
基于深度学习的板栗分级方法研究
2022-12-30 09:33王培福孙一丹鹿子涵陈晓峰
湖北农业科学 2022年21期
王培福,孙一丹,鹿子涵,王 伟,陈晓峰
(中国农业大学烟台研究院,烟台 264670)
中国是世界板栗第一大生产国与出口国,但在生产、贮藏、加工、品质检测等方面存在很多问题。板栗品质分类分级的繁杂性导致中国板栗标准化程度偏低,产品均一性较差,这限制了板栗产业在对外贸易上的发展,使得中国板栗在国际市场上售价较低[1]。
当前中国板栗分级大多依靠机器与人工,存在生产效率低、分类精确度低、人工成本高等缺点。因此,解决板栗的分级分类问题,有利于提高出口板栗品质,以增强其在国际市场的竞争力,从而促进中国板栗产业的发展。目前,对于板栗品质检测与分级的研究仍不完善,方建军等[2]利用机器视觉技术,通过采集板栗的最大长径等特征,利用神经网络分类器对板栗进行操作分级。刘洁等[3]基于近红外光谱分析技术,实现了对栗仁以及带壳板栗含水量的检测。周竹等[4]利用主成分分析法和近红外光谱技术,并结合反向传播(Back propagation,BP)神经网络,分别建立了相应的6种模型,实现了对板栗内部和表面霉变的检测。展慧等[5,6]为对板栗进行缺陷检测,将机器视觉的多源信息与近红外光谱相融合,通过建立BP神经网络提取板栗自身特征,并进行分级。值得指出的是,上述研究中所使用的传统机器学习方法通常需要人为选定特征并提取,过程较繁杂且存在准确率不高的问题。
深度学习是机器学习的一个重要分支,其工作方式为,在大量数据训练后自动提取并不断优化目标特征,有识别准确率高的优点。1994年,Lecun等[7]提出了第一个成熟的卷积神经网络架构(Convolutional neural network,CNN)LeNet-5模型,该模型在解决各类支票上的书写数字识别问题上取得了优异的成绩;之后,一系列有着更深网络结构和更高识别准确率的网络模型被相继提出。
由于近几年来计算机硬件的迅速发展与价格的不断降低,算力实现了突飞猛进,这让大规模数据处理成为可能,因此深度学习在国内外被广泛应用于农产品生产加工等[8-11]方面。CNN迅速发展,各种高精度、高效率的模型被广泛应用于农产品检测领域,倪建功等[12]利用改进型AlexNet对花生荚果品种进行识别,最高准确率达88.76%。岳有军等[13]对VGG网络进行改进并将改进后网络应用于病虫害的识别,其识别准确率较高,同时网络的鲁棒性和抗干扰能力较强。苏宝峰等[14]基于融合注意力机制的残差网络ResNet50-SE,对自然背景下不同生长时期的葡萄品种进行分类鉴别,通过迁移学习,实现基于不同时期下葡萄的嫩梢、幼叶及成熟叶片特征的识别。本研究将对基于CNN架构的Lenet-5模型进行改进,使其可以更加高效准确地对板栗进行分类分级,该改进模型可用于板栗分级加工,并为开发智能化板栗分级系统及设备提供依据。
1 材料与方法
1.1 试验材料
选用2021年秋季收获于河北省迁西县的板栗作为试验材料,根据国家标准[15]以及实际生产所需,结合实际生产,将其分为特级果(563个)、一级果(670个)、二级果(675个)以及缺陷果(489个,包括霉烂果、虫蛀果、裂嘴果等)4类,共2 397个。
试验所用计算机详细配置如下:Windows10,Intel Core i5-8300H CPU@2.30 GHz,NVIDIA GeForce GTX 1050 with Max-Q 4、16 G内存,环境配置为Anaconda3+pytorch+pycharm+python3.8+Cuda11.1+cudnn8.05,试验中使用GPU加速训练。
1.2 板栗图像采集
试验用工业相机为蓝天科技公司产,型号为LT-USB 8MP,尺寸为50 mm×50 mm×50 mm,摄像头为Sony IMX179。采集时调整镜头分辨率为2 592×1 944。将相机固定在试验支架上,固定拍摄距离为13 cm,通过USB数据线将工业相机连接到电脑上,使用功率为16 W、色温为6 500 K的光源进行补光。板栗图像采集具体方法为模拟工厂加工环境,将各等级板栗单粒通过图像采集区域,利用工业相机进行拍摄采集,并通过数据线传输到电脑进行保存。
1.3 数据集构建
CNN网络需要大量数据训练才能实现较高的准确率及较好的泛化能力,通过拍摄获得特级果图像563张,一级果图像670张,二级果图像675张,缺陷果图像489张,共计2 397张,为提高准确率以及增强网络的泛化能力,通过亮度增强、对比度增强、翻转、旋转操作等对原始图像进行扩充,扩充后共11 985张图像,经扩展后部分图像数据如图1所示。

图1 各等级板栗数据集
神经网络输入对图像像素有一定要求,为更好地保留板栗的特征,对图像进行调整,统一分辨率为256×256;之后将通过扩充构建好的数据集按照8∶2进行划分,划分后训练集和验证集分别为9 588张和2 397张,训练集用于模型训练,提取目标特征并获取超参数,因此需要较多数据,而验证集用于在训练中模型对板栗分类分级能力进行自我评估并不断优化超参数以优化模型。
1.4 模型构建
LeNet-5模型是第一个成熟的现代卷积神经网络模型,其结构示意图如图2所示。包括2个卷积层、2个池化层及3个全连接层,共计7层网络,其输入大小为32×32的灰度图,第一层和第三层为卷积层,所用卷积核大小为5×5;第二层和第四层为池化层(又叫降采样层),使用2×2大小卷积核进行平均池化;第五层为平展层(全连接层),将高维数据变为一维数据;第六层、第七层均为全连接层(FC)。使用随机梯度下降算法(SGD)优化,网络中通过sigmoid函数激活,最后采用径向基函数(RBF)的网络连接方式将预测结果输出。

图2 LeNet-5网络结构示意图
Lenet-5网络的图像输入大小为32×32的灰度图,由于板栗本身特征以及裂口、虫蛀、霉变等所致,需要较大像素的图像才能将其特征表现出来,经多次试验,决定采用256×256×3的图像作为输入,以更好地保留待训练图像特征,其中256为图像像素、3为RGB三色通道。CNN网络对图像识别的准确度会随着网络层数的增加而提高,如其他经典网络模型AlexNet网 络 共 有8层,VGG16网 络 有16层,VGG19网络有19层,因此,将LeNet-5网络层数改进 至14层(不 包 含Dropout),包 括7个 卷 积 层(Conv)、4个池化层(Pool)、1个平展层(Flatten)和2个全连接层(FC)。卷积核的作用是提取特征,实现对局部的感知,其大小对CNN的性能有重要影响。一般而言,如果想要达到相同的感受野,卷积核越小,所需要的参数量越小,同时计算量也越小。由于网络的加深,参数量增加,将原LeNet-5模型中5×5的卷积核改进,经不断试验,最终决定将部分卷积核大小改进为4×4和3×3,以便更准确地提取不同等级板栗的特征以及减少参数量,提高计算速度。
激活函数是存在于多层网络的两层网络之间,用于将上一层网络的输出转化为下一层网络的输入的一个函数关系,其作用是将两层神经网络之间的线性关系转换为非线性关系,使神经网络模型表达能力更加强大,几乎可以表示任意函数。LeNet-5使用sigmoid函数作为激活函数,sigmoid函数在一定范围外的两侧数值几乎不变,梯度趋于0,会产生梯度消失的问题[16]。为解决该问题,在改进LeNet-5网络结构中进行反向传播,故使用修正线性单元(ReLu函数)[17]替换sigmoid函数。但ReLu仍存在缺点,当网络训练中某一次权重为0或更小时,其输入为非正数时输出值均为0的特点会导致之后训练中该权重部分参数保持不变,从而造成神经元“死亡”现象。为避免神经元“死亡”,本研究采用Leaky ReLu作为激活函数。sigmoid函数、ReLu函数、Leaky ReLu函数几何图形如图3所示。
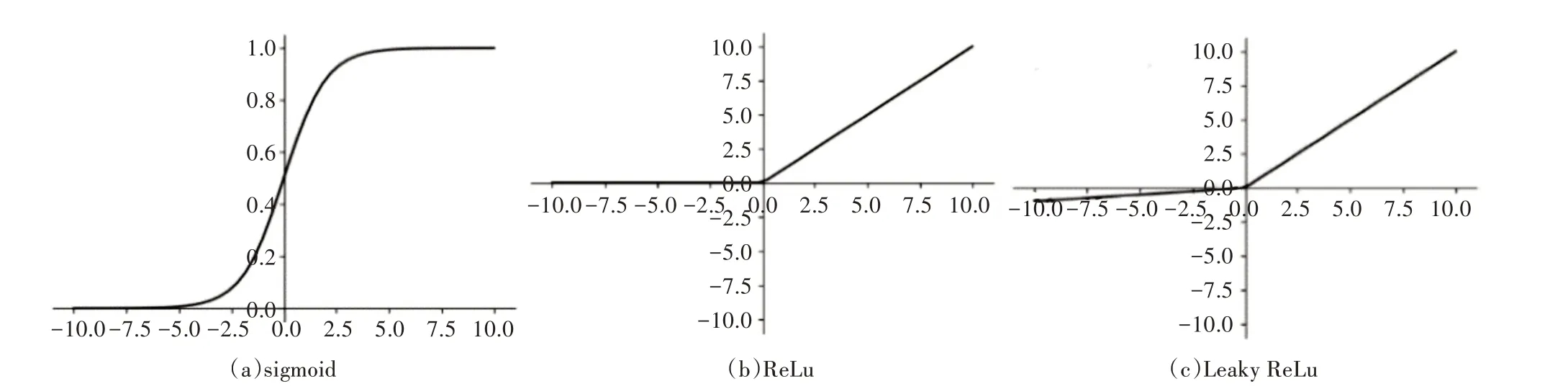
图3 3种激活函数几何图像
对LeNet-5模型改进后,网络层数增加,模型参数数量会大量增加,进而容易产生过拟合的现象。为缓解过拟合的发生,采用Dropout算法,全连接层参数量最多,容易出现过拟合现象,故将其加在全连接层之后。Dropout是指在对神经网络的某一次训练中,以一定的概率随机选择网络中的神经元并使其失活,避免神经网络过于依赖某些局部特征,以实现网络更加强大的泛化能力,避免过拟合问题突出[18]。
优化算法(Optimizer)对CNN训练以及最终效果有重要影响,目前有三类常用的优化算法,分别是梯度下降法、动量优化法和自适应学习率优化算法[19]。LeNet-5使用了随机梯度下降的方法进行优化,本研究将其改进为自适应学习率优化算法Adam,其通常被认为对超参数的选择鲁棒,其每次对偏差修正后,学习率会有确定范围,对参数的调整更加平稳。使用Softmax作为分类器,其本质为函数,计算方式为将待输出元素的指数与所有元素指数和相比,根据计算值以特级果、一级果、二级果、缺陷果四类进行输出。改进前后LeNet-5网络结构对比见表1,改进LeNet-5结构(不含Dropout层)如图4所示,模型参数见表2。

表1 改进前后LeNet-5网络结构对比
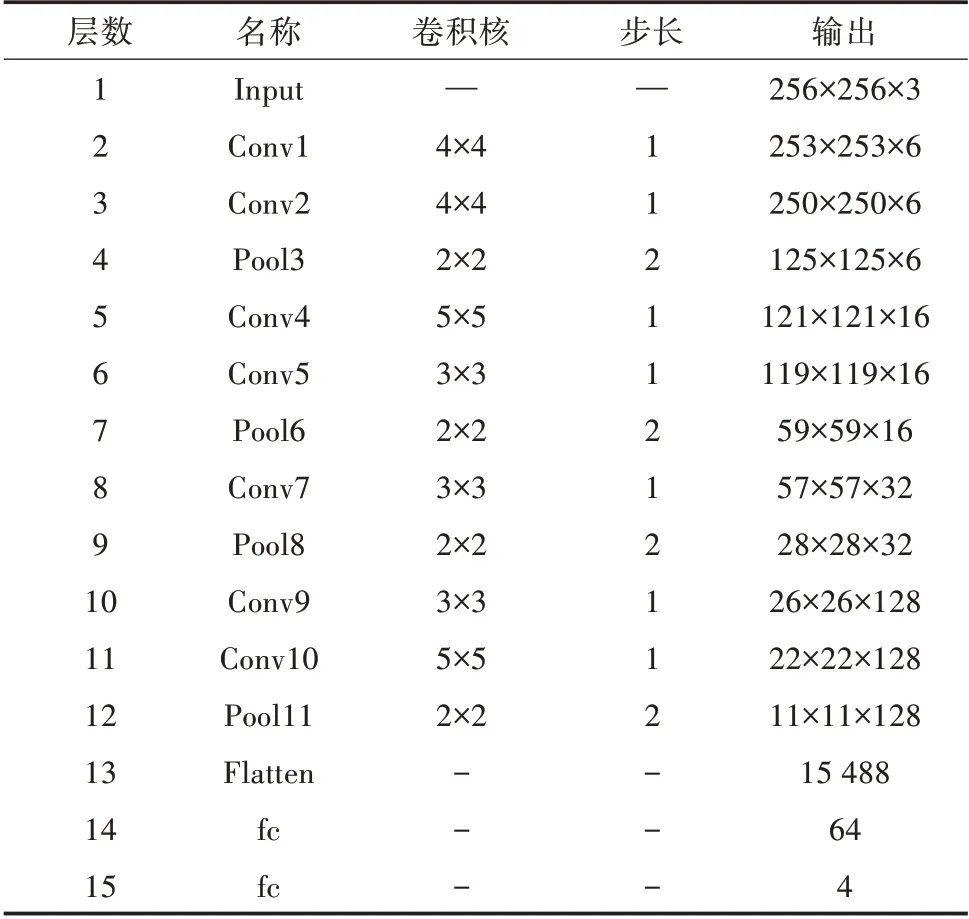
表2 改进LeNet-5模型网络结构参数

图4 改进LeNet-5网络结构
2 结果与分析
2.1 模型训练与结果分析
将上述构建好的网络进行训练,对网络不断迭代并进行参数优化,最终确定设置学习率初始(lr)为0.001,平滑常数β1和β2分别为0.900和0.999,epsilon为1e-08,学习率每隔10轮调整为之前的0.5倍,Dropout丢弃率为0.5,随机屏蔽50%神经元,训练和验证的批次尺寸大小为32;对图像数据进行批归一化处理,使其成为处于0~1的张量后送入网络进行训练,共训练50轮,训练完成后保存最优模型,训练过程精确率与loss值曲线对比如图5所示。
图5显示,随着训练迭代次数的不断增加,精确度在不断增加,损失值(loss)在不断下降,说明网络处于不断的学习状态。训练集精确度与验证集精确度在第5轮训练后超过90%,并在第10轮训练之后趋于稳定,最优模型训练集精确度为99.96%,验证集精确度为99.92%。由训练过程中网络在训练集和验证集上loss值可知,loss曲线下降逐渐缓慢,收敛情况趋于稳定,训练集与验证集loss曲线之间的间距不断变小,模型实现了对数据的良好拟合,表明本模型在板栗分级问题上具有良好的识别效果。
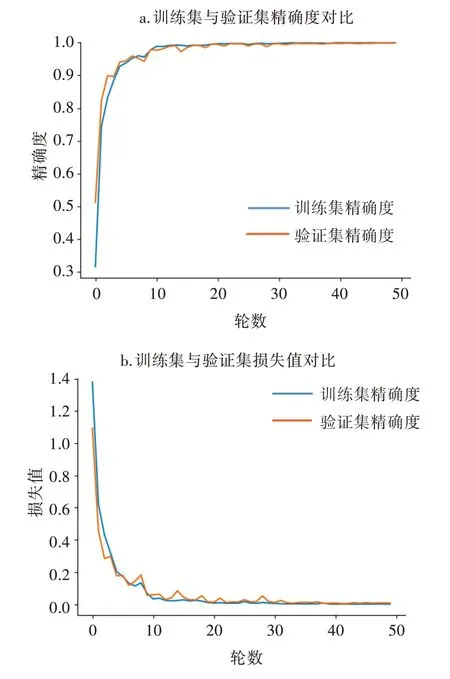
图5 改进LeNet-5网络训练集和验证集精确度与loss曲线对比
2.2 数据可视化
计算最后一层特征图所有权值的像素值,按照像素权值进行可视化,结果如图6所示。红色神经网络判断板栗等级权重最高的区域,蓝色和绿色表示网络分类权重次于红色的区域。可以看出,红色像素主要分布在板栗的边缘,因此网络对于板栗等级的区分主要是通过提取板栗的外形尺寸等特征实现的,这与最初的板栗等级划分一致,同时,对于缺陷果的检测,根据特征图上权重像素值的分布,网络利用了板栗外壳表面的虫蛀孔、裂嘴以及霉变等特征实现了很好的识别效果。

图6 不同等级板栗可视化数据特征
2.3 模型评价与对比
本研究使用精确率(Accuracy)、准确率(Precision)、召回率(Recall)作为评价指标,其计算公式见式(1)至式(3)。但是这些评价指标更适合二分类问题,所以采用分别计算每一类的3种指标,再进行不加权平均的方式评价模型能力。此外,定义了一个评价指标——单类错误率(Single class error rate,SCER),该指标在每个模型对每一类样本进行识别时进行单独评价,其计算公式如式(4)所示。

式中,TP(Ture positive)表示正类样本识别为正类样本的数量;FN(False negative)表示正类样本识别为负类样本的数量;FP(False positive)表示负类样本识别为正类样本的数量;TN(Ture negative)表示负类样本识别为负类样本的数量。
精确率是指模型识别正确的数量占总体数量的比值。一般而言,该指标值越高,说明模型效果越好。准确率是指模型在识别为正类的所有样本中真正为正类的样本,该指标值越高,模型效果越好。召回率又称为查全率,表示模型正确识别出正类样本的数量占总体正类样本数量的比值,同样,该指标值越高,模型效果越好。
为验证模型的可行性,利用上述获得的最优模型进行板栗等级识别分类测试。利用工业相机采集图像数据,共采集到171张,再从验证集中随机选取80%与采集到的图像共同构成测试集,对测试集图像数据进行预处理:将4类板栗图像顺序随机打乱,调整为256×256像素的RGB三色图像,并归一化为0~1的张量,将其送入模型进行识别,结果见表3。由表3可知,该模型对所有待分类板栗可以达到99.3%的召回率,其中,对缺陷果预测的召回率最高,对特级果和一级果预测召回率略低,测试2 088个样本共用时395.44 s,平均每识别1个样本用时0.19 s。此外,对工厂流水线作业进行模拟以验证模型的实际可行性,板栗以30 cm∕s的速度单粒通过工业相机镜头捕捉范围,可同时进行3颗板栗识别分类,分类正确率达93.6%,能很好满足工厂生产加工要求,该模型可以很好地对板栗进行分类分级。

表3 各等级板栗识别分级准确率
利用上述构建好的板栗等级数据集对原始LeNet-5模型、经典神经网络模型AlexNet和VGG16模型进行训练,图像数据输入网络之前进行归一化处理,训练参数设置如表4所示,学习率均每隔10轮变为之前的0.5倍,所有训练所得结果(包括改进LeNet-5)见表5。

表4 卷积神经网络参数设置

表5 4种卷积神经网络训练集与验证集准确度对比
将训练所得最优模型利用采集到的待测试板栗图像进行测试,所有测试结果(包括改进LeNet-5)构成混淆矩阵,对混淆矩阵引入每一类的错误率,如表6所示。原始LeNet-5模型对所有板栗识别错误率为2.68%,其中对于特级板栗识别错误率最高,改进的LeNet-5模型识别正确率明显优于原始LeNet-5模型,说明对LeNet-5模型的改进很好地提升了网络的性能,另外2种模型AlexNet和VGG16识别错误率分别为1.58%和0.96%,均高于改进的LeNet-5模型,其中AlexNet对于特级板栗识别错误率较高,改进的LeNet-5和VGG16对于一级板栗的识别正确率相同。根据混淆矩阵,可以得到4种模型的精确率、准确率、召回率,其结果如表7所示。从表7可知,改进后的LeNet-5模型效果要好于另外3种模型。
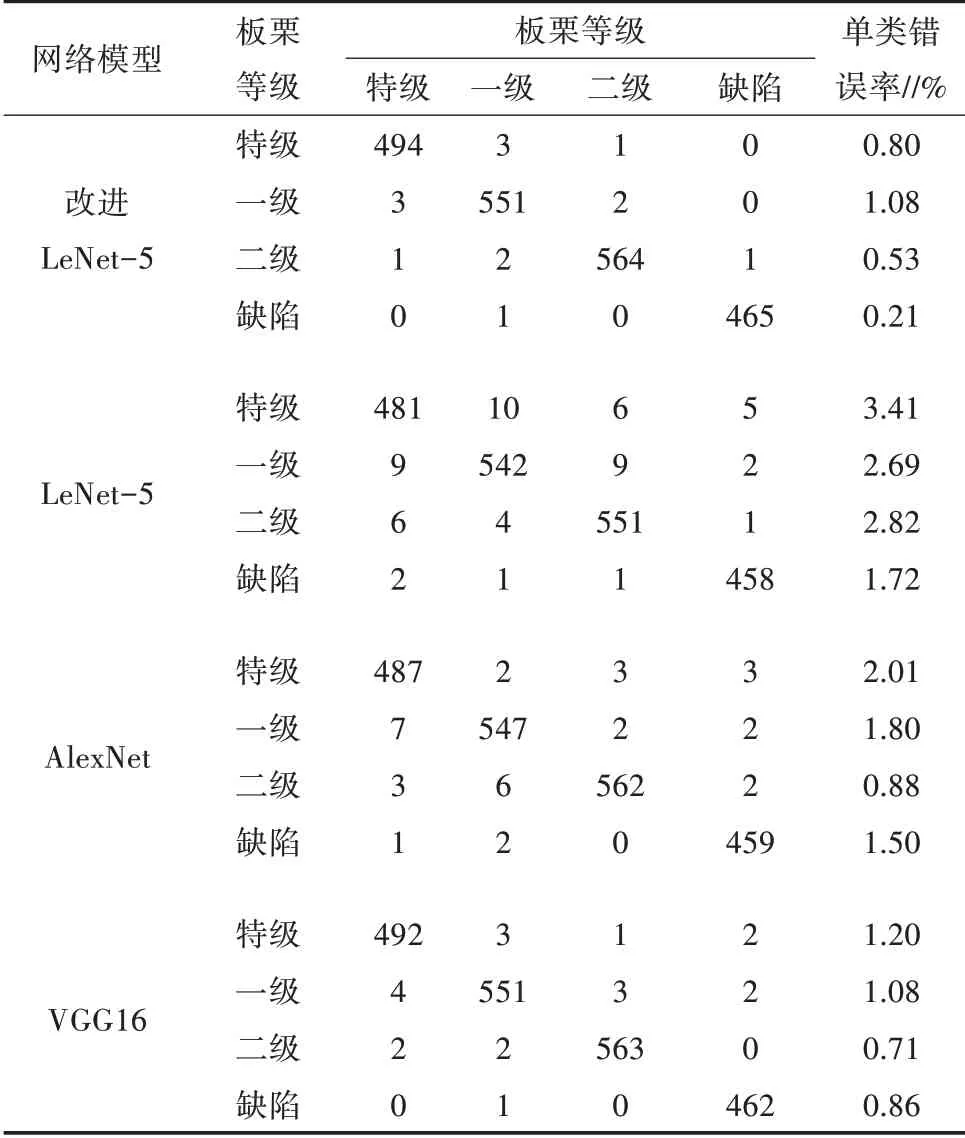
表6 4种网络的混淆矩阵

表7 4种模型精确率、准确率、召回率对比
3 讨论
中国板栗的分级标准与之前相比虽然有了较大的进步,但仍然存在一些问题,如分级指标少、分级术语模糊等问题,与国外相比仍然不够完备[20]。本研究对板栗进行分级主要是依照板栗生产出售厂家的分类方式,同时参考了国家标准。对板栗的分级标准应做到更加精细化和多样化,传统的机械分类法一般是通过不同大小的筛孔,利用体积进行筛选或利用重量进行筛选,这种分类方式对于一些缺陷果(如虫蛀果等)的筛选存在一定问题,需要人工进行二次筛选,而利用卷积神经网络模型进行筛选可以同时实现对板栗多种等级的筛选,提高分拣效率,节省人力。此外,可以开发性能更加强大的卷积神经网络模型,实现对板栗的精细精确分类,从而促进中国板栗产业的发展。
目前,深度学习被应用到水果的分级与品质检测之中的研究较多[21-23],而应用到坚果的品质检测及分级的研究较少。之前对板栗的分类分级及品质检测的研究大多是通过传统机器学习的方法[2,5,24],这种方法需要通过人工提取特征,构建分类器,过程较为繁琐且准确度不够高;而深度学习可以很好地解决传统机器学习的弱点,其性能强大,可以自动提取特征并实现更高的准确度,本研究是通过改进传统卷积神经网络LeNet-5模型来对板栗进行分级分类研究,与之前研究相比实现了更高的识别精确率。4种模型测试识别精确率等指标均较高,这可能与加入验证集构建测试集的方式有关,还应考虑是否仍然存在过拟合的问题,下一步需对该问题进一步探究。
对输入网络的图像数据进行可视化得到了特征图,从特征图可以看到,改进后LeNet-5网络模型提取了板栗尺寸特征和表面裂口、霉变和虫蛀等特征,成功地对其进行了分类,这与对数据进行分类标注时的标准一致,但在某些特征图中可以看到网络出现了错误提取特征的现象,如对于特级板栗,网络提取到了板栗壳表面硬化的浅色部分作为部分特征,且对该部分并未提取尺寸大小特征,这可能是由于特级板栗尺寸较大,该部分在采集数据时被采集到的比例较大,对于该问题还需要进一步探究。
对各等级特征图进行仔细观察可以发现,网络模型在提取板栗尺寸边缘特征时,存在提取不够准确、获取边缘过多的问题。同时发现所获得的数据集图像中普遍存在阴影,尤其对缺陷板栗的特征提取造成了较大影响。为解决此问题,可以考虑引入注意力机制[25],使网络重点关注核心目标,以实现更精准的分类。
4 小结
本研究将深度学习与机器视觉技术相结合,对传统卷积神经网络LeNet-5进行多方位的改进以提高其性能,通过目标检测对板栗进行4种分类,最终经过测试,此种分类方法可以达到99.34%的准确度。
猜你喜欢
公民与法治(2022年12期)2023-01-07
小学生作文(低年级适用)(2022年11期)2022-12-02
北京航空航天大学学报(2021年9期)2021-11-02
创新作文(小学版)(2019年10期)2019-09-25
电子制作(2019年11期)2019-07-04
小学生作文(中高年级适用)(2018年5期)2018-06-11
北京航空航天大学学报(2018年1期)2018-04-20
中国医疗保险(2017年6期)2017-07-18
中国卫生(2016年5期)2016-11-12
中国卫生(2015年10期)2015-11-10
