
Rethinking the image feature biases exhibited by deepconvolutional neural network models in image recognition
2022-12-31 03:48DaweiDaiYutangLiYuqiWangHuananBaoGuoyinWang
Dawei Dai |Yutang Li|Yuqi Wang|Huanan Bao|Guoyin Wang
College of Computer Science and Technology,Chongqing University of Posts and Telecommunications,Chongqing,China
Abstract In recent years,convolutional neural networks(CNNs)have been applied successfully in many fields.However,these deep neural models are still considered as“black box”for most tasks.One of the fundamental issues underlying this problem is understanding which features are most influential in image recognition tasks and how CNNs process these features.It is widely believed that CNN models combine low‐level features to form complex shapes until the object can be readily classified,however,several recent studies have argued that texture features are more important than other features.In this paper,we assume that the importance of certain features varies depending on specific tasks,that is,specific tasks exhibit feature bias.We designed two classification tasks based on human intuition to train deep neural models to identify the anticipated biases.We designed experiments comprising many tasks to test these biases in the Res Net and Dense Net models.From the results,we conclude that(1)the combined effect of certain features is typically far more influential than any single feature;(2)in different tasks,neural models can perform different biases,that is,we can design a specific task to make a neural model biased towards a specific anticipated feature.
KEYWORDS CNNs,features,understandable models
1|INTRODUCTION
In recent years,following the breakthrough of convolutional neural network(CNN)models in the field of image processing,the application of CNNs has experienced explosive growth.CNN models have been deployed in a variety of applications,including automated vehicles,cancer detection,and recognition systems,reaching,and sometimes exceeding,the capabilities of human beings in many scenarios.Although CNN models perform impressively in many fields,only a few seemingly obscure model parameters and very high fitting evaluation results can be obtained.While developments in understanding the underlying mechanisms of such deep neural networks is expected to continue,the perception of current CNN models as“black box”structures persists.In fact,there is widespread concern regarding the application of deep CNN models,not only because the models themselves cannot provide sufficient information,but also because of the security issues involved.However,considering the challenges highlighted here,the usefulness and security of these artificial intelligence(AI)systems will be limited by our ability to understand and control them.
Deep neural network models are more difficult to understand or interpret than traditional approaches.Before CNN models were widely adopted,manner‐designed operators were the standard approach in computer vision,for which the operator processes and the treatment of low‐level features were well established.Examples of such methods include SIFT[1]and HOG[2].For small datasets,traditional algorithms incorporating suitable operators perform very well.By contrast,for large datasets,the performance of traditional methods,such as ImageNet[3],is often significantly worse than deep CNN models[4].The black‐box characteristics of neural network models reflect two sides of the same coin.How are CNN models able to achieve impressive performance for complex tasks?It is widely accepted that CNN models combine low‐level features to form increasingly complex shapes until the object can be readily classified;this term is referred to as‘shape hypothesis’.Some recent studies have suggested that image textures play a more important role than other features,that is,that image processing contains a‘texture bias’;however,a degree of controversy has arisen surrounding this issue.
Undeniably,texture and shape are both important features and play important roles in image recognition tasks[5,6].However,we consider which a neural model bias towards a particular feature depends on the nature of the task.Here,the‘task’refers specifically to a combination of input data.Taking image recognition as an example,the classification of categories A and B,and the classification of categories A and C are considered as two different‘tasks’(task1 and task2,respectively);category A is a common category shared by the two tasks,whereas we design the other categories carefully to ensure that the main distinguishing features for category A are different for each task.We perform extensive experiments using the standard architecture of the ResNet and DenseNet models for the designed tasks.From the experiments,we note that(1)feature diversity is a greater factor in image recognition tasks than any single feature by itself;(2)for the same object recognition,shape and texture information can be both be extremely important or inconsequential depending on the task;(3)shape can be more important than texture,and vice versa.Therefore,we propose that the so‐called bias towards certain features is an artifact of neural model performance for the particular task.
2|RELATED WORKS
2.1|Shape hypothesis
From the perspective of cognitive psychology,people are very sensitive to shape[7].Deep CNN models were widely considered to combine low‐level features layer by layer to construct shapes until the objects could be readily classified.As Kriegeskorte stated‘neural network model acquires complex knowledge about the kinds of shapes associated with each category’[8].This concept has also been expressed by LeCun:‘intermediate layers in a CNN model recognise parts of familiar objects and subsequent layers can detect objects as combinations of the parts’[9].
The shape hypothesis was also supported by a number of empirical findings.For example,tasks such as human detection[2]also use richer edge information,and some algorithms can extract object edges using richer convolutional features[10],thereby proving that CNNs have learnt to identify edge features.Visualization methods[11]often highlight the object parts in high layers of the CNN.Moreover,Kubilius et al.built CNN‐based models for human shape perception and noted that CNN learnt shape representations that reflected human shape perception implicitly[12].‘Shape bias’was also discovered in CNN models for image classification,that is,the shape features of an object can be more important than other features in object classification tasks[7,13–18].This was used to argue that shape plays a greater role in CNN models than other features.
2.2|Texture bias
Other studies have provided contrasting evidence that suggests that texture features are more important.This view originated with the bag‐of‐words(BOW)model[19],which focuses solely on local features and abandons the global image structure.In this method,local features such as textures are more effective than global features such as shape.Following the increasing application of deep CNN models to image processing tasks,several studies have noted that deep CNN models can perform well even if the image topology is disrupted[20],whereas standard CNN models,in which shapes are preserved yet texture cues are removed,perform worse for object sketch recognition[21].Other research has indicated that Imagenet‐trained CNN models are biased towards texture and that increasing shape bias improves the accuracy and robusticity of image processing tasks[22].Additionally,Gatys et al.[20]suggested that local information such as textures are sufficient to‘solve’ImageNet object recognition problems.Furthermore,using the style transfer algorithm,Robert et al.proved that texture features were more important for the ResNet‐50 model than other features[23].
2.3|Summary
Of course,numerous other features can be utilised in image recognition.In this paper,our discussion focuses on the influence of texture and shape on the image recognition task.However,research into which is more important for image recognition tasks has generated some controversy.Following careful analysis of the aforementioned related studies,we find that the evaluative measures used to form conclusions are often different for individual studies.In short,CNN models may exhibit bias towards shape in certain tasks but may be biased towards texture for other tasks.
For a specific task,in fact,its real knowledge or distribution exists,but it is unknown to us.CNNs provide a way to learn or approximate this knowledge.Therefore,we examine the extent to which a neural model exhibits bias towards a certain feature based on the specific task.We design particular tasks to guide the deep neural models bias towards specific features based on our predictions.The feasibility of this approach is verified experimentally,and the results imply that the so‐called bias towards shape or texture features is linked inextricably to the CNN model performance for specific tasks.
3|APPROACH
3.1|Measurement of feature importance
In an image recognition task,the importance of a certain type of feature can be measured by its impact on recognition accuracy.As a result,the key to the experiment is to measure the drop in accuracy that results when a specific feature is removed or constrained.The more the accuracy decreases when a feature is removed or weakened,the more important this feature is,thus revealing the extent to which a CNN model is biased towards the important features.Here,we use the feature contribution rate(FCR)to describe this process.As expressed in Equation(1),the accoterm indicates the classification accuracy of the original images,whereas accrm indicates the accuracy for images in which some specific features have been removed or weakened.Thus,the smaller the value of FCR,the more important the feature is,and vice versa:
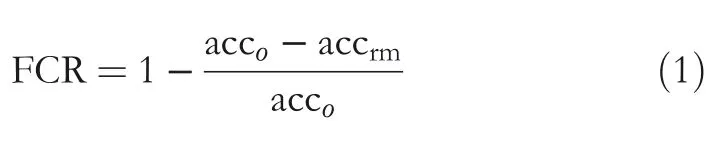
3.2|Removing(or weakening)certain features
The current debate focuses on which type of features exert a greater influence on CNN models,texture,shape,or others?Therefore,we have analysed the respective influence or importance of texture and shape in an image recognition task.Practically,it is difficult to remove a certain type of feature completely,in which case the relevant feature is suppressed rather than eliminated.
Colour removal.Colour originates from the superposition of different wavelengths of light.For RGB pictures,the colour feature is defined by the difference between R,G,and B channels.We used the brightness information of the image,which is the average of the R,G,and B channels,to replace the R,G,and B channels(see Figure 1b).
Texture weakening.Textures refer to the pixels of the picture that obey certain statistical properties.In the frequency domain,textures are usually concentrated in a certain frequency band.We used the MeanShiftFilter[24]method to remove texture information without destroying the edges.The resulting image is shown in Figure 1c.
Shape weakening.Shapes refer to a region that is described by some low‐level features.We weaken the shape by applying edge blurring.An edge extraction algorithm was first used to detect boundaries[25],then a Gaussian filter was used to blur the edges.The result is shown in Figure 1d.
Destroying topology.Topological features are very important for human identification.For example,a clock must have a dial and hands.Individually,the dial and hands are not considered to be a clock.To implement destruction of topology,we split the picture and shuffle the position of each piece,analogous to a Rubik's cube.
3.3|Designing the tasks
Task 1:Diverse Neural models are required to learn different knowledge for different tasks.First,we consider that a deep neural network model may exhibit bias towards a diversity of features depending on the nature of the task.For a specific task,the‘knowledge’was fixed;however,different models may learn this knowledge to differing degrees.As a result,we began by selecting several different tasks,with each task containing different‘knowledge’.Then,we trained several standard deep neural models via conventional methods and tested the influence of different features on different tasks.Last,we analysed the results.
Task 2:Importance of texture for the same object can be significantly different
The data‐driven learning of a neural model is designed so that the differences in an image recognition task are learnt.In this case,we designed a multi‐classification image recognition task,in which the distinctive features between each category are known.However,it is not easy to isolate a specific feature from others.Therefore,to simplify the task,we explored the importance of each category separately.We designed two subtasks(two datasets),where sub task1 contains category A,category B,and category C,...and sub task2 contains categories A,B1,and C1,....Both subtasks contain category A;in subtask1,only category A contains rich textures,whereas in subtask2,all categories contain rich textures.We explored the importance of the textures in category A for the two subtasks.Intuitively,we can hypothesise that the textures of category A should be more important in subtask1 than that in subtask2.
Task 3:Importance of shape for the same object can be significantly different
We adopted a similar design to task2.Again,we first designed two subtasks,each containing one common category,that is,category A.There were two governing conditions for this task:(1)in subtask1,the shape of the objects needed to be similar in all categories;(2)in subtask2,the shape of the objects belonging to category A needed to be obviously different from the objects belonging to the other categories.
Task 4:Texture(Shape)is more important than shape(Texture)
In this paper,we need to design tasks on the basis that a deep neural model learns the differences between categories in image recognition tasks.Therefore,we carefully designed a subtask1 consisting of categories(A,B,C,...),in which the objects in each category have a similar shape but their textures are obviously different.Conversely,we then designed subtask2,comprising categories(A,B1,C1,...),in which the object texture is similar across all categories but the object shapes are obviously different.Intuitively,if a neural network performs well for both subtasks,this would indicate a bias towards texture in subtask1 and shape in subtask2.

FIGURE 1 Images for which a certain feature has been removed or weakened:(a)original image;(b)image with the colours removed;(c)image with the texture weakened;(d)image with the shape edges weakened
3.4|Implementation
We choose four categories to design each specific task from ImageNet which contains 1000 categories.Each task(sub dataset)consisted of 1500 training images and 50 validation images.We resized all image sizes to[224,224]and the horizontal flip and image shift augmentation were in use.Thereafter,dividing images by 255 was done to provide them in range[0,1]as input.In addition,we selected to train several standard neural networks:VGG[26],ResNet[27](See Table 1),and DenseNet([Huang et al.,2017])(See Table 2)to explore feature biases.We used weight decay of 1e‐4 for all models,Adam for ResNet and momentum of 0.9 for Densenet,and adopted the weight initialisation and BN introduced by[27,28].We trained all models with a mini‐batch size of 32 or 64 on 2080Ti GPU.
4|EXPERIMENTS AND ANALYSES
4.1|Tendency of neural network model is diverse
We selected four types of features(colour,texture,edge,and image topology)to discuss their importance for deep neural networks in image recognition tasks.Additionally,we selected four models(VGG,ResNet,Inception,DenseNet)and trained them using the ImageNet dataset.Then,we randomly selected 100 classes from the training dataset and removed each feature type systematically to assess their individual contributions.Finally,we tested the performance of the neural models on these datasets.
The average performance of the 100‐classes datasets is shown in Figure 2.We note the following observations:(1)for a specific task,the importance of different features may be similar for different neural models;(2)in this task,texture and topology features were more important thancolour and edges.As shown in Figure 3,we tested the importance of four features in four categories,revealing that the most important feature of deep models was different foreach category,with each type of feature exerting a greater influence for different categories in different tasks.Consequently,we note that the observed biases were not unique to specific classes.Equipped with this information,we attempted to design a task in which deep neural models exhibit biases towards specific features based on our predictions.
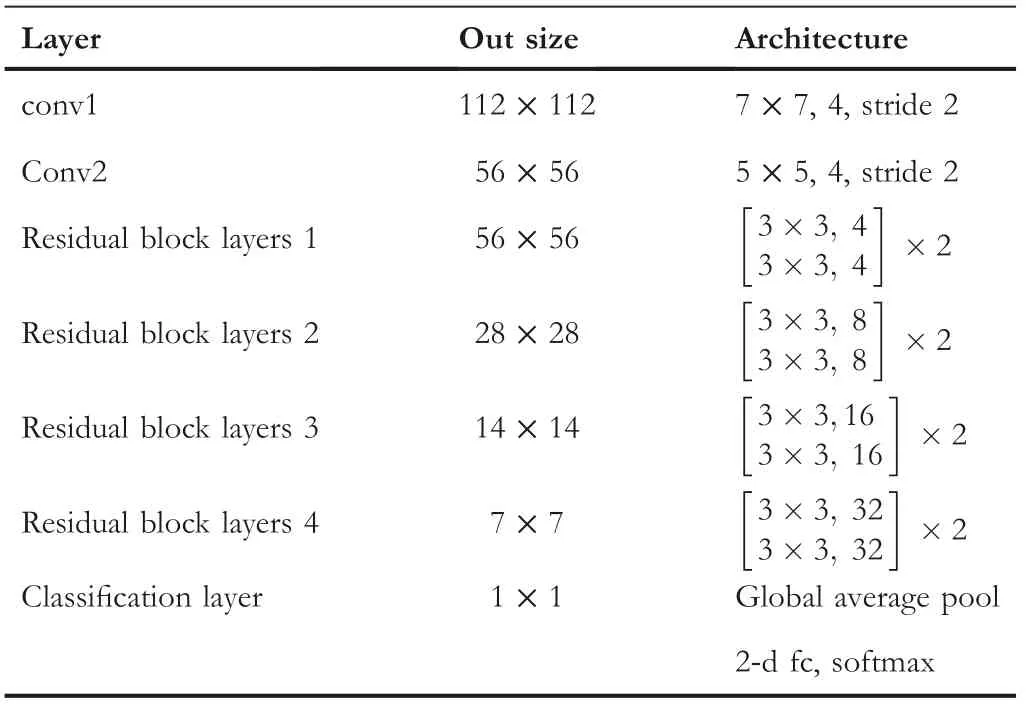
TABLE 1 Architecture for ResNet models
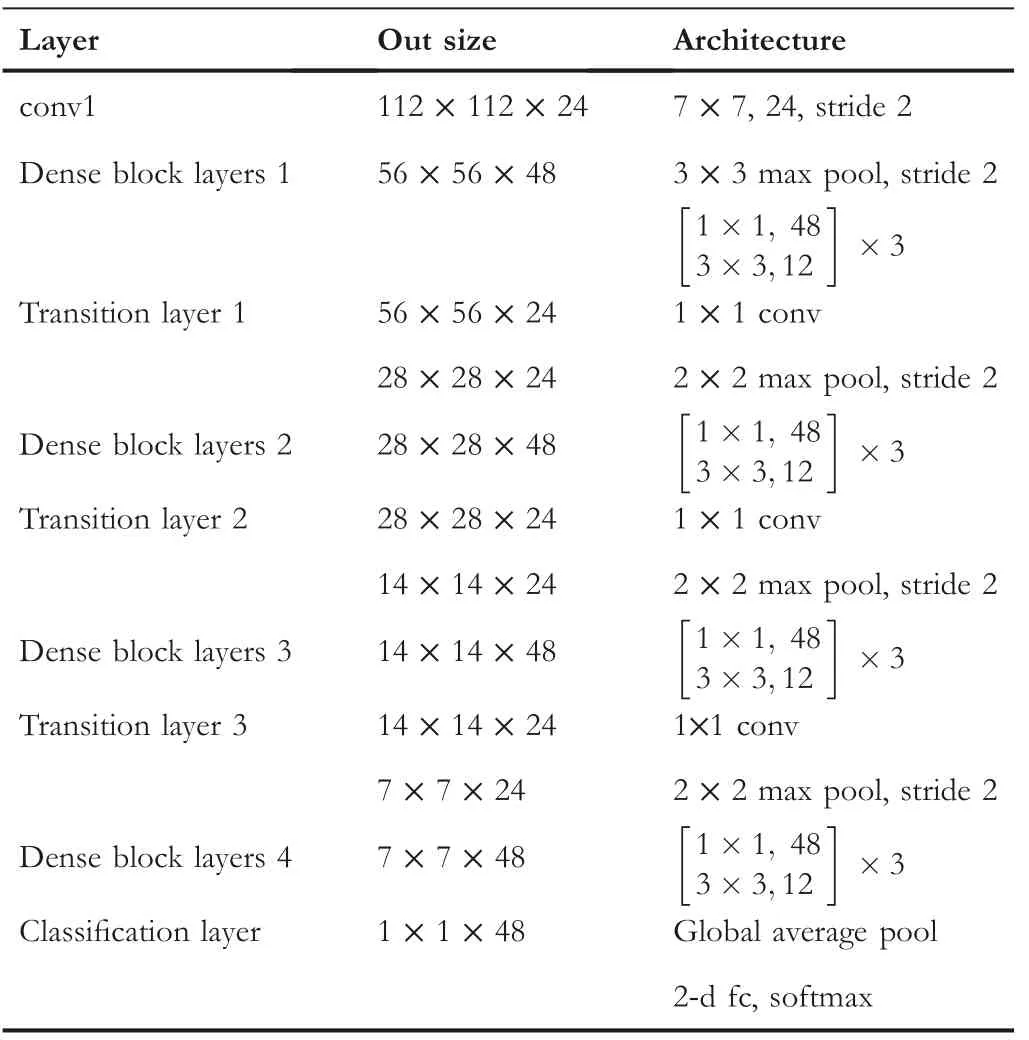
TABLE 2 Architecture for DenseNet models
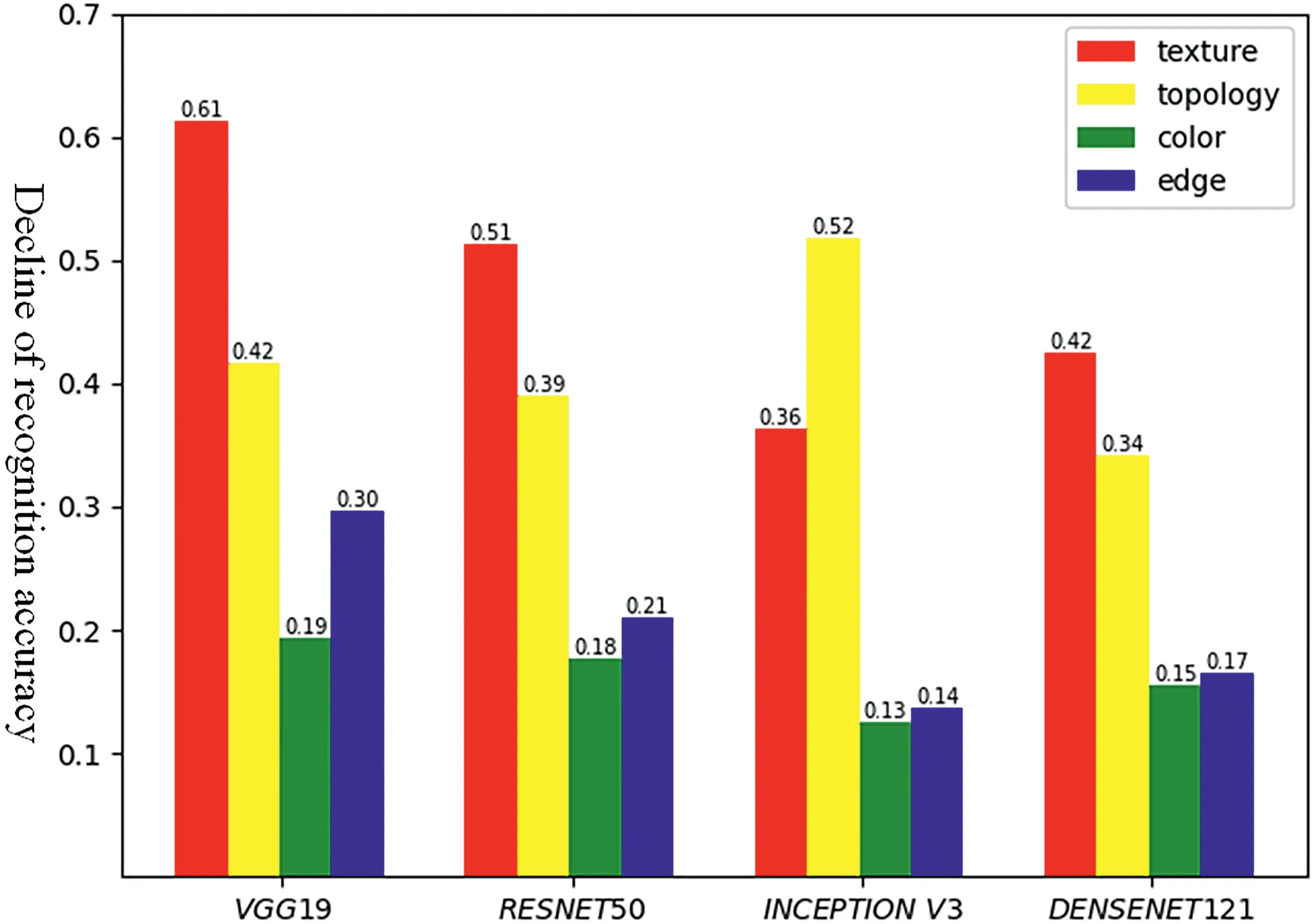
FIGURE 2 Contributions of the different feature types for different convolutional neural network(CNN)models
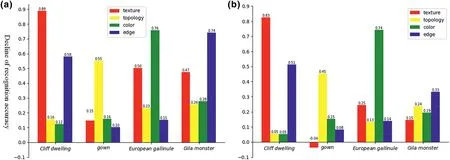
FIGURE 3 Contributions of the different feature types to selected categories for the(a)ResNet and(b)DenseNet
4.2|Texture importance analysis
A.Task design
We designed two tasks(see Figure 4),each containing four categories:task1:Pig,Cat,Dog,and Lion;task2:Pig,Hippopotamus,Walrus,and Sea Lion.For task1,all four animals are rich in hair,representing similarity with respect to their texture features,whereas for task2,only the category“pig”has abundant hair.Intuitively,in task1,it is not easy to identify the pig using only local texture features.By contrast,in task2,it is relatively easy to identify the“pig”by the local texture.Although,we cannot completely avoid the influence of other features,we just minimise their impact.We can analyse the importance of texture for the category“pig”via the two tasks,and thus verify whether the neural network model conforms to our intuition,as follows:
Step1 We trained several standard deep neural models,including the ResNet and DenseNet models,to perform task1 and task2.
Step2 We weakened the texture of the“pig”category in two tasks(see Figure 5).
Step3 We tested the performance of the deep neural models with the weakened texture“pig”category and analysed importance of texture for the“pig”category in different tasks.

FIGURE 4 Images used in the two tasks analysing the importance of texture.(a)Task 1:Pig,Cat,Dog,Lion;(b)Task 2:Pig,Hippopotamus,Walrus,Sea lion

FIGURE 5 Images illustrating the weakening of texture features.The texture becomes successively weaker from left to right in each row
B.Results
As shown in Figures 6 and 7 the recognition ability of both the ResNet and DenseNet models for the“pig”category with weakened texture in task2 decreased more than in task1.It should be noted that the texture of“pig”in task2 is much more important than in task1.In task2,texture features play an important role in both ResNet and DenseNet,whereas in task1,especially for the DenseNet model,the texture feature is less influential.Therefore,the importance of the same feature from the same category can differ significantly between the two tasks.
4.3|Shape importance analysis
A.Task design
As described in Section 4.2,two tasks were designed to analyse the importance of shape features,as shown in Figure 8:task1:fox,husky,wolf,golden retriever;task2:fox,rabbit,horse,bear For task1,all four animals have similar shapes,whereas in task2,the shape of the category“fox”was obviously different from the other three animals.As such,in task1,it is not easy to identify the fox based on shape features alone,whereas it is relatively easy to identify the fox using shape features in task2.We analysed the importance of the shape of category“fox”in each task as follows:

FIGURE 1 0 Shape importance in the(a)ResNet and(b)DenseNet models for each task

FIGURE 1 1 Images used in each task for the comparative analysis of shape and texture importance.(a)Task 1:Lion,Bear,Rabbit,Monkey;(b)Task 2:Lion,Cheetah,Tiger,Cat

FIGURE 1 2 Images illustrating the weakening applied to the lion category image with respect to(a)shape and(b)texture.The amount of weakening increases from left to right in each row of images

FIGURE 1 3 Comparison of shape and texture importance for the(a)ResNet and(b)DenseNet models for task1
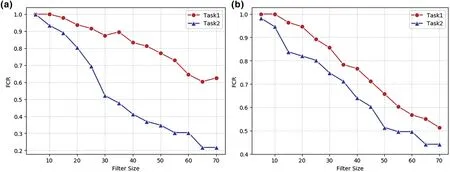
FIGURE 6 Texture importance in the Res Net model for each task.The horizontal axis represents the size of the filter window,which is positively correlated with weakening strength.(a)ResNet‐19;(b)ResNet‐51
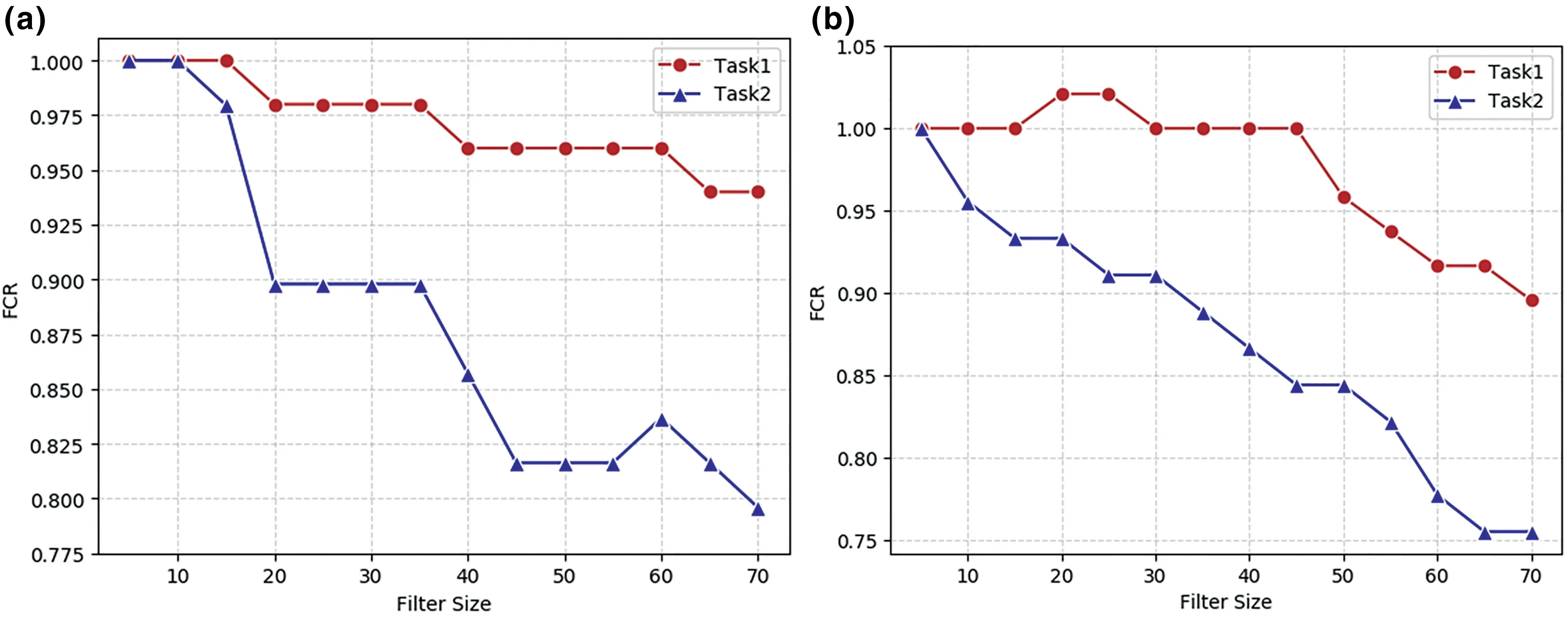
FIGURE 7 Texture importance in the Dense Net model for each task:(a)Without data augmentation;(b)With data augmentation

FIGURE 8 Images used in the two tasks for analysing the importance of shape.(a)Task 1:Fox,Husky,Wolf,Golden retriever;(b)Task 2:Fox,Rabbit,Horse,Bear

FIGURE 9 Images illustrating the weakening of shape features.The shape becomes successively weaker from left to right in each row
Step1 We trained several standard deep neural models to perform task1 and task2.
Step2 We weakened the shape of the“fox”category in each task(see Figure 9).
Step3 We tested the performance of the deep neural models with the weakened shape of the“fox”category,and analysed the importance of shape for the“fox”category in different tasks.
B.Results
As shown in Figure 10,the recognition ability of Res Net and Dense Net models with respect to the weakened shape of the category“fox”decreased more for task2 than for task1.It should be noted that the shape features of the“fox”category are far more important in task2 than in task1.
4.4|Which is more important,texture or shape?
A.Task design
As shown in Figure 11,we designed two further tasks:task1:lion,bear,rabbit,monkey;task2:lion,cheetah,tiger,cat.In task1,the shape features are significantly different between the lion and the other three animals,whereas in task 2,the texture features represent the primary differentiator between the lion and the other categories.We consider deep models to learn these differences exactly so that the model can apply to the image recognition tasks.We evaluate and compare the respective importance of texture and shape,as follows:

FIGURE 1 4 Applying increasing degrees of contour weakening to the original image(a)leads to the emergence of an increasing number of new edges
Step1 We trained several standard deep neural models to perform task1 and task2.
Step2 We obtained two groups of modified data:one in which the shape features of“lion”were weakened compared to the original image,and one in which the texture features of“lion”were weakened relative to the original image.The corresponding images are presented in Figure 12.
Step3 We tested the performance of the deep neural models on modified category“lion”,to determine which is more important,shape or texture.
B.Results
The results of the comparative analysis are illustrated in Figure 13.In task1,shape information is clearly more important than texture when considering slightly weakened edge for image recognition performed by both the Res Net and Dense Net models.Conversely,when the edge is heavily weakened,the reverse behaviour can be observed.Ultimately,it is extremely challenging to remove the shape of an object completely via edge weakening;weakening the outline of the object only creates new edges,as shown in Figure 14.This explains the initial decrease in performing the models,with the trend reversing as the filter size increases(blue lines in Figure 13).As shown in Figure 15,for task2,we can conclude that the texture information contributes more than the shape information.
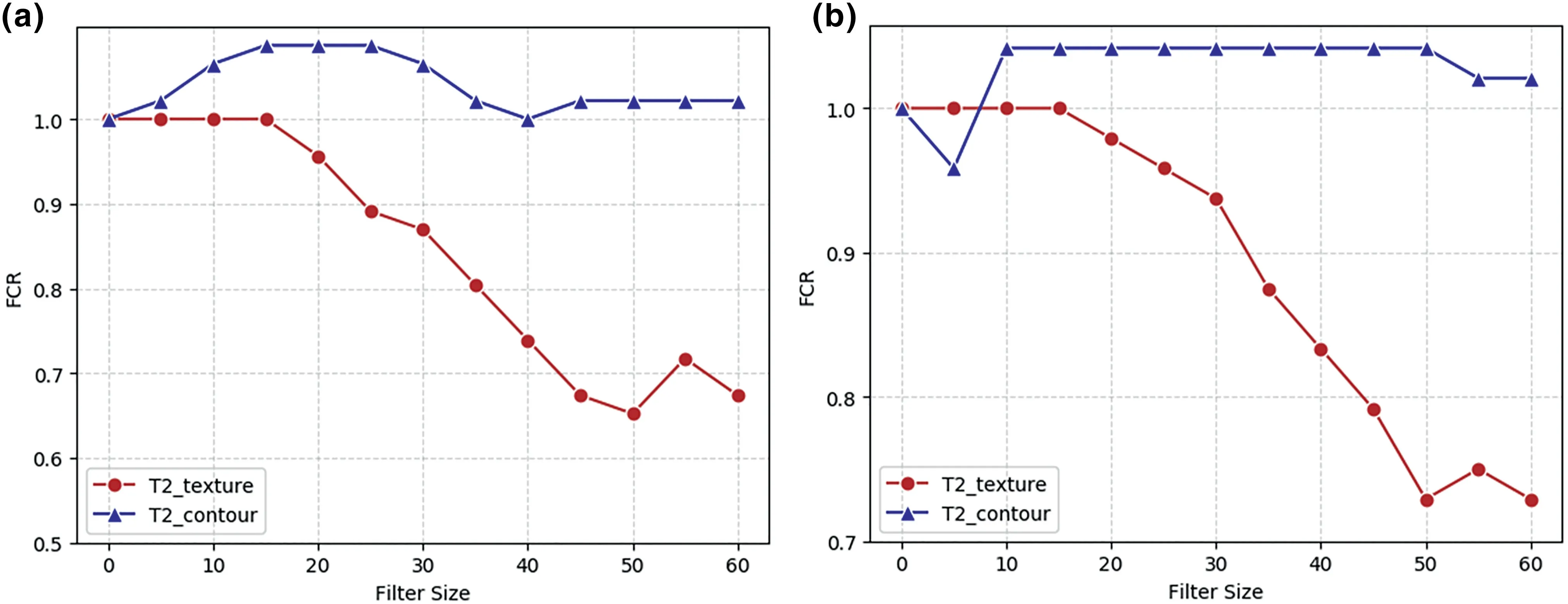
FIGURE 1 5 Comparison of shape and texture importance for the(a)ResNet and(b)DenseNet models for task2
5|CONCLUSION
Although CNNs have been applied successfully to a variety of AI systems,deep neural models are regarded as“black boxes”in many tasks.This perception arises from the fact that the influence of features in image recognition tasks remains largely unknown.It has been posited that CNN models combine low‐level features to form complex shapes until the object can be readily classified;however,recent contrasting studies have claimed that texture features are the real key to effective image recognition.
We propose that these reported biases are task specific,as clear image feature bias disparities can be observed for different tasks.In our experiments,which consider the same“object”in different tasks,many outcomes are possible;for example,texture(shape)can play an important role but,equally,can also be insignificant.In certain cases,texture features are more important than shape features and vice versa.Therefore,such biases can be designed manually,and we can design a particular task to create a deep neural model bias towards a specific type of feature that we consider vitally important to a particular task.
ACKNOWLEDGEMENT
This work was sponsored by the Natural Science Foundation of Chongqing(No.cstc2019jcyj‐msxmX0380),China Postdoctoral Science Foundation(2021M700562)and Natural Science Foundation of China project(No.61936001).
CONFLICT OF INTEREST
We declare that we have no financial and personal relationships with other people or organisations that can inappropriately influence our work,there is no professional or other personal interest of any nature or kind in any product,service and/or company that could be construed as influencing the position presented in,or the review of,the manuscript entitled.
DATA AVAILABILITY STATEMENT
The data that support the findings of this study are openly available at[https://image‐net.org/].
ORCID
Dawei Daihttps://orcid.org/0000-0002-8431-4431
 CAAI Transactions on Intelligence Technology2022年4期
CAAI Transactions on Intelligence Technology2022年4期
- CAAI Transactions on Intelligence Technology的其它文章
- Modelling of a shape memory alloy actuator for feedforward hysteresis compensator considering load fluctuation
- Apple grading method based on neural network with ordered partitions and evidential ensemble learning
- An improved bearing fault detection strategy based on artificial bee colony algorithm
- Parameter optimization of control system design for uncertain wireless power transfer systems using modified genetic algorithm
- Passive robust control for uncertain Hamiltonian systems by using operator theory
- Humanoid control of lower limb exoskeleton robot based on human gait data with sliding mode neural network