
基于ScoreCAM的X光安检违禁品检测
2022-12-30 07:51张海刚汤圣涛孙红星杨金锋
计算机工程与设计 2022年12期
赵 晴,张海刚,汤圣涛,毛 亮,孙红星,杨金锋
(1.深圳职业技术学院 粤港澳大湾区人工智能应用技术研究院,广东 深圳 518055;2.辽宁科技大学 电子与信息工程学院,辽宁 鞍山 114051;3.杭州市特种设备检测研究院 电梯检验一所,浙江 杭州 310051)
0 引 言
X光的透射成像模式会将待测物体从3D空间“压缩”到2D空间,并且成像颜色单调,差异较小,而日常行李中的物品多杂乱无序,经X光的透射,目标间形成遮挡,不利于目标检测。同时物品大小形状各异,姿态复杂多样,尺度间的差异容易导致检测模型忽略小尺寸目标,严重影响违禁物品识别的可靠程度。
张友康等[1]改进SSD算法,提出非对称卷积多视野神经网络,提高了复杂背景下的多尺度违禁品目标检测精度。郭守向等[2]结合复合骨干网络思想,改进Yolo[3-6]算法,构建了Yolo-C目标检测网络,加入特征增强模块,融合级联后特征图的特征,提高了违禁品目标识别精度。康佳楠等[7]改进Faster R-CNN,采用多层特征提取和多通道区域建议,融合图像深层和浅层的特征信息,使图像特征更全面,违禁品检测精度更高。姚少卿等[8]使用轻量化分割网络,设计空洞卷积和非对称卷积模块,违禁品识别精度和速度都得到了提高。苏志刚等[9]加入空间金字塔卷积[10,11],引入注意力机制监督特征提取过程,在U-Net模型基础上使用逐级上采样操作,完成了多目标违禁品识别任务。他们通常用候选框的方式来显示检测结果,需要大量的标注数据进行训练,属于强监督方法。弱监督方法通过建立模型,依靠图像类别标注信息学习类别间的共性,可以避免人工标注X光安检图像时可能引入的不精确甚至是错误标注。
本文提出了适合X光安检图像违禁品检测的网络模型,改进ResNet50网络,以弱监督算法ScoreCAM(Score-Weighted CAM)[12]为基础,完成违禁品定位并实现可视化。设想了4种添加可变形卷积模型的形式,扩大感受野后,在全局视野下捕捉小目标,调整卷积核的形态,预测被遮挡的违禁品特征,能有效应对X光安检图像中目标多姿态变化、遮挡和小目标漏检的技术难题,提高违禁品检出率。
1 安检违禁品检测模型
本文提出适合X光安检违禁品图像检测的模型框架,如图1所示,改进的ResNet50模型结构如图2所示。训练阶段将分好类的图片送入弱监督网络模型,加入可变形卷积模块,进行多分类预测,得到分类权重。测试阶段将训练好的权重送入弱监督网络模型,使用ScoreCAM算法,针对安检违禁品存在的多姿态、小目标问题,在弱监督网络模型加入可变形卷积模块、空洞卷积模块,便可完成多分类、目标定位、目标检测任务。上述框架实现的关键所在是如何使模型生高质量的类别热力图。
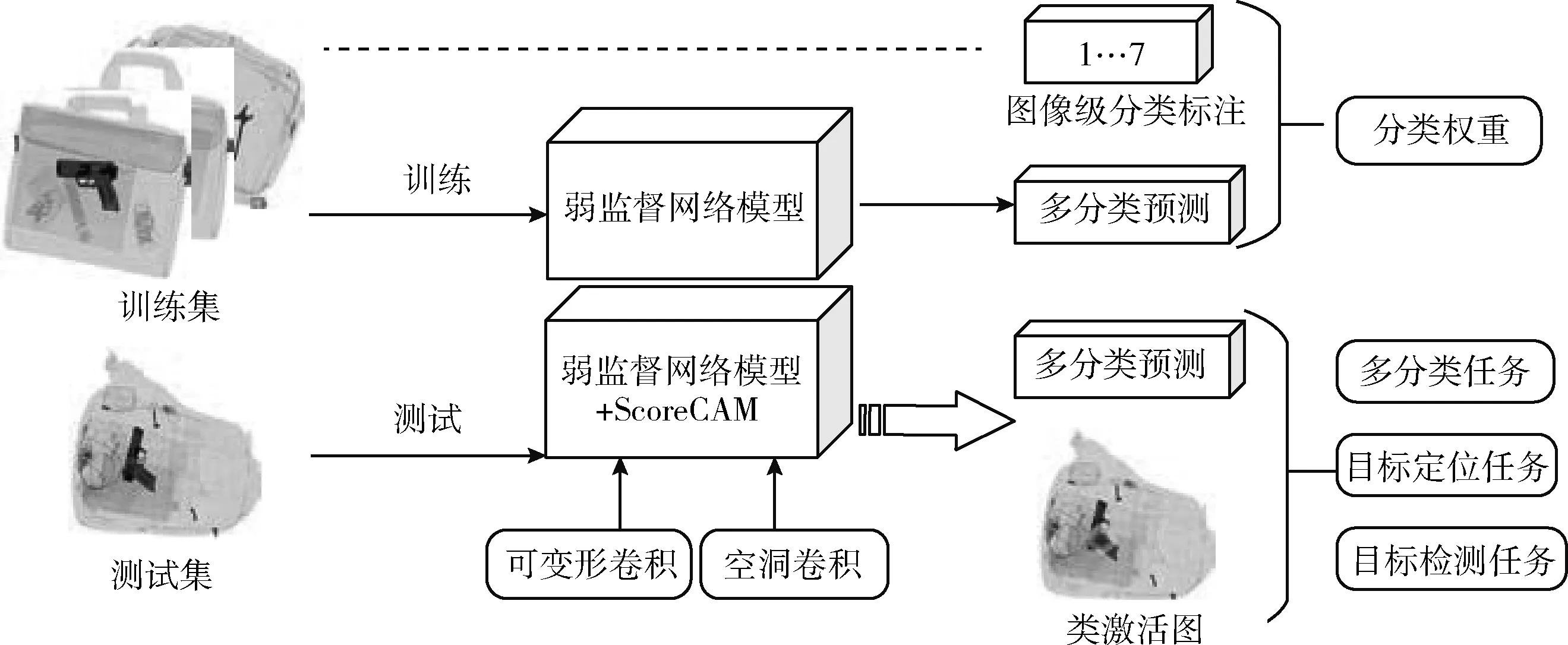
图1 X光安检违禁品模型

图2 改进ResNet50模型
模型的主干网络采用ResNet50,它在深度神经网络中增加了残差模块,通过学习多个网络层输入、输出之间的残差,保证了输入信息的完整性。残差网络结构即使面对网络层数不断加深,也能在一定程度上减小网络的过拟合程度和计算量,同时保证网络的特征提取能力。ResNet50基础模型分别用1×1,3×3,1×1的卷积堆叠,为了提高对目标的检测效果,在模型中加入了可变形卷积和空洞卷积,重点关注3×3的卷积,并设计了4种可变形卷积结构。
1.1 ScoreCAM
卷积神经网络(convolutional neural network,CNN)具有优秀的图像语义信息提取能力,图像中各目标的位置、轮廓等信息是完整包含在图像本身之中的,对CNN目标特征进行可视化,可以使本来只能用于分类的CNN具有目标检测能力。CNN一般由特征提取器与分类器组成,特征提取器负责提取图像特征,分类器依据特征提取器提取的特征进行分类,CNN深层特征图富含高度抽象的类别特征,ScoreCAM基于深层特征图进行可视化来解释CNN模型。ScoreCAM采取特征融合权重与特征图线性加权融合的方式生成类激活映射图,考虑到梯度的不稳定性,在线性权重的设计中增加了置信度,不再和GradCAM(Gradient-weighted CAM)[13]一样依赖梯度,权重设置更加合理,对安检违禁品的定位效果进一步得到提升。

(1)
其中
(2)

此过程将最后一层特征图的各个通道看成一种特殊掩码,进行上采样操作,再与输入图像逐像素相乘,在CNN中预测相应通道的类别重要程度。
ScoreCAM的类别激活图计算方式如下
(3)
其中
(4)

ScoreCAM的流程如图3所示,阶段一主要对特征图进行提取,提取到的特征图进行逐通道遍历,针对每层的特征图使用上采样和归一化操作,阶段二把前一阶段的通道作为掩码,与输入图像逐像素相乘,在CNN中得到各类别对应的响应值CIC,并将CIC作为特征融合权重。阶段三将阶段一所提取的特征图与CIC线性加权求和,得到最终可视化的结果。

图3 ScoreCAM流程
在安检违禁品检测中,利用ScoreCAM的类别判别能力定位出违禁品区域,实现可视化,给出解释的同时标注出违禁品位置。
1.2 可变形空洞卷积模块
卷积神经网络中卷积核的几何结构一般都是固定的矩形,针对几何变换方面的建模能力是有限的。在实际安检情境中,同种类的违禁品可能会存在不同的形态、大小以及视角等的变化,传统的卷积无法较好处理这些问题,很可能造成漏检,从而带来巨大的安全隐患。
可变形卷积[14]的卷积核在每一个元素上额外增加了一个方向参数,这样卷积核就能在训练过程中扩展到很大的范围。可变形卷积概括了多种尺度、长宽比和旋转的各种变换,可变形卷积采样位置如图4所示。在X光安检中运用可变形卷积,卷积核的形状可以更接近违禁品特征。

图4 可变形卷积采样位置
为进一步加强可变形卷积对几何变换学习的能力,能够学习各种不同形态、尺寸的违禁品特征,加入了调制机制,可变形卷积v2[15]不仅能对输入进行偏移,还可以调整各位置输入的权重。给定一个有K个采样位置的卷积核,wk和pk分别表示第k个位置的权重和预先设定好的偏移,令x(p) 和y(p) 分别表示输入特征图x和输出特征图y中位置p的特征,可调节的可变形卷积可以定义为
(5)
式中: Δpk和Δmk是第k个位置上的可学习的偏移和调节参数,调节参数Δmk∈[0,1], Δpk为任意值。可变形卷积v2不仅学习了偏移还学习了采样点的权重。
空洞卷积引入膨胀率参数,用来定义卷积核之间的间距,设置不同的膨胀率,得到不同的感受野,空洞卷积以低成本增加输出单元上的感受野,同时还不需要增加卷积核大小,当多个空洞卷积一个接一个堆叠在一起时,这种方式是非常有效的。
在X光安检具体情况中,违禁品常常随机分布在图像的任意位置,并且存在尺寸很小的情况,想要将小目标检测出来,有一定的难度。为解决这个问题,在空洞卷积的基础上再对卷积进行可变形操作,一方面卷积核的形状更加贴近目标违禁品特征,另一方面扩大了感受野,拥有更加丰富的语义信息,融合后不仅能学习到整体轮廓,对细节部分也能获取更多信息,增加了小目标违禁品的检出率。
对在何处增加可变形卷积模型,本文设想了4种形式,并进行了实验对比,卷积不同的修改位置如图5所示。第一种形式是把ResNet50的Layer2至Layer4的conv2中3×3普通卷积都换成了可变形卷积,更多的可变形卷积可以更好学习目标多姿态形态,但同时也带来了更大的计算量。第二种形式仅将ResNet50的Layer4的conv2中3×3普通卷积换成了可变形卷积,将最后最关键的输出层改为可变形卷积,能获取最关键的语义信息,同时对原有网络结构改动少,较好保留了原网络的优点,运算速度也大大优于第一种形式。第三种形式将ResNet50的Layer4的conv2中3×3普通卷积换成了空洞卷积,扩大了感受野,运算速度最快,接近第二种形式。第四种形式将ResNet50的Layer4的conv2中3×3普通卷积换成了可变形空洞卷积,卷积核贴近目标违禁品特征基础上进行膨胀,输出层尺度小,拥有感受野大,语义信息丰富,对原网络改动不大,运算速度也优于第一种形式。

图5 卷积不同的修改位置
2 实 验
2.1 实验环境和数据集
实验所用工作站配置了NVIDIA GeForce RTX 2070 GPU显卡,Intel(R) Core(TM) i7-9700 CPU @ 3.00 GHz,内存16 G,操作系统是Windows 10,使用pytorch深度学习框架和python语言编写程序。
本文采集图像所使用的安检机可以将32 mm的钢板穿透,单根实心铜芯的分辨能力是0.08 mm,成像方式是双能伪着色成像。为更全面模拟真实的X光安检情况,在各个采集阶段,违禁品和包裹的摆放位置进行了水平旋转和翻转,进行多次采集。包裹背景分为有背景填充、无背景填充,填充物包括USB数据线、耳机、书本、塑料瓶等常见物品。由于神经网络需要大量数据进行训练,为保证数据集的数量充足并具有多样性,本文所用的安检图像数据集经数据增强后共有23 250张安检违禁品图片,分为7类,有充电宝、叉子、仿真手枪、水果刀、打火机、钳子、剪子,具体数据见表1。这7类违禁品的X光图像涵盖了常见的违禁品图像基本特征,水果刀、仿真手枪和钳子属于金属类,打火机、充电宝属于混合物类,叉子、剪刀属于小目标类。数据集样本如图6所示。

表1 X光安检违禁品数据集

图6 数据集样本
2.2 评价指标
由于使用弱监督方法,并没有对数据用候选框进行标注。但为了对结果进行定量比较,本文做了补充实验。
为了更合理体现弱监督算法的有效性,首先将测试图片中的违禁品目标进行像素级别的语义分割,然后将弱监督算法生成的热力图转为掩模图像,再将掩模图像转为二值图像,进行归一化,最后使用语义分割准确性评价指标对实验结果进行评价,评估过程如图7所示。

图7 评估过程
实验为了评估X光安检违禁品检测的准确性和检测速度,采用以下5个评价指标:像素准确率(pixel accuracy,PA)、平均像素准确率(mean pixel accuracy,MPA)、平均交并比(mean intersection over union,MIoU)、F1分数(F1 score,F1)、频权交并比(frequency weighted intersection over union,FWloU)。
在语义分割中,准确率又称为像素准确率,定义为预测类别正确的像素数占总像素数的比例。计算方式如下
(6)
平均像素准确率分别计算每个类被正确分类像素数的比例,计算方式如下
(7)
平均交并比定义为模型对每一类预测的结果和真实值的交集与并集的比值,求和再平均的结果。计算方式如下
(8)
F1分数是衡量模型精确度的一种指标,又被称为平衡F分数(balanced score),定义为精确率和召回率的调和平均数。计算方式如下
(9)
频权交并比是根据每一类出现的频率设置权重,权重乘以每一类的IoU并进行求和。计算方式如下
(10)
式中:TP(true positive)是预测正确的正样本,FP(false positive)是预测错误的正样本,TN(true negative)是预测正确的负样本,FP(false positive)是预测错误的负样本,n是类别数。
2.3 对比实验
本文将ResNet-50作为基本框架,原网络最后一层全连接层的输入个数为2048,本文实验所用数据集共有7类,在用预训练的ResNet50模型进行迁移训练时,我们需要对网络的最后一层进行替换,替换成我们想要的输出分类数目7。在ImageNet大规模数据集训练好的深度学习模型上引入微调(Fine-tune)技术,在训练阶段加入了可变形卷积,具体是将原网络中layer4中每个bottleneck中conv2里3×3的卷积换为可变形卷积。为避免训练时梯度下降算法陷入局部最小值,使用余弦退火学习率,通过突然提高学习率,来“跳出”局部最小值并找到通向全局最小值的路径,加速模型的收敛,即使后期下降使得loss变小,也能较好地稳步靠近局部最优点。在神经网络做分类问题时,使用交叉熵作为损失函数。

图8 训练结果
测试阶段在弱监督网络模型中使用ScoreCAM算法,加入可变形空洞卷积,使用训练中第90个epoch得到的权重作为验证阶段网络的权重,最终得到验证结果。
为了选出更好的特征提取网络,我们在常用的Resnet网络和Vgg网络做了对比实验,均采用ScoreCAM算法和训练中第90个epoch对应的权重,实验结果如图9和表2所示。从图9可以观察到,除了Vgg19的结果没有被准确检测,其它的都被检测到了,Resnet18和Resnet34的结果中,热力图覆盖了过多无关区域,Resnet50的结果对违禁品目标覆盖较为全面且无关区域较少,Resnet101的结果中热力图覆盖违禁品的区域不如Resnet50准确,并且Resnet101网络层数多,训练成本较大。

图9 不同的特征提取网络比较实验
从表2的删除和插入实验中发现,Resnet50的插入值最大,删除值低至1.76,仅次于Resnet101,可以得到和图9一致的结论。综合比较后,Resnet50网络层数适中,违禁品检测和定位效果佳,于是本文选用Resnet50作为特征提取网络,结合弱监督方法模型实现违禁品的检测和定位。

表2 不同的特征提取网络删除和插入实验
为了验证ScoreCAM算法在X光安检违禁品检测中的有效性,本文将ScoreCAM算法与常用的GradCAM算法做了实验比较,均采用Resnet50特征提取网络和训练中第90个epoch对应的权重,结果如图10所示。GradCAM检测和定位效果不如ScoreCAM,ScoreCAM的插入值高于GradCAM,删除值低于GradCAM,因此ScoreCAM的结果优于GradCAM。

图10 ScoreCAM结果对照实验
为了验证所改进方法的有效性,我们进行了诸多比较实验,使用ScoreCAM算法,在弱监督网络模型中不同的层分别加入可变形卷积、空洞卷积以及可变形空洞卷积,测试了小目标类违禁品,卷积不同修改位置实验结果如图11所示,定量结果如表3所示。
从图11中可以发现,GradCAM定位不准,没有获取目标所在热力图,造成了漏检,ScoreCAM的结果成功检测并覆盖了目标物体,覆盖目标面积相比GradCAM扩大了很多。在ScoreCAM中加入DCN Layer2-4后,目标物体覆盖面积进一步加大,但无关区域覆盖过多,改用DCN Layer4后,无关区域覆盖面积有所减少。在ScoreCAM改用DCN Layer4后再加入空洞卷积,形成的结果图显示热力图几乎完全包围了目标物体,而且无关区域已经所剩无几,取得了很好的效果,ScoreCAM+DCN Layer4+dilation4效果最佳,通过上述比较,可以得出ScoreCAM算法结合可变形空洞卷积在安检违禁品检测上可以在一定程度上解决小目标漏检以及定位不准问题,可显著提高小目标检测能力和定位能力。

图11 小目标对比实验
从表3中可以进一步发现,总体来说随着可变形卷积和空洞卷积的增加,各项数值均有提升,上文图5设想的第一种形式把ResNet50的Layer2至Layer4的conv2中3×3普通卷积都换成了可变形卷积,过多的可变形卷积增加了模型的复杂度,带来了更大的计算量,实验结果也并不使人满意。第二种形式将ResNet50的Layer4的conv2中3×3普通卷积换成了可变形卷积,PA提升了1.2%,MIoU提升了0.4%,说明适当增加可变形卷积可以提高小目标检测率。第三种形式将ResNet50的Layer4的conv2中3×3普通卷积换成了空洞卷积,实验结果大幅提升,说明增加空洞卷积可以提高小目标检测率。第四种形式将ResNet50的Layer4的conv2中3×3普通卷积换成了可变形空洞卷积,设置了不同的膨胀值,实验结果进一步提升。dilation为4时,较第二种形式PA提升了3.3%,MPA提升了8.3%,MIoU提升了5%,F1提升了6.5%,FWIoU提升了3.3%。dilation设置更大时实验结果图和实验数据改进很小,结合表3以及模型复杂度比较,最终发现ScoreCAM+DCN Layer4+dilation4最为合适,由此也可验证可变形空洞卷积有效提高了违禁品目标的定位能力和小目标检测能力。

表3 卷积修改结果对比/%
图12以及表4显示了大目标对比实验的结果,通过对比发现ScoreCAM+DCN Layer4+dilation4比ScoreCAM的MPA提升了15.8%,MIoU提升了8.3%,F1提升了8.7%,FWIoU提升了0.6%,大幅提升的实验数据说明ScoreCAM算法结合可变形空洞卷积在安检违禁品检测上不仅可以在一定程度上解决小目标漏检以及定位不准问题,也可以提高了较大目标的检测能力和定位能力,进一步说明了本文算法的有效性。

表4 大目标卷积修改结果对比/%

图12 大目标对比实验
为了验证可变形空洞卷积模块在别的特征提取网络以及弱监督算法中依旧有效,本文做了相关对比实验。在表5中,均采用ScoreCAM算法和训练中第90个epoch对应的权重,使用不同的特征提取网络进行实验,实验发现ResNet50的删除和插入值优于ResNet101和ResNet152,在加入了DCN Layer4+dilation4后,ResNet101和ResNet152的检测效果也得到了相应的提升,但ResNet50+DCN Layer4+dilation4的删除和插入值依旧最佳,插入值高于其它网络,删除值在所有网络中最低,违禁品目标的检测和定位效果均得到了一定程度的提升,综合比较,ResNet50+DCN Layer4+dilation4的效果最佳,验证了可变形空洞卷积模块的有效性。在表6中,均采用ResNet50和训练中第90个epoch对应的权重,使用不同的弱监督算法进行实验,在加入DCN Layer4+dilation4后,不同的弱监督算法的删除值均有所降低,违禁品目标的检测和定位效果也更好。实验结果表明,可变形空洞卷积模块在别的特征提取网络以及弱监督算法中依旧有效。

表5 不同特征提取网络中验证可变形空洞卷积

表6 不同的弱监督算法中验证可变形空洞卷积
3 结束语
本文提出了一种弱监督机制下的X光安检图像违禁品检测模型,改进ResNet50,在ScoreCAM算法中融合可变形空洞卷积模块,避免了人工标注,能有效应对多姿态、遮挡和小目标漏检的技术难题。算法有效改善了检测性能,但同时速度也有所下降,随着网络的增大,GPU占用率也有所增加。现实生活中旅客行李杂乱,违禁品种类数量繁多,形态各异,模型在解决这个问题上还不成熟,因此下一步工作是改进模型解决多目标违禁品检测漏检、遮挡的问题,来进一步提高违禁品检测准确率。
猜你喜欢
今日农业(2021年11期)2021-11-27
北京航空航天大学学报(2021年9期)2021-11-02
学生天地(2020年18期)2020-08-25
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
职工法律天地·上半月(2018年3期)2018-04-22
北京航空航天大学学报(2018年1期)2018-04-20
故事作文·高年级(2017年2期)2017-03-01
视野(2009年7期)2009-05-22
消费导刊(2009年8期)2009-05-22
