
基于Hadoop框架与用户行为特征感知的智能图书推荐系统设计
2022-12-23 12:03花维
电子设计工程 2022年24期
花维
(西安外事学院,陕西西安 710077)
互联网技术的普及与发展改变了人们的生活、生产方式,互联网技术已经渗透进了生活的各种场景,如购物、娱乐、社交通信等,人们充分享受着互联网带来的便利。但另一方面,互联网上信息的极度丰富也使人们面临着信息过剩的问题,大量没有价值的不良信息占据着人们宝贵的接受信息时间。搜索引擎的出现使得人们可以根据其意愿进行信息筛选,限制用户获取信息的范围,较大程度地缓解无用信息的干扰。近年来,推荐系统的出现更是使得互联网可以根据用户的兴趣进行信息推送,大幅度提升了用户获取信息的效率与用户体验。推荐系统的本质也是一个搜索系统,在人们享受便利的同时也在互联网上留下了自身的各种“活动轨迹”。通过这些轨迹提取用户标签,结合用户信息构建用户画像。然后,将不同用户的不同画像输入到网页的搜索框,即可获得该用户感兴趣的信息,达到个性化匹配的目的[1-4]。
为了提升读者获取其感兴趣图书的效率并提升阅读体验,该文对图书的推荐系统进行了研究。通过引入系统工程理论指导设计,梳理图书推荐的主要流程,确定系统的软件架构;引入Hadoop 大数据处理框架,基于MapReduce 编程模式,实现了推荐算法的并行化处理,提升推荐系统的计算效率。
1 系统设计
1.1 系统需求分析与结构设计
图书在线推荐系统的研究与设计是一项庞大的软件工程任务,为达到该目的,需要有科学的理论指导。在软件工程理论中,系统的需求分析是软件设计的第一步。通过需求分析可以明确系统设计的目标,同时在这一过程中将目标进行逐级拆解,转换为计算机容易实现的功能模块,逐步转化为最终的软件系统[5-9]。
图书在线推荐系统可以实现高效、精准的书籍推荐。精准的推荐对于互联网企业增加用户粘性,提升电子商务网站的转化率具有重要意义。高效性的特点,要求推荐系统必须具有较强的实时性,具体体现在当用户特征、图书信息等要素发生变化时,推荐的内容也可以及时、快速地更新。精准性要求推荐的书籍对于用户有较好的接受度,推荐书籍应当具有一定的点击率。基于以上的目的及相关分析,设计系统的相关功能模块,如图1 所示。

图1 图书推荐系统功能模型
在图1中,图书推荐系统包含图书元数据库、用户特征库、图书挖掘子系统、行为监控子系统、用户特征子系统、搜索引擎子系统、页面推荐子系统。从图1 可以看出,推荐系统的设计与实现重点在于各项数据特征的搜集,其实质在于读者特征与图书特征间的精准匹配。想要达到该目的,既需要通过搜集读者的相关历史数据建立精准的用户画像,也需要建立图书的相关数据库,然后找到二者间的联系[10-15]。
对于用户特征库,主要依靠用户注册时的相关基础信息,如性别、年龄、职业、兴趣等作为推荐的冷启动。当用户有浏览记录、收藏记录时,逐步增加这些对于推荐的权重。
对于图书元库的建立,该文主要根据图书类别进行分类,同时记录相关的用户浏览信息。
基于以上的系统功能分析,建立如图2 所示的系统推荐流程[16]。

图2 系统推荐流程
在图2中,结合用户的行为数据库,从中提取特征行为,其次结合行为属性形成特征向量。然后利用特征向量,从数据库中筛选符合相关约束的图书元作为初始的推荐结果。随后,通过系统内置的相关规则进行过滤,再结合用户反馈以及书籍的自有属性进行排名。最终附加上推荐的原因,给出推荐结果。
图3 给出了系统的软件架构,为了提升系统推荐的实时性,系统采用分层架构。
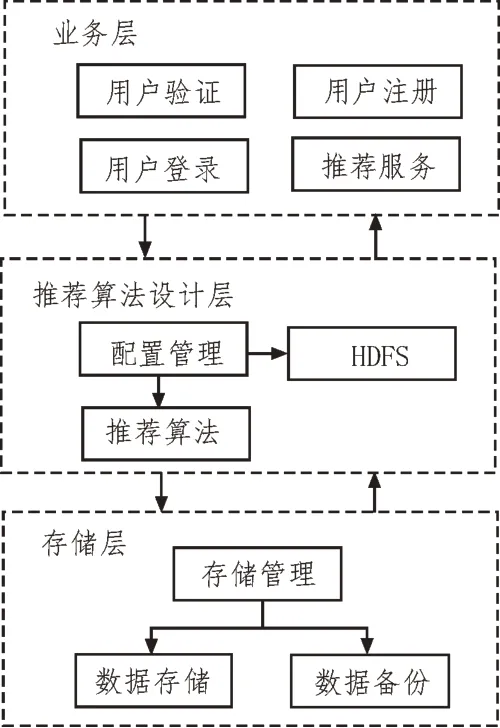
图3 图书推荐系统的软件架构
通过分层,可以降低业务层、推荐算法层与存储层间的耦合程度,每个层间只需给其余层次提供合适的软件接口即可。该种设计使得系统的软件结构更清晰,提升了系统后期的可维护性。
1.2 推荐算法
对于推荐系统而言,其核心在于推荐算法的设计。文中推荐系统使用的算法主要包括基于内容的推荐算法与系统过滤算法。
基于内容的推荐算法,需要依靠内容特征的提取,文中主要是对书籍特征的提取。由于该方法不需要用户信息,适用于新用户注册时进行系统冷启动。内容推荐的关键在于对系统内m本书建立p维的空间,然后基于用户的爱好与兴趣,利用用户与书本间的邻近度进行推荐。当基于内容进行推荐时,系统邻近度的计算方式如式(1)所示:

其中,i、j分别代表了用户向量与书本向量,这两个向量将书本、用户的特征作为向量的元素。
当系统内产生用户的日志信息后,系统将使用过滤规则进行书籍的推荐。该规则采用与目标相似度较高的用户或书籍进行推测,推断出用户对于某些书籍的潜在兴趣。在推断过程中,主要借助夹角的余弦值衡量该种相似性,其计算方法如式(2)所示:

2 算法实现
2.1 基于Hadoop的平台部署
由于图书推荐系统的推荐涉及了大数据的处理与挖掘,因此,需要数据密集型分布式计算框架的支持。该文选取的计算框架为Hadoop,该框架可以通过多个基础计算机集群的联合获得超高的计算能力,且具备良好的扩展性。在Hadoop 中包含了Pig、Chukwa、Hive 等多个项目结构,文中涉及的主要有分布式文件系统HDFS 与Hadoop 的编程模式MapReduce。对于HDFS,通过表1 的环境部署了七个节点的分布式存储系统。其中,一个是Master 节点,六个是Slaver 节点。

表1 仿真环境
对于Hadoop 的编程模式,其实现了计算过程中动态的控制计算节点,保证了Hadoop 系统的灵活性与可扩展性。在编程中,MapReduce 只受数据当前行的影响,其过程包括Map 与Reduce 两个节点。实现过程如式(3)所示:

图书的推荐高度依赖于图书度的统计,图书度反映了图书浏览或被购买的频次,是图书热门程度的重要体现,通过MapReduce 实现图书度的统计方法如下文所述。
在该系统中,读入用户日志文件,基础的存储格式为:<用户ID,商品ID,用户评分,时间戳>。在图4中,给出了用户ID 为1、2、3 的用户日志文件。经过Map后,系统得到的结果为<商品ID,所有用户的购买频次>。随后,利用Reduce 函数合并结果,以商品ID 为主键将相同商品的购买次数相加,最终得到<商品ID,商品度>作为MapReduce 的输出结果。

图4 MapReduce编程模式
通过引入MapReduce 编程模式,该系统可以灵活地定义Map 与Reduce 中的主键进行计算,统计各项数据作为系统的推荐依据。
2.2 算法仿真与系统实现
为了评估文中推荐算法在Hadoop 上的部署效果,使用Amazon 的开放数据集。在该数据集中,包含了581 921 位用户对于187 213 部图书的共112 340 015 次的图书打分记录。
图5 给出了算法在表1 Hadoop 集群上的运行时间。其中,横轴代表Hadoop 集群中计算机的数量,纵轴代表算法的运算时间,图例代表了一次性推荐不同数量的图书M。可以看出,推荐算法的运行效率受到推荐图书数量与Hadoop 节点数两个方面的影响。值得注意的是,对于文中的推荐算法而言,当推荐的图书种类数较少时(M为100 或200),集群大小对于算法计算时间的影响并不显著。当推荐的图书种类数较大时(M为3 000 或5 000),算法计算的时间随着集群数量增加呈线性减小的趋势。当M=5 000时,使用七个节点计算的时间约为890 s,而单节点的计算时间为4 400 s,时间约为单节点的1/5。因此对于Hadoop 平台,需要初始化足够数目的Mapper 文件才能充分发挥其大数据处理的优势。

图5 基于Hadoop的算法运行效率
最终,结合图3 给出的系统软件框架实现系统功能。在实现过程中,用户对于图书的打分信息使用JSP 调用JDBC后,通过数据存储模块写入数据库。系统内的推荐业务借助Hadoop 平台,结合图4的MapReduce 编程模式进行实现。在最终实现的系统个人主页的界面中,共包含了四个功能模块,系统界面通过JSP 调用相关的数据接口实现。个人主页界面上展示了用户的个人信息,且提供了搜索功能。系统会结合当前的读书热点给出“每日一荐”,根据用户的历史读书行为以及用户信息给出“猜你喜欢”的相关推荐。
3 结束语
文中对图书推荐的相关方法进行了研究,通过Hadoop 部署了系统中用户特征、用户行为日志等特征库,实现了用户特征到图书内容特征的匹配。Hadoop 大数据计算框架的引入提升了系统的计算能力与数据存储能力,对于系统后续的扩展、升级也具有较高的实用价值。
猜你喜欢
公民与法治(2022年10期)2022-10-12
疯狂英语·新读写(2022年6期)2022-06-08
疯狂英语·读写版(2022年6期)2022-06-08
少先队活动(2021年2期)2021-03-29
汽车维修与保养(2021年8期)2021-02-16
南风(2020年22期)2020-09-15
学生天地(2020年17期)2020-08-25
数学大王·低年级(2020年3期)2020-03-12
小学生优秀作文(低年级)(2019年5期)2019-04-25
当代作家(2018年11期)2018-11-27
