
基于局部结构保持的高维数据半监督深度嵌入聚类算法*
2022-12-07 09:36李梦利阳树洪李春贵
广西科学 2022年5期
曹 超,李梦利,阳树洪,李春贵
(广西科技大学电气电子与计算机科学学院,广西柳州 545006)
聚类分析利用数据的内在结构将数据划分为互不相交的子集,是数据分析中的重要课题,长期以来受到机器学习和统计分析领域学者的广泛关注。真实数据中存在一些先验知识,这些先验知识由少量标记数据或专家给出的成对约束表示,但纯粹的无监督聚类算法没有考虑数据中可能存在的先验约束关系或者监督信息,使得学习难度增大。半监督聚类算法[1-4]在大量的无监督数据中仅引入少量的先验信息即可显著提高聚类性能,从而成为近年来的重要研究方向。
半监督聚类算法大体可以分为两类。第一类半监督聚类可同时利用未标记的、足够多的数据和一些先验的知识改进聚类性能。例如,Hong等[5]提出了一种半监督的深度学习框架,可以从小规模的图像中学习更多的判别信息,并将其转移到大规模数据的分类任务中。第二类半监督聚类以强监督的方式使用先验知识,使用标签信息直接指导聚类中心的学习,并以数据驱动的方式对样本进行聚类以学习聚类中心,并得到对聚类有效的表示。例如,Chen等[6]提出一种新的半监督联合学习框架,通过在联合优化损失函数中集成少量标签信息来学习特征嵌入空间和集群分配。
传统的半监督聚类大多通过对谱聚类、非负矩阵分解和典型相关分析等浅层聚类模型进行改进,或将K-means和线性判别分析(Linear Discriminant Analysis,LDA)等算法进行结合以引入监督信息[7]。但这些方法都属于浅层模型,无法有效表达高维数据间的高层语义信息,如近年来出现的基因信息挖掘,即属于典型的高维数据分析问题。近年来,深度聚类引起了广泛关注,研究者通过学习数据的低维表示,有效缓解传统聚类算法在面对高维输入数据时的退化问题。例如,Yang等[8]提出的深度聚类网络(Deep Clustering Network,DCN)将自动编码器与K-means算法相结合;Peng等[9]提出的深度子空间聚类(Deep Subspace Clustering,DSC)引入一种新颖的自动编码器架构,学习有利于子空间聚类的非线性映射[10]。为了进一步提高高维数据的聚类性能,有研究者提出了一些端到端的深度聚类方法,将深度神经网络(Deep Neural Networks,DNN)融合到聚类中。例如,Xie等[11]在2016年提出的深度嵌入聚类(Deep Embedding Clustering,DEC),可学习数据的聚类特征并以自学习的方式划分数据。Li等[12]在2018年提出的判别提升聚类(Discriminatively Boosted Image Clustering,DBIC)算法使用卷积自动编码器改进DEC,由于该算法使用卷积网络,因此其在图像数据集上的聚类性能优于DEC。
此外,深度聚类算法之所以取得成功有两个重要的因素。首先是深度神经网络强大的特征表示能力以及计算能力,其次是不同的算法在特征学习过程中对特征施加的约束,使得深度神经网络模型在训练过程中学习到更适应于聚类任务的深度特征。尽管深度聚类算法取得了很大的突破,但是很多深度聚类算法在特征学习过程中没有保持特征之间的局部连接结构,导致从原始数据空间到低维特征空间的转换过程中破坏了数据的特征结构,从而产生没有表示意义的特征,在一定程度上影响聚类的性能。
Peng等[13]在基于稀疏先验的深度子空间聚类算法中指出,欠完备自动编码学习样本在嵌入空间中特征表达的同时,保持其在原始空间中的局部结构。受此启发,本文提出基于局部结构保持的改进半监督深度嵌入聚类(Improved Semi-supervised Deep Embedded Clustering,ISDEC)算法。首先,使用欠完备自动编码器建立输入样本及其潜在表示之间的映射关系,从而剔除样本中的不利因素,以及保留数据生成分布的局部结构。其次,将欠完备自动编码器纳入半监督深度嵌入聚类(Semi-supervised Deep Embedded Clustering,SDEC)框架,使该框架可以在保持局部结构的情况下,联合进行聚类和特征表达学习的同步优化。最后,本文采用小批量随机梯度下降(Stochastic Gradient Descent,SGD)和反向传播算法对所提出的ISDEC算法进行优化。
1 半监督深度嵌入聚类
半监督深度嵌入聚类(SDEC)[14]从预处理自动编码器开始,然后移除解码器。其余编码器通过优化以下目标进行微调:
(1)
其中,qij是嵌入点zi和聚类中心μj之间的相似性,由学生t-SNE分布函数测量:
(2)
并且式(1)中的pij是目标分布,定义为
(3)
其中,矩阵A用来描述成对约束中必须链接约束(Must-Link,ML)和不能链接约束(Cannot-Link,CL),j和j′表示k个聚类中心u的索引,aik是矩阵A的第i行k列的元素。当xi和xk被分配给同一簇时,aik=1。如果xi和xk满足不能链接的约束,aik=-1。此矩阵中的其他元素均为零。


2 改进的半监督深度嵌入聚类


L=Lu+λLs+γLr,
(4)
其中,Lr、Lu、Ls分别为重构损失、聚类损失、成对约束损失,λ是由用户定义的权衡参数,γ>0为控制重构程度的参数。当γ=0时,式(4)降为SDEC的目标。
本算法的总体框架如图1所示,使用预先训练的堆叠自动编码器(Stacked AutoEncoder,SAE)的编码层来初始化DNN结构。将成对约束添加到嵌入层z,以指导特征表示的学习。用重构损失保证嵌入空间保持数据生成分布的局部结构。q表示每个数据点的软分配,并用于计算Kullback-Leibler (KL)发散损失。
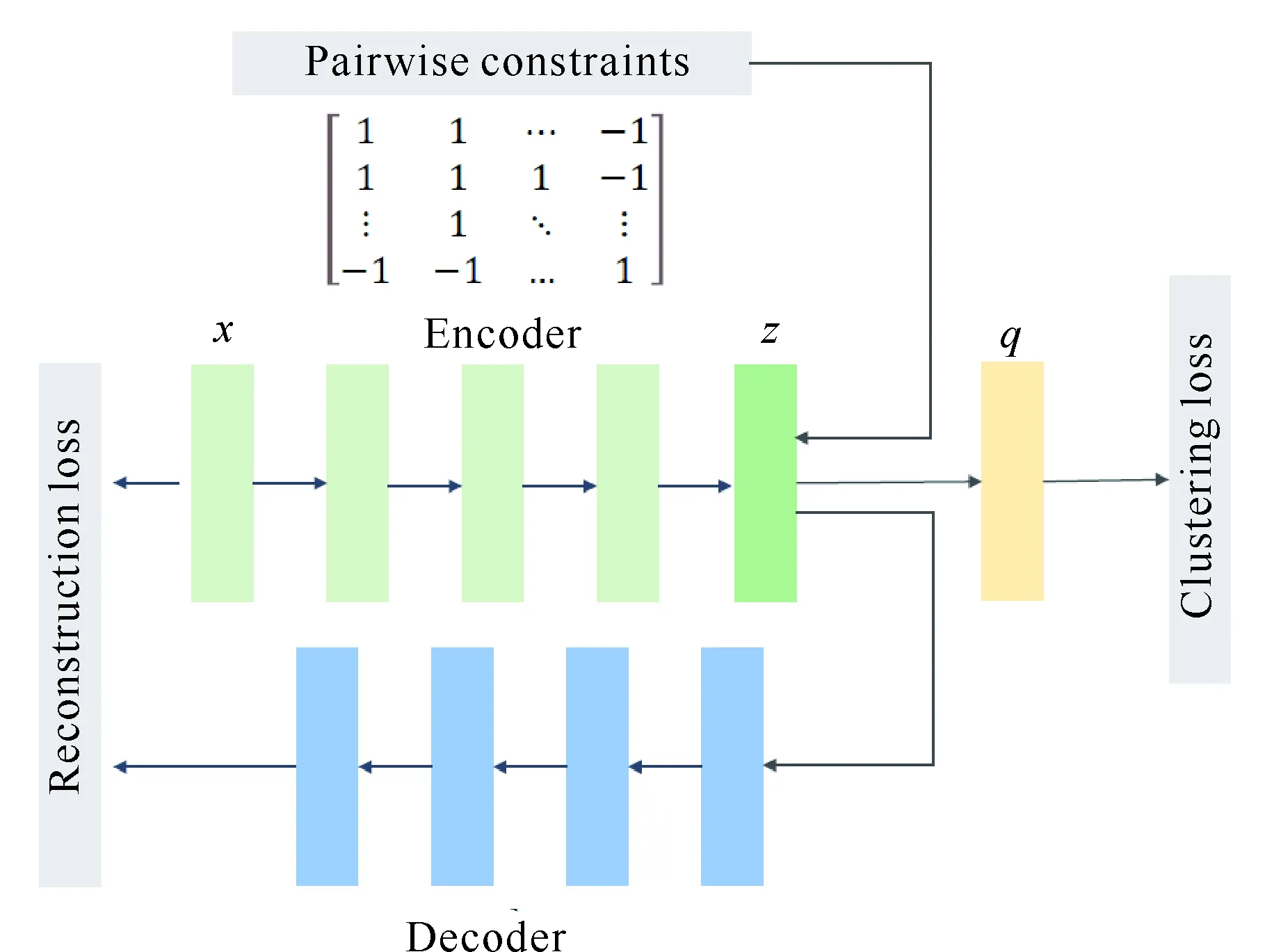
图1 ISDEC算法框架Fig.1 Framework of ISDEC algorithm
2.1 聚类损失和参数初始化
P和Q之间的KL散度被定义为聚类损失,其中Q为软标签分布,是通过学生t-SNE分布测量得出,P是从Q推导出来的目标分布。也就是说,聚类损失被定义为
(5)
其中,KL用于测量两个概率分布之间的非对称差的散度,通过式(3)和式(2)定义P和Q。
矩阵A设计的思想在于,训练时施加一个约束:将相同类别的点在潜在特征空间中彼此接近,而不同类别的点之间彼此远离。为此,成对约束损失定义为
(6)

2.2 局部结构保护
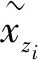
(7)

为了保证聚类的有效性,用于预处理的堆叠式去噪自动编码器不再适用。因为聚类应该在干净数据的特征上执行,而不是在去噪自动编码器中使用噪声数据,所以本文直接去除噪声,堆叠式去噪自动编码器退化为欠完备自动编码器。
至此,ISDEC 算法的总损失函数如下:
(8)
其中,Lu和Ls联合成为SDEC的总体损失函数Lc,用以实现特征数据与聚类中心改进的分配结果,Lr用于保持特征数据从预训练特征空间到微调特征空间的局部结构,使得学习到的特征保持固有本征结构,从而进一步提升特征学习和聚类任务的性能。λ是由用户定义的权衡参数,γ为控制嵌入空间失真程度的系数。
2.3 优化
利用小批量梯度下降算法结合反向传播算法最小化目标函数(8),同时对聚类中心μj,以及深度编码器参数θe和θd进行优化。
由于局部保持损失只对特征数据进行约束,而没有涉及聚类中心的计算,因此总体损失函数L对聚类中心μj具有梯度:
(pij-qij)(zi-μj)。
(9)
L损失函数对于特征zi的梯度计算如下:
(10)
注意,上述推导来自SDEC。然后给定一个具有m个样本和学习率η的小批量,μj被更新为
(11)
解码器的权重W′通过以下方式更新:
(12)
编码器的权重W通过以下方式更新:
(13)
更新目标分布,目标分布P用作“基本事实”软标签,但也依赖于预测的软标签。因此,为避免不稳定,不应仅使用一批数据在每次迭代中更新P。在实践中,本文在每T次迭代中使用所有嵌入点更新目标分布。更新规则见式(2)和式(3)。更新目标分布时,以最大概率的qij为xi的标签计算如下:
(14)
其中,qij由式(2)计算。如果目标分布的两次连续更新之间的标签分配变化(百分比)小于阈值ε,将停止训练。以下算法1总结了整个算法。
算法1:基于局部结构保持的改进半监督深度嵌入聚类
输入:输入数据:X;聚类数:K;目标分布更新间隔:T;停止阈值:δ;最大迭代:MaxIter。
输出:双自动编码器的权重W和W′;聚类中心μ和标签s。
①根据3.1节初始化μ、W和W′
②for iter∈{0,1,…,MaxIter} do
③ if iter%T== 0 then
⑥ 保存上次标签分配:sold=s
⑦ 通过式(14)计算新标签分配s
⑧ if sum(sold≠s)/n<εthen
⑨ 停止训练
⑩选择一批样本S∈X
3 验证实验
3.1 数据集
为了验证所提方法的聚类性能,本文在4个大规模数据集(MNIST、USPS、REUTERS-10K和Fashion-MNIST)和2个基因数据集(LUNG和GLIOMA)上进行实验。MNIST由70 000个28×28像素大小的手写数字组成;USPS包含9 298张灰度图像;REUTERS-10K包含大约810 000个用分类树标注的英语新闻故事[15],本文使用4个根类别:公司/工业、政府/社会、市场和经济作为标签,排除了所有带有多个标签的文档,随机抽样10 000个例子的子集,并计算2 000个最常见单词的tf-idf特征;Fashion-MNIST包含60 000个训练图像和10 000个测试图像,每张图片都以28×28像素的灰度显示。LUNG包含5类共203个样本,每个样本有12 600个基因,去除标准差小于50个表达单元的基因,得到203个样本3 312个基因的数据集;GLIOMA包含4类共50个样本,每个样本有12 625个基因,经过预处理得到了一个包含50个样本和4 434个基因的数据集。


表1 数据集的统计数据Table 1 Statistics for dataset
3.2 实验设置
将编码器网络设置为一个全连接的多层感知器(MLP),除基因数据以外的数据集的维数为d-500-500-2 000-10,基因数据由于样本少而特征多,故采用维数为d-1 000-100,其中d为输入数据(特征)的维数。解码器网络的数据集维数与编码器网络的数据集维数是颠倒的,即相应的解码器网络的数据集维数分别为10-2 000-500-500-d和100-1 000-d。深度编码器的所有内层除了输入层、输出层和嵌入层外,所使用的激活函数都是ReLU非线性函数[16]。使用与SDEC相同的参数设置对自动编码器进行预训练和微调,最大限度地减少参数调整的影响,以确保实验结果的改进是本文提出方法的贡献。
对于每个数据集,根据真实标签随机生成成对约束矩阵A。本文从数据集中随机选择两个数据点:如果两个数据点共享同一个标签,将生成一个必须链接约束;否则,将生成一个不可链接的约束。SGD的学习率为0.01。收敛阈值tol%设置为0.1%。对于所有算法,本文将聚类的数量K设为真实标签类别的数量。参数λ设置为10-5。为了评价聚类结果,本文采用两个标准评价指标:准确度(ACC)和归一化互信息(NMI)。
本文算法与K-means[1]、深度嵌入聚类(DEC)[5]、成对约束K-means (KM-CST)[17]、改进的深度嵌入聚类(IDEC)[18]、自加权多核学习(SMKL)[10]、半监督深度嵌入聚类(SDEC)[14]算法作聚类性能对比,以此证明本文算法在聚类方面的有效性。
3.3 结果与分析
对比方法的结果分别来自对应的论文公开发布的代码,如果某个算法不适用于特定数据集,聚类结果就用N/A 代替。由表2和表3可以看出,本文所提出的方法优于其他6种先进方法。

表2 ACC 测量的聚类结果Table 2 Clustering results of ACC measurements

表3 NMI 测量的聚类结果Table 3 Clustering results of NMI measurements
续表

Continued table
具体而言,KM-CST的性能优于K-means,表明结合成对信息提高了聚类性能。与传统的 K-means 和 SMKL相比,深度网络可以学习更具表示能力的特征。虽然 DEC 和 IDEC 也利用了数据的深层特征,但它们忽略了隐藏在少量标签数据中的信息。SDEC使用成对约束来指导聚类过程,但没在特征学习过程中保持特征之间的局部连接结构。以上结果表明本算法的局部结构保持与成对约束相结合对聚类的效果有更好的改进作用。
为了进一步说明所提方法的优越性,在图2中清晰地显示了ISDEC和SDEC在MNIST数据集上训练过程中的准确性,可见ISDEC优于SDEC。
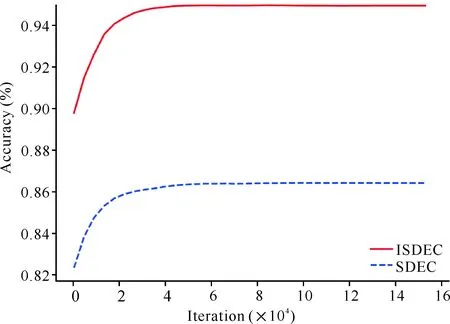
图2 ISDEC和SDEC在MNIST训练期间的准确性Fig.2 Accuracy of ISDEC and SDEC during MNIST training
通过在训练过程中对嵌入的特征空间进行可视化,可进一步显示本算法在特征学习过程中的局部保持效果。图3显示了从MNIST数据集中随机选择1 000个样本的学生t-SNE可视化,并将潜在表示z映射到 2D 空间。从聚类结果的变化趋势可以看出,随着训练次数的增加,不同簇中的样本更容易区分,同一簇中的样本也更接近,这表明学习到的特征空间更适合聚类任务。

The differences between clusters are shown in different colors
图3 训练过程中MNIST子集聚类结果的可视化
Fig.3 Visualization of MNIST sub-cluster class results during training
4 结论
针对高维数据的半监督聚类问题,本文提出了一种改进半监督深度嵌入聚类(ISDEC)算法,即在现有算法的基础上,着重考虑了高维数据的内在局部保持问题。ISDEC首先通过优化基于KL散度的聚类损失和半监督的成对约束损失来实现数据从原始高维空间到特征空间的映射,并通过引入一个基于自编码的局部保持损失来保持深度特征学习过程中数据表达之间的局部结构。然后,将深度聚类网络融合到一个统一的框架中,对潜在空间的特征进行聚类,从而有效利用样本之间的关系。本文在包括基因数据在内的若干高维数据集上进行了大量的实验研究,定性分析和定量指标都表明,本算法在学习数据的深层特征表达的同时,能有效保持数据的局部结构,从而取得较好的半监督聚类性能。
猜你喜欢
加油站服务指南(2021年4期)2021-07-21
数学年刊A辑(中文版)(2020年1期)2020-05-19
车迷(2018年11期)2018-08-30
成都信息工程大学学报(2018年3期)2018-08-29
海峡姐妹(2018年3期)2018-05-09
制造技术与机床(2017年7期)2018-01-19
公民与法治(2016年10期)2016-05-17
公民与法治(2016年8期)2016-05-17
电子器件(2015年5期)2015-12-29
少儿科学周刊·少年版(2015年2期)2015-07-07
