
基于改进YOLOv5的安检系统算法
2022-12-07 04:02柴晓辉
沈阳大学学报(自然科学版) 2022年6期
郭 烁,柴晓辉,洪 悦
(沈阳化工大学 信息工程学院,辽宁 沈阳 110142)
目前大多数公共安全事件的威胁来自持刀及持枪人员。在造成人员伤亡前检测到危险,并提前预警具有重大意义。目标检测技术的发展使监控视频和静止帧中自动识别威胁成为可能,在学校、车站和医院等公共场合中发挥着预防犯罪的重要作用[1]。近年来,随着深度学习技术的发展,图像分类、目标检测以及图像分割等技术也得到了快速的发展[2-4]。图像分类任务就是给定一个图像,然后正确给出该图像所属的类别,图像分类更适用于图像中待分类的是单一物体的情况。目标检测任务就是定位某一类语义对象(如人、建筑物或汽车)的实例,不仅适用于单目标,也适用于多目标的定位。图像分割任务就是将数字图像细分为多个图像子区域(像素的集合,也被称作超像素)的过程。公共场所由于包含多个对象,目标检测技术更适合检测刀具、手枪等危险物品。
目前常被人们使用的目标检测技术分为2种类型:1种是one-stage方法,不需要先选定候选区域并对其分类,而是直接产生物体的类别概率和位置坐标值,经过单次检测就可以直接得到检测结果,检测速度更快;另1种是two-stage方法,顾名思义需要2步进行检测,第1步先选定候选区域,第2步在候选区域的基础上利用网络对其进行分类,检测精度更高。常见的one-stage代表算法有YOLO系列和SSD[5]系列,而two-stage代表算法有RCNN、Faster-RCNN[6]。YOLO算法首先由Redmon等[7]在2016年提出,在2018年更新到YOLOv3[8]后原作者停止更新YOLO系列,后由Bochkovskiy[9]在2020年提出YOLOv4算法,不久Ultralytics公司又提出了YOLOv5算法。
由于YOLOv5算法更快,鉴于在公共场合检测刀具和手枪威胁的实时性要求,本文采用YOLOv5算法作为基准模型进行目标检测。虽然YOLOv5检测速度更快、更具有实时性,但相应的检测精度会有所下降,为了进一步提高YOLOv5算法的检测精度以及检测速度,首先引入了多头自我注意力机制,在提升检测精度的同时,降低了模型的参数量,提高了检测的速度;然后将GIoU损失函数替换成EIoU损失函数,提升了检测的精度;最后增加了常见干扰选项使模型能够有效识别过滤干扰,增强了模型的实用性。
1 YOLOv5算法
YOLOv5算法由于其模块化的设计方案,在改变自身网络宽度和深度的基础上又发布了4个模型,分别为YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,这4个模型精度越来越高,同时模型大小也在增加,为满足本文对检测速度的需求,选择YOLOv5s作为基准模型,在v5.0版本的基础上对YOLOv5s网络结构进行更改[10]。YOLOv5可以看成由输入端、backbone、neck、prediction等4部分组成。
输入端采用了Mosaic数据增强,通过随机缩放、随机裁剪、随机排布的方式将4张图片进行拼接。经过Mosaic数据增强后可以起到丰富数据集的作用,也增加了小目标数量,经过数据增强后的数据集如图1所示。

图1 Mosaic数据增强Fig.1 Mosaic data enhancement
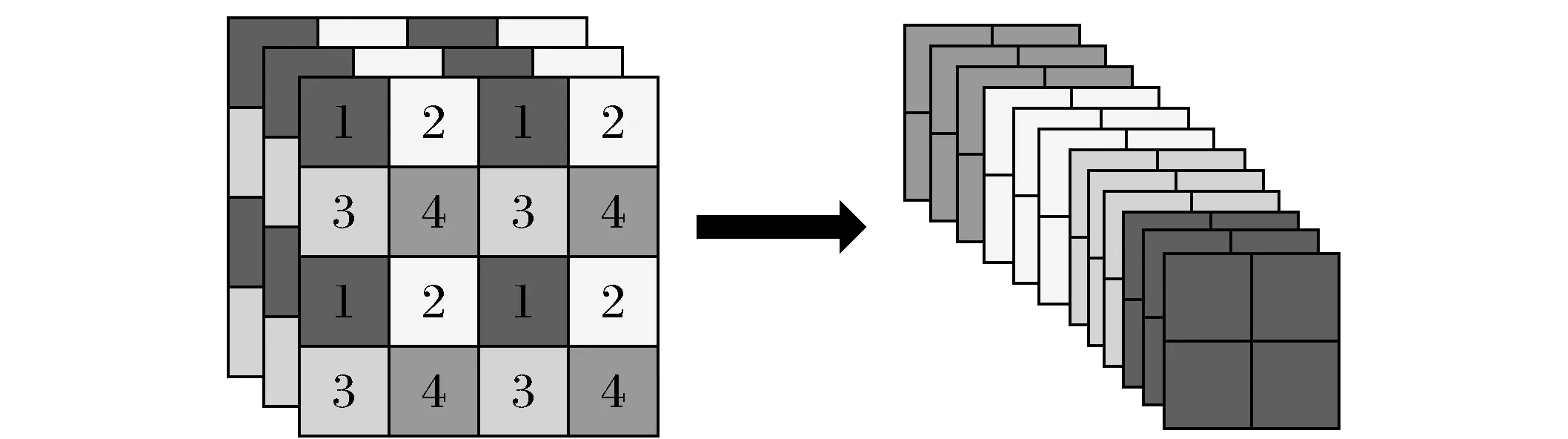
图2 切片操作Fig.2 Slice operation
backbone中采用Focus结构代替YOLOv3中backbone的前3层,起到了下采样的作用,其中最重要的是切片操作,如图2所示,以YOLOv5s的网络结构为例子,原始尺寸640×640、通道为3的图片,经过切片操作以后变成320×320×12的特征图,再经过3×3的卷积操作输出通道为32,最终变成320×320×32的特征图,在尽量减少影响mAP的基础上,起到了减少layers(层数)、减少parameters(参数量)、减少FLOPs(计算量)、减少CUDA内存占用以及提高前向传播和后向传播速度的作用。
在v5.0版本中,由原先的BottleneckCSP模块改进成C3模块,BottleneckCSP模块参照CSPnet[11]结构设计,YOLOv5的BottleneckCSP模块根据有无残差结构又分为2种形式,YOLOv5将无参差结构的BottleneckCSP模块也应用到了Neck部分中加强网络特征融合的能力,而C3模块和BottleneckCSP模块类似,区别就是减少了1个卷积模块,减少卷积模块后的C3模块参数量减少,整体网络模型变小,推理速度也变得更快,相应的精度却没有大幅下降。
YOLOv5在backbone部分的C3模块后加入了SPP模块,SPP模块参照SPP-Net[12]中的SPP模块由4个并行分支组成,这4个分支分别是内核大小为1×1、5×5、9×9、13×13的最大池化层,再将不同尺度的特征图进行Concat操作,SPP模块能够极大地增加感受野,分离出最显著的上下文特征,丰富了特征图的表达能力,有利于待检测图像中目标大小差异较大的情况,使得检测精度有所提升。
neck部分借鉴PANet[13]网络,在FPN[14]的基础上添加了自下而上(bottom-up)的增强路径,用于缩短信息路径,利用低层特征中存储的精确定位信号,提升特征金字塔架构,即FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,从不同的主干层对不同的检测层进行参数聚合,进一步提高特征提取的能力。
prediction部分回归损失函数采用GIoU Loss[15],GIoU Loss是在IoU Loss[16]的基础上进行改进的损失函数,改进后在IoU Loss的基础上,解决了边界框不重合时的问题,公式如下:
式中:I为IoU值;G为GIoU值;LIoU为IoU Loss函数;LGIoU为GIoU Loss函数;A为目标框和预测框的交集;B为目标框和预测框的并集;C为目标框和预测框的最小外接矩形。
2 YOLOv5算法的改进
2.1 Bottleneck Transformer
BoTNet[17]由UC Berkeley和谷歌在2021年初提出,它可以被看作一个简单又高效的backbone,可以将它应用于图像分类、目标检测以及实例分割等计算机视觉领域带来性能提升。虽然卷积运算可以有效地捕获局部信息,但视觉任务(如目标检测、实例分割、关键点检测)需要建模长距离依赖关系,因此基于卷积的网络需要堆叠多层。大量卷积网络的堆叠可以提高这些backbone的效果,也相应地增加了更多的参数量,与此同时网络模型也变得越来越庞大。
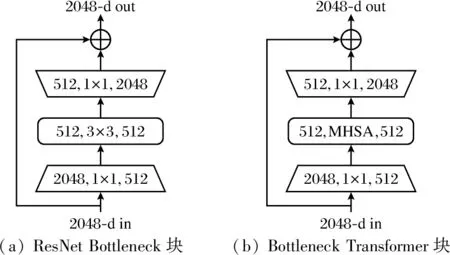
图3 ResNet Bottleneck块和Bottleneck Transformer块
建模全局依赖关系可能是一个更好的解决方法,让模型学会专注,把注意力集中在重要的信息上而忽视不重要的信息是计算机视觉中注意力机制的基本思想。大多数深度学习与注意力机制结合的研究工作是使用掩码(mask)来形成注意力机制,通过另一层新的权重是掩码的原理所在,将图片数据中关键的特征标识出来,通过学习训练,让深度神经网络学到每1张新图片中需要关注的区域,也就形成了注意力。self-attention(自我注意力)机制[18]为获取全局信息带来了新的思路,使用自我注意力机制会使模型的参数降低,避免了卷积神经网络参数堆叠造成的模型臃肿现象,自我注意力机制在减少参数量的基础上也会增加一定的精度,在机器视觉领域中使用自我注意力的一种简单方法是用Transformer[18]中提出的多头自我注意(MHSA)层替换空间卷积层。BoTNet就是在ResNet[19]基础上引入self-attention机制,用multi-head self-attention(MHSA,多头自注意力)替换掉ResNet中最后一个stage(C5)中3个Bottleneck的3×3 卷积。ResNet Bottleneck块和Bottleneck Transformer块的区别如图3所示。
由于目标检测任务输入图片较大,这使得传统的self-attention对计算机的内存以及GPU性能要求较高,为解决这些问题,BoTNet采用与卷积结合的方式,先由卷积提取有效的局部特征降低分辨率,再由全局(all2all)self-attention去处理和聚合特征图中的信息。与传统的Transformer不同,在归一化方面,BoT采用批量归一化而Transformer采用层归一化,在FFN块,ResNet结构允许BoT块使用3个非线性而Transformer只能用1个,BoTNet使用SGD而Transformer使用Adam优化器。
由于注意力不仅考虑了内容信息,还考虑了不同位置特征之间的相对距离,为了更好地将对象之间的信息与位置感知关联起来,BoT中的MHSA采用相对位置编码。
文献[17]由于引入了Transformer中的多头自注意力机制,将ResNet Bottleneck块改进成了Bottleneck Transformer块,使得ResNet得到了性能上的提升进而形成了BoTNet。这种性能提升可以应用到backbone中,提升检测的精度同时减少参数的数量。所以本文将Bottleneck Transformer块引入到YOLOv5的backbone中,在原有的C3模块基础上用Bottleneck Transformer块替换掉原来的Bottleneck块改进成BTRC3模块。考虑到自我注意力对计算机内存以及GPU性能的要求,BTRC3模块如果替换掉所有的C3模块则会带来巨大的时间消耗,故只替换掉backbone中特征图分辨率最低的一层C3,也就是替换掉最后一层C3,替换后的网络模型改善了精度也减少了参数量。本文改进后的YOLOv5的网络整体结构如表1所示。
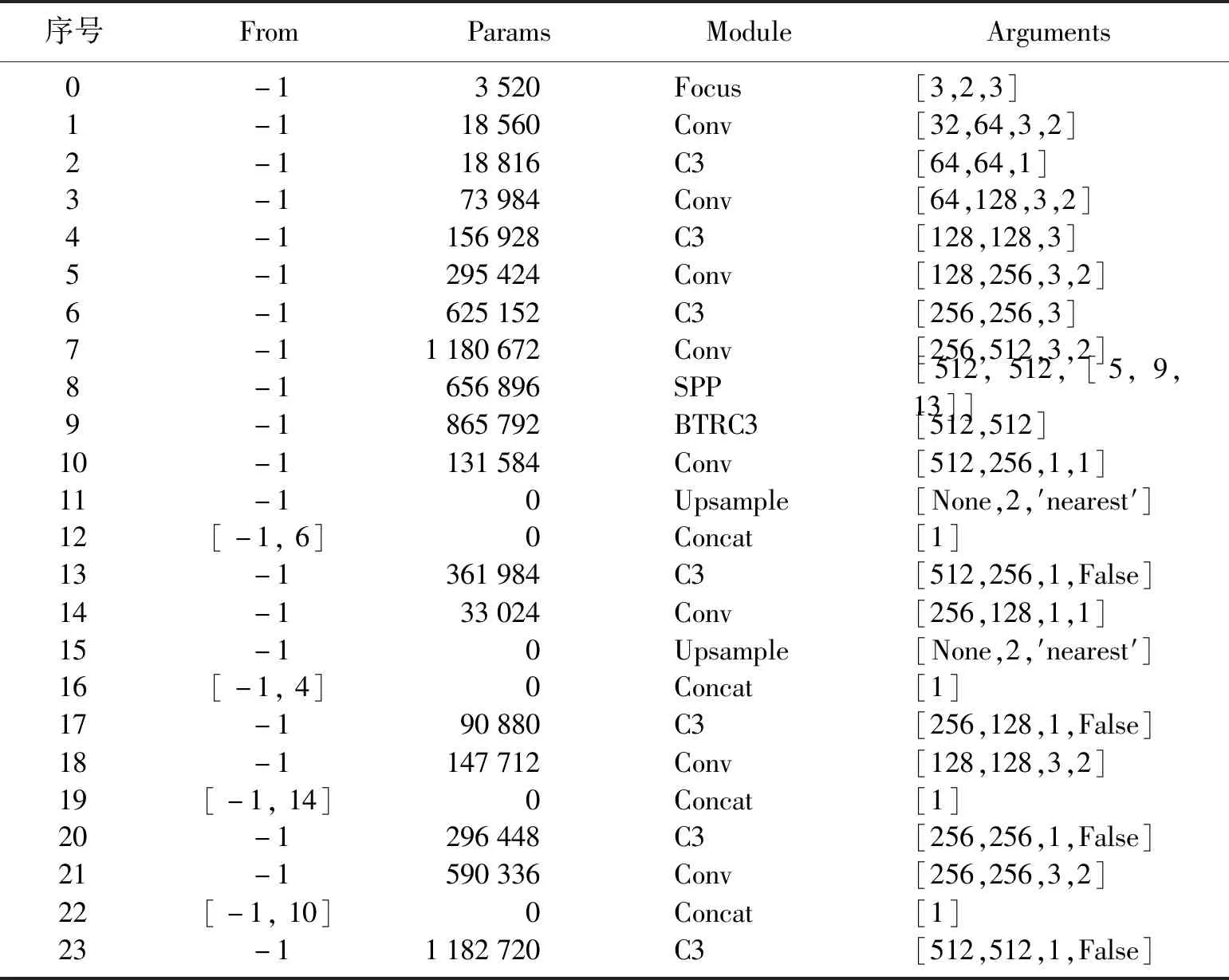
表1 改进的YOLOv5网络整体结构Table 1 Overall structure of improved YOLOv5 network
表1中From列的-1指输入来自上一层输出,Params列代表参数量,Module为模块名称,Arguments列的值分别代表该模块的输入通道数、输出通道数、卷积核大小和步长信息。
2.2 EIoU Loss
原始的YOLOv5使用GIoU Loss,GIoU Loss使用最小外接矩形的方法既可以计算非重叠区域的比例,又可以计算重叠区域的面积,能够更好地反应预测框和目标框的远近距离和重合程度。但GIoU Loss也存在一些问题,例如当预测框在目标框内部时,计算得到的GIoU等于IoU值,使得GIoU Loss退化成了IoU Loss,这时候GIoU Loss就不能很好地计算相对位置之间的关系,当预测框在水平或者在垂直方向时就会变得收敛速度慢,优化也比较困难。针对GIoU Loss出现的问题,又提出了DIoU Loss[20],DIoU Loss引入了目标框与预测框2个中心点的欧氏距离以及最小外接矩形框的对角线距离,解决了预测框在目标框内部时退化成IoU Loss等问题,收敛速度变快。DIoU Loss公式如下:
式中:D为DIoU值;LDIoU为DIoU Loss函数;ρ2代表求2个点的欧氏距离;b和bgt分别代表目标框和预测框中心点坐标;d为目标框与预测框2中心点的欧氏距离,c为最小外接矩形框的对角线距离。DIoU Loss虽然考虑了重叠面积和中心点距离几何因素对目标回归框损失函数的影响,但没有考虑到宽高比,于是当预测框和目标框中心点的距离相同、中心点的位置一样时,DIoU Loss的值就等于GIoU Loss和IoU Loss的值,为解决这种问题,文献[20]在此基础上又提出了CIoU Loss。CIoU Loss在DIoU Loss基础上,引入了一个影响因子,在考虑到重叠面积和中心点距离对损失函数影响的基础上,也同时照顾到了预测框和目标框的宽高比对损失函数的影响。CIoU Loss公式如下:
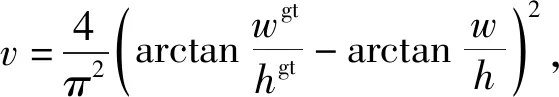
式中:LEIoU为EIoU Loss函数;Cw和Ch分别代表目标框和预测框的最小外接矩形的宽度和高度。由于EIoU Loss可以带来性能提升,因此本文将EIoU Loss作为YOLOv5模型的损失函数。
3 实验及结果分析
3.1 数据集
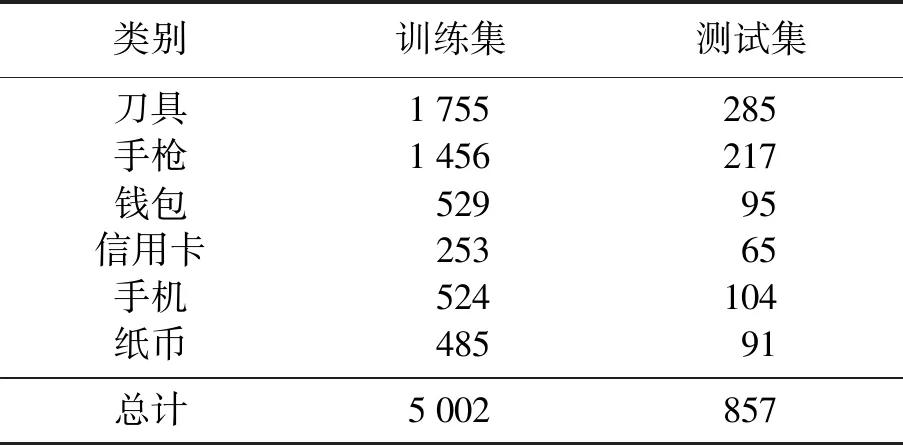
表2 数据集各部分数量Table 2 Number of each part of dataset 单位:张
本次实验使用的数据集在网上收集,包括手枪、刀具、钱包、信用卡、手机和纸币等6类物品,除手枪、刀具外的其余4类作为干扰选项。数据集共5 859张图像,其中5 002张作为训练数据集,857张作为测试集,使用Colabeler工具对图像进行标注,标注后的数据集格式为pascal-voc格式,由于YOLOv5需要使用YOLO格式的txt文件,则需要对pascal-voc格式的数据集标签进行转换成txt文件,转换后txt文件包含的内容为(id,x,y,w,h),其中id为标注框的类别,采用整数表示,x、y代表标注框中心点的坐标,w、h代表标注框的宽度和高度。数据集部分图像如图4所示,数据集各部分数量划分如表2所示。

图4 部分数据集图像Fig.4 Images of partial dataset
3.2 实验环境及参数设置
本次实验的机器操作系统是Ubuntu 18.04,CPU型号为Intel (R) Xeon (R) CPU E5-2678 v3 @ 2.50GHz,内存大小为64GB,GPU型号为NVIDIA GeForce RTX 2080 Ti,显卡内存大小为11GB,深度学习框架选择Pytorch版本号为1.7.1,并使用cuda11.0,cuDNN8.0为GPU训练加速。
本次实验将图片输入大小设置成640×640像素,由于数据训练受到GPU显存大小的影响,经过多次训练观察bachsize大小对GPU内存利用率的影响,选择性能释放最合理时的batchsize大小,故将batchsize设置成24,epoch设置成100,在训练过程中,选择合适的锚框可以加速边界框的回归,在锚框选择上采用YOLOv5中自适应锚框的方式选择合适的锚框,对数据集中标注的位置信息计算相对于默认锚框的best possible recall(BPR,最佳召回率),当BPR大于或等于0.98,则采用YOLOv5中默认的锚框大小;如果BPR小于0.98,则需要利用kmeans算法和遗传学习算法重新计算符合此数据集的锚框。由于本次实验的BPR为1,所以使用YOLOv5中默认的锚框大小,[10,13,16,30,33,23]、[30,61,62,45,59,119]和[116,90,156,198,373,326]。
3.3 评价标准
采用mAP@0.5、mAP@0.5∶0.95、Recall(召回率)、Precision(准确率)作为本次实验的评价标准,mAP@0.5是指IoU设置成0.5时的平均AP值(AP),mAP@0.5∶0.95代表在不同IoU阈值(从0.50到0.95,步长0.05)上的平均AP。TP代表真阳性即样本的真实类别是正例,并且模型预测的结果也是正例;TN代表真阴性即样本的真实类别是负例,并且模型将其预测成为负例;FP代表假阳性即样本的真实类别是负例,但是模型将其预测成为正例;FN代表假阴性即样本的真实类别是正例,但是模型将其预测成为负例。Precision表示被分为正例的示例中实际为正例的比例,Recall是覆盖面的度量表示有多少个正例被分为正例,AP为P-R曲线面积。具体公式如下:
3.4 消融实验
通过采用消融实验的方式来证明修改YOLOv5s网络所带来的性能变化,首先是测试原始的各项性能,紧接着测试修改backbone中的C3模块为BTRC3带来的性能变化,最后在第2步的基础上将GIoU Loss修改成EIoU Loss来进行性能测试。为方便起见本文将第2种网络称为YOLOv5s-BTRC3,将第3种网络称为YOLOv5s-BTRC3-EIoU。各网络的训练过程及结果用曲线的方式进行比较,分别用橙色、蓝色和红色表示YOLOv5s、YOLOv5s-BTRC3和YOLOv5s-BTRC3-EIoU,具体结果如图5所示(见封2)。
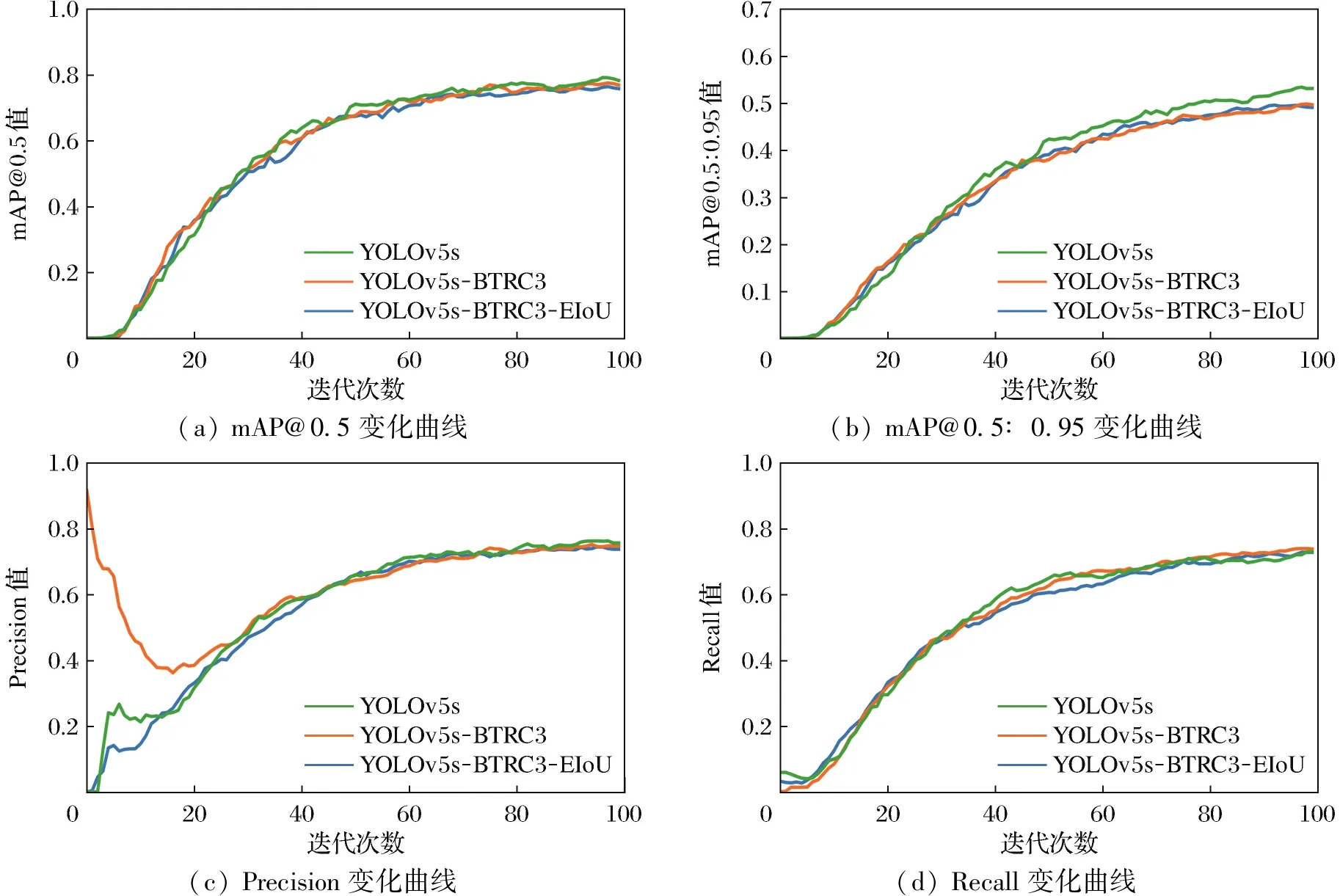
图5 各模型的训练过程Fig.5 Training process of each model
将backbone中的最后1个C3模块修改为BTRC3模块以后,由于Bottleneck Transformer的独特性,在替换后参数量减少,训练时间也相应地变短了,由表3可以看出,所有类的mAP@0.5由75.4%提高到76.3%,mAP@0.5∶0.95由49.0%提高到49.4%,刀具和手枪的mAP@0.5和mAP@0.5∶0.95均有部分提升。

表3 不同模型性能对比Table 3 Performance comparison of different models
将GIoU Loss修改成EIoU Loss以后,可以由表3看出,所有类的mAP@0.5由76.3%提高到77.5%,增加了1.2%,mAP@0.5∶0.95也由49.4%提高到53.2%,提高了0.8%,刀具类的mAP@0.5提高了1.4%,手枪类的mAP@0.5也达到了90%以上,通过表中数据可以充分证明改进后的YOLOv5s网络结构带来了显著的性能提升,可以有效检测刀具和手枪,部分检测结果如图6所示。

图6 部分检测结果Fig.6 Partial test results
3.5 主流目标检测算法对比
为了更好地证明经过本文修改后网络模型的有效性,将修改后的网络模型与Faster R-CNN、SSD、RetinaNet等主流目标检测网络进行对比实验,在实验环境相同的情况下使用相同的数据集进行训练和测试。采用mAP@0.5、mAP@0.5∶0.95、FPS(帧率)等评价标准对训练以及测试结果进行定量分析。
通过表4对比结果可以得出在本文所用数据集上,修改后的YOLOv5s网络模型在目标检测的准确度上优于主流的目标检测网络,在同等的测试环境下修改后的YOLOv5s网络模型推理时间更短、FPS更高,目标检测速度上的表现优于主流的目标检测网络。
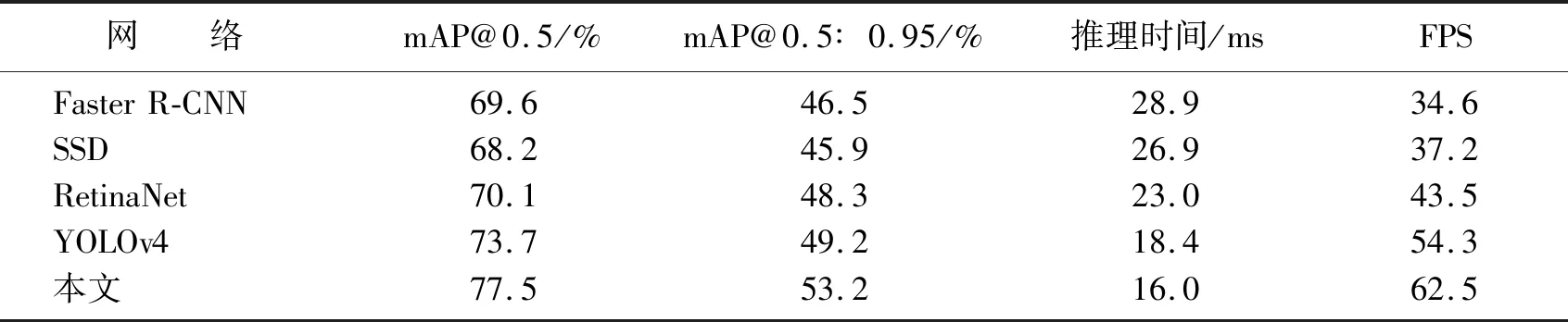
表4 主流目标检测网络测试结果对比Table 4 Comparison of mainstream object detection networks
4 结 论
本文通过参照Bottleneck Transformer将多头自注意力机制引入到YOLOv5的backbone中,在原有的C3模块基础上用Bottleneck Transforme块替换掉原来的Bottleneck块改进成BTRC3模块,在减少参数量的基础上提高了检测精度和检测速度。将GIoU损失函数改进成EIoU损失函数后进一步带来了检测精度的提升。各种实验结果证明了2种修改方式的有效性,修改后的模型推理速度更快,模型精度也得到了提升,在实验环境下可以调用摄像头实时检测,理论上可以在一定程度上减轻人工安检的压力,提高公共场所的安全性。为了更好地更快地应用到公共场所领域,在今后的工作中打算加入更多的危险物品作为数据集,在进一步减少网络参数量和提高检测速度的基础上增加检测精度,尝试将模型部署到云服务器供网络摄像头调用。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
电子制作(2019年11期)2019-07-04
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
