
基于改进YOLOv4算法的轮毂表面缺陷检测
2022-12-20 07:57吴凤和崔健新张志良张会龙郭保苏
计量学报 2022年11期
吴凤和, 崔健新, 张 宁, 张志良, 张会龙, 郭保苏
(1.燕山大学机械工程学院,河北秦皇岛066004;2.中信戴卡股份有限公司, 河北秦皇岛066004)
1 引 言
轮毂表面缺陷会影响产品的外观和品牌形象,甚至导致严重的安全问题。目前,大部分轮毂生产线都采用人工方式进行轮毂缺陷检测,操作过程繁琐,劳动强度大,且效率低下、漏检率较高,难以满足轮毂缺陷检测的精度和效率要求。机器视觉技术具有较高的检测效率和精度,且对特殊工业环境的适应性较强,已在环境目标检测、表面缺陷检测、织物纹理检测等方面得到了广泛应用[1-3]。
根据大致原理可以将各种目标检测算法分成two-stage和one-stage两类[4]。two-stage算法需要首先生成可能包含缺陷的候选框,再进行目标检测,Girshick R等[5]于2014年提出了RCNN算法,随着深度学习技术的发展,RCNN算法有了众多改进,检测精度及效率均有所提升,如文献[6]提出的Fast RCNN、文献[7]提出的Faster RCNN算法等。2017年,Cha Y J等[8]最早将Faster RCNN应用于桥梁表面缺陷定位,其主干网络被替换为ZF-net,在包含2 366张500×375像素大小图像的5类桥梁建筑数据集中,检测平均精度Pma值达到87.8%。虽然RCNN系列有多种算法,但由于训练中需要将多个候选框送入CNN提取特征,存在效率低、提取特征操作冗余等问题,无法满足大多数工业场景的检测效率要求。
One-stage算法的代表有SSD和Yolo系列算法。文献[9]最早提出的SSD算法相比于Faster RCNN,提供了一个彻底的端到端的神经网络,通过添加辅助性的特征金字塔,并融入先验框机制,解决了输入图像目标尺寸不同的问题,同时提高了检测精度。Chen J等[10]采用不同层级的特征图来改进SSD网络实现了某种紧固件的缺陷检测。但因SSD算法先验框的大小和形状不能直接通过学习获得,导致调试过程过于依赖经验,且针对小目标的检测效果不太理想。Yolo算法也是一种端到端的神经网络,由Redmon J等[11]在2016年首次提出,在此基础上结合新的主干网络和损失函数又相继提出了YOLOv2[12]和YOLOv3[13]算法。Yolo算法直接将目标边框定位问题转化为回归问题,并基于图像的全局信息进行预测,但对近距离物体和较小物体的检测效果不好,泛化能力相对较弱。谭芳等[14]采用深度学习YOLOv3算法检测行人目标,实现多目标行人跟踪的算法,在复杂环境下均获得了良好的连续跟踪效果。
2020年Bochkovskiy A等[15]发布了YOLOv4。YOLOv4在原理上与前代的YOLOv3相似,但是在主干网络、网络颈部、以及解码预测部分都结合了全新的模块方法,在保证检测效率的同时,大大提高了检测精度。Xin H等[16]使用YOLOv4算法对PCB板的缺陷进行检测,在数据预处理阶段根据缺陷的尺寸分布和标注框的尺寸大小自动细分图像,并对算法的超参数进行优化,使得检测精度有所提高。
虽然目标检测算法种类较多,但本文轮毂缺陷检测针对的是工业生产线,对缺陷检测的精度和效率都有较高要求,且轮毂缺陷的尺度范围较大,从十几cm,到几mm,缺陷的分布位置也存在随机性,故现有方法难以实现轮毂各类缺陷的高精度有效检测。因此,本文基于轮毂缺陷数据集的特点,以目前检测效果最为均衡的YOLOv4算法为基础模型,针对Yolo系列算法对小目标检测精度低、泛化能力弱的问题,融入细化U型网络模块(thinned U-shaped network module, TUM),强化多尺度特征提取与融合能力,使所得每个规模的特征都包含多个层级的信息;同时引入注意力机制,使网络对特征信息的处理更具针对性,从而提高网络检测精度,并增强网络泛化能力,在保证效率的前提下,实现缺陷的精确检测。
2 轮毂数据集制作

图1 轮毂表面缺陷种类Fig.1 Types of wheel hub surface defects
本文针对轮毂生产线中出现频率较高且对轮毂性能影响较为严重的6种缺陷(漏切、纤维、粘铝、脏污、毛刺、气孔)进行数据采集,自制轮毂缺陷数据集。采集到的轮毂缺陷图片数量依据实际工况中各种缺陷出现的比例,图像大小为4 928l×3 264 pixel,缺陷类型见图1。其中,粘铝缺陷是轮毂窗口等边角处存在粘附铝屑现象;漏切体现在轮毂的某一个面上存在黑皮或者印痕,主要由毛坯变形,加工量不准确等情况导致;纤维缺陷由于环境污染或者油漆质量差等原因导致轮毂正面有纤维或者毛发掺杂;毛刺清理未达标,导致毛刺过大形成毛刺缺陷;压力不稳、充型卷气、排气不畅等原因容易产生气孔,气孔缺陷多发生在轮毂的轮辋或轮芯处;喷涂环境或送风设备清理不及时使得轮毂表面在喷涂过程粘有灰尘,从而形成脏污缺陷。
由于在试验阶段采集到的缺陷图像数据量有限,为了进一步增加模型的学习范围,采用数据增广策略进行数据集扩充。数据增广可以提供更具多样性的训练数据,提高CNN性能,降低过拟合概率。本文运用的数据增广手段包括图像旋转、图像镜像、图像亮度对比度改变、图像添加噪声等。经过一系列增广最终得到2 346幅图像。为了得到轮毂图像数据标签(缺陷类型及坐标),运用LabelImg工具,采用手动方式对图像进行标注。最终,从2 346幅图像中共标记得到3 554个缺陷标签。
3 改进的YOLOv4算法
3.1 YOLOv4算法简介
YOLOv4是2020年最新提出的目标检测算法,它是在YOLOv3的基础上结合多种模块进行创新[15]。如图2所示,YOLOv4主要分为4个部分,分别是①输入端、②主干网络(Backbone)、③网络颈部(Neck)以及④输出预测(Prediction)模块。输入端会将数据集统一处理成相同尺寸的图片,继而输入Backbone。Backbone主要用于特征提取,该部分的网络被作者命名为DSPdarknet53,它将多个卷积核大小为3×3、步长为2的卷积结合残差方式(Res unit)共同组成CSP结构,并将其作为基本组件构成了整个主干网络,加入残差结构可以有效的抑制梯度消失的问题,保证在加深网络层数的同时不会导致网络退化。Neck部分运用了空间金字塔池化(spatial pyramid pooling, SPP)结构和路径聚合网络(PANet)结构,SPP结构是对Backbone输出的特征层经过3次卷积后的结果进行最大池化,池化过程中共使用4种不同尺度的池化层进行处理,池化核大小分别为 1×1、 5×5、 9×9、 13×13,经过SPP处理后可有效增加感受野,分离出显著的上下文特征。PANet结构是由卷积操作、上采样操作、特征层融合、下采样操作构成的循环金字塔结构。输出预测的Prediction即输出端,对Neck部分处理后的3个特征层进行结果预测,网络的输出大小与输入端图片大小相关,网络的输出维度与需要识别的目标种类数量相关。最后依据CIOU损失函数(complete intersection over union loss)对每个特征层的3个先验框进行判别,判断其内部是否包含目标并识别目标种类,同时进行非极大抑制处理和预测框调整以实现缺陷的分类及定位。

图2 YOLOv4网络结构图Fig.2 YOLOv4 network structure diagram
3.2 先验框标定
Yolo系列的目标检测算法需要在训练时预先设定先验框。原始YOLOv4算法提供的先验框是由COCO数据集聚类得到的,而COCO数据集图片与轮毂表面缺陷数据集图片中的目标大小和目标类型存在较大差异,因此采用K-means聚类算法重新生成先验框。在YOLOv4算法中,检测分为3个特征层,每个特征层中含有3个大小不同的先验框。先验框通过算法对数据集中标注好的检测目标聚类得到。在聚类过程中,首先随机化初始位置并选定9个聚类中心,计算检测目标中每个标注框与聚类中心点的交并比,并将标注框分配给交并比最大的聚类中心,分配结束后重新计算聚类中心,直到聚类中心不再发生改变,并获得最终聚类效果最好的9个先验框的宽、高。具体的目标函数D计算公式如下:
(1)
式中:Sboxi为检测目标中第i个标注框的区域面积;Scenj为第j个聚类中心的区域面积;Sboxi∩Scenj为标注框与聚类中心区域交集的面积;Sboxi∪Scenj为标注框与聚类中心区域并集的面积;n为检测目标数量;k为聚类中心个数。
3.3 Neck部分改进
轮毂表面缺陷尺度差异较大,如漏切缺陷通常占据轮毂表面的较大面积,而纤维缺陷往往只是一小片区域。one-stage算法受限于端到端的组合方式,虽然检测效率大幅提升,但对于小缺陷的检测效果往往较差。一般来说,尺度越大的特征层包含的信息越多,特征层经由下采样之后由于其尺度变小,缺陷信息会大大减少,几乎只会包含大缺陷的信息。针对该问题,对YOLOv4算法进行了改进,由于主干网络的作用主要在于对特征的提取,而Neck部分的作用在于强化提取与特征融合。为了进一步挖掘由网络前端提取到的特征,更大程度地融合更多不同尺度的特征,使得小缺陷的特征得以保留,本文剔除原YOLOv4 Backbone中38×38 pixel的特征输出,将Backbone中76×76 pixel的特征层经过CBL直接与SPP模块上采样的结果进行级联(Concat)操作;Neck部分只保留SPP模块,在原本的SPP模块后面添加多个细化U型网络(TUM)与注意力机制;经由改进Neck部分的输出特征层直接与Prediction部分连接,如图3所示。
3.3.1 TUM模块
本文设计的TUM模块位于SPP模块之后,分为下采样和融合上采样两部分。在下采样部分,进行1×1卷积和多个步长为2的3×3卷积;融合上采样部分对下采样的输出层进行上采样和特征元素融合操作,然后在最终输出层前添加1×1卷积层,以增强学习能力,保持特征的平滑。每个TUM中的输出特征层共有3种尺寸(76×76 pixel,38×38 pixel,19×19 pixel),从整体上看,分别代表浅层、中层以及深层的特征。这种多尺度的特征输出,有利于后续完成最大程度的特征提取与融合。其结构如图4所示。
3.3.2 注意力机制模块
在嵌入TUM模块后,需要将多个TUM中相同尺寸的输出特征层分别进行Concat操作,但直接的特征堆叠可能导致信息冗余,因此本文引入SE-block方式的注意力机制(图5),注意力机制可以自适应优化特征权重,增强有效特征,抑制无效特征,得到表征能力更强的特征,使得特征处理过程中小目标信息丢失的问题得以改善。
具体过程如下:①对TUM模块Concat得到的特征层进行特征压缩,将每个特征通道变成一个实数,这个实数在某种程度上具有全局感受野,并且输出的维度和输入的特征通道数相匹配;②压缩结果经由卷积网络与激活函数激活,对每个特征通道生成一个权重,输出权重描述每个特征通道的重要性;③将权重加权到由TUM模块堆叠的特征上,完成在通道维度上的对原始特征的重标定。经由以上处理得到的3个特征层便可直接输入Prediction模块。

图4 TUM模块结构图Fig.4 TUM mod ule structure diagram

图5 注意力机制模块Fig.5 Attention mechanism module
4 实验与分析
为验证算法的有效性,对提出的改进算法进行消融实验并与其他常用算法进行对比。所有算法均基于Python语言开发,使用模块包括numpy、OpenCV、tensorflow等,运行在Windows10平台下。实验所用的硬件配置为Intel Core i7 11700K CPU,16G RAM以及NVIDIA GeForce RTX3070 GPU。
4.1 评价标准
在缺陷检测中,通常将预选框与目标真实框的交并比大于0.5设定为成功预测到目标位置,通过准确率(P)和召回率(R)计算平均精确度(Pa)和加权调和平均值(Fβ),并以Pa的均值Pma作为算法精度的综合评价指标。P代表预测为正的样本中有多少是真正的正样本,与误检率相关;而R代表数据集的正样本中有多少被正确检测,与漏检率相关。Fβ是基于P和R的加权调和平均,将误检与漏检加权计算,反映了算法的综合性能,其值越大表示算法性能越佳。Pa用于评估模型在单个检测类别上的精度表现,由P-R曲线围成的面积进行表示,而Pma代表的是整体精度,Pma越大表明整体检测精度越高。
上述各指标的计算公式如下:
(2)
(3)
(4)

(5)
(6)
式中:PT表示检测正确的目标数量;PF表示检测错误的目标数量;NF表示漏检的目标数量;β为常数,∑Pa表示所有缺陷类别的Pa值总和;Nc表示缺陷总类别数。
此外,检测效率也是判定算法性能的重要指标之一,本文采用单张图片平均检测时间T作为检测效率的评价指标。T越小,表示检测效率越高,更容易达到实时检测。其计算公式为
(7)
式中:Ttotal为检测的总时间;Fn为检测的图片数量。
4.2 实验及对比结果
本文在训练时把数据集分成训练集和测试集,其中随机选取20%的各种缺陷数据图作为测试集,其余图像作为训练集。训练、测试集的比例以及数量如表1所示。

表1训练集与测试集图片数量对比Tab.1 The proportion of training and validation sets.
4.2.1 TUM模块数量对比实验
网络训练的学习率依据余弦退火的形式进行下降,余弦函数中随着自变量的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能与学习率匹配,提升训练效果。网络结构设计上采用不同的TUM模块数量,为了保证训练效率以及训练结果的可信度,选用TUM数量分别为3、4、5、6、7、8、9这7种进行多次实验,每次实验设定的迭代次数为100,置信度设置为0.5。采用3.3节中描述的改进YOLOv4算法对自制数据集进行训练,并通过测试集对其检测精度进行评估。每个案例的训练时间大约为5 h,每幅图像的测试时间大约为0.04 s。通过Pma值来衡量不同TUM数量下的模型性能,如图6所示。

图6 不同TUM数量的精度对比Fig.6 Accuracy comparison based on the number of TUM
从图6可以看出,对于数据集中6种缺陷的检测精度可以大致分为3个层次。漏切、脏污、毛刺3种缺陷由于其缺陷面积较大,特征明显,检测精度普遍较高;气孔、纤维缺陷是小缺陷,包含的特征信息较少,故检测精度较低;而粘铝缺陷虽然同样属于小缺陷,但由于其多发生在轮毂边角处,缺陷位置较为固定,缺陷特征更易提取,所以检测精度相对其他小缺陷有所提升。不同TUM数量下的检测精度有较大波动,一般来说,随着神经网络层数的加深,其提取的特征信息会愈加复杂抽象,会从简单的形状向更“高级”的信息变化,这也是加深神经网络层数的意义所在。但由于数据集规模的限制,神经网络学习到的信息有限,且神经网络每一次输入到输出的迭代过程可能会造成一些不可逆的信息丢失,在网络加深后可能导致过拟合问题。因此,本文以实验效果最佳作为确定TUM数量的依据。通过分析实验结果可知,TUM模块数量为8时检测精度最高,模型的检测平均精度可达85.8%,因此将TUM模块数量设置为8。
4.2.2 消融实验
为了验证本文对原算法改进的有效性,针对K-means聚类、TUM模块及注意力机制模块设置消融实验,实验将原算法与采用不同配置的改进后算法进行对比,对比结果见表2。

表2改进YOLOv4算法的消融实验Tab.2 Ablation experiment for improved YOLOv4 algorithm
如表2所示,运用K-means聚类得到的先验框进行训练后,相比原始YOLOv4算法平均精度(82.5%)有所提升,表明针对数据集特点重新标定先验框具有一定价值;在此基础上嵌入TUM模块,网络平均检测精度由83.33%提升到84.7%,这些提升主要反应在小尺度缺陷上;分析了TUM模块直接堆叠特征层可能存在问题而引入挤压激励模块(squeeze and excitation block, SE block)机制后,算法的检测精度进一步提升,达到了85.8%,从而证明了本文改进有效性。
4.2.3 算法对比实验
为了评估本文改进算法的性能,在相同的数据集下,训练并对比本文改进算法与SSD、Faster RCNN、YOLOv3以及原始YOLOv4算法的评价指标。由于车轮轮毂表面缺陷对于整车外观甚至安全性有较大影响,在进行缺陷检测时更希望尽可能避免漏检,因此,除了平均检测精度和检测效率外,Fβ也是值得参考的重要指标(Fβ中β值的设定不宜过低,本文设定该值为1.2,以强调召回率的重要程度)。上述各种网络在目标检测领域应用广泛,认可度较高。最终对比结果如表3~表5所示。
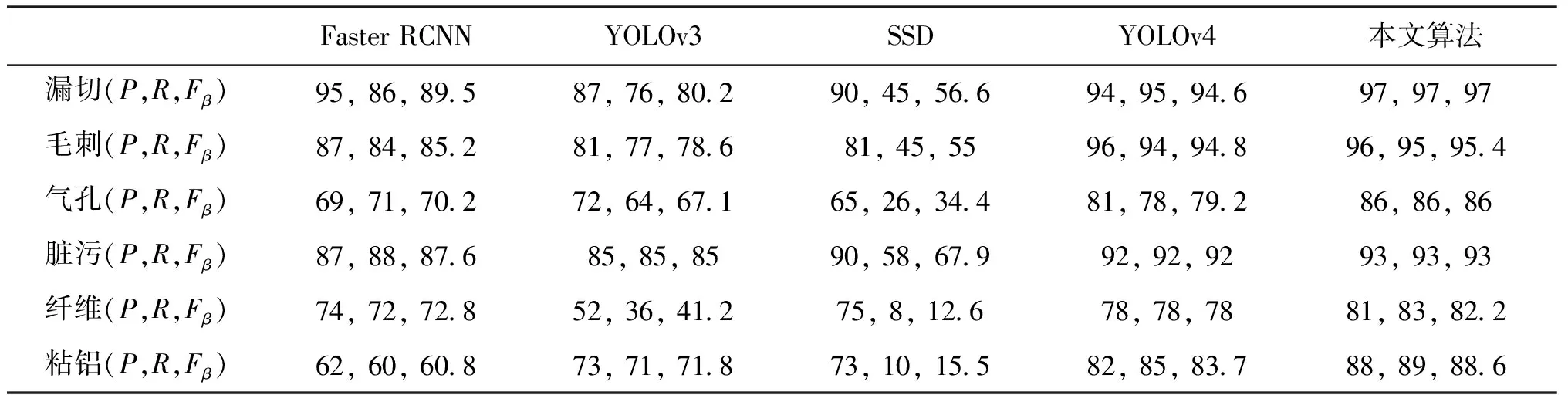
表3不同算法P,R,Fβ对比Tab.3 Comparison of different algorithms P,R,Fβ (%)

表4不同算法精度对比Tab.4 Comparison of accuracy of different algorithms (%)

表5不同算法检测效率对比Tab.5 Comparison of detection speed of different algorithms ms
表3中记录了不同算法对应不同缺陷种类的P、R、Fβ值。如表3所示,对于Fβ值,无论针对哪种缺陷本文算法都是最高的,表明本文算法可以最大程度上避免误检、漏检的发生。
从表4、表5所反映的信息可以看出,Faster RCNN算法精度为75%,但其检测效率较低,单幅图像的检测时间需要127 ms;而SSD算法正好相反,虽然其检测效率占优,但是精度较低,仅仅达到55%,尤其是针对粘铝、纤维等小缺陷的检测效果很不理想;YOLOv3算法相较前两种较为均衡,但精度上与YOLOv4还有一定差距。
对于缺陷检测,精度是相对重要的评价指标,本文算法在检测效率上与原算法差距不大,但检测精度提升了3.3%,多种缺陷在改进算法下的检测精度均有提升,尤其小缺陷检测精度的提升幅度更为明显,如粘铝缺陷的检测精度由原来的78%提升到了85%,证明了本文算法的优越性。
上述对比数据表明,本文提出的改进算法在轮毂表面多类缺陷检测上,具有最优的检测精度和较高的检测效率。实际检测效果示例如图7所示。

图7 算法检测结果Fig.7 Algorithm detection result
5 结 论
本文提出一种基于改进YOLOv4算法的轮毂表面缺陷检测方法。针对YOLOv4算法对小尺寸缺陷检测精度不足问题,通过融入TUM模块和注意力机制,提高算法的多尺度特征提取及融合能力,并依据缺陷种类,自适应分配缺陷特征权重,使得模型对小尺寸缺陷的表达能力得到提升;使用自主采集并制作的轮毂表面缺陷数据集进行模型性能验证,结果表明:改进YOLOv4算法的平均检测精度和单幅图像检测时间分别为85.8%和38 ms,在保证检测效率的前提下,有效提高了模型对小尺寸缺陷的检测效果。
猜你喜欢
汽车实用技术(2022年5期)2022-04-02
一重技术(2021年5期)2022-01-18
上海涂料(2021年5期)2022-01-15
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
铁道通信信号(2019年6期)2019-10-08
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
制造技术与机床(2017年10期)2017-11-28
雷达学报(2017年6期)2017-03-26
制造业自动化(2017年2期)2017-03-20
