
致密砾岩油藏压裂甜点预测研究
——以玛18井区为例
2022-12-19 12:55杨琨罗山贵花凌旭唐慧莹孙正龙
科学技术与工程 2022年32期
杨琨,罗山贵,花凌旭,唐慧莹*,孙正龙
(1.中国石油新疆油田分公司,克拉玛依 834000;2.西南石油大学油气藏地质及开发工程国家重点实验,成都 610500)
新疆准噶尔盆地玛湖油田是近年来在凹陷区成藏理论指导下发现的储量规模达10×108t级的特大型致密砾岩油藏[1-2],勘探开发潜力巨大。环玛湖油藏可划分为玛东、西、南、北、中5个油藏群,油层主要分布在百口泉组(T1b)和乌尔禾组(T1p),在区块上以玛18、玛131和玛2井区为主。玛18井区纵向上划分为百口泉组T1b1和T1b2共2套储层。其中,百口泉组T1b1储层孔隙度平均9.89%,气测渗透率平均5.57 mD;T1b2储层孔隙度平均9.00%,气测渗透率平均1.78 mD。井区油层渗透率级差达300以上,储层非均质性极强,天然裂缝不发育。玛18井区产能建设分为“直井+水平井试验区”阶段(2015—2016年)和水平井规模开发(2016年后)两个阶段。截至2020年底,玛18井区百口泉组油藏共有油井254口,年产油量63.5 万t。虽然玛湖油田形成了以“水平井+体积压裂”为主的开发方式,但是玛湖致密砾岩油藏在开发过程中也面临着压裂投资成本高、压后产量递减快、采收率低等难题,同时其独特的沉积特点与成藏特征,也对油藏的“甜点”预测提出了更高的挑战[3-5]。为进一步促进玛湖地区有效开发,提高油藏采收率,实现油田的稳产高产,必须进一步完善“水平井+体积压裂技术”,以提高储层压裂改造的有效性。
储层可压性是工程甜点评价的重要指标[6]。可压性是表征储层有效改造难易程度的关键参数,综合评价储层可压性,合理的选址(井位、压裂层位、压裂段位置)是压裂成功的关键,寻找“压裂甜点”,优化压裂施工参数,是提高压裂改造效果的重要手段。任岩等[7]采用组合赋权法确定各影响因素的组合权重系数,将权重系数与各影响因素标准化值进行加权,得到了页岩可压裂性评价模型;宋明水等[8]综合考虑天然裂缝、砂岩脆性、水平应力差异、断裂韧性四种影响因素,采用改进的层次分析和熵值法相结合的方法进行了致密砂岩储层可压裂性评价;袛淑华等[9]针对单一脆性指数评价裂缝孔隙型、孔隙裂缝型储层压裂难易程度的局限性,引入断裂韧性参数和裂缝密度构建了储层综合压裂参数;曾治平等[10]综合考虑岩石脆性、断裂韧性、地应力环境和天然裂缝发育程度的影响,采用层次分析法计算了各因素权重,建立了适合深层致密砂岩的可压性评价方法;赖富强等[11]对正向、负向可压裂性评价参数进行归一化处理,并采用层次分析法建立了页岩气储层可压裂性评价模型;崔春兰等[12]对储层特征和岩石可压性影响的关键因素进行研究,获得对可压性有影响的正相关指标和负相关指标,采用相关性分析和层次分析法建立可定量评价页岩储层可压裂性的数学模型。近年来,随着大数据和人工智能的发展,油气勘探开发智能化已经成为行业前沿热点和发展趋势[13-14]。研究表明,机器学习算法也是实现非常规储层压裂甜点预测的有效手段[15]。但尚未有工作对不同机器学习算法的表现进行系统对比。
目前针对玛湖致密砾岩油藏“压裂甜点”的研究尚鲜见报道,为此以玛湖油田玛18井区为研究对象,在压裂改造效果主控因素分析基础上,优选并改进已有压裂甜点评价方法,同时建立了基于机器学习的致密砾岩油藏压裂甜点预测模型,通过对不同类别甜点预测方法的系统比较,优选出最适合与玛18井区的压裂甜点模型,最终实现致密储层三维压裂甜点分布可视化,为井位部署、压裂施工选井、选段提供直接指导。
1 SRV主控因素分析
首先,以玛18井区水平井(图1)为例开展储层改造体积(simulated reservoir volume,SRV)主控因素分析。同时,SRV与产量有较好的正相关性[16-18],因此选择SRV为压裂效果评价指标。如表1所示,整理玛18井区压裂水平井的地质参数、地质力学参数、压裂施工参数以及微地震监测所得各井段的SRV,分析各参数与SRV之间的相关性大小。玛18井区两口水平井共29个压裂段。首先分析各井单段加液总量INJ、单段加砂总量PROP、杨氏模量YMOD、泊松比POISSON、渗透率PERM、孔隙度PORO、孔隙压力PP、最小水平主应力SHMIN、应力差DS共9类参数与SRV的相关性。

表1 M6井各压裂段地质参数、工程参数和SRV统计

图1 玛18井区油藏位置
如图2所示,从各参数与SRV的关系图上,难以直观地观察到相关性关系。因此,计算地质参数和工程参数与SRV的皮尔森相关系数。皮尔逊相关系数越接近1,说明变量间正相关越强,越接近-1,变量间负相关越强,当皮尔逊系数为0时,两个变量间无相关性,其计算公式为
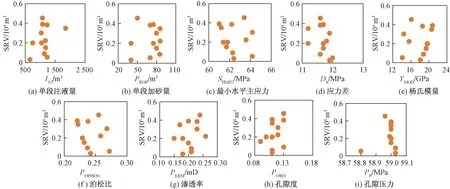
图2 M6井地质参数和工程参数与SRV的关系图
(1)
式(1)中:ρX,Y为皮尔森系数;Cov(X,Y)为两个变量的协方差;μX和μY为样本平均值;σX和σY为样本的标准差;E为期望。
如表2所示,由于SRV的数据存在一定的不确定性,因此各井计算的相关性结果有所差异。如图3所示,进一步求得了各井输入参数与SRV的平均相关性系数。可以发现,改造体积与注液量、加砂量、杨氏模量、渗透率以及孔隙度正相关,而与最小水平主应力、孔隙压力、泊松比、应力差呈负相关。根据相关性分析可以看出,玛18井区M5和M6井输入参数与SRV的相关性和平均相关性具有较高的一致性,推测这两口井数据与实际情况较为符合、数据质量较高、井情况较为简单,因此在后续甜点模型建立时优先选择这两口井的数据。从玛18井区井相关性计算结果来看,杨氏模量、泊松比和地应力与SRV相关性较强,并且总注液量与总加砂量越大,SRV范围也越广。

表2 井参数与SRV相关性计算结果
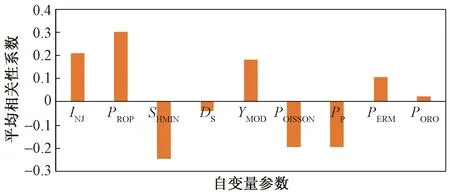
图3 各输入参数与SRV平均相关性关系图
2 压裂甜点评价研究
2.1 基于可压性模型的压裂甜点计算
储层可压裂性评价对优选压裂井段、优化开发方案和预测经济效益具有十分重要的意义。可压性是表征储层能被有效改造的难易程度的指标,与岩石力学弹性参数(杨氏模量、泊松比)、岩石强度(抗拉强度、断裂韧性)、矿物含量、脆性指数、天然裂缝参数(发育程度、强度、长度)、地应力等有关。因此,本文结合前述砾岩油藏影响裂缝扩展的主要因素分析和文献综述部分的致密油藏可压性评价模型,开展了玛湖致密砾岩油藏可压性评价模型优选和压裂甜点计算研究。主要总结和对比6种可压性评价模型(表3)。由于砾岩油藏不存在总有机碳含量(total organic carbon,TOC),因此在计算过程中去掉了表3所示可压性模型中的TOC项。此外,由于收集到的测井数据中不包含水平井各压裂段的脆性矿物含量和黏土矿物含量,因此,研究未考虑这两类参数。随后,基于总结的可压性模型,采用C++和MATLAB编写了压裂甜点计算程序。

表3 可压性计算模型统计
2.2 基于机器学习算法的压裂甜点计算
近年来,随着大数据和人工智能的发展,油气勘探开发智能化已经成为行业前沿热点和发展趋势。而目前尚未有利用水平井地质参数、工程参数和微地震监测数据的机器学习致密砾岩油藏压裂甜点预测研究。因此,开展基于机器学习算法的非常规储层压裂甜点预测研究。目前常用于回归问题的机器学习算法如表4所示[19-21]。在基于机器学习的压裂甜点预测模型中,自变量为杨氏模量等地质参数以及压裂液量等工程参数,因变量为储层改造体积。将数据集分为训练集和验证集。其中,训练集用于模型的建立,而验证集可用于评估各模型的性能好坏。

表4 用于回归问题的机器学习算法总结
提出用于压裂甜点预测的主成分分析(principal component analysis,PCA)+人工神经网络(artificial neural network,ANN)模型。PCA+ANN模型的基本思想是首先利用PCA,从多项参数中抽提出互相独立的若干项新参数系统,再利用ANN建立新的压裂甜点预测模型。利用PCA建立新模型的步骤包括:参数标准化、PCA、主成分选择和回归模型建立。如图4所示,PCA方法首先计算不同参数间的协方差矩阵,得到输入参数之间的相关性。随后通过PCA转换,获得新的相互独立的9个变量,这些变量之间的协方差矩阵如图5所示。通过PCA转换后新变量的特征值如表5所示。从这9个新变量之中,选择特征值排序前5的转换后变量作为新的输入参数,采用ANN建立压裂甜点预测模型。

图4 初始变量协方差矩阵

图5 PCA转换后变量协方差矩阵

表5 输入变量编号及PCA转换后新变量的特征值
2.3 压裂甜点模型预测效果对比
基于相关相性分析发现玛18井区压裂水平井输入参数与SRV的相关性关系更合理。因此主要采用M5和M6井的数据开展压裂甜点预测模型拟合和优选研究。根据可压性模型计算得到的是可压性指数,而可压性计算模型与压裂施工参数无关,因此采用除以总注液量的方式对SRV进行归一化处理。而可压性指数越高,代表着储层压裂改造越容易,压后SRV越大。随后比较各压裂段不同可压性模型计算的可压性指数与归一化SRV的相对大小。
如图6、图7所示,分别以M5井和两口井的总数据为样本,比较了不同可压性计算模型的预测效果。进一步以拟合优度R2评价不同可压性模型对SRV预测准确度的定量结果(表6),可以看出,文献[8,10-11]模型预测精度较高,预测单井SRV相对大小排序效果较好,可作为压裂甜点判断标准的候选模型。

表6 不同可压性模型的甜点预测精度
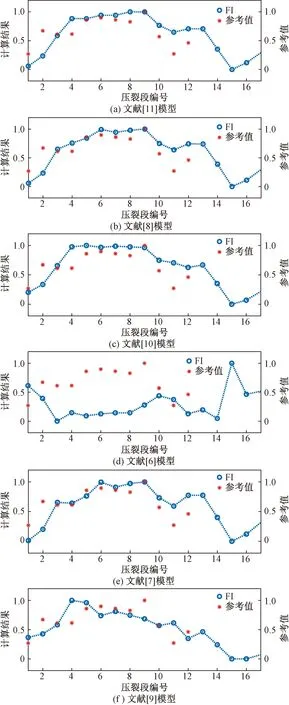
图6 M5井可压性模型预测结果

图7 玛18断块井可压性模型预测结果
随后采用玛18断块的井数据对机器学习压裂甜点预测模型进行了优选。在选择最优机器学习算法时,采用交叉检验的方法,验证算法是否合理,即M5井的数据用于训练模型,M6井的数据用于测试。基于编写的压裂甜点预测程序,对比了不同机器学习模型归一化SRV预测效果。如图8、图9所示,随机森林、Bagging回归、GRBT预测效果较好。

图8 M5井不同机器学习算法归一化SRV预测图

图9 M6井不同机器学习算法归一化SRV预测图
测试PCA+ANN模型的预测效果如图10所示。如表7所示,对比所有甜点预测模型发现,机器学习压裂甜点预测模型精度略低于基于可压性的压裂甜点预测模型精度。文献[10]模型在所有压裂甜点预测模型中表现出较好的性能。在机器学习模型中随机森林、GRBT、Bagging表现出了较好的综合性能。研究发现,部分机器学习算法的压裂甜点预测模型性能接近基于可压性计算的压裂甜点模型,但是机器学习算法性能的好坏很大程度上取决于模型建立所用样本数据库的大小和质量。随着油田开发的进行,样本数据不断迭代更新,采用所建立的机器学习压裂甜点计算流程,模型预测精度将不断提高。

表7 不同压裂甜点计算模型预测精度对比

图10 PCA+ANN模型归一化SRV预测效果
3 压裂甜点模型应用
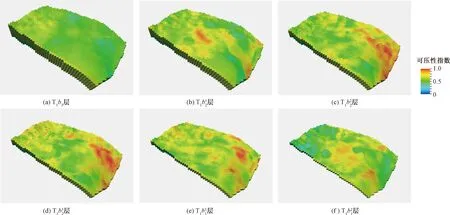
图11 玛18断块三维压裂甜点地质模型
依据产能与地质参数的相关性关系,拟合得到工区地质甜点计算公式为
SG=0.079 6φ+0.431 9K+0.140 8SO
(2)
式(2)中:SG为地质甜点系数,无量纲;φ为归一化孔隙度,无量纲;K为归一化基质渗透率,无量纲;SO为归一化含油饱和度,无量纲。
综合地质甜点与压裂甜点模型,可以计算出综合甜点。由于地质参数对产能影响程度较高,因此加重了地质甜点系数的比重。综合甜点计算公式为
Sc=2SG+FI
(3)
式(3)中:Sc为综合甜点系数,无量纲;SG为地质甜点系数,无量纲;FI为可压性指数,无量纲。

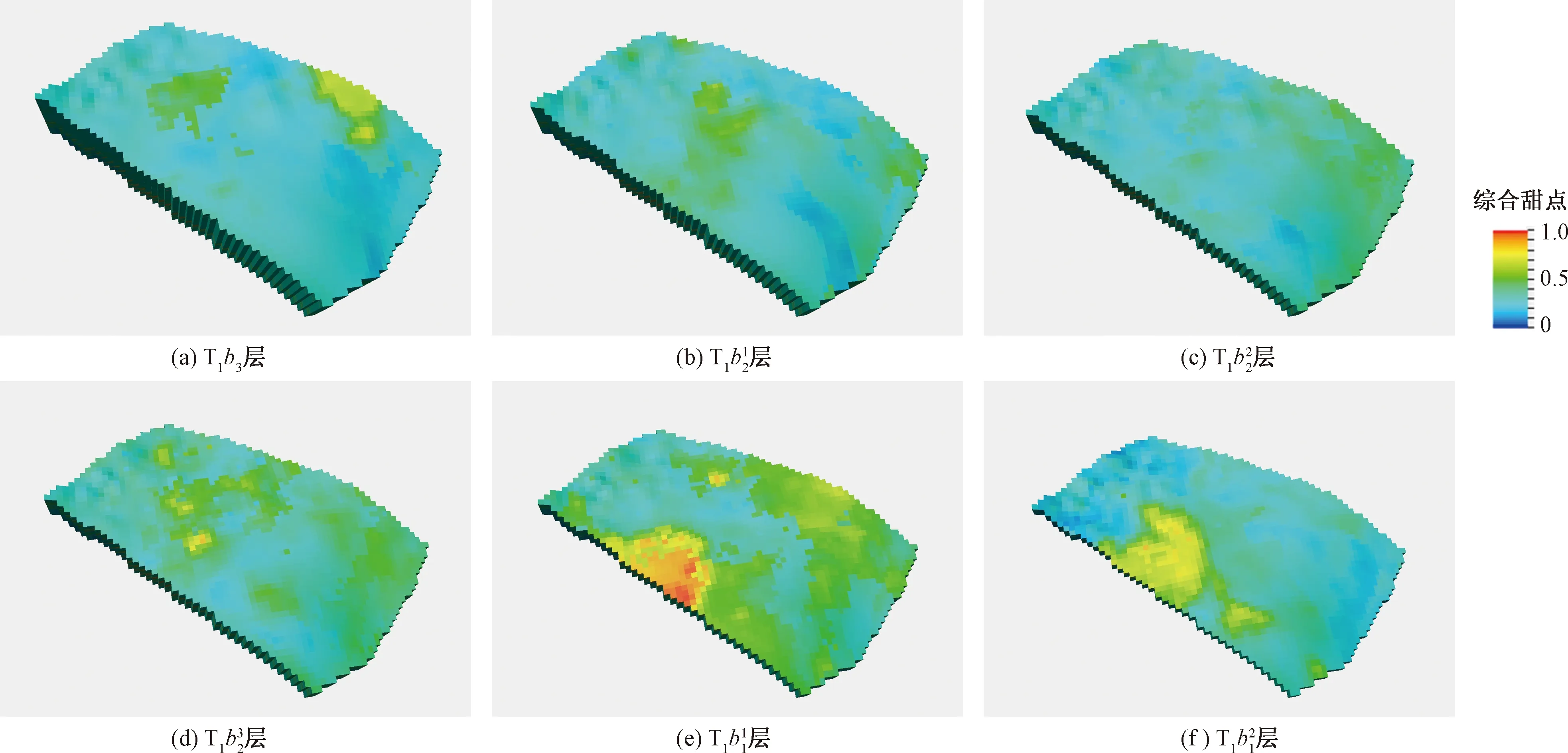
图12 玛18断块三维综合甜点地质模型
4 结论
在压裂改造效果主控因素分析基础上,优选基于可压性的压裂甜点评价方法,同时建立了基于机器学习的致密砾岩油藏压裂甜点预测模型,最终形成了适用于玛湖致密油藏的压裂甜点预测方法,为井位部署、压裂施工选井、选段提供直接指导。通过研究得到以下主要结论。
(1)通过相关性分析发现,改造体积与注液量、加砂量、杨氏模量、渗透率、孔隙度正相关,而与最小水平主应力、孔隙压力、泊松比、应力差呈现负相关关系。由于玛18井区井的微地震数据和地质力学参数可靠性更强,其输入参数与SRV的相关性和平均相关性关系具有较高的一致性。
(2)准确预测致密油藏的压裂甜点,对于优化井位部署和提高压裂施工成功率具有重要的指导意义。而对于致密砾岩油藏,通过预测效果对比认为,基于可压性指数的文献[8,10-11]模型的压裂甜点预测具有较高的精度。
(3)在基于机器学习的压裂甜点预测模型中随机森林、GRBT、Bagging模型表现出较好的性能。虽然目前基于机器学习算法的压裂甜点预测模型并未表现出优于可压性计算的压裂甜点模型,但是随着现场数据的迭代更新,采用基于机器学习的压裂甜点计算流程,模型预测精度将不断提高。
猜你喜欢
云南化工(2020年11期)2021-01-14
矿产勘查(2020年4期)2020-12-28
矿产勘查(2020年9期)2020-12-25
儿童故事画报(2020年6期)2020-08-31
儿童故事画报(2020年11期)2020-06-23
西南石油大学学报(自然科学版)(2019年2期)2019-04-25
创新作文(小学版)(2018年4期)2018-07-06
Coco薇(2016年2期)2016-03-22
西南石油大学学报(自然科学版)(2015年4期)2015-08-20
西南石油大学学报(自然科学版)(2015年3期)2015-04-16
