
基于机器视觉的配网工程安全管控检测方法
2023-01-08 14:40:36马静王庆杰孟海磊王栩成董啸赵文越任敬飞
现代电力 2022年6期
马静,王庆杰,2,孟海磊,王栩成,董啸,赵文越,任敬飞
(1.华北电力大学电气与电子工程学院,北京市昌平区 102206;2.国家电网有限公司,北京市西城区 100031;3.国网山东省电力公司,山东省济南市 250001)
0 引言
配电网工程存在施工现场点多面广、安全风险防控及现场监管难度大等特点[1-3]。目前配电网工程投资规模较大,省公司平均每年项目在3000个以上,现场作业人数上万。与上述规模相比,工程管理人员少、监管力量配备不足,容易导致现场作业不规范、安全事故多、工程完成质量差等问题,因此亟需通过强化机器视觉等人工智能手段加强配电网工程的安全与质量管控[4-5]。深度学习因提取特征能力强,识别精度高,实时性快等优点,在图像识别领域被广泛应用。
目前基于机器视觉的目标检测算法主要有:基于输入图像特征和边缘检测的传统检测技术和基于深度学习的检测技术。传统检测技术[6-8]通过选择目标候选区域,提取图像样本特征如方向梯度直方图(histogram of oriented gradient,HOG)特征、支持向量机(support vector machines,SVM)特征等,将图像特征送到迭代算法等分类器中进行分类并输出结果,传统检测算法遵循图像预处理、目标定位、目标分割及目标识别4个阶段。各个阶段的设计误差均会影响后续结果,且大量人工提取特征的使用,导致鲁棒性差,难以适用于场景复杂的配电网工程检测任务。基于深度学习的图像识别方法[9-13]采用卷积神经网络模型,识别率更稳定,适用性较广,但易受到复杂多变的环境影响,同时神经网络模型较大,速度较慢。以卷积神经网络为核心的目标检测算法可分为1阶段法和2阶段法[14]。1阶段目标检测法不使用候选框,将目标边框定位问题转化成回归问题进行处理,使得检测速度较快。2阶段目标检测法通过生成样本候选框,再利用卷积神经网络在候选框中对样本进行分类,最终完成目标的检测与识别。
针对上述问题,本文提出一种基于改进的YOLOv5网络模型的配电网工程实时检测方法。首先,对配电网工程样本数据集进行预处理,改进YOLOv5网络的特征提取网络,采用加权的双向特征金字塔网络(weighted bidirectional feature pyramid network,Bi-FPN)代替传统特征金字塔(feature pyramid network,FPN)模块,加快多尺度融合与小目标物体检测精度。基于此,改进损失函数、非极大值抑制模块,以提高模型识别精度与收敛速度,最后经过Darknet深度学习模型对识别样本进行多次重复迭代训练,保存最优权重数据用于测试集测试。
1 目标检测模型
1.1 YOLOv5模型构建
YOLO系列目标检测算法是深度学习领域经典的1阶段算法,其单一图片的推理时间能达到7 ms,可满足工程现场实时检测的需求。同时,YOLOv5模型大小仅有27 MB,而且通过参数调整就可以实现不同大小、不同复杂度的模型设计,更加适用于工业场景。
YOLOv5模型的网络结构如图1所示。由图可知模型主要分为4个部分,分别为输入网络、主干提取网络、颈部网络和预测网络[15]。

图1 YOLOv5模型网络结构Fig.1 Network structureof YOLOv5 model
YOLOv5输入端网络包括马赛克数据增强、图片尺寸处理、锚框自适应位置计算等多部分,可解决图片大小、长宽比不一致等问题,有效提升小目标识别率,适用于本项目中安全帽、熔断器等小型目标的检测。针对大型卷积神经网络中存在的梯度信息重复问题,主干提取网络采用CSPDarknet53提取信息特征,减少了模型的参数量、规模,提高了推理的速度和准确率。颈部网络采用路径聚合网络(path aggregation network,PANet)和增强模块空间金字塔池化(spatial pyramid pooling,SPP)加强特征的提取[16],以获取更有效的特征层。整个结构采用特征金字塔上采样和下采样融合的做法,FPN是自上而下的,将高层特征利用上采样的方式对信息进行传递融合,获得预测的特征图。PAN采用自底向上的特征金字塔[17],具体结构如图2所示。
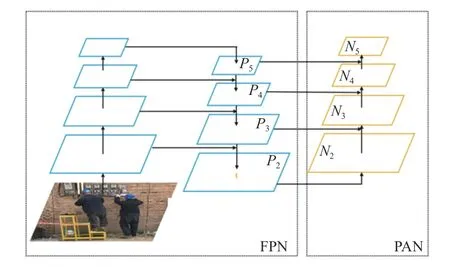
图2 FPN+PAN结构Fig.2 Structureof FPN and PAN
YOLOv5预测网络包括损失函数和非极大值抑制(non-maximum suppression,NMS)等。YOLOv5采用一种广义的交并比(generalized intersection over union,GIoU)作为损失函数,用来计算边界框的损失,可以有效解决边界框不重合的问题。非极大值抑制即为对同一位置产生的多个候选框根据置信度进行排序,选取最大值作为最佳的目标边界框。
1.2 YOLOv5网络改进
1.2.1 Bi-FPN特征网络
改进 YOLOv5网络原有的FPN结构,采用Bi-FPN网络来提取特征[18]。将CSPDarknet53中5 次下采样的后3次输出特征做多次自上而下和自下而上的特征融合,并添加新的连接来更大程度地提取特征。图3为使用Bi-FPN 特征融合网络代替YOLOv5原有的多尺度融合网络的改进YOLOv5神经网络结构[19]。

图3 改进的YOLOv5神经网络结构Fig.3 Structure of improved YOLOv5 neural network
通过快速归一化融合特征的方式,利用Bi-FPN对不同尺度的特征进行融合
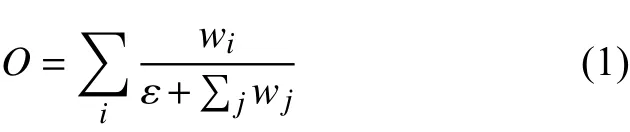
式中:取ε=0.00001,避免数值的不稳定,模型采用ReLu激活函数[20]。通过将Bi-FPN反复运算,得到3个有效特征层,将它们传输到类别预测层和边框预测层就可以获得预测结果。
1.2.2 锚框优化
本文通过K-means聚类和遗传算法,生成与当前数据集匹配度更高的锚框。K-means采用距离作为相似度的评价指标,对象之间距离越近,其相似度越高。
K-means算法流程如下。
步骤1)随机选择样本作为初始聚类中心;
步骤2)计算每个样本到聚类中心的距离并分类
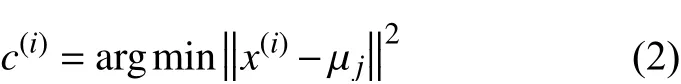
步骤3)针对每个类别,重新计算其聚类中心
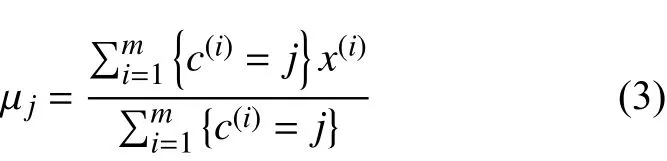
步骤4)重复步骤2)到3),直至满足收敛条件,收敛条件如式(4)所示

函数J表示每个样本点到其质心的距离平方和。K-means最终将J调整到最小。
计算初始锚框的目标框最大可能召回率(best possible recall,BPR),当其小于98%时,对锚框的宽高比进行K-means聚类后,再利用遗传算法随机变异1000次,得到更适合样本训练的先验框。
1.2.3 CIoU—Loss损失函数
本文选取CIoU作为损失函数,其计算过程如下。
如图4所示,蓝色线框为目标框,浅绿色线框为预测框。目标框坐标为B=(x1,y1,x2,y2),预测框坐标为 BP=(x1P,y1P,x2P,y2P)[21]。

图4 目标框与预测框位置图Fig.4 Location of target frame and prediction frame
目标框面积
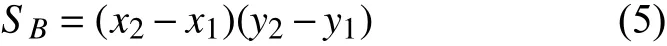
预测框面积

目标框与预测框重叠面积(交集)

式中:
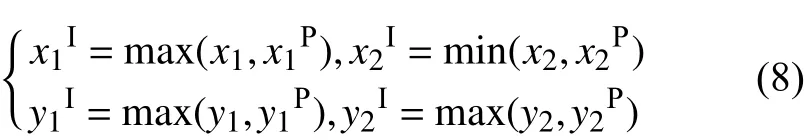
找到可以包含目标框与预测框的最小矩形BU
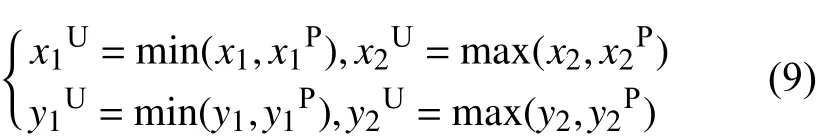
其面积(并集)

计算交并比(intersection over union,IoU):

在式(11)中,交并比的值与检测结果成正比,即交并比的值越大(接近于1),实际检测结果的预测框与物体的真实标记框越接近,算法性能越好。
计算LCIoU
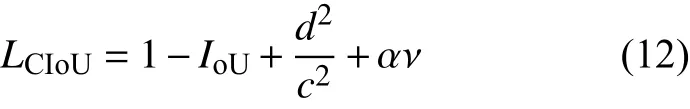
式中:α为权重函数;ν用来衡量目标框与预测框之间长宽比的一致性。

两框中心点之间的距离d、可同时覆盖预测框和目标框的最小矩形对角线距离 c为
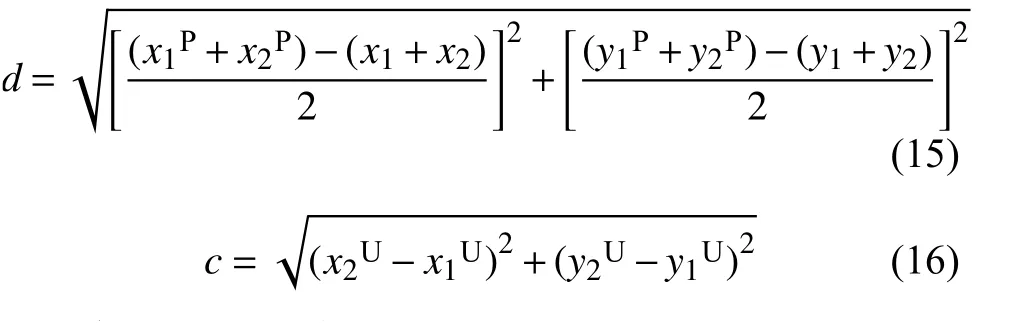
使用CIoU作为损失函数,可以充分考虑预测框与目标框的重叠面积、中心点距离、长宽比,能够进一步地快速收敛、提升性能。
1.2.4 标签平滑处理
标签平滑处理对真实标签的分布进行改造,使其不再符合独热形势,如

即
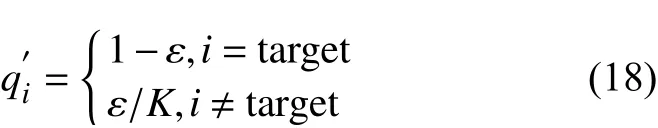
标签平滑后的分布,相当于向真实分布中加入了噪声,避免模型对于正确标签过于自信,使得预测正负样本的输出值差别不那么大,从而避免过拟合,提高模型的泛化能力。
1.2.5 非极大值抑制
在经典的非极大值抑制代码中,得分最高的检测框和其他检测框逐一算出一个对应的IoU值,并将该值超过非极大值抑制阈值的检测框全部过滤掉。但在实际应用场景中,当两个不同物体距离很近时,由于IoU值比较大,往往经过非极大值抑制处理后,只剩下一个检测框,导致漏检的错误情况发生。
基于此,基于距离的交并比计算(distanceintersection over union,DIoU)不仅考虑交并比,还考虑2个检测框中心点之间的距离。如果2个检测框之间IoU比较大,但是2个检测框的中心距离比较大时,可能会认为这是2个物体的框而不会被过滤掉[22]。非极大值抑制部分使用DIoU可以一定程度上提升对相近目标的检测。DIoU计算公式如式(19)所示
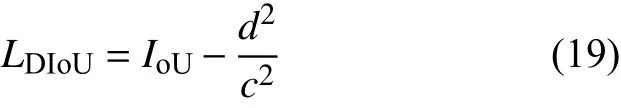
1.3 模型性能评估指标
YOLOv5网络采用平均精度均值、召回率、损失函数、查准率评估模型的性能。
如图5所示,将所有测试样本的置信度(用于表示预测的边界框对物体定位的准确程度)按种类分类后的预测得分值排序。将样本中的目标实例分成正类(分类正确的样本)或负类(分类错误的样本),若正类目标被预测为正类,则为真正类(true positive,TP)。若负类目标被预测为正类,则为假正类(false positive,FP)。同理,若负类目标被预测为负类,则为真负类(true negative,TN)。若正类目标被预测成负类,则为假负类(false negative,FN)。
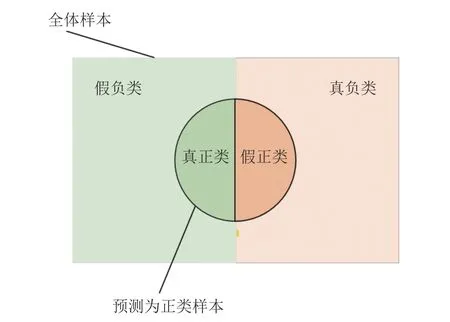
图5 样本分类情况Fig.5 Sample classification
召回率为模型正确识别出的目标占测试集中总目标的比例,如

查准率为模型识别目标的正确率,如

设定阈值不同时,可以得到多组查准率-召回率值,以查准率和召回率值作为坐标,可以绘制出P-R曲线,如图6所示。

图6 P-R曲线Fig.6 P-R curve
平均查准率(average precision,AP),为P-R曲线与坐标轴所围的面积,即查准率对召回率(recall,R)的积分,用来衡量模型在单个类别上检测的性能:
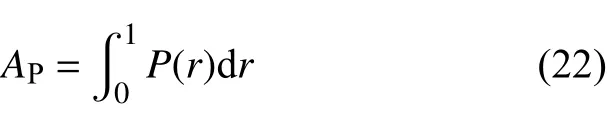
全类别平均查准率(mean average precision,mAP),为对所有类别的平均查准率求平均值,表示模型对所有类别检测的性能。
1.4 模型性能测试
目标识别实验步骤如下:
1)数据集制作。将整体数据集按照8:2比例分为训练集与测试集,采用图像标定工具标注数据,并统一为YOLO标注格式。
2)实验准备。配置实验环境,修改训练运行文件,设置迭代批量、训练次数、学习率等训练参数。
3)重复训练。导入训练集图像,进行重复迭代训练。
4)模型测试。测试生成的模型。利用模型在重复训练中生成的最优权重文件best.pt,对测试集中的图片进行识别检测。
5)结果分析。统计测试集识别结果,计算准确率。
文中网络模型训练过程参数设置如下:批量大小为32,总迭代次数为500次,学习率设置为0.001。其平均精度均值、召回率、损失函数、查准率如图7所示。
由图7可知,召回率在模型迭代到100次后稳定在0.93左右;精准率在模型迭代到80次后大于0.9;平均精度均值在模型迭代到100次时达到0.97;损失函数在模型迭代到500次时稳定,约等于0.1。
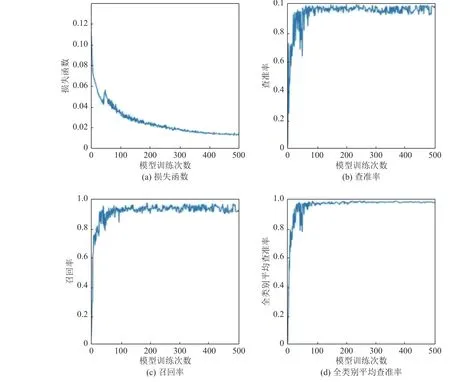
图7 YOLOv5模型性能评估Fig.7 Performance evaluation of YOLOv5 model
2 实验验证
2.1 实验环境
本次实验使用Windows操作系统,选用TensorFlow架构,使用GeForce RTX 2070的显卡进行运算。具体实验配置如表1所示。

表1 实验配置Table 1 The configuration for theexperiment
2.2 实验数据集
本实验样本集由多个企业公司提供配电网现场作业照片,以进行安全帽、熔断器等安全项目的识别。利用图像处理将原始样本集扩充至大约10000张,作为实验数据集。数据集按照8:2的比例分为训练集和测试集,其中训练集包含8000张图片,测试集包含2000张。具体数量如表2所示。

表2 样本训练集及测试数据集划分Table2 Division of sample training set and test data set
2.3 实验结果与分析
模型训练完成后,将测试集输入至模型中进行测试,测试结果如图8所示。图中红色目标框表示正确佩戴安全帽,粉色目标框表示为未正确佩戴安全帽,目标框上数值代表为各类别标签的

图8 算法识别结果Fig.8 Resultsof algorithm recognition
置信度。从算法测试结果看出,算法识别工程现场工人是否正确佩戴安全帽结果较好,同时在多目标下、目标受遮挡情况下也没有出现漏检情况。
为衡量算法测试实验的实际效果,对测试集样本中的目标识别情况进行了统计,定义样本识别准确率 k如式(23)所示

式中: nTure为样本集中算法正确检测出的目标数;nAll为图片中的目标总数。
利用式(23),可计算得安全帽识别准确率为97.87%。表3给出了本文算法与参考文献[22-23]中2种算法的测试性能对比,本文算法的准确率明显高于参考文献中算法的准确率。检测速度为140帧/s,相比于文献[23]中的改进YOLOv3算法提升了近3倍。由此可知,本方法均优于参考文献中的2种现有算法,且检测速度极快,满足工程现场检测需求。
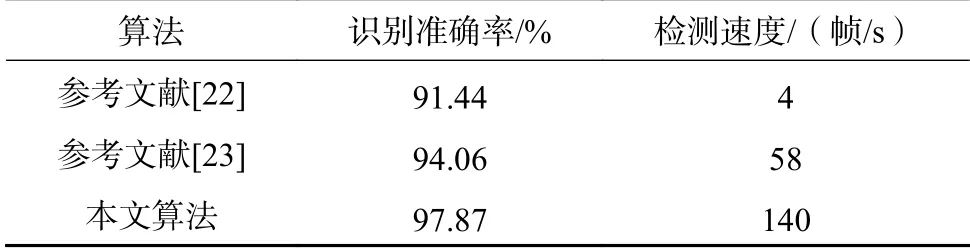
表3 算法性能对比Table 3 Comparison of algorithm performances
除安全帽外,本次实验还针对配电网工程中常见的几类安全种类进行了检测识别,检测结果如图9—10所示,识别准确率如表4所示。

图9 设备底板是否封堵检测结果Fig.9 Testing resultsof whether theequipment bottom plate is blocked or not
由表4可知,针对不同种类工程现场可能存在的安全问题,本算法识别准确率均较高。

表4 不同安全情况识别准确率Table4 Identification accuracy of different safety conditions
3 结论
1)改进YOLOv5主干特征提取网络,采用加权的双向特征金字塔网络Bi-FPN代替传统特征金字塔FPN模块,修改模型损失函数,得到了一种收敛速度更快、鲁棒性更强的改进YOLOv5模型。

图10 跌落式熔断器是否断开检测结果Fig.10 Testing resultsof whether thedrop fuse is disconnected or not
2)利用改进的YOLOv5算法进行了训练识别实验,不同类型样本准确率均可超过95%。同时,改进的YOLOv5算法识别速度快,可达140帧/s,满足工程现场实时使用要求。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
现代电子技术(2017年23期)2017-12-20 13:23:31
计算机应用(2016年10期)2017-05-12 11:02:20
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
