
基于图神经网络的工艺表格语义相似性度量
2023-01-12 12:31顾星海鲍劲松
计算机集成制造系统 2022年12期
花 豹,周 彬,顾星海,鲍劲松
(东华大学 机械工程学院,上海 201620)
0 引言
机械工艺规划是一种需要依靠先验知识的重用设计过程,它所制定的加工工艺规程蕴含大量的工艺知识。据统计,约40%的新产品会重用相似产品的加工工艺规程,约40%会对相似产品的加工工艺进行一定修改,只有20%需要全新的工艺设计[1]。因此,有效、准确地度量不同工艺规程的相似工艺,用以工艺重用,对于缩短产品工艺设计周期具有重要意义。但大部分工艺规程都以表格形式记录,以非结构化文档图像为载体。这使得工艺表格的内容呈现出复杂、多样的特点,且文字不可直接编辑和利用。此外,工程师在重新设计新产品的工艺表格之前,会从已有成功实例中人工寻找相似的工艺表格[2],但人工评判不同工艺表格的相似工艺往往带有主观因素,无法完全涵盖语义信息,不准确且效率低,严重影响设计效果。目前,在工艺重用中,尚缺乏有效评估相似工艺规程的相关研究。
挖掘工艺表格中的语义信息,进而评估不同表格实例的相似工艺正成为一个热点研究。首先需要提取表格信息,将不可编辑的字符转换成可编辑的形式。目前,表格信息提取研究大多基于表格检测与光学字符识别(Optical Character Recognition, OCR)[3-5]文字识别技术。表格检测是为了定位表格区域,排除其他非表格元素的干扰,然后利用成熟的OCR技术识别表格文本。AMARNATH等[6]提出表格框线检测的方法,定位表格区域,用于手写文档图像的表格信息提取;吕志刚等[7]提出融合局部图像特征的表格检测算法,应用于OCR信息识别软件;MILOSEVIC等人[8]提出模板匹配的方法识别表格及其单元格,用以提取表格信息。但上述方法都基于启发式规则,泛化性较差,因此为了提高泛化性,不少学者倾向于采用深度学习的方法。GILANI等[9]采用Faster R-CNN(faster region-based convolution neural networks)检测文档中表格区域;SUN等[10]则在文献[9]的研究基础上增加表格框角点定位的方法,用以提升表格检测精度。而定位表格区域是为了排除非表格元素干扰,从而保证OCR技术提取表格文本的效果。
提取表格信息之后,需要进行不同表格工艺信息的相似性度量,为工艺知识重用提供支撑。目前,工艺相似性度量方法可大致分为:
(1)基于传统的方法。常智勇等[11]基于编辑距离计算加工意图字符串间的相似性,用于工艺重用;李秀玲等[12]通过向量空间模型将工艺实例向量化表示后,基于奇异值分解和二范数计算工艺实例间的相似度,用于合并相似的工艺知识;万姗等[13]基于本体概念度量数控维修案例间的相似性,用于重用历史维护案例知识,提高维护服务效率。但传统方法都无法处理工艺信息间的联系及其深层语义。
(2)基于深度学习的方法,又可分为基于文本向量和基于图谱向量两种方法。基于文本向量的方法是在词向量的基础上,通过训练将文本表示成向量并计算距离以表征语义相似度[14]。陈治宇等[15]基于Word2vec将装配工艺语素嵌入成词向量计算距离得到词与词的相似度,用于装配工艺文档词素分类。但对于工艺表格而言,只将提取的文本映射成向量以度量相似性,会因缺失工艺表格特有的语义与结构特点,导致结果不准确。基于图谱向量的方法是将信息构建成图谱,根据图谱节点间的连接关系,通过训练将图谱表示成向量服务于下游任务[16-17]。例如TransE[18]系列模型和GraphSAGE[19]、Graph2vec[20]等图神经网络模型,但TransE系列模型将图谱分解为互不相关三元组的有限集合,仅关注单条三元组信息的嵌入表示,对图谱上下文信息的编码能力较弱,因此无法用于全局语义相关的工艺表格。Graph2vec利用子图的有序结构表示图谱的结构特征,可以弥补TransE的缺陷,但是它仅能提取网络的结构特征,无法提取节点的属性。而GraphSAGE通过邻居采样和聚合操作可以学习图谱中节点的嵌入表示,但它只考虑局部拓扑结构,无法扩展到全局结构,因此会损失具有强刚性结构特点的工艺表格的大量结构信息[21]。
综上所述,现有方法主要由于无法有效提取工艺表格的各种特征,导致不适用于度量工艺表格的相似性。因此,本文以PDF格式及图像存档的工艺表格文档为研究对象,首先分析了工艺表格的结构与语义特征,为了提升工艺表格检测精度,提出了改进的Mask R-CNN网络精准定位工艺表格区域并利用OCR识别其文本信息;然后针对其中的关键单元文本,构建了具有工艺表格结构特性与语义关系的图网络模型,以图结构的形式表示工艺表格,并作为特征提取算法的输入。接着,结合Graph2vec和GraphSAGE各自优点,提出图神经网络组合算法用以分别提取图网络模型的结构特征和节点属性,并以向量形式呈现;最后基于提取的特征向量,驱动提出的一种联合相似度综合评估方法, 用以支撑工艺表格的相似性度量。
1 表格特性分析及其区域检测
本章首先分析工艺表格的关键单元及其结构特性与语义关系,用于构建图网络模型中的边。之后提出改进的Mask R-CNN(mask region-based convolution neural networks)网络定位表格区域,用以排除非表格元素干扰;最后采用PaddleOCR模型识别表格文本,获得单元格文本框的位置信息与文本信息,用于构建图网络模型中的节点。
1.1 工艺表格特性分析
虽然不同企业制定的工艺表格结构和形式各不相同,但为起到在实际操作中的工艺指导作用,其基本组成要素(要素是工艺表格中属性值与属性组合成的键值对信息)大致相同,且工艺设计主要需要对象、资源和工艺等信息,其中的某些信息对它来说并不需要。例如签字、备注、审核等与具体工艺信息无关的内容,而工时单元是加工实时动态信息,缺乏工艺设计价值。因此,只需提取其中的关键单元(单元由要素构成,即具有同类性质的键值对集合),即工序、毛坯、零件、产品单元。其中:①工序单元指由工序号、工序名称、工序内容等用于描述零件加工工序信息的工艺表格规范组成部分,其内容占比最高;②毛坯单元指由材料牌号、毛坯种类、毛坯外形尺寸等用于描述加工原材料信息的工艺表格规范组成部分;③零件单元指由零件图号、零件名称等用于描述零件层面的属性信息的工艺表格规范组成部分;④产品单元指由产品名称、产品型号等用于描述产品层面的属性信息的工艺表格规范组成部分。此外,各个关键单元还具有各种结构特性与语义关系,如图1所示。
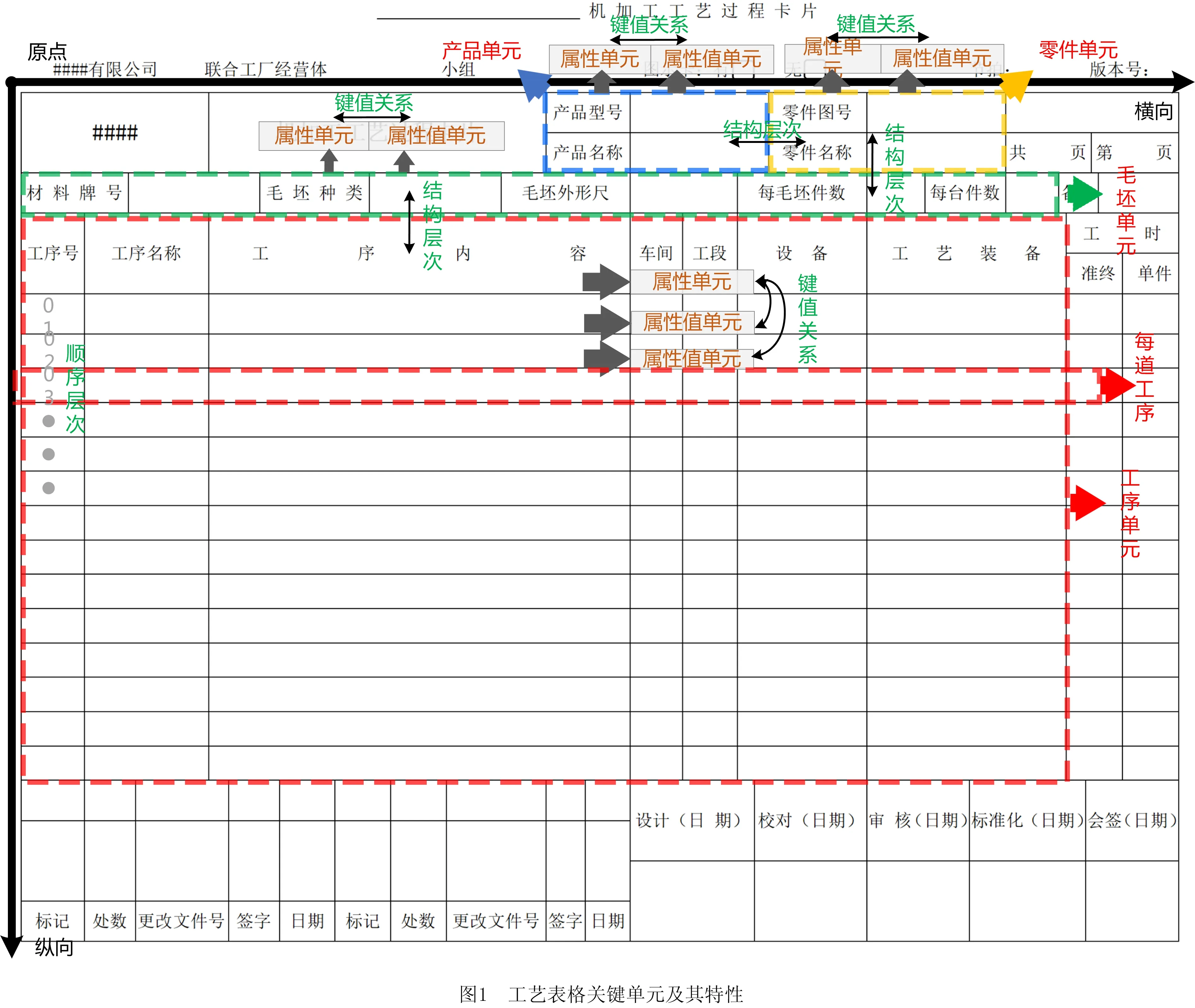
结构特性指关键单元所包含单元格的位置特征。其中:①工序单元的属性单元格同行,其属性值单元格同列,且一个属性单元格下方排列着多个属性值单元格;②产品单元与零件单元具有相似对称性,属性及属性值单元格的纵向、横向坐标分别对应相同,且属性单元格列于属性值单元格之前;③毛坯单元的属性及属性值单元格的纵向坐标相同,且相邻、交替,属性单元格列于属性值单元格之前。
语义关系指不同单元格文本的键值、属性、层次和约束关系。其中:①键值关系指属性值单元格文本是值,属性单元格文本是键,相互映射。②属性关系指属性单元格包含于关键单元中,例如毛坯单元包含材料牌号、毛坯种类等属性单元格。③层次关系包括结构层次和顺序层次。结构层次指关键单元间的语义逻辑关系,例如产品单元是零件单元的上结构层次、工序单元是毛坯单元的下结构层次等。顺序层次指工序单元中每行表示一道工序,众多工序间有加工顺序关系。④约束关系指一些属性值单元格的制定受制于某些属性值单元格的内容,例如工序内容直接影响工段、设备等单元格制定。综上所述,从结构特性上反映出表格结构特点,从语义关系上反映出工艺的层次性、语义关联等特点,是后续构建图网络模型中边的依据。
1.2 工艺表格区域检测
为了获得关键单元的文本信息,需要定位表格区域,降低由其他非表格元素混入带来的干扰。目前,表格定位的研究方法可分为传统图像处理与深度学习两个方向。传统图像处理无法实现自适应的表格区域检测,而深度学习的方法克服了自适应文档表格的识别问题。例如Faster R-CNN[9]、Mask R-CNN[26]、YOLO[27]等,但是它们只能处理文档中的简单表格,不适用于结构复杂,边界特征不突出的工艺表格,并且表格检测准确率还有大量的提升空间。因此,本文设计了一种改进的Mask R-CNN网络用于工艺表格检测并提高精度。如图2所示。首先采用Mask R-CNN网络[22]检测表格区域。因为Mask R-CNN实现了像素级别的精度对齐。具体而言,Mask R-CNN使用区域特征聚集(RolAlign)代替了Faster R-CNN的区域特征池化(RoIPooling)提取感兴趣区域(Region of Interest, ROI)的特征。RoIPooling使用取整量化,导致Feature map(特征图)的ROI存在尺度误差;RolAlign不使用取整量化,而采用双线性插值获取浮点数坐标在像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。
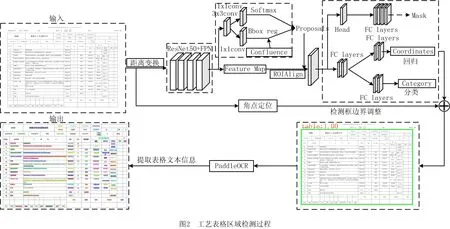
其次,由于Mask R-CNN网络通常用于自然图像的物体检测,为了使其能够兼容非常规物体的表格,本文对表格图像分别做欧几里得、线性和最大距离变换并合并结果[9],用以计算文档图像中文本区域和空白区域间的距离,更好地突出表格区域,使其贴近自然图像。
然后,为了保证检测框的精准预测,本文采用Confluence算法[23]替换Mask R-CNN中的优选目标框操作—非极大抑制(Non Maximum Suppression, NMS)算法[24]。因为NMS算法取IOU值(交并比,即两个框的相交部分面积/相并部分面积)最高的目标框,去除低值框,但当IOU值最高的目标框不是最优时,它返回次优目标框,所以结果并不是最优。而Confluence算法通过曼哈顿距离来度量目标框间的交汇度,然后通过置信度加权得到最优框,最后通过和最优框的交汇程度去掉其他假阳性框。该方法不仅不依赖于IOU值消除误检,还可删除附近的高重复框,效果好于NMS算法。
最后,本文将角点定位的方法迁移到Mask R-CNN网络中,进一步提升表格检测精度。角点定位指在检测表格框的同时检测表格的4个角点并划分为角点组,若同行角点的纵坐标或同列角点的横坐标差值超过设定阈值则被过滤。对检测框的4个角点坐标与角点组的4个角点坐标做算术平均数,得到新的4个角点坐标用于调节检测框,从而提升表格检测精度。
检测出表格区域后,本文利用Paddle OCR[25]模型识别表格文本,增大字段阈值(即判断为同一字段的字符间距离),使得一个单元格中的所有字符划分为一个文本框字段,最后获得文本框的位置信息和文本信息,用于后续图网络建模。
2 工艺表格建模与相似性度量
上述提取工艺表格文本信息是为了挖掘语义特征、度量工艺相似性。依据1.1节,关键单元的工艺信息具有语义关联、结构层次等特点,适合于用图结构的数据描述。因此,本文对关键单元的工艺信息进行图网络建模,同时,为了高效地提取图网络模型特征度量工艺表格的相似性,本文结合Graph2vec和GraphSAGE各自优点,提出一种图神经网络组合算法分别提取其网络拓扑结构与节点属性特征并以低维实值向量形式表达,支撑提出的联合相似度综合计算工艺表格相似性的方法。
2.1 工艺表格的图网络建模
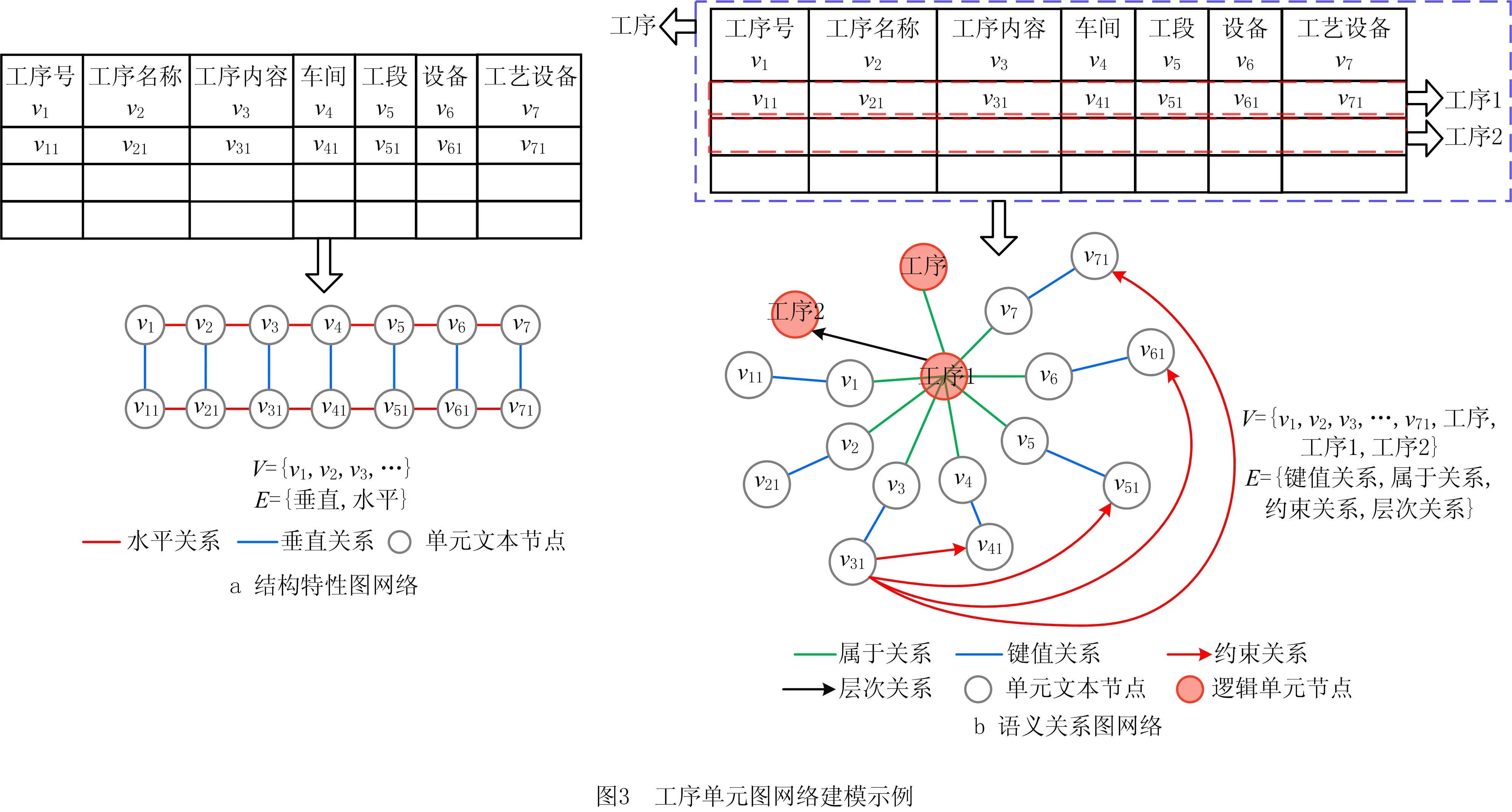
对关键单元的工艺信息进行图网络建模时,为了保留工艺表格的结构特性与语义关系,本文提出分别构建结构特性的图网络与语义关系的图网络。
(1)依据结构特性的图网络建模是指融合了关键单元文本的结构及位置特征。如图3a所示,将每个关键单元文本框看作一个节点v,文本框与其邻居文本框间的垂直与水平关系看作节点间的关系边E,依据文本框位置,构建无向图GStru_char=V,R,其中:V表示节点集合,R表示边E的关系集合,R=E×{垂直关系,水平关系}。节点属性包括文本框的位置属性与文本属性,位置属性是将文本框的绝对位置转化为相对位置;文本属性是文本框的文本信息经BERT(bidirectional encoder representation from transformers)模型转换为文本向量。
(2)依据语义关系的图网络建模是指融合了工艺信息间的语义关联特征。如图3b所示,它不仅将每个关键单元文本框作为一个节点v,还将4个关键单元以及每道工序看作一个逻辑节点。依据1.1节的4种语义关系确定边E,构建混合图网络GSema_rela=V,R,其中:V表示节点集合,R表示边E的关系集合,R=E×{键值关系(无向边),属性关系(无向边),层次关系(有向边),约束关系(有向边)}。节点属性仅具有与结构特性图网络相同的文本属性。
由于工艺信息具有相对重要性,需要设定节点权重Wv和边权重WE,设定依据有3条:
(1)各个边权重WE相等:W键值=W属性=W层次=W约束,W水平=W垂直。其中W键值,W属性,W层次,W约束分别表示具有键值、属性、层次、约束关系的边权重;W水平,W垂直分别表示水平、垂直关系的边权重。
(2)工艺表格着重描述的是零件的加工工艺,而毛坯是零件加工的基础,工序单元蕴含信息量又大于毛坯单元。因此,产品、零件、毛坯、工序单元中各个节点权重Wv关系为:W工序>W毛坯>W零件>W产品。其中W工序,W毛坯,W零件,W产品分别表示工序、毛坯、零件、产品单元中的各个单元格文本框表示的节点权重。
(3)约束关系使得某些节点的重要性大于其他节点,而具有约束关系的节点必有键值关系。因此为了增加特征提取时重要节点的信息传输概率,增大约束方节点的键值关系的边权重:
(1)

本文基于层次分析法(Analytic Hierarchy Process, AHP)[26]构建层次模型计算节点与边的权重,采用1~9分标度法,如表1所示。

表1 工艺表格图网络的节点或边权重标度
依据标度法构造判断矩阵B,并计算特征根和特征向量:
BW=λmax。
(2)
其中:λmax为B的最大特征根;W为对应于的正规化特征向量,其各个分量即为权值。
最后检验矩阵的一致性,计算它的一致性指标CI,并查询随机一致性指标RI,计算不一致性指标CR,公式如下:
(3)
(4)
其中n为指标个数。若CR在允许范围内,则权重有效,否则返回修改判断矩阵,直至通过。
依据上述图网络建模方法,可以对工艺表格关键单元中的文本信息分别构建结构特性图网络集合和语义关系图网络集合。
2.2 图网络模型的特征提取
为了高效提取图网络模型的结构特征与节点属性,用以评估工艺表格相似性,本文提出将Graph2vec提取结构特征时可扩展全局结构的优点与GraphSAGE提取节点属性时融合局部拓扑结构、聚合邻居信息、可扩充节点属性的语义丰富性的优点相结合,弥补Graph2vec无法提取节点属性与GraphSAGE无法扩展全局结构的缺点,形成一种有效适用于工艺表格特征提取的图神经网络组合算法,为工艺表格相似性的度量提供数据支撑。
2.2.1 结构特征提取
Graph2vec用于提取网络结构,具有较好的全局及局部结构提取能力。其原理为首先通过对所有图网络模型中的所有节点进行有根子图采样,获得总有根子图集合。有根子图定义:每次循环遍历图中各个节点时,以当前节点作为根节点,沿着与之相连的各个路径分别进行不同深度的节点采样,而得到的子图网络。然后最大化地随机预测每个图网络的有根子图出现在子图集合中的概率,得到每个图网络的结构特征向量,若两个图网络结构特征相似,则其有根子图往往也相似。其过程如图4所示。
算法1有根子图采样GetWLSubGraph(v,G,d)。
输入:v表示子图的根节点。G=(N;E;λ)表示要抽取子图的图网络,d表示抽取子图时被遍历节点的度,E表示图网络中的边集合,N表示图网络中的节点集合。

/*子图集合初始化*/
/*深度d=0时退出递归*/
(2)if d=0 then
(4)else
(5) Nn:={n′|(n,n′)∈E}
/*递归遍历*/
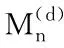
/*合并递归遍历的结果*/

/*将图G中以n为根节点的深度为d-1的有根子图与排序列表进行连接*/
(10)end
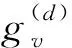
(5)
(6)
(3)最后修正输出的图网络向量表示矩阵:Φ=Φ-α(∂J∕∂Φ),α为学习率,Φ为输出图网络集合的向量表示矩阵,其中每列表示每个图网络的结构向量表示V结构=Φi,其中,i表示第i列,即第i个图网络的结构特征向量。具体过程见算法2伪代码。
算法2结构特征提取Graph2vec(G,D,σ,e,a)。
输入:子图集合G={G1,G2,…,Gn};子图采样的最大深度D,依据此参数会生成subgG,嵌入维度σ,迭代次数e,学习率a。
输出:所有图网络的向量表示矩阵Φ∈R|G|×σ。
/*随机初始化矩阵*/
(1)Initialize Φ∈R|G|×σ;
/*迭代*/
(2)for k=1 to e do
/*随机排序所有图*/
(3) list=SHUFFLE(G);
/*初始化*/
(4) for each Gi∈list do
(5) for each n∈Nido
(6) for d=0 to D do
/*修正Φ*/
(9) Φ=Φ-a(∂J∕∂Φ);
/*返回向量表示矩阵*/
(10)return Φ;
(11)end;
2.2.2 节点属性提取
Graph2vec虽有效提取了网络的结构特征,但无法提取节点的属性特征;而GraphSAGE是一种可以利用邻居节点的属性信息高效产生目标节点属性特征的归纳式学习框架,非常适合提取网络节点的属性特征。其原理是结合目标节点的局部结构,通过节点链接进行多层邻居节点采样,最后通过多层聚合函数不断融合邻居节点的信息,以获得目标节点的属性信息,其过程如图5所示。

(1)首先,图网络表示为G(V,E),每个节点表示为v,两节点间的层数表示为k,对图网络中的目标节点的邻居节点进行k层采样,作为待聚合信息的节点。
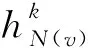
(7)
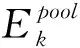
(3)最后,对所有节点属性的特征向量进行加权平均,结果作为整个工艺表格图网络的节点属性特征表示V属性。具体计算见算法3伪代码。
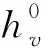
(8)
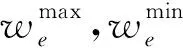
(9)
需要对聚合函数中的参数进行学习。本文采用无监督学习损失函数,它倾向于使得相邻的节点有相似的表示,使相互远离的节点表示差异变大,公式为:


(10)
式中:zu表示节点u通过GraphSAGE生成的向量表示,节点v是节点u的固定长度随机游走到达的邻居节点,σ为激活函数,Pn是负采样的概率分布,Q是负样本的数目,vn是负样本,E是期望。负采样是指采样里距离目标节点zu较远的节点。
算法3节点属性提取。
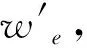
输出:所有节点向量表示V属性。
/*节点特征初始化*/
/*遍历节点,邻居采样,聚合信息*/
(2)for k=1,…,K do
(3) for v∈V do
/*有权聚合与拼接*/
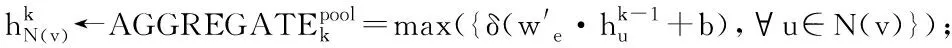
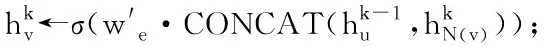
(6) end
/*生成目标节点的属性特征向量*/
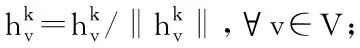
(8)end
/*所有节点生成的属性特征向量加权平均*/
(10)end
2.3 工艺表格的联合相似性度量
通过结构特征提取与节点属性提取分别得到图网络模型的结构特征向量与节点属性特征向量,之后采用余弦相似度各自计算相似度。但是孤立评价相似性无法相互协调结果,且边、节点数量及其属性维度往往不平衡,需要调节结构与属性相似度。因此,本文提出一种联合相似度综合评估两者,并设定阈值T,联合相似度定义如下:
Sim=λsim结构+(1-λ)sim属性。
(11)
其中:0<λ<1;sim结构、sim属性分别表示结构特征余弦相似度与节点属性余弦相似度;Sim表示联合相似度。若联合相似度超过阈值,比较的两张工艺表格相似,反之,则不相似。
3 实验分析
3.1 表格检测分析
3.1.1 实验准备
本文以变速箱轴承座工艺表格实例作为实验对象共500张,利用旋转、缩放等方法扩充至1 000张,按照8∶2的比例划分训练集与测试集,用于训练改进的Mask R-CNN网络。需要说明的是工艺表格不仅针对机械制造工艺,还适用其他领域,如纺织服装生产工艺等。实验环境配置参数:Intel(R)Core(TM)i5-10400F @2.90 GHz CPU、NVIDIA GeForce RTX2060显卡、Win10操作系统。
3.1.2 实验结果
训练参数设置:批量训练尺寸取16,初始学习率取0.001,权重衰减系数取0.000 5,迭代次数epoch取500,参数更新方法采用梯度下降法。经过训练获得损失函数和精确度在训练集和测试集上随迭代次数收敛的曲线如图6所示。
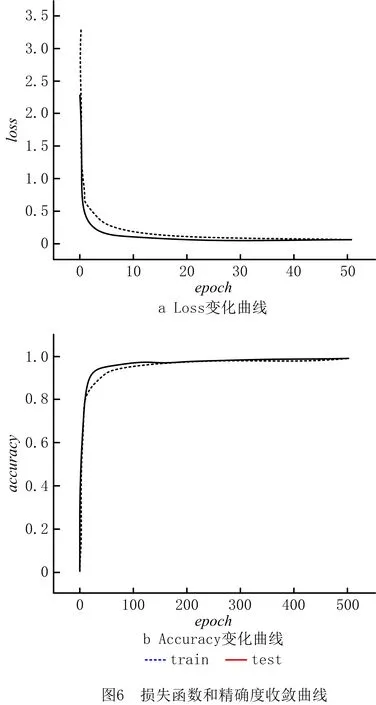
迭代200次左右,loss值基本不再下降,在测试集上的精度值最优为98.47%。为了体现改进方法的优势,图7给出了所提方法中改进策略的表格处理效果对比。

图7a为距离变换后突显的表格区域;图7b表明角点定位微调的检测框精度更高;图7c表明Confluence算法保留的候选框没有非表格元素干扰,效果优于NMS算法;图7d表明ROI Align比ROI Pooling在提取ROI特征时误差更小。
为了验证本文改进的Mask R-CNN的有效性,与表格检测领域的其他常用方法进行比较,使用精确率(P)、召回率(R)和F1值作为评价指标,实验结果如表2所示。

表2 改进方法与其他方法对比
Mask R-CNN(NMS)比Faster R-CNN(NMS)的精确率高4%左右,Faster R-CNN(NMS+corner)比未引入角点定位的Faster R-CNN(NMS)的精确率高4%左右,表明本文改进策略的有效性,而与未改进的Mask R-CNN相比,本文改进的Mask R-CNN的精确率提升约5%,与加入角点定位的Faster R-CNN相比精确率提升约4%,结果表明本文改进的Mask R-CNN表格检测方法效果有所提升。
3.2 相似性度量分析
3.2.1 图网络建模及评价指标
本文事先以专家经验在500份工艺表格数据集中确定了125个相似对和125个非相似对,即具有相似和非相似工艺的工艺表格,为防止数据冗余,每张工艺表格仅允许被划分为一个相似对或非相似对。在对其进行表格检测和OCR识别之后,获得单元格文本框,针对其中关键单元的文本框分别构建结构特性图网络和语义关系图网络数据集,按照8∶2的比例划分训练集与测试集。表3为本文研究的表格样本的特征分析。表4为本文图网络数据集的统计情况。

表3 表格样本特征分析

表4 图网络数据集节点与关系统计
其中对于权重计算,首先依据表(1)构造4种单元节点权重的判断矩阵,如表5所示。
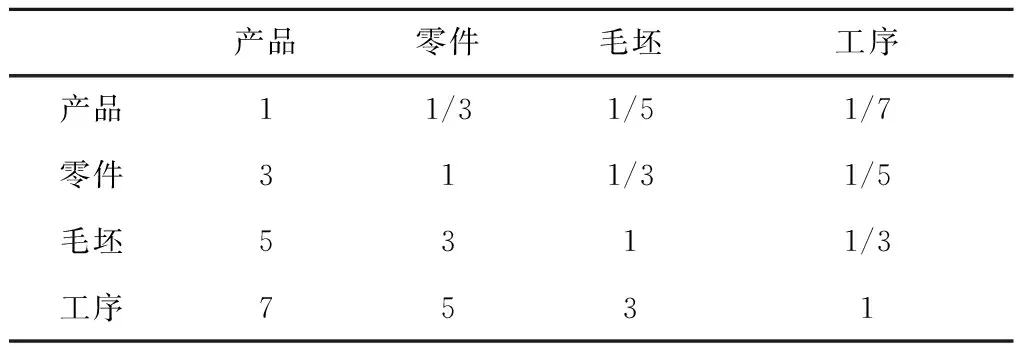
表5 四种单元节点权重的判断矩阵

本文以AUC(area under curve)[28]为评价指标,它是由预测的ROC曲线和横坐标包围面积计算得来的,用以衡量一个二分类模型性能的好坏,AUC值越大表示相似对与非相似对的分类效果越好,实质是工艺表格特征提取能力越强,使得相似性推理效果越好。本文以SN205滚动轴承座工艺表格为样例分别建模结构特性与语义关系的图网络,如图8和图9所示。
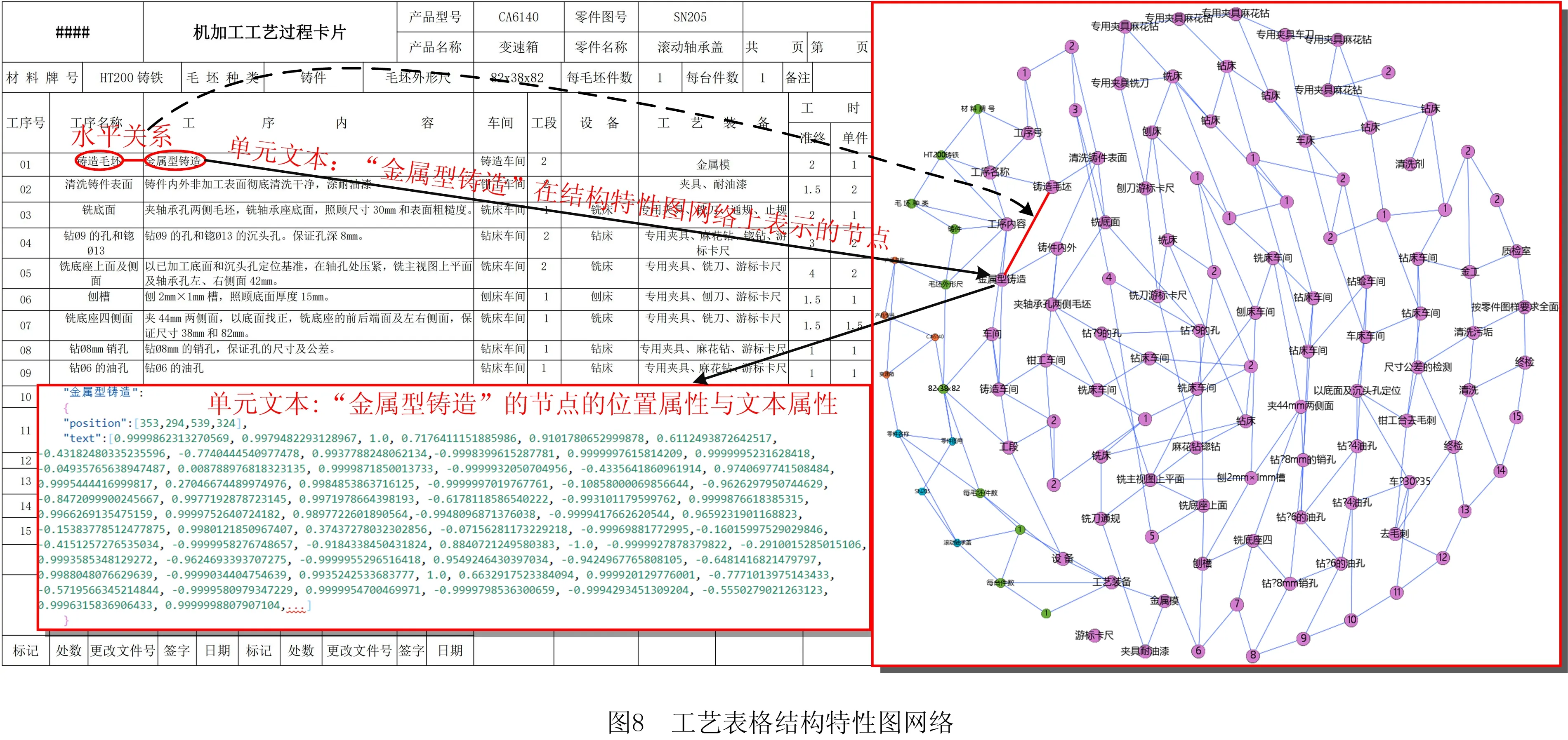
3.2.2 实验结果
在Graph2vec实验中,使用随机梯度下降算法来学习模型参数,初始学习率为0.001,负采样率设置为0.000 1,训练批次设置为16,epoch设置为50,嵌入维度设置为1 024。Graph2vec使用随机梯度下降优化算法2第8、9两行的参数,使用反向传播算法估算导数,依据经验调整学习率a,由于训练过程中整个子图集合规模较大,本文采用负采样方法提高效率,即在训练时,选择不属于子图集Gi的k个子图样本c′={subg1,subg2,…,subgk},c′subgG,k<<|subgG|,c∩c′={},每个负样本都不存在于需要表示学习的图Gi中,而是存在于子图总集合中,在训练时只更新负样本的向量表示而不是整个子图集合,达到简化样本规模的目的。
在GraphSAGE实验中,使用Adam优化器来学习模型参数,初始学习率为0.001,负采样率设置为0.000 1,训练批次设置为16,epoch设置为50,嵌入维度设置为256,聚合层数设置为2。GraphSAGE采用无监督学习方式训练聚合函数从节点的邻域聚合邻域节点的特征信息,通过前向传播得到目标节点的向量表示,然后使用Adam梯度下降进行反向传播优化式(7)聚合函数内的参数。
本文分别使用Graph2vec和GraphSAGE提取图网络模型的结构特征向量和节点属性向量,之后将两者作为联合相似度评估方法式(11)的输入,计算出相似度大小,再根据设定的阈值评估相似对与非相似对。该过程如式(12)所示。
Sim=λsim属性+(1-λ)sim结构。
(12)
式中:sim属性、sim结构分别为两个工艺表格的属性与结构相似度值;V结构、V属性分别为工艺表格的结构与属性向量;Sim为联合相似度;λ一般设为0.5。
相似对的数量取决于联合相似度阈值T的设置,较大的阈值可以获得相似性大的相似对,而较小的阈值设定可以得到相似程度不同的相似对,通过设置不同的阈值挖掘相似对,可以发现适用于两种数据集的阈值大小[29]。本文比较了不同阈值T对AUC的影响,实验结果如图10所示。由结果可知,结构特性图网络、语义关系图网络的最优阈值分别为75%、85%。
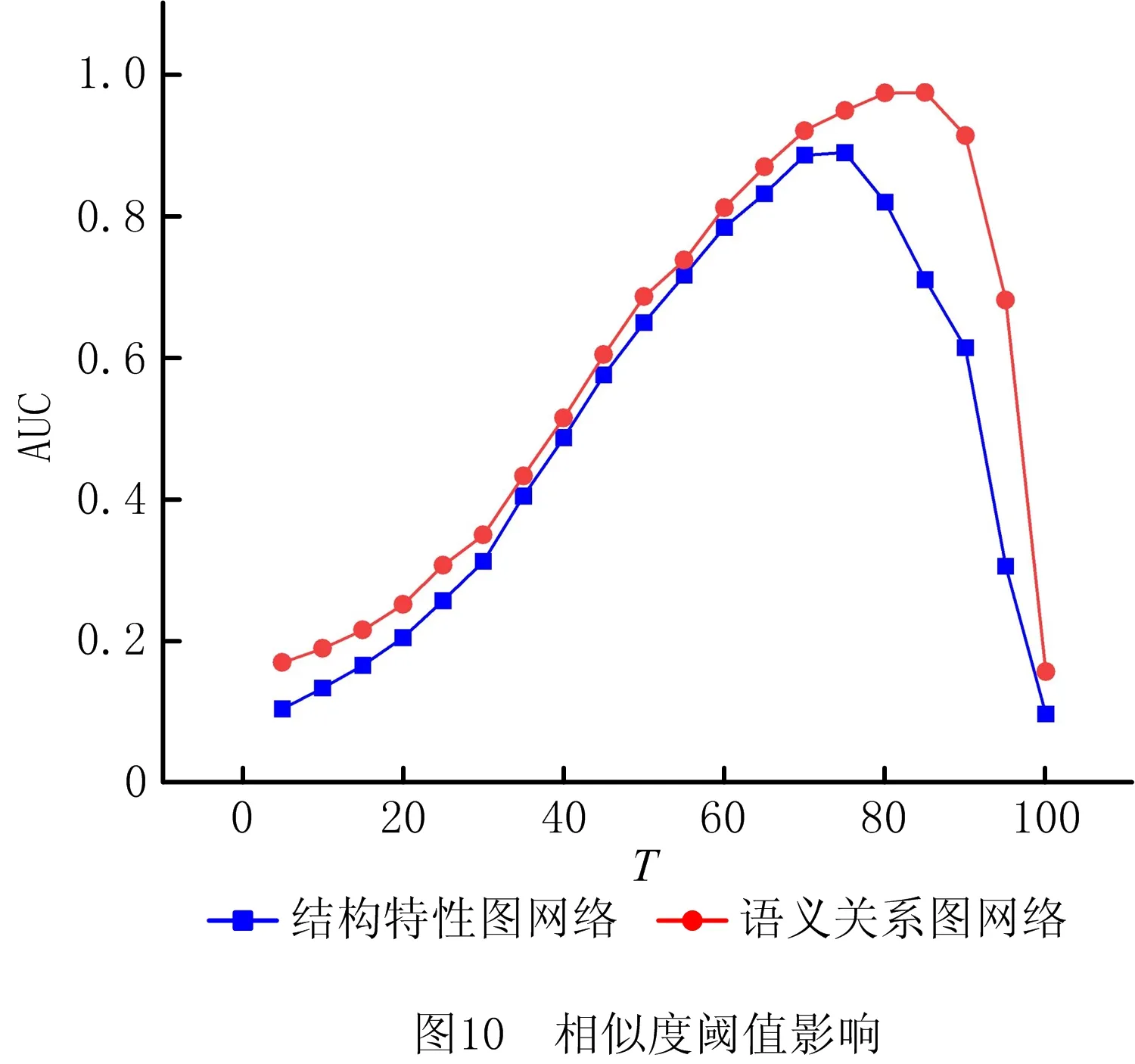
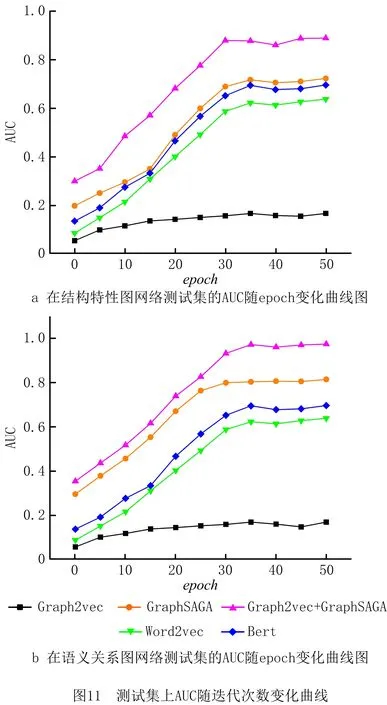
为了验证本文方法的有效性,与文本嵌入Word2vec[30]及BERT进行对比[31]。同时,为了研究哪种图网络最能真实反映工艺表格的工艺信息,本文对两种图网络数据进行了对比实验,均使用最优阈值来评判相似对与非相似对。图11为在测试集上的AUC随着迭代次数的增加,各个模型推理性能的变化曲线。
各模型在30个epoch后基本达到最优且趋于稳定,且本文方法的性能相较于其他方法最优。各模型最优性能时的AUC结果如表6所示。

表6 最优性能的各模型AUC对比
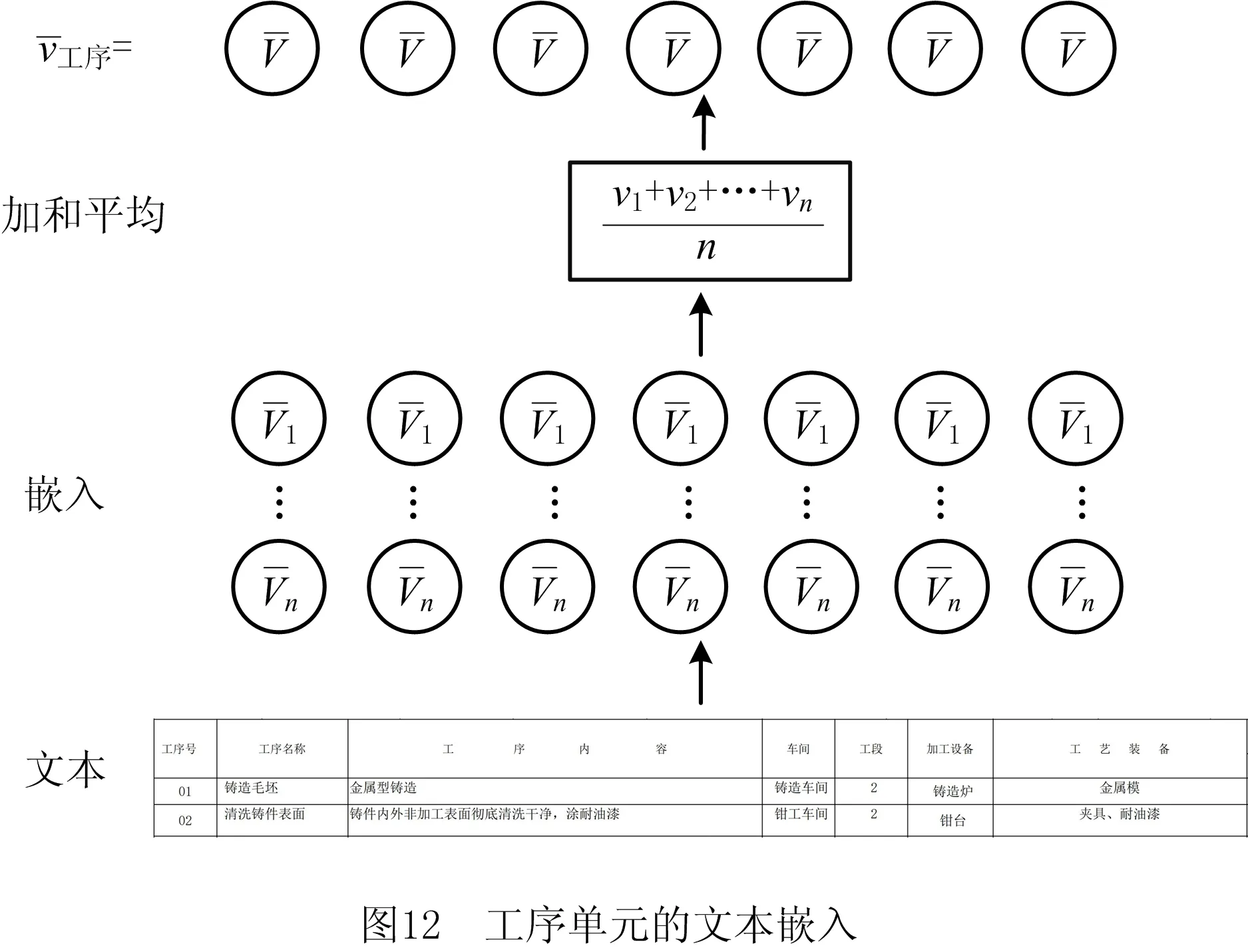
Graph2vec与GraphSAGE的消融实验是分别提取特征向量后直接利用余弦相似度值评估相似对,目的是探究各自影响。Word2vec与BERT的对比实验是以单元文本框为对象,以产品、零件、毛坯、工序单元为整体,将单元格文本嵌入成向量后,按列加和取平均向量作为各个单元文本的向量,以余弦相似度推理相似性。
(13)
(14)

如图12所示为工序单元的文本嵌入。它未保留表格特性,只考虑节点的文本属性,因此,表5中两种图网络数据的结果相同。
含有GraphSAGE的结果中,语义关系图网络的AUC比结构特性图网络的AUC平均多9%左右,而在仅有Graph2vec的结果中,两者相差不多,原因在于语义关系图网络含有丰富的语义逻辑,不但蕴含工艺表格的语义关系与文本信息,不受文本框位置的限制,而且语义关系也能如结构特性一样还原表格结构,结果表明语义关系图网络比结构特性图网络更能反映工艺表格的工艺信息。在仅有Graph2vec与仅有GraphSAGE的结果中,GrpahSAGE的AUC比Graph2vec的AUC平均多70%左右,原因在于Graph2vec仅能提取图网络的结构特征,而评判相似对的重要因素在于工艺表格的文本语义,结构特征无法反映工艺信息,而GraphSAGE不但可以提取大量的节点属性特征,而且邻居采样时结合了局部拓扑结构,既提取了节点属性,又提取了局部结构特征,因此效果要好于Graph2vec。除此之外,本文方法的AUC也是明显高于Word2vec、BERT的AUC,原因在于Word2vec、BERT未能保留工艺表格特性,无法提取包含语义关系的工艺表格特征,结果验证了本文方法的有效性。
3.2.3 实例验证
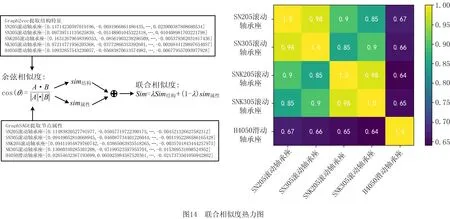
为了验证在语义关系图网络下,本文所提方法的可行性,将新编制SN205滚动轴承座的工艺表格与已有SN305滚动轴承座、SNK205滚动轴承座、SNK305滚动轴承座、H4050滑动轴承座的工艺表格实例进行工艺复用,其中,英文代号表示轴承座等径孔型号,同型号下数字代号越大表明轴承座各方面尺寸越大。先通过1.2节表格检测去除干扰信息并进行OCR识别表格,得到单元文本框,再依据2.1节构建5个语义关系图网络模型,如图13为其中两个实例的示意图。之后利用本文方法分别提取结构特征与节点属性,获得结构向量与属性向量,最后以热力图呈现计算的联合相似度,如图14所示。SN205滚动轴承座的工艺表格与SN305滚动轴承座、SNK205滚动轴承座、SNK305滚动轴承座、H4050滑动轴承座的实例的相似度对应分别为98%、90%、85%、67%,依据图10得到的语义关系图网络最佳相似对评估阈值P=85%,前3个相似度超过了阈值,表明与SN205滚动轴承座的工艺表格都具有相似工艺,其中与SN305滚动轴承座的工艺表格相似程度最高,可作为工艺重用设计的最佳选择,结果验证了该方法的可行性。
4 结束语
针对由于工艺表格结构复杂、工艺信息量大等特点,从而难以有效描述工艺表格中的复杂结构与丰富信息,导致人工度量工艺表格相似性的精度差、效率低的问题,本文提出一种面向工艺表格的图神经网络组合算法提取其特征信息,用以度量工艺表格相似性。本文所提方法的创新点如下:
(1)为了准确地检测表格,提出一种改进的Mask R-CNN方法,先利用距离变换增大表格区域特征,然后利用Confluence算法替换Mask R-CNN中NMS算法改进目标框择优效果,最后利用角点定位微调输出检测框的精度。实验结果表明,所改进的Mask R-CNN精确率提升约5%~7%左右。之后利用OCR技术提取检测的工艺表格文本信息。
(2)为了完备地描述工艺表格特性,将其划分成结构特性和语义关系两部分,进而,创新性地对关键单元的工艺信息设计了结构特性与语义关系图网络模型,为了提取模型的特征用以相似性度量,提出了Graph2vec与GraphSAGE图神经网络组合算法,提取工艺表格图网络的结构特征与节点属性,用以驱动设计的联合相似度评估方法匹配相似的工艺表格。实验结果表明该方法的AUC最优可达97.41%左右,比文本嵌入方法的AUC平均多24%左右,表明了提取工艺表格特征的有效性。以实例验证了该方法计算相似的工艺表格,用以工艺重用设计的可行性。

但是该方法并不是端到端的,且维度、样本量等对效果有一定影响。后续将研究结构特征与节点属性相互融合以实现端到端的相似性计算,并探究维度、数据集大小等对其有效性的影响。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
现代临床医学(2022年1期)2022-02-12
电脑爱好者(2021年12期)2021-06-22
电脑爱好者(2021年8期)2021-04-21
数学大王·趣味逻辑(2020年6期)2020-06-22
数学大王·趣味逻辑(2020年5期)2020-06-19
开放教育研究(2020年2期)2020-03-31
文化创新比较研究(2020年13期)2020-01-01
高中时代(2017年7期)2018-02-24
小天使·六年级语数英综合(2017年10期)2017-10-20
