
基于改进的YOLOv3与EPnP算法的几何体位姿估计①
2022-12-15 09:43许德章
佳木斯大学学报(自然科学版) 2022年6期
郭 雨, 许德章
(1安徽工程大学人工智能学院,安徽 芜湖 241000;2 芜湖安普机器人产业技术研究院有限公司,安徽 芜湖 241007)
0 引 言
位姿估计对于增强现实、虚拟现实、机器人抓取技术等应用至关重要[1]。位姿估计是求解世界坐标系与像素坐标系之间的旋转和平移关系,因此实现位姿估计不仅要检测目标位置,还要得到姿态信息。随着CNN的迅速发展,深度学习在位姿估计中发挥着重要作用。Pose-CNN[2]通过对输入的彩色图片进行分割,预测待检测目标的中心坐标,提取特征图的ROI区域,输出四元数,表征3D旋转矩阵。SSD-6D[3]以单帧RGB图像为输入,基于扩展的SSD,预测目标2D bounding box以及目标种类、离散视点和面内旋转在每个特征图位置的得分,通过射影几何特性构建目标的6D姿态池,最终通过姿态池优化得到精确的位姿结果。BB8[4]使用一个CNN 粗略分割对象,用另一个CNN预测给定分割对象3D边界框投影的2D位置,然后使用 PnP 求解目标位姿。但这些算法都只能对指定的数据集做离线的位姿估计,不能实时检测目标信息,导致精度较低。基于上述问题和机器人动态抓取技术研究,采用自制几何体模型数据集作为研究对象,提出一种基于改进的YOLOv3[5]与EPnP结合的算法求解几何体模型的位姿。首先利用改进的YOLOv3算法检测目标,其次预测几何体模型3D虚拟控制点的2D像素坐标,使用EPnP算法求解3D-2D的旋转矩阵和平移矩阵,最终得到目标的位姿估计结果,满足后续机器人动态抓取的精度。
1 YOLOv3目标检测算法
YOLOv3作为一阶段(one-stage)检测算法,主要是由主干特征提取网络(Darknet-53)和特征融合预测网络(FPN和Yolo Head)组成,如图1所示。
通过网络模型得到预测调整参数,将预测调整参数与真实框调整参数代入损失函数进行计算。损失函数由三部分组成,分别是预测框定位误差、置信度误差和分类误差。损失函数公式为式(1):
(1)
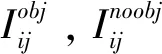
2 改进YOLOv3目标检测算法
为了提高YOLOv3算法的检测精度,改进算法的位置回归损失函数,采用完全交并比损失函数(CIOU)计算位置回归损,同时引入轻量模块通道注意力机制(ECAnet),运用网络自适应注意重要信息,调整特征图,提升算法的检测效果。
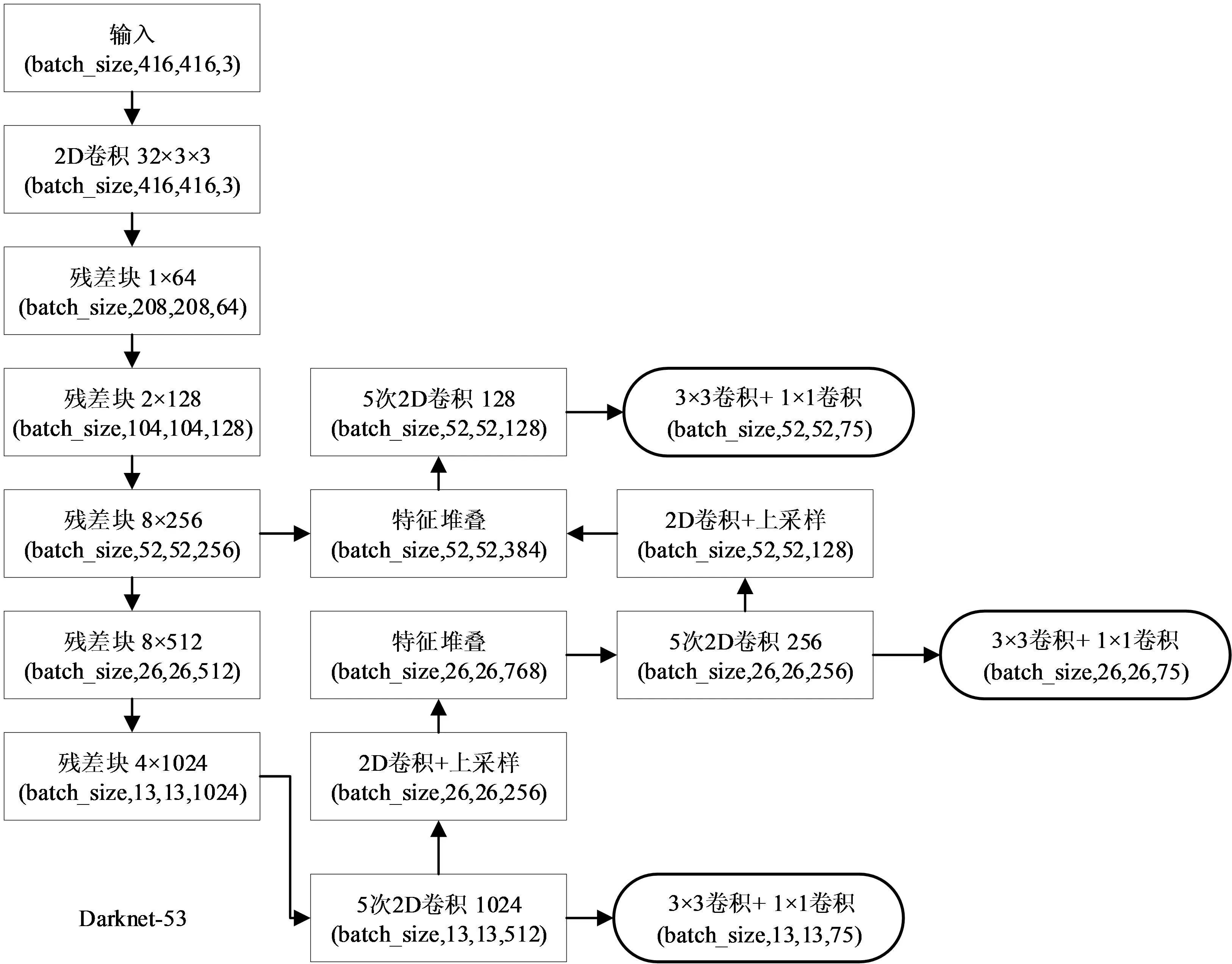
图1 YOLOv3网络模型
2.1 引入CIOU函数
YOLOv3中,采用IOU衡量预测框的检测效果,具有尺度不变性。IOU为预测框和真实框两者重叠面积与总面积的比值,公式为式(2):
(2)
为了克服梯度无法回传问题,郑朝辉等[6]提出了CIOU的概念。CIOU兼顾预测框与真实框的重叠率、尺度问题和检测框长宽比一致性的计算。其损失函数公式为式(3),(4):
(3)
(4)
式(4)中v为度量长宽比的相似性,b,bgt为预测框和真实框的中心点,ρ为计算两个中心点的欧氏距离,c为同时包围预测框和真实框的最小闭包区域的对角线距离。
2.2 引入ECANet注意力机制
由于通过自制目标数据集,没有对数据集进行图像增强处理,放入原始的YOLOv3网络模型中训练得到的预测效果不太理想。为了让网络集中学习目标所在的位置区域,使其能够关注到目标的特征点,快速有效地学习图像信息。为此引入ECANet注意力机制。ECANet为改进版的通道注意力机制,它去除原有的全连接层模块,直接在全局平均池化之后的特征上通过1D卷积跨通道交互,避免了数据降维。将其加入到YOLOv3网络模型,自适应判断重要特征数据,提高网络模型的性能。图2为引入ECANet注意力机制的网络模型。
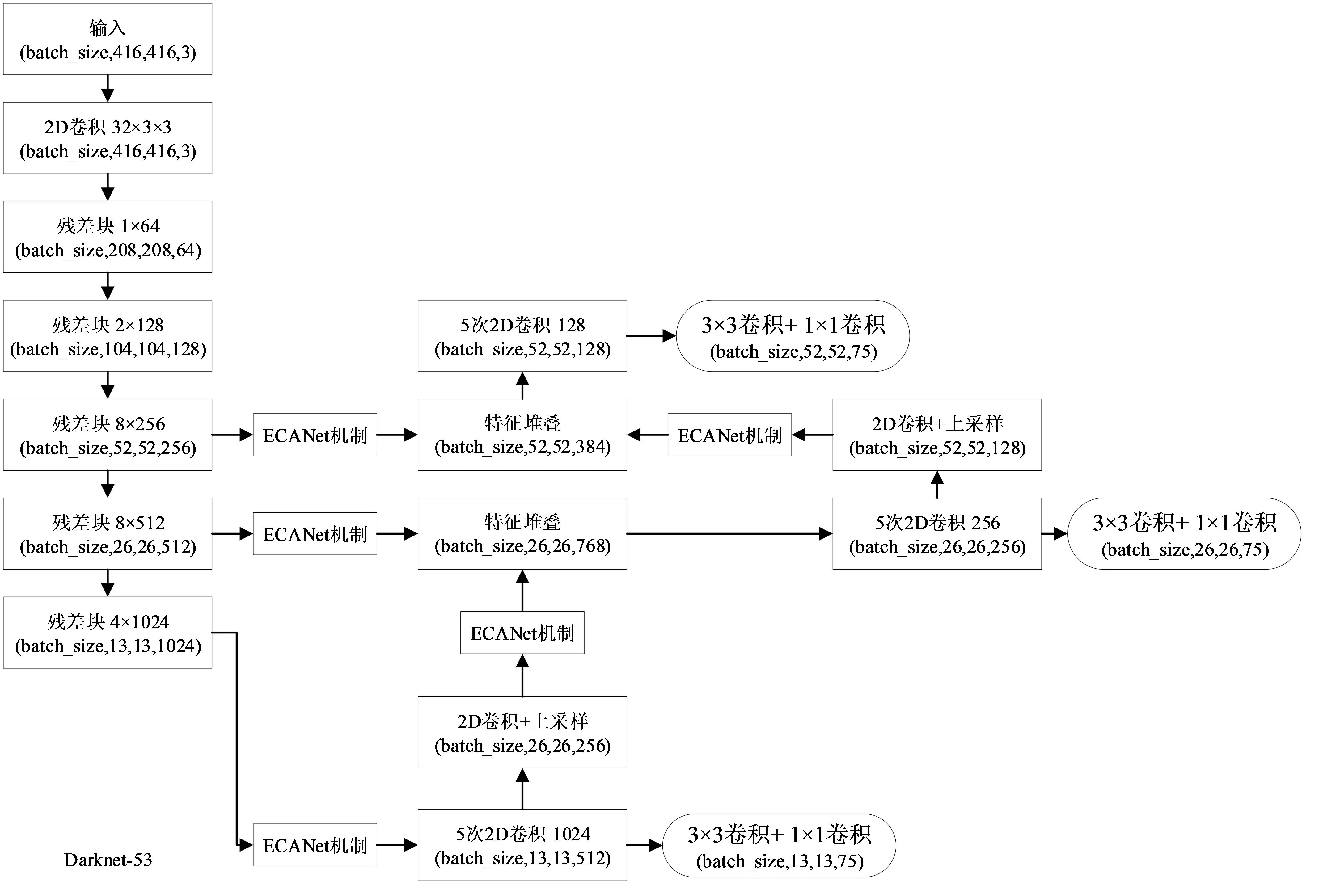
图2 YOLOv3改进网络模型
通过改进YOLOv3算法,提高了对模型的检测精度,为后续位姿估计提供了基础,所用的位姿估计方法将在下一节阐述。
3 EPnP算法位姿估计
PnP问题于1981年首次提出,在物体位姿估计方面有重要应用价值,引起人们广泛重视[7]。对于许多强纹理的目标,一般采用关键点和基于边缘的方法,通过对ROI区域分割,特征点提取,最后用PnP算法得到3D坐标与2D图像坐标对应关系进行目标的位姿求解。PnP算法易受噪声影响或者存在误差匹配则无法求解位姿,对于弱纹理或无纹理的几何体模型目标,没有明显的特征关键点,难以求解位姿。
EPnP算法是PnP算法的非迭代形式,其原理是利用虚拟控制点线性加权的结果表示真实物体上特征点在相机坐标系下的坐标。根据自制的不同纹理的几何体模型的数据集,通过预测目标模型3D虚拟控制点的2D像素坐标,然后利用EPnP算法求解目标的位姿。采用9个虚拟控制点来参数化目标模型,求解不同纹理的目标位姿。
(5)
目标世界坐标系下的3D坐标可用虚拟控制点线性加权表示(n>=5),aij为加权系数。
目标的3D坐标和虚拟控制点的坐标之间的关系在相机坐标系下如式(6):
(6)
两个坐标系下的虚拟控制点关系如式(7):
(7)
假设目标的3D坐标在像素坐标系下的投影坐标为(ui,vi),则投影坐标与3D虚拟控制点之间的关系如式(8):
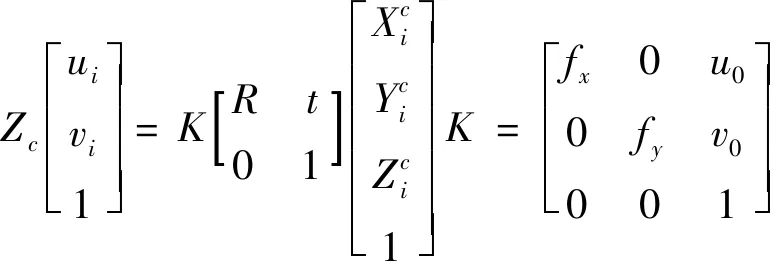
(8)
式(8)中Zc为坐标点的投影深度,K为相机内参矩阵,fx,fy,u0,v0为相机内部参数。
通过建立目标的3D虚拟控制点与像素坐标之间的关系,将3D点与2D点之间一一对应,再利用EPnP算法将3D虚拟控制点线性加权求和对目标进行位姿求解,并得出目标的旋转矩阵R和平移矩阵t。
4 实验结果与分析
4.1 实验数据集
利用Intel D415深度相机采集六种几何体模型(圆,六棱柱,锥体,正方体,圆锥,圆柱)图像作为数据集,数据集共有1000张图像,以9:1的比例随机制作(训练集与验证集)和测试集,900张图像进行网络的训练与验证,其中训练集与验证集的比例为9:1,100张用于测试训练完成的网络。利用labelimg软件对数据集中带检测目标进行标注。实验的参数如表1所示。

表1 实验设备配置参数表
实验训练包括冻结阶段和非冻结阶段,动量为0.9,衰减为0.0005,总共训练100个Epoch。前50个Epoch的batch_size为8,学习率为1×10-3;后50个Epoch的batch_size为4,学习率为1×10-4。
4.2 实验结果与分析
使用mAP和F1分数作为算法的评价指标。mAP 是计算每个类别的平均精度(AP),再对所有类别的平均精度求取均值得到,其公式为(9):
(9)
式(9)中C为数据集的目标种类,APi为每一类的AP,P为精准率,R为召回率。
F1分数(F1Score)是精准率和召回率调和均值的2倍。往往作为模型泛化能力的评价指标,F1 分数为 0-1 之间的小数,F1 分数越大表明模型泛化能力越强,其公式为(10):
(10)
将YOLOv3算法与改进的算法进行对比实验,利用自制几何体模型数据集进行训练测试得到每一种几何体模型类别AP值,对比结果如表2所示。
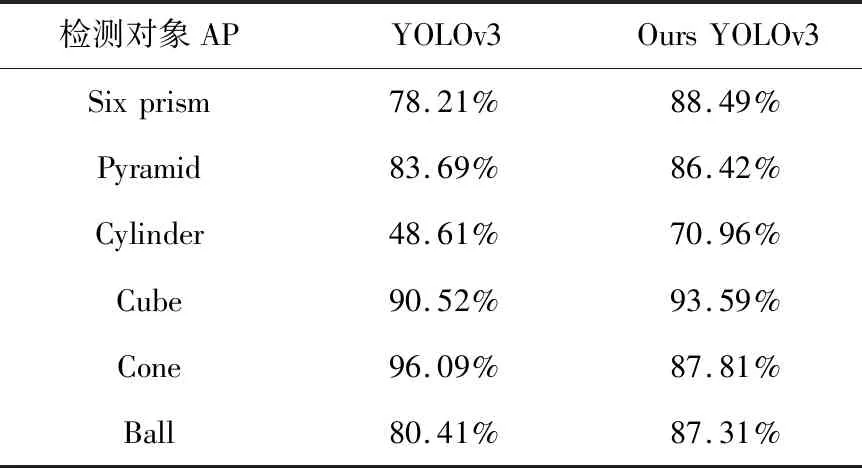
表2 两种算法的AP值对比
图3为网络训练损失图。从图中可以看出,随着训练次数的增加,两者的验证集损失都逐渐降低。在50个Epoch时,由于网络中所有参数都参与训练,损失值会上升,后续逐渐趋于稳定。而且改进的YOLOv3算法比原算法的初始Epoch验证集损失值降低,收敛速度更快,收敛稳定后损失值降低了34.9%。
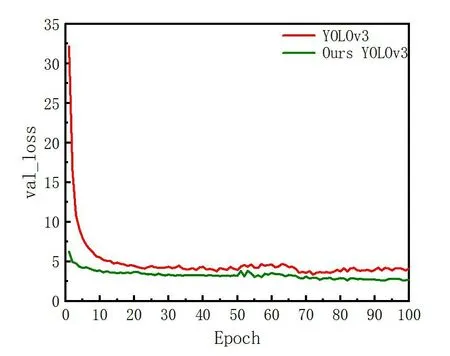
图3 网络训练损失图
进一步对两种算法的mAP和F1分数整体评价指标进行对比,结果如表3所示。
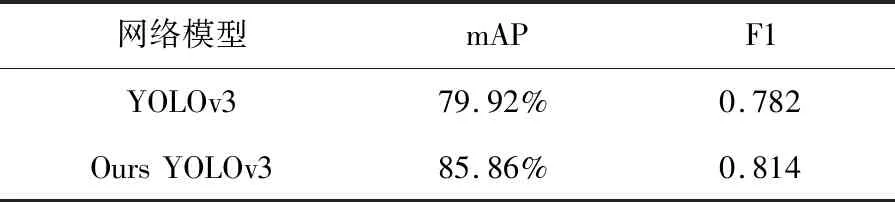
表3 整体检测网络性能对比
从表3可以看出,在设置mAP@0.5时,相较于YOLOv3算法,改进的YOLOv3的mAP与F1分别提高了约6%,3%,提升了网络模型的检测精度,增强了整体泛化能力,为后续目标的位姿估计提供了准确的类别信息。
图4和图5分别为YOLOv3和改进的YOLOv3的实际检测结果图。从图中可以看出,改进后的YOLOv3的预测框与真实框的重合度更高,对物体的定位更加准确,检测效果更好。

图4 YOLOv3检测结果图

图5 YOLOv3改进检测结果图

图6 位姿估计效果图
图6为位姿估计效果图。从图中可以看出,能够较好的得到目标的质心和3D边界框尺寸。
通过自制的几何体模型LINEMOD数据集,将其代入EPnP算法网络模型中,得到每种几何体位姿平移误差、旋转误差和像素误差的结果,结果如表4所示。
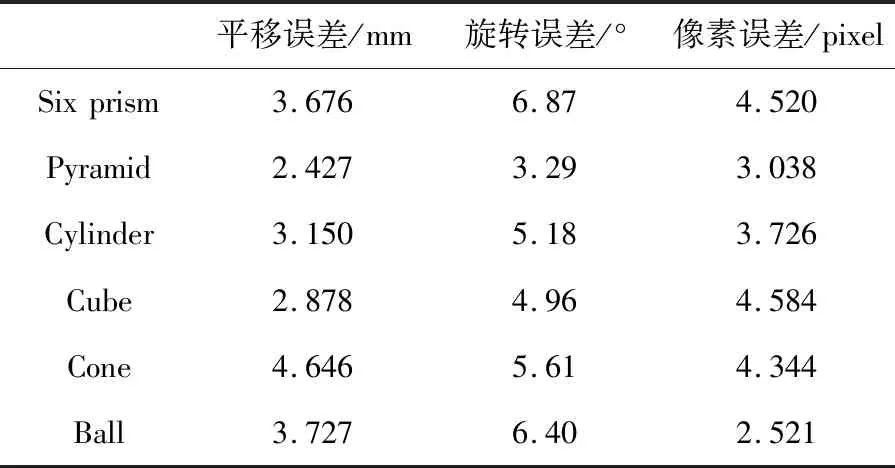
表4 位姿估计误差结果表
由表4可知,得到的六种几何体模型位姿估计的平移误差均小于5mm,旋转误差均小于7°,特征点像素误差均小于5pixel。能够对相机与目标之间的相对位姿进行较为精确的检测,进而可以认为,能够对几何体模型的位姿进行较为精确的估计,满足后续机器人动态抓取的精度。
5 结 语
基于改进的YOLOv3算法和EPnP算法对几何体模型进行目标检测和位姿估计,实验结果表明,改进的YOLOv3算法能够快速实现几何体模型的检测定位和位姿估计,有较高的检测精度,验证了该算法的有效性。
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
今日中国·法文版(2020年7期)2020-07-04
中国特种设备安全(2019年1期)2019-03-13
北京航空航天大学学报(2017年4期)2017-11-23
中国工程咨询(2017年12期)2017-01-31
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
山东青年(2016年2期)2016-02-28
湖北工业大学学报(2016年5期)2016-02-27
安徽地质(2016年4期)2016-02-27
