基于残差的门控循环单元
2022-12-31 02:56张忠豪董方敏胡枫吴义熔孙水发
自动化学报 2022年12期
张忠豪 董方敏 胡枫 吴义熔, 孙水发,
在过去的十几年里,深度学习的提出对全球各个领域带来了巨大的影响.深层神经网络、卷积神经网络和循环神经网络(Recurrent neural network,RNN)等神经网络模型被广泛应用于各个领域.其中,循环神经网络具有捕获长序依赖的能力,因此被广泛应用于语音识别[1]、语言建模[2]、机器翻译[3]等自然语言处理[1−4]领域.然而,普通循环神经网络会因为梯度消失[5]和梯度爆炸问题而变得不稳定,于是学者们提出基于长短期记忆单元(Long short-term memory,LSTM)的时间递归神经网络[1,6]来缓解梯度消失和梯度爆炸问题.虽然LSTM 确实有效,但其门限繁杂,于是近些年有许多针对LSTM的改良方案被提出,其中门控循环单元(Gated recurrent unit,GRU)[7]是LSTM 最具代表性的一种改进方案.
深度学习的成功主要归因于它的深层结构[8−9],然而训练一个深层网络是较为困难的事.随着网络层数的增加,梯度消失、梯度爆炸、网络退化[10]等问题会导致模型被损坏.为了能够进行更深的网络训练,目前已有多种深层前馈神经网络的结构被提出,最具代表性的有高速公路网络[9],用于卷积神经网络的残差网络[11],以及最近被提出的能够进行更深网络训练的简单循环单元(Simple recurrent units,SRU)[12−13].
在循环神经网络体系中,因为通常使用了饱和激活函数,所以很少会发生梯度爆炸问题,但是由饱和激活函数而带来的梯度消失问题却很常见.虽然LSTM 和GRU 相比传统的RNN 是具备缓解梯度消失问题的能力,但实际上这种缓解是有限的,这个问题将在后文通过实验来具体展现.在循环神经网络中也存在着网络退化问题,导致循环神经网络的性能随着网络层数的增加而越来越糟糕.采用高速公路网络的方法能够缓解网络的退化问题,但是这种方法会增加网络参数量和训练耗时[11].近两年备受关注的SRU 网络也包含了类似高速公路网络的结构[13],同时SRU 舍去了循环单元中的时间参数,所以在运行快速的同时在一些任务中也能够进行更深的网络训练.
本文通过对GRU 结构的深入研究,发现通过修改其候选隐状态的激活函数并添加残差连接,可以有效地解决原始GRU 的梯度消失和网络退化问题.而对于使用了非饱和激活函数而可能导致的梯度爆炸隐患,本文则是采用了批标准化(Batch normalization,BN)[14]的方法来解决.在本文的3 类不同对比实验中,本文设计的(Residual-GRU,Re-GRU)在3 类实验中均取得了比GRU、LSTM、Highway-GRU、SRU 等网络更好的效果,并且在同样的配置下,本文设计的Re-GRU 比LSTM 和Highway-GRU 耗时更短.
1 现有技术
1.1 门控循环单元
门控循环单元(GRU)是LSTM 的简化改进,GRU和LSTM 的共同点是每个神经元都是一个处理单元,每个处理单元都包含了若干个门限,门限可以判断输入的信息是否有用.与LSTM 不同的是,每个GRU 处理单元仅有两个门限,并且GRU 的单元只有一个时序输出,所以GRU在保证能有效传递时序相关信息的条件下,拥有更少的参数量.GRU 单元结构如图1 所示,公式定义如下:
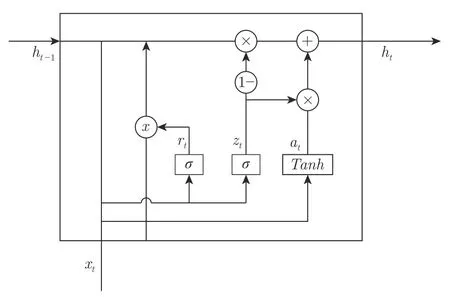
图1 GRU 单元结构Fig.1 GRU structure
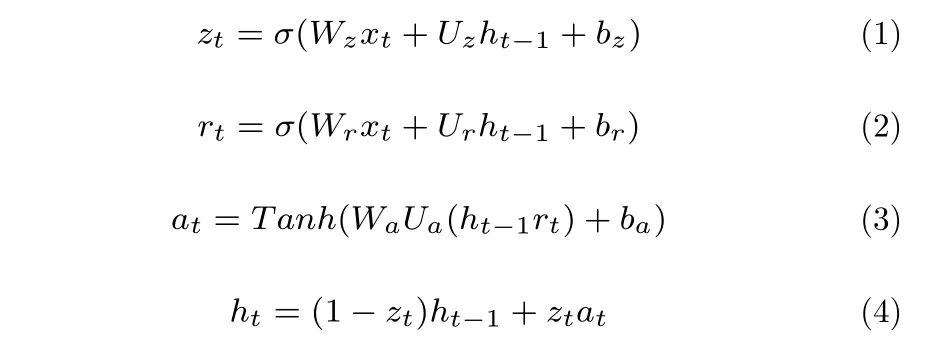
式中,xt表示当前层的t时刻输入值,ht−1是t−1 时刻的状态输出值,zt和rt分别为t时刻的更新门和重置门,更新门和重置门的激活函数σ是Sigmoid 函数,at为t时刻的候选隐状态,ht表示当前时间t的状态向量,Tanh是候选隐状态的双曲正切激活函数,模型权重参数是Wz、Wr、Wa、Uz、Ur和Ua,偏置向量为bz、br和ba.
1.2 高速公路网络
在普通神经网络中,若网络层数过高且没有特殊限制,往往会产生冗余的网络层,冗余网络层存在不必要的计算,这通常会导致网络性能变差.要想让网络不产生冗余,就需要对网络结构进行特殊的设计.假设x是网络某层的输入,F(x) 表示x经过了某种运算,H(x) 是此层的输出,则普通网络的输出为H(x)=F(x).如果能在经过冗余的网络层时让输出H(x) 直接等同于输入x,也就是构成一个恒等映射H(x)=x,这样就能避免了信息通过不必要的计算,从而保证了信息的有效传递,实现消除网络退化的目的.
高速公路网络[9]是一种能实现深度神经网络的结构,高速公路网络通过一个辅助门控T来控制输出的信息.假设某层的输入为x,原始的输出为F(x). 则当T=1 时则新的输出H(x) 完全由F(x) 构成,当T=0 时则新输出H(x)完全由上一层的信息x构成.通过门控T即可让有效信息有效传递,从而使网络层不冗余.常用的高速公路网络结构见图2,公式定义如下:
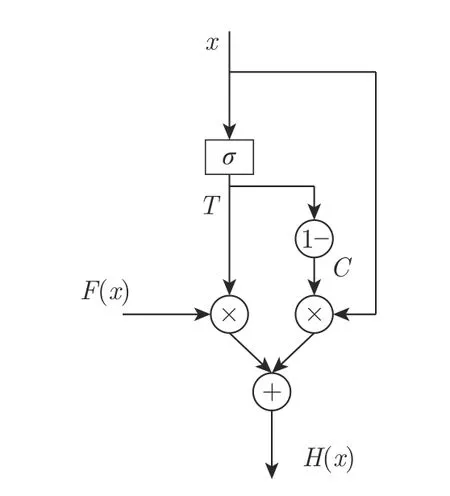
图2 高速公路网络结构Fig.2 Highway-network structure
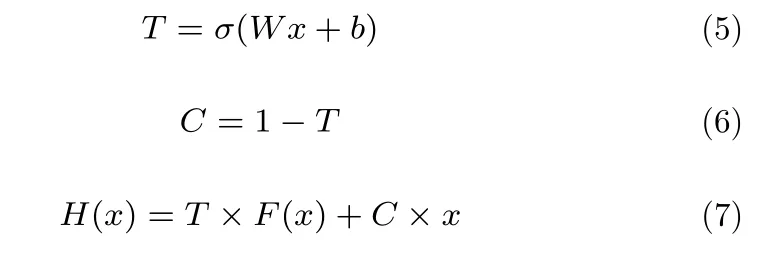
式中,x是输入,w是权重,b是偏置向量,F(x) 是未经过高速公路网络之前的输出,C与T是高速公路网络的门控,σ是门控T的激活函数,H(x) 是高速公路网络输出.
高速公路网络通过门控的控制,可以确保相有效信息能够畅通流动.SRU 网络也是运用了这种类似的结构[13],使其网络能够更好地保证信息传输.
1.3 残差网络
残差网络[11]的主要贡献是更好地解决了学习恒等映射函数问题,并且没有增加网络参数数量.残差网络将拟合恒等映射函数H(x)=x转化为优化残差函数F(x)=H(x)−x.当残差函数中F(x)=0 时就构成了H(x)=x的恒等映射,这样就避免了多余网络层产生的冗余,使得网络在梯度下降的时候能够有效地应对网络退化问题[11].有研究表明,网络退化的原因是权重矩阵的退化[10],而残差连接的不对称性能够很好地应对权重矩阵退化问题.
残差网络与高速公路网络不同在于: 高速公路网络认为需要通过门限来控制残差的量,而残差网络认为残差是随时存在的,所以在计算的时候不需要门限的限制.通过建立与之前层的信息通道,使得网络可以堆积残差,从而网络可以进行更深层的训练.所以残差网络能更有效地学习残差映射且不会有更高的复杂度.残差网络公式见式(8),原始残差网络如图3 所示[11].而在没有残差计算的时候,输出y则完全由σ(Wxl+bl) 提供.
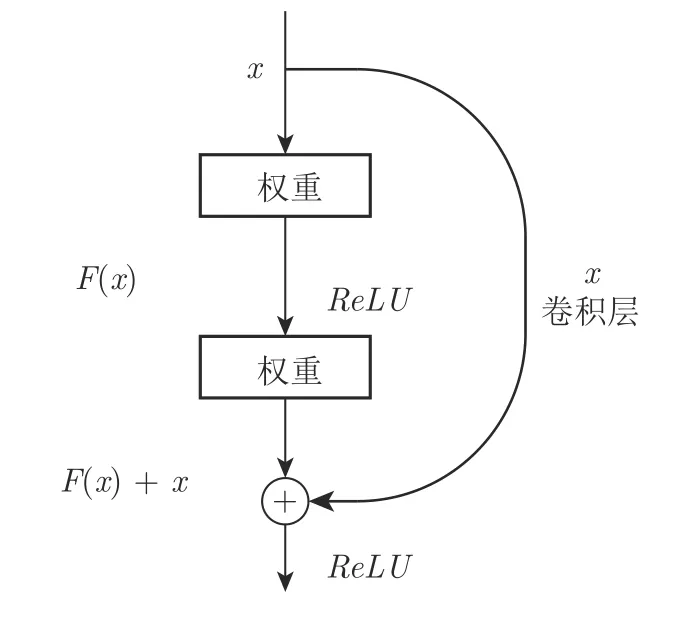
图3 残差网络结构[11]Fig.3 Residual-Networks structure[11]
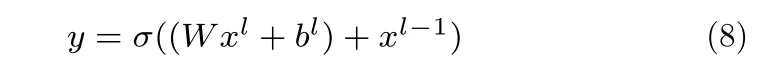
式中,xl表示l层的输入,xl−1表示l−1 层的输入,y表示l层的输出,bl为l层的偏置项,σ为激活函数.
2 残差门控循环单元
2.1 残差门控循环单元结构
在循环神经网络中,梯度消失和网络退化尤为严重.针对这两个问题,本文通过对GRU 改进来解决.在GRU的算法公式中最核心的公式为候选隐状态式(3).式(3)的输出值和前一时刻隐状态的输出值共同决定了GRU 隐状态的最终输出.所以本文的改进主要针对GRU 的候选隐状态公式,主要分为以下3 点:
1)非饱和激活函数
将GRU 的候选隐状态的激活函数改为线性整流函数(Rectified linear unit,ReLU),这样能够让本文的改进网络能够很好地避免由饱和函数引起的梯度消失,进而能够应对更深度的网络训练[15].常见的ReLU 函数为:
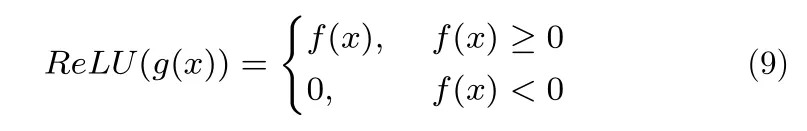
式中,ReLU函数的输入是f(x),f(x) 表示x经过某种运算.
由于ReLU在负半区的导数为0,所以一旦神经元激活后的值为负,则梯度为 0. 当f(x) 大于 0 时,有:
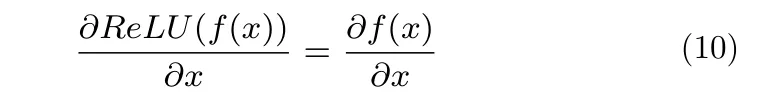
ReLU激活函数可以保证信息传输更加直接,相比饱和的激活函数,ReLU不存在饱和激活函数带来的梯度消失问题,且能更好地配合残差信息的传递.将式(3)改为:
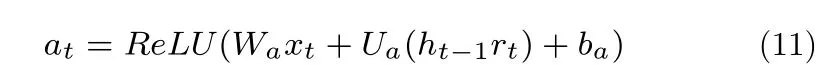
在过去的循环神经网络中,使用无边界的非饱和激活函数通常会产生梯度爆炸问题.ReLU是非饱和激活函数的代表,也存在梯度爆炸问题.而将非饱和激活函数与批标准化技术相结合,可以有效地使梯度爆炸问题得到有效的缓解[11, 16].其中文献[16]在GRU 上进行了类似的改进,也表明了在GRU 网络上使用非饱和激活函数的有效性.本文选择ReLU 是由于其具有代表性,使用其他类似的非饱和激活函数亦是可行的[17].
2)添加残差连接
本文参考卷积神经网络中残差网络的方式来对GRU进行改进,从而解决GRU 中的梯度消失和网络退化问题.具体地,本文是将残差连接放在式(11)中.对于引入的残差信息,本文使用的是前一层的还未激活的候选隐状态值,而不是前一层的隐状态输出值原因是未激活的值相比激活后的值具有更多的原始信息.本文所设计的改进方案与卷积神经网络中的残差网络不同,Re-GRU 的每一层都有残差连接.改进后的隐状态公式为:

此外,也有研究者尝试过在循环神经网络上建立残差连接[13],也设计过在GRU 公式的其他公式中添加残差,例如直接在式(4)中添加残差连接,或在式(3)的激活函数之外添加残差连接,而通过大量实验和算法推导发现本文所提方案是实验中性能最佳的改进方案.
3)批标准化
批标准化[14]通过对每个训练小批量的每个层的预激活的均值和方差进行规范化来解决数据内部协变量偏移,同时也能够加速训练工程和提高系统性能.同时也能够加速训练工程和提高系统性能.使用批标准化可以缓解非饱和激活函数造成的梯度爆炸问题[16].本文通过改变GRU 的激活函数同时添加残差连接,再运用批标准化的优秀性质,可以达到消除传统GRU 中的梯度消失和网络退化的目的.结合批标准化之后本文的Re-GRU 第l 层的单元结构见图3,结构单元公式如下:
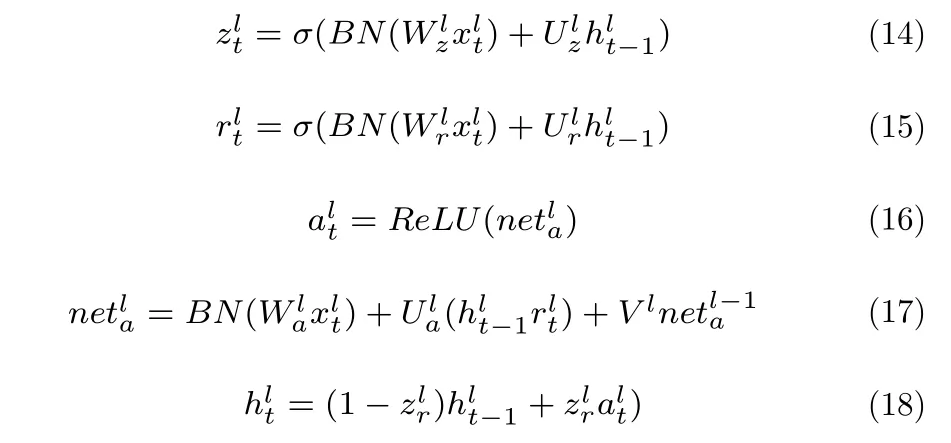
式中,BN表示采用的批标准化.由于批标准化的性质就是消除偏差,所以式(14)、式(15)和式(17)中的偏置向量b被忽略.
2.2 残差门控循环单元的反向传播
由于循环神经网络具备层数空间,同时也具备时序性,所以在循环神经网络中存在反向传播和沿时间的反向传播.本文设计的Re-GRU 是基于神经网络上下层而建立的残差网络,所以本文仅对Re-GRU 的候选隐状态的反向传播展开讨论.
使用F(m) 对式(17)中的部分函数进行等效替换,替换后的结构如图4 所示.
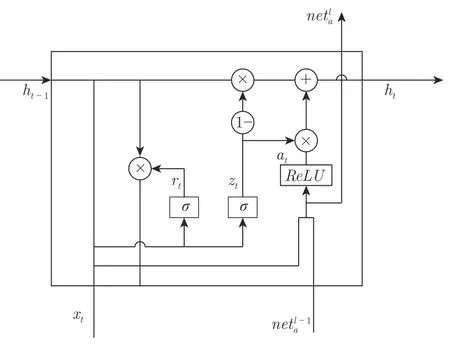
图4 Re-GRU 结构Fig.4 Re-GRU structure
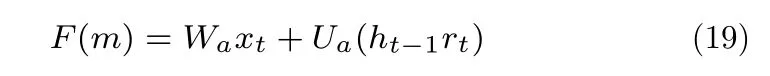
假设此时时刻为t,设L为网络当前层数,设l为要计算的误差项所在层数,L层到l层之间有若干个网络层.设网络每层的神经元个数相同,此时式(17)的维度匹配矩阵V可以被忽略,则式(17)可以简化为:

由于ReLU 在负半区的导数为0,一旦神经元激活后的值为负,则梯度为0,也就相当于不进行训练.所以当大于0 时,有:
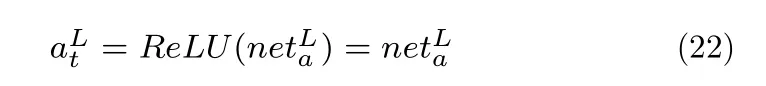
结合ReLU 的性质,在梯度大于0 时有:
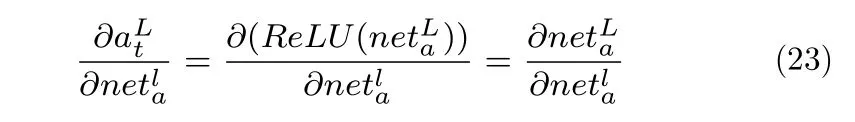
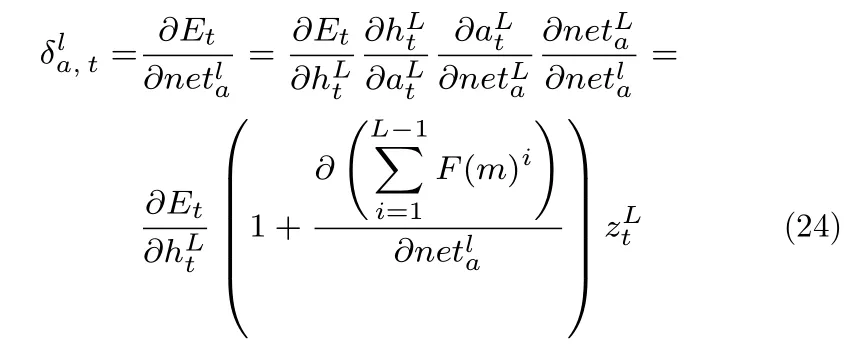
式中,E为误差,表示L层t时刻的状态向量,为L层更新门门限.
Re-GRU 的权重以及权重都使用来计算更新.由式(24)可知,在改变激活函数并添加残差连接后,Re-GRU第l层候选隐状态误差项就能避免因L层到l层之间的多层连续相乘而导致的梯度消失.通过Re-GRU 的反向传播,可以表明本文的Re-GRU 相比传统的循环神经网络更有利于有效信息在层之间进行传递,也表明了Re-GRU对梯度变化的敏感性,达到了解决网络退化的目的.
3 实验和结果分析
3.1 数据集和任务
本文实验中的神经网络都是在Linux 系统上利用Pytorch 平台搭建神经网络完成模型训练,都使用NVIDIA Ge-Force GTX 1060 显卡进行加速训练.本文分别对图像识别、语言模型预测和语音识别三类情况各进行了实验.图像识别使用MNIST数据集[18],语言模型预测使用PTB 数据集[2−3,19]和WikiText-2 数据集[20],语音识别使用TIMIT数据集[1, 21].为了方便本文更快完成地实验,并且为了公平性,本文实验中的每种循环神经网络都只使用单向的循环网络结构.
3.2 MNIST 数据集手写字识别任务
本文的第1 个实验任务是图像识别,采用了MNIST手写字数据集.该数据集包含了60000 张28 × 28 像素图片的训练集和10000 张28 × 28 像素图片的测试集,选择这个数据集主要是它能很好地展现梯度消失现象,并且小数据集很方便进行模型试验.在此数据集上,本文使用了RNN、GRU、LSTM、RNN-relu、GRU-relu、Highway-GRU、Re-GRU、SRU 来进行对比实验.其中的RNN-relu是将激活函数替换成ReLU 的RNN,GRU-relu 是将候选隐状态激活函数换成ReLU 的GRU,Highway-GRU 是使用了高速公路网络结构的GRU.本文对每个神经网络都使用相同的配置: 均使用交叉熵损失函数作为损失函数;梯度下降优化器均使用均方根传递(Root mean square propagation,RMSProp);均使用一层全连接层来匹配输出维度和目标维度;隐藏层的神经元均为64 个,初始学习率均为0.01.所有网络分别进行1、2、7、10、14 层的网络训练.
实验的评估标准为识别测试集的准确率.具体实验结果见表1.由表1 可以看出,RNN、GRU、LSTM 在网络层数增加时,其模型的准确率则逐渐降低.在7 层之后RNN、GRU、LSTM 模型的识别精度降低到约10%.由于这个任务要做的是识别一个手写字图到底是0~ 9 中的哪一个数字,而随机给出一个数字命中正确的概率就为10%,所以10%的准确率相当于随机的预测,此时的模型已是无效模型.
本文对RNN 和GRU 的激活函数进行修改,将饱和的激活函数(RNN-relu)改为非饱和激活函数(GRU-relu).由表1可以看出,RNN-relu 和GRU-relu 相比,RNN 和GRU 具有更好的表现.这种效果的提升主要是使用了非饱和激活函数,从而避免了饱和激活函数带来的梯度消失问题.图5 展示了同为7 层的GRU、GRU-relu、Re-GRU 的训练过程中的损失值变化曲线.通过对比图5 中的GRU 和GRUrelu 的损失值变化,可以很直观地看出,在使用饱和激活函数时,GRU 深层网络的梯度无法得到有效更新,使得损失函数不能有效的降低,而使用了非饱和激活函数,则能避免这种因使用了饱和激活函数而导致的梯度消失问题.
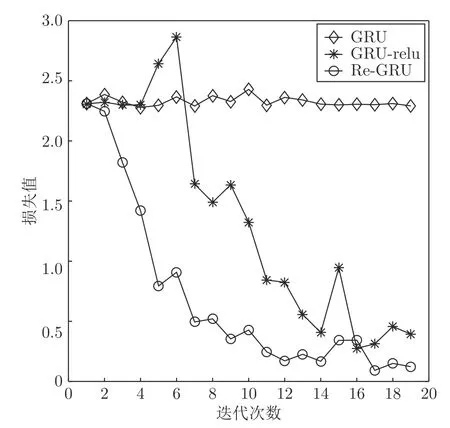
图5 7 层网络的GRU、GRU-relu、Re-GRU 在MNIST 数据集上的损失变化曲线Fig.5 Loss curve of GRU,GRU-relu and Re-GRU on the MNIST data set of a seven-layer network
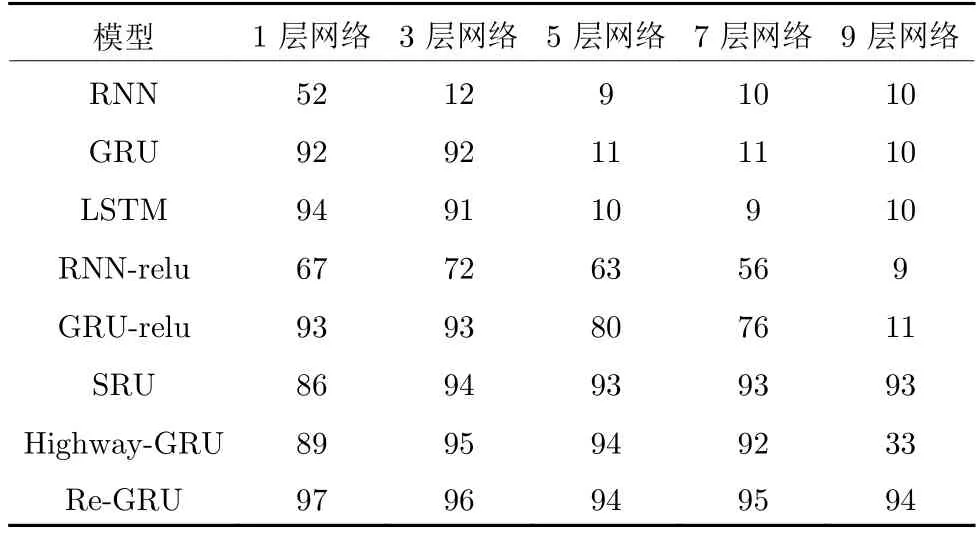
表1 MNIST 数据集测试结果 (%)Table 1 MNIST dataset test results (%)
但是,简单地修改激活函数只能解决梯度消失问题,却并不能应对网络退化问题.从2~ 14 层准确率变化情况可以看出,GRU-relu 和RNN-relu 的准确率随着层数递增而不断下降,到第14 层时两者的模型都发生损坏,这种情况主要是由于网络退化而导致的.Highway-GRU 的结果可以表明利用不对称算法的方式是可以缓解网络退化的问题.对于Highway-GRU,在2~ 10 层时,模型都表现较好,但到了第14 层时,模型也发生了问题,使得准确率大幅度下跌,这种情况是Highway-GRU 模型在网络层数较深时产生了梯度问题.对于SRU,能维持较好模型效果的主要原因是其结构单元舍弃了时间信息参数,所以在不需要时序信息的图像任务中有较好的表现.
通过对比表1 可以看出,本文设计的Re-GRU相比其他模型不仅具备更好的识别效果,同时在网络层数很深时依然是一个有效且良好的模型.而在图5 中,对比3 种模型的损失值变化曲线,能够很清晰地反映出本文设计的Re-GRU 损失值下降更加平滑且有效.在更加深层的训练中,本文设计的Re-GRU 能够避免梯度问题,依然能保持良好的准确率.值得注意的是,本文设计的Re-GRU 在层数增加时,准确率会小幅度降低.这种情况主要是因为MNIST数据集较小,很容易产生过拟合现象,而Re-GRU 并不能避免过拟合的发生.
3.3 PTB 和WikiText-2 语言模型预测
本文第2 个实验是语言模型预测,使用的数据集是在语言模型预测中常用的数据集Penn Treebank (PTB)[19].该数据集包含了10000 个不同的词语和语句结束标记符,以及标记稀有词语的特殊符号.与图像任务不同,语言模型任务是时序性的,能更好地对比不同循环神经网络的性能.本文使用了Pytorch 官方的语言模型示例源码来完成PTB 数据集的训练和测试,其中的网络结构部分源码是本文重新构建的.在此数据集上,本文同样使用了RNN、GRU、
LSTM、RNN-relu、GRU-relu、SRU、Highway-GRU、Re-GRU 进行对比实验.实验采用困惑度(Perplexity,PPL)评估标准,一般来说PPL 值越小则表明模型效果越好[2].实验中的每个循环神经网络配置都是完全相同的: 均设置了650 个神经元;嵌入层的大小均为650,均使用了批标准化,丢弃率均为50%.每种网络分别进行3、5、7 层的网络训练,具体结果如表2 所示,其中逗号左为PPL 值,逗号右为迭代一次的运行时间.
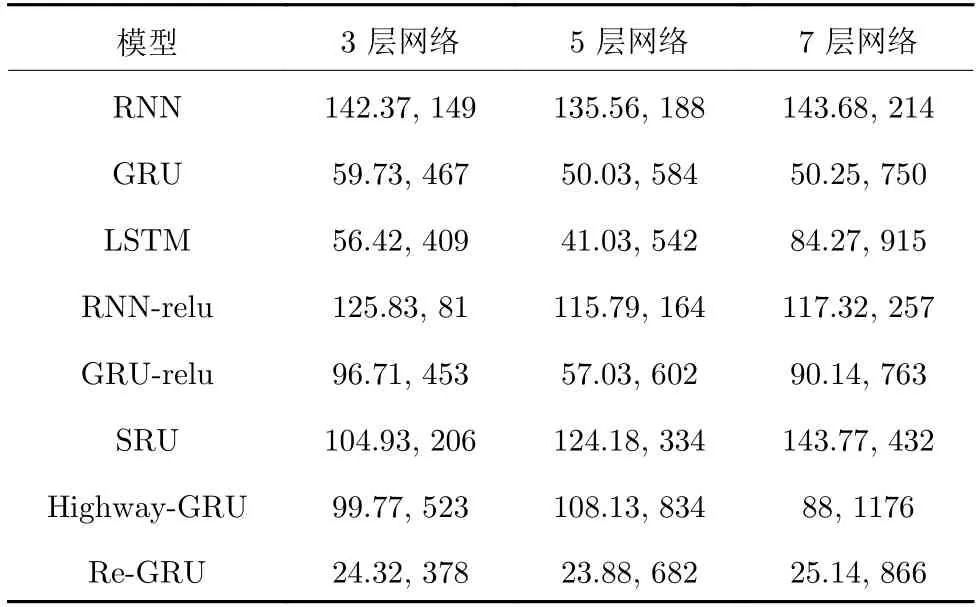
表2 PTB 的测试结果 (PPL,s)Table 2 PTB dataset test results (PPL,s)
表2 中,除了本文的Re-GRU 之外,表现最好的是LSTM,在第5 层的时PPL 达到了41.03.但是当网络层数升高到7 层时,LSTM 的PPL 值升高了一倍.
由表2 可知,Highway-GRU 在实验2 中表现不理想.与GRU 和LSTM 的测试结果相对比,Highway-GRU 的表现要差很多.虽然Highway-GRU 能够在网络层数增加时有效降低PPL 值,但是其时间消耗是相对最多的.本文同时对Highway-GRU 进行了更深的网络训练,在9 层网络时,Highway-GRU 的PPL 值为90.86,11 层时为90.64,这样的结果相比其他的模型效果是较差的,因为Highway-GRU 的复杂结构并不适用于这个任务.SRU与高速公路网络具有类似的结构,而SRU 舍弃了时序参数.所以SRU虽然运行速度很快,但是效果却并不理想.
由表2 可以看出,本文设计的Re-GRU 不仅有着最优的PPL 值,而且在网络层数升高的同时依然保持良好的效果.将GRU 和和Re-GRU在训练过程中每次迭代得到的损失值进行统计,并绘制了损失值变化曲线(见图6).其中图6(a)为完整变化曲线,图6(b)为局部放大图.通过对比图6 的损失变化曲线可以明显地看出,本文设计的Re-GRU 在迭代时损失下降更加平滑且更快.这正是由于本文设计的Re-GRU 网络对梯度变化敏感,使得Re-GRU 在网络的空间上的反向传播能够更有效的传递信息,从而使模型能更有效的完成学习任务.表2 直观地表明,本文设计的Re-GRU 相比GRU 和LSTM 的PPL 值降低了超过50%,并且本文设计的Re-GRU 在网络较深时依然能够拥有较好的模型效果.在时间消耗的对比上,本文设计的Re-GRU 低于LSTM和Highway-GRU.值得一提的是,在PTB 数据集上,本文设计的Re-GRU 所得到的困惑度达到23.88,这个测试结果比此前最佳记录的效果提升超过了一倍[2, 22].
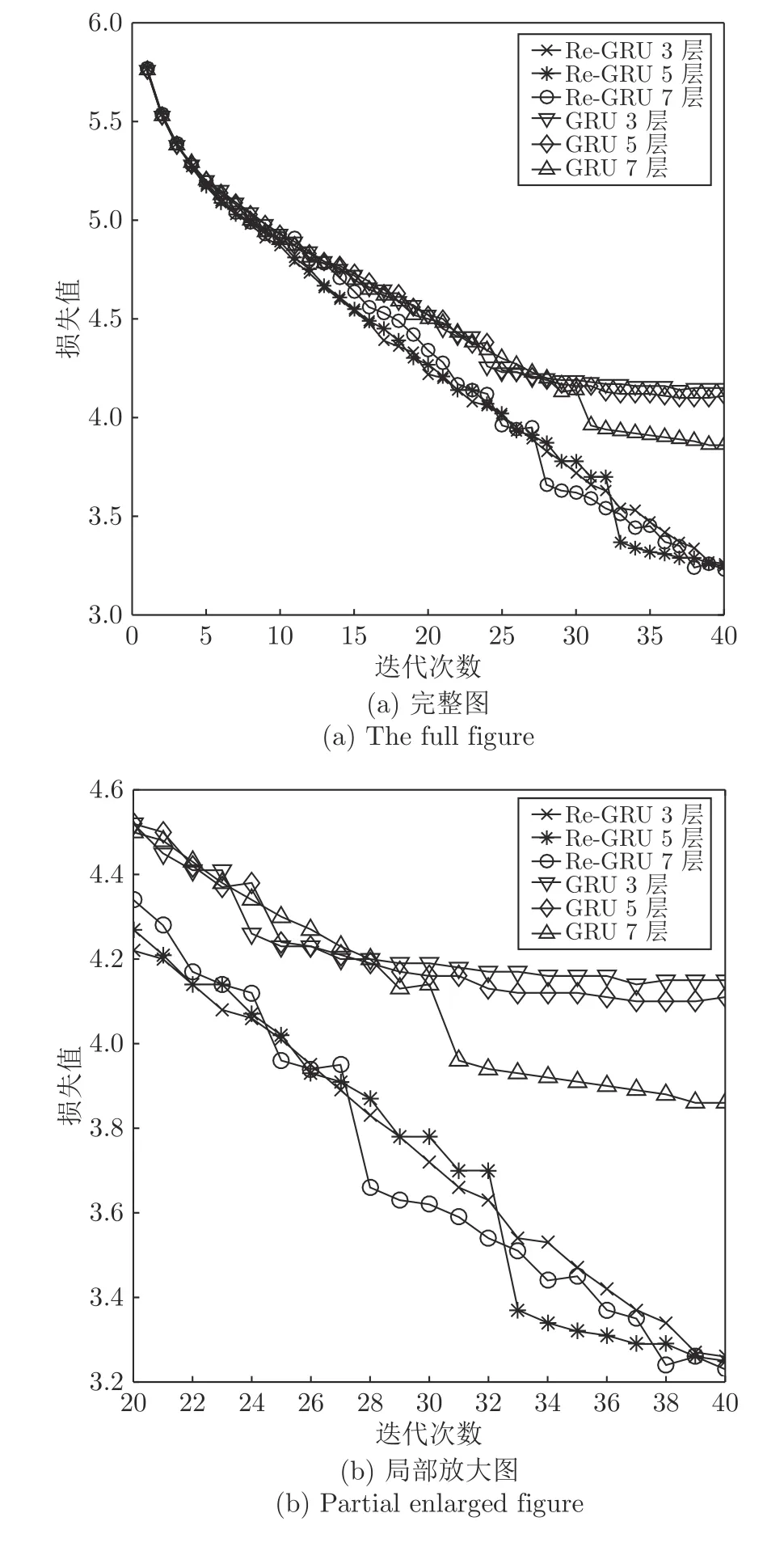
图6 GRU与Re-GRU 在PTB 数据集上的损失值变化曲线Fig.6 Loss curve of GRU and Re-GRU on PTB dataset
为了进一步探索网络模型在语言模型任务上的有效性,本文采用了一个与PTB 数据集相类似的WikiText-2数据集[20]作为本文的第3 个实验.WikiText-2 相比PTB数据集规模更大一倍.本文挑选了RNN、GRU、LSTM、SRU、Re-GRU 网络来完成实验,均使用7 层的网络结构,其他参数设定与本文实验2 的参数设置相同.实验结果见表3,其中逗号左为PPL 值,逗号右边为一次迭代的时间消耗.

表3 WikiText-2 的测试结果(PPL,s)Table 3 WikiText-2 dataset test results (PPL,s)
表3 中,本文设计的Re-GRU 依然拥有最低的PPL,并且运行时间低于LSTM.通过表3与表2的数据对比 可以发现,各个网络的在PTB 数据集和WikiText-2 数据集上的实验效果基本类似,表明了本文改进方法的有效性.
另外,经过多次实验和分析,实验所用各个网络模型效果较好的主要原因是使用了批标准化算法.当不使用标准化时,以上网络结构实际性能普遍都达不到表2 和表3的结果.当使用了批标准化技术后,各网络结构的性能皆有较大提升,而各个模型的性能差异主要是网络结构的不同,其中本文设计的Re-GRU 结构在表2 和表3 中均有最佳困惑度的表现.
3.4 TIMIT 数据集语音识别任务
本文第4 个实验是语音识别,主要是语音识别声学模型训练,采用经典的TIMIT 语音识别数据集[23].该数据集一共包含6300 个句子,由来自美国8 个主要方言地区的630 个人每人说出给定的10 个句子,所有的句子都在音素级别上进行了手动分割好和标记[21].语音识别也是一个时序的任务,通过这个任务,进一步证明了本文设计的Re-GRU的可靠性和适用性.该数据集的训练集和测试集分别占90%和10%.数据的特征是,首先采用Kaldi 工具箱[24]提取的39 维梅尔频率倒谱系数;接着,使用Kaldi 工具箱来完成语音识别基线任务,标签是通过对原始训练数据集执行强制对齐过程而得到的.有关的更多细节参见Kaldi的标准s5配置;然后,在Pytorch平台上利用Pytorch-Kaldi[21]构建神经网络完成声学模型训练;最后,本文使用Kaldi 的解码器完成语音识别效果评估任务,评估标准采用标准的音素识别错误率(Phone error rate,PER).
在语音识别实验中,本文同样进行了RNN、GRU、LSTM、RNN-relu、GRU-relu、SRU、Highway-GRU、Re-GRU 的循环神经网络模型训练,并且补充了一个使用了非饱和激活函数的GRU 改进网络Light-GRU (Li-GRU)[21].所有神经网络模型分别进行了3、5、7 层网络的实验,最后使用Softmax 分类器进行分类.本文为每个循环神经网络都设置了每层450 个神经元;均设置了20%的遗忘率;初始化方式均为正交初始化[25];批处理大小设置为每次8个句子;损失函数均使用交叉熵损失函数;优化器均使用RMSProp 算法;均使用了批标准化技术;初始学习率均设置为0.0008;所有的模型进行25 次迭代训练,均设置了相同的学习率衰减.具体实验结果见表4,其中逗号左为PER 值,逗号右为一次迭代的时间消耗.
由表4 可以看出,RNN、GRU、SRU、Li-GRU 和LSTM 在层数增加时错误率明显上升.Highway-GRU 相对于GRU 有更低的音素识别错误率,并且在层数增加时有着更好的模型效果,但其消耗的时间却明显高于其他结构.而本文设计的Re-GRU 在7 层网络时,比GRU 的音素识别错误率低1.4%,比LSTM 低0.8%,比Li-GRU 低1%.此外,在训练耗时方面,Re-GRU 的时间消耗低于LSTM和Highway-GRU.
表4 TIMIT 的测试结果(%,s)Table 4 TIMIT dataset test results (%,s)
图7(a)为GRU 和Re-GRU 在训练过程中对训练集的损失值变化曲线,为了让对比效果更明显,本文选择了3 层、5 层和7 层网络并且没有使用学习率衰减.其中图7(b)为图7(a)的第20~ 25 次迭代的损失值曲线放大图.由图7 可以看出,传统GRU 的损失值随着网络层数的增加而越来越大,而本文设计的Re-GRU 能随层数增加而有效降低损失值.损失值的有效降低使得本文设计的Re-GRU模型音素识别错误率能够低于其他模型.
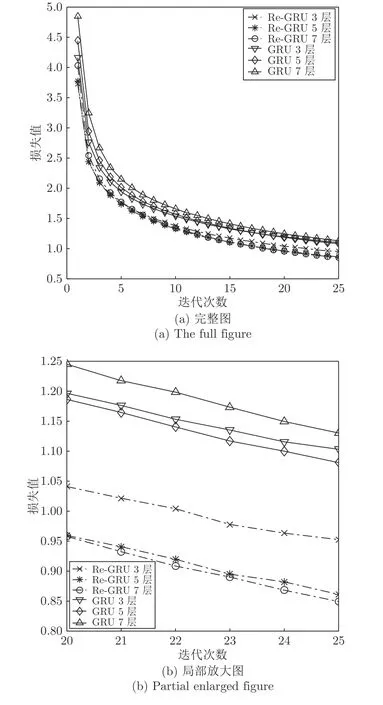
图7 GRU与Re-GRU 在TIMIT 数据集上的损失值变化曲线Fig.7 Loss curve of GRU and Re-GRU on TIMIT dataset
当本文在TIMIT 数据集的梅尔频率倒谱系数特征值上使用Pytoch-Kaldi 平台构建7 层网络的双向Re-GRU时,模型的音素识别错误率低至15.0%,对比文献[21]方法,本文设计的Re-GRU 具有更优的模型效果.
此外,本文采用了类似于文献[11]的构建跨越两层的残差连接,将Re-GRU 的跨越一层改为跨越两层.跨越两层可以更远的传递信息,通过这种方式可以使网络进行更远的残差学习.在TIMIT 数据集上进行额外的对比实验,发现在同样网络深度下,跨越两层的Re-GRU 比跨越一层的Re-GRU 音素识别错误率大约要更低0.1%~ 0.3%.
4 结束语
在循环神经网络体系中,存在着梯度消失和网络退化问题,本文基于GRU 提出的Re-GRU 具备解决梯度消失和网络退化问题的能力.与传统循环神经网络相比,本文的Re-GRU 在网络层数较深时模型依然能有较好的性能,并且本文的改进并没有增加网络的参数量.相比传统的循环神经网络,本文的Re-GRU 有着更低的错误率和较低的训练耗时.在缺点方面,本文设计的Re-GRU 不能够避免过拟合现象: 如果使用了特别深的网络,虽然模型的损失值可能继续降低或者保持不变,但模型效果却可能变差.此外,之前也对RNN 和LSTM进行了类似的改进并进行实验,发现本文的改进方法在RNN 上使用后能够相对RNN 有较大效果提升,但却并不适用于LSTM.通过理论分析和具体实验发现: 当将LSTM 的两个或其中一个时序传输公式中的饱和激活函数修改为非饱和激活函数时,都会导致模型发生梯度爆炸问题;并且,仅仅对LSTM 直接添加残差连接未能取得较大效果提升.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
电子制作(2018年1期)2018-04-04
现代商贸工业(2017年23期)2017-09-13
北京航空航天大学学报(2017年12期)2017-04-23
物联网技术(2015年8期)2015-09-14