
基于ALBERT预训练模型生成式文本摘要
2022-12-22 07:14许文军郑肇谦
长春工业大学学报 2022年6期
许文军, 郑 虹, 郑肇谦
(长春工业大学 计算机科学与工程学院, 吉林 长春 130102)
0 引 言
文本摘要[1]是一项非常重要的任务,人们也提出了很多解决文本自动摘要的方法。目前有两种比较主流的方法,即抽取式摘要和生成式摘要。抽取式摘要是一个从句子中提取的句子组成的摘要,所以组成句子之间的紧密性不强,从而降低了用户对原文本的理解,无法完全满足人们的需求。因此,生成式摘要就此产生。生成式文本摘要主要利用自然与处理技术对原文本进行深度理解,然后用生成式文本摘要模型模拟人类的思维方式对原文本进行概括总结,最终形成摘要。与抽取式摘要不同的是,生成式摘要中的词语和句子不全来自于原文,会生成新的词语和句子,在表达方式上具有多样性。因此,生成式摘要更接近人工生成的摘要,符合人们对摘要的要求。
1 相关工作
随着深度学习在自然语言处理领域的不断应用,各种新的模型被提出。Ganesan K等[2]提出基于图方法的生成式摘要模型,首先要输入文本来构建图,然后再根据构建好的图生成摘要。See A等[3]首次提出指针及覆盖网络机制。在摘要片段生成的过程中,通过指针控制从原文中选择生词或者是从字表中选取生词进行生成,解决了摘要片段生成中可能出现的未注册登录的生词问题,引入了一种覆盖机制来有效地解决摘要中的词语或短语重复问题。2018年,Lin J等[4]首次提出一种基于序列到序列模型的卷积神经网络,用来在文章层次上获得语义表示,以减少摘要生成时的语义无关。2019年,Song K等[5]提出的MASS是一个基于序列到序列框架的预训练模型。2020年,Zhang J等[6]提出PEGASUS基于预训练的序列到序列的模型。张丽杰等[7]采取TF-DF、LDA、位置权重指派与MMR相结合的方式,对不同的句子分配不同的权重,提出了抽取式摘要模型。Mehdad Y等[8]提出基于图的生成式文本摘要模型,利用查询语句从输入文本中获取语句的重要信息,再用聚类方法对语句特征的相似度进行分析。在摘要生成的过程中,根据路径权重以及排序得分来选择最佳路径作为生成摘要。
2 文中模型与方法
2.1 ALBERT预训练模型
随着大量预训练模型的提出,如ELMo[9]、OpenAI GPT[10]、BERT[11]等已经广泛用于文本生成任务[12]。文中提出一种基于预训练的新型自然语言生成模型,设计了一个两阶段的解码过程,充分利用ALBERT模型[13]提取上下文信息等特征。第一阶段,使用一个单向上下文向量的解码器来生成摘要。第二阶段,掩盖了摘要中的每一个词,并使用解码器逐个预测细化的词[14]。为了进一步提高生成序列的自然性,将强化目标与解码器结合。文中提出的ALBERT模型适用于中文文本,在显著降低参数量的同时,对BERT模型在生成文本任务中的欠缺表现加以改进,有效提高了模型生成文本摘要质量。ALBERT模型结构如图1所示。
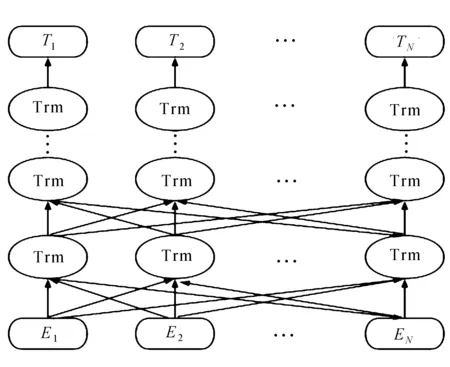
图1 ALBERT模型结构
图中,E1,E2,…,EN表示输入文本,而T1,T2,…,TN表示最终得到的文本序列特征向量。
2.2 双向的预训练上下文编码器
在序列到序列框架的生成式模型[15]基础上,提出一种基于神经注意力机制的序列到序列模型。此模型是为了生成概率最大化的目标序列,在编码和生成的过程中,注意力机制关注文本中最重要的位置。表示为
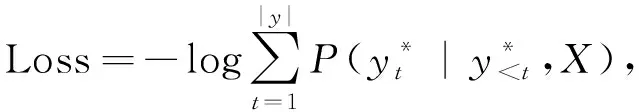
(1)

X----输入序列;
y----输出的摘要。
传统的序列到序列的生成模型在解码过程中只考虑了单向的上下文信息。这可能会导致模型的性能下降,因为完整的上下文信息包含前面的信息和后面的信息。以往的方法是通过改进注意力计算[16]来缓解这一问题,文中我们证实了双向的上下文信息比单向的上下文信息更好地解决了这一问题。ALBERT是由几个层组成。在每一层中,首先有一个多头自注意子层,然后是一个具有残差连接的线性仿射子层[17]。在每一个自注意力子层中注意力得分eij首先被计算出来。
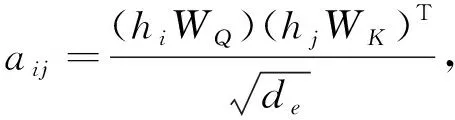
(2)
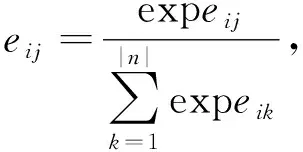
(3)
式中:i,j----输出和输入向量序列的位置,i,j∈[1,N];
de----输出维度;
WQ,WK----矩阵参数。
然后计算输出,公式为
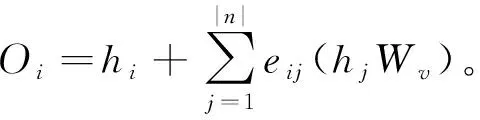
(4)
这是通过先前的输出hi相加得到h所有的加权和。最后一层的输出序列是输入序列的上下文编码。
使用ALBERT模型的预训练上下文编码器时,在训练前输入完整的序列,它们可以通过双向的上下文调节模型词级表示,更好地解决序列不匹配等问题。基于ALBERT基础上构建的序列到序列框架,文中设计了一个词级的细化解码器来解决上述问题。对于有效减少曝光偏差的问题,还引入了一个离散目标的细化解码器。模型的总体结构如图2所示。
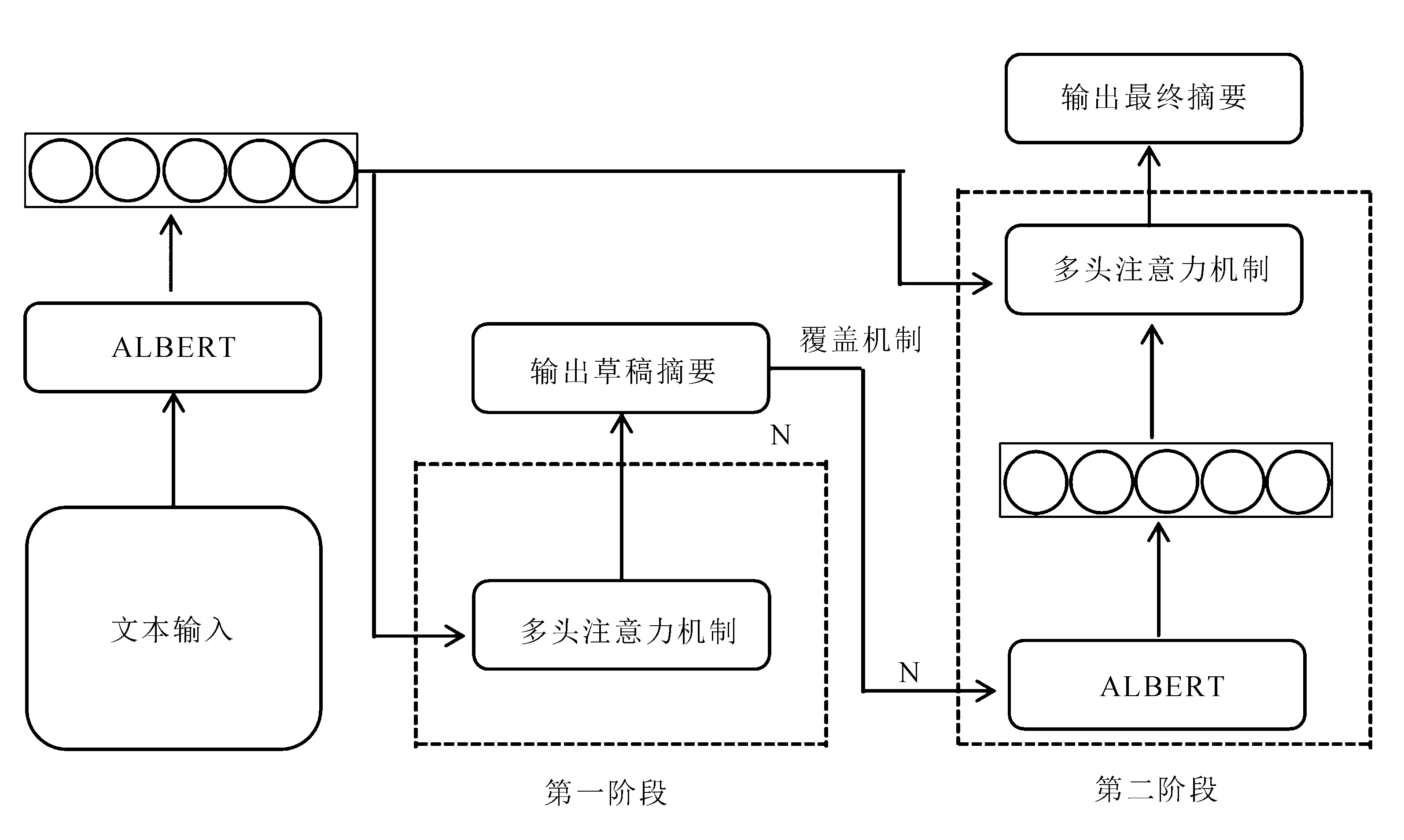
图2 文中模型结构示意图
3 基于ALBERT预训练生成式模型
3.1 ALBERT编码器
将输入文档表示为X={x1,x2,…,xm}。 相应的摘要表示为Y={y1,y2,…,yL},L代表摘要长度。给定输入文档X,首先通过单向的上下文解码器预测摘要,通过产生的摘要可以控制上下文的长度,并改进摘要的内容。在编码器端输入文本X转化为向量H={h1,h2,…,hm},然后将向量输入到解码器并生成摘要A={a1,a2,…,a|a|}。使用ALBERT作为编码器。首先将输入序列转化为词嵌入,然后计算文本的词嵌入作为编码器的输出。
H=ALBERT(x1,x2,…,xm)。
(5)
3.2 ALBERT解码器
在解码器中使用ALBERT的词嵌入矩阵,在时间步长t时将之前的摘要输出{y1,y2,…,yt-1}加入到词嵌入向量{q1,q2,…,qt-1}中。由于解码器的输入顺序不完整,所以引入一个N层Transformer的解码器来学习条件概率P=(A|H)。基于Transformer的编码器-解码器的多头注意力机制可帮助解码器学习摘要和源文档之间的软对齐。在第t时间步长时,解码器结合之前的输出和编码器的隐藏层表示预测并输出条件概率为
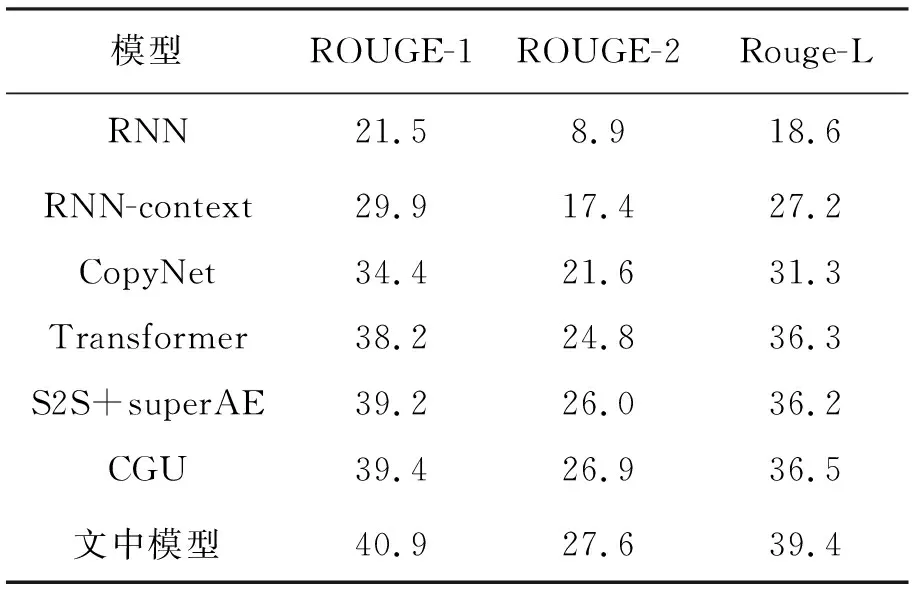
q 每个生成的序列将在带有特殊“[PAD]”的位置被截断。解码器的摘要过程如图2的第一阶段所示。 (6) (7) 在解码过程中往往一些出现在文档中的词是词汇表之外的词,为了解决未登录词问题,采用了基于复制机制[18]在Transformer解码器上。在解码器时间步长t处,使用Transformer最后一层解码器输出ot与编码器输出hj的双线性点积计算源文本X上的注意概率分布, (8) (9) 然后计算复制门gt∈[0,1],从源文本和产生的词汇中进行软选择。Wc,Wg,bg是参数, gt=sigmoid(Wg·[ot,h]+bg)。 (10) 使用gt计算复制概率和生成概率的加权和,得到扩展词汇的最终预测概率v+x,其中x是源文档之外的未登录词。最终概率的计算方法为 (11) 提出一种新的优化解码器,草稿解码器的输出作为优化解码器的输入,并输出一个优化之后的摘要。如图2的第二阶段所示,首先掩盖摘要草稿中的每一个词,然后将草稿提供给ALBERT以生成上下文向量。最后,利用与草稿解码器相同的N层Transformer解码器预测一个改进的摘要词。在第t个时间步长,输入摘要的第t个字被掩码,解码器通过摘要中的其他词来预测优化的词。此过程的学习目标为 (12) 并且a≠t={a1,…,at-1,at+1,…,a|v|}。 草稿解码器和优化解码器之间共享参数,因为单独使用参数会大大降低模型的性能。原因可能是在训练过程中使用了Teacher Forcing训练机制,因此词级精简解码器学会了根据给定的词来预测新的词。这类似于语言模型的预训练,但可能不足以使解码器学习生成精练的摘要。所以在模型中所有解码器共享相同的参数。 在模型训练期间,目标是使生成序列的对数似然性最大化。此过程中将出现不匹配的现象,而这种不匹配会损害模型的性能,因此在模型中添加了离散目标,并通过以下方法对其进行优化,引入策略梯度法,摘要草案过程的离散目标为 (13) 其中草稿摘要从预测分布中采样,R(as)为奖励分数与标注摘要对比。为了优化离散目标和生成可读序列之间的平衡,在实验中使用ROUGE-L。将离散目标与最大似然目标混合。显示解码过程的最终目标为 (14) 优化过程中也引入了类似的目标。 在模型训练期间,模型的目标是两个过程中目标的总和,并使用了“Teacher Forcing”算法,将标注摘要提供给每个解码器,并最小化以下目标。 (15) 在测试阶段的每个时间步长通过 选择预测的单词,使用集束搜索生成草稿摘要,并使用贪心搜索生成精练的摘要。 实验使用的训练数据集为LCSTS,包括训练集、测试集、验证集[19]三个部分,训练集包含2 400 591组数据(包含文本和摘要),验证集包含10 666组数据,测试集包含1 106组数据,LCSTS数据集具体且不抽象,常作为文本生成领域的数据集。 本实验融合ALBERT预训练模型,使用ALBERT字表,大小为21 128字,字向量维度大小为768,并把解码器层数和多头注意力数分别设置为与编码器相同的12层和12头。针对LCSTS数据集,批大小设置为16,输入字符最大长度为130,输出文章字符最大长度为30。在测试阶段使用束大小为3的集束搜索。 ROUGE是文本自动摘要领域摘要评价技术的通用指标之一,文中选择使用ROUGE-N和ROUGE-L作为模型的评价指标,下面详细介绍ROUGE-N和ROUGE-L方法。ROUGE-N中的N指的是N元词的模型,通常情况下,N∈[1,4],使用ROUGE-1、ROUGE-2、ROUGE-L作为评价指标,对摘要结果进行评价。 文中模型将对比以下使用LCSTS中文数据集的基准模型,并从相关文献中直接抽取实验结果。 4.4.1 RNN和RNN-context 模型在RNN的基础上加入了注意力机制。 4.4.2 CopyNet[20] 使用RNN作编码器,解码器采用生成模式和拷贝模式。 4.4.3 S2S+superAE[21] 在训练模型阶段用Auto encoder监督Sesq2Seq模型的学习,以提高encoder的性能。 4.4.4 CGU[22] 基于全局编码的Seq2Seq模型,通过设置全局门控单元对编码器的输出信息进行筛选。 4.4.5 Transformer 基于注意力机制的Seq2Seq模型,且具有较好的并行能力。 4.4.6 文中模型 将文本通过预训练模型ALBERT编码表征,再输入到Transformer解码器中生成摘要,ALBERT更好地输出上下文信息,并和Transformer一样都是文中的基础模型。 文本摘要在LCSTS上实验结果见表1。 表1 文本摘要在LCSTS上实验结果 从表中可以看出,文中提出的模型ROUGE评价结果相比于其他模型有较大的提升,ROUGRE-1、ROUGE-2、ROUGE-L均高于其他模型。文中模型在生成摘要的正确性、连贯性和表达性上都有一定的提升。 为了对比文中模型和CGU模型以及基于Transformer模型在实际案例中生成摘要的性能,从LCSTS数据集中抽取两个案例文本进行分析展示,见表2。 表2 文本摘要实例 续表2 第一个案例中,Transformer模型和CGU模型只片面地总结了摘要中的内容,在语义理解上存在偏差。说明了使用ALBERT后提升语义理解的准确性。 第二个案例中,Transformer模型和CGU模型没能准确总结文本的主旨,而文中模型与参考摘要最为接近,能很好地抓住文章的主旨。 综合上述两个实际案例,提出的模型不仅较好地综合了生成式文本摘要模型的语言流畅性高的优点,而且能够较好地抓住全文关键信息,准确地表达原文含义,同时较好地展现了双向上下文信息,与参考摘要更接近。 提出基于ALBERT的预训练文本摘要模型,为使词向量带有上下文语义特征,引入ALBERT预训练模型。为使生成的序列更自然且不重复,引入双向的预训练上下文编码器。为了解决未登录词问题,采用复制机制。为使生成摘要质量更高,提出摘要优化过程,设计了一个草稿解码器和优化解码器。最后,使用集束搜索解码算法进行解码,最终生成摘要,并且模型也取得很好的实验结果。 虽然文中提出的模型实验效果优于之前提出的模型。但在生成摘要阶段使用传统的集束搜索技术,生成的摘要偶尔会概括一些不太重要的信息。为了解决这一问题。下一步会采用指针生成网络,生成更精确、质量更高的摘要。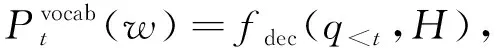
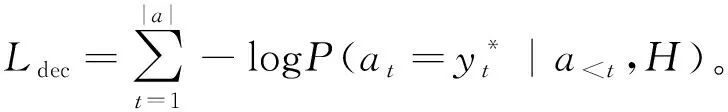
3.3 复制机制
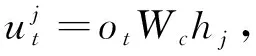
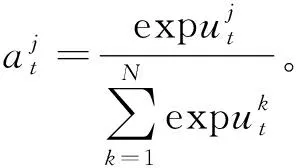

3.4 摘要优化过程
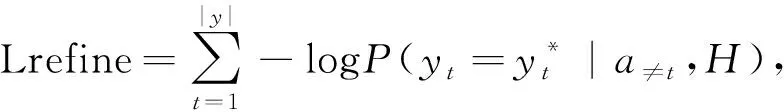
3.5 训练与推理
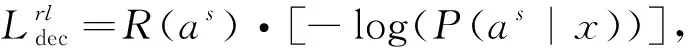
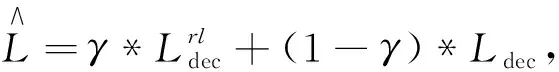
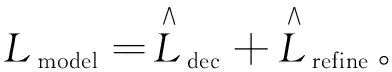
4 实验及结果分析
4.1 实验数据集
4.2 实验设置
4.3 评估指标
4.4 结果与分析


5 结 语
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
小学生必读(低年级版)(2021年10期)2022-01-18
锻压装备与制造技术(2021年5期)2021-11-13
考试与评价·七年级版(2021年4期)2021-08-14
读写月报(初中版)(2021年12期)2021-05-25
科学技术创新(2021年5期)2021-03-17
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
——编码器
演艺科技(2020年7期)2020-08-13
家庭影院技术(2019年8期)2019-12-04
