结合聚类分解的增强蚁群算法求解复杂绿色车辆路径问题
2022-12-31 02:56胡蓉李洋钱斌金怀平向凤红
自动化学报 2022年12期
胡蓉 李洋 钱斌 金怀平 向凤红
传统的车辆路径问题(vehicle routing problem,VRP)由Dantzig 和Ramser 于1959 年首次提出[1].该问题主要描述为在满足车辆载重、容积、行驶里程及客户服务要求等条件的同时,合理调度车辆出行数量、行车路线、出行时间,使得总运费用最优化.随着社会经济的高速发展,跨区域多车队联合车辆配送需求明显增加[2−4].同时,当今环保要求越来越严格,考虑燃油消耗和碳排放等因素的低能耗车辆配送已开始受到重视[5].此外,日益激烈的市场竞争逼迫企业注重降低物流配送成本和提高客户满意度[6].在此背景下,研究带时间窗的低能耗多车场多车型车辆路径问题(Low-energy-consumption multi-depots heterogeneous-fleet vehicle routing problem with time windows,LMHFVPR_TW),
具有十分重要的现实意义.由于VRP 为NP-hard问题,而VRP 可归约为LMHFVPR_TW,故LMHFVPR_TW 也属于NP-hard 问题,对其开展研究亦具有较大理论价值.
低能耗车辆路径问题近年已开始受到重视,但相关研究仍较为有限.在低能耗多车场车辆路径问题 (Low-energy-consumption multi-depots VRP,LMVRP)方面,Jabir等[7]在问题中考虑碳排放等因素,利用蚁群算法与变邻域搜索(Variable neighborhood search,VNS)相结合进行求解.仿真实验表明,该算法可有效求解小规模和大规模问题.Kaabachi等[8]在问题中考虑距离、碳排放和燃油消耗等因素,并在蚁群算法中加入插入、交换和2-opt等邻域搜索策略以提高算法局部搜索能力,取得良好的效果.在低能耗多车型车辆路径问题 (Low-energy-consumption heterogeneous-fleet VRP,LHFVRP)方面,Xiao等[9]在问题中考虑交通拥堵和碳排放等因素,并设计融合变邻域搜索和整数规划的迭代搜索算法进行求解.Kwon等[10]在问题中考虑碳排放交易机制(即各国之间通过碳排放交易市场相互买卖碳排放量,以保证该国的碳排放量在其规定的配额内),然后采用混合禁忌搜索算法进行求解.目前尚无LMHFVPR_TW 的相关研究.
对于多车场车辆路径问题 (Multi-depot VRP,MVRP)、多车型车辆路径问题(Heterogeneousfleet VRP,HFVRP)和多车场多车型车辆路径问题(Multi-depot heterogeneous-fleet VRP,MHFVRP)这几类复杂VRP,智能算法已有一定的研究.现有研究大多对问题进行整体编码和求解,但由于这些问题比单车场单车型VRP (即传统VRP)具有更多的决策变量和约束条件,使得解空间扩大且编码解码较为繁琐,这时仅靠智能算法本身已难以将搜索快速引导至目标值整体较优的不同区域(即较优区域)执行,容易导致算法实际搜索效率下降.因此,近年来部分学者在所提算法中,先采用某种分解策略将问题合理分解为多个相对简单的子问题,从而将算法搜索尽量限定于解空间中部分存在优质解的较优区域之内,然后再用智能算法等求解各子问题并获得原问题的解,取得良好效果.在MVRP方面,主要考虑地理条件、客户需求和交货时间等因素,并采用聚类算法把MVRP 分解为一系列单个车场VRP,然后采用粒子群优化(Particle swarm optimization,PSO)算法[11−12]、遗传算法[13]等求解.在HFVRP方面,主要考虑车辆载重量、车辆运输费用和客户需求等因素,并采用路径分割法把HFVRP 分解为一系列单车辆VRP (即旅行商问题(Traveling salesman problem,TSP)),进而采用禁忌搜索算法[14]等求解.在MHFVRP 方面,由于该问题复杂度高,为HFVRP 和MVRP 的综合,故大都先采用分解策略将MHFVRP 分解为一系列HFVRP (即单车场异构车辆的VRP),然后采用路径分割法将各HFVRP 进一步分解为多个TSP.譬如,Dondo等[15]先采用一种启发式聚类算法将全部客户分成若干类,然后利用路径分割算法分配车辆,从而将原问题转化为多个小规模TSP,然后再利用混合整数规划求解器进行求解.Tang等[16]先利用最近邻方法把客户聚类到相应的车场,然后再用扫描法对每个车场中的客户进行路径分割,进而将原问题转化为多个TSP,最后采用蚁群算法求解.上述文献中的仿真实验和算法对比验证了分解策略和智能算法结合的必要性.然而,对于现实物流配送中大量存在且更为复杂的LMHFVPR_TW,尚无结合分解策略的智能求解算法,故开展相关研究意义重大.
蚁群算法(Ant colony optimization,ACO)是一种模拟蚂蚁寻找食物的群智能优化算法,最早由Dorigo等[17]提出并首次用于求解TSP.ACO 借鉴蚂蚁觅食的群体智能行为,利用信息素浓度矩阵(以下简称信息素矩阵)学习和保留蚂蚁在各自行驶路径(即问题解)上留下的信息素浓度信息,并基于该矩阵构建路径转移概率矩阵(以下简称概率矩阵),然后通过对概率矩阵采样生成新种群来实现路径搜素(即解空间搜索)并引导搜索方向.ACO 采用正反馈机制使得较短行驶路径(较优解)的优良信息得以更多积累,可引导算法在较短时间内到达解空间中存在优质解的区域.这使得算法具有较强的全局搜索能力,从而在多种VRP 上得到成功应用[7−8, 18−24].从ACO 在VRP 系列问题上的研究现状来看,采用合理的信息素浓度计算策略可控制全局搜索的方向,引入基于有效邻域操作的局部搜索能进一步提高算法性能,两者是设计有效ACO 的关键.文献调研表明,ACO 求解LMHFVPR_TW 的研究目前处于空白状态.
本文研究LMHFVPR_TW 的建模与求解.在建模方面,给出包含经济费用、燃油消耗费用和客户满意度费用的运输总费用计算模型,并建立以最小化运输总费用为优化目标的LMHFVPR_TW.在求解方面,考虑到LMHFVPR_TW 这类问题的解空间庞大且整体编码解码复杂,直接采用智能算法难以在较短时间内实现有效搜索,故提出一种结合聚类分解的增强蚁群算法(Enhanced ant colony optimization based on clustering decomposition,EACO_CD)进行求解.
EACO_CD 的结构如图1 所示(以2 个车场2 类车型为例).由图1 可知,EACO_CD 由问题分解阶段和子问题求解阶段组成.1)在问题分解阶段,为确保分解后的各子问题区域尽量覆盖解空间中的优质解区域,设计两层基于K-means 的聚类算法对问题进行逐步分解.第1 层聚类算法为所提的一种改进平衡K-means 聚类算法(Improved balanced K-means algorithm,IBKA),用于给每个车场分配一定数量的客户,从而形成一系列带时间窗的低能耗单车场多车型VRP (LHFVRP with time windows,LHFVRP_TW);第2 层聚类算法为所提的一种带粒子群优化的混合K-means 聚类算法(Hybrid K-means clustering algorithm with PSO,HKMA),用于给每个LHFVRP_TW 中的每类车型合理分配一定数量的客户,进而得到一系列带时间窗的低能耗VRP (Low-energy-consumption VRP with time windows,LVRP_TW).两层聚类分解算法将原问题最终分解为子问题LVRP_TW,而不是分解为比LVRP_TW 规模更小的带时间窗的低能耗TSP,这使其子问题的解空间区域相对较大,有利于算法对原问题解空间中更多区域进行搜索,可望获得更好的解.2)在子问题求解阶段,采用所提的增强蚁群算法(Enhanced ant colony optimization,EACO)对每个分解后子问题(即LVRP_TW)的解空间区域进行搜索,进而将子问题的解合并后得到原问题的解.在EACO 中,采用动态的信息素浓度挥发系数(以下简称信息素挥发系数),并进一步加入信息素挥发系数控制因子以调节其取值,可避免算法过早收敛,并进一步引导算法全局搜索到达更多的不同区域;同时,设计基于4 种变邻域操作的两阶段局部搜索策略,用于对全局搜索发现的优质解区域进行细致且高效的搜索,以平衡全局和局部搜索并增强算法性能.最后,通过仿真实验和算法比较验证所提算法的有效性.

图1 EACO_CD (EACO_IBKA_HKMA)结构Fig.1 Framework of EACO_CD (EACO_IBKA_HKMA)
1 LMHFVRP_TW 建模与分析
本节建立LMHFVPR_TW 模型并对问题特点和求解算法进行分析.LMHFVPR_TW 为带软时间窗约束的多车场多车型车辆配送问题,优化目标为最小化运输总费用(即经济费用、燃油消耗费用和客户满意度费用之和).该问题在已知客户位置坐标、车场位置坐标、客户货物需求量、客户时间窗、各车场车型特征(表1 中给出相应的符号定义)的情况下,希望找到各车场中车辆的最佳配送路线(由第1.3 节问题模型中的决策变量具体取值确定),从而使总运输费用达到最优.LMHFVPR_TW的应用场景很多,譬如电商和连锁超市的商品配送、战区和疫区的紧急物资配送、石化企业成品油的一次和二次配送等.
1.1 问题假设和符号定义
LMHFVPR_TW 满足如下假设:
1) 每个车场当中的每一类车型都参与配送任务;
2) 每个车场所含的车型种类相同;
3) 车辆在一次任务分配中仅进行一次配送;
5) 车辆从车场出发,完成服务后需回到原车场;
6) 每个客户都被服务,被服务的次数有且仅有一次;
7) 车辆配送中的货物需尽量在每个客户要求的到达时间段内送达.
LMHFVPR_TW 的相关符号定义如表1 所示.

表1 符号及定义Table 1 Symbols and definitions
1.2 问题优化目标计算模型
LMHFVPR_TW 的优化目标为运输总费用ZTotal,该优化目标由3 部分组成: 经济费用ZEmission-cost、排放费用ZEmission-cost及客户满意度费用ZCustomer-Satisfaction.其中,经济费用由运输距离费用F1和车辆固定成本F2组成,排放费用设定为燃油消耗费用F3,客户满意度费用由软时间窗惩罚费用F4构成.

其中,式(3)中燃油消耗量FUMij的计算基于文献[10]中的综合燃油消耗模型和参数设置,并假设各类车型的油耗参数相同,可得到FUMij的计算式为

1.3 问题模型
问题优化目标为
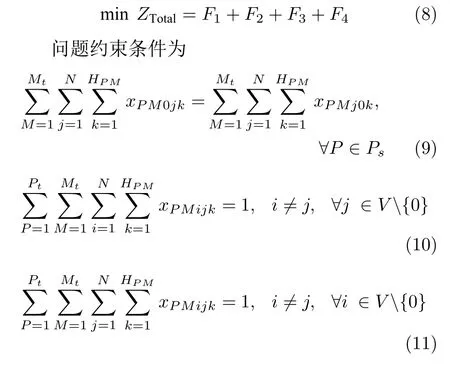

其中,式(9)要求从某车场出发的车辆数目和回到该车场的车辆数目相等;式(10)和式(11)要求每个客户只能被一辆车服务1 次;式(12)要求所有车辆均需参与配送,且配送完后返回原车场;式(13)要求生成的配送方案或问题解不出现不含车场的子回路;式(14)要求车辆配送过程中不能超过其对应车型的额定载重量.
1.4 问题特点分析
由第1.3 节可知,本文的LMHFVPR_TW 为具有非线性和大规模约束的0-1 整数规划问题.相对于传统VRP,式(1)~ (4)使优化目标不同且更加复杂,同时式(4)使优化目标具有非线性;多车场和多车型的引入,使得决策变量由传统VRP 的3维变量xijk变为5 维变量xP Mijk,导致决策变量和约束的数量增多,这使得问题解空间更加庞大和复杂.此外,相对于常规0-1 整数规划问题,VRP 系列问题均含子回路消除约束(式(13)),该类约束的数量为 2N+1−2,这种指数级的约束数量限制了问题的求解规模.虽然可以通过增加连续决策变量,使式(13)的约束个数变为客户数N的多项式,从而扩大问题的求解规模,但此时原问题近似转化为同时含离散和连续决策变量的混合0-1 整数规划问题,该近似问题的求解难度并未降低[26].
1.5 问题求解算法分析
VRP 系列问题(包括本文的LMHFVPR_TW)均可建模为0-1 整数或混合整数规划模型,其求解算法分为两类.一类为运筹学算法,包括分支定界、分支切割、动态规划等[27].该类算法主要以线性代数和几何分析为基本工具,利用问题优化目标函数和约束条件式的结构信息构造遍历或部分遍历解空间的搜索,可在几分钟至几十分钟内求解较小规模问题(客户数小于等于20),同时经过合适设计,也可用于求解较大规模问题(客户数大于等于80),但往往求解时间很长[27−29].不同于线性规划问题,0-1规划问题具有非凸特性,其内在几何结构与最优解间的关系仍属开放问题,目前仅在无约束0-1二次规划等少数具有特殊结构的简单问题上存在有效多项式时间求解算法[6,28,30],尚无通用的最优解多项式时间求解算法.对于LMHFVPR_TW 这类复杂的0-1 规划问题,采用已有的运筹学算法框架虽然也可设计相应的求解算法,但算法难以在较短时间获取较大规模问题的满意解.另一类是智能优化算法(以下简称智能算法),包括蚁群优化算法、遗传算法、禁忌搜索算法等[27].该类算法不依赖于问题结构,而是将问题的约束条件隐式地包含在所设计的解的编码、解码规则中处理,并利用某种拟人、拟物的机制不断生成新的可行个体或解,从而引导算法执行搜索,往往可在几秒或十几秒内就能获得各类VRP的满意解[6, 27, 31].
目前,各类文献对所提智能算法使用少量个体(一般种群规模为 20∼100)运行少量代数(一般进化代数为 100∼1000)后,为何都可获得问题的满意解,基本都只从算法本身的机制进行解释.这导致现有研究过于追求新方法层面的创新.实际上,智能算法之所以有效,是由其编码解码规则和智能算法自身机制共同决定的.智能算法并不直接对0-1变量编码,而是对客户序号排列进行编码解码规则的设计.这样的排序编码解码,容易将解中元素的取值限定在满足约束的可行范围,从而避免繁杂的约束处理,可明显提升算法搜索效率.同时,排序编码解码规则所确定的解空间极为扁平,问题目标值的变化范围远远小于排序模型解空间的规模,这非常有利于算法短时间内获取满意解.具体来说,譬如优化目标为最小化总行驶距离的单车辆VRP(即TSP),假如有100 个客户,任意两个客户间的距离为在区间[1,1000]上均匀分布的随机数,且要求车辆从某个客户驻地(车场)出发,服务完客户后返回该驻地,则其目标值变化范围在(1,1000000)之内(1000000 为各客户间的距离之和的上限,实际的最大目标值小于此值),而解空间规模为99!(车辆出发位置的客户需扣除),平均每一个具体目标值对应约 9×10149个不同排列或解,这表明数量巨大的不同解具有相同的目标值.对于其他更为复杂的VRP (包括本文的LMHFVPR_TW),也存在这一情况.另外,离散问题本身解之间没有梯度,相邻解之间的目标值差别可能很小,也可能较大.排序编码解码规则所确定解空间的 “极为扁平”性和“无梯度” 性,使得各种智能算法即使只用几秒(CPU为 2.6 GHz 的主流PC 在 1 s 内可搜索并评价含100个客户的传统VRP 问题的数万个解)搜索解空间中极小的区域(数万的数量级相对于99! 类似于1根针或更小的面积相对于体育场),也可能到达较广的目标值区域,同时其内在的寻优机制可驱动算法到达目标值较优的不同区域搜索,从而获得满意解.智能算法这种通过对解空间极小区域的搜索来实现对目标值较广且较优区域的搜索,是其有效的本质原因,也是现有运筹学算法这类偏遍历或部分遍历解空间的算法难以做到的.因此,设计智能算法以实现对LMHFVPR_TW 快速有效求解,是合理且必要的.
由第1.4 节和第1.5 节的分析可知,对于LMHFVPR_TW 这类非凸、非线性问题,直接采用运筹学方法在短时间内获取满意解难度很大,故本文设计一种智能算法(即结合聚类分解的增强蚁群算法EACO_CD)进行求解.
2 问题求解算法EACO_CD
本文所提的求解算法EACO_CD 包含问题分解阶段和子问题求解阶段(见图1).通过两层聚类分解,原问题LMHFVPR_TW 转换成为Pt×Mt个单车场单车型子问题LVRP_TWs,然后采用本文设计的子问题求解算法EACO 依次对每个LVRP_TW 进行求解,进而可获得原问题的解和优化目标值.第2.1 节介绍EACO_CD 中问题分解阶段的细节,包含两层聚类算法的细节和复杂度分析;第2.2 节介绍EACO_CD 中子问题求解阶段的细节,包含EACO 的细节和复杂度分析;第2.3 节介绍EACO_CD 的总体框架并分析整体复杂度.
2.1 EACO_CD 的问题分解阶段
EACO_CD 的问题分解阶段执行两层聚类算法,第1 层聚类算法为IBKA,用于将原问题LMHFVPR_TW 分解为Pt个单车场子问题LHFVRP_TWs;第2 层聚类算法为HKMA,用于将每个单车场问题LHFVRP_TW 进一步分解为Mt个单车场单车型子问题LVRP_TWs (见图1).在对数值型数据进行聚类时,大都采用K-means、模糊聚类(Fuzzy cluster)等算法[14, 32−34].而针对混合型数据,可采用K-prototypes 算法或先将混合型数据转换为数值型数据[35].由于本文问题中的客户属性数据均为值型,不需要对数据类型进行转换,同时,Kmeans 具有线性计算复杂度,已成功应用于VRP系列问题[12, 14, 33, 36−37],故本文在IBKA 和HKMA中采用K-means 作为基本分解策略.
2.1.1 第1 层聚类算法(IBKA)
本文问题的优化目标(见式(8)) 由4 部分组成,其中有两部分与车辆运输距离有关.当车辆距客户较远时,配送所产生的燃油消耗费用和距离费用都随之增加(见第1.2 节模型),故IBKA 采用客户之间的欧氏距离作为评价标准,将客户聚成与车场数目相同的几类,使得每个车场服务其中一类客户.但是,随着客户数量逐渐增大,聚类后会出现每个车场服务的客户数量相差较大.为确保每个车场的客户资源能均衡分配,设计IBKA 进行聚类.由于文献[37]提出的K-means 平衡算法仅适用于2 类客户之间的平衡(Pt=2),本节将文献[37]提出的Kmeans 平衡算法推广客户群,同时设计车场分配规则,可更为合理地确定各车场服务的客户群.进而,获得Pt个单车场子问题LHFVRP_TWs.IBKA 的步骤如下.
步骤1.对全体客户进行K-means 聚类.初始化聚类重心为每个车场的坐标位置,初始化聚类数量为车场数量,以欧氏距离作为评价指标,以迭代次数作为终止条件.
步骤2.平衡客户群.完成上述步骤后进行k类客户群之间的平衡计算,具体如图2 所示,按每类客户群数目由大到小排序,根据两类客户间的边缘算法[37],将客户较多的客户群依次向其余客户较少的客户群移动,循环操作直至各类客户群中客户数目达到平衡.

图2 4 类客户平衡移动示意图Fig.2 Diagram of balanced movement for four customer groups
步骤3.计算每个车场到各聚类重心的距离.列出距离矩阵A,设A为Pt×Pt的二维矩阵,矩阵中的每一个元素表示某一车场坐标到某聚类重心的距离,即
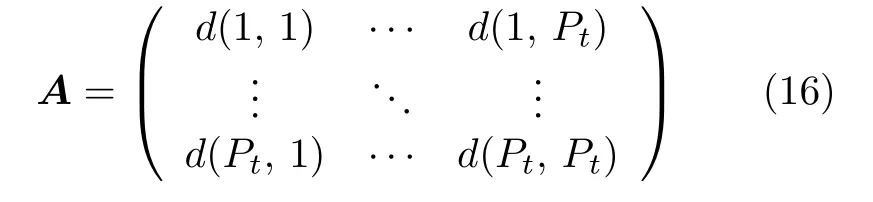
其中,d(i,j) 为车场坐标i到聚类重心坐标j的欧氏距离.
步骤4.按设计的分配规则对车场所服务的客户群进行分配.选取矩阵A中不同行(车场不同)不同列(客户群重心不同)的Pt个元素并相加,共有Pt! 种不同的组合及对应的累加和选出其中最小的Smin(见式(17)) 所对应的组合中每个元素d(i,j) 的行、列标号即为车场i所服务的客户群j. 采用Smin确定车场服务的客户群有利于整体减小车辆运输距离.
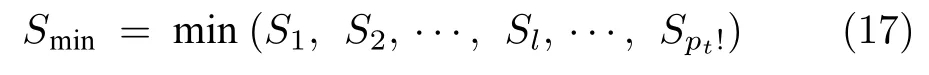
其中,Sl表示矩阵A中对不同行不同列元素的第l种累加和.
对于K-means 迭代次数为gen1K、平衡迭代次数为genb、问题规模为N_Pt(客户数量_车场数量) 的问题,IBKA 的计算复杂度(以下简称复杂度)TIBKA分别由K-means 聚类复杂度O(gen1K×Pt×N)、客户平衡复杂度 O (genb×(Pt×N)2) (最坏情况)、获取方阵A的复杂度 O () 和获取Smin的复杂度 O (Pt×) 决定.因此,
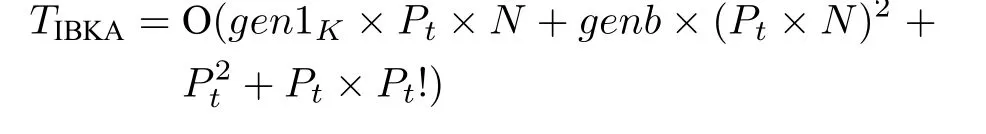
针对3 车场和144 客户的本文问题LMHFVPR_TW,采用IBKA 进行车场划分.根据列出距离矩阵A(3×3),分别给出矩阵A(3×3)中不同行不同列的Pt个元素累加和的全部组合方式,并计算不同的累加和共3! 次(见式(18)).若Smin=S1,即车场1 服务A类客户,车场2 服务B类客户,车场3 服务C类客户,划分结果如图3 所示.图3 中上、下子图分别为未采用和采用平衡聚类的结果.从图中可以看出,采用平衡聚类可使各车场服务的客户数量更加接近,有利于提高各车场的整体效率和控制子问题规模.
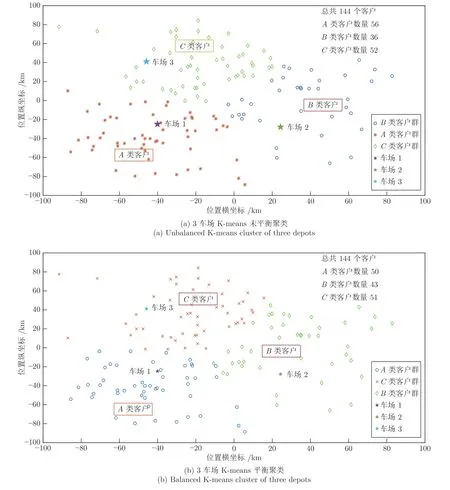
图3 3 车场K-means 未平衡聚类与平衡聚类比较Fig.3 Comparison of unbalanced K-means cluster and balanced K-means cluster of three depots

2.1.2 第2 层聚类算法(HKMA)
客户的时间窗、客户的货物需求重量、客户与车场间的距离是影响本文问题优化目标(见式(8))的重要因素,故HKMA 将其作为客户的3 类属性,采用K-means 对客户聚类后再为各类客户分配相应的车型.K-means 聚类时是将每个客户作为一个对象(质点).在多属性客户进行K-means 聚类时,需将各属性做加权和后才可进行.然而,上述3 类属性对优化目标(见式(8))的影响程度无法直接确定,故需对各属性权重系数进行优化,从而提高子问题分解的合理性.
HKMA 为内外两层结构,外层执行微粒子群优化(PSO) 算法,用于优化属性权重系数向量λ(λ=(λ1,λ2,λ3)且λ1+λ2+λ3=1);内层对基于每个λi的聚类分解效果进行评价,并将评价值fi(λi)作为PSO 种群个体的适应度值.HKMA的工作机制如图4 所示,其中PSO 种群PPSO的每个λi(i= 1,···,M1)表示一组权重系数取值,基于λi对单车场问题LHFVRP_TW 做K-means 聚类可得到Mt类客户群,将Mt类车型和Mt类客户群逐一配对,得到单车场单车型子问题LVRP_TW(记为Ai,j,i和j分别为车型和客户群编号,i,j=1,···,Mt),f(Ai,j) 表示对问题Ai,j采用第3.1 节的编码规则随机生成10 个解的评价值(即子问题总运输费用)的平均值,Fi为f(Ai,j) 组成的方阵,Sum_fk(k=1,···,Mt! ) 表示第k个由Fi中Mt个相互不同行(车型不同)不同列(客户群不同)元素累加所得的值,fi_min 取所有Sum_fk中的最小值并赋值给fi(λi). 由Mt个车型和客户群均不同的Ai,j可构成一个LHFVRP_TW,故Sum_fk实际上是对第k种子问题分解方式合理性的评估,同时fi_min用于标识相对最为合理的子问题分解方式.
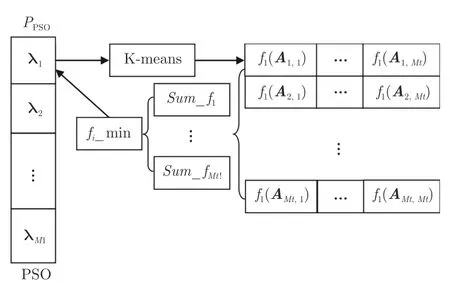
图4 HKMA 工作机制Fig.4 Running mechanism of HKMA
令ZTotal(Ai,j) (见式(8))为个体Ai,j的目标函数值,λopt为PPSO的历史最优个体,subP(λopt)为f(λopt) 对应的Mt个单车场单车型问题LVRP_TWs 的集合(具体见前述),Maxgen(PSO) 为HKMA 中PSO 算法的运行代数,gen2K为HKMA中每次执行K-means 算法的运行代数.HKMA 的具体步骤如下.
步骤1.令gen=1,随机生成PPSO中的每个λi.
步骤2.(内层): 确定PPSO中所有λi的适应度值(具体见前述).
步骤3.(外层): 若gen>1,则将当代PPSO和父代PPSO的个体进行冒泡排序,并择优保留前M1 个组成PPSO. 更新λopt和subP(λopt).
步骤4.(外层):PPSO通过PSO 算法进化后得到新的种群PPSO,也即得到M1 组新的权重系数向量.
步骤5.令gen=gen+1,若gen≤Maxgen(PSO),则返回步骤2,否则输出subP(λopt).

在本文算法EACO_CD 中,HKMA 的参数设置为M1=10,M2=10,Maxgen(PSO) =10和gen2K=20,PSO 中的惯性权重和加速因子的设置与文献[38]相同,具体设置为惯性权重ω=0.9 ,速度因子c1=1.2,c2=1.5.针对第2.1 节中示例问题的车场1 和其服务的A类客户(即IBKA 划分得到一个单车场子问题LHFVRP_TW),采用HKMA 进行车型划分,可得图5 和图6.由图5 和图6 可见,A类客户依据车型和客户的3 类属性得以进一步划分,从而将1 个LHFVRP_TW 分解为规模更小的2 个单车场单车型子问题LVRP_TWs.

图5 HKMA 三维聚类效果Fig.5 The 3D clustering results of HKMA
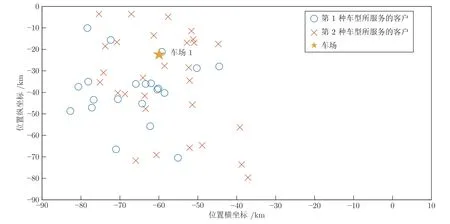
图6 HKMA 二维结果Fig.6 The 2D results of HKMA
2.2 EACO_CD 的子问题求解阶段
通过上一阶段的两层聚类分解后,原问题LMHFVPR_TW 转换成为Pt×Mt个单车场单车型子问题LVRP_TWs,从而本阶段可采用本文设计的子问题求解算法EACO 依次对每个LVRP_TW进行求解,进而可获得原问题的解和优化目标值(见图1).第2.2.1~ 2.2.4 节介绍EACO 的细节,第2.2.5节给出EACO 的复杂度分析.
2.2.1 编码与解码规则
EACO 对各车辆服务的所有客户进行整体编码.每只蚂蚁代表多辆车,每只蚂蚁的行驶路径(即子问题LVRP_TW 的l个解)为对应各车辆的总行驶路径.譬如对于第l只蚂蚁服务10 个客户,可记为:πant(l)=[1,4,9,5,10,2,3,6,7,8].
EACO 采用文献[39]中的方法对每只蚂蚁的行驶路径进行解码,即逐一选择车场中的每辆车,将πant(l)中客户从左向右依次加入当前车辆,如果当前车辆的载重量大于其服务客户的总需求量,则继续往该车辆中加入客户,否则选择下一辆车继续依次加入剩余客户.譬如,对于上一段的πant(l),假设需两辆车进行服务,解码后可得πant(l)=[πvehicle(1),πvehicle(2)]=[1,4,9,5],[10,2,3,6,7,8].
显然,当采用上述编码解码规则时,式(13)的子回路消除约束自然得到满足,同时也不违反其他约束.
2.2.2 全局搜索
2.2.2.1 初始化
首先,利用扫描法(Sweep algorithm,SWA)构造1 只蚂蚁的行驶路径[40],并采用该路径对信息素浓度τij进行初始化

其中,i,j为客户编号,Pm为信息素浓度值的初始值(设置为大于1 的值).为防止算法过早陷入局部最优[41],设置信息素浓度τij的最大值和最小值为

然后,设置信息素浓度增量 ∆τij=0 以及种群大小popsize=(2/3)×N.
2.2.2.2 蚂蚁行驶路径搜索
EACO 每代通过对当前种群中各蚂蚁行驶路径的确定来实现对问题解空间的全局搜索.每只蚂蚁均利用式(22)确定其行驶路径.

其中,i为当前客户,u为下一客户,为第l只蚂蚁从i到u的转移概率,s为蚂蚁l还未服务过的客户,τiu(τis) 为i和u(s) 间的信息素浓度,ηiu(ηis)为i和u(s) 之间距离的倒数,α和β为重要程度权重,tabu为蚂蚁已经搜索过的客户地点集合.对tabu}进行轮盘赌选择,即可得到u的取值,从而确定蚂蚁l从客户i出发需到达的下一客户.
2.2.2.3 信息素浓度更新
EACO 每代对每只蚂蚁的信息素浓度采用式(23)~ (26)依次进行更新

其中,γ为信息素挥发系数控制因子(初始设置为1),Ma和Mb为迭代次数系数(均设置为5),T为基准值(设置为50),Lb为当前最好解对应的目标函数值,t表示算法进化的代数(即算法第t次迭代),ρt为第t代的信息素挥发系数(初始设置为0.9),ρmin和ρmax分别为ρt的最小值和最大值(分别设置为0 和1),为第t代的信息素浓度增量,W为信息素增量常数(设置为500),为第t代的信息素浓度.γ根据算法每代的实际运行效果动态调整其取值,可在运行效果好(差)时增加(减小)信息素浓度,有利于增强算法合理引导搜索的能力.
2.2.3 局部搜索
本节在基本变邻域搜索(VNS)[42]基础上提出一种两阶段变邻域局部搜索策略(Two-stage variable neighborhood search,TVNS),对EACO 每代发现的当前最好解进一步执行高效且细致的邻域搜索,以提高解的质量.
TVNS 为在车辆间和车辆内部分别执行多种邻域操作(见图7)的两阶段局部搜索,两个阶段中各邻域操作均在当前最好解上执行且每次执行的最大次数均设置为genlocal=20.首先,第1 阶段随机选择两辆车,依次对车辆间的客户执行 “Insert”和“Exchange”邻域操作,如果在执行操作期间发现更好解,则更新当前最好解并立刻进入第2 阶段,否则各邻域操作均执行至最大次数genlocal后进入第2 阶段.然后,第2 阶段逐一选择每辆车,对每辆车的内部客户依次执行 “2-opt”、“Insert”、“Exchange”和 “Swap”邻域操作,如果在执行操作期间发现更好解,则更新当前最好解并立刻对下一辆车执行操作,否则各邻域操作均执行至最大次数genlocal后再对下一辆车执行操作.第2 阶段结束后完成本次局部搜索.

图7 局部搜索策略Fig.7 Local search strategy
2.2.4 EACO 终止条件
设定终止条件为算法的运行时间,如果满足运行时间要求,则输出服务所有客户的每辆车的行驶路径以及相应的行驶总费用.
2.2.5 EACO 复杂度分析

其中,l ~ogN表示低于N的亚线性复杂度.
2.3 EACO_CD 整体结构及复杂度分析
2.3.1 EACO_CD 整体结构
算法EACO_CD 的整体结构如图1 所示(以2 个车场2 类车型为例).由图1 可知,EACO_CD对Pt×Mt个子问题LVRP_TWs 依次执行EACO进行求解,最终将获得的各子问题解合并,得到原问题的解,同时将各子问题解的优化目标值累加,得到原问题的优化目标值,从而实现对原问题的求解.
2.3.2 EACO_CD 复杂度分析
EACO_CD 是对本文问题LMHFVPR_TW的整体求解,其复杂度TEACO_CD由分解算法IBKA的复杂度TIBKA(见第2.1.1 节)、分解算法HKMA总的复杂度total(THKMA) (见第2.1.2 节)、求解算法EACO 总的复杂度total(TEACO) 组成(见第2.2.5节).即
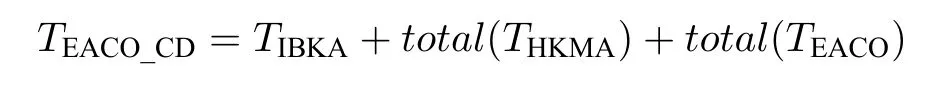
虽然TIBKA,total(THKMA)和total(TEACO) 中的变量较多,但除N(客户数量)、Pt(车场数量)、Mt(车型数量)与问题规模相关,Z(局部搜索每次迭代搜索的邻域或个体)与具体问题相关,popsizeE设置为2/3×N(见第2.2.2.1节)以外,其余变量均与算法相关且实际使用中都设置为常数.因此,可得简化式如下:

显然,所有变量的多项式次数不超过2,影响TEACO_CD的是TIBKA中的 O(Pt!) 和total(THKMA) 中 的O(Pt×Mt!). 然而,实际问题中Pt和Mt一般都不大于10,而若仅计算10!,用CPU 为2.6 GHz 的主流PC 可在1 s左右完成计算,故EACO_CD 对大多数实际问题可在较短时间内结束运算.另外,如果Pt(Mt)很大(譬如为50),可将IBKA 的步骤4 (HKMA 的步骤2)中穷举不同行不同列的组合改为采样Pt(Mt)的多项式次数的组合,从而扩大EACO_CD 求解问题的规模.
3 实验比较与分析
本节所有算法的测试均采用以下软硬件配置:英特尔I7 处理器(3.2 GHz),8 GB 内存,Win10 操作系统,MATLAB2018a 编程环境.
3.1 EACO 参数设定
在第1 节所提出的目标函数中(见式(7)),距离费用系数设定参考文献[7],车辆固定费用参考文献[9],燃油费用系数设定参考文献[43],时间窗惩罚费用系数参考文献[16],具体取值见表2.

表2 目标函数中的相关系数Table 2 Coefficients in the object function
EACO 的残留信息素重要程度α,启发信息素重要程度β,初始化信息素浓度参数Pm,信息素增量常数W为4 个主要的参数,为确定合适的参数组合,对这4 个参数进行正交实验,各参数设置水平如表3 所示.由于聚类分解后原问题LMHFVPR_TW 转变为Pt×Mt个LVRP_TWs,故采用Solomon 标准VRPTW 数据集中的问题c101 (100 个客户) 进行测试.每组参数组合下的EACO 在c101 上独立运行20 次,取20 次的平均最小运输总费用值作为平均响应值ARV,参数设置的正交表见表4,参数的平均响应值和影响力见表5.由表4和表5 可得,EACO 的参数设置为:α=1.25,β=2.5,Pm=1.1,W=500.

表3 主要参数与水平Table 3 Main parameters and level

表4 参数设置的正交表Table 4 Orthogonal table of parameter settings
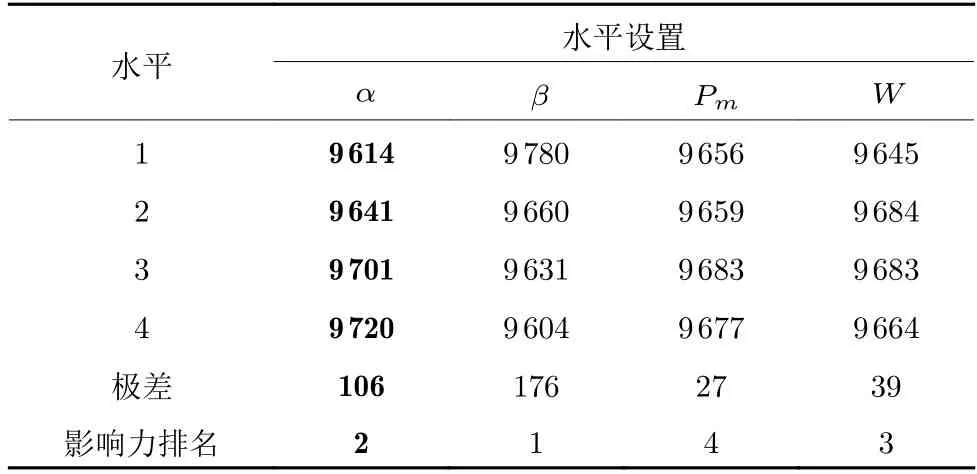
表5 各参数不同水平下的平均响应值和影响力Table 5 Average response values and influences table at different levels of each parameter
3.2 实验设计及测试问题选取
3.2.1 实验设计
EACO_CD 由IBKA、HKMA 和EACO 组成.为验证EACO_CD 的有效性,先将这3 种算法分别与国际期刊上的相近算法进行比较,最后再进行总体比较.测试实验车辆参数见表6.
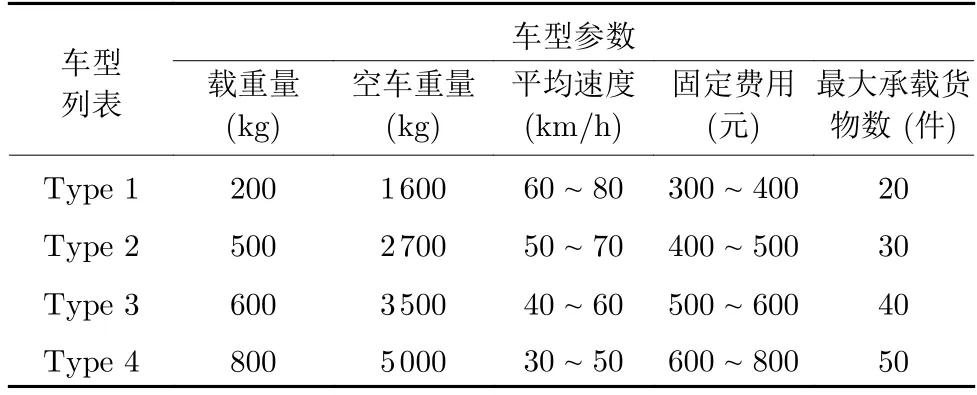
表6 4 种不同车型相关参数设置Table 6 Related parameter settings for four different vehicle types
首先,为验证EACO 的有效性,在多车场单车型问题LMVRP_TW 上,将EACO1与国际期刊中的有效算法DHACO[37]进行对比.EACO1 为EACO_CD 不含两层聚类的算法,而DHACO 为不含分解且直接求解整个问题的一类蚁群算法.EACO1 采用DHACO 的编码.测试结果见表7.
其次,为单独验证IBKA 的有效性,在多车场单车型问题LMVRP_TW 上,将EACO_IBKA与EACO_KM、EACO_NNA 进行对比.这3 种算法为在EACO1 中分别加入3 类第1 层聚类算法(即IBKA、K-means[12, 14]、NNA[11])后得到.测试结果见表7.
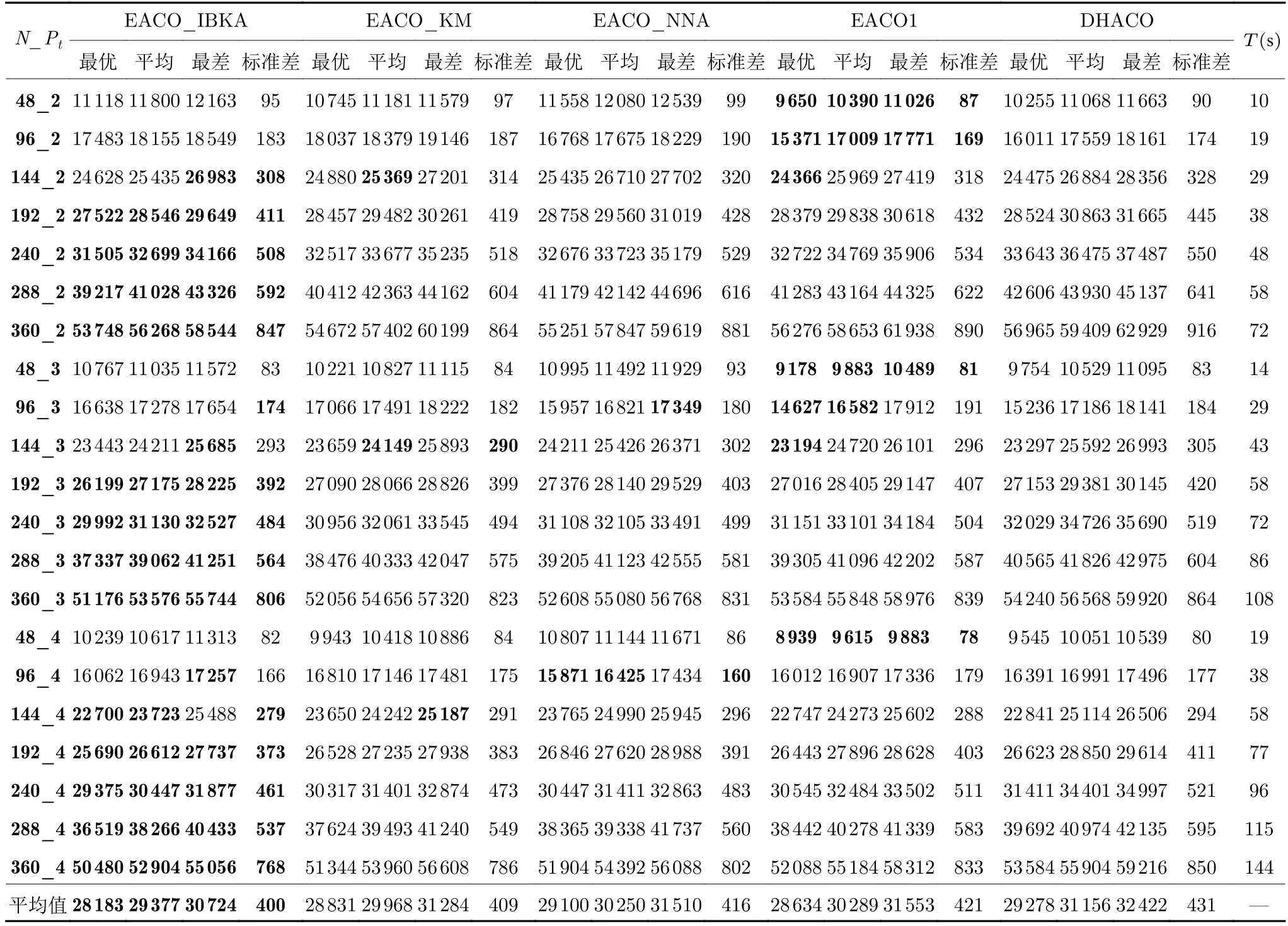
表7 EACO_IBKA与其他算法对比结果Table 7 Comparison results of EACO_IBKA with other algorithms
然后,为单独验证HKMA 的有效性,在单车场多车型问题LHFVPR_TW 上,将EACO_ HKMA 和EACO_RDA、EACO_RAA、EACO_ KEW、EACO2、TSA_RDA[10]进行对比.前4 种算法为在EACO1中分别加入4 类第2 层聚类算法(即HKMA、RDA[10]、RAA、KEW)后得到,其中RDA根据客户需求量优先选择最大载重量的车型,进而将问题分解为一系列单车辆LVRPs (即TSPs),RAA随机将客户划分给某种车型,KEW 给每类客户属性分配相同权重后用K-means 划分车型(即简化的HKMA),RAA 和KEW 均将问题分解为一系列单车型LVRP_TWs;EACO2 为EACO1 改用多车型编码后得到,用于直接求解整个问题;TSA_RDA 为国际期刊中的有效算法,该算法在禁忌搜索算法中加入RDA.测试结果见表8.

表8 HKMA与其他划分算法的对比结果Table 8 Comparison results of HKMA and the other dividing algorithms
最后,为验证EACO_CD 的有效性,在本文问题LMHFVPR_TW 上,将EACO_CD 和国际期刊中的有效算法IACO_CD[16]和IHGA[13]进行对比.IACO_CD 为两层分解算法,该算法第2 层将问题分解为单车辆LVRP (即TSPs),而IHGA 通过加入车型编码后对问题进行整体求解.测试结果见表9.
3.2.2 测试问题选取
本文的测试数据来源于网站(http://neo.lcc.uma.es/vrp/)中的MDVRP 数据集(数据中不存在明显聚类特征的客户位置分布).其中包括问题pr01 (48 个客户),pr02 (96 个客户),pr03 (144 个客户),pr04 (192 个客户),pr05 (240 个客户),pr06(288 个客户),p22 (360 个客户).由于该数据中未含有车型数据,故在HKMA 和EACO_CD 的有效性验证时加入车型数据(见表6),各比较算法在每个问题上独立运行20 次,每个算法设置相同运行时间T(s).性能指标为各算法20 次运行中的最优值(Best)、平均值(Average)、最差值(Worst)和标准差(SD).各种带分解策略的比较算法每次运行时间为问题分解算法与问题求解算法运行时间的总和,譬如,EACO_CD 每次运行的时间为EACO、IBKA和HKMA 的运行时间总和,表7~ 9 中粗体为算法运行结果的较小值.
3.3 实验结果比较和分析
3.3.1 验证EACO 有效性
由表7 可知,EACO1 (即不含问题分解策略的EACO_CD)的最优值和平均值均优于DHACO.在算法全局搜索部分,DHACO 和EACO1 的复杂度无明显差异,但EACO1 在全局阶段引入信息素挥发系数控制因子,进一步动态调节信息素挥发系数,可有效控制信息素的挥发,从而提高了算法的全局搜索能力.在算法局部搜索部分,相比DHACO的VNS 策略,EACO1 的TVNS 能有效搜索更多不同区域,具有更强的局部搜索能力.
3.3.2 验证IBKA 有效性
由表7 可知,EACO_IBKA 总体优于EACO_KM 和EACO_NNA.这表明IBKA 通过聚类和平衡客户群,可以更合理地分配车场并较好实现子问题解耦.同时,EACO_IBKA 也总体优于不含问题分解策略的整体求解算法EACO1 和DHACO.这说明采用有效的问题分解策略为算法提前确定需搜索的较优区域,可在一定程度上避免过多的低效搜索,有利于增强算法性能.此外,测试结果显示,带分解策略的算法更适用于较大规模问题,原因在于这些问题的解空间更加庞大,仅依靠智能算法自身进化机制难以快速引导算法发现优质解区域.
3.3.3 验证HKMA 有效性
由表8 可知,EACO_HKMA 总体优于其他比较算法.这表明HKMA 综合考虑客户的3 类属性并为各属性设定合适的权重,可以更合理地划分子问题.具体而言,EACO_HKMA 明显优于EACO_RDA 和TSA_RDA,这说明RDA 将问题分解为更小规模的单车辆LVRPs (即TSPs)会将算法实际搜索空间限定得过小,从而遗漏较多存在优质解的区域;EACO_HKMA 明显优于EACO_RAA(除N=96的1 个较小规模问题)和EACO_KEW,这说明RAA 随机划分子问题的方式和KEW 给各属性分配相同权重后再划分子问题的方式,均无法获取真正优质的搜索区域;EACO_HKMA 也明显优于整体求解算法EACO2,这再次验证了将问题先合理分解可把算法搜索直接限定在较优搜索区域进行,有利于提高算法效率.此外,与第3.3.2 节类似,本节的分解策略同样对较大规模问题更有效.
3.3.4 验证EACO_CD 有效性
由表9 可知,EACO_CD 总体优于IACO_CD和IHGA.具体而言,EACO_CD 的最优值、平均值、最差值均明显优于IACO_CD,且标准差整体较小,这说明IACO_CD 将问题分解为更小规模的单车辆LVRPs (即TSPs)会遗漏较多存在优质解的区域,同时IACO_CD 自身算法的搜索能力有限,从而导致该算法的性能和鲁棒性较差;EACO_CD 的最优值、平均值、最差值、标准差明显优于IHGA (除N=96 的2 个较小规模问题),这表明随着车场、车型和客户的增多,本文问题LMHFVPR_TW 的可行解空间呈指数倍增加,仅采用智能算法(如IHGA)难以在较短时间内完成大范围搜索以获得原问题的优质解,而EACO_CD 依靠合理的问题分解能将EACO 的搜索限定在较优区域之内,进而利用EACO 较强的搜索能力可短时间内从较优区域中获得优质解,从而使其性能和鲁棒性均较强.

表9 EACO_CD 性能验证Table 9 Performance verification of EACO_CD
综上可知,结合IBKA 和KHMA 的EACO_CD是求解本文问题LMHFVPR_TW 的有效鲁棒算法.
4 结束语
针对多车场多车型绿色车辆路径问题LMHFVRP_TW,本文提出一种结合聚类分解策略的增强蚁群算法(EACO_CD) 进行求解.这是首次采用智能优化算法求解该问题.EACO_CD 包括两个阶段.第1 阶段为问题分解,该阶段设计两种聚类分解策略IBKA 和HKMA,用于对LMHFVRP_TW 进行分解,从而有效控制问题规模并快速引导算法在较优区域内搜索;第2 阶段为子问题求解,该阶段采用EACO 对每个分解后的子问题LVRP_TW 进行求解.在EACO 的全局搜索中,通过加入信息素挥发系数控制因子动态调节信息素挥发系数的取值,可较好地避免算法出现过早收敛,进而引导算法搜索达到解空间中更多的不同区域.同时,为增强EACO 的局部搜索能力,设计一种两阶段变邻域搜索对全局搜索获得的优质解区域进行细致且高效的搜索.仿真实验和算法比较验证了所提EACO_CD 是求解LMHFVRP_TW 的有效算法.对于HFVRP 和MHFVRP,已有的问题分解方法大都将其最终分解为一系列更为简单的单车辆VRP(即标准TSP),这一分解方式是否合理且唯一,目前尚无人探讨.本文所提的IBKA 和HKMA 把LMHFVRP_TW 有效分解为一系列单车型VRP(即多车辆TSP),使其子问题具有较大的可行解区域,进而适当扩大了算法的实际搜索空间,取得了更好的效果.这表明合理选取子问题可在一定程度上提高算法求解性能,也对复杂车辆路径问题如何进行分解优化设计具有借鉴意义.后续研究将把EACO_CD 和随机处理技术结合,用于求解动态复杂车辆路径问题.
猜你喜欢
消防界(电子版)(2022年19期)2022-11-16
意林彩版(2022年1期)2022-05-03
成都信息工程大学学报(2021年6期)2021-02-12
读友·少年文学(清雅版)(2020年1期)2020-05-20
铁路通信信号工程技术(2020年4期)2020-04-28
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
科技视界(2018年11期)2018-07-31
领导决策信息(2017年9期)2017-05-04
岷峨诗稿(2017年4期)2017-04-20