
基于改进的Vision Transformer杂草生长周期识别方法研究
2022-12-22 07:14王贵参杨承林蒲佳佳伍俊霖王红梅
长春工业大学学报 2022年6期
王贵参, 杨承林, 蒲佳佳, 伍俊霖, 王红梅
(长春工业大学 计算机科学与工程学院, 吉林 长春 130102)
0 引 言
农业是社会发展中支柱性基础产业,为社会的快速发展提供最基础的保障。我国具有丰富的农业耕地,在农业方面发展具有巨大的潜力。但是,农业灾害的出现也危害着农业的快速发展,例如杂草、病虫灾害等因素给农业带来巨大损失[1]。目前,人力除草已逐渐淘汰,传统的粗放式大面积化学除草也带来了许多不利的影响,精准式喷洒技术是根据杂草的生长周期情况定点定量喷洒除草剂,既能降低对田间生态环境的影响,又能提高除草效率[2]。
在早期杂草生长阶段,杂草叶片数量与生长期直接相关,因此,可以根据叶片的数量识别杂草生长的阶段。近几年来,因为卷积神经网络(Convolutional Neural Networks, CNN)能够提取图像的有效特征,使得计算机视觉领域得到快速发展[3],并在农业领域得到广泛应用,例如杂草分类[4]、杂草检测[5]、害虫生长识别[6]和植物病虫害检测与诊断[7]。Abdalla A等[8]通过迁移学习方式融合不同的CNN模型,对杂草密集区域进行分割,取得了显著的效果。但是使用神经网络进行训练模型需要叶子在实例级别上进行完全分割,对于每张图片的处理可能需要较长的时间,整体效率不高[2]。Teimouri N等[9]使用Leaf-Countinng数据集训练一个卷积神经网络,该模型不需要进行实例级别上的分割操作,提升了检测速度,但识别成功率较低。
使用传统卷积网络进行杂草检测需要进行像素级别的分类任务,并采取额外的措施进行处理,这增加了整个过程的复杂性。随着Transformer[10]结构模型的出现,贾伟宽等[11]通过优化Transformer结构,在拥有复杂背景的果实检测中获得良好的效果。
综上所述,传统模型对复杂环境下杂草的识别需要进行多步操作,难以实现整体的自动化。由于卷积神经网络设计的模型需要进行实例分割,所以带来识别效率变低、准确率不高的问题。文中通过对Vision Transformer[12]的改进,运用神经网络提取丰富的语义特征,对复杂环境下杂草不同生长周期的特征进行识别。
1 基本原理
1.1 Vision Transformer结构介绍
随着Transformer结构模型在自然语言处理(Natural Language Processing, NLP)领域的广泛应用,越来越多的学者希望将Transformer结构模型应用到图像领域。Dosovitskiy A等[12]提出Vision Transformer网络模型,不再将整张图片变成一维向量输入,而是将图片进行分块处理,使得模型产生的参数量和计算量减少。图像分块处理如图1所示。
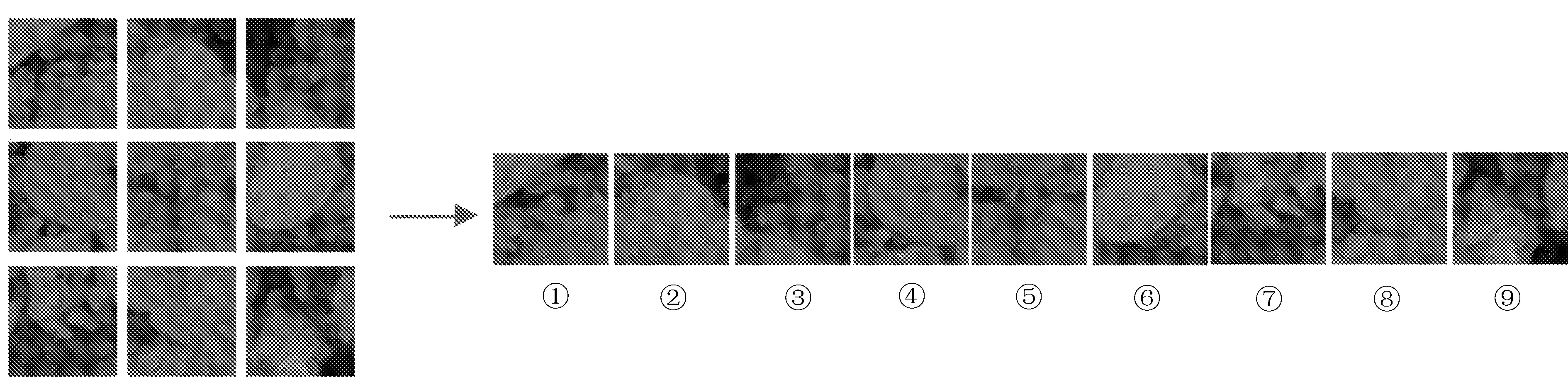
图1 图像分块操作
与传统的卷积神经网络和循环神经网络架构模型不同的是,Vision Transformer采用自注意力(Self-Attention)机制进行信息融合。其模型具有参数量少、复杂度低的优点。如此众多的优点使得Attention机制的模型广泛应用在NLP领域,如我们耳熟能详的BERT模型[13]、GPT3模型[14]都是基于Self-Attention机制的模型。Self-Attention计算过程为
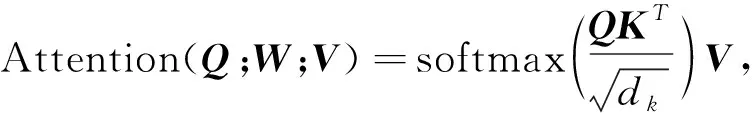
(1)
式中:Q----Query矩阵;
K----Key矩阵;
V----Value矩阵;
dk----Key矩阵的维度。
Vision Transformer使用了原始Transformer中的Encoder部分,同时在Encoder Block块中使用了多头注意力机制(Multi-Head Attention, MSA)。Transformer Encoder Block模块如图2所示。
图2中的多层感知机(MLP)子模块如图3所示。
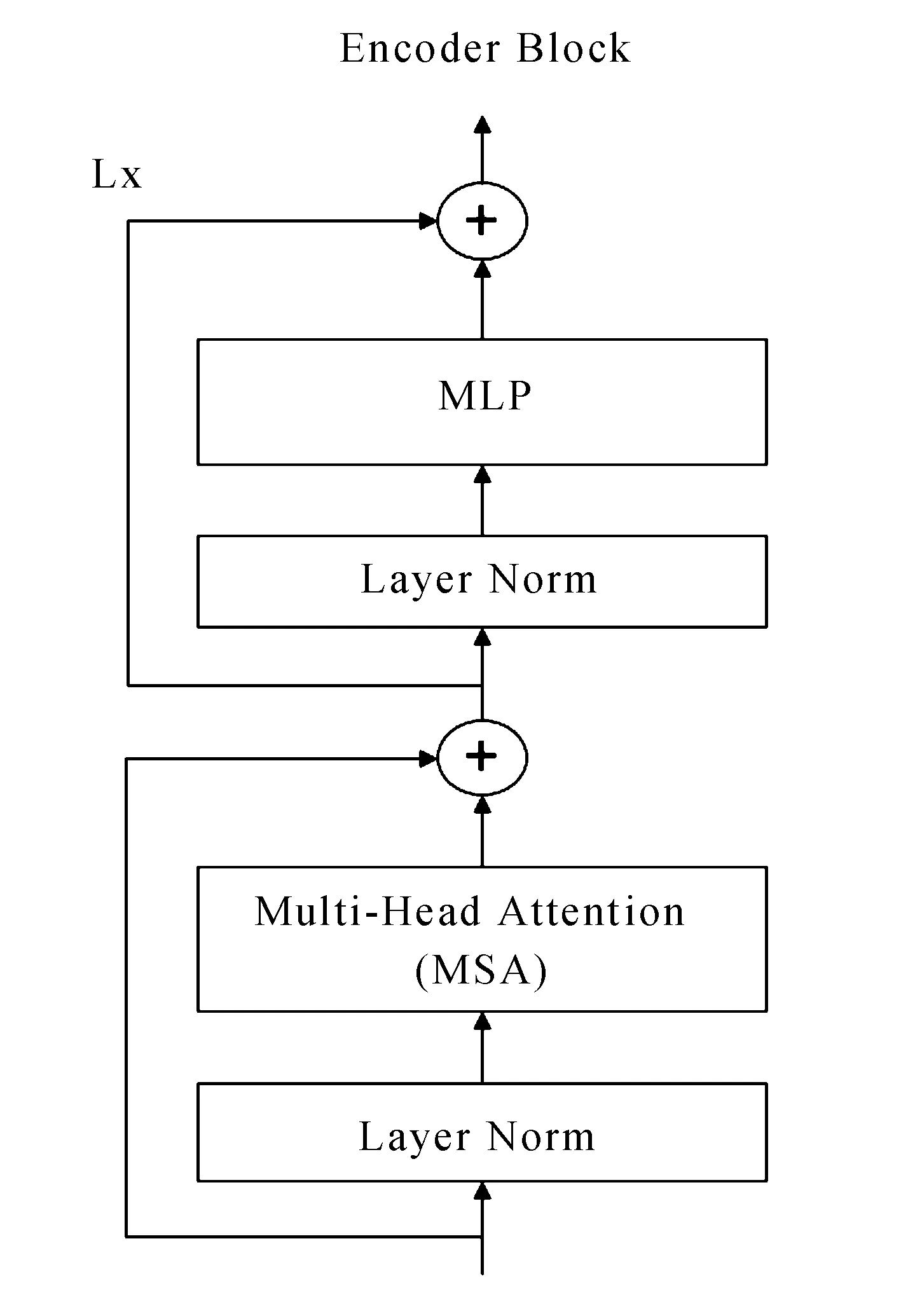
图2 Encoder Blocker 模块
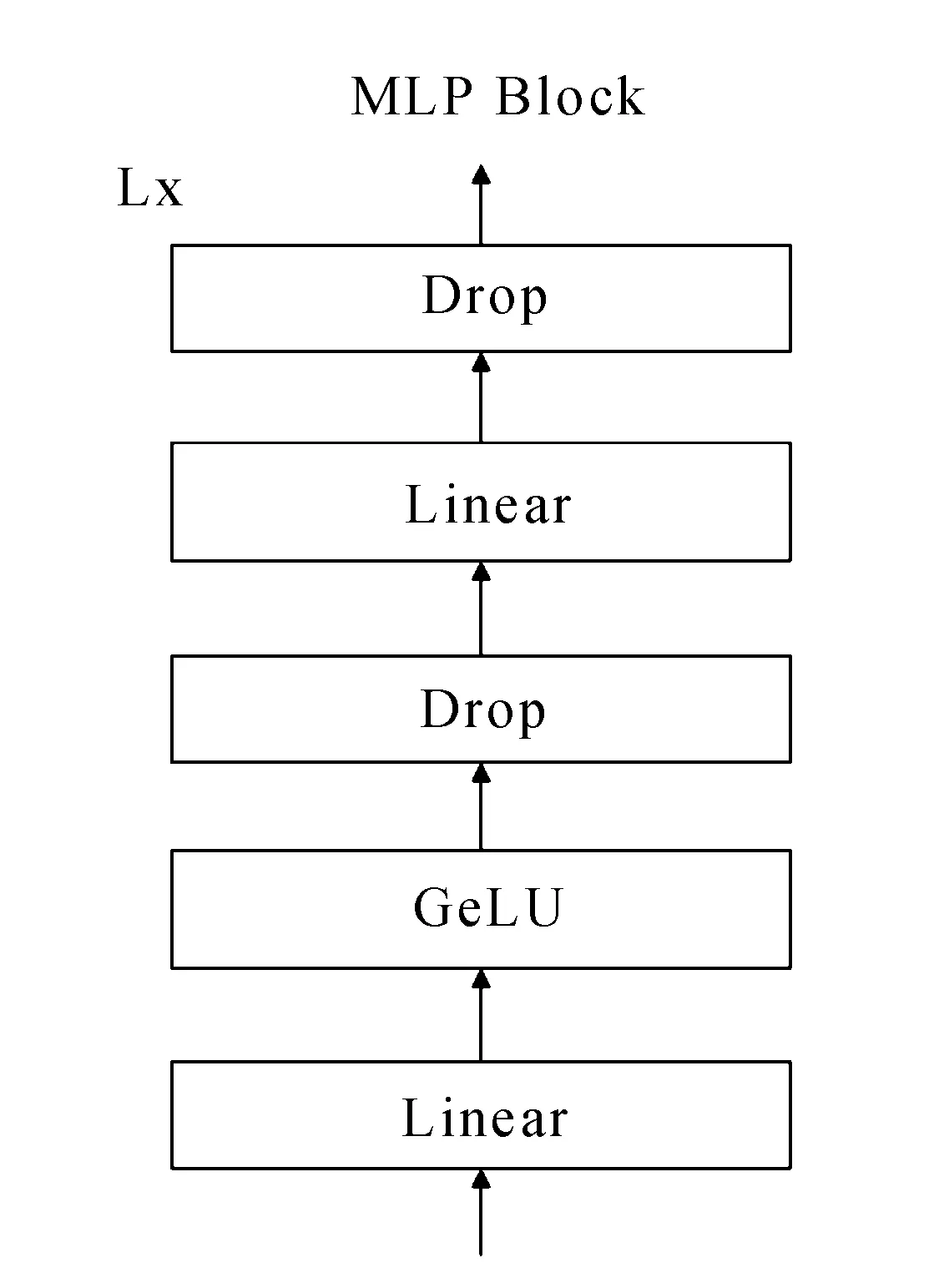
图3 MLP Block模块
整个MLP模块的作用是进行线性变换,通过先升维后降维的方式进行信息融合,在两次线性变化之间使用GeLU作为激活函数,并添加Drop操作来增加模型鲁棒性。
Transformer为处理二维的图像信息,采用将图像切分的做法。首先将输入图像x∈RH×W×C进行重塑到x∈RN×(P2×C),其中,P为分割块(patch)的尺寸,N为输入序列的长度,C为通道数。将分割块的图像信息、位置信息及图像类别信息重塑到一维向量作为输入,
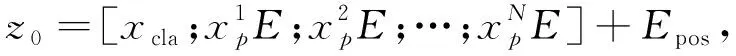
(2)
式中:xcla----可学习的嵌入向量,与其他向量维度一样,它的输出进行分类预测;
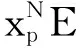
Epos----序列的位置信息。
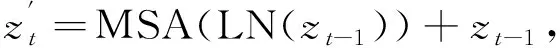
(3)
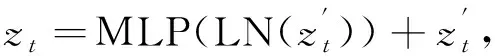
(4)
式中:zt-1----上次Encoder Block模块的输出值;
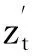
zt----本次Encoder Block模块的输出值。
经过Encoder Block处理后的信息再经过一个LayerNorm层处理,

(5)
1.2 Inception结构介绍
增加网络深度和宽度是提升网络性能最直接的方案,但也会带来诸多问题:网络越大,参数越多,使得计算复杂度越高;网络越深,则会出现梯度弥散问题,难以优化模型。研究者希望在增加网络深度和宽度的同时减少参数,在这种需求和形势下,Szegedy C等[15]提出了Inception结构方法。
随着近几年来的计算机技术快速发展,多层螺旋CT不断的发展,明显提高球管转以及时间分辨率。除此之外,旋转1周探测器可以覆盖扫描范围约为3240 mm,因此,5 s内即可完成心脏检查,从而明显提高临床检查成功率。相关研究对130例研究对象(均无临床症状,而心电图检查阳性、ECT检查结果显示冠状动脉缺血改变)实施64层螺旋CT冠状动脉造影检查、经皮选择性冠状动脉造影检查,其检查结果显示,64层螺旋CT冠状动脉造影检查的灵敏度(54.60%)、特异度(95.10%)、阳性预测值(77.60%)、阴性预测值(87.10%)及准确度(85.50%)均更高(P<0.05)。
Inception结构是把模块化的思想引入其中,把多个不同大小的卷积核或池化操作放在一起组装成一个网络模块,并将模块放入网络结构。使用统一大小的卷积核对不同大小目标作用不一样,进行卷积容易出现漏检现象,使用多个尺度的卷积核进行卷积运算能够有效减轻漏检问题,进而提取到更多的深层次信息。
2 杂草图像识别模型网络结构
通过学习以上基础网络知识,结合杂草的特征,提出如下进行杂草生长周期识别研究的网络模型,具体模型结构如图4所示。
文中提出的网络模型主要由Transformer骨干层、多尺度卷积层和分类层三部分组成。将Vision Transformer-base16作为主干网络,并对其做如下修改:去掉在线性变化单元添加一个空Token的操作,将分类头单元去掉。给定输入图像时,将图像分块并通过线性层进行展平,同时与位置编码信息(Postion Embedding)进行相加。通过主干网络产生特征信息,将得到的信息进行维度交换,并且重塑。然后在主干网络后使用连续的两个1×1卷积层进行信息提取。将四个分支结构运用在多尺度卷积层,分别进行1×1卷积、3×3卷积、5×5卷积和池化操作,为减少计算量,使用两个3×3卷积代替5×5卷积,并为进一步降低计算量,引入连续非对称卷积替换传统卷积,将3×3卷积替换成1×3卷积和3×1卷积,这样不仅增加了网络深度,也减少了参数量,进而降低了模型的过拟合风险。将多尺度层提取到的信息进行拼接,并进行信息融合。在分类层,先将卷积后的特征图进入一个全局平均池化层(GAP)进行降维,最后使用Softmax函数对杂草图像进行识别分类。
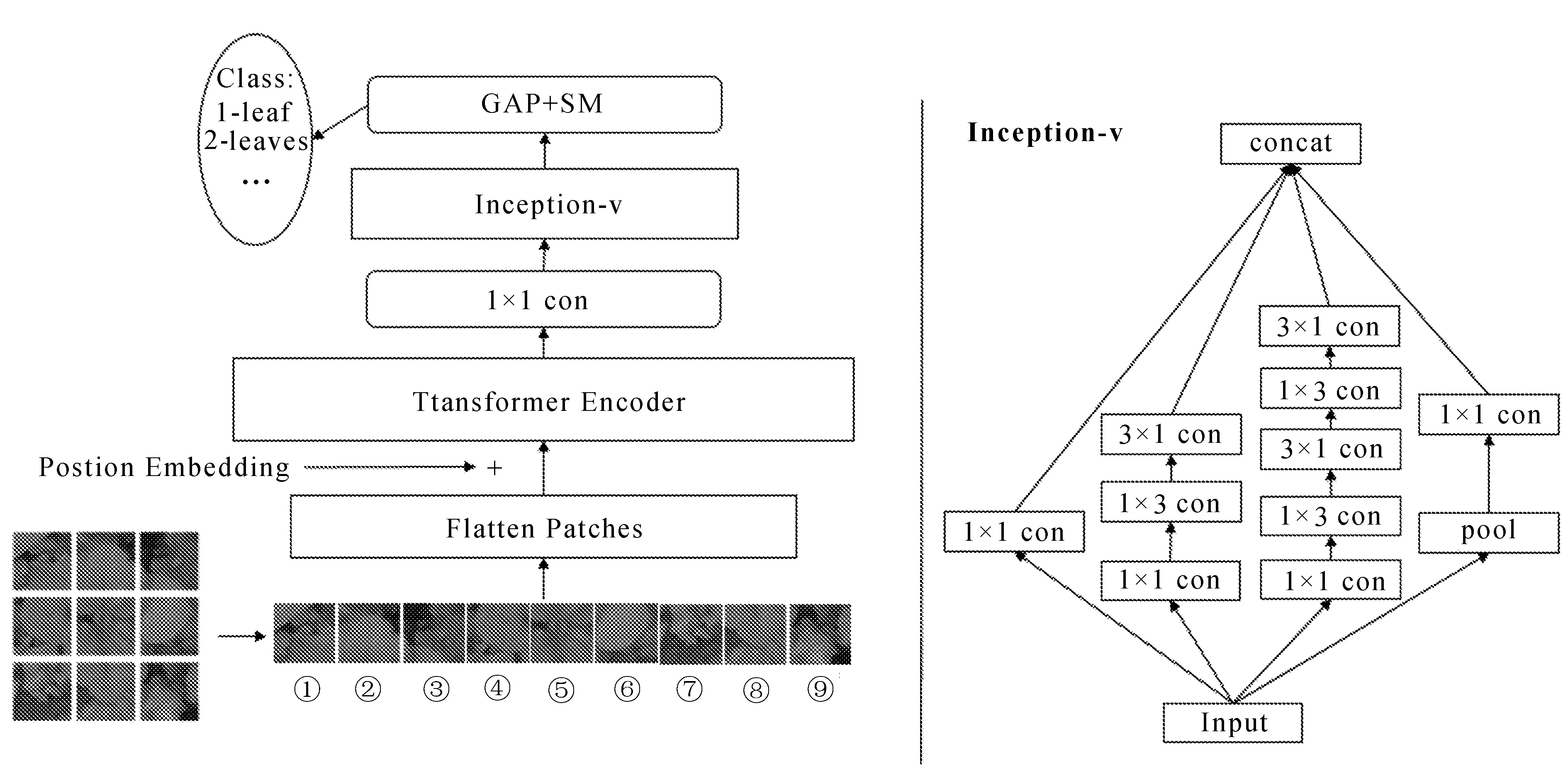
图4 模型结构
3 实验与分析
3.1 实验环境和参数设置
文中所有实验在Linux系统下实现,操作系统为Ubuntu20.04,运行环境的GPU显卡为NVIDIA GeForce RTX 3090,显存24 GB,基于Python3.7进行编程,所使用的深度学习框架为Pytorch。整个训练过程中,使用Adamw优化器进行优化网络,将初始学习率设置为0.001,在训练过程中,模型的批次大小为128,beats设置为(0.9,0.99)。
3.2 数据集
选用Leaf-Counting[9]作为实验数据集,如图5所示。
图5 数据集
在本数据集基础上进行模型设计和评估。本数据集是专门用于深度学习研究农业杂草生长周期识别模型工作的数据集,由专业人士使用手机、相机或工业级别相机拍照获取,图像获取来自丹麦的各个地区不同环境条件下,包含不同的土壤类型、图像分辨率和不同的光线条件。这些照片是在三个季节收集,包含了18种类别的9个生长周期。各个生长周期杂草数量见表1。
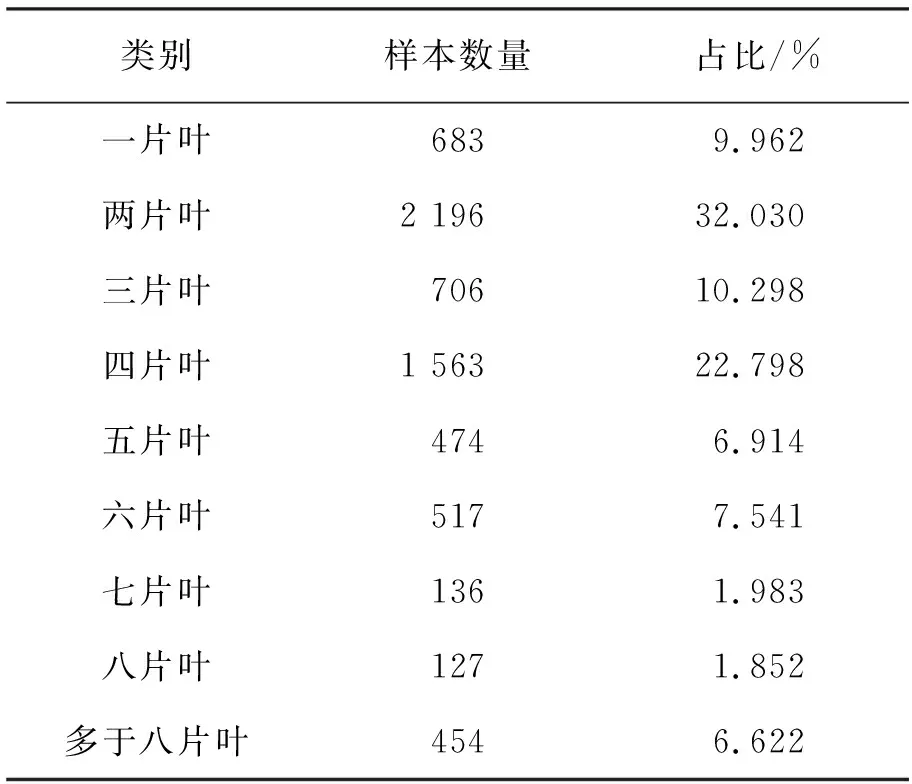
表1 各生长周期杂草数量
实验所用数据集共有图片9 372张,其中训练集6 856张,测试集2 516张。
3.3 预处理
通过表1可知,不同生长周期的杂草数量存在严重的分布不均衡问题,需要对其进行预处理,使不同生长周期的杂草样本数量差距降低。对数据集进行如下预处理,将训练集中数据量较低的类别图像通过随机旋转、翻折,改变图片的亮度、对比度、添加随机噪声等操作进行数据扩充,如图6所示。
扩充后的各类生长周期杂草数量分布比较均匀。为降低网络训练的参数量,加快网络训练速度,将样本大小调整为224×224的尺寸。
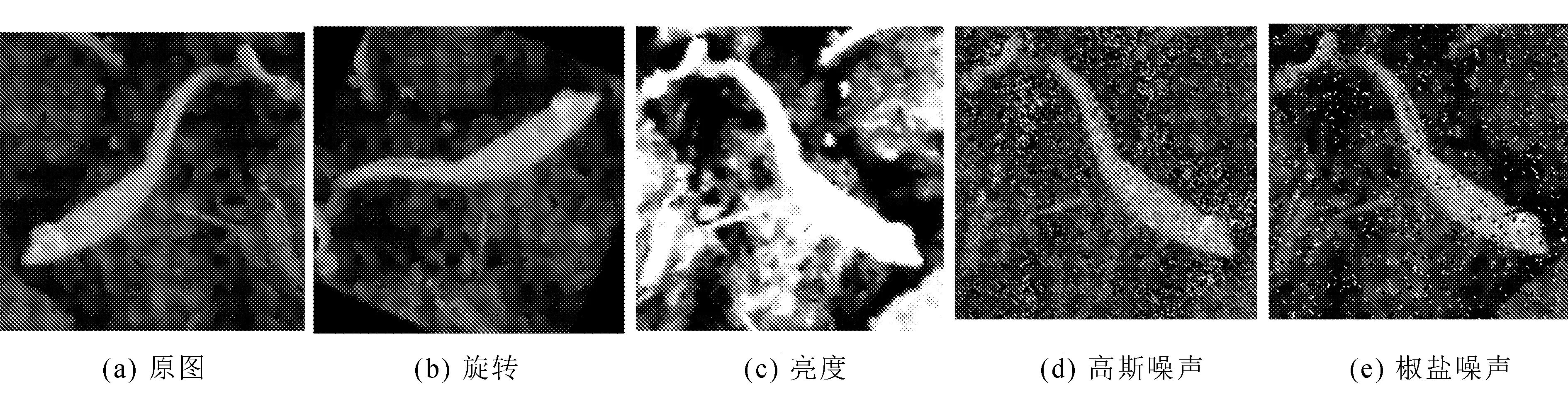
图6 数据增强后的图片
3.4 评价指标
将实验结果进行定量评价,文中选择以下性能指标进行模型评价,包括总体精度(Accuracy)、召回率(Recall)、精确率(Precision)。
各评价指标计算公式为
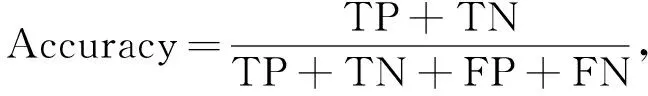
(6)
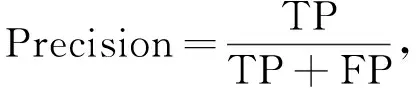
(7)
(8)
式中:TP----正阳性;
FP----假阳性;
FN----假阴性;
TN----正阴性。
3.5 实验结果分析
3.5.1 网络模型对比实验
通过实验将多种卷积神经网络模型以及文中提出的网络模型在Leaf-Counting数据集上的实验效果进行对比。实验分别采用ResNet-50[16]、Inception-v3、ViT以及文中提出的ViT_Inception网络作为杂草生长周期的识别网络,所有网络模型使用数据增强后的数据集。通过多次实验,使用相同的训练超参数,用优化后结果探讨不同网络模型的实验结果,各网络模型的杂草生长周期识别结果对比见表2。
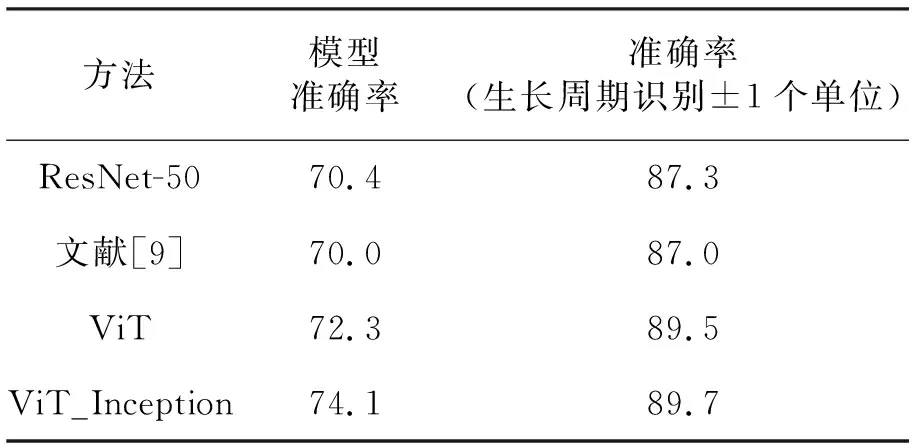
表2 网络模型对比实验 %
生长周期识别±1个单位准确率为文献[9]中提出的一种识别方法,表示属于上个生长周期或者下个生长周期都为正确的准确率。
由表2可得,相对于文献[9]中Inception-v3网络,ResNet-50通过加入残差链接,使得识别准确率相比较Inception-v3网络模型提升0.4%。一般而言,神经网络的层数越多,从原图中获取的信息就会越丰富,特征就越复杂,伴随会出现网络过拟合问题,ResNet系列网络通过残差结构有效地缓解了在增加网络深度的同时造成网络过拟合问题。ViT网络模型相比于传统卷积神经网络会通过注意力机制获得更加丰富的信息,只使用ViT网络模型获得2.3%的提升,该网络结构内部也使用了残差网络结构,进一步证明残差结构在模型中起到重要作用。文中提出的模型通过使用改进的ViT模型作为主干网络,在主干网络后使用多尺度卷积模块进行特征的进一步提取,从而获得更加丰富的信息。与其他神经网络模型相比,所提出的模型效果最好,相比于Inception-v3网络,提出的模型整体识别准确率提升4.1%。
3.5.2 样本集扩充对比实验
原始数据集存在数据分布不均衡的问题,通过数据增强和调整类别平衡的方式来缓解数据分布不平衡的问题。使用文中提出的ViT_Inception模型进行对比实验,分别使用原始数据集和扩充数据集作为训练集,并在同一测试集上验证数据集扩充对网络模型识别的影响。实验训练过程均采用相同的训练超参数配置,实验结果见表3。

表3 样本扩充对比实验 %
由表3可得,在网络模型相同、网络超参数一致的情况下,使用原始数据集在文中改进的模型上训练效果最高只有73.3%,使用扩充后的数据集训练的网络模型可以达到74.1%的识别准确率。实验结果表明,扩充样本数据集对网络模型的准确率有明显的提升。
3.5.3 各阶段生长周期对比实验
在测试集中,文中改进模型的准确率比文献[9]提升了4%,但整体准确率并不是很高。为进一步探讨问题,与文献[9]进行对比实验,从而观察各个类别的识别状况。在对比实验中,训练和测试过程均采用相同超参数。
文中所提模型对测试集进行测试得到的混淆矩阵如图7所示。
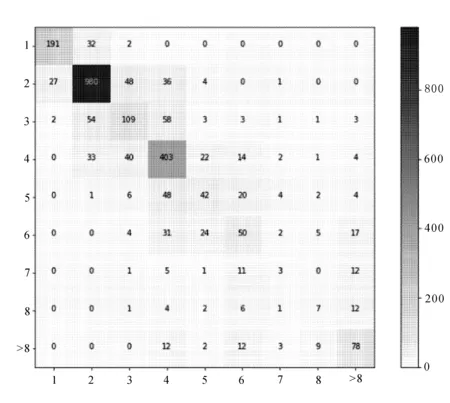
图7 测试集混淆矩阵
对角线上的数字表示分类正确,其他位置表示分类错误。与文献[9]对比各类别召回率见表4。
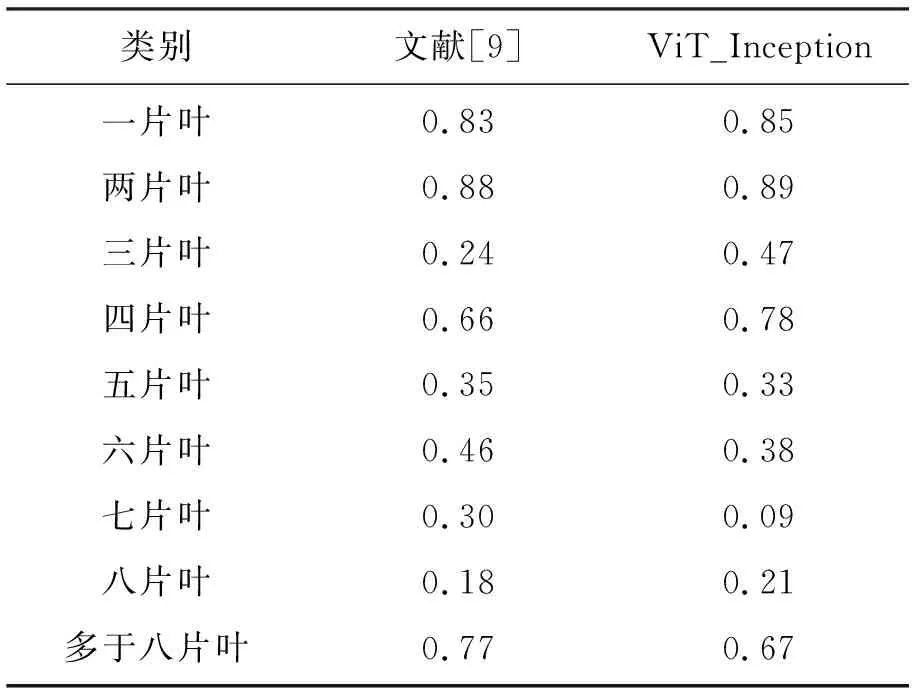
表4 各类别召回率(Recall)
由图7和表4可得,文中提出模型在多数类别中对样本的召回率有所提升,明显优于文献[9]中相对应的类别。但也发现对于叶片数较多的类别表现并不是特别理想,通过统计可知,在原始数据集中对于叶片数较多的类别样本数量比较少,并且测试集中对应类别数量也比较少,模型的扰动对数据量较少的类别会产生较大影响。虽然通过合理的数据增强和类别平衡方法可以缓解该问题,但本质上还需要更加丰富的数据集,这也对后续的科研工作指明方向,需要对数据集进行合理的扩充。
4 结 语
提出一种用于农业杂草生长周期识别的深度学习方法,该方法基于当前在图像分类任务上取得优异成绩的ViT网络作为主干网络,对其模型进行调整,更加适用于农业杂草识别任务。实验结果表明,对于杂草生长周期识别的准确率提升4.1%,并有效地避免过拟合的现象。通过以上实验说明,所提模型对杂草生长周期识别具有较快的识别优势,并且优于其他主流模型,可为进一步智能杂草生长周期识别的发展提供帮助。
猜你喜欢
科教新报(2022年22期)2022-07-02
今日农业(2021年5期)2021-11-27
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年13期)2020-01-14
高中生学习·阅读与写作(2019年2期)2019-09-10
电子制作(2019年11期)2019-07-04
