
一种基于加权K⁃means的边缘服务器部署方案
2022-12-14 02:17刘乃安张澍文李晓辉吕思婷
现代电子技术 2022年24期
刘乃安,张澍文,李晓辉,吕思婷
(1.西安电子科技大学通信工程学院,陕西 西安 710071;2.西安电子科技大学广州研究院,广东 广州 510555)
0 引 言
近年来,移动互联网产业飞速发展,文献[1]引用全球移动数据流量预测:更新在联网设备的数量将超过全球的总人口数。如今联网设备的数量早已呈爆炸式的增长,为了满足5G 时代海量计算、海量数据、时延敏感和海量连接等需求,欧洲电信标准协会在2014年启动移动边缘计算(Mobile Edge Computing,MEC)标准项目。随着软件定义网络(SDN)和网络功能虚拟化(NFV)的提出,文献[2⁃4]指出移动网络运营商(MNOs)将内容分发网络(CDN)功能集成到移动网络。5G 通信网络架构不同于4G 通信网络架构,它将核心网的应用下沉至网络边缘侧。边缘服务器的部署将直接影响智能终端的接入速率、网络时延、连接的可靠性以及智能终端的体验质量。文献[5]通过在网络边缘部署移动边缘服务器,智能终端的部分请求不用再去访问核心网,而是通过访问建立在基站侧的边缘服务器,使得传输距离变短从而降低了时延。未来MEC 业务的实现,会使网络传输压力下降,边缘服务器的合理部署可有效避免网络拥塞和负载均衡。
S.Nunna 等人描述了大量的移动边缘计算应用场景,如今汽车行业的自动驾驶和电子医疗领域的机器人远程手术等业务都迫切需要通过MEC 来实现低延迟、近距离通信服务和全局感知等功能[1]。在每个基站配备一台边缘服务器会消耗过多的资源,因此合理的部署方案十分关键。文献[6]中提出了一种基于传统K⁃means算法的方案来解决边缘服务器的部署问题。该方法可以简单快速地获取单一时刻的簇心,但并没有考虑到当移动终端的位置产生变化后的结果对边缘服务器部署的影响。近年来,有大量的研究人员通过改进K⁃means算法获得更好的分类效果。文献[7]中描述了不同聚类算法之间的差异,并根据文献[8]提出了一种基于距离和权重改进的K⁃means 算法,有效地避免孤立点和噪点对结果的影响。对于实际的应用场景,需要尽可能地在边缘服务器业务范围内覆盖更多的终端设备,为每一个用户提供服务。针对上述研究,本文从实际情况出发,通过KNN 算法将模拟的移动设备根据与基站的距离进行分类,并获取每个基站侧的流量统计值,采集每一个移动终端的位置坐标进行加权K⁃means 算法处理,寻找聚类中心。另外,建立一个模拟场景来测试不同方法得到的边缘服务器部署位置,针对不同边缘服务器个数和不同时间段下的传输时延进行评估。实验结果表明,所提方案显著地降低了传输时延,缓解了网络拥塞,从而提高了用户的体验质量。
1 背景与问题描述
1.1 移动边缘计算的背景
现如今,海量的移动设备对于数据处理的要求越来越高,为了提高用户上网的舒适感,文献[9⁃10]中提出了云计算的解决方案,即将数据传输到远程云端进行计算存储。但是云端在地理位置上与智能终端距离较远,并不能满足低时延的要求,因此移动边缘计算被提出。MEC 通过NFV 以及SDN 两大技术将网络功能、内容和资源部署在边缘服务器,缩短与智能终端的距离,从而降低时延。相较于云计算这种集中式结构,移动边缘计算则属于分布式结构,虽然单个的边缘服务器的处理能力有限,但是服务节点的数目多,相邻的边缘服务器之间也可以进行数据的交互。移动网络边界计算平台可以放置在基站侧,缩短数据传输的距离,满足低时延的要求。
1.2 边缘服务器部署问题
边缘服务器部署在基站一侧,相较于云计算有着地理位置上的优势,但如何选取边缘服务器的部署位置就成了MEC 技术最关键的一步。合理的部署位置可以实现移动用户的覆盖率最大化,减少孤立用户偏离边缘服务器的覆盖范围,从而使移动用户得到良好的体验质量。本文算法是基于流量统计所提出,根据CNNIC(中信证券研究部)提供的数据,自1997年至今,中国手机网民规模达到80%以上,其中手机网民占整体网民比例接近100%,网民每周上网时间也在逐步增多,其中短视频时长占比持续提升。MEC 的提出不仅能提高用户的体验质量,还能够降低基站对于网络资源提供的压力。根据上述研究,可实现的功能有:边缘服务器的部署将进一步促使移动运营商与各种包含短视频业务和车联网业务的公司合作;移动运营商通过为有需求的公司提供MEC 服务,使移动用户获得更加舒适的用户体验。
2 系统模型
本文系统模型的符号概述如表1所示,根据实际的系统模型可确定目标函数及约束方程。本文将文献[11]中提出的负载均衡问题中所应满足的带宽占用比和利用负载平衡因子判断当前接入网络的负载情况作为判断平衡负载情况的参考。

表1 符号概述
2.1 系统架构
移动边缘计算的系统框架如图1所示,作为一种三级网络架构,它包括数据中心层、边缘服务器层和移动终端设备层。移动终端设备层中包含种类繁杂的移动设备,如手机、便携式计算机和车联网设备等。在之前关于边缘服务器部署的研究[6]中,并没有提出当移动终端发生位置变化时是否会对边缘服务器的部署产生影响。由于移动终端的数量过于庞大,所以通过研究设备移动的方式选择边缘服务器部署位置是难以实现的。本文通过模拟流量峰值时移动终端的分布位置得到坐标,并根据基站侧采集到的流量对移动设备进行加权,有效地弱化终端设备的移动性。因为人类生活习惯和活动场所范围的局限性,当用户基数不断扩大时,个别用户大范围的转移不会对边缘服务器的部署问题产生本质的影响。相较于任意时刻下选择边缘服务器位置部署的模型,本文所提方法更具有实用性和真实性,所部署的边缘服务器可以进一步提高用户的QoE。
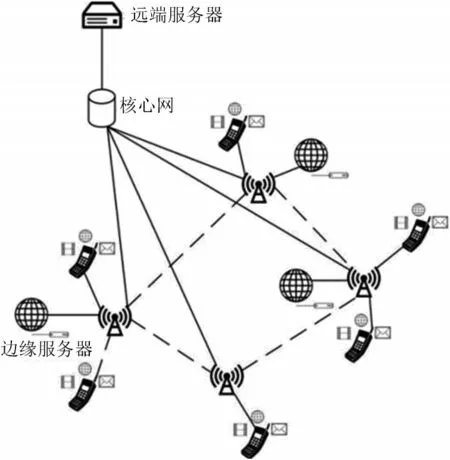
图1 MEC 系统框架
解决边缘服务器的部署问题主要取决于边缘服务器层以及移动终端设备层。边缘服务器层由基站B 和边缘服务器S 构成,在基站与基站、边缘服务器与边缘服务器之间都可以进行数据交换。为了解决边缘服务器的部署问题,需要尽可能地使边缘服务器所覆盖的移动终端数目最大化,减少网络各层之间数据传输的距离和时延,减少开发商的建造成本以及提高用户的体验质量。移动终端设备层由不同种类的可与边缘服务器层进行数据交换的设备U构成。
每个基站bi和其覆盖范围下与其进行数据传输的终端用户uij(i=1,2,…,m;j=1,2,…,n)之间的传输时延可用欧几里得距离d(bi,uij)表示,基站与边缘服务器si之间的传输损耗用d(bi,sj)表示,公式如下:
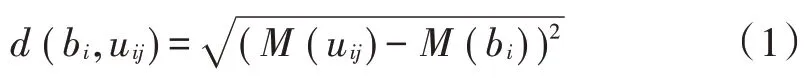
由于d(bi,uij)≫d(bi,sj),所以基站与边缘服务器之间的传输损耗可以忽略不计。本文需要解决的是如何部署边缘服务器在实时条件下对于移动终端的时延最小化的问题,即解决平均传输距离问题,使平均传输时延降低到最小,公式为:
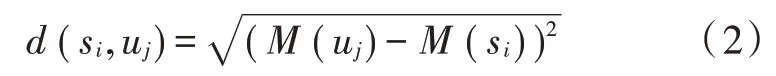
2.2 目标方程与约束
边缘服务器部署中的普遍约束问题包括边缘服务器si是否部署在基站bj上、智能设备uj是否分配给边缘服务器si,以及对用户服务质量的约束。
边缘服务器与基站的连通性表示为:
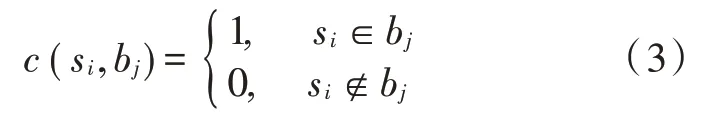
智能终端与边缘服务器的连通性表示为:
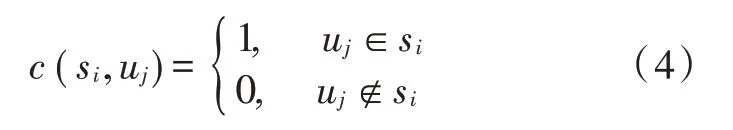
用户服务质量的约束表示为:

式中σ表示智能设备uj与边缘服务器si之间的网络延迟。
现在的边缘服务器部署问题没有考虑不同时段智能终端访问的实际情况,即用户高峰时段或用户集中区域,智能设备的高密度访问会导致网络出现拥堵的情况。为了克服这一问题,在边缘服务器的部署问题中加入用户的访问数据量这一约束,以便更合理地分配网络资源,更快速地进行网络数据传输。这一约束问题可表示为:
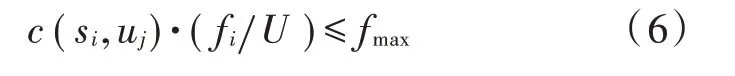
本文以系统平均完成时间最小化为目标函数,公式如下:
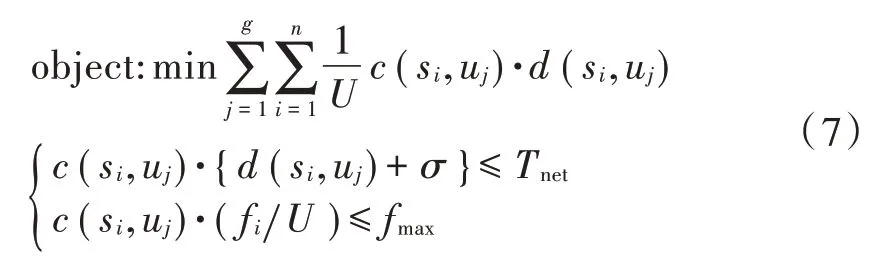
3 部署算法
文献[12]中分析了近几年聚类算法的算法思想、关键技术以及优缺点。其中针对数值类型数据的实验,K⁃means 算法的运行效率远高于传统层次聚类算法。传统K⁃means 算法是一种简单、高效的聚类算法,但是传统K⁃means 算法随机选择簇心的机制可能导致结果陷入局部最优。因此需要对传统的K⁃means 算法进行改进,让它更加适合在MEC 场景下对边缘服务器进行寻址。文献[13]提出一种基于距离和样本权重改进的K⁃means 算法,以密度峰值作为加权的参考依据并且有效地选择初始聚类中心,提升了算法的性能。但是对于边缘服务器部署的实际问题,智能终端的密度会随着用户位置的变化而发生变化。因此本文依据基站侧的流量统计提出一种改进的K⁃means 算法,主要内容如下:
1)数据采集。在300×300的地图中模拟真实场景放置4 个坐标已知的基站bm,模拟人口分布特点随机生成800个终端设备样本点,并获取每个设备的位置坐标un。
2)数据分类。本文暂不考虑终端设备在不同基站覆盖范围下的数据切换问题,只根据设备距离基站的真实距离对100 个样本点进行分类。使用k=1 的KNN 算法,根据每个样本点到不同基站的欧氏距离,选择距离最小的基站作为一个子集,如图2所示。其中nA,nB,nC,nD表示A、B、C 和D 基站下对应的智能设备数目。
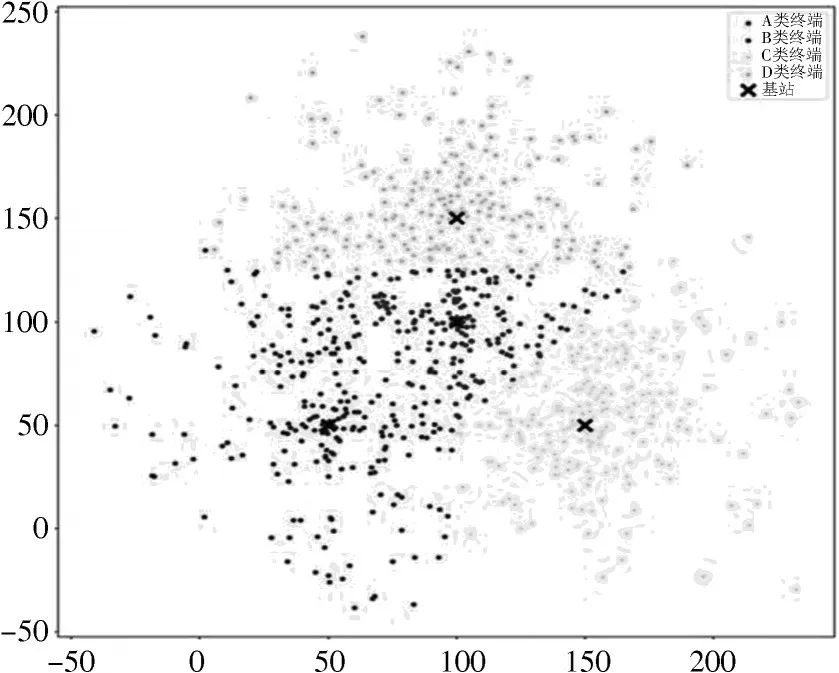
图2 终端设备分类效果图
3)权值分配。根据基站上统计到的日流量,通过式(8)计算不同组数据集样本的权重,得到不同基站下对应智能终端所属权重ωA,ωB,ωC,ωD。
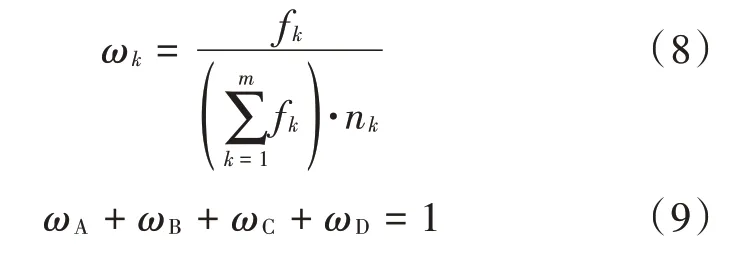
4)算法实现。将随机选取的l个对象作为原始聚类中心,通过100 次迭代,将加权后的终端地理位置按照距离聚类中心最近的原则重新分配到每个聚类中,最终得到聚类中心的坐标sl。由于随机挑选原始聚类中心会对算法的结果产生影响,所以本文将多次产生的结果再次进行聚类划分,得到误差最小的结果。图3为选择4 个边缘服务器分布结果图。
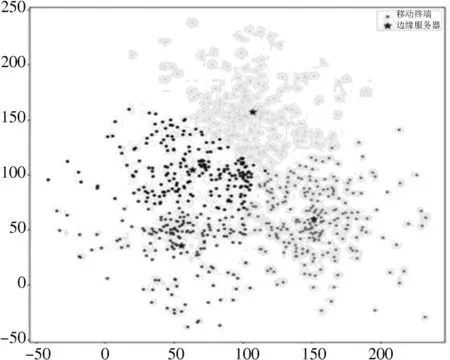
图3 加权K⁃means 算法边缘服务器的部署位置
4 实验与分析
对所提算法结果进行分析,在智能终端和基站数量分布相同的情况下,分别比较所提加权K⁃means 算法、传统K⁃means 算法和随机方法在模拟环境中的终端的响应时延。
4.1 不同数量边缘服务器下的效果对比
如图4所示,当边缘服务器部署的数量越多时,智能终端的响应时间逐渐降低,当边缘服务器的数量增多,智能终端总是可以访问距离最近的边缘服务器。由于边缘服务器的部署问题需要考虑实际成本,为了避免资源浪费,移动运营商希望在满足用户体验质量的同时,可以使部署策略产生成本最小化。
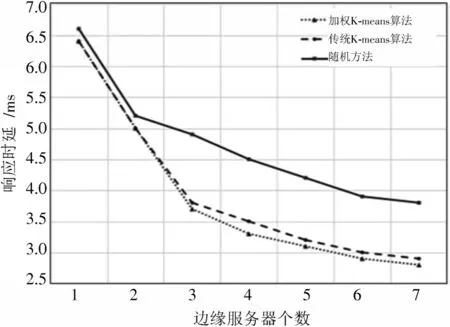
图4 边缘服务器不同数量下的响应时延
图4中,横坐标是边缘服务器的个数,纵坐标是所有终端的平均响应时间。当边缘服务器部署的数量大于6 个时,响应时间的变化率也逐渐减小,部署过多的边缘服务器将会造成资源以及成本的浪费。综合考虑部署成本、响应时延以及用户体验质量等因素,发现选择6 个边缘服务器的部署策略是最合理的。对比分析发现,本文提出的方案相较于随机部署方法和传统K⁃means 算法选择的部署位置,对于移动终端用户的响应时延总是最小的。
4.2 不同时段下边缘服务器部署效果对比
为了使边缘服务器可以满足各种场景下移动用户的体验质量,本实验根据用户的实际需求在不同时段场景下进行分析。当移动用户的响应轨迹发生变化时,边缘服务器的部署位置是否还能支持低时延的传输以及尽可能多的连接请求是本文探究的关键问题。本文分别模拟早晨、中午和傍晚三个时间段终端设备的分布位置和分布密度,如图5所示。由图5可知,在早晨和傍晚阶段,人口分布较为均匀并且网络传输压力较低,加权K⁃means 算法和传统K⁃means 算法相较于随机部署方法有着不错的表现。到中午时,人口多聚集于公司、学校等场所,分布稀疏度明显,部分区域的网络传输压力增大,这种场景对于边缘服务器的部署是一种考验。实验结果可以得出,传统K⁃means 算法相较于随机部署方法有着不错的优势,而本文提出的加权K⁃means 算法对于边缘服务器部署问题更加具有优势。
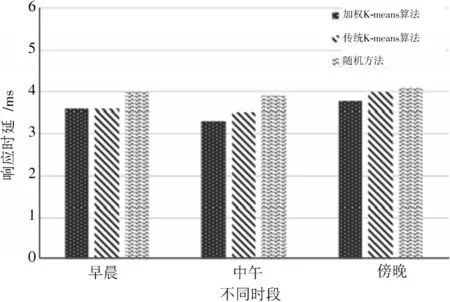
图5 不同时段下的响应时延
综上所述,本文提出的加权K⁃means 算法相较于传统K⁃means 算法和随机部署的方法对于边缘服务器部署位置的选择更加合理;并且本文算法随着场景的不断切换和智能终端用户对于边缘服务器请求的不确定性,表现出更加优秀的适应性。
5 结 语
边缘服务器的部署问题是获取服务于用户效率最大化的寻址问题。在实际处理这个问题时,不仅要满足对于设备的低时延要求,还应该考虑对于运营商成本最小的问题。在设计算法上,由于模拟的数据量远没有实际的设备数据那么庞大,因此需进一步优化本文算法,在规模更大、数据更密集的场景下实现精确的数据结果。边缘服务器处理寻址问题有待解决,在得到部署位置之后,还应该根据各个服务器之间的协同工作,找到更加优化、便捷地处理数据的卸载方案。
猜你喜欢
电子制作(2019年23期)2019-02-23
测控技术(2018年6期)2018-11-25
探索科学(2017年4期)2017-05-04
通信产业报(2016年44期)2017-03-13
系统工程与电子技术(2016年7期)2016-08-21
中国交通信息化(2016年8期)2016-06-06
电测与仪表(2016年17期)2016-04-11
移动通信(2015年17期)2015-08-24
发明与创新(2015年29期)2015-02-27
雕塑(1999年2期)1999-06-28
