
预测性对快速读者和慢速读者词汇加工的影响*
2023-01-04 00:18张慢慢胡惠兰张志超强白学军臧传丽1
心理学报 2023年1期
张慢慢 胡惠兰 张志超 李 鑫 汪 强白学军臧传丽1,,3
预测性对快速读者和慢速读者词汇加工的影响*
张慢慢1,2,3胡惠兰2张志超2李 鑫2汪 强1,2,3白学军1,2,3臧传丽1,2,3
(1教育部人文社会科学重点研究基地天津师范大学心理与行为研究院;2天津师范大学心理学部;3学生心理发展与学习天津市高校社会科学实验室, 天津 300387)
本研究借助眼动仪通过两个实验考察了熟练阅读中快速读者与慢速读者对语境预测性的利用是否有差异。实验1比较快速组与慢速组在中央凹加工高、低预测词的差异。实验2对比两组读者利用副中央凹预视(相同、相似假字、低预测词和不相似假字)加工高预测词的差异。实验1结果显示两组读者有相似的预测性效应:对高预测词的注视时间比低预测词更短。实验2结果显示两组读者的预视效应存在差异:慢速组在相同预视下对目标词的跳读率高于低预测预视, 而快速组在这两种预视下的跳读率差异不明显但高于慢速组; 慢速组在低预测和不相似预视下注视目标词的时间分别长于相同预视, 而快速组的这两种效应较小。结果表明, 两组读者利用预测性的差异表现在副中央凹加工阶段, 即慢速读者比快速读者利用相似预视激活预测性信息的效率更低, 且在低预测或无效预视下对词汇的识别和语义整合更困难, 这说明慢速读者在词汇加工中更依赖语境且对无关信息的抑制更弱。这些结果支持词汇质量假说。
预测性, 中央凹加工, 副中央凹预视, 快速读者, 慢速读者, 中文阅读
1 引言
在阅读中, 熟练读者不只是被动接收文字视觉信息输入, 还会主动凭借阅读经验并结合语境对后文内容形成预期(Ferreira & Chantavarin, 2018; Rayner et al., 2016)。那些符合读者预期的词也即高预测词, 它们只需较短的注视(即中央凹视觉区的信息加工)就可以被识别; 而且在被注视前, 通过副中央凹视觉区提取的有效信息(即副中央凹预视, parafoveal preview)可以提前激活高预测词, 导致对高预测词的跳读更多或注视更短(Clifton et al., 2016; Schotter et al., 2015; Staub & Goddard, 2019)。这表示通过前文语境预测即将出现的词可以使词汇的语义激活更早且更快, 词汇加工效率更高。而且, 高预测词比低预测词的回视更少、总注视时间更短, 即语义整合效率更高(Tiffin-Richards & Schroeder, 2020)。由此可见, 利用语境预测性是熟练阅读的一个重要内容(Ferreira & Chantavarin, 2018; Staub, 2015)。然而, 不同熟练读者对预测性的利用存在个体差异, 这是本研究关注的内容。
熟练阅读的个体差异可以使用阅读测验分数来区分(如: Ashby et al., 2005; Veldre & Andrews, 2015), 也可以直接使用有效的阅读速度来区分(如: 张慢慢, 臧传丽等, 2020; Jordan et al., 2016; Rayner et al., 2010)。在阅读理解有效的前提下, 阅读速度越快表明阅读效率越高(Ashby et al., 2005; Rayner et al., 2010)。有效的阅读速度是衡量个体阅读能力的一个非常有效的综合指标(Rayner et al., 2016)。因而, 本研究以阅读速度来区分个体差异, 关注具有熟练阅读技能(即可以良好地进行阅读理解)的读者; 其中, 阅读速度相对较快的读者为快速读者(fast reader), 阅读速度相对较慢的读者为慢速读者(slow reader; Rayner et al., 2010)。
关于不同阅读能力读者如何利用语境预测性进行词汇加工主要有两种理论解释。一种是词汇质量假说(lexical quality hypothesis; Perfetti, 2007)。词汇质量指读者的词汇知识, 包括词形、词义和词的用法, 其中“质量”指词的心理表征(包括音、形和义等)的精确性和灵活性。高质量的词汇表征不仅在音、形和义上有精确的特征, 而且音、形和义之间有很强的连接, 这可以促使读者快速提取词汇语义进而完成阅读理解。因此, 词汇表征质量是决定阅读能力的一个关键因素。高阅读能力或快速读者的词汇表征质量高, 对词汇的编码和识别更加自动化且高效, 其词汇加工对语境信息的依赖程度比较小。而低阅读能力或慢速读者的词汇知识不精确或词汇表征质量不高, 为了弥补这方面的不足, 他们更倾向于借助语境信息来预测并理解词义。也就是说, 该观点认为高阅读能力或快速读者采用自动化且独立于语境的词汇加工策略, 而低阅读能力或慢速读者采用基于语境的词汇加工策略。一些研究证实了借助语境预测词汇对较低阅读能力读者来说更为重要(Ashby et al., 2005; Veldre & Andrews, 2015)。例如, Ashby等人比较了中等阅读能力和高阅读能力读者对不同词频和预测性词汇加工的差异。结果显示, 在高预测语境中, 中等阅读能力读者在加工低频词时比高阅读能力读者更倾向于将注视尽快脱离目标词并返回到前文语境, 试图借助语境信息来通达目标词词义; 但是在低预测语境中, 由于中等阅读能力读者较难根据语境预测词义, 他们对高频词和低频词的注视时间都更长。这说明阅读能力较低的读者更依赖语境预测性来识别词汇。其他对青年读者(Slattery & Yates, 2018)、老年读者(Zhao et al., 2019, 2021)、儿童读者(Johnson et al., 2018; Liu et al., 2020)及聋人读者(Bélanger & Rayner, 2013)等群体的研究也支持该结论。
第二种是源于认知科学领域的预测编码(predictive coding)理论。该理论主张大脑在处理信息时普遍使用预测编码这一策略:大脑主动预期未来要发生的事件, 构建该事件的认知框架, 使未来事件的一些或全部特征得到预激活, 进而促进对未来事件的加工以及尽量减小预测错误(Clark, 2018; Williams, 2020)。在阅读中读者借助语境信息来预期即将出现的词汇, 从而促进了对这些词汇的加工。阅读理解的效率在很大程度上取决于预测的作用(Ferreira & Lowder, 2016)。也就是说阅读效率越高的个体, 其对预测性的利用程度越高:高阅读能力或快速读者由于阅读经验丰富、预测编码熟练, 他们利用语境预测词汇的效率更高; 而低阅读能力或慢速读者由于阅读经验少、预测编码不熟练, 不善于或较晚才使用预测性信息进行词汇加工(Hawelka et al., 2015)。Hawelka等人在比较快速读者与慢速读者预测性效应时发现, 预测性对快速读者跳读目标词的影响大于慢速读者, 即预测性越高, 越能促进快速读者跳读目标词; 慢速读者在注视目标词时受预测性的影响大于快速读者, 即预测性越高, 越能减少慢速读者的注视时间。这些结果说明快速读者通过副中央凹提前利用预测性对目标词进行了加工, 慢速读者较少通过副中央凹加工提前激活预测性信息, 更倾向于在注视目标词(即中央凹加工)时才开始利用预测性。类似结果在儿童读者中也被验证:成人读者在词汇加工早期开始借助预测性促进词汇加工, 而儿童读者则在词汇加工后期利用预测性进行词汇语义整合(Johnson et al., 2018; Tiffin-Richards & Schroeder, 2020)。这些研究表明高阅读能力读者可以迅速利用预测性提前对后文词汇加工, 对预测性的利用更加自动化。
由上述基于拼音文字阅读的研究可知, 词汇质量假说和预测编码理论对高、低阅读能力读者预测性效应的不同观点分别得到了实证数据支持。与拼音文字不同, 中文书写系统缺乏词切分标记, 每个字所占空间等同而复杂程度不同, 这导致中文读者表现出与拼音文字读者不完全相同的眼动模式(Li & Pollastek, 2020)。语境对中文词汇加工非常重要, 可以促进读者(尤其是低阅读能力读者; Liu et al., 2020)对较难词汇的加工(Huang & Li, 2020)。那么, 在熟练中文阅读中预测性效应的个体差异是否表现出不同于拼音文字的模式?这是本研究关注的问题。已有的中文研究对比了不同年龄群体的预测性效应。相比于青年读者, 阅读经验较少的儿童不能即时利用预测性进行词汇加工, 在后期的词汇语义整合过程才使用预测性信息(刘妮娜等, 2020); 老年读者经验相对丰富, 可以较早利用预测性加工词汇, 但后期需要更多回视进行语义整合以此来弥补认知老化带来的代价(Zhao et al., 2019)。对具有熟练中文阅读技能的青年读者来说, 其阅读经验相对丰富、认知发展相对稳定, 但他们的词汇加工存在个体差异:慢速读者比快速读者的词汇加工效率低(张慢慢等, 2022; 张慢慢, 臧传丽等, 2020)。那么, 是慢速读者更依赖语境预测性来完成词汇加工, 还是快速读者更善于预测后文的词汇?这是本研究旨在探讨的具体问题。对该问题的考察, 不仅可以为了解个体在毕生发展中利用语境预测性的变化趋势提供青年群体的证据, 还可以为当前的中文阅读模型(Li & Pollatsek, 2020)和其他眼动控制模型(如: E-Z读者模型, Reichle, 2011; SWIFT模型, Engbert & Kliegl, 2011)提供个体差异性研究的实证数据, 以拓展这些模型的适用范围。
前文提到预测性不仅在注视目标词(即中央凹加工)时发挥作用, 还通过副中央凹预视提前发挥作用——前提是预视信息有效(如: Chang et al., 2020; Staub & Goddard, 2019)。基于此, 本研究将通过两个实验分别从中央凹加工和副中央凹加工来揭示预测性对快速读者与慢速读者词汇加工的影响。实验1直接比较快速读者与慢速读者对高预测词和低预测词的加工是否存在差异, 主要揭示中央凹加工过程。根据以往研究, 读者对高预测词加工得更快取决于在副中央凹获得了有效预视, 而且副中央凹预视对高预测词加工的作用大于低预测词(Balota et al., 1985; Staub, 2015)。因此实验2以高预测词为目标词, 通过操纵高预测词的预视类型(相同、低预测、相似和不相似)来考察利用副中央凹预视激活预测性的个体差异。根据预测编码理论, 快速读者比慢速读者利用语境的程度高, 本研究预期快速读者比慢速读者有更大的预测性效应(实验1)和更大的预测性预视效应(实验2); 根据词汇质量假说, 快速读者的词汇质量更高且对语境依赖更小, 本研究预期快速读者比慢速读者有更小的预测性效应(实验1)和更小的预测性预视效应(实验2)。
2 实验1:预测性对快速读者和慢速读者中央凹词汇加工的影响
2.1 方法
2.1.1 被试
共67名母语为汉语的天津师范大学在校大学生或研究生参加了本实验。所有被试视力或矫正视力正常, 均不知道实验目的。实验结束后每人获得一定报酬。其中1名被试数据因阅读理解正确率较低且有较多数据记录丢失而被排除分析。对其余66名被试在实验中的阅读速度(即句子长度除以总阅读时间)排序, 参考以往研究(如: Jordan et al., 2016; 张慢慢, 臧传丽等, 2020), 选取阅读速度排名前15的被试作为快速组(= 567字/分,= 51字/分), 选取排名后15的被试作为慢速组(= 275字/分,= 37字/分), 快速组的阅读速度非常显著地快于慢速组(= −0.72,= 0.04,= −17.55,< 0.001, 95% CI = [−0.80, −0.64])。快速组被试的平均年龄为21 ± 1岁, 其中女生12名。慢速组被试的平均年龄为21 ± 2岁, 其中女生12名。
参考与本实验设计接近的研究(白学军等, 2011)得出在注视时间上预测性的效应值(Effect size= 0.67), 利用Gpower计算样本量为11时达到的统计检验力约为0.8。本实验同时关注快速组与慢速组的预测性效应, 每组各15名被试满足该效应的统计检验力。
2.1.2 实验材料
从Cai和Byrsbert (2010)的汉语字词语料库选取60对双字词作为目标词。将每对目标词编在相同句子框架中, 使每对目标词在句子语境下分别为高预测和低预测(如表1)。高预测词与低预测词的词频、首字字频和尾字字频均无显著差异(s < 1.23,s > 0.05), 二者的总笔画数、首字和尾字笔画数也无显著差异(s < 1.12,s > 0.05)。具体信息如表2。

表1 高预测与低预测条件下的实验材料举例
注:示例中“电影”为高预测词, “话剧”为低预测词。
采用5点(“1”代表“非常不通顺”, “5”代表“非常通顺”)等级评定量表, 请40名天津师范大学在校学生(未参与其他评定和眼动实验)对含有高预测词和低预测词的句子进行通顺性评定。高预测条件下句子的通顺性(= 4.23,= 0.38)比低预测条件下的通顺性(= 4.09,= 0.38)高,(1, 59) = 11.26,= 0.001, ηp2= 0.16。但是, 把通顺性作为协变量的数据分析显示, 通顺性差异不影响高预测与低预测条件在各个指标上的结果(注视时间:||s < 1.34,s > 0.05; 跳读率:= 0.37,= 0.712)。
另请20名天津师范大学在校学生对目标词的预测性进行评定。具体过程为, 要求被试只根据句子前半部分信息(目标词及其之后的内容被略去)来填补句子后面内容。依据补充的内容计算出目标词的预测性。高预测词被预测出的概率(= 0.69,= 0.15)显著高于低预测词(= 0.02,= 0.04),(1, 59) = 1084,< 0.001, ηp2= 0.95。

表2 高预测词和低预测词的词频和笔画数信息
注:括号内为标准差。
2.1.3 实验设计
采用2 (阅读组别:快速组、慢速组) × 2 (预测性:高预测、低预测)的混合实验设计。其中, 阅读组别为被试间变量, 预测性为被试内变量。
2.1.4 实验仪器
使用加拿大SR Research公司生产的EyeLink 1000 Plus眼动仪记录被试的眼动轨迹。该仪器的采样率为1000 Hz。实验刺激呈现屏的刷新率为144 Hz, 分辨率为1024×768像素。实验材料以黑色宋体在白色背景下呈现。被试离刺激呈现屏约为55 cm, 每个字约占0.89°视角。
2.1.5 程序
每个被试单独施测。被试进入相对安静的实验室后, 填写基本信息与知情同意书。主试引导被试以相对舒适的坐姿就坐, 要求被试将下巴正确放在下巴托上以确保头部相对固定。随后, 向被试呈现指导语“接下来会在屏幕中逐个呈现一些句子, 请认真阅读并理解每个句子的意思。有些句子后有阅读理解判断题, 请根据前一句的内容进行判断。如果判断为‘是’, 请按‘F’键; 如果判断为‘否’, 请按‘J’键”。主试在确保被试正确理解指导语后, 对被试的眼睛进行三点校准。校准结束后进入练习环节。练习共8个句子, 其中5句含判断题。被试熟悉实验流程后, 进入正式实验。正式实验共60个句子, 其中20句有判断题。所有句子随机呈现。整个实验约持续25分钟。
2.2 结果
快速组的阅读理解正确率为92% (= 5%), 慢速组的阅读理解正确率为90% (= 6%), 说明两组被试均能很好理解句子且没有显著差异,(1, 14) = 0.05,= 0.831。
在筛选原始眼动数据时, 首先排除注视时间小于80 ms或大于1200 ms的注视点。之后, 根据下列标准删除极端情况的句子:(1)被试按键失误或头动导致的追踪丢失(0.83%); (2)句子总注视点少于3个(2.3%); (3)分析指标在3个标准差之外(整体分析: 0.85%, 局部分析: 1.03%)。
数据分析主要包括以句子为单位的整体分析和以目标词为兴趣区的局部分析。前者用来检验快速组与慢速组整体阅读水平的差异, 分析指标包括平均注视时间、向前眼跳长度和次数、向后眼跳长度和次数、总阅读时间(闫国利等, 2013; 张慢慢, 臧传丽等, 2020)。平均注视时间体现了每一次注视的情况, 一般与总注视次数结合使用, 平均注视时间长且总注视次数多, 说明句子整体难度大。总阅读时间从整体上反映句子加工难度, 句子越难或个体阅读能力较低, 总阅读时间越长, 综合反映每次注视的时间和总注视次数。向前眼跳长度和次数可以反映后文内容加工的难易, 随后文内容难度增加, 向前眼跳变短, 向前眼跳次数增多。向后眼跳(或回视)长度和次数, 反映了句子语义整合情况, 向后眼跳短或次数多, 表明语义整合较难。此外, 向前和向后眼跳次数可以共同反映总体注视次数。
目标词分析用来检验两组读者利用预测性信息加工中央凹词汇的差异, 分析指标包括第一遍阅读过程中在目标词上的(1)首次注视时间(first fixation duration, FFD; 首个注视点的时间), (2)单次注视时间(single fixation duration, SFD; 有且只有一次注视的时间), (3)凝视时间(gaze duration, GD; 从首次注视到首次离开目标词之间的所有注视的时间之和), (4)跳读率(skipping probability, SP; 目标词被跳读的概率)。这些指标反映了目标词的识别过程:第一遍阅读时间越短、跳读率越高, 表明目标词越容易被识别(闫国利等, 2013)。此外, 还分析(5)回视路径时间(regression path duration, RPD; 在第一遍阅读中从目标词上的第一次注视开始到眼睛越过目标词右侧前的所有注视点时间总和)和(6)总注视时间(total fixation duration, TFD; 在目标词上的所有注视点时间总和), 这两个时间的长短分别反映了后期语义整合和总体词汇加工的难易程度。
所有指标在R语言环境下(R Development Core Team, 2021)使用lme4数据处理包(Bates et al., 2015)建立线性混合模型(Linear Mixed Model)进行分析。使用马尔可夫链蒙特卡罗(Markov-Chain Monte Carlo)算法得出事后分布的模型参数作为显著性的估计值(), 能同时反映来自被试和项目的变异(Baayen et al., 2008)。在运行线性混合模型前, 对注视时间、注视次数、眼跳长度和阅读速度指标进行对数转换。对跳读数据的分析使用广义线性混合模型(Generalized Linear Mixed Model)。在模型中, 阅读组别和预测性为固定因素, 被试和项目为交叉随机效应, 同时考虑被试和项目的随机截距和随机斜率(Barr et al., 2013)。
2.2.1 句子分析
对句子整体分析的描述性结果与固定效应结果见表3。结果显示, 阅读组别主效应在整体分析的指标(除向后眼跳长度外)非常显著(||s > 3.79,s < 0.001)。具体表现为, 与快速组相比, 慢速组对句子平均注视时间更长, 向前眼跳更短且更多, 向后眼跳(即回视)更多, 总阅读时间更长, 整体速度更慢。这些说明快速组与慢速组的区分非常有效。
2.2.2 目标词分析
快速组与慢速组在目标词上各眼动指标的平均数和标准差如表4所示, 固定效应估计值见表5。
阅读组别主效应在各指标上都非常显著(||s > 3.40,s < 0.01), 即与快速组相比, 慢速组对目标词的首次注视、单次注视、凝视、回视路径和总注视时间更长, 跳读更少。
预测性主效应在注视时间指标上非常显著(s > 2.49,s < 0.05), 而在跳读率(= −0.89,= 0.372)上不显著。具体表现为, 被试对低预测词的首次注视、单次注视、凝视、回视路径和总注视时间都比高预测词更长。不过, 被试对高预测词和低预测词的跳读率相近。
阅读组别与预测性的交互作用在各指标上都不显著(||s < 1.22,s > 0.05), 即预测性效应在快速组与慢速组上没有显著差异。使用BayesFactor数据处理包进行线性混合模型的贝叶斯分析(Morey et al., 2018)进一步确定阅读组别与预测性是否存在交互作用。通过对比全模型(包含阅读组别主效应、预测性主效应和两因素的交互作用)的贝叶斯因子(Full)与主效应模型的贝叶斯因子(Main), 即=Full/Main, 可以评价阅读组别与预测性是否存在交互作用。若值小于1, 则支持两因素没有交互作用; 若值大于1, 则支持两因素存在交互作用。默认先验概率值设为0.5, 蒙特卡罗迭代次数(Monte Carlo iterations)设定为100000。结果显示, 各指标的值均小于1 (SP:= 0.07; FFD:= 0.13; GD:= 0.17; SFD:= 0.26; RPD:= 0.11; TFD:= 0.10), 支持无交互作用。使用不同先验概率值(即0.2、0.3、0.4、0.5、0.6、0.7和0.8)进行敏感性分析的结果也支持无交互作用。

表3 快速组与慢速组在句子上的平均眼动指标与阅读组别固定效应估计值
注:char.表示单位为字, 下同。

表4 快速组与慢速组在高、低预测目标词上的平均眼动指标
注:FFD表示首次注视时间, SFD表示单次注视时间, GD表示凝视时间, SP表示跳读率, RPD表示回视路径时间, TFD表示总注视时间。括号内为标准差。下同。

表5 在目标词上各指标的固定效应估计值
注:S和F分别表示慢速组和快速组, LP和HP分别代表低预测和高预测条件。下同。
2.3 讨论
实验1通过对比快速组与慢速组对高、低预测词的中央凹加工来检验两组读者利用预测性的差异。在目标词上存在明显的预测性效应:被试对高预测词的第一遍阅读时间、回视路径时间和总注视时间比低预测词更短。组别主效应也非常显著, 即快速组比慢速组对目标词的第一遍阅读时间、回视路径时间和总注视时间更短, 跳读率更高。该结果与以往研究结果非常一致(如: Ashby et al., 2005; Hawelka et al., 2015; Slattery & Yates, 2018)。更重要的是, 上述指标一致显示阅读组别与预测性没有交互作用, 即快速组与慢速组的预测性效应没有显著差异。这意味着无论在词汇的早期识别过程还是在后期语义整合阶段, 快速组和慢速组都利用了预测性信息, 且利用程度没有差异。这与拼音文字阅读研究结果不同, Ashby等人发现较低阅读能力读者在早期词汇识别和后期语义整合过程受预测性的影响都大于高阅读能力读者。实验1结果与中文阅读中的儿童读者与老年读者利用预测性的模式也不同(刘妮娜等, 2020; Zhao et al., 2019, 2021), 具体见总讨论。
另外, Hawelka等人(2015)发现快速读者在注视目标词前通过副中央凹利用预测性加工了目标词, 进而对目标词有更多跳读; 而慢速读者则在注视目标词时才开始使用预测性加工词汇。然而本实验结果显示快速组与慢速组在跳读率上的预测性效应相似, 与Slattery和Yates (2018)的研究结果相似。跳读率在一定程度上反映了读者副中央凹加工的情况(张慢慢, 张志超等, 2020), 但是上述研究与本实验均没有直接操纵副中央凹预视, 无法明确快速读者与慢速读者在副中央凹加工中对预测性的利用是否存在差异。而且在中文阅读中双字词的跳读普遍较低(如: 张慢慢, 臧传丽等, 2020; Zhao et al., 2021), 仅参考该指标难以全面了解副中央凹预视情况。鉴于此, 实验2将通过对目标词设置不同预视来检验上述问题。
3 实验2:副中央凹预视对快速与慢速读者预测词加工的影响
3.1 方法
3.1.1 被试
来自天津师范大学共85名在校大学生和研究生参加了本实验。所有被试视力或矫正视力正常, 其母语均为汉语, 均不知道实验目的且未参加实验1。实验后每人获得一定报酬。由于5名被试阅读理解正确率较低, 其数据被剔除。对80名有效被试的阅读速度排序, 选取前20名被试作为快速组(= 655字/分,= 133字/分), 选取后20名被试作为慢速组(= 309字/分,= 28字/分), 快速组的阅读速度非常显著地高于慢速组(= −0.72,= 0.05,= −15.62,< 0.001, 95% CI = [−0.82, −0.63])。快速组与慢速组的年龄均为20 ± 1岁, 快速组有16名女生, 慢速组有17名女生。
参考与本实验设计较接近的研究(Drieghe et al., 2005)得出在注视时间上预视类型的效应值(Effect size= 0.70), 利用Gpower计算样本量为14时达到的统计检验力约为0.8。本实验同时关注快速组与慢速组的预视效应, 每组20人可满足该效应统计检验力。
3.1.2 实验材料
选用实验1高预测条件的句子作为实验材料, 其中高预测词为目标词。使用边界范式(boundary paradigm; Rayner, 1975)操纵目标词整词的预视(如图1所示), 包括相同预视(目标词本身)、低预测预视、相似预视和不相似预视。低预测预视为实验1中的低预测词。相似预视或不相似预视是通过同时操纵目标词的首字和尾字的视觉相似或不相似实现的。相似预视是与目标词视觉相似的假字, 其首字笔画数为8 ± 3, 尾字笔画数为8 ± 3。不相似预视是与目标词不相似且读者不熟知的字(Windows系统自带专用字符), 其首字笔画数为8 ± 3, 尾字笔画数为8 ± 2。4种预视条件下首字笔画数、尾字笔画数和总笔画数没有显著差异(s < 2.67,s > 0.05)。

图1 不同预视条件下的实验材料举例
注:“动物”为目标词, 虚线仅为了显示隐形边界所在位置, 在正式实验中不会呈现; 眼睛越过边界后, 预视内容都被目标词“动物”替代。相似预视和不相似预视是通过对目标词的两个字均进行操纵实现的。
在边界范式中, 目标词(如“动物”)之前会设置一条隐形的边界, 当眼睛在边界之前, 目标位置呈现的是预视内容; 在眼睛越过边界时, 预视内容被目标词取代。通过对比不同预视下对目标词的注视时间等指标, 可以得知读者提取副中央凹信息的差异。
3.1.3 实验设计
采用2 (阅读组别:快速组、慢速组) × 4 (预视类型:相同预视、低预测预视、相似预视、不相似预视)的两因素混合实验设计。阅读组别为被试间变量, 预视类型为被试内变量。
下面具体解释设置4种预视类型的目的及不同预视类型对比的作用:(1)设置不相似预视(与目标词和句子语境无关)作为控制条件。与控制条件相比, 如果其他类型预视下对目标词的注视时间减少,即可知读者获得了某类预视效应, 或者说读者从副中央凹提取了该类信息(Clifton et al., 2016; Rayner et al., 2016)。(2)通过比较相同预视与不相似预视可得出完全有效或相同预视下的效应, 即经典的预视效应(Rayner et al., 2016)。(3)通过设置低预测预视来检验预测性在副中央凹预视中是否发挥作用:首先比较低预测预视与不相似预视, 若前者比后者注视时间短或跳读率高, 则说明读者获得了低预测且语义连贯(可用通顺性衡量)的预视; 在此基础上, 如果相同预视(高预测且语义连贯)比低预测预视下的注视时间更短或跳读率高, 则说明读者可以获得预测性的预视效应。(4)有研究发现副中央凹的部分视觉信息足够激活高预测词的表征(Balota et al., 1985)。为此, 设置与目标词视觉相似的预视来检验部分视觉信息对高预测词加工的作用:首先比较相似预视与不相似预视可以得到相似预视效应, 再比较相似预视与相同预视可知部分视觉信息发挥的作用是否等同于相同预视。在结果分析中重点关注(3)和(4)中的比较。预测性预视效应越大, 表明读者对预测性的利用程度越高或者对语境更依赖。相似预视与相同预视差异越小, 表明读者利用部分视觉信息激活高预测词的程度越高。
3.1.4 实验仪器
采用加拿大SR Research公司生产的EyeLink 1000塔式眼动仪记录被试的眼动轨迹。该仪器的采样率为1000 Hz, 显示器的刷新率为150 Hz, 分辨率为1024×768像素。实验刺激以黑色宋体在白色背景下呈现。被试距离屏幕约为65 cm。每个汉字大小约为1.1°视角。
3.1.5 程序
同实验1。实验2有8个练习句, 其中4句设有阅读理解判断题。正式实验包含60个实验句和40个填充句, 其中有36句设有阅读理解判断题。所有句子随机呈现。整个实验约持续30分钟。
3.2 结果
快速组(= 93.13%,= 4%)与慢速组(= 95.41%,= 4%)对句子的阅读理解正确率没有显著差异,(1, 19) = 0.36,= 0.552, 表明两组读者都可以很好地理解句子内容。
针对原始数据, 首先剔除短于80 ms或长于1200 ms的注视点。然后根据以下标准筛选句子:(1)删除由于被试按键失误或头动导致的追踪丢失的句子(0.17%); (2)删除句子总注视点少于3个的句子(0.21%); (3)边界变化过早或延迟, 或第一次通过边界或注视目标词时眨眼的句子(17.46%)。(4)删除注视时间指标在3个标准差之外的句子(句子分析:0.86%, 目标词分析:0.87%)。分析指标和分析方法同实验1, 只是在实验2的模型中, 固定因素为预视类型和阅读组别。
3.2.1 句子分析
快速组与慢速组在句子水平各指标的平均值与组别固定效应结果如表6所示。在整体分析的指标(除向后眼跳长度外)表现出非常显著的组别效应(||s > 4.56,s < 0.001)。具体来说, 与快速组相比, 慢速组的平均注视时间更长, 向前眼跳更短且次数更多, 向后眼跳(即回视)次数更多, 总阅读时间更长, 整体速度更慢。这表明两组被试在阅读整体水平上的差异非常明显, 实验2对两组被试的划分非常有效。
3.2.2 目标词分析
快速组与慢速组对目标词的注视和跳读的平均数和标准差如表7所示, 在目标词上的固定效应结果见表8。
阅读组别主效应在跳读率、单次注视时间、凝视时间、回视路径时间和总注视时间上非常显著(s > 2.06,s < 0.05), 在首次注视时间上边缘显著(1.98,= 0.055)。即与快速组相比, 慢速组对目标词跳读率更低, 第一遍阅读时间、回视路径时间和总注视时间都更长。这表明快速组的词汇加工整体上比慢速读者更快。
预视类型主效应在跳读率和注视时间上都非常显著。在跳读率上:(1)相同预视和低预测预视分别比不相似预视条件的跳读率更高(|s > 5.37,s < 0.001), 但是, 低预测预视与相同预视的跳读率没有显著差异(= −0.87,= 0.385), 这表明了无论预视内容的预测性高或低, 只要预视内容与句子语义连贯就会引起跳读。(2)相似预视下的跳读率高于不相似预视(= −4.40,< 0.001), 但低于相同预视(= −2.10,= 0.036), 这说明副中央凹部分视觉信息可以促使读者跳读, 但其促进程度未达到相同预视的水平。在注视时间上:(1)相同预视下的注视时间显著短于不相似预视(|s > 7.48,s < 0.001), 即相同预视效应。除了总注视时间外(= 0.87,0.385), 低预测预视条件下的第一遍阅读时间(FFD、SFD和GD)和回视路径时间都显著短于不相似预视(|s > 4.86,s < 0.001)。而且, 相同预视比低预测预视下的注视时间更短(|s > 3.55,s < 0.001)。这些表明了被试在副中央凹加工中利用了预测性信息。(2)相似预视比不相似预视下的注视时间更短(|s > 4.67,s < 0.001), 即相似预视效应。不过, 相似预视下的注视时间长于相同预视(|s > 3.53,s < 0.001)。这说明相似预视促进了目标词加工, 但被试从相似预视中的获益程度小于相同预视。
阅读组别与预视类型的交互作用在跳读率上显著, 具体是阅读组别×预视(低预测vs.相同)效应显著(= −2.66,= 0.008)。简单效应分析表明, 快速读者在低预测与相同预视下对目标词的跳读率差异边缘显著(= 0.03,= 0.02,= 1.70,= 0.088), 而慢速读者在相同预视下对目标词的跳读显著多于低预测预视(= −0.04,= 0.02,= −2.23,= 0.025),说明慢速读者只在预视内容是高预测时才更容易跳读。其他交互作用不显著(|s < 1.67,s> 0.05)。

表6 快速组与慢速组对句子的平均注视情况与阅读组别固定效应估计值
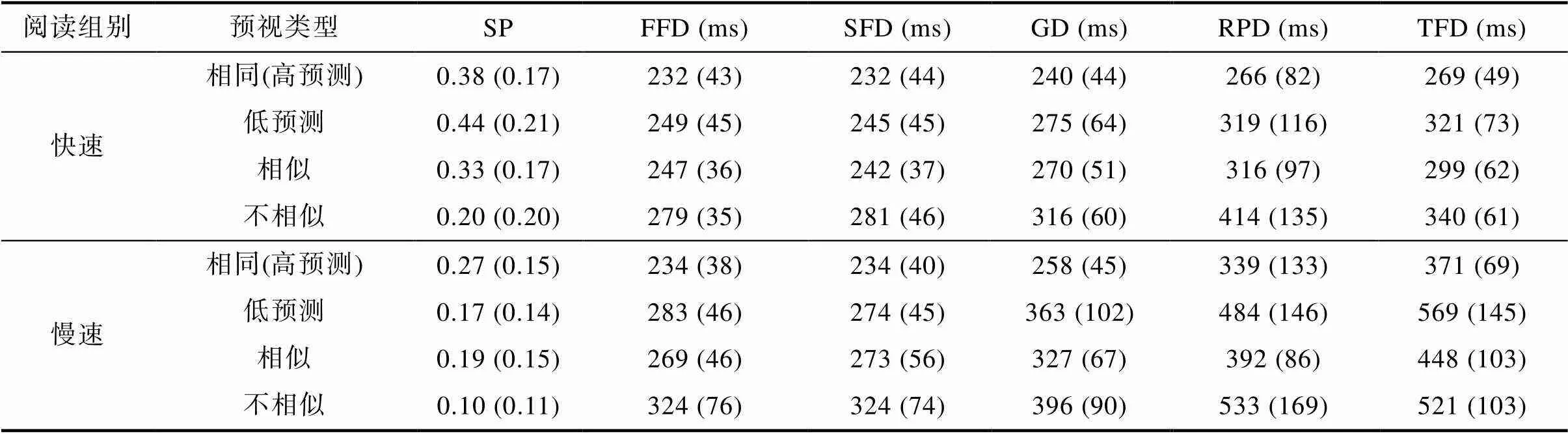
表7 快速组与慢速组对目标词的平均注视和跳读率
注:括号内为标准差。
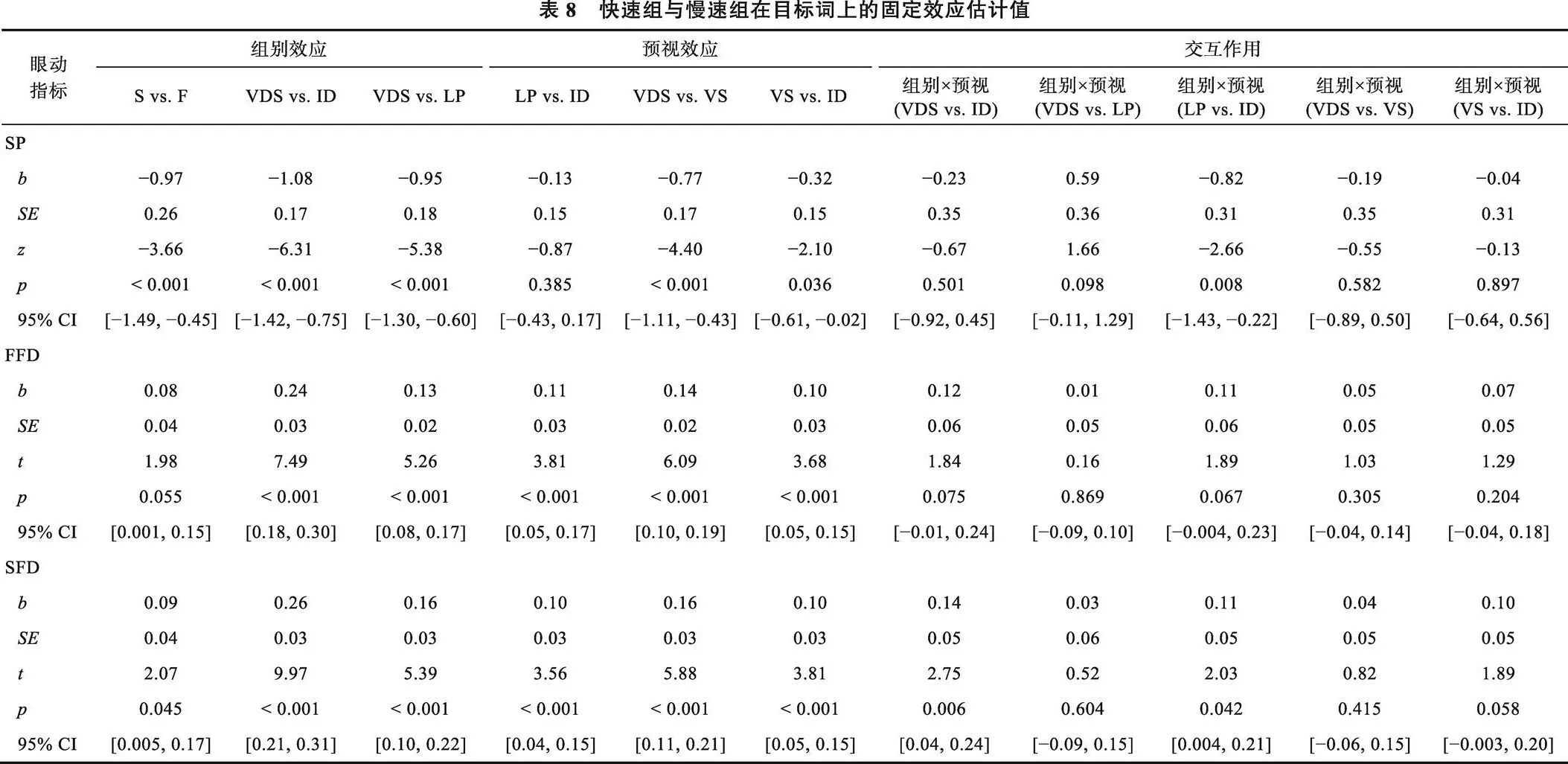
阅读组别与预视类型的交互作用在注视时间上显著。(1)阅读组别×预视(不相似vs.相同)在首次注视时间边缘显著(= 1.84,= 0.075), 在单次注视时间、凝视时间和总注视时间非常显著(s > 2.08,s < 0.05), 在回视路径时间上不显著(= 1.23,0.226)。简单效应分析表明两组被试都有显著的相同预视效应(快速组:s > 4.50,s < 0.001; 慢速组:s > 7.69,s < 0.001), 即在不相似预视下对目标词的注视时间显著长于相同预视; 但是慢速组比快速组的相同预视效应更大。这主要是由于慢速组在不相似预视下对目标词的注视更长导致的。阅读组别×预视(不相似vs.低预测)不显著, 即两组读者的低预测与不相似预视效应相似(|s < 1.46,s > 0.05)。阅读组别×预视(低预测vs.相同)在首次注视时间上边缘显著(= 1.89,= 0.067), 在单次注视、凝视时间、回视路径和总注视时间上显著(s > 2.02,s < 0.05)。简单效应分析显示, 预测性预视效应在快速组中不明显(FFD:= 0.03,= 0.02,= 1.66,= 0.096; SFD:= 0.03,= 0.02,= 1.31,= 0.192)或效应较小(GD:= 0.06,= 0.02,= 2.39,= 0.017; RPD:= 0.07,= 0.03,= 2.18,= 0.029; TFD:= 0.07,= 0.03,= 2.72,= 0.007), 而在慢速组中的效应非常显著且更大:低预测预视下对目标词的注视时间长于相同预视条件(s> 4.10,s < 0.001)。这些表明慢速组在低预测预视下对目标词的加工比快速组更困难, 反映了他们对语境更依赖。(2)阅读组别×相似预视(不相似vs.相似)在各个注视时间上不显著(|s < 1.04,s > 0.05)。阅读组别×预视(相似vs.相同)在首次注视时间、回视路径时间和总注视时间上不显著(|s < 1.64,s > 0.05), 在凝视时间(1.82,0.069)和单次注视时间(1.89,0.058)上边缘显著。简单效应分析表明, 相似与相同预视的差异在快速组中较小或不明显(|s< 1.83,s > 0.05), 而在慢速组中非常显著:相似预视下对目标词的单次和凝视时间显著长于相同预视(SFD:= 0.07,= 0.02,= 3.91,< 0.001; GD:= 0.10,= 0.02,= 4.61,< 0.001)。结合以上分析可知, 快速组在副中央凹对部分视觉信息的利用程度接近相同预视; 而慢速组虽然可以利用副中央凹的部分视觉信息加工目标词, 但其效率低于快速组。
3.3 讨论
实验2检验了快速读者与慢速读者在副中央凹加工中通过预视激活预测词的差异。与实验1一致, 实验2的目标词上也有显著的阅读组别主效应。在注视时间上, 相同(高预测)预视短于低预测预视, 且二者均比不相似预视更短, 这表明了两组读者在副中央凹加工中利用预视信息激活了预测性并随即促进了对目标词的加工。但是, 在跳读率上没有发现预测性的预视效应。这可能是由于双字词的跳读率普遍较低, 预测性对跳读的影响不敏感(Zhao et al., 2021); 也可能是由于影响跳读与注视的眼动控制机制不同(Zhang et al., 2019)。另外, 在跳读和注视时间上相同预视效应大于相似预视效应, 这表明部分预视信息促进了目标词的识别, 但其促进作用小于相同预视。
快速读者与慢速读者对高预测词的预视效应存在差异。一方面, 慢速组比快速组的预测性预视效应更大, 主要体现在低预测预视条件下慢速读者对目标词的第一遍阅读时间(首次、单次和凝视时间)、回视路径时间和总注视时间比快速读者更长, 即慢速读者在早期词汇识别和后期语义整合均存在更大困难。这表明慢速读者在副中央凹预加工过程中更依赖语境, 进而对随后的中央凹词汇识别与语义整合有更大的影响。另一方面, 与相同预视或相似预视相比, 慢速读者在不相似预视下对目标词第一遍阅读时间和总注视时间显著大于快速读者, 即对目标词加工更困难, 这意味着慢速读者的词汇加工更易受副中央凹无效预视信息的干扰, 与以往研究结果一致(张慢慢, 臧传丽等, 2020)。在跳读率上, 快速组对高预测和低预测预视下的目标词跳读都比较高; 而慢速组整体上比快速组跳读更少, 且只有在高预测预视时才更倾向于跳读。这些结果不支持Hawelka等人(2015)发现的慢速读者无法在副中央凹利用预测性信息的结论。具体原因见总讨论。
4 总讨论
本研究通过两个实验考察了在中文阅读中快速读者与慢速读者对预测性信息加工的差异。实验1主要检验快速读者与慢速读者对高、低预测词的中央凹加工过程。在此基础上, 实验2从副中央凹加工角度检验快速与慢速读者利用预视激活高预测词的差异。实验1结果显示, 在目标词的第一遍阅读时间、跳读率、回视路径时间和总阅读时间上, 快速读者与慢速读者的预测性效应没有差异。也就是说, 两组读者在词汇的识别和语义整合过程中利用预测性的程度相同。实验2通过操纵高预测词的副中央凹预视发现, 快速读者与慢速读者在副中央凹预视中都激活了预测性信息, 但是两组读者借助副中央凹预视加工高预测词的模式存在显著差异。具体表现在两个方面:一是慢速读者比快速读者有更大的预测性预视效应(低预测vs.相同), 这主要是由于慢速读者在低预测预视下对目标词的识别和语义整合较困难。二是慢速读者比快速读者有更大的不相似与相同效应以及相似与相同效应, 这主要是由于当副中央凹呈现不相似预视时慢速读者对目标词的加工出现困难, 当呈现相似预视时慢速读者利用副中央凹部分视觉信息通达目标词词义的效率较低。
由两个实验结果可知, 本研究未发现快速读者比慢速读者有更大的预测性效应, 与Hawelka等人(2015)的研究不一致, 不符合预测编码理论的观点。该理论预期, 高阅读能力读者或快速读者在阅读中可以更早且更有效地利用预测性, 在词汇加工中表现出更大的预测性效应; 而低阅读能力读者或慢速读者由于阅读经验较少不能很好地利用预测性进行词汇加工, 从而表现出更小的预测性效应(Hawelka et al., 2015)。然而, 本研究的实验2揭示了在副中央凹加工中慢速读者有更大的预测性预视效应:当预视内容不符合预期时他们在目标词的识别和语义整合过程都需要花费更多时间来完成, 体现了慢速读者对语境有更大的依赖。该结果更符合词汇质量假说的观点, 即高效率阅读得益于高质量(精准、连贯且充分)的词汇表征, 慢速读者由于词汇表征质量不高, 需要借助语境来识别词汇以保证阅读理解顺利进行(Perfetti, 2007; Veldre & Andrews, 2015)。而且, 在实验2中快速读者在副中央凹利用部分视觉信息与利用相同预视信息加工目标词的效果相近, 但是慢速读者借助部分视觉预视加工目标词的程度显著低于相同预视, 这意味着快速读者利用部分视觉信息激活目标词的正字法表征更高效, 反映了其词汇编码的质量更高。该观点在其他相关研究也得到验证, 例如, 快速读者比慢速读者能更有效利用词汇空间频率(即单位视角内某刺激呈现的视觉细节程度), 特别是对低空间频率的利用(Jordan et al., 2016); 高阅读能力儿童读者从视觉相似预视获得的预视效益大于低阅读能力儿童(Johnson et al., 2018)。这些结果共同说明, 相比于慢速读者或低阅读能力读者, 快速读者或高阅读能力读者对副中央凹信息(包括部分副中央凹信息)的利用程度更高, 能更快地从视觉信息通达词汇信息。在本研究中快速读者从副中央凹提取到的部分视觉信息可以更快且更自动化地用于词汇通达, 这可能是因为快速读者有更精细的词汇表征,也可能是由于快速读者从副中央凹提取的部分视觉与目标词的语境整合效率更高。此外, 结合慢速读者受不相似预视的干扰比快速读者更大这一结果可知, 慢速读者在抑制不符合语境或无效的预视信息的激活时比较低效, 而快速读者在抑制不符合预期的信息激活或解决不正确预视带来的冲突方面更高效, 支持了以往研究(如: Gernsbacher, 1993; Tiffin-Richards & Schroeder, 2020; Veldre & Andrews, 2015; 张慢慢, 臧传丽等, 2020)。综合上述分析, 本研究结果更支持词汇质量假说。
上述结果在一定程度上也反映了中文阅读的独特性。根据Hawelka等人(2015)对拼音文字的研究, 快速读者在副中央凹加工过程开始利用语境预测性提前加工目标词, 慢速读者则在注视目标词时(中央凹加工)才开始借助语境进行词汇识别。而本研究实验2的结果表明中文阅读中快速与慢速读者在副中央凹加工中都利用了预测性信息。由于中文文本排列紧密且没有明确词边界信息, 因此中文阅读中的词汇加工比拼音文字更复杂或更有难度。根据中文阅读模型(Li & Pollatsek, 2020), 知觉广度内的汉字是平行加工的, 词汇识别和词切分同时发生, 这导致中文读者普遍比拼音文字读者提取更多的副中央凹信息。即便是阅读能力较低的儿童读者(刘妮娜等, 2020)或成人慢速读者(本研究)也能较早提取副中央凹信息。因此中文阅读中的慢速读者或低阅读能力读者更可能在副中央凹加工中就开始依赖语境信息来切分词汇或加工词汇。这体现了中文读者在阅读中对文本书写特征的独特适应性。
从中文阅读发展角度来说, 本研究发现在青年读者群体中的个体差异与其他年龄群体的差异模式不同。以往对中文阅读的研究发现, 高阅读能力儿童在副中央凹加工阶段开始利用预测性信息, 而低阅读能力儿童读者则在晚期词汇整合中才开始利用(刘妮娜等, 2019); 老年人从词汇识别到后期语义整合都对语境非常依赖(Zhao et al., 2019)。在本研究中, 快速与慢速青年读者都能获得预测性预视信息。这些结果整体上表明了青年读者的副中央凹加工效率高于儿童读者和老年读者。然而青年读者的副中央凹加工存在个体差异, 即慢速读者的词汇加工受预测性预视信息的影响大于快速读者, 不支持一致性假说(uniformity assumption, Andrews, 2015):在成为熟练读者以后, 不同个体之间的阅读过程一致, 只是信息处理速度的差异。相反, 本研究结果支持差异性观点:阅读过程中的个体差异在毕生发展中普遍存在, 即便成为熟练读者后不同个体之间的阅读过程也可能存在本质区别(Rayner et al., 2012; Reichle et al., 2013)。本研究发现快速与慢速读者利用预测性信息加工词汇的模式存在本质差异:在副中央凹加工阶段, 慢速读者比快速读者更依赖语境, 并进一步影响其随后的中央凹加工和语义整合。基于拼音文字提出的E-Z读者模型通过对儿童读者与成人读者在阅读中眼动数据的模拟证实, 阅读技能的发展与提高主要是由于词汇加工和后期语言加工效率的提升, 这也是决定读者眼动模式的主要因素。尽管阅读个体差异方面的研究数据较少, 但该模型推测, 阅读发展中的个体差异也主要是由于词汇加工的准确性或速度的差异导致的(Reichle et al., 2013)。本研究发现慢速读者的副中央凹加工效率低、对语境依赖更大, 其随后的中央凹词汇加工和后期语义整合都受到这一事实的影响, 符合E-Z读者模型的推测。虽然中文阅读模型(Li & Pollatsek, 2020)对预测性效应进行了很好的模拟和解释, 但主要是基于一般大学生群体的眼动数据建立的, 该模型对中文阅读中的个体差异尚未做具体预测和模拟。本研究结果可为检验当前理论提供来自中文阅读个体差异方面的证据。
5 结论
由本研究可知, 在中文阅读中, 快速读者与慢速读者利用预测性的差异表现在副中央凹加工阶段。具体为, 与快速读者相比, 慢速读者利用副中央凹相似预视激活预测信息的效率更低, 在低预测或无效预视下进行词汇识别和语义整合时更困难, 表明了慢速读者在词汇加工中更依赖语境且对无关信息的抑制更弱。这些结果支持了词汇质量假说。
Andrews, S. (2015). Individual differences among skilled readers: The role of lexical quality. In A. Pollatsek, & R. Treiman (Eds.),(pp. 129−148). New York, NY, US: Oxford University Press.
Ashby, J., Rayner, K., & Clifton, C. (2005). Eye movements of highly skilled and average readers: Differential effects of frequency and predictability.(Section A),(6), 1065−1086.
Baayen, R. H., Davidson, D. J., & Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items.,(4), 390−412.
Bai, X. J., Cao, Y. X., Gu, J. J., Guo, Z. Y., & Yan, G. L. (2011). Effects of Predictability and space on Chinese reading: An eye movement study.,(6), 1282−1288.
[白学军, 曹玉肖, 顾俊娟, 郭志英, 闰国利. (2011). 可预测性和空格对中文阅读影响的眼动研究.,(6), 1282−1288.]
Balota, D. A., Pollatsek, A., & Rayner, K. (1985). The interaction of contextual constraints and parafoveal visual information in reading.,(3), 364−390.
Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: Keep it maximal.,(3), 255−278.
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4.,(1), 1−48.
Bélanger, N. N., & Rayner, K. (2013). Frequency and predictability effects in eye fixations for skilled and less− skilled deaf readers.,(4), 477−497.
Cai, Q., & Brysbaert, M. (2010). SUBTLEX−CH: Chinese word and character frequencies based on film subtitle.,, e10729.
Chang, M., Zhang, K., Hao, L. S., Zhao, S. N., McGowan, V. A., Warrington, K. L., … Gunn, S. C. (2020). Word predictability depends on parafoveal preview validity in Chinese reading.,(1), 33−40.
Clark, A. (2018). A nice surprise? Predictive processing and the active pursuit of novelty.,(3), 521-534.
Clifton, C., Ferreira, F., Henderson, J. M., Inhoff, A. W., Liversedge, S. P., Reichle, E. D., & Schotter, E. R. (2016). Eye movements in reading and information processing: Keith Rayner’s 40 year legacy.,, 1−19.
Drieghe, D., Rayner, K., & Pollatsek, A. (2005). Eye movements and word skipping during reading revisited.,(5), 954−969.
Engbert, R., & Kliegl, R. (2011). Parallel graded attention models of reading. In S. P. Liversedge, I. D. Gilchrist, & S. Everling (Eds.),(pp.787−800). New York, NY, US: Oxford University Press.
Ferreira, F., & Chantavarin, S. (2018). Integration and prediction in language processing: A synthesis of old and new.,(6), 443−448.
Ferreira, F., & Lowder, M. W. (2016). Prediction, information structure, and good-enough language processing. In(Vol. 65, pp. 217−247). Academic Press.
Gernsbacher, M. A. (1993). Less skilled readers have less efficient suppression mechanisms.,(5), 294−298.
Hawelka, S., Schuster, S., Gagl, B., & Hutzler, F. (2015). On forward inferences of fast and slow readers: An eye movement study.,, 8432.
Huang, L. J. Q., & Li, X. S. (2020). Early, but not overwhelming: The effect of prior context on segmenting overlapping ambiguous strings when reading Chinese.,(9) 1382−1395.
Johnson, R. L., Oehrlein, E. C., & Roche, W. L. (2018). Predictability and parafoveal preview effects in the developing reader: Evidence from eye movements.,(7), 973−991.
Jordan, T. R., Dixon, J., McGowan, V. A., Kurtev, S., & Paterson, K. B. (2016). Fast and slow readers and the effectiveness of the spatial frequency content of text: Evidence from reading times and eye movements.,(8), 1066−1071.
Li, X. S., & Pollatsek, A. (2020). An integrated model of word processing and eye-movement control during Chinese reading.,(6), 1139−1162.
Liu, N. N., Wang, X., Liu, Z. F., & Yan, G. L. (2020). The effects of the word predictability on eye movements of skilled and less-skilled developing readers in Chinese sentences reading.,(6), 1369−1375.
[刘妮娜, 王霞, 刘志方, 闫国利. (2020). 词汇预测性对中文高, 低阅读技能儿童眼动行为的影响.,(6), 1369−1375.]
Liu, N. N., Wang, X., Liu, Z. F., Wang, Y. S., & Yan, G. L. (2019). The effect of contextual predictability on parafoveal process for highly- and low-skilled developing readers during Chinese reading.,(4), 848−853.
[刘妮娜, 王霞, 刘志方, 王永胜, 闫国利. (2019). 语境预测性对中文高低阅读技能儿童预视加工的影响.,(4), 848−853.]
Morey, R. D., Rouder, J. N., Jamil, T., Urbanek, S., Forner, K., & Ly, A. (2018).. Retrieved from https://CRAN. R-project.org/package = BayesFactor
Perfetti, C. A. (2007). Reading ability: Lexical quality to comprehension.,(4), 357−383.
R Development Core Team. (2021).. Vienna, Austria: R Foundation for Statistical Computing. Retrieved from http://www.Rproject.org/.
Rayner, K. (1975). The perceptual span and peripheral cues in reading.,(1), 65−81.
Rayner, K., Pollatsek, A., Ashby, J., & Clifton, Jr. C. (2012).(2nd ed.) (pp.377−396). Psychology Press.
Rayner, K., Schotter, E. R., Masson, M., Potter, M. C., & Treiman, R. (2016). So much to read, So little time: How do we read, and can speed reading help?,(1), 4−34.
Rayner, K., Slattery, T. J., & Bélanger, N. N. (2010). Eye movements, the perceptual span, and reading speed.(6), 834−839.
Reichle, E. D. (2011). Serial-attention models of reading. In S. P. Liversedge, I. D. Gilchrist, & S. Everling (Eds.),(pp. 767−786). New York, NY, US: Oxford University Press.
Reichle, E.D., Liversedge, S.P., Drieghe, D., Blythe, H.I., Joseph, H., White, S.J., & Rayner, K. (2013). Using E-Z Reader to examine the concurrent development of eye- movement control and reading skill.,(2), 110−149.
Schotter, E. R., Lee, M., Reiderman, M., & Rayner, K. (2015). The effect of contextual constraint on parafoveal processing in reading.,, 118−139.
Slattery, T. J., & Yates, M. (2018). Word skipping: Effects of word length, predictability, spelling and reading skill.,(1), 250−259.
Staub, A. (2015). The effect of lexical predictability on eye movements in reading: Critical review and theoretical interpretation.,(8), 311−327.
Staub, A., & Goddard, K. (2019). The role of preview validity in predictability and frequency effects on eye movements in reading.,(1), 110−127.
Tiffin-Richards, S. P., & Schroeder, S. (2020). Context facilitation in text reading: A study of children’s eye movements.,(9), 1701−1713.
Veldre, A., & Andrews, S. (2015). Parafoveal lexical activation depends on skilled reading proficiency.,(2), 586−595.
Williams, D. (2020). Predictive coding and thought.,(4), 1749−1775.
Yan, G. L., Xiong, J. P., Zang, C. L., Yu, L. L., Cui, L., & Bai, X. J. (2013). Review of eye-movement measures in reading research.,(4), 589− 605.
[闫国利, 熊建萍, 臧传丽, 余莉莉, 崔磊, 白学军. (2013). 阅读研究中的主要眼动指标评述.,(4), 589−605.]
Zhang, M. M., Hu, H. L., Bian, H., Li, F., Zhang, Z. C., & Zang, C. L. (2020). Word frequency effects in fast and slow readers during skilled Chinese reading.,(3), 304−310.
[张慢慢, 胡惠兰, 边菡, 李芳, 张志超, 臧传丽. (2022). 中文阅读中快速读者与慢速读者的词频效应.,(3), 304−310.]
Zhang, M. M., Liversedge, S. P., Bai, X. J., Yan, G. L., & Zang, C. L. (2019). The influence of foveal lexical processing load on parafoveal preview and saccadic targeting during Chinese reading.,(6), 812−825.
Zhang, M. M., Zang, C. L., Xu, Y. F., Bai, X. J., & Yan, G. L. (2020). The influence of foveal processing load on parafoveal preview of fast and slow readers during Chinese reading.,(8), 933−945.
[张慢慢, 臧传丽, 徐宇峰, 白学军, 闫国利. (2020). 快速与慢速读者的中央凹加工对副中央凹预视的影响.,(8), 933−945.]
Zhang, M. M., Zhang, Z. C., & Zang, C. L. (2020). Is skipping based on full or partial processing of the parafoveal word in Chinese reading?,(3), 311−317.
[张慢慢, 张志超, 臧传丽. (2020). 跳读是基于副中央凹词的部分加工还是完全加工?,(3), 311−317.]
Zhao, S. N., Li, L., Chang, M., Wang, J. X., & Paterson, K. B. (2021). A further look at ageing and word predictability effects in Chinese reading: Evidence from one-character words.,(1), 68−76.
Zhao, S. N., Li, L., Chang, M., Xu, Q. Q., Zhang, K., Wang, J. X., & Paterson, K. B. (2019). Older adults make greater use of word predictability in Chinese reading.,(6), 780−790.
The effect of lexical predictability on word processing in fast and slow readers during Chinese reading
ZHANG Manman1,2,3, HU Huilan2, ZHANG Zhichao2, LI Xin2, WANG Qiang1,2,3, BAI Xuejun1,2,3, ZANG Chuanli1,2,3
(1Key Research Base of Humanities and Social Sciences of the Ministry of Education, Academy of Psychology and Behavior, Tianjin Normal University, Tianjin 300387, China) (2Faculty of Psychology, Tianjin Normal University, Tianjin 300387, China) (3Tianjin Social Science Laboratory of Students’ Mental Development and Learning, Tianjin 300387, China)
According to the lexical quality hypothesis, high proficient (fast) readers have well-specified lexical representations which enable automatic word identification and less context decoding, while low proficient (slow) readers rely on context for word identification during reading due to their imprecise lexical quality. In contrast, the predictive coding framework assumes that high proficient readers rely more on their reading experience to predict the upcoming context compared to low proficient readers. However, it is still unclear how skilled readers with different levels of reading proficiency rely on context information (e.g., predictability) for word processing during Chinese reading. In two experiments, the present study aimed to investigate individual differences in the use of predictability for word identification by using the eye-tracking technique.
In Experiment 1, eye movements of fast and slow readers were recorded while they were reading sentences containing predictable or unpredictable target words, with the aim to investigate the differences in predictability effects between the two groups. Sixty pairs of predictable-unpredictable target words were selected, each of which was embedded into the same sentence frame. Fifteen fast and 15 slow readers, selected from a group of 66 participants based on their reading rates, participated in Experiment 1. In Experiment 2, parafoveal previews of the 60 predictable target words (identicalword, visually similar pseudocharacter, unpredictable word or visually dissimilar pseudocharacter) were manipulated by using the boundary paradigm to explore how parafoveal preview influences processing of predictability information in the fast and slow readers. The eye movements of 20 fast and 20 slow readers, selected from a group of 80 participants on the basis of their reading rates, were recorded while they were reading sentences containing predictable target words with different previews in Experiment 2.
The results showed that fast readers fixated shorter and less on the target words and were more likely to skip the target words than slow readers. In Experiment 1, although reliable predictability effects with shorter fixations for predictable than unpredictable words were found, it did not interact with reading groups. However, results in Experiment 2 showed robust parafoveal preview effects on the target word which interacted with reading groups. In particular, the two groups had the same first-pass fixation times (i.e., FFD, SFD, GD) at the target words under the identical previews, while slow readers made longer fixations than fast readers at the targets with unpredictable previews or unrelated previews. In addition, fast readers skipped target words at a similar probability under both the identical preview and unpredictable preview conditions, while slow readers were less likely to skip target words with unpredictable previews than identical previews.
The current findings indicate that fast and slow readers rely on context to a similar degree during their foveal lexical processing whereas the two groups show different utilization of previews of the predictable word during their parafoveal processing. To be specific, compared to fast readers, slow readers are inefficient in activating the predictable word with a visually similar preview; moreover, slow readers are disturbed more by the unpredictable preview or the visually dissimilar preview for their lexical processing, which suggests that slow readers are less effective in suppressing unrelated or inappropriate information during reading. Such findings provide evidence for the lexical quality hypothesis and are in support of the linguistic-proficiency hypothesis related to individual differences in the E-Z reader model.
predictability, foveal processing, parafoveal preview, fast reader, slow reader, Chinese reading
2021-12-29
* 国家自然科学基金项目(31800920; 31571122; 32000786)。
臧传丽, E-mail: zangchuanli@163.com; 白学军, E-mail: bxuejun@126.com
B842
猜你喜欢
艺术生活-福州大学厦门工艺美术学院学报(2022年1期)2022-08-31
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
航空维修与工程(2020年6期)2020-09-21
疯狂英语·爱英语(2020年9期)2020-01-07
中华胰腺病杂志(2019年4期)2019-08-29
时代英语·高二(2015年1期)2015-03-16
新闻前哨(2015年2期)2015-03-11
外语教学理论与实践(2014年2期)2014-06-21
中华胰腺病杂志(2012年3期)2012-11-07
