
联合语义代价体的立体匹配网络改进方法
2023-01-07 07:39:20何培玉黄劲松
导航定位学报 2022年6期
何培玉,黄劲松
联合语义代价体的立体匹配网络改进方法
何培玉,黄劲松
(武汉大学测绘学院,武汉 430079)
立体匹配是自主移动平台获取周围环境深度信息的主要方式之一。针对在低纹理、前景物体难以与背景区分等场景下,经典立体匹配算法性能下降明显这一问题,围绕将语义信息引入立体匹配网络开展研究,对现有联合语义信息的立体匹配网络进行整合抽象,并针对现有方法的缺陷提出了联合语义代价体的立体匹配网络改进方法,结合残差结构设计,更充分地利用语义信息的同时保证了算法的实时性。实验结果表明,联合语义信息对立体匹配网络整体精度有所提升,并对病态区域中的结果有所改善,同时验证了本文方法相较于其他联合语义信息方法的优越性。
深度学习;立体匹配;语义信息;语义分割;多任务网络
0 引言
双目立体匹配旨在通过对双目图像中的同名点进行匹配,根据匹配点对的视差来恢复图像中物体的深度信息。根据获得的深度信息,可以进一步提取出场景中的障碍物,恢复物体的3维信息,广泛地应用在例如无人驾驶车辆等自主移动平台的环境感知模块以及3维重建等领域。
相较于文献[1-2]中传统的立体匹配方法,端到端的方法在估计精度和计算速度等方面得到了极大的提升[3]。在传统方法中,人为设计的视觉特征鲁棒性较差,难以适应多种复杂环境,而端到端的方法凭借其强大的学习能力在多种场景下实现了快速且准确的立体匹配[4]。早期,例如文献[5-6]中的一些方法使用卷积神经网络来替代传统立体匹配方法中的部分步骤。2016年文献[7]提出了视差网络(disparity network, DispNet),基于编码器-解码器的框架首次实现了端到端的立体匹配网络。文献[8]中基于几何和上下文的深度回归网络(geometry and context network, GCNet)首次将 3维(3-dimentional, 3D)卷积引入了立体匹配网络构建中,保留了更多的特征信息。除此以外,在GCNet中提出了使用可微的最值函数(soft argmax)来实现最后的视差回归(regression)。自此,在基于深度学习的立体匹配方法中,基于3D卷积和soft argmax的方法逐渐成为主流。
但对于低纹理、前景物体不明显等复杂区域,端到端的立体匹配网络虽然相较于传统方法有一定程度的改善,但是仍然难以得到十分准确的视差结果[9]。为了进一步提高立体匹配网络精度,文献[10-12]中的各种网络通过增加代价体规模或数量的方式提高对上下文信息的利用,有效提高了立体匹配的整体精度,但上述方式极大地增加了内存消耗,同时需要大量的计算。例如文献[10]中的金字塔立体匹配网络(pyramid stereo matching network, PSM),一次前向计算需要进行数千亿次浮点运算,参数量也达到了数百万个,难以进行实时推断。
针对上述问题,文献[13-16]均是基于多任务网络框架,以联合语义特征图的形式在立体匹配分支中引入语义信息,以较小的代价有效提高立体匹配网络精度,同时获得其他相关信息。但是上述联合语义信息的方法基于不同的立体匹配网络框架,在模型构建上具有其特异性,同时训练方式也有很大差别,因此无法依据上述论文的结果对不同的联合方式进行说明和比对,对研究如何合理、有效地在立体匹配网络中联合语义信息造成了阻碍。
本文在统一的立体匹配网络框架中实现了已有的联合语义信息的方法,同时提出了一种结合语义代价体和残差结构的联合方法,并在国际上最大的自动驾驶场景下的计算机视觉算法评测数据集(KITTI)中的双目数据集(KITTI Stereo)上验证联合语义信息对立体匹配算法整体精度的提升以及对病态区域视差估计结果的改善,对上述多种联合语义信息的方式进行了比较。KITTI数据集是由德国卡尔斯鲁厄理工学院(Karlsruhe Institute of Technology, KIT)和丰田工业大学芝加哥分校(Toyota Technological Institute at Chicago, TTIC)联合创办,利用组装的设备齐全的采集车辆对实际交通场景进行数据采集获得的公开数据集。
1 网络结构
1.1 单一立体匹配网络
本文采用的统一的立体匹配网络框架如图1所示。网络结构可分为特征提取、构建代价体、正则化代价体及视差回归4个部分。双目图像同时输到特征提取模块以获取双目特征图;随后使用双目特征图构建代价体,以此表示双目特征在待估计视差范围内的匹配关系;再通过3D卷积层对代价体进行正则化处理,最后使用soft argmax操作对正则化后的特征图进一步回归,得到预测的视差图。
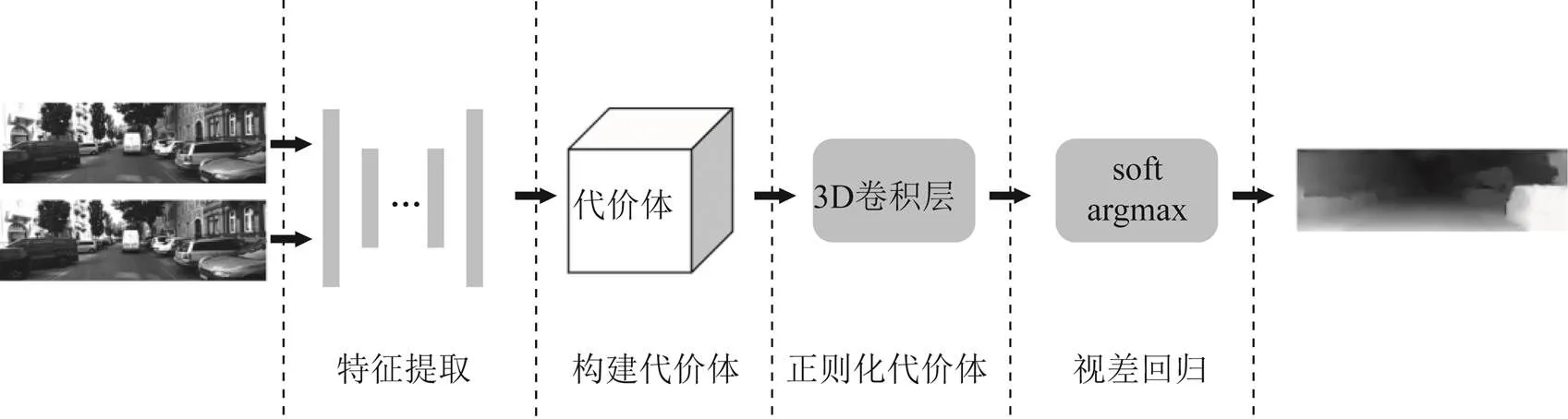
图1 立体匹配网络框架
在具体的网络设计中,特征提取部分采用简单的编码器-解码器结构;同时,为了获取丰富的上下文信息,在上采样过程中通过文献[17]中提出的跳连操作将底层特征和深层特征融合。代价体的构建则采用了单通道方式,即在通道维度上求解范数作为匹配代价值,以此减小3D卷积层的计算量。
立体匹配网络和语义分割网络在结构上具有很大程度的相似性,且均是稠密的、像素级别的输出。语义分割网络框架如图2所示。语义分割网络在编码器-解码器结构的特征提取器后添加若干层二维卷积以及归一化指数函数(softmax)操作以构建语义分割分支,对特征图进行进一步处理并将特征图转换为语义标签的概率分布。
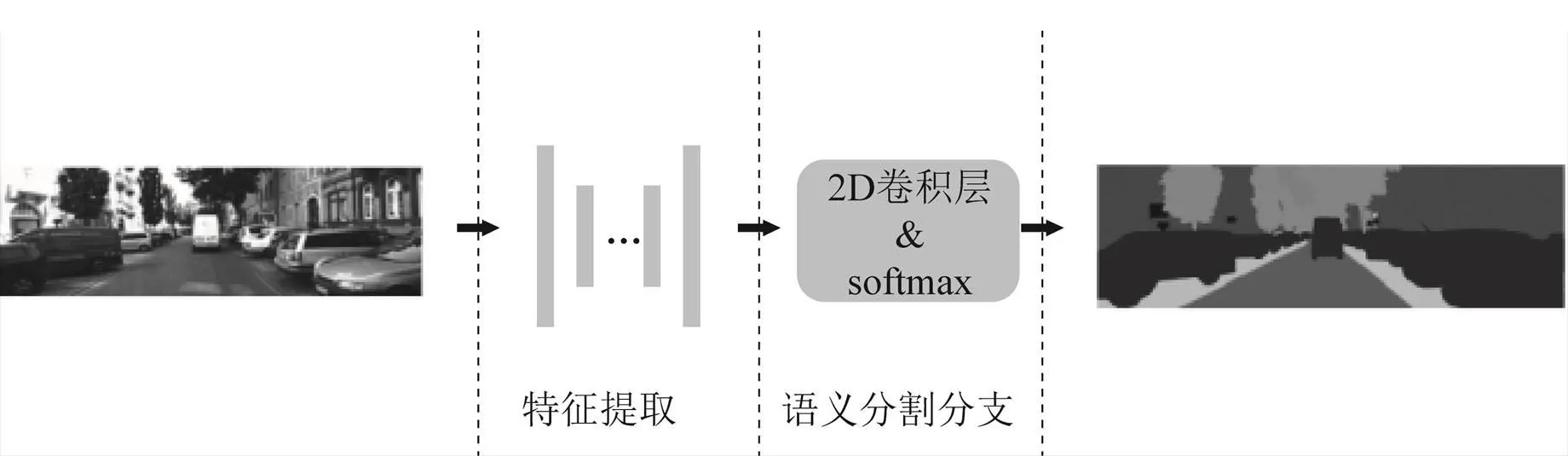
图2 语义分割网络框架
从算法流程和特征类型上看,立体匹配网络中主要借助局部的、低语义的底层特征进行左右目间的同名点匹配,而语义分割网络中主要依靠更大感受野、包含更多语义信息的特征进行语义标签的预测,二者的信息存在互补的关系。除此以外,根据语义分割获得的语义信息,可以提高低纹理、遮挡等区域的立体匹配结果的准确性。因此可通过联合语义信息提升立体匹配的精度。
1.2 现有联合语义信息的方法
1.2.1 联合语义分割任务
考虑到立体匹配和语义分割均是稠密的像素级预测任务,其特征提取模块存在共用的可能性,因此可直接在已有的立体匹配网络基础上添加语义分割分支,以多任务网络形式联合语义信息,具体框架如图3所示。
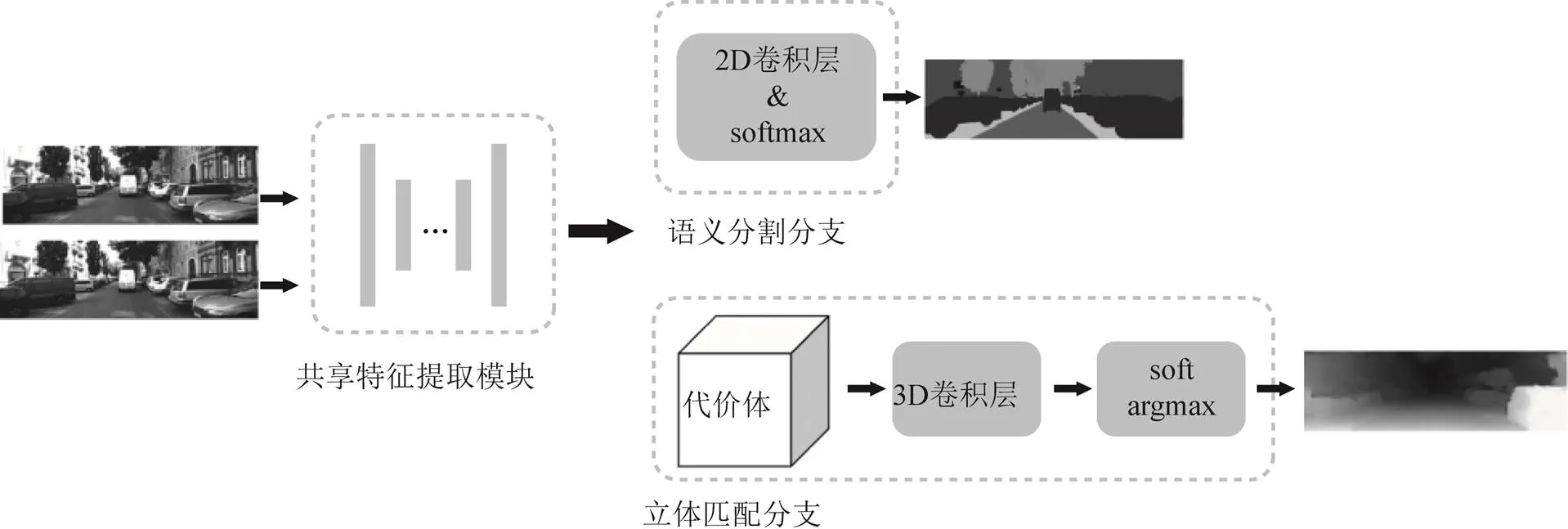
图3 立体匹配和语义分割的多任务网络框架
其中特征提取部分完全共享,生成的特征图可以同时输入立体匹配分支和语义分割分支中,分别进行语义分割结果和视差图的估计。而语义分割分支与立体匹配分支的设计与1.1节中保持一致。
以多任务的形式联合语义信息可丰富原本立体匹配任务中的特征类型,但仅仅是通过反向传播影响底层特征提取模块。因此在多任务的基础上,已有的研究考虑了更多样的联合方法,加强 2个子任务的联系。
1.2.2 联合语义特征图
联合语义特征图是指在多任务网络基础上将语义分割分支中产生的特征图引入立体匹配分支中,参与到视差估计的过程中。目前文献[13-16]中的已有研究均是通过该方式将语义信息添加到立体匹配网络中,但根据引入语义特征图的位置不同可分为特征图级联、代价体融合和细化视差 3种联合模式。其中文献[13]提出的语义分割的立体匹配网络(semantic segmentation stereo matching network, SegStereo)是在进入立体匹配分支前,将2个任务的特征图级联,共同构建代价体,也即特征图级联的联合方式;文献[14]中基于金字塔代价体的语义立体匹配网络(semantic stereo matching network with pyramid cost volumes, SSPCV-Net)在代价体进入3D卷积模块之前利用代价体聚合模块将原有的代价体和语义代价体融合,采用的是代价体融合的联合方式;而文献[15]中的语义辅助的视差网络(disparity estimation network with semantics, DispSegNet)和文献[16]中的实时语义立体匹配网络(real-time semantic stereo matching network, RST2Net)则是在立体匹配分支生成视差图后,联合语义特征图对已有的预测结果进行细化,是细化视差的联合方式。
特征图级联的联合方式将双目的语义特征图和输入立体匹配分支的原始特征图在通道维上进行级联,替代原有的特征图来进行代价体的构建和后续的视差计算。具体网络框架如图4所示。
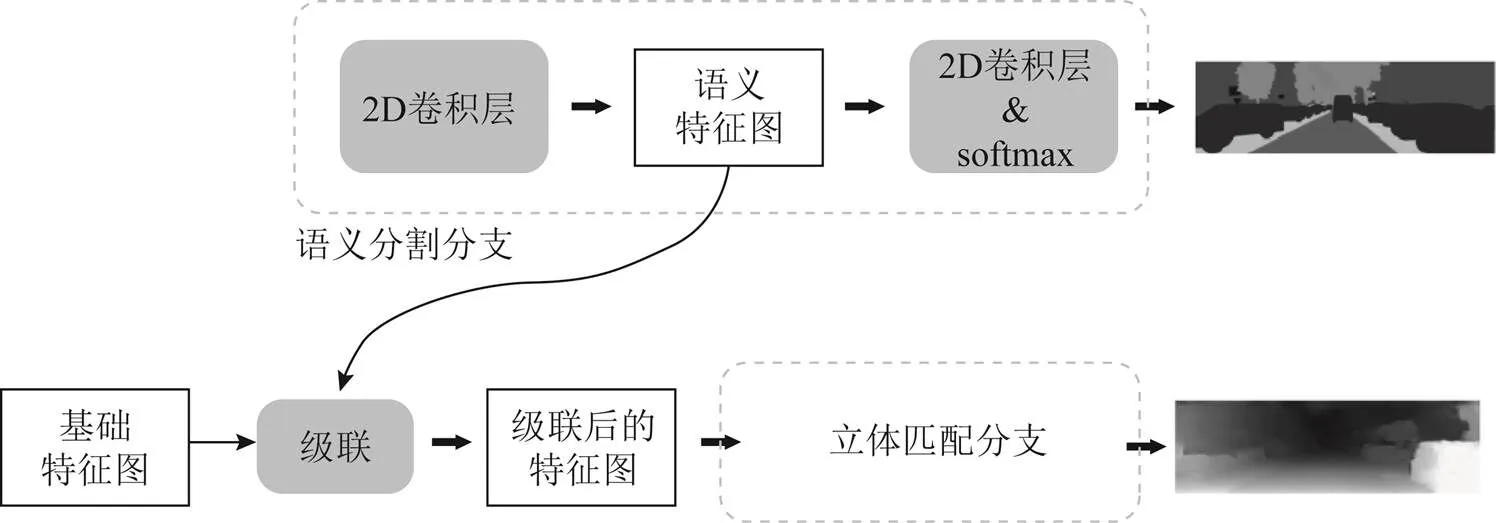
图4 特征图级联的联合网络框架
代价体融合的联合方式是利用语义特征构成新增的代价体,再与立体匹配分支中原有的代价体进行融合,共同输入3D卷积模块中进行代价体的正则化。在代价体融合的过程中,首先要进行语义代价体的构建,然后要建立代价体的融合模块,将语义代价体和原有的特征代价体进行融合,再将融合后的代价体输入3D卷积层中进行处理。整体网络框架如图5所示,其中的代价体融合模块与SSPCV-Net中设计一致。
除了上述2种联合方式,还可以将已有的视差估计结果与语义特征图在通道维上级联,再将级联的结果输入简单的、由多个2D卷积堆叠起来的细化模块,利用语义信息细化原有的视差估计结果。细化视差的联合网络结构如图6所示。
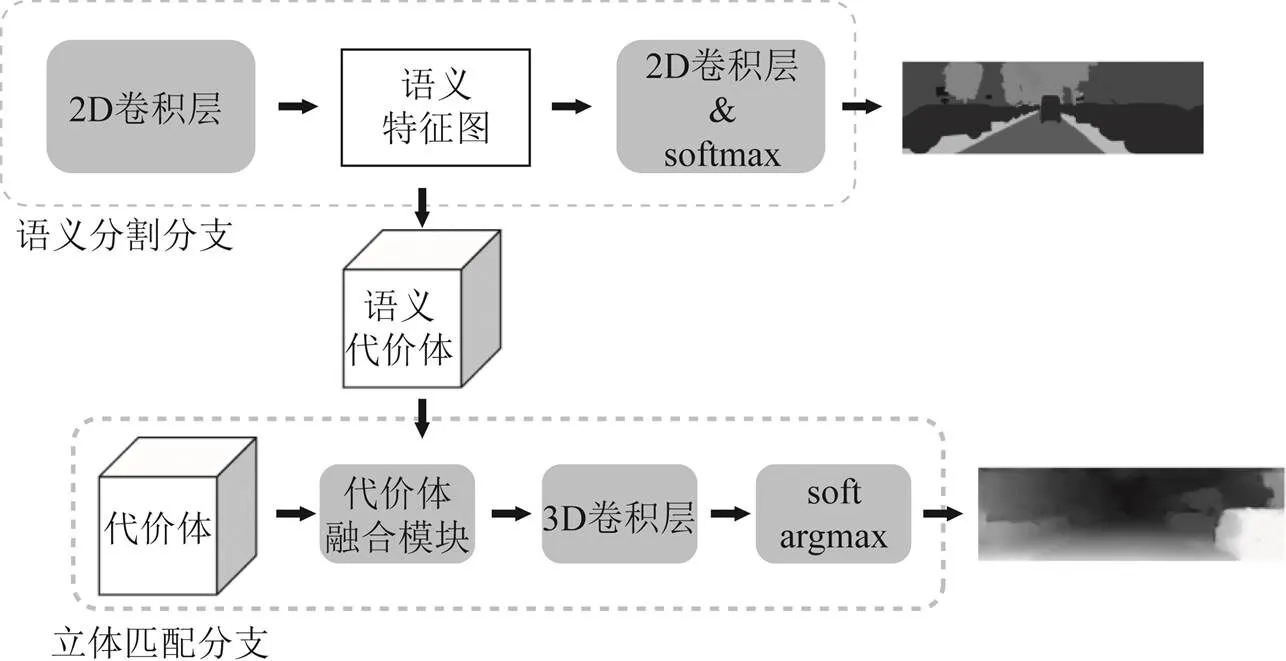
图5 代价体融合的联合网络框架
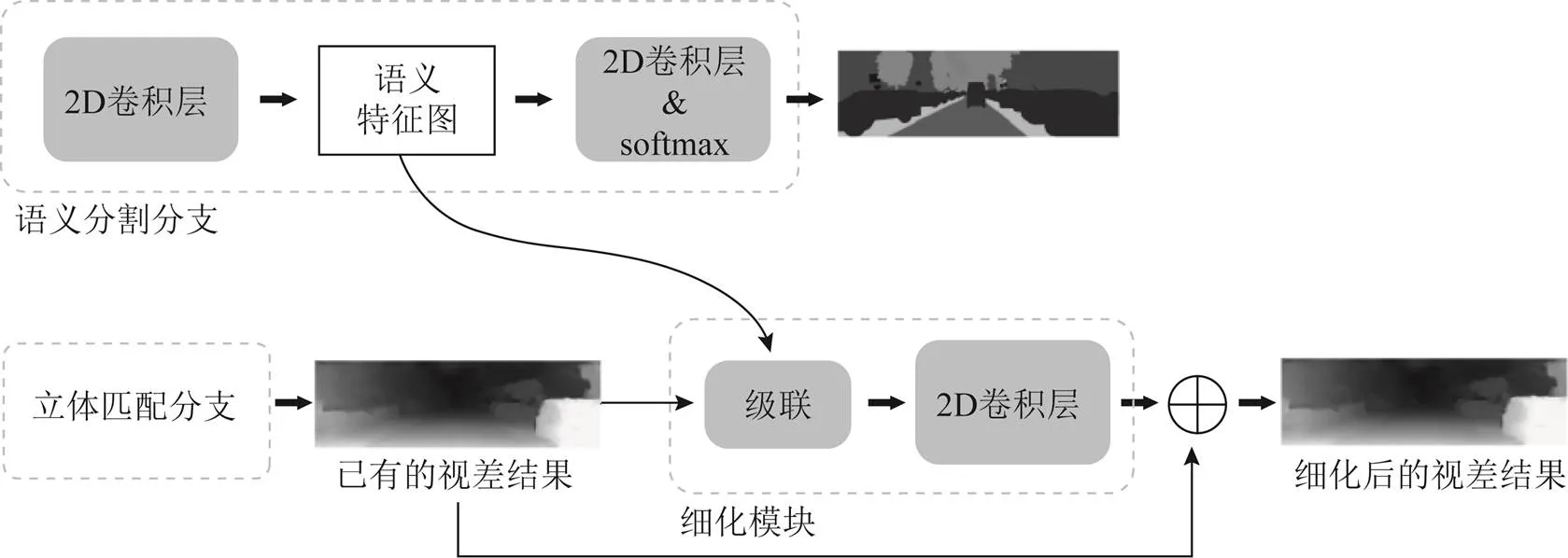
图6 细化视差的联合网络框架
1.3 联合语义代价体的立体匹配网络改进方法
特征图级联的联合网络使用级联后的特征图进行代价体的构建,但是在通道维上级联的融合方式过于简单,且在构建单通道代价体过程中存在较大的信息损失。同样地,代价体融合的联合方式如果基于单通道代价体进行融合会存在较大的信息损失,但如果使用多通道的代价体则计算量过大。而细化视差的联合网络仅仅使用了单目的语义特征,没有用到双目语义特征的匹配信息。因此考虑将以上3种联合方式结合起来,本文提出利用单独的语义代价体对已有的视差结果进行细化。该方法首先使用语义特征和已有的视差结果构建规模较小的语义代价体,然后通过堆叠的3D卷积对语义代价体进行处理,最后利用估计视差残差(residual)的方式来实现视差细化。具体网络结构如图7所示。
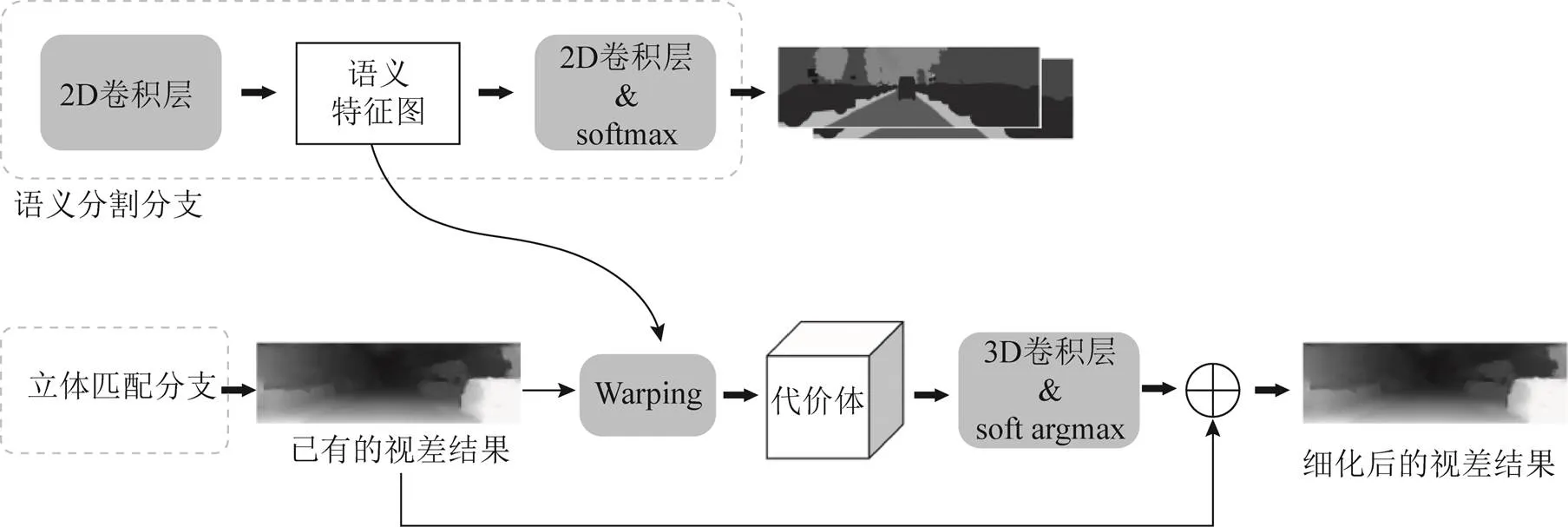
图7 联合语义代价体的立体匹配网络框架
联合语义代价体的方法首先利用已有的视差结果将右目的语义特征投影(warping)到左目,再将得到的投影结果与原本的左目语义特征图用于构建语义代价体。通过正则化代价体和视差回归过程,网络得到相较于已有视差结果的残差值,将该残差值与原有的视差结果相加即可得到经过细化后的视差结果。不同于立体匹配分支中原本的代价体构建方式,此处语义代价体的构建利用了已有的视差结果,在视差残差的范围上构建语义代价体,很大程度上减小了语义代价体的规模。
构建单独的语义代价体的方式既能够利用到单目语义特征来引导物体边缘部分的视差估计,也能够通过语义特征之间的匹配关系进一步完善原本特征难以匹配的区域,更完整、充分地利用到语义信息。同时残差结构的设计减小了语义代价体的规模,进而减少了处理语义代价体所需要的计算消耗,保证了算法的实时性。
2 实验与结果分析
2.1 数据集及评估指标
1)CityScapes。城市场景数据集(CityScapes)是语义分割中常用的数据集,采集于真实的驾驶场景,包含了50个不同城市的街道场景中记录的立体视频序列,包含了5000帧的高质量像素级语义标注。数据集中的视差图是通过半全局匹配算法(semi-global matching,SGM)算法获得,精度很低且存在大量的空洞,难以作为准确的立体匹配训练数据。该数据集主要用于对网络进行预训练。
2)KITTI Stereo。该数据集同样采集于真实的驾驶场景,其中视差信息来源于激光雷达的点云数据,是稀疏的、更为准确的视差标注。但是数据集规模较小,仅有约400对训练立体图像对,因此主要用于对模型进行微调及后续评估。
3)评估指标。立体匹配常常采用-像素误差(-pixel error,PE)评估视差估计结果的准确性,计算方式为
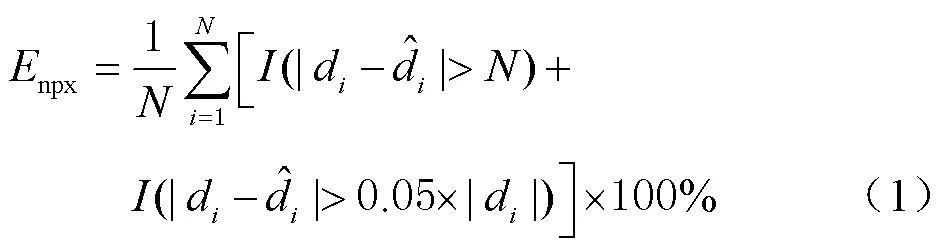
2.2 损失函数
本文采用平滑的最小绝对值偏差损失函数(smooth l1 loss)进行视差分支的训练,在语义分割任务中则采用交叉熵函数(crossentropy loss)进行训练。
定义视差损失函数为
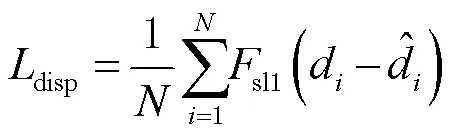
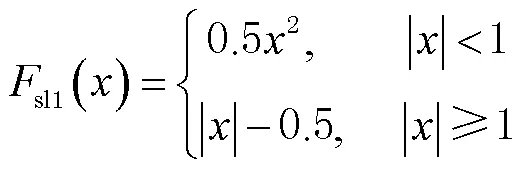
语义分割损失函数定义为
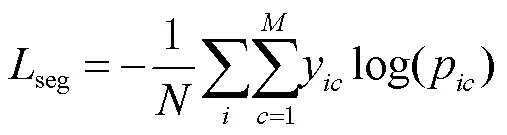
联合语义信息的立体匹配网络的整体损失函数为
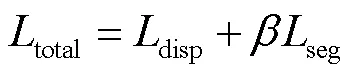
2.3 结果分析
为了说明联合语义信息后对立体匹配算法整体精度的提升,以及对多种联合语义信息的方式进行比对,进行了多组实验对不同的网络结构生成的视差结果进行评估。
在表1中,对单独的立体匹配网络、多任务网络、特征图级联的联合网络、代价体融合的联合网络、细化视差的联合网络以及基于语义代价体细化视差的联合网络的浮点运算次数(floating point operations, FLOPs)、参数量和推断时间进行了统计和比对。
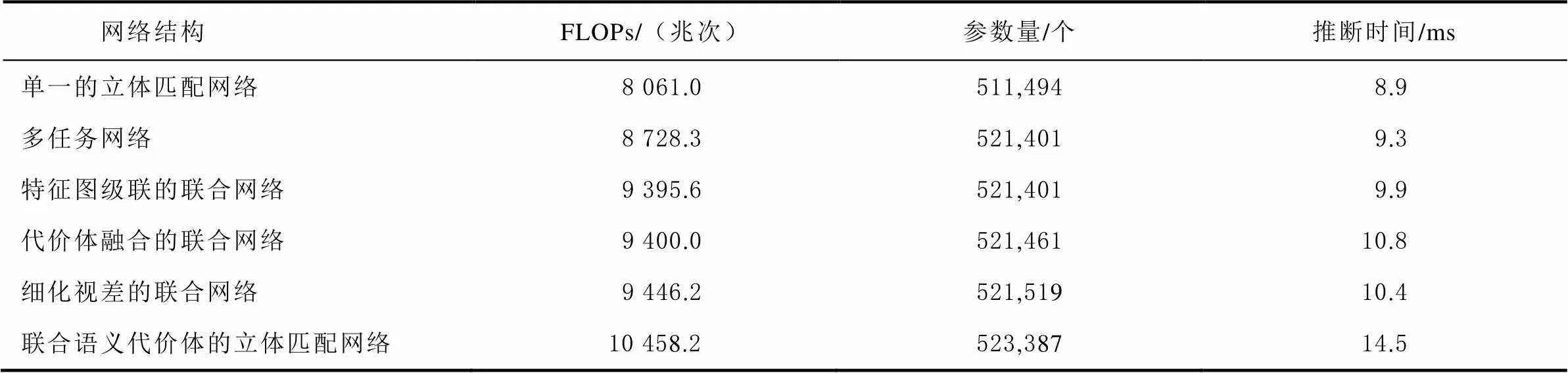
表1 不同网络结构的计算效率统计
从表1可以看出,相较于单独的立体匹配网络,联合语义信息的各个网络计算量和参数量仅存在少量的增长,但即使是其中最复杂的结合语义代价体和残差结构的联合网络,其浮点运算数和参数量亦均比PSMNet低1个数量级,且能保证实时的推断速度。
从KITTI Stereo的训练集中随机分离出40张图片作为验证集,不参与模型的训练。在训练结束后使用验证集对模型进行整体精度的评估,评估结果如表2所示。

表2 不同网络结构在KITTI Stereo上的表现
从表2中的评估结果可以看出,联合语义信息有效提高了立体匹配结果的整体精度。单以多任务的形式联合语义信息,在整体精度的提升上并不明显;而在不同的联合语义信息的网络结构中,联合语义代价体的立体匹配网络对于结果的整体精度提升最高。
图8和图9中分别选取了包含了大部分低纹理区域的图像1和前景物体不明显的图像2作为测试图像,对各个网络产生的视差预测结果以及预测误差进行可视化。预测结果可视化结果中亮度越大表示视差值越大,也即距离越近。在预测误差可视化结果中,亮度越大表示误差值越大。
从图8和图9可以看出,仅仅联合语义分割任务难以对病态区域有明显的改善,而联合语义特征图和联合语义代价体的方式相较于单一的立体匹配网络在低纹理区域能进行更为准确、完整的视差估计;对于低纹理区域以及从色彩上难以分辨的前景物体,例如电线杆、树木等,联合语义的网络也获得了更准确的视差结果。另在表3中统计了图像1和图像2在多种网络结构中预测结果的3-像素误差值,从指标上说明了联合语义特征图和联合语义代价体的立体匹配网络在低纹理区域以及前景物体处视差结果的明显改善。

图8 图像1的预测结果和预测误差可视化

图9 图像2的预测结果和预测误差可视化

表3 图像1和图像2的视差结果3-像素误差统计 %
上述实验从1/3-像素误差的定量评估和部分复杂场景的可视化2个方面证实了联合语义分割的立体匹配网络相较于单独的立体匹配网络在整体精度上的提升以及复杂区域上的改善。同时,各种联合语义信息的立体匹配网络均在计算量和参数量上都保持了合理的增长,在实验设备上维持了实时的推算。其中,本文提出的联合语义代价体的立体匹配网络因为构建了单独的语义代价体,既能够利用到单目语义特征来引导物体边缘部分的视差估计,也能够通过语义特征之间的匹配关系进一步完善原本特征难以匹配的区域,更为完整、合理地应用了语义信息,虽然在计算量和参数量上增长较大,但是在整体精度的提升和对复杂区域结果的改善2个方面都取得了最佳的效果。
3 结束语
本文对已有的联合语义信息的方法进行了抽象整合,针对现有方法利用语义信息不足的缺陷,提出了一种联合语义代价体的立体匹配网络改进方法,以残差形式构建视差细化模块,充分利用语义信息的同时减小了语义代价体的规模和后续的计算消耗。实验结果表明,本文提出的联合语义代价体的立体匹配网络改进方法在15毫秒每帧的推断效率下达到4.31%的3-像素误差,相较于已有的联合方式,更大程度地改善了立体匹配结果,且不影响算法的实时性。
[1] SCHARSTEIN D, SZELISKI R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms[J]. International Journal of Computer Vision, 2002, 47(1): 7-42.
[2] BROWN M Z, BURSCHKA D, HAGER G D. Advances in computational stereo[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(8): 993-1008.
[3] 刘振国,李钊,宋滕滕,等.可变形卷积与双边网格结合的立体匹配网络[J].计算机工程,2022(5):1-9.
[4] LAGA H, JOSPIN L V, BOUSSAID F, et al. A survey on deep learning techniques for stereo-based depth estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
[5] ZBONTAR J, LECUN Y. Computing the stereo matching cost with a convolutional neural network[EB/OL]. [2022-05-06].https://arxiv.org/pdf/1409.4326.pdf.
[6] ZBONTAR J, LECUN Y. Stereo matching by training a convolutional neural network to compare image patches[J]. J. Mach. Learn. Res., 2016, 17(1): 2287-2318.
[7] MAYER N, ILG E, HAUSSER P, et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[EB/OL]. [2022-05-06].https://arxiv.org/pdf/1512.02134.pdf.
[8] KENDALL A, MARTIROSYAN H, DASGUPTA S, et al. End-to-end learning of geometry and context for deep stereo regression[EB/OL]. [2022-05-06].https://arxiv.org/pdf/1703.04309.pdf.
[9] 郑秋梅,温阳,王风华.基于多卷积核通道特征加权双目立体匹配算法[J].计算机与数字工程,2021,49(10):2113-2117.
[10] CHANG J R, CHEN Y S. Pyramid stereo matching network[EB/OL]. [2022-05-06].https://arxiv.org/pdf/1803. 08669.pdf.
[11] 张锡英,王厚博,边继龙.多成本融合的立体匹配网络[J].计算机工程,2022,48(2):186-193.
[12] ZHU Z, HE M, DAI Y, et al. Multi-scale cross-form pyramid network for stereo matching[EB/OL]. [2022-05-06].https://arxiv.org/pdf/1904.11309.pdf.
[13] YANG G, ZHAO H, SHI J, et al. Segstereo: exploiting semantic information for disparity estimation[EB/OL]. [2022-05-06].https://arxiv.org/pdf/1807.11699.pdf.
[14] WU Z, WU X, ZHANG X, et al. Semantic stereo matching with pyramid cost volumes[EB/OL]. [2022-05-06].https://openaccess.thecvf.com/content_ICCV_2019/papers/Wu_Semantic_Stereo_Matching_With_Pyramid_Cost_Volumes_ICCV_2019_paper.pdf.
[15] ZHANG J, SKINNER K A, VASUDEVAN R, et al. Dispsegnet: leveraging semantics for end-to-end learning of disparity estimation from stereo imagery[J]. IEEE Robotics and Automation Letters, 2019, 4(2): 1162-1169.
[16] DOVESI P L, POGGI M, ANDRAGHETTI L, et al. Real-time semantic stereo matching[EB/OL]. [2022-05-06]. https://arxiv.org/pdf/1910.00541.pdf.
[17] RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[EB/OL]. [2022-05-06].https://arxiv.org/pdf/1505.04597.pdf.
An improved method of stereo matching network combined with semantic cost volume
HE Peiyu, HUANG Jingsong
(School of Geodesy and Geomatics, Wuhan University, Wuhan 430079, China)
Stereo matching is one of the main ways for autonomous mobile platforms to obtain the depth information of the surrounding environment. Aiming at the problem that the performance of the classic stereo matching algorithm is obviously degraded in the scenes with low texture and the foreground objects are difficult to distinguish from the background, this paper focuses on introducing semantic information into the stereo matching network. This paper integrates and abstracts the existing stereo matching network combined with semantic information, and then proposes an improved method for stereo matching network combined with semantic cost volume in view of the shortcomings of the existing methods. Combined with residual structure, it can make full use of semantic information while ensuring that the real-time inference. The experimental results show that the joint semantic information improves the overall accuracy of the stereo matching network as well as the improvement in ill-conditioned regions, and at the same time verifies the superiority of the proposed method compared with other methods to combine semantic information.
deep learning; stereo matching; semantic information; semantic segmentation; multi-task network
P228
A
2095-4999(2022)06-0157-08
何培玉,黄劲松.联合语义代价体的立体匹配网络改进方法[J].导航定位学报, 2022, 10(6): 157-164.(HE Peiyu,HUANG Jingsong.An improved method of stereo matching network combined with semantic cost volume[J]. Journal of Navigation and Positioning, 2022, 10(6): 157-164.)
10.16547/j.cnki.10-1096.20220621.
2022-05-26
何培玉(1997—),女,重庆长寿人,硕士研究生,研究方向为深度学习。
黄劲松(1969—),男,湖南长沙人,博士,副教授,研究方向为自主移动机器人技术。
猜你喜欢
小型微型计算机系统(2022年1期)2022-01-21 02:55:06
天津大学学报(自然科学与工程技术版)(2018年6期)2018-05-30 00:57:46
海峡姐妹(2017年12期)2018-01-31 02:12:22
测绘科学与工程(2017年3期)2017-08-16 02:46:00
测绘科学与工程(2017年1期)2017-05-04 03:40:46
作文与考试·初中版(2017年12期)2017-04-19 20:24:45
现代计算机(2016年3期)2016-09-23 05:52:13
浙江大学学报(工学版)(2016年11期)2016-06-05 09:21:03
西部广播电视(2015年5期)2016-01-16 03:45:06
中学生(2015年12期)2015-03-01 03:43:53
