
基于PCA-ELM的矿井突水水源识别方法研究
2022-12-17 05:08梁戈龙李继升冯来宏李唐玥琪
能源环境保护 2022年6期
梁戈龙,李继升,冯来宏,杜 松,李唐玥琪
(1. 华能庆阳煤电有限责任公司核桃峪煤矿,甘肃 庆阳 745306;2. 华能煤炭技术研究有限公司,北京 101100;3. 中国煤炭地质总局勘查研究总院,北京 100039)
0 引 言
矿井安全是一直困扰人类的一项大问题,煤矿突水是我国华北型煤田的主要危险之一。及时准确地预测矿井突水水源对矿井生产具有重要意义,预测矿井突水的许多因素在很大程度上都具有不确定性[1]。在样品主要成分显而易见的情况下,贝叶斯定律适用于具有几个因素的样品的模糊综合评价。雷西玲使用BP算法和神经网络预测了山区的水源[6],BP神经网络使用逆变误差法来确定人类大脑中模拟信息处理过程的能力的值,可以识别大量用于突水水源的非线性关系的各种数据。但是,由于算法的缓慢收敛,以及初始值和设置对结果的影响更大,使得该方法的准确度易受影响。主成分分析(PCA)在一定程度上采用了降维思想,抵消了水样品之间复杂信息的影响,将大量指标转化为小而全面的指标的同时继续反映了原来的变量信息。
ELM算法是由阎志刚等人在2006年开发的一种算法,该算法不需要在学习过程中调整网络的输入值,也不需要调整隐藏层的位移、综合性能等特征,可以有效地消除数据之间的关联,减少计算的复杂性。当网络引入变量时,通常包含相互关联信息的煤矿影响因素,重建样本训练可减少神经网络结构复杂性并提高收敛速度。使用PCA和ELM的组合方法来预测煤矿的突水水源,收集分析矿井的各充水含水层水化学历史数据,并根据PCA-ELM构建水源识别模型,为煤矿突水预测提供了新的思路和方法。
本文使用PCA分析矿井水样品中的水化学数据,以确定不同含水层中水样的主要控制因素,以便更准确地确定各充水含水层特征。在此基础上,利用ELM模拟水样本中的基本控制因素,提高ELM算法的运算速度和精确度,并为其他类似矿区相似矿井提供技术支持。
1 矿井常见突水水源的水化学基本特性
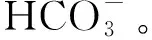
2 矿井突水水源判别数学模型的建立
我国煤矿由于矿井突水遭受了大量财产损失和人员损失,因此预防和应对水灾的科学技术措施对快速正确定义矿井突水水源是非常关键的。由于各充水含水层的不同地质特征,不同来源的矿井突水水源的水化学特征差异明显[8]。常用的模糊评价方法如灰色关联理论、支持向量机、BP神经网络分析理论、贝尔斯、费舍尔等大都没有考虑影响指数之间的信息存储,导致判别结果的误差。为了消除这一影响,本文采用了一种主要的方法来分析矿井中有争议的水源模型中的因素指标。
2.1 主成分分析法
主成分分析(Principal Component Analysis, PCA)是一种多元统计数学方法,将高阶问题转化为低量度问题,简化计算的过程,尽可能避免试验的误差结果,避免无用重复的计算。通过主成分分析的方法,其主元件之间的分析变量不仅小,而且十分有利于分析,使之创建的指标之间进行相互关联,有关变量参数的信息占原始数据样本的大部分。
当抽样容量非常大时,综合评估就更加困难,因为在使用初级组件时,处理结果的最佳方式是用较低的初级组件而不是较低的初级信息,即损失最少的信息。为了解决这个矛盾,必须研究确定关键成分数量的指导原则。
最大数据突变的原则是主组件必须采取最大的数据偏转方向,以便主组件能够尽可能多地表达源信息。
最小乘法原理分析的主要成分是在新空间中引入原始数据。从几何角度看,信息分析在核心成分中所造成的最小损害必须在正方形中实现,并在新超平面中达到原样品投影的最小距离。
群体相似性改变了一个基本原则,在这个原则中,为了分析信息造成的最小损失,需要对数据之间的相似之处进行最小的改变。对角线抽样系统的最佳综合表达原理是使主组件尽可能接近初始变量,而不损失源。
2.2 理论与算法
2.2.1 PCA法
PCA将原始指标组合成一组新的相互关联的综合指标,同时提取了尽可能多的反映原有指标的信件,反映了尽可能多的初始指标。假设在评估一个物体时,源信息是集中的,且有选择性的,每个样本都有一个变量P,这使它成为一个n×p阶的样本数据矩阵,记为式(1)。
Xi=[xi1,xi2,…,xip]T
(1)
贡献率是指出,从任何核心组件中提取的信息占总数的很大一部分,投资水平越高,相关主组件反映总信息的可能性就越大。基本成分k的贡献率如式(2)。
(2)
在通常的情况下,分析前m个主成分的贡献率,详见式(3)。
(3)
如果前面的数据大于85%,用前m个主成分的组合如式(4)。
P=Y1,Y2,…,Ym
(4)
因此,与其改变原始数据X,不如减少数据量,以便将原始变量转化为不相关的变量,而失去尽可能少的源信息方向。
2.2.2 ELM
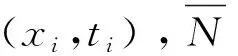
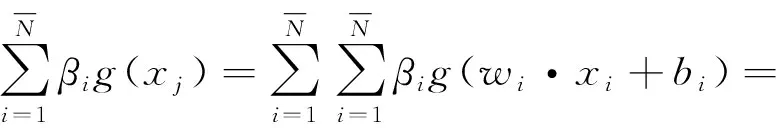
(5)
相比于其他分类模型,ELM具有良好的分类效果,但在面对高维数据时建模时间较长。用主成分分析法对高维数据集进行特征提取,再将提取后的数据集输入ELM模型进行建模和调参,将有效地提高ELM收敛速度和建模效率。
2.3 基于PCA-ELM的煤矿突水预测
利用PCA-ELM的分析方法预测煤矿突水的流程如图1所示。
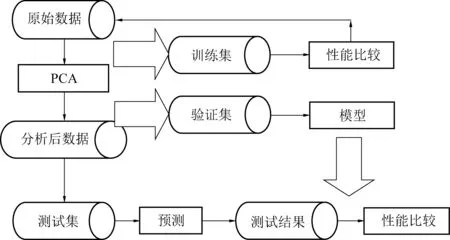
图1 基于PCA-ELM的煤矿突水预测流程Fig.1 Prediction process of coal mine water inrushbased on PCA-ELM
首先利用PCA法分析了影响煤矿突水的许多影响因素,得到了控制因素,决定了各充水含水层的水化学特征,然后将只包含基本管理要素的抽样数据分解为训练、验证和测试。最后,通过与ELM算法相匹配,评价PCA-ELM用来预测突水的优势。
2.4 煤矿突水预测建模
基于PCA-ELM的煤矿突水预测模型构建步骤如下:
(1)利用PCA的方法,对煤矿突水主控影响因素进行筛选,并检查正常使用煤炭的采样基质,并在x矩阵中标准化处理,根据共变矩阵R确定主组件的数量、主组件输入系数和总贡献率;通过计算主成分贡献率及累积贡献率,基于凯塞标准选择累积贡献率最高的3个主成分。为了使3个主成分的差异性最大化,采用最大方差旋转法对主成分轴进行了适当旋转,使每个主成分具有最高荷载的变量数最少,从而简化对主成分的解释,更好地揭示水化学指标所表达的信息。通过基本组件的数量构建ELM模型的教学样本。
(2)建立ELM网络模型。在处理了经过分析的各充水含水层水化学历史数据后,收集了数据样本,以便重新设计和创建ELM网络模型。首先,需要一个样品来练习,详见式(6)。
{xi,ti},i=1,2,…,N
(6)
初始隐藏层节点数设为i。
(3)利用统计数据验证煤矿突水预测模型,如果获得预测结果与其他算法运算结果相比具有明显的优势,可以开始重建模型和算法基本成分,结果将更为可取。
3 实验评估
3.1 样本数据选择
本文选择了研究中国典型华北型煤田的矿井水数据,根据这些数据运用PCA-ELM和ELM预测矿井突水状况。压力影响作为煤矿突水输入参数。参数定义原则:不能量化的数据在两位数模型中量化,定量的数据定量表示,如果没有构建,则断层为1或0。由于气象因素和水化学测试数据类型不同,在构建预测模型之前,必须将影响天气的因素综合起来,并将所有实验数据系统地输入进去。
3.2 参数选择
在建模过程中,当隐藏节点的数量不同时,模型的性能就会大不相同,图2提供了具体的分析结果。
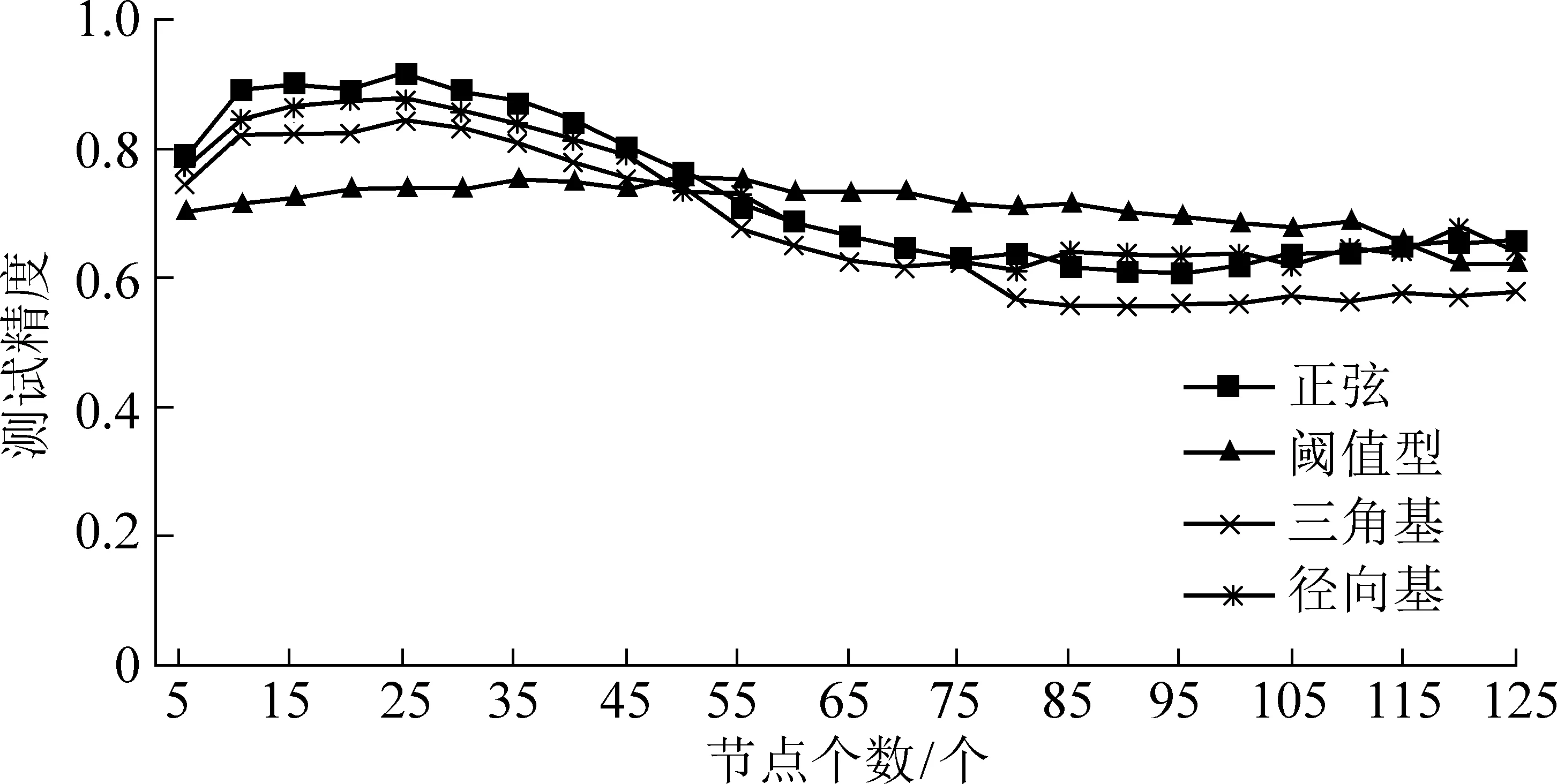
图2 激励函数对应的测试精度Fig.2 Test precision corresponding to the excitation function
由图2可知,在正弦、阈值型、三角基、径向基4个激励函数中,当激励函数为正弦且节点个数为25时,测试精度最高,往后随着节点个数增加,测试精度逐渐降低。因此,对比选择正弦函数为算法相对应的激励函数,隐藏节点个数为25。
3.3 对比试验
PCA方法用于减少原始数据,PCA-ELM测试和ELM的测试进度比较结果如图3所示。
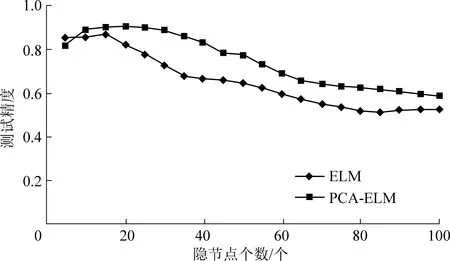
图3 ELM与PCA-ELM的测试精度比较Fig.3 Comparison of test accuracies betweenELM and PCA-ELM
据图3所知,ELM预测的准确性总是比PCA-ELM低。分析非主要成分的测试集中冗余影响因素数据众多,而只有主控因素的碳元素被控制。选择的最佳参数分别用于ELM和PCA-ELM的准备和测试,测试结果见表1。

表1 ELM与PCA-ELM实验结果比较
表1显示,PCA-ELM分析方法不同于ELM方法,其输入数据分析的主要成分,减少相应的试验变量,降低多余部分数据产生的误差,提高模型预测精度,并加快模型计算速度,比较算法和计算模型,PCA-ELM方法预测煤矿的突水水源精度更高。
3.4 结果分析
为了解决水样本中的多样和水样本中更小信息的影响,分析了表2的主要成分,表2显示了系数矩阵,其中不同的成分解释了表2中的偏差。根据表2可知,前3个组件累积解释91.936%,故认为在各离子中,前3个阳离子作为水样主要组件来模拟训练样本。
3.5 MATLAB仿真训练
3种主成分离子的含量值为输入值,3种水的类型为输出值,即网络设置的输出节点数为3。为了使判别结果尽可能接近所有的学习样本,研究样本的数量等于学习样本的数量,即24;网络的输出状态为3,相当于剩下的3个层。在本文的ELM模型中,分析S型函数(Sigmoid),其为隐含层神经元的传递函数,而修正的双方都使用ELM算法来指导样品,确定ELM 1的类型,即分类识别。在ELM模型中,使用MATLAB软件模拟测试样品,该样本应在10 s内分类,最后,其分析结果见表3。
对水样进行分类的结果显示,检测结果100%相同,表明PCA-ELM混合的矿井突水水源方法分类识别性能好,具有一定价值。

表2 各成分解释方差率

表3 ELM识别结果
3.6 结果对比
与此同时,使用模拟BP神经元网络将输入层设置为3,对应于Na+、Ca2+、Mg2+,因此,设置3号输出神经元的网络结构为“3-7-3”型,logsig训练算法用于传输,trainlm传输功能,结果如表4所示。由表3和表4可知,ELM网络更精确,学习结果比BP网络更准确。
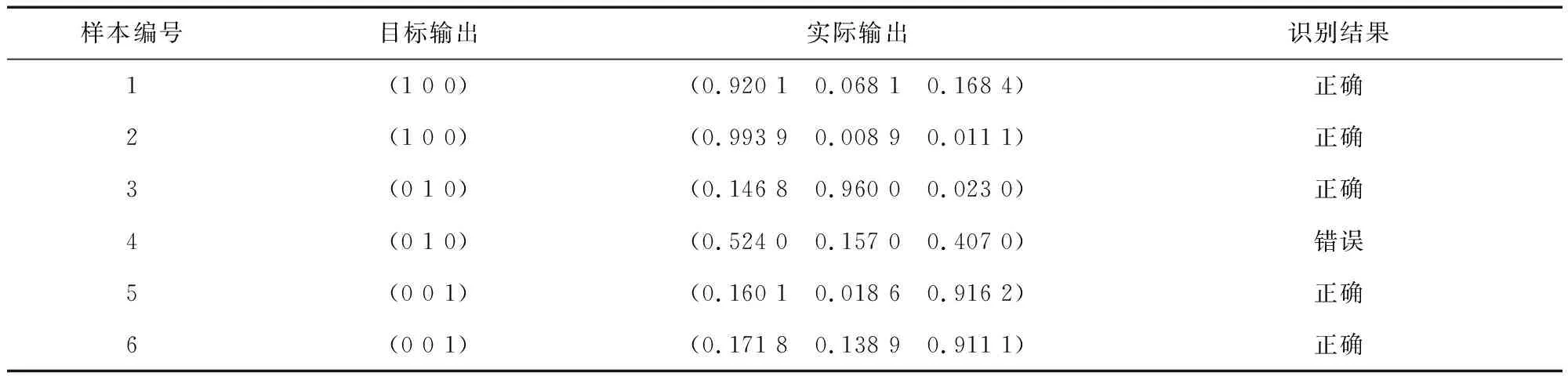
表4 BP网络识别结果
BP神经元网络随机链接权值和阂值,在本研究中对随机抽样样本网络参数输出的权值造成误差甚至引发不稳定模型的情况。
4 结 论
对于各含水层水化学组分差异性不大的矿井突水水源,使用常见的水化学分类法和常规统计方法并不能很好地判别各含水层水化学组分差异性不大的矿井突水水源,其误差较大,通过PCA-ELM模型与其它神经网络模型相比,模型的准确率达到100%,其判别效果优于BP神经网络模型(83.3%),为矿井突水水源的判别提供了一种新方法。
猜你喜欢
品牌研究(2022年18期)2022-06-29
内江科技(2021年6期)2021-12-28
煤矿安全(2021年11期)2021-11-23
黑龙江水利科技(2020年8期)2021-01-21
当代陕西(2019年24期)2020-01-18
小天使·六年级语数英综合(2016年7期)2016-05-14
河北地质(2016年1期)2016-03-20
铁道科学与工程学报(2015年5期)2015-12-24
中国煤层气(2015年5期)2015-08-22
当代畜禽养殖业(2014年2期)2014-08-22
