
基于领域情感词典与字词特征融合的中文抑郁症文本分类方法
2022-12-19 03:40卓广平乔俊福张光华
中北大学学报(自然科学版) 2022年6期
刘 豪,卓广平,乔俊福,张光华
(1. 太原师范学院 计算机系,山西 晋中 030619;2. 太原工业学院 自动化系,山西 太原 030008)
0 引 言
抑郁症是当前社会最常见的一种心理疾病,其带来的负面影响也引起了人们的广泛关注. 据世界卫生组织的最新调查显示[1],世界上有超过3亿人患有抑郁症,而我国的抑郁症患者就高达5 000万. 虽然心理治疗、物理治疗和药物治疗等方法可以有效治疗抑郁症[2],但大多数人受生活环境和对抑郁症认知不足的影响,不能及时发现个人病情,导致我国抑郁症的识别率偏低,这也成为目前研究和治疗抑郁症的一个主要障碍.
随着微博和贴吧等各种网络社交平台的发展,越来越多遭受抑郁症折磨的年轻患者将网络平台作为表达自己负面情绪和自杀想法的主要途径. 而通过对网络平台的这类文本进行分析和处理,能够有效识别用户的情绪状态,将有助于抑郁症的预防和研究.
文本分类是自然语言处理的基础任务之一,目的是推断出给定文本的类别,在情感分析、垃圾短信分类、对话行为分类等方面有着广泛的应用[3]. 当前文本分类方法主要分为三类:传统基于规则和字典的方法、基于机器学习模型和深度学习模型的方法、混合方法. 何铠等[4]在TF-TDF算法的基础上增加权重预处理和词密度权重两个环节,提出了一种基于权重预处理的中文文本分类算法PRE-TF-IDF;钟桂凤等[5]为了提高文本分类的准确性和运行效率,利用改进的AlexNet-2对长距离词相依性进行有效编码,同时在模型中添加注意力机制,可以高效学习到目标词的上下文语义关系. 武渊等[6]基于渗透假设的类平衡分层求精原理,提出了一种融合多层异构注意力机制、卷积和循环神经网络的自动分类方案. 随着预训练模型的发展,孙红等[7]在融合BERT词嵌入和注意力机制的基础上提出了BBGA模型,该模型在处理大规模的数据时,能兼顾分类的精度和处理效率. 上述方法都是基于字级或词级的编码方式进行分类,在中文文本的分类方法中,没有考虑中文本身的字词特性,即中文的字和词都有各自的信息和特征,单级别的编码会损失文本的语义特征信息. 文献[8]对比研究了中文的字级和词级表现,发现字级的中文文本分类模型往往表现得更好. 然而,字级的分类模型存在语义信息不足或缺失的问题;词级模型由于词组的数量过多和词分布的稀疏性,不利于模型训练和收敛;而字词特征结合的编码方法兼顾了两者的优点,一方面能够更多地表征文本信息,另一方面较词级编码更容易训练和收敛. 在字词特征融合的研究中,杨敬闻[9]提出将词组按字进行编码,例如将“北京”这个词组按“京”字编码处理;殷章志等[10]和殷昊等[11]采用不同模型对字和词分别训练,最后再将两种向量进行拼接作为字词特征融合后的输入;陈欣等[12]提出一种混合的编码方式,即分别对字和词进行编码,然后再按字的长度与词向量交叉拼接作为融合后的输入. 上述学者提出的方法在一定程度上融合了中文的字词特征,但该类方法增大了词组处理的额外开销,并且都采用了通用域的词组信息编码方式,使模型缺乏领域的概括能力[13]. 而采用领域情感词典的方式在具体的自然语言处理任务中的表现会更优[14].
本文提出了一种基于领域情感词典与字词特征融合的中文抑郁症文本分类方法. 该方法基于通用域词典和词语相似度计算构建并扩展了抑郁症领域的情感词典;其次通过在字级模型中增加抑郁症患者语料的情感词组,融合了中文的字词特征,优化了字词的表征能力. 通过将该方法应用于BERT[15]模型的实验表明,基于领域词典与字词特征融合的BERT-W模型能够更好地完成中文抑郁症文本分类任务.
1 中文抑郁症情感词典的构建
情感词典是一种重要的资源,在文本分类和情感分析等应用中起着至关重要的作用[16]. 但是目前对抑郁症情感词典的构建处于初步研究阶段,该领域现有的情感词典资源十分有限. 本文通过网络爬虫获取抑郁症患者的评论语料,并基于抑郁症患者评论语料的语言多变性和情感极性丰富等特点,对其进行去噪处理和分词等处理后构建中文抑郁症情感词典. 构建情感词典的具体步骤如图1 所示.

图1 构建情感词集Fig.1 Acquisition of sentiment word set
1.1 预处理
抑郁症患者的评论语料中包含了特殊符号、链接和图片等信息,这类信息基本上对情感极性的判定没有帮助,因此需要对评论语料进行去噪和分词处理. 具体处理实例如表1 所示.

表1 语料预处理和分词处理实例Tab.1 Examples of preprocessing and word segmentation
对原文本进行预处理主要包括两步:1) 去除链接、图片和表情包;2) 替换特殊字符. 因为“¥” “@”以及空格等这类特殊字符并不能体现文本的内在信息,统一通过“^”符号替代. 如文本“真的好累!想死也死不成……”被替换成“真的好累^想死也死不成^”.
中文分词是中文文本处理的基础步骤. 不同于英文句子,中文句子中没有词的界限,因此,在进行中文自然语言处理时,通常需要先进行分词. 目前,常用的分词方法主要有基于词典的分词方法[17]和基于统计机器学习或深度学习[18]的方法. 这些方法需要有较大规模的精准词典作为支撑,而本文由于相关文本数据的有限性,采用Jiaba分词工具对文本进行分词. Jieba分词工具通过利用大规模的中文词库,确定汉字之间的关联概率,将汉字间概率最大的组成词组,并形成最后的分词结果;而且除了分词,该工具还支持添加自定义的词组.
1.2 种子词集的获取
在对评论语料进行预处理和分词生成候选情感词集后,过滤掉文本中常见但没有实际意义的词,同时保留真正影响文本的词语,再通过TF-IDF(Term Frequency-Inverse Document Frequency)加权算法得到种子词集. TF-IDF 算法可以对评论语料进行词频权重分析,并提取其中权重较高的特征词作为抑郁症种子词. TF-IDF的计算公式为
TF-IDF=ftf*fidf,
(1)

(2)

(3)
式中:特征词i属于候选情感词集;ftf(i)表示特征词i在文本总词数d中的频率;fidf(i)表示逆文档频率;n表示文本总数. 通过TF-IDF算法筛选出无用词,得到的种子词集结果更加准确、客观.
1.3 抑郁症情感词典的生成
种子词集作为领域词典的子集,反映了该领域的部分特点;由于种子词集在领域语料中的不全面性,容易造成情感词汇的遗漏,为了进一步提高抑郁症情感词典的质量,本文用种子词集在知网和大连理工的通用域情感词典上做了扩展处理. 抑郁症情感词典的扩展过程如图2 所示.
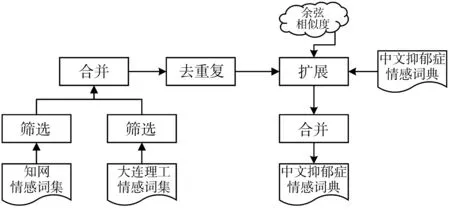
图2 抑郁症情感词典的扩展Fig.2 Expanding on the emotional dictionary of depression
在情感词典的扩展过程中,选取知网和大连理工情感词典的消极词汇作为基础;筛选部分主要是去除单字符的情感词汇;种子词集是由TF-IDF算法得到;种子词集的扩展是通过文本在Word2Vec[19]模型中训练,得到词汇的向量表示,然后通过计算种子词与基础情感词间的余弦相似度得到词间的相似程度,最后选取相似度值最大的词汇作为扩展词. 词典的数量变化如表2 所示.
经过TF-IDF加权算法得到的种子词共1 159个,经过Word2Vec模型训练和余弦相似度计算扩展的词汇共973个,合并得到2 132个情感词,作为本文所使用的中文抑郁症情感词典. 余弦相似度的计算公式为

(4)
式中:n表示词向量的维度;xi表示词x在第i维上的值;θ表示词间的夹角;cos值越大表示词间的相似度越高,本文选取相似度高的词作为扩展词.

表2 词典扩展数量变化Tab.2 The change in number of extensions
2 基于BERT的词嵌入模型
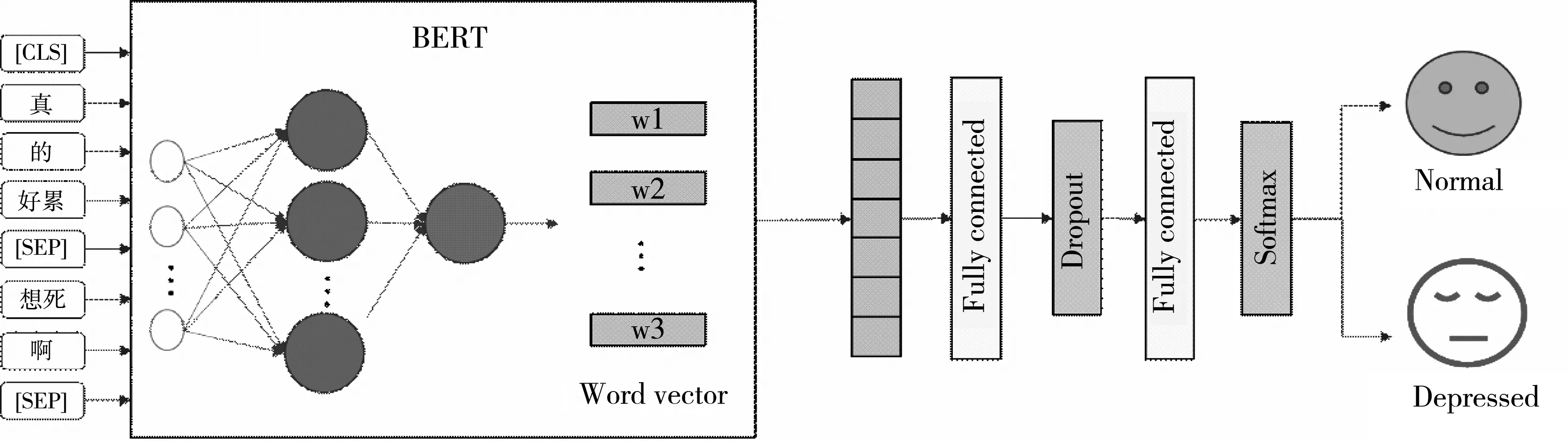
将文本信息或数据转化为可供计算机识别的形式,是文本分类和命名实体识别等自然语言处理任务的基础. 目前,常用的词嵌入模型主要有Word2Vec[19]、ELMo[20]和BERT[15]等. 传统使用one-hot和Word2Vec编码方式训练得到的词向量在一定程度上能够表示词语之间的关系,但这种关系是词和向量间相对应的静态关系,并不能根据具体语境对输入序列进行动态表示. 而BERT模型在大量语料训练的基础上,融合了词语在不同上下文的特殊表达,使得模型能够充分获取输入文本中的语义信息. BERT生成词向量的输入如图3 所示.

BERT词向量输入由字向量、句向量和位置向量的三个向量求和生成. 其中,字向量是字本身的向量表示,CLS和SEP字符表示文本的起始位置和结束位置;句向量表示句子的文本信息,用于区分不同的句子;位置向量表示字在文本中的具体位置,用于区分句子中不同位置字的语义信息. 通过融合这三种向量特征,实现了词向量的动态表示,优化了字词的表征能力.
本文提出的BERT-W模型在BERT模型的向量生成方式上有所改变. 该模型对文本不再是按字编码,而是先进行分词处理,再对单字和抑郁症情感词分别编码;同时,将抑郁症情感词组当作独立的部分,以融合文本的字向量特征和词向量特征,这样能够进一步提高字词的表征能力. BERT-W词向量生成方式与基于字和基于词的方式对比如图4 所示.

图4 中,BERT-char是BERT按字编码的向量生成方式,这种方式实现简单,但蕴含的语义信息不丰富;BERT-word是全领域词的编码方式,优点是蕴含的语义信息较全,缺点是由于词组的高数量和词分布的稀疏性,模型的表现效果不佳,且训练时间过长;而BERT-W模型结合了两种方式的优点,是基于抑郁症领域情感词的编码方式,一方面较字级编码能蕴含更多的语义信息,另一方面较词级编码能更容易训练和收敛.
BERT-W模型基于抑郁症领域情感词典并融合了中文的字词特征,在中文抑郁症分类任务上表现更好. BERT-W模型完成中文抑郁症文本分类任务的方法框架如图5 所示.
3 实验与分析
为了验证本文提出的方法的有效性,给出所使用的数据集和实验环境,以及模型准确性的评价指标,并通过统计来比较分析模型的性能.
3.1 实验数据
由于公开的抑郁症患者中文语料资源十分有限,本文通过网络爬虫技术从百度贴吧获取抑郁症患者的评论语料4 720条、正常语料5 000条,共计9 720条. 去除图片、链接和表情包等无效文本后,剩余评论语料3 409条和正常语料4 266条,各选取3 300条后构建了中文抑郁症情感数据集CDSD. 其中,选取抑郁症患者的评论语料和正常语料各3 000条作为本文实验的训练集数据,选取各自剩余的300条作为本文实验的测试集数据.
3.2 实验环境与参数设置
本文的实验基于Linux操作系统,用于训练的GPU是RTX 3060T,软件环境包括python 3.8和pytorch框架,模型参数设置如表3 所示.

表3 模型参数Tab.3 Parameters of model
3.3 实验评价指标
本文为评估各种分类模型的性能,采用精确率(Precision)、召回率(Recall)和F1-score值作为实验的评判指标. 其中,正样本表示抑郁症文本,负样本表示正常文本;精确率也叫查准率,表示在预测为正样本的所有样本中,真实的正样本所占的比例;召回率也叫查全率,表示在所有真实的正样本中,被预测为正的样本所占的比例;在理想状态下,精确率和召回率越高代表模型的性能越好,但事实上两者是相矛盾的;而F1值作为精确率和召回率的调和平均值,用来评估模型在精确率和召回率上的综合性能. 各个指标的计算公式分别为

(5)

(6)
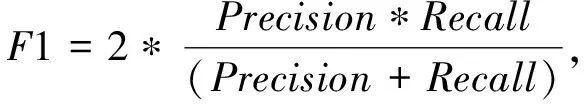
(7)
式中:TP表示被分类正确的正样本数目;TN表示被分类正确的负样本数目;FP表示被分类成正样本的负样本数目;FN表示被分类成负样本的正样本数目.
3.4 实验结果与分析
对于数据集CDSD采用不同分类方法(TextCNN,TextRNN,TextRCNN,DPCNN,FastText,ERNIE,BERT,BERT-W)进行分类. 其中,模型TextCNN、TextRNN、TextRCNN、DPCNN、FastText和ERNIE模型是基于Word2Vec的静态字向量文本表示方法;BERT模型是基于动态的字向量文本表示方法;BERT-W模型是基于动态的字词向量融合的文本表示方法. 得到的对比结果如表4 和图6 所示.

表4 不同模型的实验结果Tab.4 Experimental results of different models
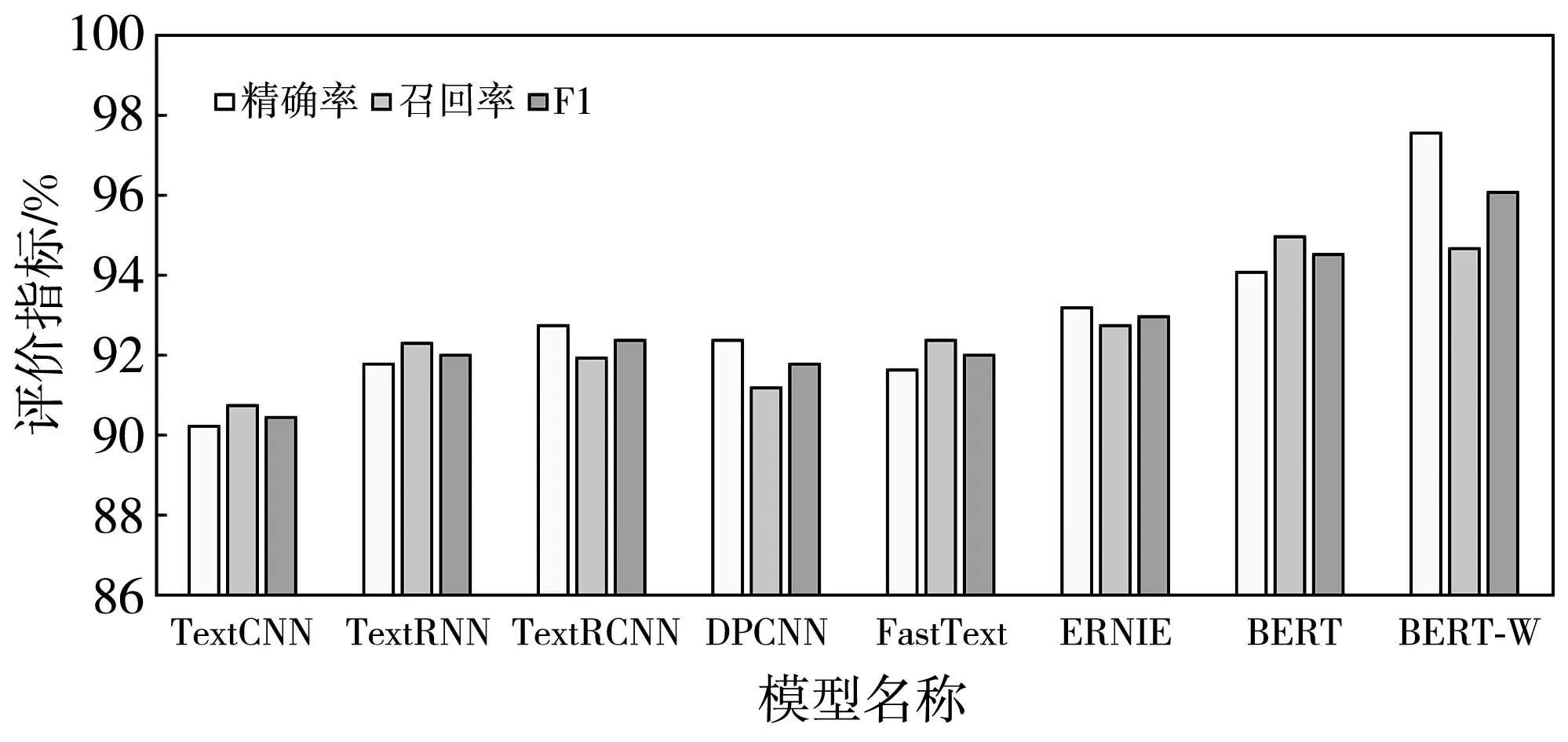
图6 实验结果对比图Fig.6 Comparison of experiment results
由表4 和图6 的实验结果可知,基于BERT的动态语义表示模型能更好地提高语义的表征能力,在精确率、召回率和F1值的评价指标上均高于基于Word2Vec的各类静态表示模型. 基于字向量的BERT模型和融合了抑郁症情感词的BERT-W模型对比结果表明,BERT-W模型的精确率提高了3.53%,F1值提高了1.58%,在抑郁症患者的文本分类任务上,其分类能力有一定的提升.
为验证抑郁症领域情感词典和字词特征融合分类方法的有效性,本文在CDSD数据集上进行了对比实验,实验对比结果如表5 所示.

表5 不同实验方法对比Tab.5 Comparison of different experimental methods
由表5 可知,按字编码的BERT-char模型的平均训练时长最短;按全域词编码的BERT-word模型在Recall上的表现愈显不足,且模型的训练和收敛时长接近BERT-char模型的3倍;而BERT-W模型只多用了少量的训练时长,在精确率等评价指标上的总体表现却更好.
另外,为验证BERT-W模型的泛化能力,本文将所提方法应用在WU3D数据集[21]上,实验结果如表6 和图7 所示.
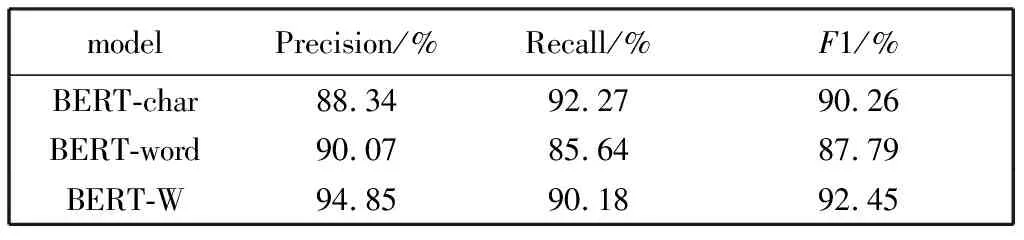
表6 WU3D数据集实验结果Tab.6 The Experimental results of WU3D
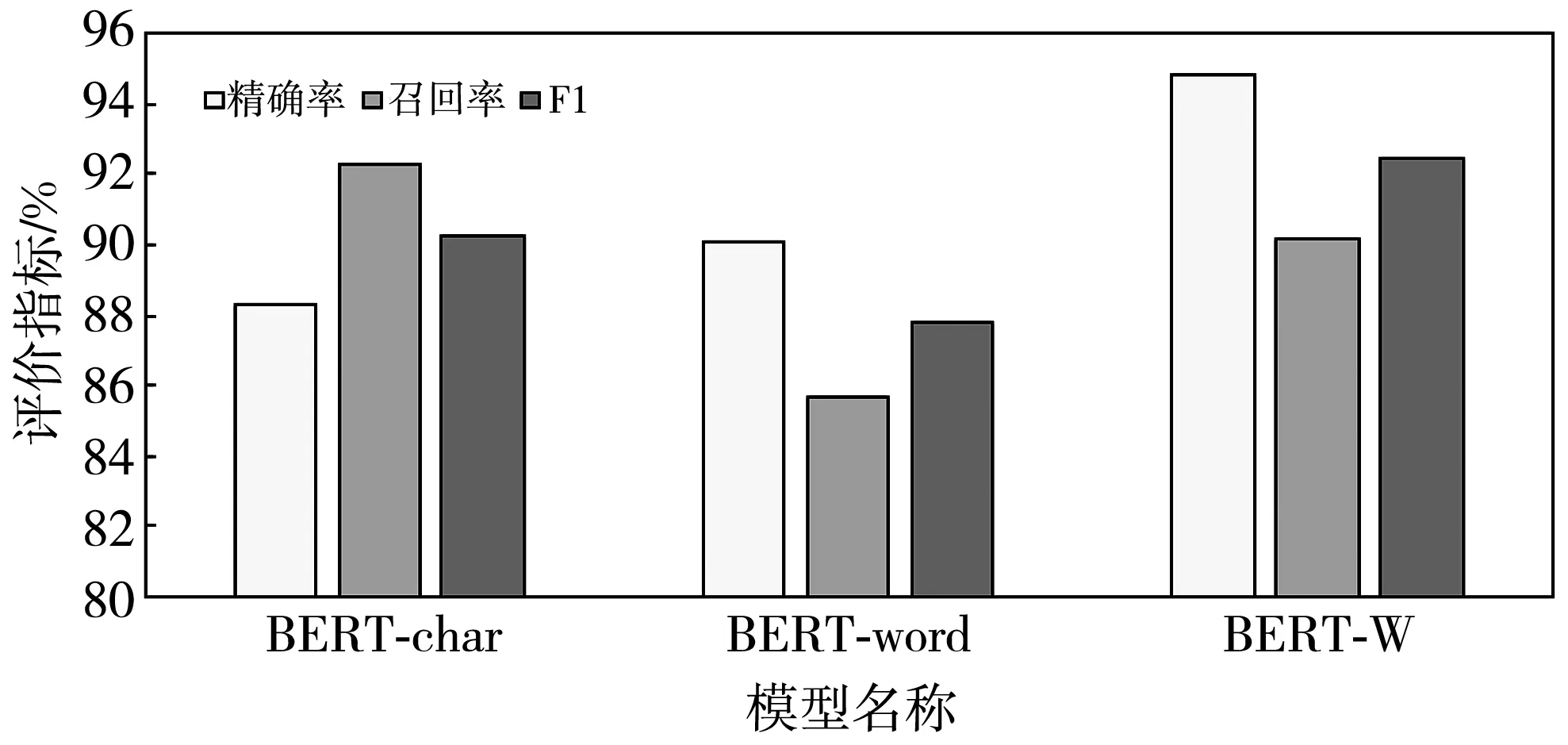
图7 WU3D实验结果对比图Fig.7 Comparison of WU3D experiment results
在WU3D数据集的实验结果中,BERT-W模型在精确率上比BERT-char模型高出6.51%,比BERT-word模型高出 4.82%,在F1值上的表现也更佳. 实验结果表明,基于抑郁症领域情感词和字词特征融合的BERT-W模型与实验的其他模型相比,具有更强的语义表征能力,在中文抑郁症文本分类任务上的表现也更好.
4 结论与展望
本文基于抑郁症领域情感词典提出了一种字词特征融合的中文抑郁症文本分类方法,用以解决抑郁症患者的文本的准确分类问题. 首先,考虑到领域情感词典在分类任务中的重要性,基于通用域词典和词语相似度计算构建并扩展了抑郁症领域的情感词典;其次,针对中文字词的不同特点,同时考虑了字级和词级的信息特征;最后,本文将该方法应用于BERT模型,构建了处理中文抑郁症文本分类任务的BERT-W模型. 实验结果表明,相比其他文本向量表示方法和只考虑字或词的BERT分类模型,融合领域情感词和中文字词特征的BERT-W模型能够更好地表征语义信息,在用户的文本抑郁倾向分类任务中的表现也更优.
后续可以对用户文本、图像、音频与视频等不同信息源提取的特征进行融合,设计并实现多模态的检测模型,从而更好地进行抑郁倾向文本的分类.
猜你喜欢
通信技术(2021年12期)2022-01-25
校园英语·月末(2021年13期)2021-03-15
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
英语文摘(2019年5期)2019-07-13
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中关村(2014年5期)2014-05-15
