
基于机器学习的球团矿质量预测模型研究现状
2022-12-29 10:52杨会利张建良刘征建王耀祖孙庆科
天津冶金 2022年6期
杨会利,李 跃,赵 克,张建良,刘征建,王耀祖,孙庆科
(1.鞍山钢铁集团有限公司大孤山球团厂,辽宁 鞍山 114046;2.北京科技大学冶金与生态工程学院,北京 100083;3.北京科技大学人工智能研究院,北京 100083;4.北京科技大学自动化学院,北京 100083)
0 引言
随着国家供给侧结构性改革和低碳节能战略发展目标的实施,钢铁行业的发展和生存面临着严峻的挑战。对于高炉炼铁来说,球团矿是高炉冶炼必备的原料,球团矿的质量直接影响着高炉的正常运行和铁水的质量。因此对入炉球团矿的质量要求越来越高,这也就促进了球团矿工业的发展。球团矿入炉前的质量检测是必不可少的环节,而目前球团矿的质量检测结果大多是在成品球团矿生产出来后经现场人工采样,送化验室检测后得到。由于球团矿质量检测时间长,现场获得质量数据时间滞后,很难及时快速对成品球团矿的质量进行控制和调整,当发现球团矿质量不合格时,已经造成了巨大的损失。因此建立成品球团矿质量实时预测系统对球团矿质量、高炉生产及环境保护都有非常重要的意义。
目前计算机和人工智能技术已被广泛地应用于工业各个领域,进一步加强生产方式智能化绿色发展已成为诸多钢铁企业的研究热点。近年来,随着大数据、机器学习、深度学习的发展,基于大数据开发的智能控制、智能预测算法也被应用到工业的各个领域,例如烧结矿质量预测[1],球团矿质量预测[2]。为了能够实时监测成品球团矿的质量,国内外学者做了大量的研究。本文总结了近些年球团矿质量预测算法研究,主要包括案例推理、神经网络、遗传算法以及其他改进算法等,以期为钢铁企业球团矿质量预测的智能化提供参考。
1 球团矿质量预测研究现状
国内外对球团矿质量预测主要分为两大类,如图1所示。一类是对成品球团矿质量化学成分预测的研究,另一类是对球团矿质量物理性能预测的研究。
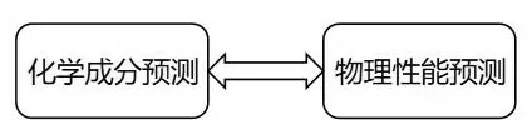
图1 球团矿质量预测Fig.1 Pellet ore quality prediction
国内外对球团矿质量化学成分的预测研究比较多。文献[3]通过搭建BP 神经网络模型预测碱度,国外有学者通过对风箱废气分析来预测FeO 含量。Liu Bin[4]等人建立了3 种不同的人工神经网络模型来预测球团矿的热状态指数(RDI、RI、RSI),根据球团矿理论确定网络输入,然后使用灵敏度分析来量化每个输入变量的重要性,并逐渐降低网络的输入维数,最后通过最小网络输入因子来提高网络预测的准确性,仿真结果表明,预测模型符合实际工程应用要求。
在球团矿质量物理性能方面主要预测的是转鼓指数和抗压强度。在球团的最佳粒径方面德国人做过深入研究,球团矿生产要尽可能满足粒度均匀,大小适中,粒度不均匀会降低球团的透气性,会在焙烧和预热过程中影响球团的干燥和预热速度,同时也影响冷却的速度,从而使得球团矿质量下降。Wang Yukun[5]等人提出一种基于核主成分分析(KPCA)和RBF 神经网络结合模型,通过分析链篦机-回转窑球团矿生产过程的热工参数,确定输入输出变量,利用核主成分分析算法(KPCA)处理样品数据并简化模型结构,然后利用RBF神经网络建立了球团抗压强度预测模型,利用全局优化的模拟退火算法对网络模型的参数进行优化,得到高精度的预测模型。仿真结果表明,该模型能够准确预测球团矿的抗压强度,克服原有球团矿抗压强度测量试验方法滞后的缺点。
2 球团矿质量预测模型
2.1 基于案例推理模型
案例推理(Case-based Reasoning)技术起源于Roger Schank 于1982年在Dynamic Memory 中的描述,在1988年由Roger C.Schank,Robert P.Abelson提出[6],是人工智能领域中新崛起的一种基于知识问题求解和学习的方法[7]。图2为案例推理流程,由图2可以看出,该方法是基于案例库中存储的过往案例的解生成新的问题的解,从而解决现实中随机出现的难以量化的解[8]。案例推理主要包括四个步骤,即案例描述、案例检索、修改重用、保存更新。由于钢铁企业在过去的生产过程中生成大量的历史数据,结合案例推理的方案将历史生成的大数据得以利用从而对以后产品质量的预测有着很大的生产意义。

图2 案例推理流程图Fig.2 Case inference flowchart
2.1.1 案例描述
将案例推理(CBR)引入到焙烧球团质量预测中就是找出球团矿的质量与各生产参数指标之间的关系。根据现场专家经验和历史数据的分析,可以用向量对球团矿案例进行描述,同时将问题特征向量的元素设定为焙烧性能指标,可以将入炉生球量、煤气流量、主引风机风量、风箱温度、烟罩温度、和烧嘴温度等设定为焙烧性能指标;将解的特征向量元素设定为球团质量指标[9]。基于主成分分析法对影响球团质量的指标进行处理[10],从球团矿24个性能指标中得到3 个综合特性指标,分别为化学成分FeO 质量分数(ym1)、转鼓指数(ym2)、抗压强度(ym3)。根据以上设定,影响球团矿质量因素指标和球团矿质量评价指标可以用向量表示为:
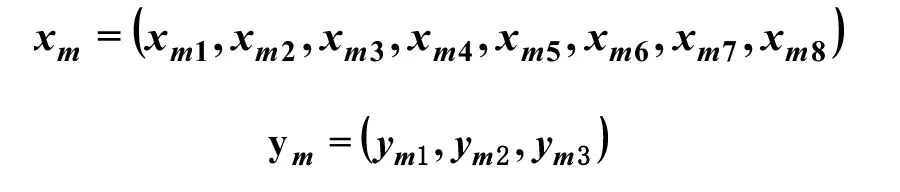
2.1.2 案例检索
案例检索与匹配是实现案例推理中非常重要的环节,案例检索的速度大小和案例检索的精度会影响案例推理的最终效果。为了满足速度和精度的要求,要在案例库尽可能检索出与待求解问题相同或类似的集合,且要尽可能减少检索次数。案例检索方法主要有最近邻、聚类分析、人工神经网络等,最常用的方法就是最近邻算法[11],最近邻算法(k-Nearest Neighbor,KNN)是机器学习的经典算法之一。最近邻算法基于N 个已经标注好的训练集样本T={Xi,i=1,…,N},对于新输入的测试集样本,通过计算其与训练样本之间的距离进行分类。在案例检索中认为每个案例的特征是相同的且都有各自的权重w,每个案例都可以用与其最接近的案例来近似表示,通过求解二者之间的距离来评价当前案例与案例库中案例的接近程度[12]。计算案例之间最常用的距离是欧几里得距离,则案例库中第m条案例xm和当前案例x0之间的欧几里得距离为[13]:
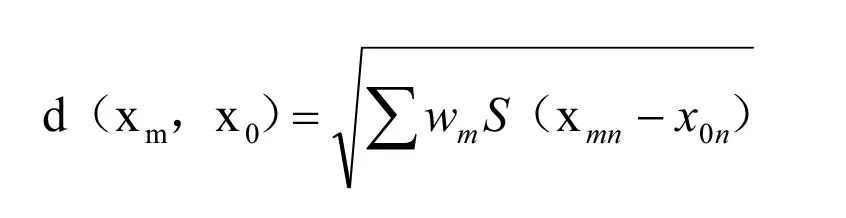
其中d 的值越小,表明当前案例与案例m 越相似。
2.1.3 修改重用
所谓案例重用,就是用在案例库中检测到的案例所提供的解决方案来解决目标案例的问题,对匹配信息好的案例可以直接套用案例库案例的解决方法作为目标案例的解决方法。大多数情况下,没有完全匹配的案例,只能通过对相似案例的解决方法进行调整得出新的解决方案。
2.1.4 保存更新
修改重用后的目标案例即使是与案例库的一些案例极为相似,但依然会存在细微的差别,因此该目标案例可以作为新的案例加入到案例库中,从而达到更新案例库的功能[14]。
刘丕亮[9]等人基于某炼铁厂的生产数据建立初始案例库,利用主成分分析法和k-means 算法建立索引结构,采用最近邻算法进行检索,修改重用,更新案例库。最后用球团焙烧实际数据仿真验证,对FeO 质量分数、转鼓指数、和抗压强度进行预测,并将预测结果和多元线性回归对比,结果表示案例推理预测精度高于多元线性回归。两种算法各质量指标参数预测相对误差绝对平均值如表1所示。

表1 两种算法各质量指标参数预测相对误差绝对平均值Table 1 Absolute average value of the prediction relative error of each quality index parameter of the two algorithms%
东北大学的胡睿[11]为了分析影响球团矿抗压强度的各段温度,选取了预热一段、预热二段、窑头和窑尾的温度作为输入,以球团矿成品球抗压强度作为输出,建立了基于案例推理的球团矿质量预测模型,从而得出抗压强度预报值和喷煤量应该输出值。李东喆[15]改进了案例推理预测球团矿抗压强度的模型,通过搭建球团矿抗压强度的质量控制器和球团矿生产过程的PID 控制器,以达到控制影响预热球团抗压强度的过程参数的目的,并验证了控制系统能达到设定的控制要求。
2.2 基于BP神经网络模型
BP(Back-propagation)神经网络是最传统的神经网络,是Rumelhart 和McClelland 在20世纪八十年代提出的一种误差反向传播的多层前馈神经网络[16]。BP 算法解决了多层神经网络中隐单元层权重连接的问题,得到了广泛的应用[17]。BP神经网络结构如图3所示。

图3 BP神经网络结构Fig.3 BP Neural network structure
BP 神经网络是深度学习的基本组成部分,输入向量和输出向量都是已知的,其任务是完成输入X和输出Y之间的非线性映射[18],如等式(1)所示。

BP 神经网络属于监督学习,图3显示的是一个标准神经网络结构,左边蓝色的为输入层,该输入层有三个神经元,中间为隐含层,通常神经网络有较多的隐含层,最右边红色的部分为输出层。每个神经元在计算线性加权后输出,然后经过激活函数将计算结果传输给下一层,在训练过程中,从输入层依次经过隐藏层到输出层从前往后的过程叫做前向传播。通过输出层预测值和真实值之间的误差,不断计算损失函数,不断地更新神经网络的权重和偏置项,该过程是从输出层反向传播的,故不断地更新神经网络参数的过程叫做反向传播。训练神经网络的过程包括前向传播和反向传播两个过程。
东北大学王武海[19]将球团矿生产过程按工艺划分为焙烧、预热、环冷等各个阶段,并找出影响每段的主要参数,根据各个分段的特点进行建模,分别建立了链篦机、回转窑、环冷机三个部分的球团抗压强度BP 神经网络模型,并从不同的角度对模型进行验证,结果显示模型性能较好。金达尔刚公司[20]建立了一个三层的BP 神经网络模型来预测球团矿的冷压强度,该网络的输入变量分别为给料率、料层高度、焙烧温度等12 个变量,输出为成品球的冷压强度。经过神经网络训练和测试表明,该网络的预测结果与实际结果的误差在3%以内,同时得出了输入变量对成品球团矿冷压强度的影响程度关系。闫洪伟[21]搭建BP 神经网络对球团矿抗压强度、转鼓指数和筛分指数进行预测,获得一定的效果,但预测精度还有待提升。东北大学的李明[22]依托弓长岭球团公司现场生产数据,搭建了基于BP 神经网络的抗压强度和转鼓指数的预报模型,结合球团的固结机理,构建了抗磨指数预测模型,该模型能够及时准确预测成品球团矿冷的物理质量,可以指导生产及时调整控制参数从而达到提高球团矿物理性能的目的,最后结果表明所建立的预报模型可应用于实际工程中。
2.3 基于遗传算法模型
遗传算法是在20世纪60年代由美国密歇根大学的John Holland 提出的,遗传算法的主要思想是模拟达尔文生物进化论,是一种用于解决最优化的一种搜索启发式算法,主要包括选择、交叉、变异三个过程[23]。遗传算法流程如图4所示。
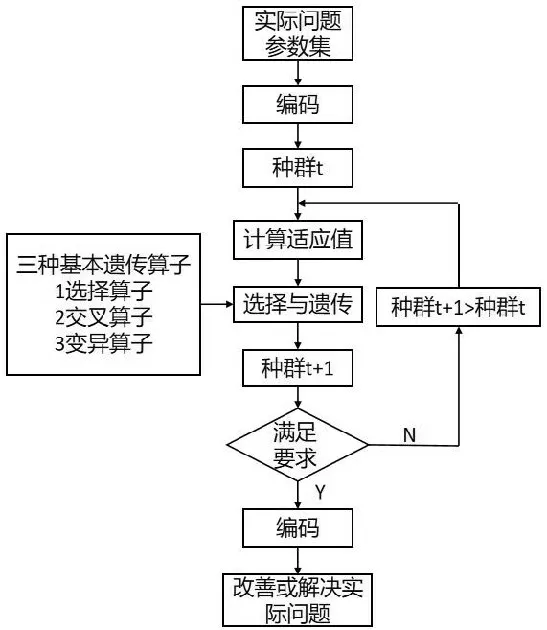
图4 遗传算法流程图Fig.4 Genetic algorithm flowchart
李东喆[15]搭建了BP 神经网络模型来预测预热球团抗压强度质量,同时结合遗传算法对BP 神经网络参数进行优化,并设计了预热球团抗压强度的质量控制系统。徐建有等人[24]利用遗传算法对神经网络的初始权值和阈值进行优化,搭建了基于遗传算法优化的BP 神经网络,并以实际生产数据为依据,对抗压强度、转鼓指数和筛分指数等质量指标值进行预测。结果表明该模型收敛快,精度高,对球团矿的生产有重要指导意义。闫洪伟[21]在BP算法的基础上搭建了GA-BP 网络模型,结果表明相对于BP 神经网络,经过遗传算法的优化,该模型对球团的抗压强度、转鼓指数和筛分指数的预测准确率都有较大的提高,同时遗传算法加快了模型的收敛速度。邱波[25]等人利用遗传算法优化的BP 神经网络建立预热球团的质量预测模型,仿真验证结果表明,球团质量模型精度达到了质量控制要求。
2.4 其他模型
江山[26]等人提出并建立了基于非线性主成分分析方法与自适应小波神经网络相结合的球团矿质量预测模型,对转鼓指数和抗压强度进行预测,结果表明该网络比传统的BP 网络对质量的预测准确率更高。闫洪伟[21]在BP 算法的基础上,将粒子群算法应用到网络中,结果表明,粒子群-BP 算法的预测精度非常高,但是其收敛速度偏慢。韩阳[27]在SVM的基础上进行改进,提出了一种球团矿冶金性能预测的SVM 改进模型,将球团矿相的纹理特征、颜色特征和分形特征构成的特征向量进行主成分提取并将其作为输入,探索了矿相主特征与其冶金性能的关系。Jie-sheng[28]等人提出一种基于生物地理学优化算法的径向基神经网络模型,该模型以成品球团矿质量最相关的物料厚度、窑头的温度、窑尾的温度等六个变量作为输入,以成品球团矿的质量指数作为输出。仿真结果表明,该模型具有较好的泛化能力和较高的预测精度。Xiao-hui Fan[29]等人根据回转窑温度变化曲线预测了球团抗压强度,从而辅助工艺的优化过程。部分球团质量预测算法的预测效果如表2所示。

表2 部分球团质量预测算法的预测效果Table 2 Prediction effect of some prediction algorithms on the pellet quality
3 结论
本文介绍了国内外球团矿质量预测研究的现状,重点总结了各种球团质量预测的算法模型,并对各算法模型在球团矿质量预测上的效果进行了对比分析。目前的算法都是在大数据基础上开发出的智能算法,在现实生产过程中,随着工况的变化,模型预测精度就会出现振荡。因此可以考虑将球团矿生产过程机理加入智能算法模型中,与算法相结合使得球团矿质量预测模型更加精确。
随着近些年计算机技术和人工智能的发展,各种智能算法都在不断地优化升级,智能算法在球团矿质量预测上的精度也在不断地提高。随着数字化时代的到来,在保证预测精度的情况下,建立全面的球团矿质量预测孪生系统是未来发展的方向。
猜你喜欢
中国毕业后医学教育(2022年4期)2022-11-29
宁夏大学学报(自然科学版)(2022年1期)2022-04-30
矿业工程(2021年5期)2021-11-30
水上消防(2021年4期)2021-11-05
新疆钢铁(2021年1期)2021-10-14
汽车工程(2021年12期)2021-03-08
内蒙古教育(2021年2期)2021-02-12
电子制作(2019年16期)2019-09-27
武汉科技大学学报(2019年3期)2019-05-18
电子制作(2019年24期)2019-02-23
