
基于Logistic方法构建的中国降雪判定方法研究
2022-12-18 06:15:58林文青陈活泼
大气科学学报 2022年6期
林文青,陈活泼
中国科学院 大气物理研究所 竺可桢-南森国际研究中心,北京 100029
降雪是降水在特定温度等气象要素条件下的一种表现形式。长期以来,受限于人工观测误差大、观测站点稀少等客观因素,降雪观测资料收集尚存在诸多问题。因此,从降水数据中区分降雪就成了众多科学研究的首要选择。然而,目前大多数的气象、水文、遥感等相关研究中,降水相态的雪相和雨相的区分只基于给定的温度(即单温度阈值法)(Forbes et al.,2014;Froidurot et al.,2014)。这类方法在研究区域范围内使用空间均一的临界温度结合降水数据,作为降雪判定的依据。例如,将气温小于0 ℃时的降水(降水量大于0.1 mm)判定为降雪(董啸等,2010;齐非非和范昊明,2015;努尔比亚等,2016;陈海山等,2019),进而进行部分区域降雪变化特征和成因机制方面的分析。Sun et al.(2010)利用0 cm地表温度和气温小于0 ℃的降水定义降雪,并对其变化特征进行分析,发现近年来我国青藏高原东部、新疆北部的极端降雪呈显著增加趋势,而东部地区则呈减少趋势。此外,由于相对湿度可以通过控制雪花蒸发冷却影响周围空气温度与降水的关系,有研究认为相较于气温,湿球温度或露点温度更接近降水粒子的实际温度,并且可以通过解释蒸发冷却效应而提高对降雪判定的准确性(Ye et al.,2013;Behrangi et al.,2018)。Marks et al.(2013)将湿球温度小于0 ℃的降水认定为降雪,并通过分析美国爱达荷州奥威希山脉站点资料发现降水相态的判定与地表湿度密切相关。Ye et al.(2013)认为露点温度小于0 ℃为区分欧亚大陆北部地区降水相态的关键。
随着气候变暖加剧,未来降水持续增多,而北半球大多数地区的降雪减少(Krasting et al.,2013;Chen et al.,2020;Lin and Chen,2022),导致更多的降水以降雨的形式出现,这可能会使洪水等极端事件发生的概率显著增加(Chen et al.,2013;尹家波等,2021)。在这一背景下,仅根据简单的、空间均一的温度阈值来划分降水相态,将大大增加降雪估计的偏差,并使得偏差传播到河流径流、地表反照率和地表-大气能量交换估算中,对未来气候变化预估等研究造成了很大的不确定性。近年来的研究表明,除气温外的其他气象要素,如湿度、气压、风速、海拔高度等对降雪的发生也有着重要的影响。例如,韩春坛等(2010)利用中国站点资料建立了降雪临界温度与站点海拔高度、经纬度的经验公式,将降雪认定为气温小于该临界温度时的降水。此外,已有观测研究表明,雨、雪相态变化依赖于与温度相关的经验函数(S曲线法)。Legates(1987)利用Cehak-Trock(1957)提供的格陵兰岛附近23个站点的长期月平均降雪量和降水量数据与气温进行拟合得到降雪判定的经验公式,后被广泛应用于欧亚大陆乃至全球的降雪变化研究(Legates and Willmott 1990;Rawlins et al.,2006;Krasting et al.,2013)。Ding et al.(2014)利用1951—1979年中国地区站点资料建立了降水相态与湿球温度的经验公式;秦艳等(2020)利用Ding et al.(2014)的方法对天山1961—2018年雪水比变化特征进行分析,发现天山雪水比(降雪量/降水量)以0.016%/(10 a)的趋势减少;章诞武等(2016)、赵求东等(2020)也使用Ding et al.(2014)的方法对中国降雪和极端降雪特征进行了相应分析;但罗江姗(2020)对中国地区降雪判定方法评估的研究表明,相比于气温(小于0 ℃)、850~700 hPa高度场厚度(小于1 500 m)和Ding et al.(2014)的方法,按照湿球温度小于0 ℃判定的降雪要与观测降雪更为接近。
相较于前文提到的单温度阈值法和S曲线法,基于观测气象资料拟合的Logistic模型对降水相态的识别结果更为稳定。在瑞士地区降雪判定方法的探讨中,Koistinenand Saltikoff(1998)使用雪水频次比与气温进行Logistic一元拟合。Froidurot et al.(2014)在此基础上将他们的方法发展为分别考虑单因子(仅考虑温度)和多因子(温度+其他变量)的多元Logistic拟合,并且发现在所有的Logistic拟合变量测试中,地表气温和相对湿度组合的方式对降水相态识别解释能力最强。Behrangi et al.(2018)对全球32个地区多种降雪判定方法的评估结果表明,Logistic多因子拟合方法可以更好地区分降雨和降雪,并且优于单因子拟合和其他单温度阈值方法。Jennings et al.(2018)基于Logistic模型对北半球雨雪相区分的研究中也指出,气温+相对湿度或湿球温度的Logistic方案在[-1,3] ℃区间的降雪判别性能要明显优于单温度阈值方法。此外,Chen et al.(2014)指出,利用Koistinen and Saltikoff(1998)提出的Logistic一元回归模型计算的中国地区降雪准确率高于仅使用气温小于0 ℃进行判定的结果。因此,基于中国地区的观测资料,使用Logistic多因子拟合方法因地制宜地建立降雪判定方法,从而准确地从降水中区分降雪,对增强降雪判定的稳健性至关重要,这是本文重点关注的科学问题。
1 数据和方法
1.1 数据
由于中国地区1980年之后的降水数据未标记其数据类型(韩春坛等,2010;Ding et al.,2014),所以本文选用的站点观测资料为:1951—1979年中国824个台站的地面气候资料日值数据集(中国气象局(CMA)V3.0:包含逐日降水、气温、0 cm地面温度、相对湿度、风速、气压、海拔高度、经度、纬度等变量)。
考虑到降水相态的不确定区间主要在[-10,10] ℃的温度区间内(Dai,2008),本文剔除了气温大于10 ℃时的降雪和气温小于-10 ℃时的降雨数据。经过缺测筛选,最终选取819个站点资料(图1)。为了便于后续不同地区降雪变化的分析,将中国地区分为:西北地区(NWC:75°~111°E,36°~46°N)、青藏高原地区(TIB:77°~106°E,27°~40°N)、华北地区(NC:111°~119°E,36°~46°N)、东北地区(NEC:119°~134°E,39°~54°N)、华东地区(EC:116°~122°E,27°~36°N)、华中地区(CC:102°~116°E,27°~36°N)、西南地区(SWC:97°~106°E,21°~27°N)和南方地区(SC:106°~120°E,20°~27°N)(Xu et al.,2015)(图1)。

图1 中国区域观测站分布及分区(NWC为西北地区,TIB为青藏高原地区,NC为华北地区,NEC为东北地区,EC为华东地区,CC为中部地区,SWC为西南地区,SC为南方地区)
1.2 研究方法
1.2.1 降雪判定方法
① 单温度阈值法
本文选取的单温度阈值法主要有5种,包括基于气温(Ta)、湿球温度(Tw)、露点温度(Td)、0 cm的地面温度(T0)低于0 ℃时的降水(日降水量>0.1 mm)(董啸等,2010;Sun et al.,2010;Marks et al.,2013;Ye et al.,2013),以及气温低于特定降雪临界温度(韩春坛等,2010)时的降水定义为降雪;依次称为气温法、湿球温度法、露点温度法、0 cm地面温度法和Han方法。其中,Han方法中的Tc即为根据中国站点海拔高度(H)、经度(E)和纬度(N)确定的临界温度,呈动态变化,如式(1)所示:
Tc=0.014 5E-0.023 4N+0.000 4H+5.338 2。
(1)
利用Stull(2011)和Bolton(1980)的方法分别计算湿球温度(Tw)和露点温度(Td),具体如下:

atan(Ta+HR)-atan(HR-1.676 331)+
4.686 035。
(2)
(3)
(4)
其中:b=17.67;c=243.58 ℃;HR为相对湿度。
② S曲线法
本文选取的S曲线法包括Legates(1987)和Ding et al.(2014)的方法(下文称为Ding方法),具体如下:
F=(1.0+1.61×(1.35)Ta)-1,S=F·P。
(5)
(6)
其中:F为降雪(S)占降水(P)的比例(后称雪水频次比),Ding方法中的ΔS为调节温度尺度的参数(ΔS=2.734-1.634×HR)。
③ Logistic方法
本文认为Logistic降雪判定模型中的降水仅由降雪和降雨两部分构成,因而不讨论雨夹雪、雾、露、霜等的变化(详见2.2节)。基于观测数据的Logistic拟合方法中α、β、γ、λ、ξ为模型参数,psnow为降雪发生概率(Froidurot et al.,2014;Behrangi et al.,2018;Jennings et al.,2018),T为温度,具体如下:
(7)
(8)
(9)
(10)
为了评估不同因素对降雪判定的贡献,分别进行Logistic单因子(只包含温度,参数γ、λ、ξ均为0)和多因子拟合的对比研究。将温度(气温(Ta)、湿球温度(Tw)、露点温度(Td))和相对湿度(HR)、气压(P)、风速(W)的组合作为模拟变量,对观测数据进行10种Logistic回归拟合;分别称为:气温方案(LogTa、LogTaHR、LogTaHRP、LogTaHRPW)、湿球温度方案(LogTw、LogTwP、LogTwPW)和露点温度方案(LogTd、LogTdP、LogTdPW)。例如,LogTa、LogTw和LogTd方案中温度T分别为气温(HR)、湿球温度(Tw)和露点温度(Td),此时参数α和β由降雪发生概率psnow和相应温度通过式(7)回归得出。
1.2.2 降雪方法评价指标
通过降雪判定成功率和Heidke技巧评分对各方法模拟降雪的准确性进行定量化计算,二者越接近于1.0越好,具体如下:
① 降雪判定成功率=1-未正确判定降雪的比率。
② Heidke技巧评分(Heidke Skill Score,SHS)(Heidke,1926),SHS的数值范围为[-1,1],如式(11)和(12)所示:
(11)
(12)
式(11)中:N11为判定发生且观测也发生的降雪样本数量;N00为判定和观测均不发生的降雪样本数量;N10为判定发生但观测不发生的降雪样本数量;N01为判定不发生但观测发生的降雪样本数量;C为参数值,如式(12)所示。
③ 降雪量拟合效果评价方法
利用均方根误差(ERMS)、平均绝对百分误差(EMAP)、模型一致性指数(IA)和拟合优度(R2)对S曲线法、Logistic拟合方法计算得到的降雪量与观测之间的拟合效果进行评价。
(13)
(14)
(15)
(16)

2 结果与分析
2.1 降水类型资料分析

图2 1951—1979年中国区域降雪(红色)和降雨(蓝色)发生站次数与气温Ta(a)、湿球温度Tw(b)、露点温度Td(c)、0 cm地面温度T0(d)的关系
据统计,1951—1979年中国地区[-10,10] ℃气温区间内降雨样本数为115 788站次,降雪样本数为54 421站次,降水样本数(降雨和降雪事件的总和)为170 209站次。图2为气温、湿球温度、露点温度、0 cm地面温度区间范围内的降雪和降雨样本数量统计。中国地区降雪主要分布在西北(6 007站次)、华北(4 344站次)、东北(16 785站次)、青藏高原(12 166站次)、华中(7 146站次)和华东地区(7 631站次),而西南(165站次)和南方地区(177站次)相对较少。中国地区[-10,10] ℃气温区间内99.99%的降雪发生在气温Ta≤8 ℃的温度范围,99.99%的降雨发生在Ta≥-8 ℃的范围。即雨雪事件的重叠范围,也就是雨、雪相共存的气温范围大致为:[-8,8] ℃。考虑到使用不同温度时,雨雪事件重叠范围的差异性,本文统一选取降雨(降雪)事件/总降水事件≥98%的温度范围进行后续研究。气温Ta、湿球温度Tw、露点温度Td、0 cm地面温度T0的[-8,8] ℃区间内,大于等于98%雨雪事件的温度重叠范围分别:[-3,4]、[-3,1]、[-5,0]和[-2,6] ℃。
以往研究将雪水频次比F>50%时发生的降水全部归类为降雪,而F<50%时则全部为降雨(Koistinen and Saltikoff,1998;Froidurot et al.,2014;Behrangi et al.,2018;Jennings et al.,2018)。图3为中国地区[-8,8] ℃之间统计的降雪、降雨、雨夹雪事件发生概率与气温的关系。当同时考虑降雨、降雪、雨夹雪时,降雪发生概率(雪水频次比)与气温呈现类似Logistic曲线的关系,随气温由-8 ℃增至8 ℃,降雪发生概率逐渐减小为0;降雨发生概率则与降雪呈近似相反的分布,而雨夹雪呈钟形分布且在1~2 ℃发生概率达到最大。三者发生概率的交点,为降水相态转变的临界点,在F=35%附近。但如果不考虑雨夹雪等降水混合相态的变化(图3b),降雨和降雪发生概率与气温的曲线交点在F=50%附近。因此,在本研究降水相态判定中,仍沿用前人雪水频次比F=50%时的温度作为降水相态判断的临界温度,当F>50%时发生的降水即为降雪,当F<50%时发生的降水则为降雨。
图4给出了雪水频次比F与Ta、Tw、Td和T0的关系,发现这四种温度与雪水频次比均呈现类似Logistic曲线的关系,且雪水频次比F=50%处的温度从小到大依次为:Td、Tw、Ta和T0。此外,Ta、Tw和Td的雨雪事件重叠温度范围明显小于T0,故后续雪水频次比与温度的Logistic拟合选用Ta、Tw和Td以及其他影响降雪事件发生的气象要素进行。
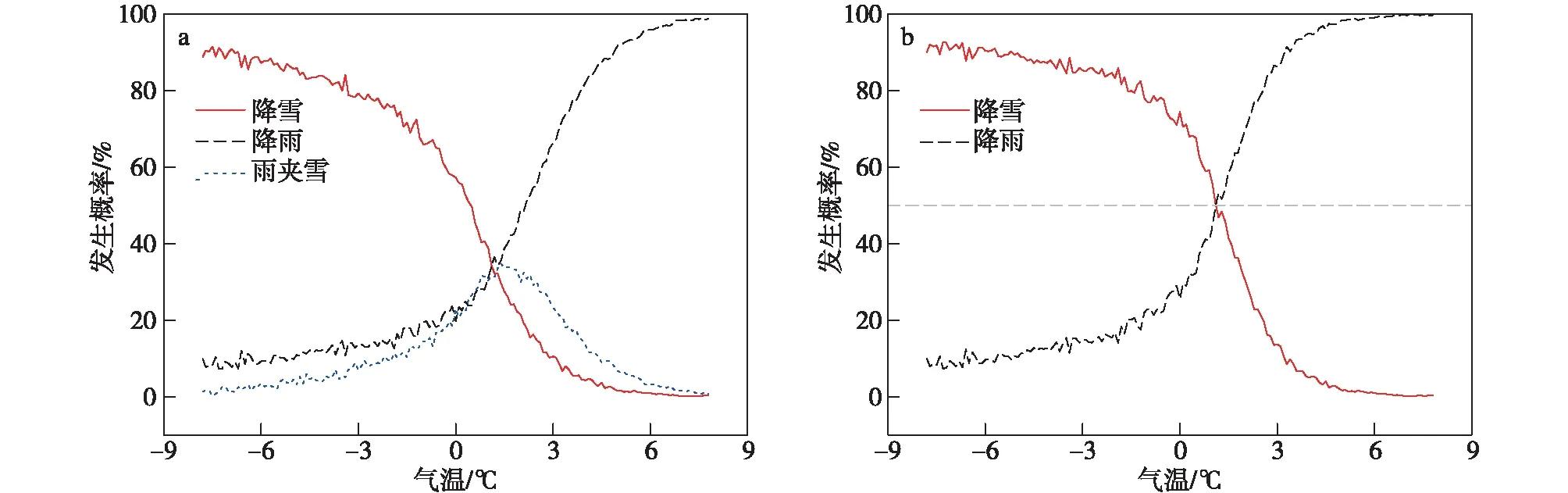
图3 观测站降雪、降雨和雨夹雪发生概率与温度的关系(a),以及仅考虑降雪、降雨时二者发生概率与温度的关系(b)

图4 雪水频次比F与气温Ta、湿球温度Tw、露点温度Td、0 cm地面温度T0的关系
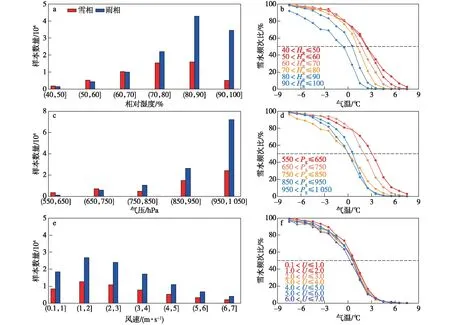
图5 中国区域降雪(红色)和降雨(蓝色)在相对湿度(a、b)、气压(c、d)、风速(e、f)各区间的样本数量(a、c、e),以及对应的雪水频次比与气温的关系(b、d、f)
为了探究不同气象因子对降雪的影响,统计了[-8,8] ℃之间相对湿度HR、地面气压P、风速(图5)海拔高度和经纬度(图未显示)在不同区间下的雨雪样本数量。将HR分为6个区间(40,50]、(50,60]、(60,70]、(70,80]、(80,90]、(90,100]%;将P分为5个区间(550,650]、(650,750]、(750,850]、(850,950]、(950,1 050] hPa;将风速分为7个区间(0.1,1.0]、(1.0,2.0]、(2.0,3.0]、(3.0,4.0]、(4.0,5.0]、(5.0,6.0]、(6.0,7.0] m/s。从图5中可以看出降雪、降雨事件数量随着HR升高和风速的增大先增多再减少。降雪事件数量分别在相对湿度(70,80]%(15 520站次)和风速(1.0,2.0] m/s(12 656站次)的区间达到最大随后减小;降雨事件数量在湿度区间(80,90]%(43 024站次)和风速区间(1.0,2.0] m/s(26 765站次)达到峰值。而降雪和降雨与气压关系较为类似,随着气压的增大,雨雪样本数量逐渐增多,在(950,1 050]hPa区间(降雪:24 147站次;降雨:72 056站次)样本数量到达峰值。此外,从不同HR和风速区间下的雪水频次比与温度的关系中可以看出,随着HR升高和风速增大,气温Ta=0 ℃时的雪水频次比F依次降低,即低温低湿和低温低风速条件有利于降雪事件的发生。就不同P区间下的F与Ta的关系可以看出气温Ta=0 ℃时,通常较低的气压区间发生雪水频次F更大。即低温低压条件通常有利于降雪事件的发生。相比较而言,风速对降雪事件发生的影响要小于相对湿度和气压的影响。
值得注意的是,海拔高度0~1 km分布的降雪事件数量达到总降雪事件的56%,降雨事件数量为总降雨事件的71%(图略);而在海拔高度4~5 km分布的降雪事件仅为总降雪事件的3%。虽然不同海拔高度、经度、纬度区间下的F与温度也呈现类Logistic曲线关系,但考虑到中国地区站点分布等因素的影响,我们认为这三个变量对中国全域降雪判定探讨的参考意义较小。所以在选取除温度外的影响降雪判定的气象因子时,只选用HR、P和风速。
2.2 基于Logistic方法建立降雪判定模型
考虑到中国地区降雪主要分布在西北、华北、东北、青藏高原、华中和华东地区,而西南和南方地区相对较少。因此,在进行雪水频次比F和其他影响因素的Logistic拟合时,我们分别进行整个中国、西北、华北、东北、青藏高原、华中和华东地区的模型构建,西南和南方地区的降雪则采用整个中国区域的Logistic模型进行计算。据统计,中国地区819个站点降水资料中,[-8,8] ℃之间的降水数据记录有170 209条。这里选取大量样本作为训练集,约占总量的90%,而剩余的10%作为验证集。以中国站点的降雪判定Logistic模型为例,通过对训练集中随机5 000个降雪、降水和温度(气温、湿球温度、露点温度)以及其他变量(相对湿度、气压、风速)进行75次Logistic拟合,训练得到75组系数。在此过程中,使用Fisher评分算法中的广义线性模型优化系数(Jennings et al.,2018),从而减少模型相对于5 000个随机观测数据的偏差。最后,取平均值作为最终选定的系数。其中,Logistic单因子拟合系数如表1所示。

表1 用中国观测数据拟合的Logistic方法系数
对西北、华北、东北、青藏高原、华中和华东地区的Logistic模型构建与中国地区的类似,但受到数据量的限制,系数训练次数为10次。

图6 17种降雪判定方法在不同温度区间的正确率:(a)训练集;(b)验证集
2.3 各降雪判定方法在中国地区的适用性比较
本节使用降雪事件成功率、SHS指数和降雪量拟合效果评价方法对1.2.1节中所列单阈值方法、S曲线法和2.2节中基于中国地区资料建立的Logistic降雪判定模型的降雪模拟性能进行对比研究,讨论这些降雪判定方法(共计17种)在中国地区的适用性。图6为中国地区17种降雪判定方法在气温[-8,8] ℃区间内降雪事件训练集和验证集的成功率。从各方法训练集的降雪判定成功率比较中可以看出,基于气温、湿球温度、露点温度、0 cm地面温度的单温度阈值方法判定的降雪事件在气温大于4 ℃和小于2.5 ℃时有着较高的成功率,普遍大于0.85;而在气温[-2.5,4] ℃之间成功率较低。尤其是基于0 cm地面温度法和气温法判定的降雪事件在[0,1] ℃附近成功率小于0.50,而湿球温度法在该范围内的正确率大于0.55,略优于气温法和0 cm地面温度法。
Han方法则对[0,3.5] ℃温度范围内的降雪判定存在较大不确定性,该范围内的各温度区间降雪判定正确率均小于0.5。而Legates方法判定的降雪,其气温范围主要为[-1,1] ℃(图6)。相较于单温度阈值法和S曲线法,Logistic拟合系列方法的降雪事件成功率更高;除LogTa外,对[-1,1] ℃内的各温度区间成功率也均高于0.60。而从Logistic拟合系列方法的成功率比较中也可以看出,湿球温度方案要优于气温方案和露点温度方案。而湿球温度方案中LogTw、LogTwP和LogTwPW的成功率较为接近,也就是说在Logistic拟合方法中考虑了气温和相对湿度的方案要优于仅考虑气温的方案,但气压和风速则对降雪事件判定成功率的影响不大。从图6b验证集降雪事件成功率分析中可以得到与训练集较为一致的结果。
从[40,100]%相对湿度区间的各方法训练集和验证集的成功率分布(图7)中可以看出,在单温度阈值方法中,露点温度法和0cm地面温度法在相对湿度[40,55]%区间内的降雪判定成功率小于0.65,而气温法、湿球温度法和Han的方法成功率大于0.75。S曲线法中,Ding的方法对不同相对湿度区间估计的正确率估计均大于0.75,而Legates方法的成功率要相对差一些,但也都大于0.70。综合来看,Logistic气温方案和湿球温度方案要优于露点温度方案以及单温度阈值法和S曲线法。

图7 17种降雪判定方法在不同相对湿度区间的正确率:(a)训练集;(b)验证集
图8给出了利用LogTa、LogTw和LogTd方案中当站点雪水频次比F=50%时的温度计算得到的全国站点降雪临界温度分布。可以看出,青藏高原地区降雪临界气温、临界湿球温度和临界露点温度均高于其他地区,平均而言分别为:1.4、-0.9和-3.4 ℃。也就是说利用气温法(Ta<0 ℃)判定降雪时可能会低估青藏高原地区降雪量,而利用湿球温度法(Tw<0 ℃)和露点温度法(Td<0 ℃)可能会高估青藏高原降雪量,后续将进行进一步的补充验证。此外,平均而言,西北、华北、东北、华中和华东地区,Logistic方法计算得出的降雪临界气温分别为:0.3、0.03、-0.5、0.1和-0.6 ℃;临界湿球温度分别为:-1.5、-2.1、-2.6、-1.7和-2.0 ℃;临界露点温度分别为-3.3、-4.3、-4.8、-3.3和-4.1 ℃;进一步说明不同地区站点降雪的临界温度各有不同,为了保证降雪判定的准确性,应该采取合理的动态阈值方法进行计算。
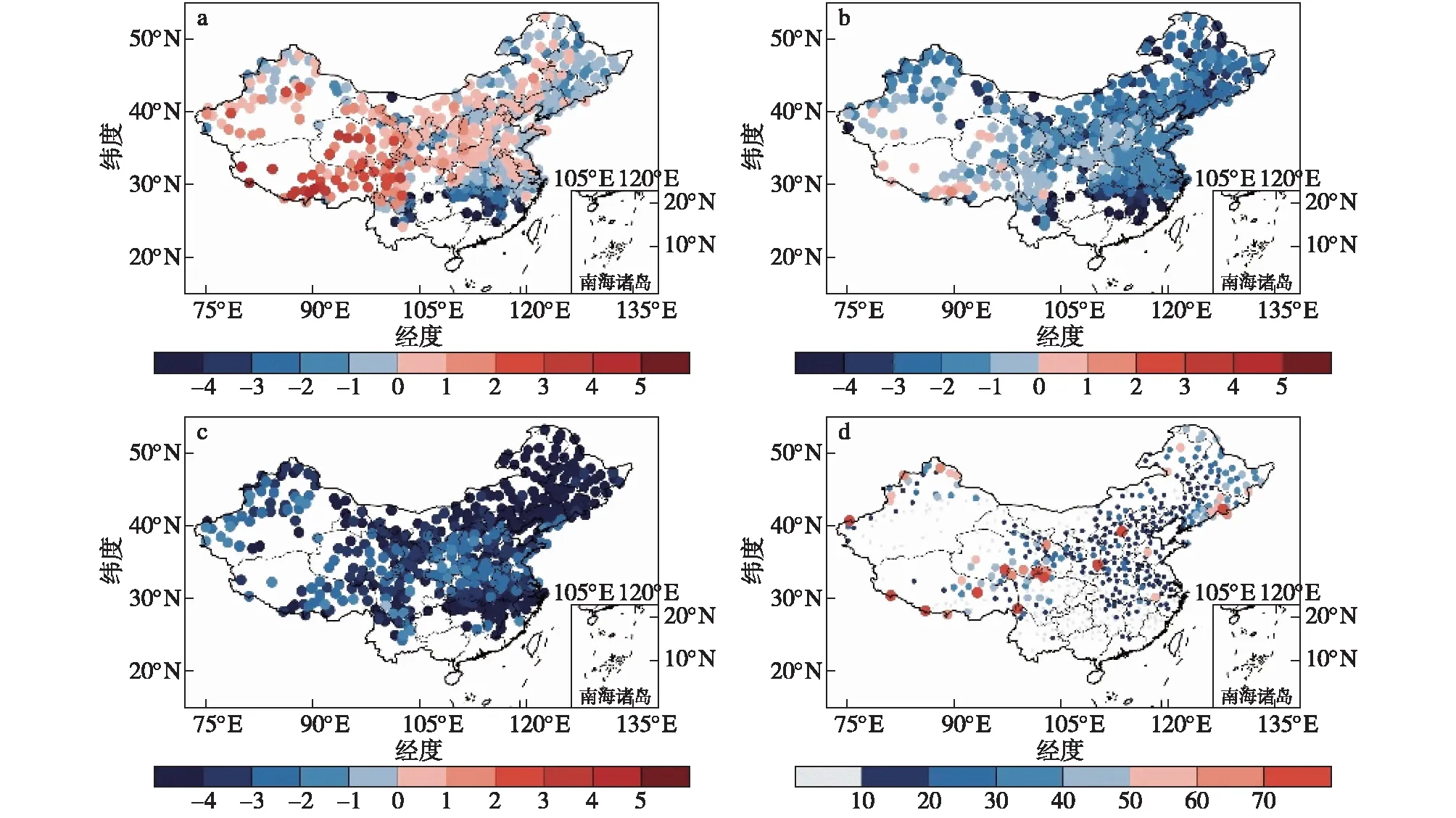
图8 Logistic方法得到的降雪临界气温(a;单位:℃)、临界湿球温度(b;单位:℃)和临界露点温度(c;单位:℃),以及观测的降雪量(d;单位:mm)
通过对不同区域降雪判定效果的评估,可以明确各种方法对各区域降雪判定的适用性。Heidke评分指数(SHS)可以反映不同的降雪判定方法对降雪事件的模拟能力,值越接近1.0越好(Behrangi et al.,2018)。图9为17种方法判定的不同地区SHS指数分布。在气温[-8,8] ℃区间内,对单温度阈值方法而言,露点温度法在整个中国的SHS值为0.82,小于其他方法。此外,单温度阈值法对青藏高原地区的降雪模拟效果普遍劣于其他区域,尤其是0 cm地面温度法在青藏高原地区的SHS值仅为0.57;相比于气温法,湿球温度法在各地区的SHS均达到0.80以上,即湿球温度法对各地区降雪模拟效果要优于气温法。在S曲线法中,Ding方法除东北地区外,对其他区域的降雪模拟均优于Legates方法;Ding方法在整个中国区域的SHS为0.86,大于Legates方法的0.84。值得注意的是,Logistic拟合方法对整个中国地区的降雪判定而言,考虑了相对湿度的气温方案和湿球温度方案SHS为0.90,仅考虑气温的方案SHS为0.88,而露点温度的三个方案(LogTd、LogTdP、LogTdPW)的SHS约为0.87。相比较而言,Logistic拟合的系列方法对各地区降雪判定较为稳健,尤其是在青藏高原地区;其中考虑了相对湿度的气温方案和湿球温度系列方案在青藏高原的SHS均大于0.84,露点温度系列方案SHS大于0.82,而仅考虑气温的方案SHS为0.80,但也优于单温度阈值中的气温法(0.74)。在气温[-3,4] ℃区间内,各方法对降雪判定的准确度均有所降低,但Logistic拟合方法的气温方案和湿球温度方案明显优于露点温度方案和其他方法。Logistic气温方案与湿球温度方案单因子和多因子拟合之间SHS差别相对较小,也就是说气压和风速等因子对降雪的判定影响不大,即气温和相对湿度是影响降雪发生的先决条件。因此,LogTa、LogTaHR和LogTw三种方案对各地区降雪事件的模拟要优于单阈值方法和S曲线法。

图9 17种降雪判定方法在不同气温区间的Heidke技巧评分指数:(a)[-8,8] ℃;(b)[-3,4] ℃
为验证LogTa、LogTaHR和LogTw三种方案的稳定性,我们利用这三种方法及其他降雪判定方法所得的降雪量与观测结果进行对比。图8d给出了1951—1979年中国地区观测降雪量气候态。可以看到,观测降雪主要分布在西北、华北、东北和青藏高原地区。其中青藏高原大部分站点年降雪量超过40 mm。在北纬25°N以南的地区降雪量分布较少,年平均降雪量低于10 mm。

图10 1951—1979年5种单温度阈值方法计算的降雪量(a、c、e、g、i)及其与观测值的偏差(b、d、f、h、j)(单位:mm):(a、b)Ta;(c、d)Tw;(e、f)Td;(g、h)T0;(i、j)Han
图10分别给出了1951—1979年单温度阈值法计算的中国地区降雪量及与观测的偏差。可以看出,在单温度阈值方法中,湿球温度法、露点温度法和Han的方法对中国大多数地区的降雪量有着不同程度的高估,尤其在南方地区高估更为明显;平均而言,对降雪量分别高估了36.4%、63.8%和127.1%。气温法对降雪量的高估为8.2%,0 cm地面温度法对降雪量低估为11.0%。在青藏高原地区,气温法对降雪量明显低估,而湿球温度法和露点温度法则高估了降雪量,这与图8的分析结果一致。
在S曲线法中,基于湿球温度判定降雪的Ding方法同样高估了中国大部分地区的降雪量,正偏差为66.8%(图11)。而基于气温判定降雪的Legates的方法其降雪量负偏差明显(-14.4%)。由于Logistic单因子(只考虑温度)和双因子(考虑温度和HR)拟合的雪水频次比和降雪量都较为接近,且LogTa、LogTaHR和LogTw三种方案对降雪的判定效果要优于单阈值方法和S曲线法。因此,这里仅展示这三种方案的拟合结果。相比于单温度阈值方法和S曲线法,Logistic系列拟合方法估计的雪水频次比和降雪量分布与观测更为接近,但不同的Logistic拟合方法之间存在些许差异(图11)。例如,LogTa方案对中国中部和华东的部分地区降雪量略有高估,而LogTaHR和LogTw方案则相反。平均而言,LogTa、LogTaHR和LogTw方案与观测降雪量之间的偏差依次为:17.0%,1.7%和1.9%,可以看出与观测的偏差均小于其他方法。总体而言,LogTaHR和LogTw方案对各地区雪水频次比和降雪量的判定要优于单温度阈值方法、S曲线法及其他Logistic方法。
此外,分析不同地区降雪量的变化情况,可以看出各地区观测降雪量呈现出明显的年际变化特征(图12)。相较于S曲线法,Logistic系列方法判定的降雪量与观测更为接近,且能够很好地捕捉其年际变化特征,尤其在西北、华北、东北和华中地区(图12)。Ding方法对降雪量的高估在除华北以外的地区都较为明显,尤其是在青藏高原地区;在青藏高原地区观测降雪量均值为29.0 mm,而Ding方法估计的降雪量均值达到44.1 mm(表2),其ERMS高达15.3 mm,EMAP为53.9%,模型一致性指数仅为0.44。Legates方法则对各地区降雪存在不同程度的低估,尤其对于青藏高原地区,均值仅为22.6 mm,ERMS为7.3 mm,EMAP为21.8%,模型一致性指数为0.63,略优于Ding的方法。
从LogTa、LogTaHR和LogTw方案在青藏高原地区降雪量判定的时间序列上可以看出,LogTaHR的均值(29.7 mm)与观测最为接近,且其ERMS仅为2.5 mm,EMAP为7.5%,R2为0.81,IA为0.94。也就是说在对青藏高原地区降雪量的判定上,LogTaHR方案要优于S曲线法和其他Logistic方案。此外,对于西北地区,各个方法在均值、ERMS、EMAP、R2和IA方面的差距较小,但总的来说LogTw拟合效果评价参数均达到最优。在华北和东北地区,LogTaHR方案以ERMS、EMAP较小和决定系数R2大于0.97、IA大于0.99的优势略领先于LogTw方案。此外,Logistic系列方法对华中地区降雪判定结果显示,LogTa方案与LogTw方案结果较为接近,优于LogTaHR方案和S曲线法。在华东地区,LogTw方案判定降雪量的均值为14.5 mm,与观测14.1 mm更为接近,其ERMS为2.6 mm,EMAP为17.1%,模型IA为0.96,优于其他方法。
总的来说,Logistic方案对降雪的判定效果整体上优于S曲线法,而考虑温度和湿度结合的Logistic方案要优于仅考虑气温的方案,但气温+相对湿度和湿球温度方案之间的差别不大。综合降雪事件成功率、SHS指数和降雪量及时间序列的分析结果可以看到,LogTw方案(或LogTaHR方案)具有更高的准确率,更适用于中国地区降雪的判定。表3为各地区Logistic方法系数。
3 结论
本文采用中国地面气候日值数据集分析了中国地区降雪与各气象因子之间的关系,在此基础上发展了基于Logistic拟合方法的中国地区降雪判定新方法,并与单温度阈值法和S曲线法等降雪判定方法在中国地区的适用性开展对比研究,主要结论如下:
1)中国地区降雪主要分布在青藏高原、西北、东北、华北、华东和华中地区,而西南和南方地区相对较少。雨、雪事件的气温重叠范围为[-8,8] ℃,在此区间内,降雪发生概率(雪水频次比F)与气温呈现类似Logistic曲线的关系。随气温由-8 ℃增至8 ℃,降雪发生概率逐渐减小为0%;认定在F=50%附近雨、雪相态发生转变,当F>50%时发生的降水即为降雪,当F<50%时发生的降水则为降雨。一般情况下,低温低湿、低温低压、低温低风速条件有利于降雪事件的发生。

图11 1951—1979年S曲线法和Logistic方法计算的降雪量(a、c、e、g、i)及其与观测值的偏差(b、d、f、h、j)(单位:mm):(a、b)Ding;(c、d)Legates;(e、f)LogTa;(g、h)LogTaHR;(i、j)LogTw
2)分别针对整个中国以及不同区域构建基于Logistic拟合方法的降雪判定模型。降雪判定性能评估结果指出,单温度阈值法在[-2.5,4] ℃气温区间内的降雪判定成功率较低,Ding方法在[0,3.5] ℃范围内的成功率小于0.50,而Legates方法在[-1,1] ℃对降雪判定存在较大不确定性。相比较而言,Logistic拟合系列方法对降雪事件判定的成功率均值更高,且湿球温度方案要优于气温方案和露点温度方案。不同区域降雪判定效果评分指数SHS也表明Logistic拟合系列方法对各地区降雪模拟也较为稳健,尤其在青藏高原地区。但Logistic方法中温度和相对湿度对降雪的判定影响较大,而气压和风速的影响较小。总的来说,LogTa、LogTaHR和LogTw三种方案对降雪事件的判别准确度要高于单阈值方法和S曲线法。

图12 中国不同区域观测的以及S曲线法、Logistic方法拟合的降雪量时间序列:(a)NWC;(b)NC;(c)NEC;(d)TIB;(e)CC;(f)EC

表2 S曲线法和Logistic方法模拟的降雪量与观测降雪量的比较

续表2

表3 用中国6个子区域观测数据拟合的Logistic方法系数
3)LogTa、LogTaHR和LogTw方案拟合的降雪量与观测较为接近,且偏差均小于其他方法。Logistic系列方法判别的各地区降雪量的年际变化与观测较为接近;尤其在青藏高原地区,LogTaHR方案判定结果与观测的一致性指数达到0.94,而Ding和Legates方法分别仅为0.44和0.63。综合降雪事件判定成功率、SHS指数和降雪量时空变化分析结果,Logistic方案对降雪判定效果明显优于其他方法,而湿球温度方案(LogTw)和气温+相对湿度方案(LogTaHR)差别不大。因此LogTw方案(或LogTaHR方案)对中国地区降雪判定具有更高的准确率。
猜你喜欢
暖通空调(2024年1期)2024-01-25 03:40:26
气象与环境学报(2022年5期)2022-11-05 13:43:58
祝您健康·文摘版(2022年7期)2022-07-07 22:01:47
水利水电快报(2019年10期)2019-09-10 07:22:44
Advances in Meteorological Science and Technology(2019年2期)2019-05-31 01:34:18
少儿科技(2018年7期)2018-08-04 22:35:11
成都信息工程大学学报(2017年6期)2017-03-16 03:04:39
西藏科技(2016年10期)2016-09-26 09:02:08
电力勘测设计(2015年3期)2015-03-22 05:10:28
海外星云 (2012年5期)2012-04-29 00:44:38
