
基于卷积神经网络的前方车辆检测系统研究
2023-01-03 08:12仇成群李沛润
重庆交通大学学报(自然科学版) 2022年11期
仇成群,李沛润,杨 锋,朱 瑞
(1. 盐城师范学院 江苏省智能光电器件与测控工程研究中心,江苏 盐城 224007; 2. 盐城工学院 机械工程学院,江苏 盐城 224051; 3.东北林业大学 土木工程学院,黑龙江 哈尔滨 150040)
0 引 言
在车辆越来越普及的现代生活中,对交通车辆的监控和跟踪越来越受到城市管理者的重视。交通车辆检测[1]面临的困难包括以下几个方面:
1)复杂交通场景中的车辆检测是一项多目标、多尺度物体检测任务,建立深度模型具有很大挑战。
2)在图像采集过程中,有些车辆总是被路上的其他物体遮挡,如绿化带、路障、电线杆或其他车辆甚至伪装,难以从图像中获得车辆有效信息。
3)在采集车辆图像过程中,对光强度有一定的要求,实际识别中获得的图像往往不符合照明条件。
4)交通场景图像通常捕获移动车辆,因此获得的车辆运动目标可能模糊不清。此外,在雾蒙蒙的天气中,车辆图像也有些模糊,增加了车辆检测的难度。
目前智能汽车研究[2]的主要趋势分为两个,一个是智能辅助驾驶系统,另一个是无人驾驶系统。有关智能辅助驾驶技术与理论已经在一定程度上应用于实际场景中。R-CNN(region-convolutional neural networks)是将深度学习应用到目标检测上的算法,其在对象检测基准测试中显示了良好的性能[3-6]。RPN(region proposal network)以卷积特征映射作为输入,并输出潜在的投资回报率。车辆尺度的大变化导致RPN忽略了小物体。
定向梯度[7](HOG)和Haar[8]样特征的直方状图是最常见的特征。最早的实时探测器之一是一个级联检测器,它达到了具有竞争力的精度。基于部件的可变形模型(DPM)和支持向量机(SVM)是基于零件的模型方法的两种著名模型[9]。
基于单目视觉的前方车辆障碍物检测系统,该系统依靠安装在车辆上的摄像头,在行驶过程中收集前方道路的数据信息,并且在所获取的图像中,进行假设区域生成和检验,以便驾驶员实时获得信息。实现前方车辆检测的另一个关键是实时性,由于道路环境的不断变化,加上车辆与车辆之间的距离关系,会导致在所获取的图像中,车的大小不一致。为了确保检测的实时性,首先假设生成,根据通过车辆的形状、车辆底部阴影等简单的特征,在图像中确定车辆所在位置,避免对整个图像进行检索,保证系统的实时性。然后假设检验,对所选的卷积神经网络进行训练,利用其对假设生成的区域进行检验,提高系统检测的准确性。通过这种方法可以提高系统对检测前方车辆的实时性和准确性。
1 车辆假设区域生成
1.1 车辆辅助驾驶系统
一些先进的车辆辅助驾驶系统(ADAS)正在进行智能车辆的研究,该系统主要是要处理其他车辆的检测和跟踪。目前,商用设备基于距离传感器,如雷达或激光。这种传感器具有直接距离测量,能够恶劣的天气条件下工作。此类传感器只检测前面的车辆,视野范围较窄。如果车辆被超过,系统有一个阶跃输入,响应可能不稳定。虽然视觉很难处理信息,但它能够提供车辆周围环境更丰富的描述。此外,目前许多交通事故都是人为的错误造成的。由于这些原因,基于计算机视觉的ADAS可以在许多方面帮助驾驶员:
1)平台管理。这些车辆在高速公路上以高速和近距离方式行驶有很多限制,比如,不会有突然的操作,道路环境能够被很好的建模,所有的车辆都朝着同一方向行驶。只需要检测到前面的车辆。
2)停车或起步。城市内经常会发生交通堵塞,自动驾驶系统可以帮助驾驶员及时停止或启动车辆。虽然距离传感器是最好的选择,但它们之间会存在一定的干扰导致检测错误。
3)盲点感知能力。该系统能够检测到另一辆车正在超车并及时提示。
4)无人驾驶。该系统必须定位和跟踪其周围的所有车辆。车辆在高速公路和道路的同一个方向行驶。
基于计算机视觉的车辆检测研究分为3类:
1)基于基本特征。定义车辆基本特征:对称性、边缘、阴影等,并在图像中按顺序查找。
2)基于模型的信息。该研究方法比基于基本特征的算法更健壮,但速度较慢。
3)基于深度学习的基础。该研究方法主要是基于神经网络,而利用神经网络需要汇集许多的图像。它们通常被用来确认检测结果。否则,必须扫描整个图像,而且速度非常慢。
1.2 图像的形态学处理
基于全局形状模型[10]的图像分割方案由以下各块组成:
1)初始模型M。
2)可变形的模型M(Z)。该模型是通过前一个模型的变形参数Z得到的。
3)似然概率密度函数P(I|Z),表示在图像I中发生变形集Z的概率。
4)寻找后验概率P(I|Z)的最大值的搜索算法。
似然函数P(I|Z)必须被设计为在变形模型与图像I匹配时达到其最大值。由于阴影、遮挡、天气条件等,该模型(图1)由7个参数定义:位置(x,y)、车辆宽度和高度、挡风玻璃位置、保险杠位置和车顶角度。这些参数具有以下范围:
1)x位置:0~340像素。
2)y位置:0~240像素。
3)宽度:40~100像素。
4)高度:40~100像素。
5)挡风玻璃位置:高度值的20%~30%。
6)保险杠位置:高度值的50%~60%。
7)车顶角度:宽度值的0%~25%。
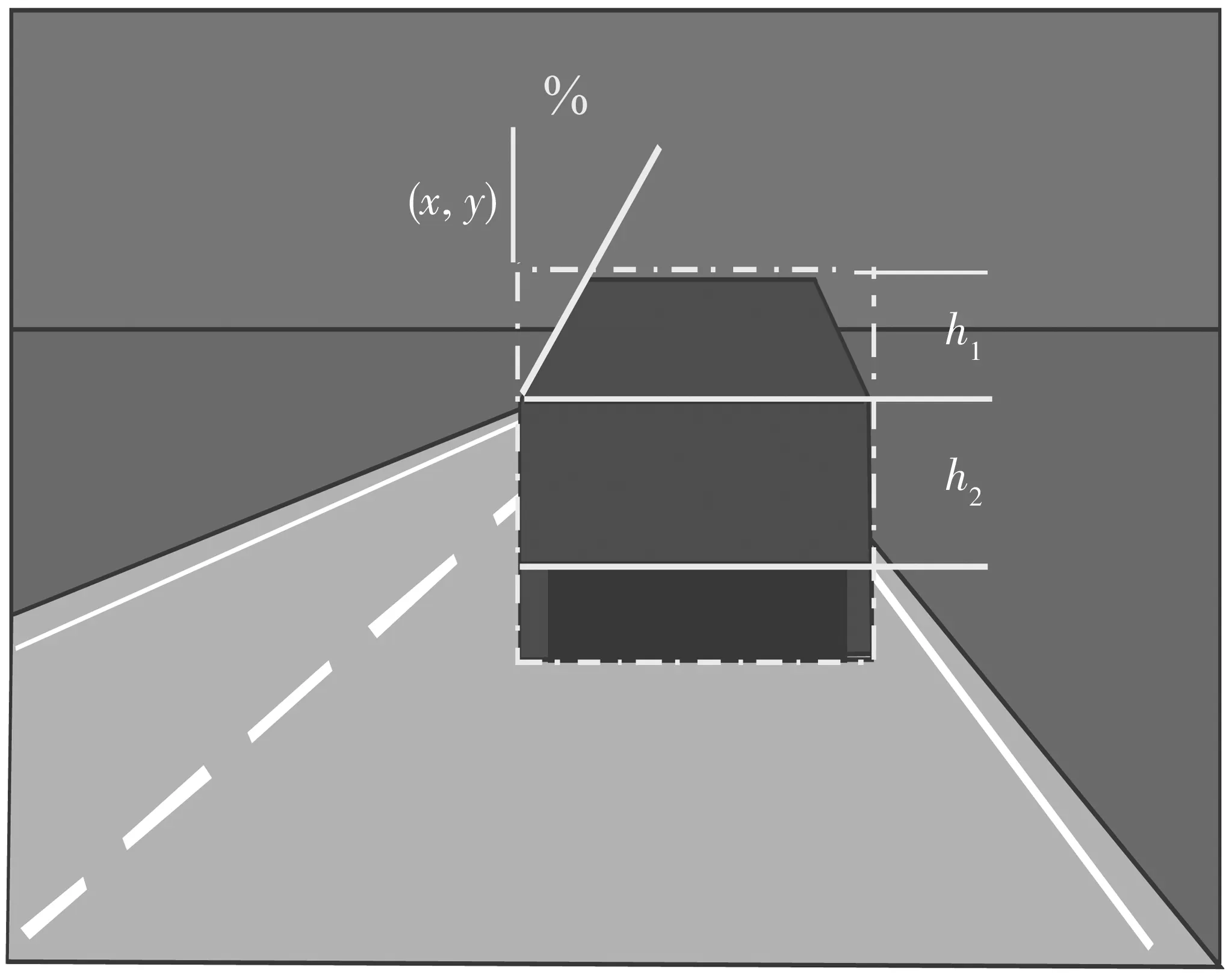
图1 车辆的几何模型Fig. 1 Geometric model of the vehicle
能量函数考虑了以下3个因素:对称性、形状和车辆阴影。
1.2.1 对称性
考虑了垂直边缘和水平边缘的对称性。因此,可以找到图像的垂直和水平梯度分量。只考虑其中一个组件的高响应和另一个组件的低响应的像素。同行的像素对中心像素作为对称轴,公式为:
(1)
(2)
式中:Dmin和Dmax分别为图像中搜索车辆的最小和最大宽度;xi和xj分别为位置x方向的分量;yi和yj分别为y方向的分量;Gh和Gv分别为梯度的垂直分量和水平分量;Th和Tv为阈值。
对于具体模型,对称能量的值为:
(3)
(4)
(5)
式中:h为车辆模型的高度;w为其宽度;Sv为垂直边缘的对称性测度;Sh为水平边缘的对称性测度;Esv为垂直边缘的对称能量;Esh为水平边缘的对称能量;Esim为整体对称能量。
1.2.2 形 状
对于具体的高度h、宽w、位置(x,y)、挡风玻璃位置t和保险杠位置m的特定模型,垂直梯度能量Egv和水平梯度能量Egh为:
(6)
(7)
以及整体梯度能量Eg为:
(8)
获得一个距离图像D,其中每个像素显示到最近边缘的距离。从该图像计算到垂直边缘能量的距离Dgv和水平边缘能量Dgh为:
(9)
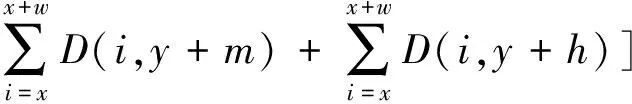
(10)
(11)
式中:Eα是整体距离能量。
1.2.3 阴 影
高度h、宽度w、位置(x、y)、保险杠位置m的车辆阴影能量Esom由模型下部的平均灰色水平定义为:
(12)
如果为绝对黑色,则能量值为1,白色则为0。最终的能量E为:
E=-[kaEsom+kbEg-kcEd+kdEsom]
(13)
式中:ka、kb、kc、kd分别为能量项的加权参数。
对图像I、P(I|Z)的给定变形Z的估计遵循吉布斯分布:
(14)
式中:k为正常化常数。
1.3 搜索算法
搜索算法必须在两个相反的任务之间找到平衡,探索完整的搜索空间和对某些区域的开发。哈希方法是探索的极端情况,其中基于梯度的爬山方法是最有效的方法。
遗传算法在一个优化过程后的几个方向进行平行搜索,模拟自然选择和进化。为了完成这项任务,可能产生解决方案,它们可以根据搜索全局最大值的结果的适合度来交换信息。
对遗传算法中个体数量和迭代次数进行实验以获得最佳数量的个体。对于不到500个个体,没有获得能量函数的最大值。与许多个体一样,达到该值的迭代次数较少,但迭代的减少并不能补偿较高的计算成本(图2)。另一项实验检查两个种群的适应度进化。如图3中可以看出,有1 500个个体的种群在第1次迭代中具有更好的适应度值,但差异很小,即使在一些迭代中,较小的种群也会有更好的结果。在第30次迭代后,这些值被稳定下来。通过两个实验,个体的数量被固定在550。
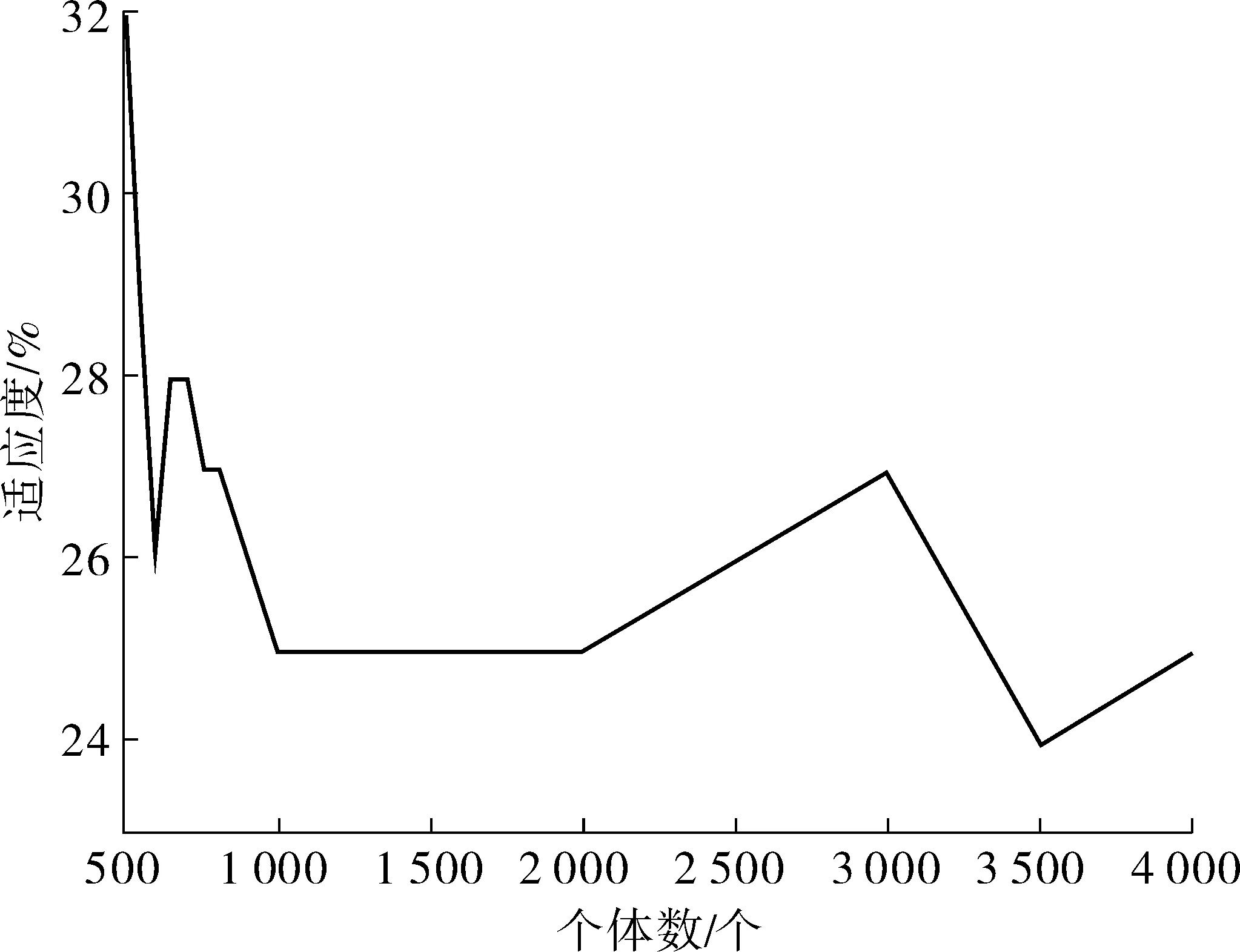
图2 能量函数Fig. 2 Energy function
假设区域的生成是基于一个几何模型,其能量函数包括车辆的形状和对称性及其产生的阴影的信息。并且利用一种遗传算法来寻找最优的参数值。第1步是进行直方图拉伸,这样图像就独立于光照(天气条件);第2步得到梯度的垂直和水平分量,并进行阈值计算,以得到垂直和水平边界。将一些错误的形态变换应用于连接断裂的边缘;然后,释放像素小于特定值或大于其他值的边缘从这些图像可以计算出到边缘的距离和对称性。
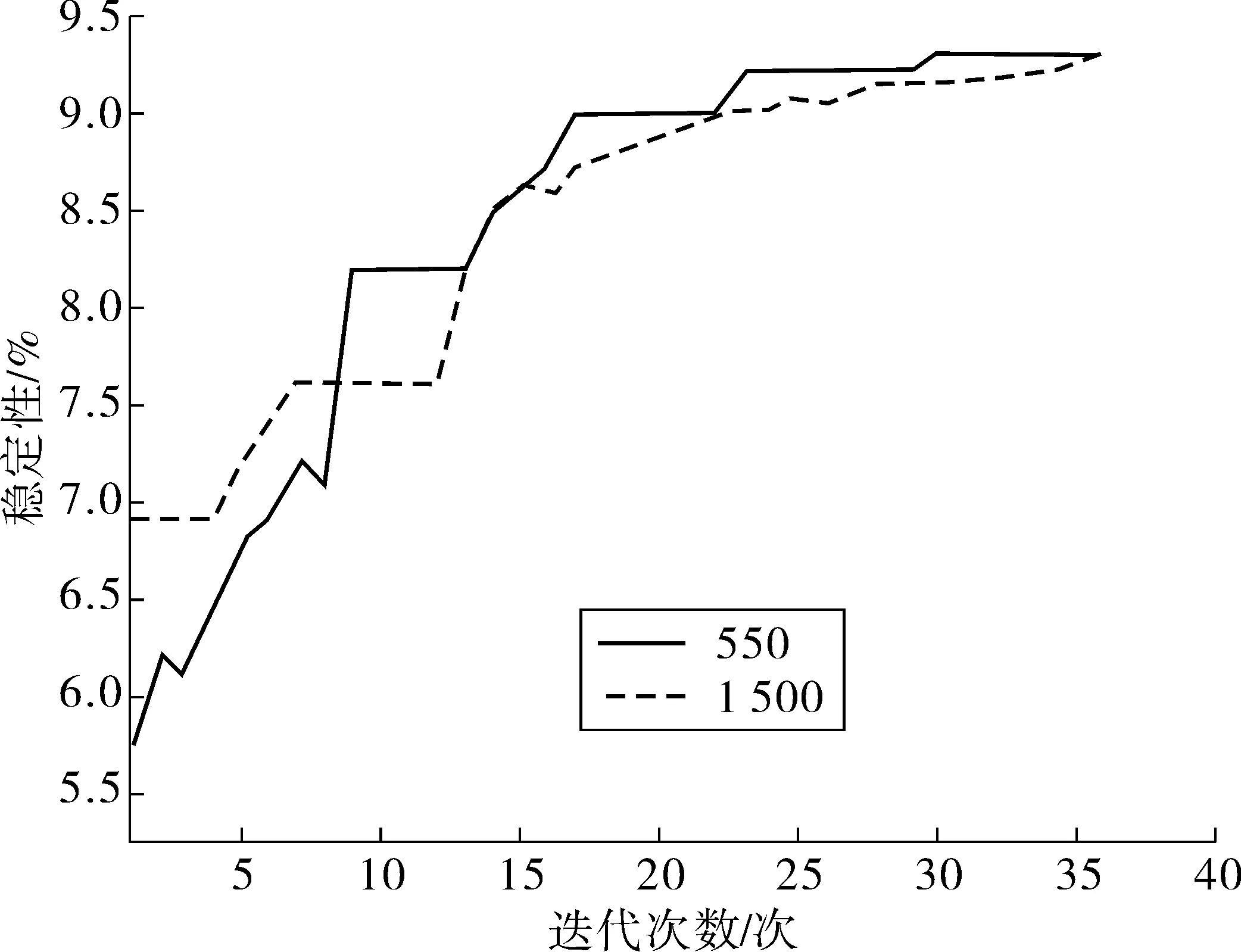
图3 能量函数进化的迭代次数Fig. 3 Number of iterations of energy function evolution
2 数据信息收集
为了训练卷积神经网络,需要从网络或者实际生活中收集样本。所收集的样本需要分为正样本和负样本。因为收集样本的方式很多,因此照片的大小会有所不同,所以将图像尺寸标准化为50×50。正样本包括从各个角度截取的车辆,可以发现车辆后方的照片很多。
负样本是收集于网络或者实际拍摄。它们与正样本相同,都需要将图像尺寸标准化为50×50。为了将卷积神经网络的训练范围扩大,所选取的图像并不是车辆,且选取的种类多种多样。负样本包括人和建筑,船,树木和其他物体。表1是所收集的正样本和负样本的数量。

表1 训练集信息Table 1 Training set information 个
为了将选取的卷积神经网络训练范围扩大,笔者将收集的图像进行镜像处理,如图4。由于收集的图像并非对称,所以采用镜像处理,可以增加训练的次数。

图4 镜像处理Fig. 4 Image processing
3 车辆检测系统的仿真
3.1 算法平台
采用深度学习中的卷积神经网络(CNN)进行性能的实现和优化,并采用Python软件编写程序,用Origin进行模拟仿真。表2为所用电脑的配置。

表2 实验环境Table 2 Experiment environment
3.2 系统仿真
实验对重叠采样与非重叠采样的卷积神经网络进行比较,其中选取CNN-1为非重叠采样,选取的CNN-2为重叠采样。这两个卷积神经网络结构都是由三层卷积层、三层池化层和两层全连接层组合而成。如图5,CNN-1池化采样的区域S2为3×3,即采样区域没有重叠,CNN-2池化采样的区域S2为4×4,即相邻的采样区域是会有重叠。
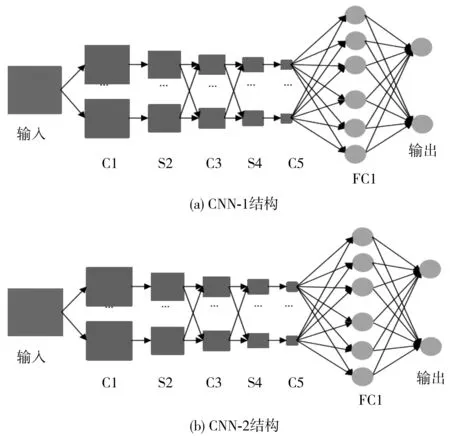
图5 CNN-1和 CNN-2结构对比Fig. 5 Comparison of CNN-1 and CNN-2 structures
由图6和表3看出,CNN-2的准确率更高达到了95.78%,CNN-1的准确率只有94.21%,所以将池化采样区域分为40×40可以提高卷积神经网络的准确率,即采用重叠采样。

表3 结果对比Table 3 Comparison of results
因为池化层的不同也会对卷积神经网络的正确率造成影响,所以选取了不同池化层的卷积神经网络进行比较,得到的结果为:Max+Ave+Ave相较于其他池化层性能最佳,准确率达到了98.19%。而Ave+Ave+Max性能最差为94.21%。如果在S3层采用的池化层为平均值时,会降低检测的准确性,相反,如果在S1层采用最大池化值的话,性能则会有显著的提高,且对S2、S3、S4层的池化层采用平均值。这样所得出的卷积神经网络准确率最高。

图6 CNN-1和 CNN-2迭代次数变化曲线对比Fig. 6 Comparison of iteration times curves of CNN-1 and CNN-2
3.3 检测结果和评估
图7展示了车辆检测前方障碍物的结果,其中,图7(a)和图7 (b)两幅图为所生成的假设区域,图7(c)和图7(d)两幅图为系统经过假设验证后的结果。
在简单场景下进行车辆检测,检测较为容易,所需要的时间也少,可以保证一定的鲁棒性和准确性,能够精确的定位出前方的车辆。在复杂场景下进行车辆检测,由于该场景中包括了较多的树木,且由于高架的原因造成阴影较多,导致了生成的假设区域较多,检测速率也会由此下降。虽然速率下降,但是通过假设检验过程后,对于前方车辆的检测还是较为准确的。
根据多次统计计算,生成假设区域这一阶段所需要的时间为145 ms,但是由于道路场景,特殊情况等问题,会造成生成假设区域所需要的时间不同,也因此造成了假设检验阶段消耗的时间较多。

图7 不同场景车辆检测前方障碍物对比Fig. 7 Comparison of obstacles in front of vehicles detected in different scenes
4 结 语
在人工神经网络中,选取了由深度学习发展而来的卷积神经网络。卷积神经网络具有训练集相对较少,结构层次较多优点,利用卷积神经网络对捕捉的假设区域进行检验,最后反馈给驾驶员。
为提高在行驶过程中车辆检测的准确性和鲁棒性,试验中利用遗传算法对车辆形状、阴影选取最优值,其中包括了对图像进行灰度化处理,滤波去噪的过程。最后,从获取的图像中选择出感兴趣区域,减少检测需要的时间。试验结果表明:采用重叠采样的卷积神经网络准确率较高,并且系统稳定性也较强。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
现代电力(2022年2期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
CHIP新电脑(2016年3期)2016-03-10
