
基于Swin-Unet的混凝土裂缝分割算法研究
2022-12-22 13:50刘森
河南科技 2022年23期
刘 森
(长沙理工大学土木工程学院,湖南 长沙 410114)
0 引言
作为当今建筑中的主要材料,混凝土在建筑中起着至关重要的作用。混凝土在服役过程中,因荷载的作用和材料性能的退化,使其表面出现裂缝,不仅影响建筑物的美观和耐久性,甚至会缩短建筑物的使用寿命,威胁其结构安全。因此,要及时发现裂缝的位置,分析裂缝出现的原因和损伤程度,并采取措施来防止裂缝进一步延伸。
近年来,随着深度学习的快速发展,深度学习领域中的卷积神经网络(CNN)已被广泛应用于各种分割任务中,并在裂缝检测领域中表现出不错的性能。特别是,U-Net[1]及其变体在该领域的应用更成功,如建筑物表面裂缝检测[2]、桥梁裂缝检测[3]、路面裂缝检测[4]和混凝土裂缝检测[5]等。然而,因卷积操作的归纳偏置,使其无法学习全局,完成远端的信息交互,从而阻碍分割网络的进一步提升。通过引入Transformer[6]模型来弥补卷积的缺陷。利用Transformer 在特征图中捕捉长距离特征的优势,能有效弥补CNN因局部偏置和权值共享对全局信息把握不足的缺点。Swin-Unet[7]是一种基于U-Net改进的纯Transformer模型,其延用CNN 中的 U 型网络架构,并通过 Swin Transformer[8]模块来弥补卷积操作的缺陷,能更好进行局部及全局的语义特征学习,有着更优的性能。因此,本研究借鉴深度学习领域的Swin-Unet分割模型来完成混凝土的裂缝检测。
1 模型架构
目前,图像分割主要基于卷积神经网络(CNN)。其中,U 型网络(U-Net)作为经典的CNN,其在利用跳跃连接的同时,保留在下采样中丢失的细节信息和在低分辨率图像中获取到的全局特征,这种融合不同尺度特征的编码器-解码器的结构设计能大幅度提升分割模型的性能。因此,Swin-Unet 模型延用这种U型架构,同时引入Swin Transformer模块来弥补卷积操作无法进行远程信息交互的缺陷。
1.1 Swin-Unet模型架构
与传统的U-Net 结构相同,整个Swin-Unet 模型由3 部分组成,即编码器(左侧部分)、解码器(右侧部分)以及跳跃连接(中间跨线部分),如图1所示。

图1 Swin-Unet模型架构
1.1.1 编码器。输入的图片先通过patch par⁃tition 模块,其将图片切分成大小相等,且互不重叠的分块,并对每个分块进行线性嵌入,可将输入向量的维度变成预先设置好的值,图中维度用C 来表示。随后将嵌入的分块依次送入Swin Transformer模块和patch 融合层,用来生成不同尺度的特征表述。其中,Swin Transformer 模块负责学习特征,patch 融合层负责下采样操作,将输入该层的特征图的分辨率缩放至一半。
1.1.2 解码器。解码器由多个Swin Trans⁃former模块和patch 扩张层组成。patch 扩张层进行上采样操作,将输入该层的特征图扩充至2 倍分辨率,最后一个patch 扩张层会将特征图扩充至4 倍分辨率,用于将特征图还原成原图尺寸,最后通过线性映射层进行像素级别的预测,判断被预测的像素点是否属于裂缝。
1.1.3 跳跃连接。和传统的U-Net一样,跨线负责的是特征融合,以级联的方式将特征图输送到解码器来融合多尺度特征,从而弥补原始信息的丢失。
1.2 基础模块
1.2.1 Swin Transformer模块。Swin Transformer是整个网络最基础的模块,和传统的多头注意力(MSA)结构不同的是,Swin Transformer 是基于滑动窗口构建的,图2 为两个串联的Swin Transformer 模块。每个Swin Transformer 模块由两个层归一化(Layer Norm)层、多头自注意力模块和多层感知机(MLP)组成。

图2 两个串联的Swin Transformer模块
在两个连续的Swin Transformer模块中,分别采用基于窗口的多头自注意力模块(W-MSA)和基于滑动窗口的多头自注意力模块(SW-MSA)。
Yao 等[9]提出的多头注意力(MSA)采用的是全局自注意力机制,即在整张图上进行自注意力计算,其计算复杂度与图片大小成平方关系。当图像增大时,计算量也会飞速上涨。W-MSA 使用窗口对计算范围进行限制,在每个窗口内进行自注意力计算,可极大降低计算的复杂度,提高训练速度。但因每个窗口互不重叠,每次进行自注意力计算时,窗口与窗口间没有信息交流,SW-MSA 通过滑动窗口来实现窗口与窗口间的信息交流。采用基于滑动窗口的自注意力模块,不仅具有标准的transformer 自注意力机制的全局信息提取能力,还能降低计算复杂度。MSA 复杂度与W-MSA 复杂度的计算公式见式(1)、式(2)。

式中:H 为图片的高;W 为图片的宽;C 为图片的维度;Ω为复杂度计算函数;M为图块数量。
由于试验采用长宽均为512 的RGB 图像,通过patch partition 模块后切分出的图块个数应为128 ×128,远小于图像像素点个数512 × 512。因此,理论上Swin Transformer更有利于模型的训练。
1.2.2 patch 融合层。为了让图像有层级式的概念,这里要用到类似池化的操作。在Swin-Unet中,Patch 融合层是将图像的高和宽缩小至原来的一半,将图像维度升为原来的2倍。patch融合操作如图3 所示。先将每个图块隔一个像素选取一个数值,将图片切分成4 块,然后将切分开的图块进行通道融合,其维度将会扩大为原图块的4 倍,最后通过全连接层,将其维度压缩为原图块的2倍。
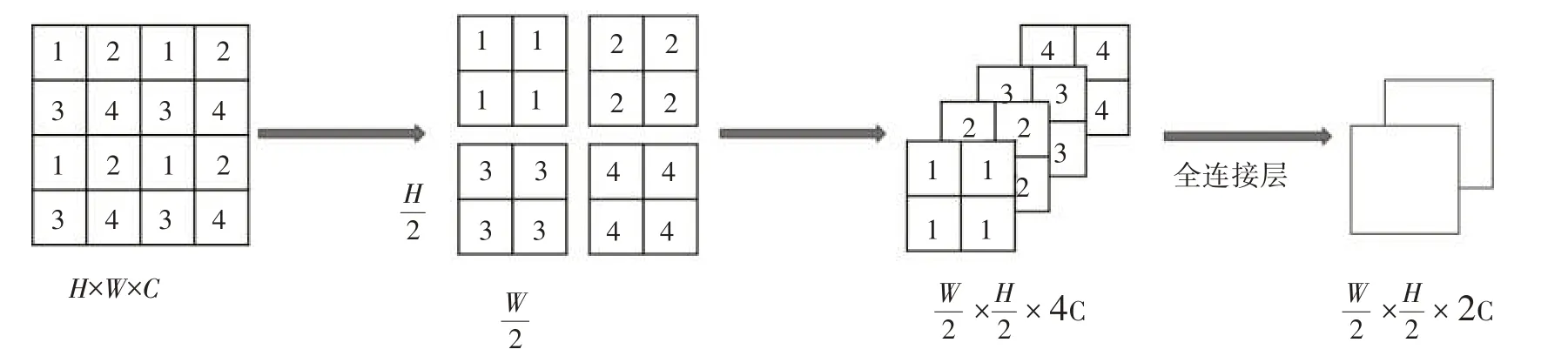
图3 patch merging模块
2 评价指标与数据集制作
2.1 评价指标介绍
混淆矩阵(见图4)是情形分析表,显示以下四组记录的数目,即作出正确判断的肯定记录(真阳性)、作出错误判断的肯定记录(假阴性)、作出正确判断的否定记录(真阴性)以及作出错误判断的否定记录(假阳性)。

图4 混淆矩阵
其中,TruePositive(TP)为样本的真实类别是正类,模型识别结果为正类;FalseNegative(FN)为样本的真实类别是正类,模型识别结果为负类;False Positive(FP)为样本的真实类别是负类,模型识别结果为正类;True Negative(TN)为样本的真实类别是负类,模型识别结果为负类。
2.1.1 F1 score。
精准率(Precision)是指被预测为正样本的检测框,其预测正确的占比,见式(3)。
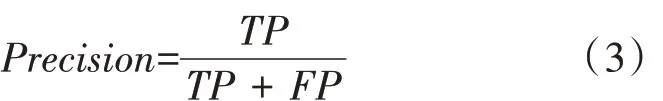
召回率(Recall)是被正确检测出来的真实框占所有真实框的比例,见式(4)。
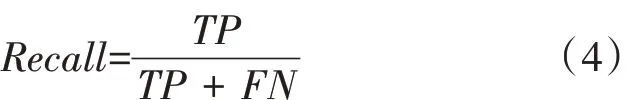
考虑Precision 和Recall 是一对矛盾的度量,为了能够综合考虑这两个指标,引入F1 score,其计算公式见式(5)。

式中:P为精确率;R为召回率。
2.1.2 交并比(IOU)。IOU 是用来评价两个区域的相似性,是度量两个检测框的交叠程度。考虑试验是二分类,且背景所占的比例大,用IOU 作为评价指标比平均交并比(MIOU)更合理,IOU 的计算公式见式(6)。
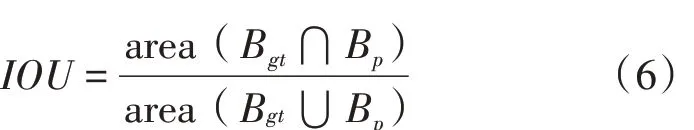
式中:Bgt为真实框,即提前标注好的裂缝框;Bp为预测框,即模型预测出来的裂缝框。
2.2 数据集制作
本研究的裂缝图像采集对象为已投入使用的居民楼,共采集到300 张裂缝图片。采集工具为大疆御Mavic Air2 无人机,无人机携带相机所拍摄的照片最大尺寸为4 800 万像素,所拍照片为三通道的RGB 图像。考虑到图像尺寸过大导致模型难以训练,将采集到的图像裁剪为长宽均为512 的RGB图像。
同时,由于采集到的图像背景过于单一,难以达到泛化的目的。因此,为丰富数据集的多样性,让模型学到丰富的裂缝图像特征,提高模型的泛化性能和复杂背景下裂缝分割的鲁棒性,本研究采用公 共 数 据 集 Original_Crack_DataSet_1024_1024[10]、Concrete Crack Images for Classification[11]、CrackFor⁃est和CRACK500进行辅助训练。从中筛选出3 200张图片用于该试验。其中,包含桥梁裂缝、道路裂缝、建筑外墙裂缝。将这3 518张图片按训练集、验证集和测试集约8∶1∶1 的比例进行划分,即2 918张图片作为训练集、300 张图片作为验证集、300 张图片作为测试集(见图5)。
3 模型对比
为了验证本研究提出的模型的分割性能,采用PSPNet[12]、U-Net、Res U-Net[13]、DeepLabV3+[14]、TransUnet 等5 种模型进行比较。在保证数据集相同的前提下,训练网络模型,并通过验证集测得的评价指标与通过测试集预测出的分割结果进行对模型分析比较。
3.1 评价指标对比
通过比较其精准率、召回率、F1、IOU 来验证训练效果(见表1)。
由表1 可知,Swin-Unet 的识别效果最好,其次是TransUnet,其评价指标分数与Swin-Unet 相差无几,但其训练时间更久,这是因为TransUnet 使用的是全局自注意力机制,图片越大,计算量就越大。在传统的卷积神经网络中,U-Net 的识别效果最佳,但其F1分数与IOU仍略低于Swin-Unet。

图 数据集示例图
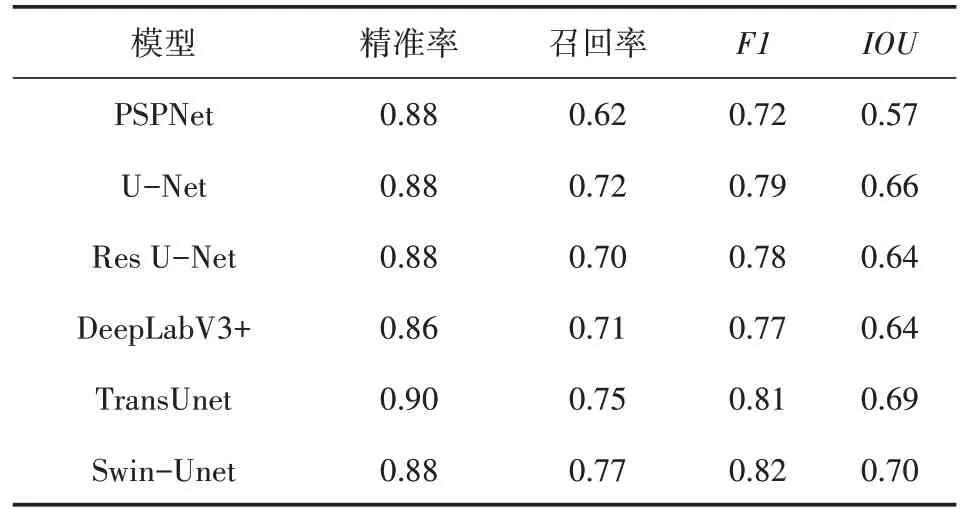
表1 评价指标
3.2 分割效果对比
在测试集中随机抽取4 张图片进行预测,各模型的分割结果见表2。
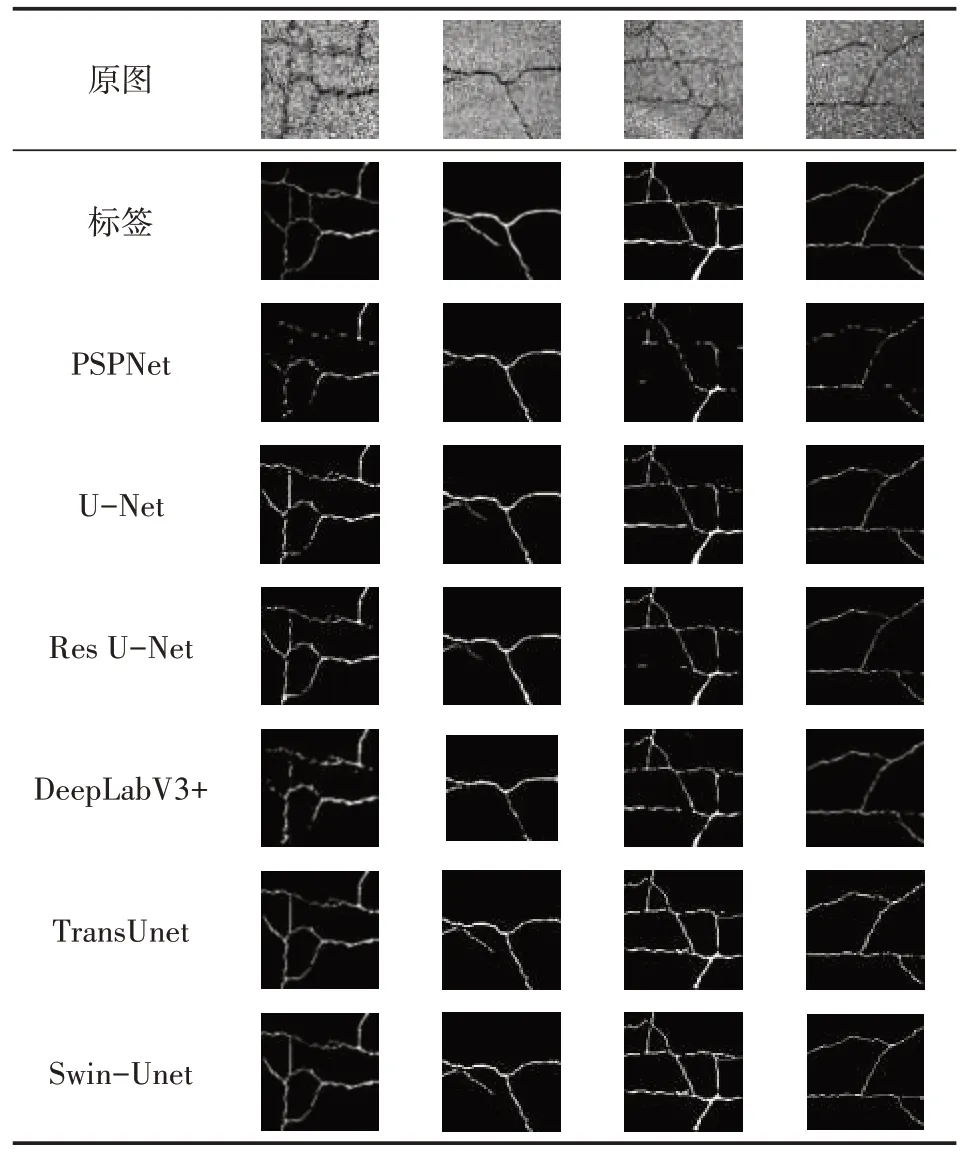
表2 预测结果
对比分割效果可以发现,在传统的卷积神经网络中,U-Net的分割效果最佳,但第1、2、3张图仍有部分地方有较大瑕疵。Swin-Unet 对测试图进行分割,虽有些许瑕疵,但仍然取得最好的分割效果。
4 结论
通过对试验结果进行分析,从评价结果和分割效果两方面进行对比,Swin-Unet 比卷积神经网络有相对较好的检测效果。这表明Transformer 更利于图片特征的提取。对比计算复杂度,并通过试验进行验证,Swin-Unet 与transunet 在数据集、学习率和batchsize 都相同的前提下,Swin-Unet 的训练时间更短,且不降低识别效果。这说明基于窗口的自注意力机制比全局自注意力机制更有利于对模型的训练。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中国惯性技术学报(2019年6期)2019-03-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
第二课堂(课外活动版)(2016年2期)2016-10-21
火控雷达技术(2016年3期)2016-02-06
