
基于随机森林的二手摩托车残值率预估模型
2023-01-11 15:24梅培楠
现代计算机 2022年20期
牟 娇,梅培楠
(1.贵州大学人民武装学院,贵阳 550025;2.贵州中安云网科技有限公司,贵阳 550003)
0 引言
随着国民经济的发展与人民物质生活的提高,摩托车从传统的代步工具逐步向个性化、性能化、科技化发展,摩托车受众越来越广,二手摩托车演变成了个性化的二手摩托车交易,二手摩托车交易市场发展呈现大好前景[1]。
欧美日等国家的二手车已形成了一个体系成熟的市场,二手车价格评估由具有评估资格的相关部门根据二手车市场行情制定评估规则[2]。与国外成熟的二手车市场相比,国内二手车交易评估体系不健全,对车辆进行合理、准确的估值成为二手车交易亟待解决的问题。学者针对二手车的估值研究早已进行,二手车的估值影响因素维度多、且非线性,难以使用规律的方法进行评估,随着大数据与人工智能技术的发展,学者逐渐将机器学习方法应用于二手车评估问题,以其计算快、智能化、数据处理量大等优势成为研究的新热点[3-5]。
周凌云[3]早在2012年使用决策树进行汽车评测,具有良好的预测准确率;曹静娴[4]利用决策树、logistic回归和神经网络建立了不同的二手车性能评估模型,实现了对二手车性能的多种复杂混合因素在一定程度上的定量分析;刘聪等[5]将自适应提升方法(AdaBoost)应用于二手车价值的评估,提出一种以决策树桩作为弱分类器的集成方法,其准确率较传统决策树方法得到提高。
本文参考二手车估值模型的建立方法,收集二手摩托车交易数据,通过随机森林算法进行统计建模,建立二手摩托车残值率估值模型,以其对二手摩托车交易估值起到指导作用。
1 随机森林算法
随机森林(random forest,RF)方法是美国科学家Breiman[6]于2001年提出的一种统计学习方法,它是由并行式集成学习的Bagging方法与随机子空间方法(random subspace)相结合而形成[7]。随机森林是基于决策树的随机属性选择训练算法,随机森林算法具有抗噪性强、计算开销小等优点,可用于分类和回归任务[8]。二手车残值率输出为连续值,属于回归问题。近年来,国内外学者在众多领域中都使用了随机森林回归模型。许允之等[9]将随机森林算法应用于徐州雾霾预测研究,建立徐州空气质量指数回归预测模型,均方根误差在6左右,为徐州雾霾的形成原因以及治理措施提供了参考;王仁超等[10]基于随机森林回归方法建立了爆破块度预测模型,为堆石坝爆破施工管理与控制提供了科学指导;Osman等[11]使用随机森林回归模型进行机械钻速预测,指导钻井从业者以最小的时间和成本完成钻井项目;Ramalingam等[12]采用混合Harris Hawk优化随机森林算法(HHO-RF)建立了分散光伏电站的有效数据预测模型。
如图1所示,基于随机森林的二手摩托车残值率预估模型的预测步骤如下:
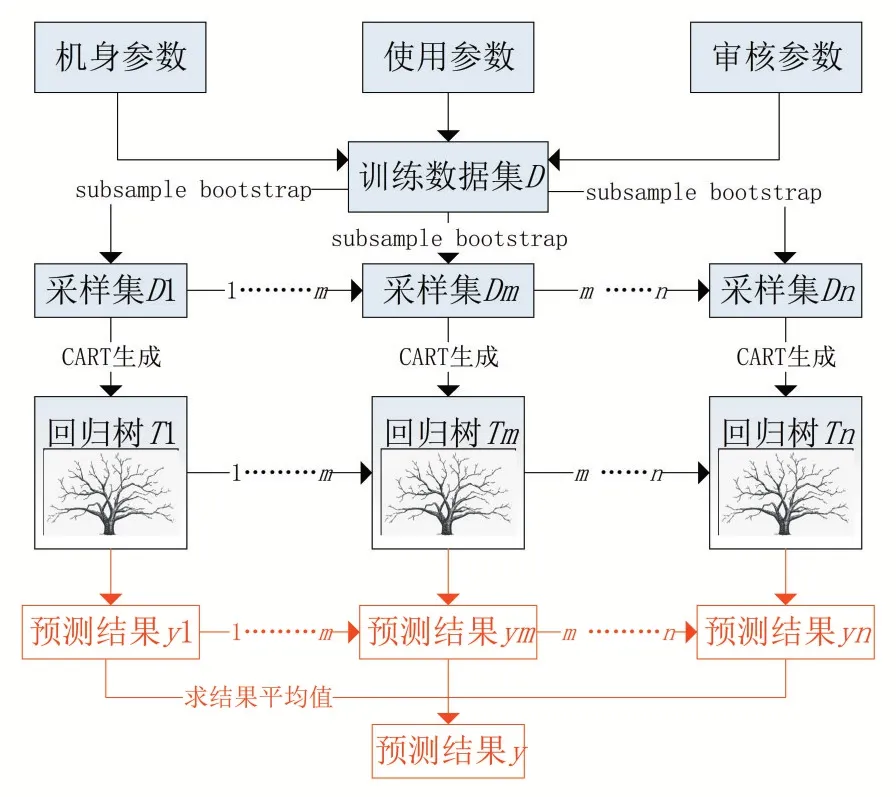
图1 基于随机森林的二手摩托车残值率预估模型的预测步骤
(1)构建训练数据集:将二手摩托车的成交残值率作为模型的输出变量(标签值),摩托车机身参数、使用参数及审核参数作为模型的输入变量(属性值),标签值及属性值组成训练数据集D。
(2)构建随机森林:对数据量为m的训练集D进行m次随机采样,得到样本量为m的采样集D';在所有属性中随机选择K个属性特征,建立决策树回归模型;重复以上步骤T次,建立T棵回归决策树,构成随机森林。
(3)预测二手摩托车残值率:将预测集中的属性值输入到训练完成的模型中,模型将会计算T棵决策树的回归结果平均值作为其输出结果,得到摩托车残值率。
2 模型特征选取与预处理
影响二手摩托车残值率的主要变量有:机身参数、使用参数及审核参数。
2.1 摩托车机身参数
发动机参数选择发动机型号、排量、环保标准、供油方式作为输入特征;车体参数选择座高、油箱、整备质量、abs、冷却类型作为输入特征。
2.2 摩托车使用参数
摩托车使用参数包括:车龄、行驶里程、上牌城市。上牌城市对二手摩托车价格有显著影响。
2.3 摩托车审核参数
摩托车审核参数包括:车况等级、车主报价,车况等级由人工标注,分为优秀、良好、一般、较差、很差。
本文数据来源于某二手车交易网站数据库,数据存在异常值、缺失值、重复值等问题,在数据进行模型训练前针对不同特征进行数据预处理,如行驶里程单位统一为km;为车身颜色、座高、整备质量等缺省值补上该车型的默认配置;若某一数据缺省特征值超过1/3,删除该数据。数据预处理后,剩余有效数据约6975条,随机划分测试集与训练集,1/4数据作为测试集,3/4数据作为训练集。数据预处理后的部分特征数据集见表1。
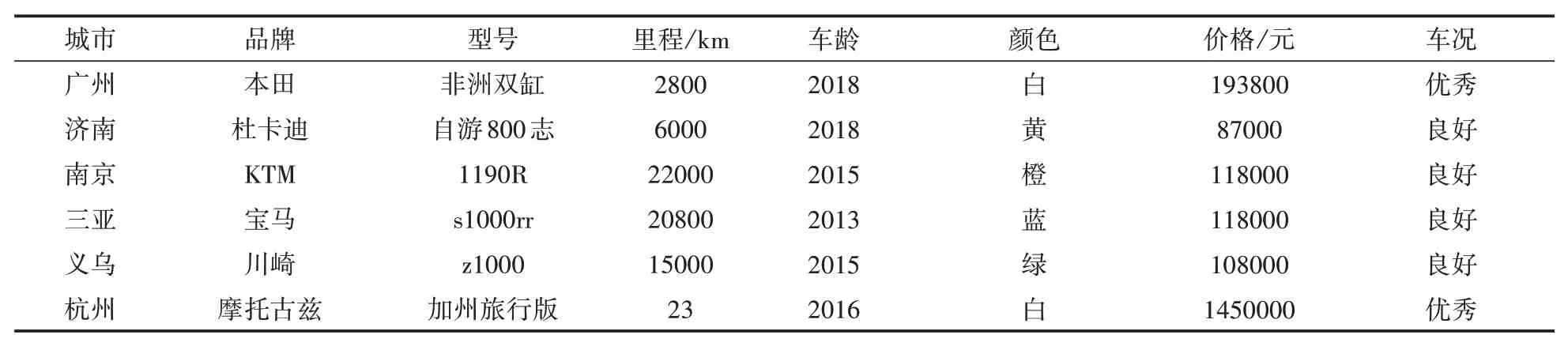
表1 部分特征数据集
数据预处理后,存在特征为属性值、特征值需缩放等不同特征处理问题,使得进入模型训练的特征更加精确,提高模型训练的效率,选取特征不同的处理方式见表2。

表2 特征处理
3 训练过程与结果分析
此模型选取二手摩托车残值率作为输出值(标签值),残值率计算公式如下:

本文采用平均绝对误差(mean absolute er⁃ror,MAE)和R方(R-squared,R2)作为模型评价指标,MAE用来描述模型预测值的准确率,R2用来描述预测值与实测值之间的相关程度,计算公式如下:
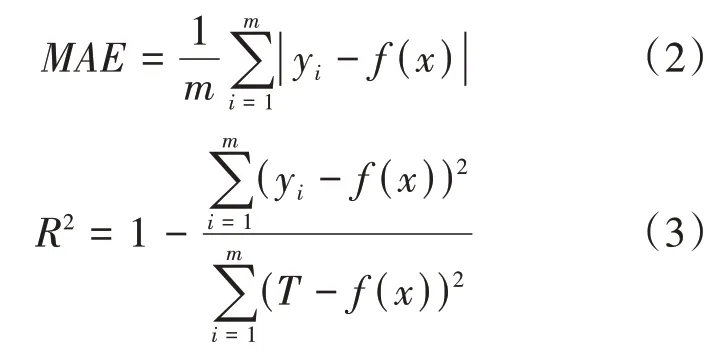
式中:m为训练集个数;y为残值率预测值,f(x)为残值率真实值,T为残值率真实值的平均值。
3.1 不同参数对预测准确度的影响
本文从200棵决策树到2000棵决策树,依次递增200棵;内部节点再划分所需最小样本数选择2至8,依次递增2;叶子节点最少样本数选择1至4,依次递增1。不同排列组合下进行回归预测,部分预测结果见表3。
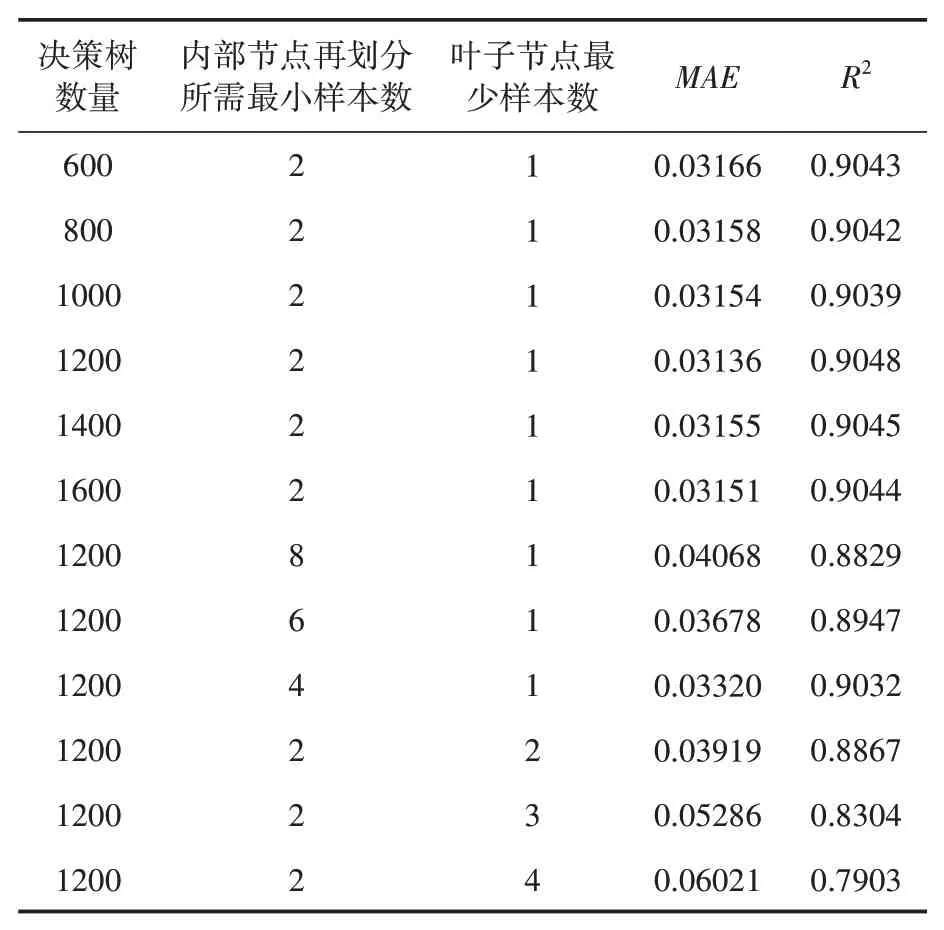
表3 部分预测结果
从实验结果初步可看出,决策树的数目越多,平均误差越小,拟合程度越好,但决策树达到一定数量后,增加决策树的数量对模型准确度提升效果不佳。在数据量样本不多时,内部节点再划分所需最小样本数及叶子节点最少样本数越小,模型预测结果拟合程度较好。决策树数目1200,内部节点再划分所需最小样本数2,叶子节点最少样本数1的时候误差最小,预测值与实际值的拟合度如图2所示。通过实验结果得知,基于随机森林回归的二手摩托车残值率预测模型整体效果良好,MAE值大都在5%以内,预测准确度较高;R2值大都在90%以上,预测值与实际值相关性强。
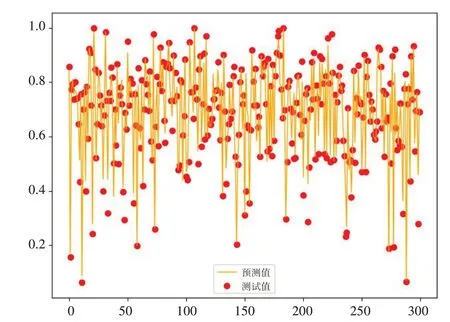
图2 预测值与实际值的拟合度
3.2 特征重要性
随机森林算法提供特征重要性的计算,计算过程如下:
(1)针对随机森林中建立的决策回归树,计算袋外数据(OOB)的误差,记作errOOB1;
(2)对袋外数据OOB所有样本的特征X随机加入噪声干扰,再次计算袋外数据误差,记作errOOB2;
(3)对随机森林中的所有决策树计算上述两个误差值,特征X的重要性计算公式为
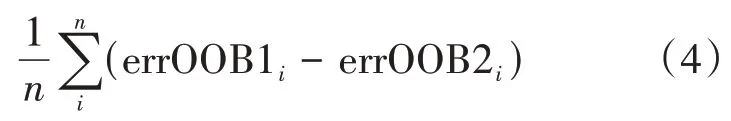
式中,n表示决策树的个数。
通过给决策树特征随机加入噪声,袋外准确度大幅度降低,表示该特征对决策树影响很大,对所有决策树取平均值,得到特征的最后重要性。特征重要性结果见图3。可以看出,车龄、行驶里程及上牌城市三个特征重要程度较高,符合市场规律。
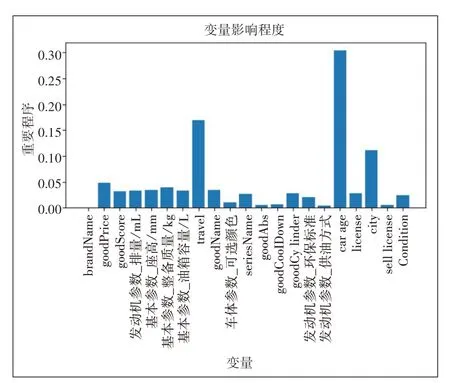
图3 特征重要性
4 算法对比分析
为进一步验证随机森林模型在二手摩托车估值模型上的优劣,采用交叉验证法选取贝叶斯岭回归[13](BayesianRidge)、普通线性回归[14](LinearRegression)、弹性网络回归[15](Elastic⁃Net)、支持向量机回归[16](SVR)、神经网络[17](BP-NN)预测模型构建预测模型,进行实验对比分析。计算上述模型的MAE、R2、训练时间三个评价指标,各模型的对比结果见表4和图4。
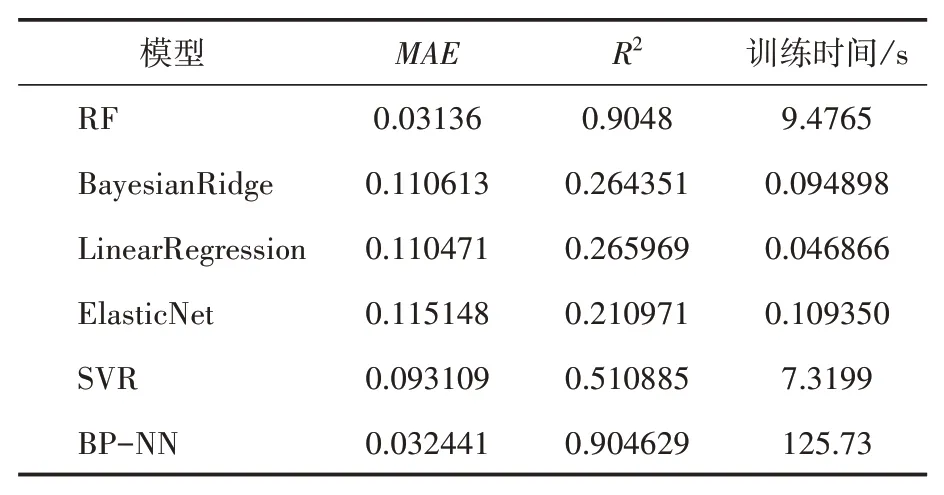
表4 模型预测结果对比
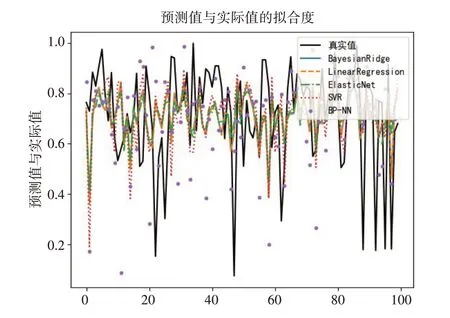
图4 预测值与实际值的拟合度
根据对比结果,可以看出在预测模型准确性上,RF、BP-NN模型预测准确性明显优于其他回归模型,RF、BP-NN的MAE均值均在0.035以下,R2能达到0.90以上。在运行效率上,RF、BP-NN的运行效率远低于其他模型,但RF的运行效率与BP-NN相比仍具有一定优势。综合比较上述结果,RF在高维度的回归预测问题上,准确性表现优秀,且具有良好的运行效率。
5 结语
二手摩托车估值模型成功建立,能带来以下应用价值:促进二手摩托车行业定价透明规范化——二手摩托车出售者能够通过模型来预测自己的二手摩托车能够卖多少钱,使价格定在一个合理区间,更容易售卖出去。购买者在市场里只需考虑自己想要的摩托车配置和能够接受的折旧度,利用模型来确定二手摩托车价格,更容易买到性价比较高的商品。为相关研究者提供研究思路——本文从影响因素分析、数据预处理、模型参数选择来逐步建立二手摩托车残值率估值模型,希望能够为相关研究者提供一些研究思路。
猜你喜欢
世界科学技术-中医药现代化(2021年8期)2021-12-21
汽车维修与保养(2020年11期)2020-11-23
中国管理信息化(2019年20期)2019-12-02
农业工程学报(2019年17期)2019-11-11
空气动力学学报(2019年1期)2019-03-19
电子制作(2018年16期)2018-09-26
电子制作(2017年24期)2017-02-02
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
车迷(2016年10期)2016-02-14
IT时代周刊(2015年9期)2015-11-11
