
面向概念漂移且不平衡数据流的G-mean加权分类方法
2022-12-16 02:42:44李光辉代成龙
计算机研究与发展 2022年12期
梁 斌 李光辉 代成龙
(江南大学人工智能与计算机学院 江苏无锡 214122)(1634113866@qq.com)
信息的爆炸性增长导致数据流广泛出现在各个应用领域中,如无线传感器数据流、银行交易数据流等[1-3].数据流中的潜在分布或目标概念随着时间推移发生变化,这种现象被称为“概念漂移”[4-5].概念漂移会导致在过去数据上训练的分类模型性能显著下降,无法适应当前的新概念,这给传统的数据挖掘算法带来新的挑战.另一方面,当数据流中存在类别不平衡现象时,即某一类的实例数量显著多于其他类,数据流分类会变得更加困难,因为少类实例(minority class instance)[6-7]出现频率过低导致分类模型对它们学习不充分,而我们通常更关注少类的分类情况,因为误分类一个少类实例的代价通常远大于误分类一个多类实例(majority class instance)的代价,例如在癌症诊断中,将患癌人群诊断为健康会带来严重后果.
目前可以同时处理概念漂移和类别不平衡问题的数据流分类方法大多是基于集成学习的思想,主要包括在线集成和基于数据块的集成方法[8].在线集成方法以Wang等人[9]提出的OOB(oversampling online bagging)和UOB(undersampling online bagging)为代表,它们将过采样和欠采样技术与Online Bagging[10]相结合,动态调整采样频率,有效解决了数据流中类别不平衡问题.在线集成方法通常还与针对不平衡数据流设计的漂移检测方法结合,例如Wang等人[11]提出的DDM-OCI(drift detection method for online class imbalance learning)结合Online Bagging,通过监测少类召回率的变化在不平衡数据流中检测漂移.但DDM-OCI假设数据流服从高斯分布,因而在实际应用中存在较高的误报率.为此,Wang等人[12]又提出了LFR(linear four rates)使用统计学检验分析中的TPR(true positive rate),TNR(true negative rate),PPV(positive predicted value),NPV(negative predicted value)4个指标的变化显著性来检测漂移,有效降低了DDM-OCI的误报率.而Wang等人[13]提出的HLFR(hierarchical linear four rate)使用分层假设检测框架,在第1层使用LFR检测漂移,第2层使用排列检验(permutation test)验证漂移的真实性,进一步降低了LFR检测漂移的误报率.在所有基于数据块的集成方法中,Gao等人[14]提出的UB(uncorrelated bagging)是第一个解决数据流中类别不平衡的方法.UB使用集成框架,不断累积数据流中的少类实例,然后添加到当前数据块中平衡数据分布.然而这种策略不仅需要大量的内存空间来存储累积的少类实例,而且没有考虑少类实例上可能发生概念漂移的问题,有较大的局限性.为此,Chen等人[15]提出的SERA(selectively recursive approach)改进了UB,它使用马氏距离计算累积的少类实例和当前数据块中少类实例的相似度,只选择相似度较高的少类实例平衡当前数据块的类别分布.进一步,Chen等人[16]又提出了REA(recursive ensemble approach),该方法使用KNN(k-nearest neighbors)计算相似度,替换SERA中的马氏距离度量,解决了少类实例中的子概念问题.而针对重采样过程存在的一些困难因素,例如异常数据,类别重叠等,Ren等人[17]提出了GRE(gradual recursive ensemble),它使用DBSCAN聚类技术将当前少类实例分为若干个簇,然后分别计算各个簇中实例和过去数据块中少类实例的相似度,选择部分少类实例填充至当前数据块,解决了重采样过程中数据异常和类别重叠问题.Wu等人[18]提出的DFGW-IS(dynamic feature group weighting with importance sampling)通过分析当前数据块和过去数据块的海林格距离差异来检测概念漂移,同时结合重要性采样处理类别不平衡问题.基于数据块的集成方法存在一个共性问题:它们都假设少类实例的概念不会发生变化,即过去数据块中的少类实例可以继续使用.然而在实际情况中,类的先验概率随时间也会发生变化,过去数据块中少类实例可能就是当前数据块中的多类实例.另外,重复访问历史数据也不符合数据流挖掘的要求.因此,以Ditzler等人[19]的Lean++CDS和Lean++NIE为代表,一些不需要保存历史数据的集成方法被提出.Lean++CDS是Learn++NSE和SMOTE(synthetic minority class oversampling technique)的简单结合,其中Learn++NSE用于处理概念漂移,而SMOTE产生新的少类实例以平衡当前数据块的类别分布,无需保存任何历史数据.Lean++NIE也不需要访问历史数据,在每个数据块上对多类实例进行欠采样,结合Bagging技术生成一个由多个成员分类器组成的子集成模块,并根据成员分类器在过去和当前数据块上的G-mean性能分配权重,有效平衡每个类别的重要性.此外,Lu等人[20]提出的DWMIL(dynamic weighted majority for imbalance learning)在集成模型中只保留有限数量的成员分类器,每个成员分类器的权重根据在当前数据块上的G-mean性能决定,并随着时间衰减,直至小于某个阈值被移除,兼顾了效率和性能.
基于上述分析,目前已有的方法主要存在2个问题:一是需要大量空间保存过去的少类实例进行重复使用,且没有考虑类先验概率变化的情况;二是集成方法中的成员分类器权重是基于数据块更新的,缺乏在线更新机制,面对突变型漂移或发生在数据块内的漂移时,难以快速应对.为此,针对二分类数据流,本文在基于数据块集成方法上引入了在线更新机制,提出了一种基于G-mean加权的在线不平衡数据流分类方法(online G-mean update ensemble for imbalance learning, OGUEIL),以集成框架为基础,每到达1个新实例,增量更新每个成员分类器及其权重,并对少类实例随机过采样,无须保存历史数据,同时周期性地训练多个具有差异性的候选分类器以提高集成模型的泛化能力.与同类方法相比,本文主要贡献有3个方面:
1) 提出了一种基于G-mean的在线加权策略,可以根据当前数据分布及时调整每个成员分类器的权重,有效解决不平衡数据流中的概念漂移问题.
2) 在集成模型在线更新过程中引入了对少类实例的随机过采样策略,既提高了少类实例的召回率,又增加了集成的多样性.
3) 基于混合采样和自适应滑动窗口技术提出了一种候选分类器训练策略,周期性地对当前窗口上的数据同时使用边界人工少类实例合成技术[21]和随机欠采样技术生成多个具有差异性的候选分类器,并将它们选择性地添加至当前集成模型中,提高泛化能力.
1 相关知识
1.1 数据流概述
在数据流分类领域,数据流由大量按时间顺序到达的实例组成,表示为S={s1,s2,…,st,…},其中st=(Xt,yt)表示时刻t到达的实例,Xt=(d1,d2,…,dn)代表n维向量,意味着数据流S是n维的,yt∈{c1,c2,…,ck}表示实例st真实类别,k为数据流S中所有类别数量.
1.2 概念漂移定义和分类
概念漂移是指数据流中的目标概念随时间发生改变,在数据流分类领域,目标概念一般指当前分类模型学习到的决策边界.具体而言,假设数据流S服从某分布Ft(X,y),P(y|X)表示y关于X的条件概率分布,代表决策边界,若在时刻t+1有Ft(X,y)≠Ft+1(X,y)且Pt(y|X)≠Pt+1(y|X),表明原有的决策边界发生变化,这种现象称为概念漂移[8,22].
概念漂移的分类普遍是基于概念变化的速度[22-23].当新旧概念过渡很快,旧的概念突然被另一个数据分布完全不同的新概念取代,这种漂移属于突变型概念漂移(abrupt concept drift);反之,新旧概念过渡较慢时,旧概念被新概念逐渐替换,且二者在漂移前后或多或少有些相似,则属于渐变型概念漂移(gradual concept drift).
1.3 在线过采样集成算法OOB
针对数据流中的类别不平衡问题,Wang等人在OB(online bagging)[10]基础上提出了在线过采样集成算法OOB(oversampling OB)[9].OB将传统的集成学习算法Bagging从静态数据领域扩展到了数据流领域.Bagging算法首先对所有样本放回随机采样,然后得到多个训练集,最后训练多个不同的成员分类器.因此每个样本会被重复选择k次,且k服从二项分布,如式(1)所示:

(1)

2 基于G-mean加权的在线不平衡数据流分类方法
针对二分类数据流中的概念漂移和类别不平衡问题,本文提出了一种基于G-mean加权的数据流分类方法(OGUEIL).OGUEIL属于在线集成方法,其主要思想是通过使用在线决策树Hoeffding tree[24]和基于G-mean的在线加权机制,在基于数据块的集成方法中引入在线更新机制,避免数据块大小难以选择的问题,可以有效处理各种类型的概念漂移,包括突变型、渐变型以及发生在数据块内部的漂移,提高分类性能.在线更新过程中,OGUEIL结合OOB[9]对少类实例进行随机过采样,既提高了少类实例的召回率,又增加了集成的多样性,且不需要保存任何历史数据.此外,OGUEIL会周期性地添加和淘汰集成中的成员分类器以维持集成模型的分类效率和性能.OGUEIL包含更新、淘汰、候选分类器训练、加权和决策5个过程,下面分别详细介绍各过程的算法思路与伪代码.
2.1 在线更新和淘汰机制
在OGUEIL中,每获得一个新实例(xt,yt),所有成员分类器更新一次.为解决数据流中类别不平衡导致少类召回率过低的问题,OGUEIL结合OOB[9]算法对少类实例随机过采样,即对每个少类实例学习k次,且k服从参数为ξ的泊松分布,ξ为当前数据流中多类实例与少类实例的数量比,OOB伪代码如算法1所示.由于数据流的不稳定性,类的先验分布可能发生变化,甚至少类和多类发生角色互换,因此OGUEIL需要实时监测数据流中多类实例和少类实例的分布情况.
算法1.OOB[9].
输入:时刻t到达的实例(xt,yt),当前集成模型Ω,当前多类实例数量|Ymaj|,当前少类实例数量|Ymin|;
输出:更新后的集成模型Ω.
① while到达一个新实例
② 对于当前集成模型Ω中的每一个分类器Ci:
③ 计算当前数据流的不平衡率ξ←|Ymaj|/|Ymin|;
④ if当前实例属于少类
⑤ 根据式(3)设置k~Poisson(ξ);
⑥ else
⑦ 设置k~Poisson(1);
⑧ end if
⑨ 更新k次分类器Ci;
⑩ end while
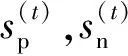
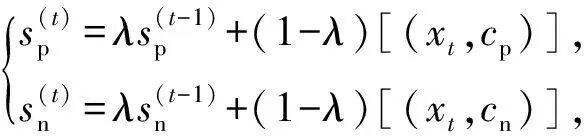
(2)
如果xt的真实类别是正类cp,那么[(xt,cp)]=1,否则[(xt,cp)]=0,对于负类cn也是同理,而λ为预设的时间衰减因子.区别于传统累加每个类别实例的方式,这种方式使用时间衰减因子进行指数平滑,强调当前数据的影响同时弱化旧数据的影响,更适合用在数据流中.然后根据式(3)确定少类和多类,其中δ为预设的阈值.若满足式(3),正类cp被标记为多类,负类cn为少类,反之亦然.

(3)
在本文中,参数δ是通过大量实验获得的经验值,δ过大或过小均会影响到算法性能.在第3节实验中,本文将详细介绍各个参数的设置.为保证集成分类的效率和准确率,OGUEIL使用淘汰机制优化集成结构:每当创建一个新候选分类器时,若集成模型的成员数量没有达到预设的最大值m,直接添加成员,否则替换权重最小的成员,这样保证了集成模型的成员不会随时间无限增加,降低内存消耗.
2.2 候选分类器训练
如何训练泛化能力强的候选分类器是克服多类别不平衡、提高少类分类准确率的关键.普遍的解决方案是对多类实例欠采样或对少类实例过采样,这2种方法都有各自的优点和缺陷.本文结合过采样和欠采样,提出了一种基于混合采样的候选分类器训练方法(candidate classifier training, CCT),如算法2所示.OGUEIL每隔固定周期检测当前窗口中各类实例的数量是否均超过预设值β,若满足则开始训练T(T>1)个新候选分类器.首先确定当前窗口中所有类实例数量的最大值(max)和最小值(min),然后在min和max之间随机取值N作为之后每类实例的重采样数量.对于实例数量少于N的类,OGUEIL使用边界人工合成少类样本方法(BorderlineSMOTE)[21]将其数量过采样至N,值得注意的是,它属于过采样方法的一种,通过在决策边界附近人工合成少类样本来平衡数据分布,既增强了决策边界,又降低了过拟合的风险;而对于实例数量大于N的类,通过随机欠采样(RUS)将其数量削减,最终使用类分布相对平衡的数据集训练候选分类器.由于OGUEIL每次生成不止一个候选分类器,且每次的采样数量都是随机选取,因此可以最大限度减少有价值的信息的丢失.同时,由于训练每个候选分类器的数据集都不同,OGUEIL会得到一组具有足够多样性的候选分类器,可以增强整体集成分类器的泛化能力.生成T个候选分类器后,此时如果当前集成规模|Ω|与T之和小于预设的集成最大成员数m,直接添加成员分类器,否则移除集成中权重最小的成员分类器,直至满足|Ω|+T 算法2.CCT. 输入:当前窗口W中的数据D; 输出:新的候选分类器. ① 确定D中所有类实例数量的最大值max和最小值min; ② 在[min,max]内随机取值N作为之后每个类实例的重采样数量; ③ 对实例数量少于N的类使用Borderline-SMOTE过采样至N; ④ 对实例数量大于N的类使用RUS欠采样至N; ⑤ 使用处理后的数据集D训练一个新的候选分类器. 数据流集成分类方法的加权机制大都是基于数据块的,即每到达一个数据块,集成中每个成员分类器的权重由在当前数据块上的分类精度决定.当面对突变型漂移或发生在数据块内的漂移时,基于数据块的加权机制难以快速调整成员分类器的权重.此外,基于分类精度的加权机制容易受到类分布的影响,导致成员分类器偏向多类,忽略少类.为此本文提出了一种基于G-mean的在线加权机制,它的特点是每到达一个新实例而不是一个完整的数据块,所有成员分类器的权重更新一次且不受类分布的影响.更新成员分类器时既考虑该分类器创建的时间,又考虑它在最近d个数据上的G-mean性能.二分类数据流中,G-mean就是正类cp上的准确率PR和负类cn上的准确率NR的几何平均值,如式(4)所示: (4) (5) (6) (7) 在时刻t,每个成员分类器的权重通过式(8)~(11)更新: (8) (9) (11) (12) 其中,sgn(·)为符号函数,若括号中结果大于0,返回1,代表正类cp;否则返回-1,代表负类cn.OGUEIL的伪代码如算法3所示: 算法3.OGUEIL. 输入:数据流S、检测周期d、集成模型容量m、成员分类器Ci、少类实例数量最小值β、滑动窗口W、候选分类器个数T; 输出:加权集成模型Ω. ① while每到达一个新实例(xt,yt) ③ 根据式(2)增量计算每个类的实例大小; ④ 根据式(3)确定当前数据流中的少类和多类; ⑤ 把新实例(xt,yt)添加到窗口W中; ⑥ 根据式(8)~(11),使用(xt,yt)更新集成中每个成员分类器Ci的权重; ⑦ 每隔d个实例: ⑧ if窗口W中的少类实例数量大于β: ⑨ 调用CCT算法T次,训练T个新的候选分类器; ⑩ end if OGUEIL集成模型使用Hoeffding tree做基分类器,Hoeffding tree学习每个实例的时间复杂度为O(1),故含有m个Hoeffding tree的集成模型学习时间复杂度为O(m).OOB使每个Hoeffding tree训练k次,k服从泊松分布,OGUEIL的时间复杂度变为O(km).每个类的数量计算均通过增量计算,所以时间复杂度为O(1).CCT算法创建T个候选分类器的时间复杂度为O(2TN),N代表采样数量,而每个基分类器通过式(8)~(11)加权需要O(1)时间,对m个基分类器加权的时间复杂度为O(m).综上,OGUEIL的时间复杂度为O(km+2TN+m),由于k,m,N,T均与输入数据流的规模无关,故OGUEIL关于数据流规模的时间复杂度可解析为O(1). 关于方法的空间复杂度,由于OGUEIL使用滑动窗口处理数据,创建分类器时需存储N个样本数据.因此方法的空间复杂度为O(TN),这里T为候选分类器个数.显然,滑动窗口大小、采样数量和分类器个数均与输入数据流的规模无关,故关于输入数据流规模的空间复杂度仍可视为O(1). 为验证OGUEIL方法的性能,本节将OGUEIL和其他5种同类方法在人工和真实数据集上进行实验比较.对比方法可分为2类:一类是基于数据块的集成方法:DWMIL[20],Learn++NIE[19](后面简称为LPN)和REA[16];另一类是在线集成方法:OAUE[26],OOB[9].实验环境:1台处理器为Intel Core i7-7700HQ,内存为16 GB的笔记本电脑,运行Windows 10系统和python3.7.在该环境下,分别实现了本文方法和对比方法,对比方法的参数设置均各参照对应文献.OGUEIL的参数设置为:成员分类器使用python的scikit-multiflow包[27]的Hoeffding tree使用默认设置;时间衰减因子λ和类别不平衡检测阈值δ设置参照文献[9],分别设为0.9和0;p根据大量实验确定,设为500;集成最大成员数量m=15;创建候选分类器所需的最小少类实例数量β=15;ε=0.000 000 1. 本文利用以下指标对方法进行评价,包括二分类数据流中的分类准确率ACC(accuracy)、几何均值Gmean(geometry mean)、少类召回率MCR(minority class recall),其具体定义如式(13)(14)所示. (14) Table 1 Confusion Matrix表1 混淆矩阵 实验共用到6个人工数据集和2个真实数据集,详情如下: Sine数据集[4].该数据集生成器有2个属性x和y.分类函数是y=sin(x),在第1次漂移之前,函数曲线下方的实例被标记为正类,曲线上方的实例被标记为负类,共有2个类别.在漂移点,通过反转分类规则来产生漂移.Sine共包含100 000个实例,每隔20 000个实例产生1次漂移,类分布平衡,含10%噪声. Sea数据集[28].该数据集生成器有3个属性,其中第3个属性与类别无关,如果x1+x2<α,实例分类为正,否则为负,x1,x2表示前2个属性.通过欠采样生成2个新的数据集:1)Seaac通过欠采样产生类别不平衡,不平衡率(指少类实例所占百分比)初始化为0.05,在数据流中某处会突然上升至0.95,即多类实例变为少类实例;2)Seanc通过欠采样产生类别不平衡,不平衡率固定为0.05. Circle数据集[4].该数据集生成器有2个属性x和y.4个不同圆方程表示4个不同概念.圆内的实例被分类为正,圆外为负,共2个类别.在漂移点通过更换圆的方程来产生漂移.Circle数据集共包含50 000个实例,每隔12 500个实例产生1次漂移,类分布平衡,含10%噪声. Hyper Plane数据集[28].该数据集生成器有10个属性,通过连续旋转决策超平面产生漂移.Hyper Planenc包含50 000个实例,不平衡率固定为0.05. Gaussian数据集[28].该数据集生成器有2个属性,通过改变高斯成分的均值和方差产生漂移.本实验中通过欠采样产生类别不平衡数据集Gaussiangc,不平衡率初始化为0.05,然后逐渐上升至0.95. Electricity数据集[4].该数据集为真实数据集,收集了澳大利亚新南威尔士州电力市场的45 312个电价数据,包含8个属性和2个类别. Weather数据集[20].该数据集为真实数据集,包含贝尔维尤和内布拉斯加州50多年来的天气信息.任务是预测一天是否下雨.本实验中通过欠采样实现类别不平衡[20],不平衡固定为0.05,包含18 159个实例,有8个属性和2个类别. 表2总结了所有数据集的信息.实验用到的8个数据集进一步可分为四大类,模拟4种不同场景:1)概念漂移的类平衡数据集,包括Sine,Circle,Electricity;2)有概念漂移的类别不平衡数据集且包含不平衡率突然变化的情况,包括Seaac;3)有概念漂移的类别不平衡数据集且包含不平衡率逐渐变化的情况,包括Gaussiangc;4)有概念漂移的类别不平衡数据集且不平衡率固定不变,包括Seanc,Hyper Planenc. Table 2 Description of Datasets表2 数据集的描述 本节用OGUEIL的参数p(基分类器更新周期)的不同值对算法G-mean性能进行了实验,结果如表3所示. 由表3中数据可知,参数p的不同取值对OGUEIL的G-mean性能影响较小,同时p=500时在8个数据集上的平均排名最高,所以最终OGUEIL的参数p设置为500. Table 3 G-Mean Results of OGUEIL Under Different p Values表3 不同p值下的OGUEIL的G-mean结果 本节比较了OGUEIL和其他5种方法在上述8个数据集上的分类准确率,G-mean和少类召回率,结果如表4~6所示.表4给出了所有方法的8个数据集上的准确率结果.根据表4可以看出:其一,Sine,Circle,Electricity 3个数据集的类分布相对平衡,准确率可以较好地反映每种方法的性能,OGUEIL在这3个数据集上准确率均排在第1,表明OGUEIL可以很好地处理各种类型概念漂移,紧接着是OAUE和DWMIL,二者结果相近;其二,在其余类分布不平衡数据集上,OAUE均排名第1,但这不能表明OAUE处理类别不平衡数据流中概念漂移的能力强于其他方法,因为数据流的类分布严重不平衡时,准确率会偏向于多类,意味着一个方法只有把所有实例预测为多类就可以获得很高的准确率,严重忽略少类实例,不能合理地反映方法性能.表5给出了各方法G-mean的实验结果,G-mean对类分布不敏感,在平衡或不平衡数据流中都可很好地反映一个方法的性能.结果显示:OGUEIL在7个数据集上平均排名最高,DWMIL次之,而OAUE的G-mean性能很差,在Weather上甚至为0,但它的准确率很高,这表明它的多类性能很好而少类性能很差,主要因为它没有处理类别不平衡的机制,容易将少类实例误分类为多类实例.REA是针对不平衡数据流的方法,但它的G-mean性能很差,甚至弱于OAUE,主要因为它保存过去所有数据块中的少类实例,然后通过KNN(k-nearest neighbors)选择部分少类实例平衡当前数据块的类分布,这种机制很容易受到概念漂移的影响,当少类上的概念发生漂移时,少类实例会和多类实例大量重叠,严重影响方法G-mean性能.少类召回率的结果如表6所示,OGUEIL和DWMIL的平均排名并列第1,特别地,在Sine,Circle,Electricity这3个类分布相对平衡的数据集上,OGUEIL的少类召回率高于DWMIL,而在剩下的类分布不平衡数据集上OGUEIL的少类召回率低于DWMIL.结合表4,5,OGUEIL在准确率和G-mean上的表现均优于DWMIL,表明OGUEIL在维持少类性能的同时没有过多牺牲多类的性能,在2个类上的性能达到了最佳平衡. Table 4 Accuracy Results of All Datasets表4 所有数据集上的准确率结果 Table 5 G-Mean Results of All Datasets表5 所有数据集上G-mean结果 Table 6 Minority Class Recall Results of All Datasets表6 所有数据集上少类召回率结果 Fig. 1 Experimental results on the Sine dataset图1 Sine数据集上的实验结果 Fig. 2 Experimental results on the Hyper Planenc dataset图2 Hyper Planenc数据集上的实验结果 图1为Sine数据集上的结果,该数据集为类分布平衡数据集,可以发现各方法在准确率、G-mean和少类召回率上的性能变化曲线基本一致,以图1(a)的准确率结果为例,可以得到以下观测结果:1)OGUEIL的准确率最高,OAUE和DWMIL次之,REA的准确率最低,表明OGUEIL,OAUE和DWMIL的抵抗概念漂移能力较强.2)Sine数据集每隔全部数据的20%,通过反转分类规则产生一次突变型概念漂移,OGUEIL,OAUE,DWMIL受影响较小,准确率轻微下降后迅速恢复,其中OGUEIL得益于它的在线更新和在线加权机制,发生漂移后迅速更新所有成员分类器及其权重值,最先完成新概念的学习,准确率曲线率先上升.3)LPN,OOB,REA受概念漂移影响严重,尤其是REA,准确率甚至下降至0.5左右,这主要因为REA所有成员分类器无法增量更新,集成模型缺少成员分类器的淘汰机制,遭遇概念漂移时,在旧概念上训练的大量成员分类器既不能增量更新,也不被淘汰,从而严重影响性能.LPN和REA类似,所有成员分类器也无法增量更新,集成模型也没有淘汰机制,但它有独特的加权机制,LPN中每个成员分类根据分类性能调整权重时,会使用sigmoid函数对它在当前数据块上的性能和过去所有数据块上的性能加权,可以快速地消除旧概念对当前集成模型的影响,同时若发现某个成员分类器的性能弱于随机分类器,该成员分类器的权重置则被设置为0,消除它对最终决策的负面影响,故它处理概念漂移的能力强于REA.OOB没有加权机制和成员分类器淘汰机制,但它的成员分类器是在线分类器,遭遇概念漂移时通过在线更新缓慢适应新的概念,整体效果略好于REA. 图2为Hyper Planenc上的结果,该数据集是类分布不平衡的且不平衡率固定为5%,包含渐变型概念漂移.OAUE的准确率始终保持较高水平,但这以严重牺牲少类上的性能为前提,它的少类召回率远低于其他方法.OGUEIL在3个评价指标上的性能曲线都没有较大波动,始终保持着较高的水平,表现出较强的抗概念漂移能力.并且它在准确率和少类召回率上排名第2,在G-mean上排名第1,这表明OGUEIL很好地平衡了在每个类上的性能.DWMIL在少类召回率上性能很好,排名第1,但它准确率排在第5,这表明DWMIL以大幅牺牲多类上的性能为代价提高它在少类上的性能,处理类分布不平衡的策略有些激进.LPN的G-mean曲线和DWMIL的G-mean曲线十分接近,但它的少类召回率低于DWMIL少类召回率而准确率高于LPN的准确率,表明LPN处理类分布不平衡的策略较DWMIL保守一些,没有为了提高少类上的性能而过多牺牲多类上的性能.OOB和REA在少类召回率上保持稳定,都高于OAUE的少类召回率,但在准确率和G-mean上低于OAUE的且存在较大的波动,主要因为它们对概念漂移的响应较慢,影响了在多类上的性能. Fig. 3 Experimental results on the Seaac dataset图3 Seaac数据集上的实验结果 Fig. 4 Experimental results on the Gaussiangc dataset图4 Gaussiangc数据集上的实验结果 图3给出了各方法在Seaac上的实验结果,该数据集是包含渐变漂移的类分布不平衡数据集,而且不平衡率会在数据集中发生突变,导致多类实例和少类实例的角色互换,因此在不平衡率变化处重置所有评价指标,如图3中虚线所示(数据流40%的位置,虚线和实线部分重合).OGUEIL在各项性能指标上一直比较稳定,不平衡率突变后,它会根据当前数据流中类分布快速识别出多类实例和少类实例,然后调整集成中的所有成员分类器过采样的目标,性能恢复最快,最终在准确率上排名第2,G-mean上排名第1,少类召回率上排名第4.而LPN,DWMIL,OOB,REA的恢复速度依次递减.至于OAUE,它在准确率上受不平衡率突变影响最小,始终保持较高水平,原因与Hyper Planenc数据集上的相同,但它在G-mean和少类召回率上波动很大,在不平衡率突变前,随着少类实例的增加,各项性能逐渐上升,突变后,由于缺乏处理类分布不平衡机制,一直处在下降状态.值得注意的是,REA的少类召回率在不平衡率突变前很低,突变后,少类召回率大幅上升,甚至最后排名第1,这是因为突变前REA将大量多类实例预测为少类实例,突变后,多类实例变为少类实例,从而获得了较高的少类召回率. 图4为Gaussiangc上的结果,该数据集是包含渐变漂移的类分布不平衡数据集,而且不平衡率会在数据集中逐渐发生变化,数据流的状态由不平衡逐渐变到平衡然后又到不平衡,因此在2次不平衡率变化处重置所有评价指标,如图4中虚线所示.在第1次不平衡率变化后,数据流状态由类分布严重不平衡逐步过渡到平衡状态,除REA外所有方法的性能都保持稳定或上升状态.第2次变化后,数据流又从平衡状态转变至不平衡状态,多类实例变为少类实例,而少类实例变为多类实例,由于类分布的变化,所有方法的性能都有所下跌,然后随数据流增加逐渐上升.OGUEIL的准确率基本保持稳定,最终排名第2,在G-mean和少类召回率上在短暂下降后迅速恢复,最终排名分别为第1和第3,整体上在3个性能指标上没有出现较大波动,始终保持较高水平,表明OGUEIL有效地降低了概念漂移和类分布变化对集成性能的影响.除了少类召回率,REA和LPN在准确率和G-mean上均显著低于没有处理类分布不平衡机制的OAUE的准确率和G-mean,可能的原因是该数据集上的概念漂移严重影响了REA和LPN在多类实例上的准确率. 8个数据集上,所有方法的运行时间如表7所示.平均运行时间最短的是OOB,主要因为OOB的方法结构简单,它没有加权机制,没有成员分类器的添加和淘汰机制,也无需保存任何历史数据,只需维护集成模型在线更新和对少类实例的过采样.OGUEIL在所有数据集上的运行时间都慢于OAUE,二者的加权和集成模型成员的创建、添加和淘汰操作的耗时相近,主要差别在于OGUEIL整合了OOB,集成模型的在线更新比OAUE增加了少类实例的过采样.REA集成模型的成员分类器为静态批处理方法,无法在线更新,减少了时间消耗,但是它的集成模型没有淘汰机制,会保留所有成员分类器,同时它需要从历史数据块中寻找k个最近邻用以平衡当前数据块的类分布,这些机制导致了REA在小规模数据集上的运行效率较高,例如Electricity,Gaussianac等,而大规模的数据集上效率较低,例如Sine,Circle等,因为数据量越大,REA创建的成员分类器越多,搜索k个最近邻的耗时也越高.DWMIL和LPN的运行时间明显高于其他方法,主要因为二者都使用由若干静态批处理分类器组成的集成分类器作为集成模型的成员分类器,不过DWMIL的集成模型有剪枝策略,LPN没有,这就意味着LPN的规模会随数据流无限扩大,导致决策时间消耗越来越大.此外,LPN在权重计算阶段,不仅要考虑每个成员分类器在当前数据块上的性能,还要考虑它在之前每个数据块上的性能,这也会严重增加时间消耗. Table 7 Comparison of Running Time表7 运行时间对比 s 本文针对数据流中存在概念漂移和类别不平衡的问题,提出了一种新的不平衡数据流分类方法OGUEIL,它基于集成学习框架,综合基于数据块的方法和在线方法的优点,可以有效处理不平衡数据流中的概念漂移.OGUEIL是基于完全增量的方法,无需保存任何历史数据,使用在线分类器作为成员分类器,每到达一个实例,对集成模型中的所有成员在线更新的同时根据每个成员在最近若干数据上的G-mean性能加权,性能越好的成员获得权重值也越大.每隔固定周期,OGUEIL检查当前是否满足创建新候选分类器条件,若满足就通过混合采样创建多个具有差异性的候选分类器,然后选择性地添加至集成中,并使用2种淘汰机制控制集成模型的规模,保持决策的高效性和准确性. 本文利用6个人工数据集和2个真实数据集模拟了4种不同场景,对OGUEIL与5种主流的同类方法进行了全面的对比实验.结果表明,OGUEIL在少类数据上保持良好性能的同时没有牺牲在多类数据上的性能,在平衡与不平衡数据流下都可以有效处理概念漂移,综合性能优于其它方法,具有较强的鲁棒性. 作者贡献声明:梁斌提出了算法思路和实验方案,完成实验并撰写论文;李光辉和代成龙提出了指导意见并修改论文.2.3 加权和决策机制


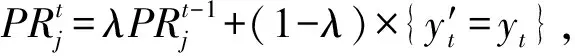

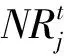


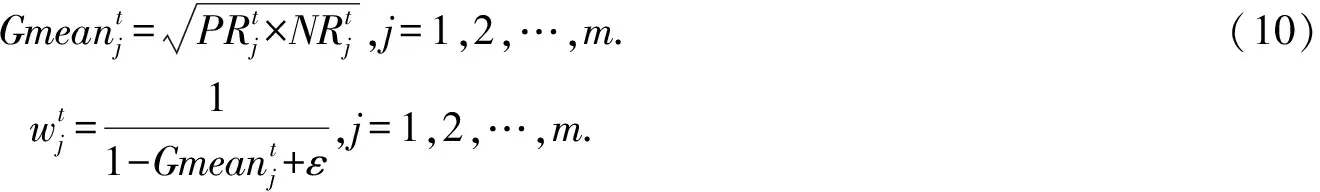
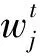
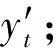
2.4 计算复杂度分析
3 实验结果及其分析
3.1 性能评价指标


3.2 数据集介绍
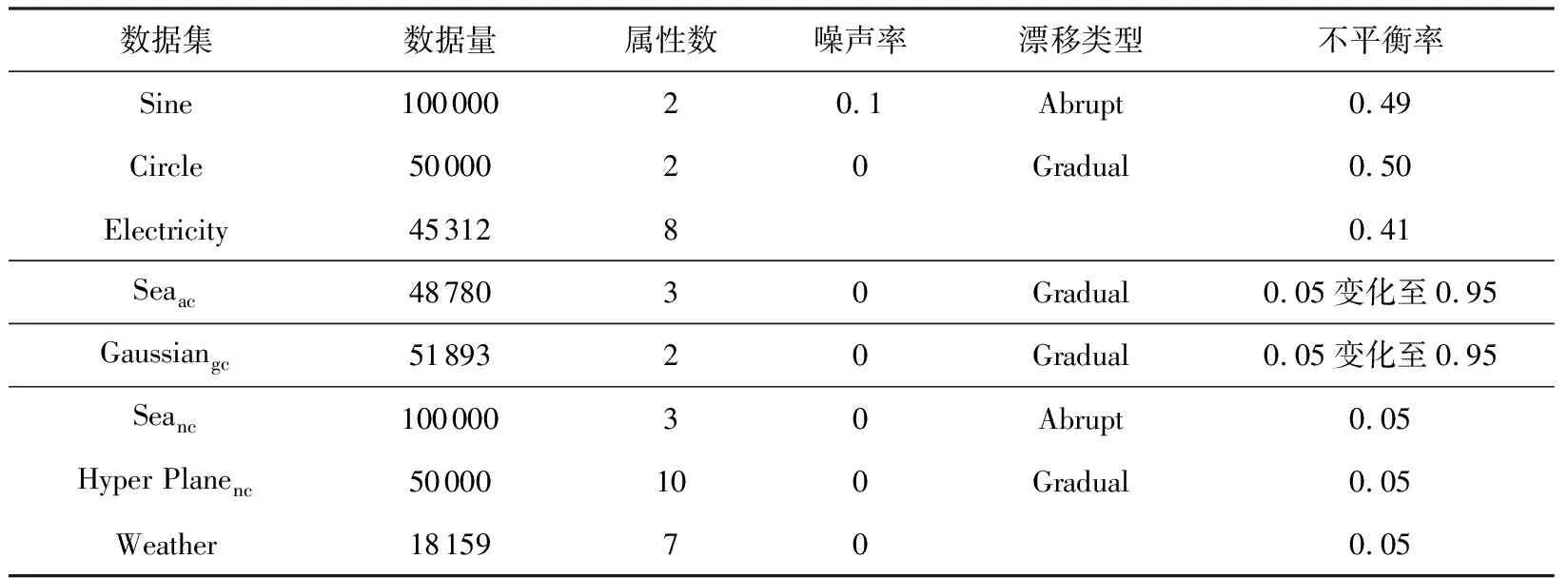
3.3 参数实验

3.4 实验结果分析

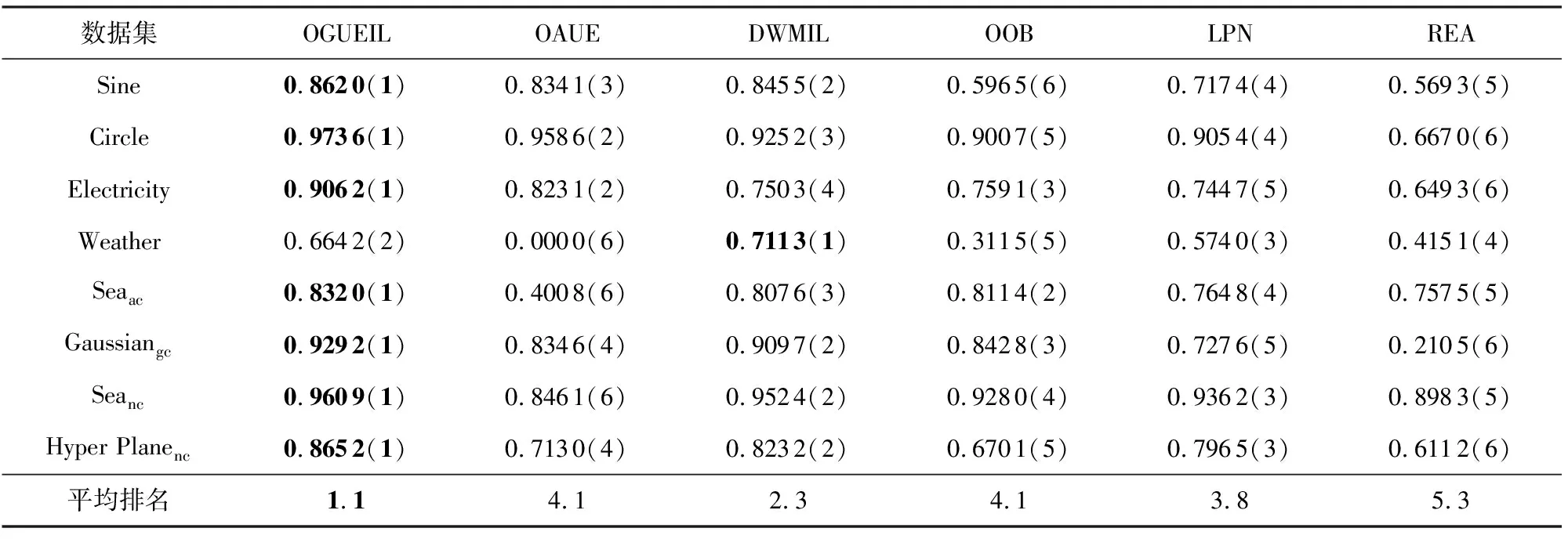

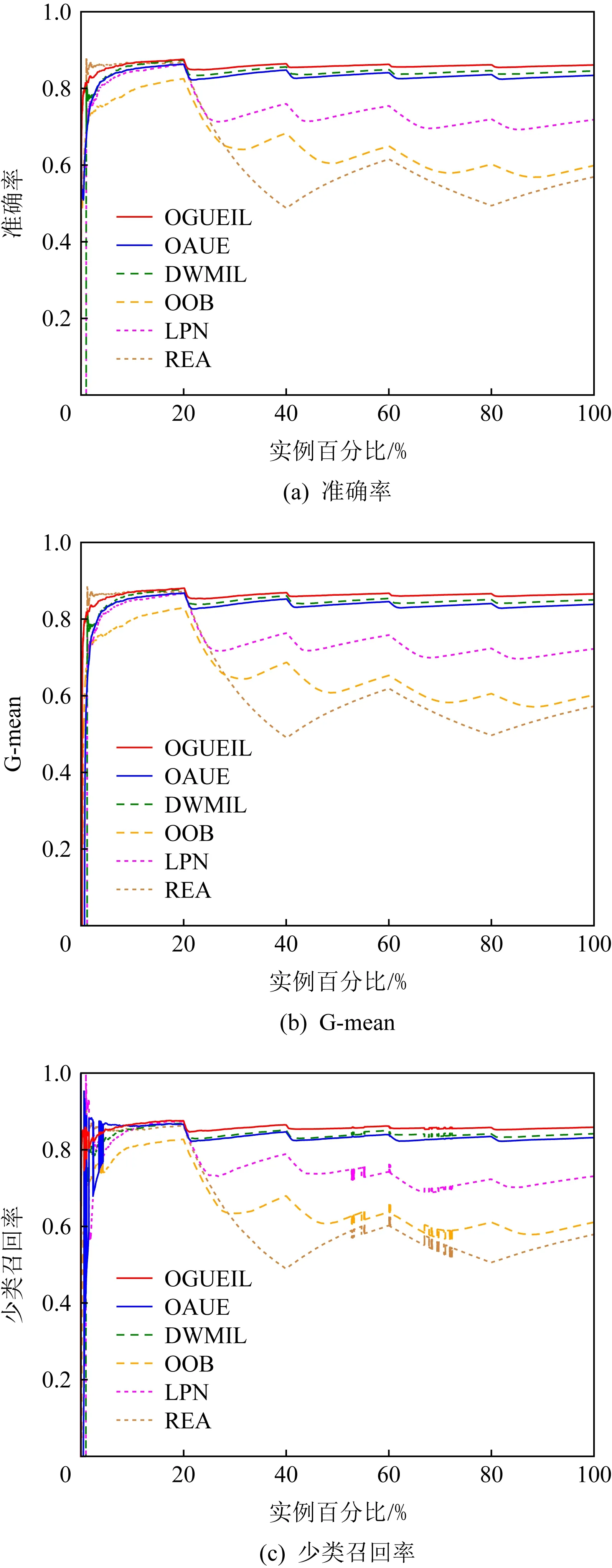

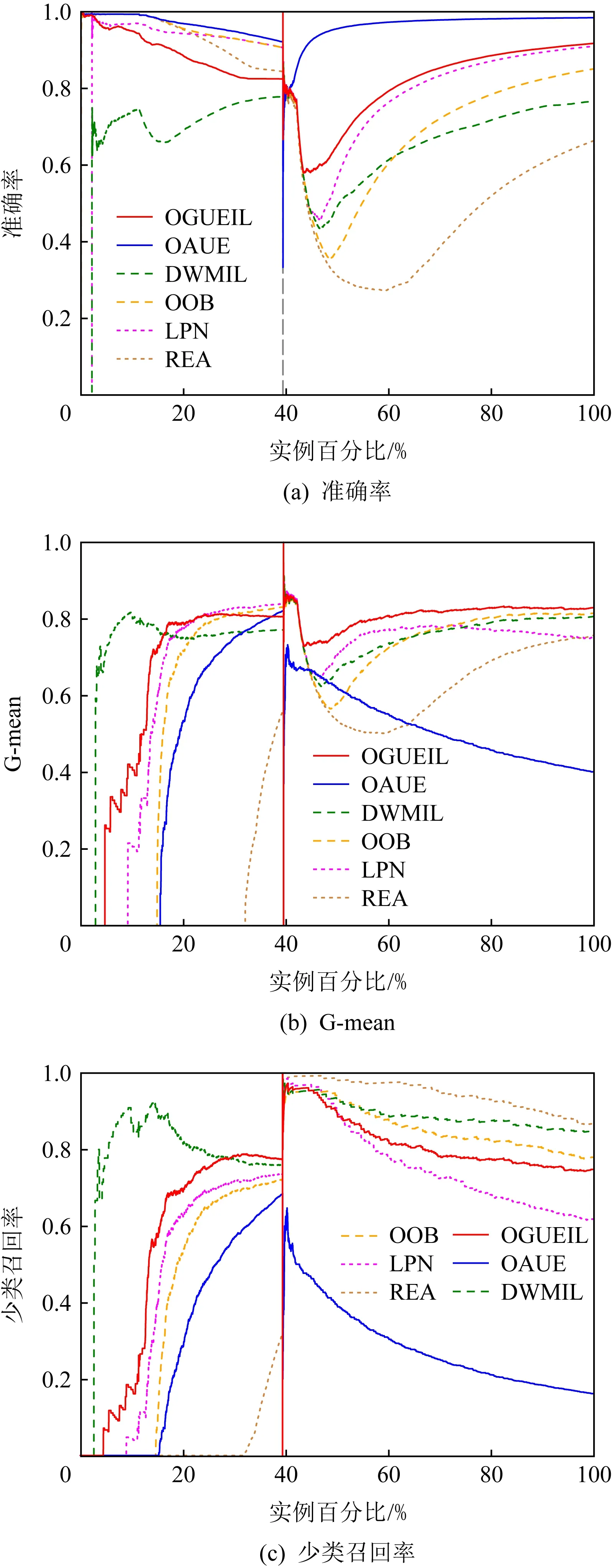

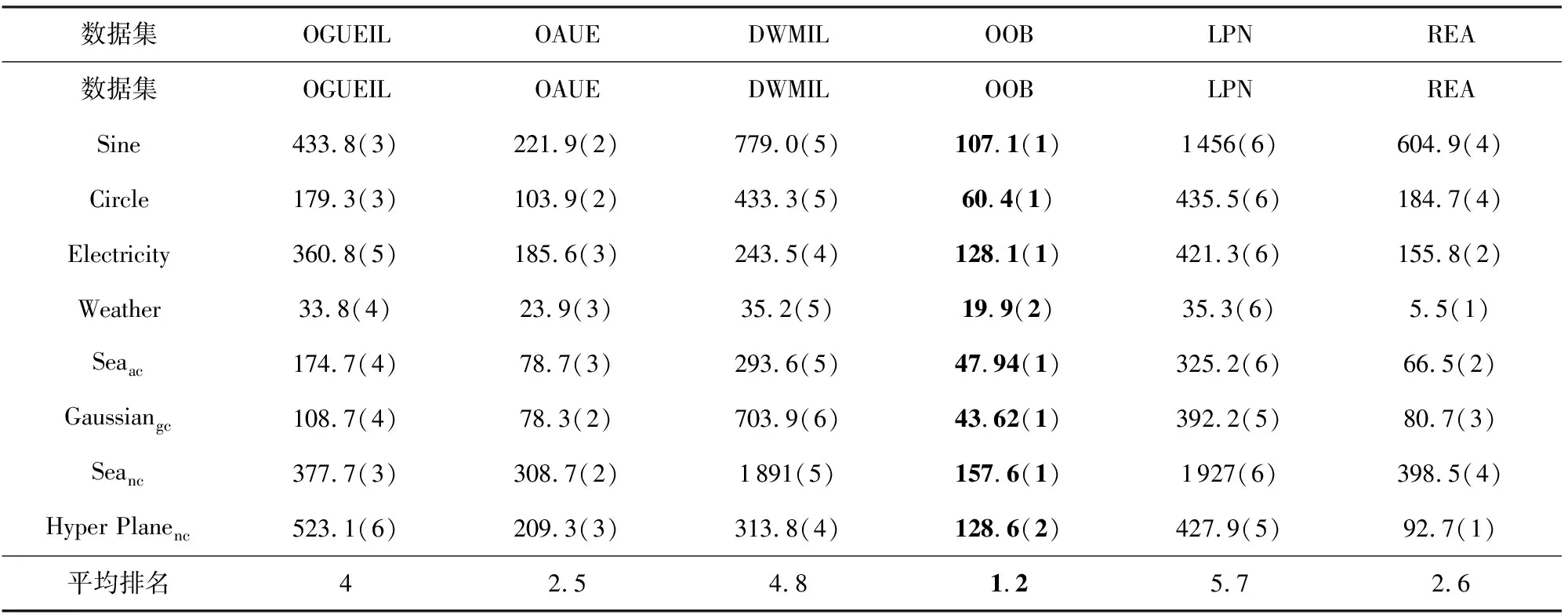
3.5 运行时间比较
4 结束语
猜你喜欢
汽车维修与保养(2020年11期)2020-06-09 05:42:22
电子测试(2018年1期)2018-04-18 11:52:35
电脑与电信(2018年12期)2018-03-23 02:37:36
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
西北工业大学学报(2015年3期)2015-12-14 13:08:48
中国卫生(2014年7期)2014-11-10 02:32:54
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
电测与仪表(2014年15期)2014-04-04 12:05:20
