
基于属性基加密的云存储数据安全删重算法
2022-12-24 07:50:56刘玉龙
计算机仿真 2022年11期
刘 啸,刘玉龙
(江苏师范大学计算机科学与技术学院,江苏 徐州221116)
1 引言
科学技术的突飞猛进,互联网技术被广泛应于各个领域,在云计算系统中可通过云存储实现对数据的储存和管理,满足用户的数据访问需求,实现云存储的关键是利用存储硬件和相关云服务软件共同完成数据的存储,为用户提供高质量的服务[1,2]。在当下以及未来,将会有更多用户使用云存储服务,云存储不仅可以降低用户对移动硬盘、U盘等固定设备的使用率,同时在网络条件下,也可使用户随时随地存储数据、利用数据,既方便又快捷。云存储兴起虽短,但已有较好的发展势头,拥有较大规模的潜在用户群体。在云计算快速发展的前提下,云存储技术应运而生,它是企业或个人用户将重要数据文件存储于云服务器,并支付相关费用,由云服务器提供数据管理服务的技术[3,4]。
云存储广泛应用的同时,其用户为节约存储空间,更高效地管理数据,要求云存储技术更具安全性、高效性。特别对于企业而言,数据信息安全对高新技术企业至关重要,涉及企业的商业机密和研究成果[5],关系企业的经济发展。传统云存储加密方式的劣势在于密钥管理需花费高昂的费用以及在访问数据时其控制粒度太宽泛,且私密性不高,存在数据信息泄露的风险[6]。
云存储用户的急速增长,云服务器空间占用增大,且存储空间存在大量基于相同明文的不同密文,造成数据冗余,大规模的冗余数据致使存储成本高昂,因此,将冗余重复数据删除十分必要。刘竹松等人[7]研究利用Merkle哈希树方案对云存储数据去重处理,该方法虽使加密数据免于字典攻击,但云存储空间利用率不高;刘红燕等人[8]为避免用户隐私发生泄露,研究了利用用户定义安全条件实现数据安全删重的算法。该方法虽可使数据免于恶意用户的信道监听攻击,但该方法的去重效率还有待提高。
为解决数据冗余,提高云存储空间的利用率,本文提出基于属性基的云存储数据安全删重算法,在实现重复数据删除的基础上,又确保数据更加安全,保护用户数据免受攻击。
2 属性基加密
属性基加密是利用多个属性标志身份信息,并将其与系统的访问结构关联,使之访问控制性能更加细粒化,运用CP-ABE密文策略和KP-ABE密钥策略判断用户是否有权访问数据信息,提高数据信息的安全性能[9]。基于属性的加密(ABE)的原理是一组属性与密文有某种联系,一组属性和私钥具有某种联系,对于某用户而言,用一阈值描述其私钥属性和密文属性的适合度,当阈值大于某设定值时,此用户方可对密文解密。密文策略CP-ABE是发展后的ABE算法中的一种,由于其属性与密钥产生联系,密文决定用户访问策略,更适用于云存储的应用范围。
CP-ABE由四部分组成。
第一部分:Setup()。可产生主密钥MK和公钥PK。
第二部分:CT=Encrypt(PK,M,T)。密文CT是利用PK和访问结构树T加密明文M获得。
第三部分:SKs=KeyGen(MK,S)。私钥SKs可利用MK及用户属性值S产生。
第四部分:M=Decrypt(CT,SKs)。利用私钥SKs对密文CT解密获得明文M。Decrypt()能够解密需满足条件:S符合T。
属性:所有属性集合表示为P={P1,P2…,Pn},A表示用户私钥相关的属性集,用AP表示P的属性子集,且AP不为空。
访问结构树:对数据的访问管理可通过访问结构树体现,每个属性都可用访问结构树的叶子表示,关系函数用树内各节点表示,可用and、or、nofm门限。基于秘密分享,将各个节点都视为一个秘密,在进行加密操作时按从上到下顺序将秘密赋予各个节点,按从下至上顺序对根节点进行解密操作。访问结构树是数据访问管理方法的阐述,欲实现解密操作,需使用户私钥相关的属性集与访问策略相匹配。
CP-ABE算法:
第一步Setup():W1为双线性群,w为W1的生成元,e:W1×W1→W2为W1的双线性映射。
A={a1,a2,a3,…,an}为属性集,针对各属性ai∈A(1≤i≤n)任意选取xiW1(1≤i≤n),随机选择相关系数α、β,PK={W0,w,wβ,e(w,w)α}为公钥,向用户公布,MK={β,wα}为主密钥,主密钥不可公开,需私下保存。
第二步Encrypt(PK,M,T):利用PK和访问结构树T对明文M进行加密。首先构建访问结构树,原理是:用lx表示节点x的门限值,qx表示x节点经过lx-1次选择后的任意多项式,节点x的秘密为qx(0)。任意选取秘密s∈Zp,Zp为任意数集合,使qV(0)=s,根节点为V,而访问树上的其余节点x,使qx(0)=qparent(x)(index(x)),parent(x)退回到节点x的上一级节点,index(x)退回到节点x的序号。叶子集合表示为F,密文CT的描述为:
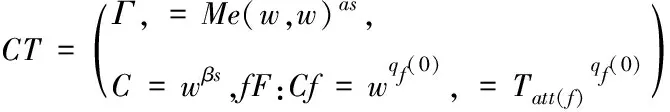
(1)
式中:退回叶子节点的属性为att(f)。
第三步KeyGen(MK,S):产生属性集S的私钥。用S表示私钥相关的属性集,其为u的子集。r∈Zp为产生的一个任意数,将任意数rj∈Zp赋予各个属性j∈S,私钥SK可描述为
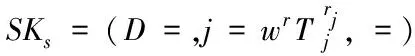
(2)
第四步Decrypt(CT,SK):利用私钥SKs对密文CT解密获得明文M。DecryptNode(CT,SK,x)为递归运算,当i=att(f)时,针对各个叶子节点x进行计算。
DecryptNode(CT,SK,x)=
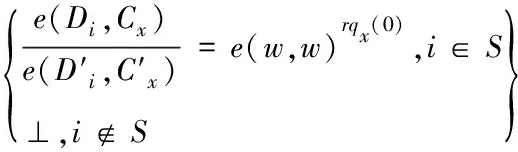
(3)
针对各非叶子节点x,拉格朗日多项式的差值节点e(w,w)rqx(0)最少要使用lx个,通过节点x的子节点{Zj}可获得e(w,w)rqx(0),通过计算e(w,w)rqx(0)获得e(w,w)rqzj(0),当A=e(w,w)rqR(0)=e(w,w)rs,可获得明文M=/(e(C,D)/A)。
3 存储数据安全删重
基于属性基加密的存储数据安全删重算法可实现重复数据的删除处理。首先分类处理存储数据,在此前提下建立数据引用度标签区分数据属于非频繁引用数据还是频繁引用数据,该标签依据椭圆曲线进行构建。非频繁引用数据删重通过验证加密数据的明文是否重复,以保证明文数据与其密文一一对应,频繁引用数据采用改进的收敛加密算法,以确保云服务器数据安全存储前提下,将数据删除效率提升。通过非频繁引用数据和频繁引用数据的删除共同完成云服务器数据安全删重。
3.1 椭圆曲线设定
云服务器CSP和用户构成加密的主体,(X1,X2)为云存储信息,{Uz}z∈(1,2,…,n)为任意数据集合,利用X3=X1+X2加密数据,{CT(X3,Uz)}为加密后的密文集合,存储于CSP。设定E(a,b)GF(2m)为椭圆曲线,GF(2m)为特征为2的有限域,点(x,y)∈GF(p)×GF(p)满足条件为
y2+xy=x3+ax2+b(a,b∈GF(2m)∧b≠0)
(4)
O为椭圆曲线原点,用椭圆曲线表示满足式(4)的点(x,y)和无数O的集合,G∈E(a,b)GF(2m)为所选基点,将a、b、G公布,经CP-ABE加密后的密文为CT,以T为数据的流行度阈值。
3.2 引用度查询

第一步:Cj传输数据mj至云服务器,通过shj=SH(mj)对mi的短哈希值进行计算,并上传至CSP。
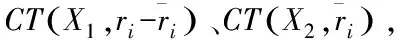
第三步:CSP计算sj数量,得到count(sj),与引用度阈值T比较,如果大于T,数据mi是频繁引用数据,小于T是非频繁引用数据。
3.3 非频繁引用数据删重
用户将数据的密文CT(X3,Kmi-ei)、CT(Kmi-mi)储存于云服务器CSP内,其中ei=SHA-1(mi)。mi的加密密钥为Kmi,通过ei使Kmi盲化,获得Kmi-ei,采用X3对其加密获得的密文为CT(X3,Kmi-ei),数据mi的密文为CT(Kmi-mi)。
当数据mi为非频繁引用数据时,可作如下处理:
第一:当sj与si相匹配,sj=si时,那么mj=mi,云服务器CSP向用户传送密文CT(X3,Kmi-ei),用户根据X3=X1+X2解密密文获得Kmi-ei,算出Kmi=Kmi-ei+ej,接着用Kmi加密数据mi,获得密文CT(Kmi-mj),并传送至CSP,CSP对CT(Kmi-mj)=CT(Kmi-mi)进行判断,当等式成立,删除CT(Kmi-mj),并生成CT(Kmi-mi)的链接允许用户访问。
第二:当不存在与sj相同标签时,说明数据mi的初始传输用户就是Cj,CSP会向用户Cj传送选取于{CT(X3,Uz)}密文集合的任意密文CT(X3,U),用户通过X3解密密文获得U,通过Kmj=U+ej加密mj,获取密文CT(Kmj,mj),并存储于CSP。
3.4 频繁引用数据删重
数据m的私密度因其数量的增多而处于下降状态,上传该数据的用户数量表示为count(m),如果count(m)=T时,用户先对数据m的哈希值进行计算,e=SHA-1(m),X3=X1+X2,选取数据m的加密密钥为Km=X3+e,通过计算获得CT(Km,m),并在CSP中存储,如果count(m)>T,向CSP传输e′=SHA-1(CT(Km,m))即可,密文CT(Km,m)无需传送,CSP会为用户提供CT(Km,m)的访问链接,实现频繁引用数据m的删重。
4 实验分析
设定实验环境:服务器端运行平台采用某云服务器,内存8GB,以某台计算机为客服端,i5处理器,内存8GB,运用C++语言编程实现本文算法的云存储数据的安全删重,设置数据引用度阈值为8。首先对用户上传数据的查询标签数量与引用度阈值进行比较,当查询标签数量小于阈值8时,为非频繁引用数据,当大于8时为频繁引用数据。
云存储数据在向云服务器CSP传送和用户下载过程中,大致可包括以下主要操作:产生查询标签、检验标签、引用度查询、属性基加密、收敛加密、传送数据等。通过设置文件数据规模检测云存储数据加密、删重中各主要操作的耗用时间,云存储数据各操作的时间耗用情况如图1所示。

图1 本文算法各步骤耗时对比
分析图1可知,云存储数据在传送和下载的过程中,不断增大传送文件的数据量,运行以上各操作所花费的时间开销呈现逐步增大的态势。其中,传送数据操作耗用时间最大,约为全部运行时间的60%以上,该实验结果表明云平台传送文件的耗时最高,因此,为突出本文所提算法的应用效果,下面针对云存储数据的传送耗时进行测试。
比较本文算法、文献[7]算法、文献[8]算法对云存储300MB文件传送耗时,实验结果如图2所示。
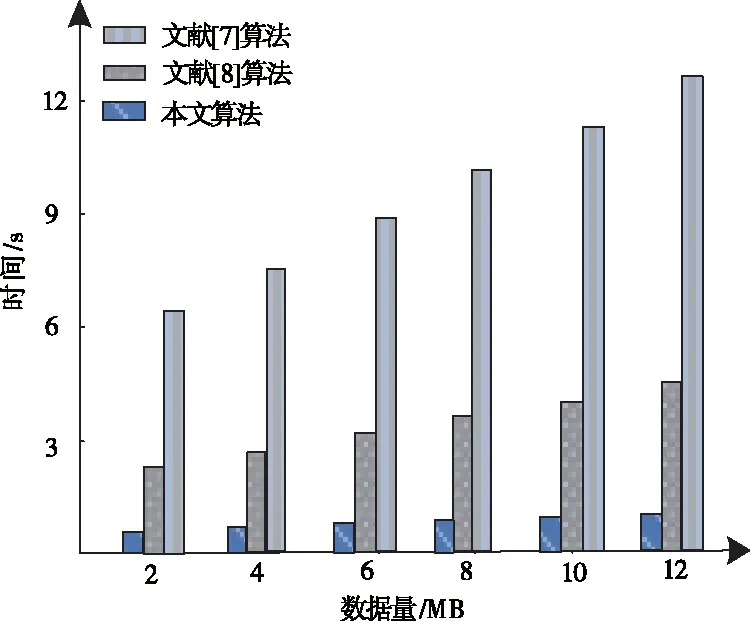
图2 不同算法的数据传送时间开销对比
分析图2可知,本文算法下云服务传送数据的时间变化幅度最小,耗时最短原因是本文算法可执行非频繁引用数据的删重,当数据数量低于引用度阈值时,本文算法可去除重复密文,大大节约计算时间,使数据的云存储时间很少,节省云服务器的存储空间。
假定云服务CSP中存储5万个数据信息,设定重复数据比例分别为3%、8%、15%、20%,利用本文算法对云存储中的重复数据作删除处理,验证本文算法数据删除能力,结果参见图3所示。

图3 重复数据删除
分析图3可知,随着云存储数据信息数量的增多,3%、8%、15%、20%比例的重复数据的成功删除概率呈现上升趋势,其中重复率为3%的云储存数据,在数据量较小时,该曲线的成功删除率呈线性快速增长,随着数据量的逐步增大,曲线走势慢慢趋于平缓,最终实现数据的100%删除,与重复率3%曲线相比,重复率8%的云存储数据,在数据量相对较少时,该曲线的成功删除率上升趋势同样呈线性增长,但增长速度明显慢于3%曲线,后期随着数据量的增大,走势慢慢缓和,重复数据100%删除。相比之下,云存储数据重复率为15%和云存储数据重复率为20%的重复数据删除速度稍慢,由于该云存储中存在重复数据较多,曲线的上升趋势最慢,但也均能实现重复数据的完全删除。本实验结果表明本文算法的重复数据删重能力较强,具有较强的适用能力。
5 结论
为解决现有的云存储数据删重算法存在的时间开销较大问题,提出基于属性基加密的云存储数据安全删重算法。为增强云存储数据传送的安全性,采用属性基加密的CP-ABE密文策略作为云存储数据的加密算法。划分加密数据为非频繁引用数据和频繁引用数据两种类型,全面实现云存储重复数据删重。实验结果证明了采用本文算法存储文件,可高效率完成数据删重。通过对不同比例重复数据作删除处理,表明本文算法具有显著的删重效果。
猜你喜欢
电子与信息学报(2023年9期)2023-10-17 01:15:06
黑龙江大学自然科学学报(2022年1期)2022-03-29 00:57:56
计算机与网络(2022年2期)2022-03-17 22:48:16
计算机仿真(2021年10期)2021-11-19 08:17:42
网络安全技术与应用(2021年7期)2021-07-16 06:13:20
电子制作(2019年14期)2019-08-20 05:43:42
当代贵州(2018年21期)2018-08-29 00:47:20
装甲兵工程学院学报(2018年1期)2018-06-19 09:57:06
电子制作(2017年20期)2017-04-26 06:57:48
信息安全研究(2015年3期)2015-02-28 20:17:54
