成的空间模式训练分类器的性能。尽管MVPA很受欢迎,但需要人为选取特征,可重复性差且耗时。
随着深度学习的发展,越来越多基于深度学习的方法被运用于影像数据分析。Dvornek等[4]使用基于Long Short-Term Memory的递归神经网络,通过静态fMRI对ASD患者对照和进行分类。Eickenberg等[5]利用基于卷积神经网络(convolutional neural network,CNN)的模型,通过fMRI信号对观看自然风景的大脑进行预测。Seeliger等[6]根据生成对抗网络,借助fMRI信号来重构视觉图像。Wen等[7]使用深度残差神经网络模拟视觉皮层处理,提供了一种高效策略,以建立高维和分层视觉特征的皮质表征预测模型。Zhao等[8]基于三维卷积,开发了一种用以识别和分类不同类型的功能性脑网络。Khosla等[9]使用一种三维卷积神经网络方法实现集成学习策略,该方法利用了rs-fMRI数据的全分辨率三维空间结构,并适合非线性预测模型。与传统机器学习方法不同,深度学习可以自动提取数据的特征,以达到自动分类的目的。卷积神经网络作为当下使用最多的方法之一,越来越多的人将其运用于fMRI分类中。深度学习通过多层网络的非线性变换自动提取数据中的隐含特征,但是由于缺乏对其内部工作机理的理解与分析,通常被看作“黑盒”模型,导致用户只能观察模型的预测或分类结果,而不能了解模型产生决策的依据。尤其在医疗数据的应用场景中,仅向用户提供最终的预测结果而不解释其原因,很难让用户信任和理解该模型。因此,对模型分类结果进行可解释性分析至关重要[10-13]。
鉴于fMRI数据的高维特性,本文采用三维卷积神经网络模型(3D-CNN)[14]对其进行分类,并与支持向量机(support vector machine,SVM)在不同评价指标下进行比较。同时,通过梯度加权类激活映射方法(Grad-CAM)[15]和导向梯度加权类激活映射方法(Guided Grad-CAM)对3D-CNN进行可解释性分析,以可视化的方式定位得到输入样本中影响3D-CNN决策的关键因素,以确定特定任务下所激活的功能脑区。
1 数据集与实验方法
1.1 实验数据
1.2 3D-CNN
在CNN被广泛使用之前,大多图片分类实验使用全连接神经网络。全连接神经网络虽然在最终的分类结果上表现较好,但是也存在以下缺点:图像展开为向量,丢失空间信息;参数过多,效率低下,训练困难;大量的参数易导致网络过拟合。CNN的提出恰好解决了以上问题。卷积操作能很好地提取数据的相邻空间信息,避免数据的像素展开成向量后造成的空间信息损失。相比二维卷积,三维卷积增加了空间维度,其输入数据和卷积核均为三维,表示为(P,Q,R),卷积操作如图1所示。
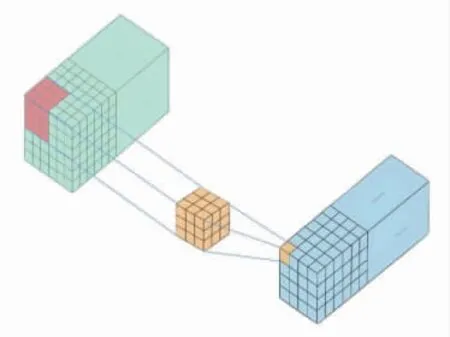
图1 三维卷积操作示意图
对于功能磁共振数据,三维卷积能有效提取其空间特征。三维卷积操作如下
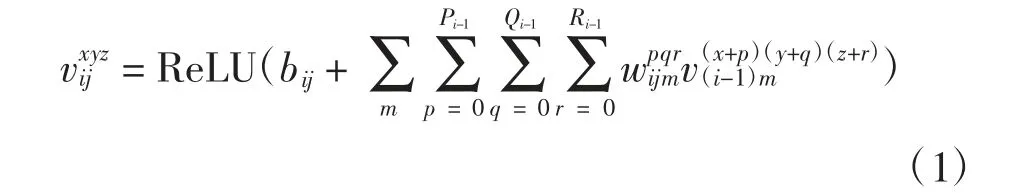
式中:vxyzij表示网络第i层通道为j位于(x,y,z)的值;bij为偏置;wpqrijm表示通道为m的卷积核位于(p,q,r)的值。
本研究基于三维卷积方法,构建了一种用于识别任务态功能磁共振成像的三维卷积神经网络(3DCNN)。该神经网络结构是由输入层、卷积层、池化层、激活函数层以及全连接层拼接而成。卷积层由多层三维卷积构成,是网络的核心层,网络中大部分的计算量都来源于此层。池化层对数据进行下采样,从而减少网络参数量。激活函数层为网络增加了非线性因子,非线性激活函数能够在输入、输出之间生成非线性映射。全连接层则是为了融合前面提取的特征,最后在输出层对数据类别进行预测。3D-CNN网络结构如图2所示。
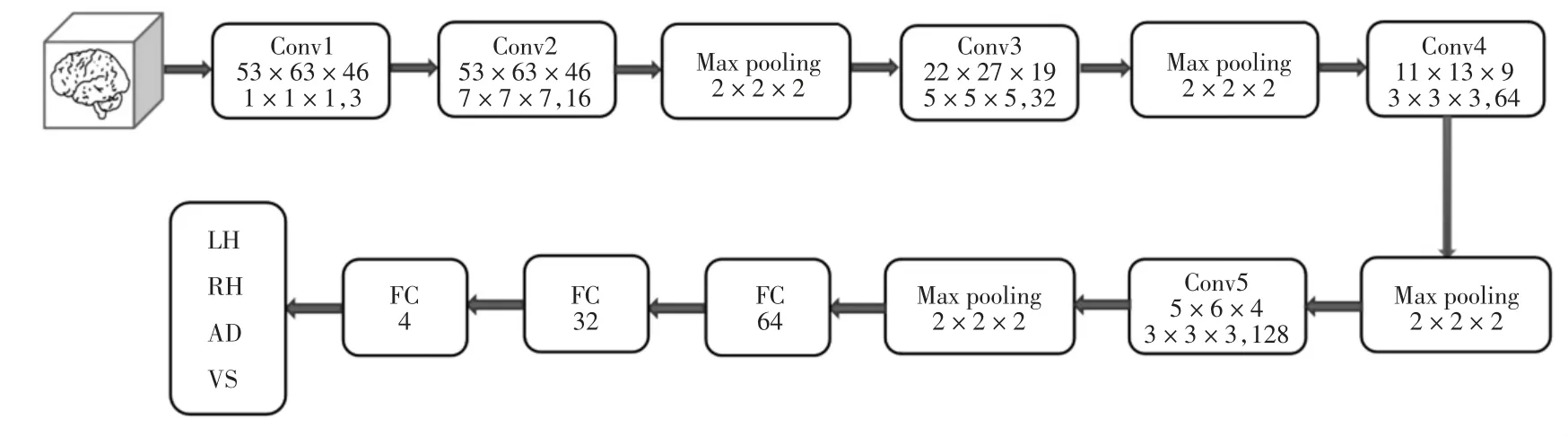
图2 3D-CNN网络结构
3D-CNN网络由5层卷积层和3层全连接层组成。输入的原始数据通道大小为1。其中,第1层卷积层的输入大小为53×63×46,输出通道大小为3,卷积核的大小为1×1×1。卷积核设置为1×1×1,目的是将图片通道变为3,以便后续可使用Guided Grad-CAM进行可视化。整个网络的池化层大小为2×2×2,全连接层的长度分别是64、32,最后是一个四分类的全连接层,分别对应LH、RH、AD、VS。损失函数选择交叉熵损失函数,其在做分类(具体几类)训练时用。优化器被用来更新和计算影响模型训练和模型输出的网络参数,使其逼近或达到最优值,从而最小化损失函数E(x)。常用的优化器有Adam、SGD、RMSprop等,本研究选用SGD优化器。训练时网络的学习率设置为0.001,动量参数设置为0.9,权重衰减为0.000 5,batch大小为64。
1.3 支持向量机
支持向量机是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。在深度学习被广泛运用之前,SVM是监督学习中最具影响力的算法之一。该算法的核心思想是找出最大的决策边界,从而达到能最大程度分类数据的目的。SVM最初主要是用来解决二分类问题,在这个基础上进行扩展后,也能够处理多分类问题以及回归问题。具体实验步骤如下:
(1)对fMRI数据进行预处理,为提高输入特征的有效度,将所有数据去除背景(设为0)并仅保留大脑体素。去除背景前后的数据(Axial方向的切片)对比如图3所示。

图3 预处理前与预处理后的t-fMRI数据对比
(2)将之前的三维数据(X,Y,Z)转换为(X*Y*Z)。由于功能磁共振成像数据的复杂性,并不是每一个特征值都能很好地体现区分度,故某些特征值不存在分析的价值。将转换后的数据表示为X=(X0,X1,…,Xn-1)m×n,其中,Xj=[x0j,x1j,…,x(m-1)j]T。通过设置方差阈值去除不必要的特征,以提取关键的大脑区域。计算式为
2016年,倦怠发生比例最高的是重症医学(55%)、泌尿医学(55%)和急诊医学(55%);2017年,倦怠比例发生最高的是急诊医学(59%)、妇科医学(56%)和家庭医学(55%);2018年倦怠发生比例最高的是重症医学(48%)、神经医学(48%)和家庭医学(47%)。见表1。

(3)使用LinearSVC对数据进行分类。LinearSVC是根据liblinear实现的线性分类支持向量机,既能实现二分类,也能实现多分类。
1.4 脑激活定位
执行不同任务时会激活对应的脑区,为了探索这种相关性,借助分类结果,采用可视化的方式对其进行定位。相关实验表明,CNN的卷积层能提取输入数据的空间位置信息,因此卷积层具有定位的能力。基于此能力,可以获取图像中影响CNN决策的关键因素。但是为了整合卷积层所提取的特征,CNN网络使用了全连接层,这样破坏了CNN的定位能力。为了解决这个问题,Zhou等[16]提出了类激活映射(class activation mapping,CAM)解释方法。CAM以热力图的形式可视化类激活图,即使用全局平均池化(global average pooling,GAP)替代CNN最后的全连接层。CAM虽然能减少CNN的训练参数,但是造成了网络结构的改变,所以需要重新训练网络,这无疑是很耗时的一项工作。因此,本文采用效率更高的Grad-CAM方法,Grad-CAM是CAM的一种泛化形式,该算法不需要对网络重新训练。Grad-CAM的计算为

式中:c为网络判别的类别;yc为该类别对应的logits(即没经过Softmax的值);A为卷积输出的特征图(最后一层卷积);k为特征图的第k通道;i、j分别为特征图的横、纵坐标;Z为特征图的大小(即长×宽)。
这一过程是求特征图上梯度的均值,相当于一个全局平均池化操作。
得到权重后将特征图在通道维度上进行线性加权,融合得到热力图,如式(6)。Grad-CAM对融合后的热力图增加一个ReLU操作,只保留与结果呈正相关的值。
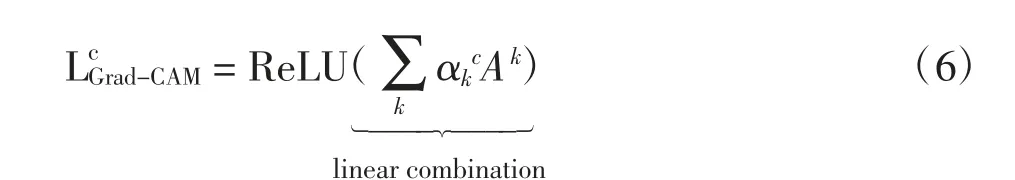
一般来说,Grad-CAM在2D数据上会有更好的表现。因此,从3D数据fMRI中提取Axial方向的2D切片,再把提取出来的切片作为Grad-CAM的输入。
Grad-CAM是一种以粗粒度的方式对影响CNN决策的关键因素进行可视化的方法,缺少了如GuidedBP[17]这样像素级别的细粒度可视化效果。因此,本文继续采用Guided Grad-CAM,对CNN网络进行细粒度的可视化解释,Guided Grad-CAM由Grad-CAM与GuidedBP结合而成。在GuidedBP中,舍弃第一层卷积层,直接获取第二层卷积层的梯度。
2 实验结果与分析
本实验硬件环境基于Windows平台,配置为11 th Gen Intel Core i7-11800H,NVIDIA GeForce RTX 3070显卡。实验代码均使用Python编程语言。
为了更好地对比3D-CNN与SVM的性能,采用4个常用的评价指标:准确率(Accuracy,ACC)、精确率(Precision)、召回率(Recall)以及F1-score。表1展示了4种任务态在不同模型中各个评价指标的情况。
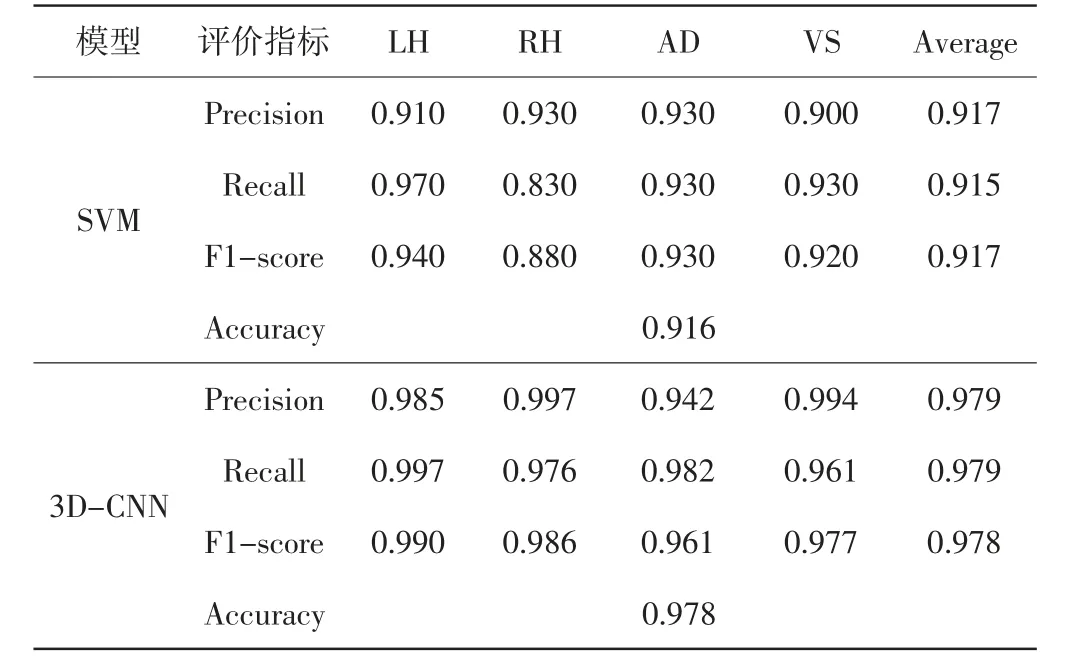
表1 SVM和3D-CNN模型在不同评价指标上的表现
从表1可知,3D-CNN在各个指标上的数据都优于SVM,产生这种现象很大程度上是由于三维fMRI数据在转换为一维数据过程中丢失了信息。而3DCNN的输入是原始数据,因此很好地保留了数据的空间特征。
图4为3D-CNN模型在训练时的损失曲线,从图4可以看出,模型在40次迭代后已基本趋于收敛。

图4 3D-CNN训练时的损失曲线
可视化结果如图5所示。
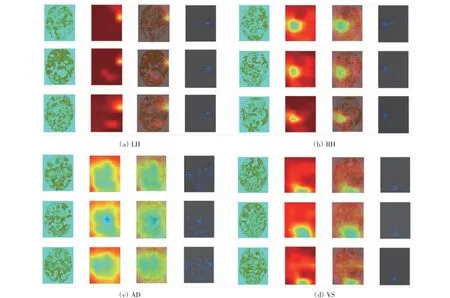
图5 Grad-CAM和Guided Grad-CAM在4种不同t-fMRI上的可视化结果
从4种不同t-fMRI中分别选出3幅在Axial方向的图像。在每张图中,第1列为原始图像,第2列为Grad-CAM中的热力图,第3列和第4列分别为Grad-CAM和Guided Grad-CAM的可视化结果。相关研究表明,当人使用左(右)手时,右(左)脑会产生反应。大脑中负责听觉处理的主要部位是颞横回,距状沟则负责视觉处理。其中,颞横回位于大脑外侧沟下壁上,距状沟位于脑半球内侧面后部。对比图5发现,其可视化结果与实际研究相符,即左(右)手握紧激活右(左)脑区,听觉刺激激活大脑中央,视觉刺激激活大脑后部。
3 结语
本文提出的3D-CNN模型能很好地对任务态fMRI进行分类,与传统机器学习算法SVM相比,3DCNN具有更好的分类效果,其能直接对t-fMRI进行分类,无需人为特征提取,并且避免了高维数据转换为一维数据时造成的空间信息丢失。通过采用Grad-CAM和Guided Grad-CAM对3D-CNN进行可解释性研究,确定了不同任务状态下所激活的大脑区域,从而达到通过t-fMRI解码大脑活动状态的目的。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中国临床医学影像杂志(2021年6期)2021-08-14 02:22:00
海洋信息技术与应用(2020年1期)2020-06-11 12:43:56
中国生殖健康(2020年6期)2020-02-01 06:29:06
传媒评论(2019年4期)2019-07-13 05:49:14
电子制作(2019年11期)2019-07-04 00:34:38
中国生殖健康(2018年6期)2018-11-06 07:09:42
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
