
基于Word2vec的铁路工程地质语料库构建与词嵌入
2022-12-22 06:07:40戴均豪
科技创新与应用 2022年35期
戴均豪
(中铁第一勘察设计院集团有限公司,西安 710043)
大量的高质量、多类型的铁路工程地质文字资料随着各地铁路工程勘察设计、建设施工等工作的进行而快速积累[1]。然而,文字资料的利用效率普遍较低,文字资料中蕴含着的大量信息还有待挖掘。
在铁路工程地质领域信息化、智能化的背景下,图件、数据和模型等内容逐步实现了高效获取、自动分析等[2],而文字资料的智能化进展较慢。
自然语言处理(Natural Language Processing,NLP)是计算机问世之后,人们试图探索以自动的方式对自然语言进行加工的方法,NLP本身是一个融会贯通了计算机科学、人工智能、语言科学、逻辑学和心理学等多领域知识与成果的跨学科研究[3]。NLP技术在语义分析、词性标注、实体识别、机器翻译及情感分析等方面已取得一定进展,并具有广阔的探索空间[4]。语料库和词向量是NLP的先导工作,也是文档资料智能处理的基础。
目前存在的语料库及语言模型大多面向通用领域,如维基百科、新闻和微博等。国内外针对特定领域的语料库也逐步开展研究,如国防、医学、新闻与航空等[5-8]。而通用语料和其他领域语料难以适应铁路工程地质工作需要。因此,构建面向铁路工程地质的语料库、训练领域内的语言模型十分必要。
1 Word2vec模型
Word2vec模型等词嵌入方法诞生之前,自然语言处理过程通常将词汇表示成单一的、离散的编号,如独热码表示法(One-hot Representation),其将词语表示成0、1构成的高维向量,维度大小即语料中词汇量的大小,每个词在它的特定维度值为1,其余位置填0。显然,这种方法不能完全表达语义信息,且在计算过程中会造成维度爆炸。
Word2vec将语料的独热码作为输入和输出,用神经网络模型的隐藏层参数当作当前词语的分布式表征(词向量)时,能够很好地获取词语之间的语义关系或语义相似度[9]。Word2vec包括CBOW和Skip-gram 2种词嵌入模型,2个模型都包含输入层、投影层和输出层。其中,CBOW模型训练原理是在已知当前词的上下文的前提下预测当前词,而Skip-gram模型的训练原理是在己知当前词的前提下预测其上下文[10](图1)。

图1 Word2vec模型结构示意图
2 语料库构建
为训练面向铁路工程地质的Word2vec模型,需要构建粒度为“词”的语料库。流程如图2所示。
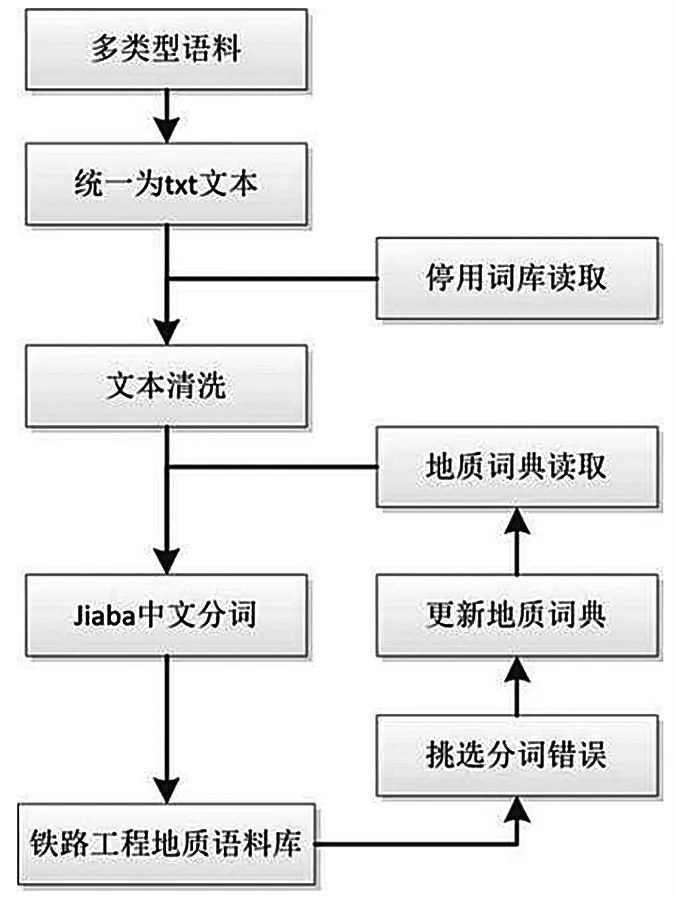
图2 语料库搭建流程图
2.1 语料收集
本文针对铁路工程地质领域,收集了如下几方面的语料:①领域相关的文献300篇;②相关规范及工作手册23册;③各环节程序文件105份;④教材和专著等11部。
2.2 预处理
以上各方面语料需统一为.txt文本格式以便于输入计算机处理,随后统一存放、利用Python中的os函数库对路径下的全部文件进行读写合并,形成生语料。将上述语料删除乱码、空行、特殊字符与字母数字等难以利用的文本。另外,将与文本语义无关的语气词、介词、连词、定语,以及停用词删除。经过上述2方面的文本清洗工作,随后将语料利用Jiaba中文分词函数库进行分词。
Jiaba函数库可以对日常用语进行分词操作,但是对于专业名词繁多的地质文本的分词效果不好,此时需要准备《地质辞典》中的词汇供Jiaba读取,来提升分词效果。另外,需要将工程地质学、岩土工程勘察及铁路工程施工等各分支学科下的复杂专业名词汇总到地质词典中。
分词后形成了可以输入Word2vec的训练语料。但其中难免有个别专有名词没有被词典收录,需要根据分词结果文件,挑选未分词、误分词的词语,加入已有词典。重复分词、挑选分词瑕疵,如此往复,以寻求分词效果的最大化,以获得质量最佳的语料库(图2)。最终获得的语料库总词数为4 192 189词,并完善铁路工程地质词典37 975词。
2.3 词频统计
为了实现快速理解语料主要概述内容,对构建的语料库进行词频统计,可以绘制“词云”图、对语料库做简单的关键词提取[11]。由图3可知,文字比例越大表示其重要度越高,“工程”“结构”“地质”“形变”等词汇重要性最高。

图3 铁路工程地质语料库词云
3 词嵌入
3.1 词向量训练
本文选用Word2vec模型中的Skip-gram模型来进行词嵌入。Skip-gram是一种简单却实用的词嵌入模型。在输入层输入该词的独热码,在第一个隐层,输入该编码的线性映射W*x+b(x即为该词的独热编码,W、b为参数),第三层可以看成分类器,使用Softmax回归。训练样本是当前词和上下文词的One-hot编码,模型的输出为输入词的上下文取词窗口中出现词汇表中各词汇的概率[10]。
依照上述方法,对前述工作中形成的语料库输入Skip-gram词嵌入模型进行训练,规定batch-size、词嵌入维度、上下文取词窗口大小及负采样样本数量等超参数,获取词嵌入文件。此处词嵌入初始维度为300维,即每个词语映射在300维的向量空间中。
3.2 降维可视化
对于训练好的300维词向量,由于维度过高,不便于理解和观察,可以利用t分布随机近邻嵌入(t-SNE)算法进行降维可视化[12]。本文随机抽取所有词向量中的500条词向量,由300维投影至二维,即可在平面直角坐标上刻画各条词嵌入的结果。由图4可知,在向量空间中距离相近的词语蕴含着较高的语义相似度,如“不良地质”“地质灾害”“滑坡”“泥石流”等词汇语义相似度较高。

图4 铁路工程地质词向量降维可视化
3.3 语义相似度计算
词向量在高维空间中的欧氏距离,可以表达词与词之间的语义相似度。利用Gensim库中的Similarity函数可以计算词向量之间的语义相似度[13]。为检验训练的词向量的有效性,可选取具有连续性规律的地质名词来计算语义相似度。本文选取“侏罗系”来计算其和其他年代地层名词来完成有效性验证。由图5可知,随着地质年代关系越远,语义相似度也越低。

图5 年代地层名词间语义相似度
3.4 聚类
为检验所训练的语言模型能否有效区分2类铁路工程地质词汇,将年代地层名词与岩性名词的词向量进行聚类后可视化。由图6可知,2类词汇的词向量投影位置有着较为明显的区分,绝大部分都聚类正确。

图6 年代地层与岩性名词聚类可视化
4 结论
利用NLP技术,针对铁路工程地质领域开展语料库构建和词向量训练,得到以下结论。
(1)本文完善了1套构建铁路工程地质语料库的方法流程,构建了4 192 189词的语料库,完善了37 975词的地质词典。
(2)本文在语料库基础上训练了Word2vec模型,获取的词向量能够准确表达语义,为后续铁路工程地质文本语义分析、实体识别等应用完成前期基础。
猜你喜欢
河北地质(2021年2期)2021-08-21 02:43:46
智富时代(2019年6期)2019-07-24 10:33:16
中国资源综合利用(2017年4期)2018-01-22 02:46:58
水利规划与设计(2017年12期)2017-02-06 03:40:03
海外华文教育(2016年1期)2017-01-20 08:21:58
高中生·天天向上(2016年9期)2016-11-22 09:10:34
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
河南科技(2014年18期)2014-02-27 14:15:14
