
基于智能技术的图书馆人机采分编协同探究
2022-12-06 06:31:46钱晶
新世纪图书馆 2022年10期
钱 晶
0 引言
近几年,在人工智能、云计算、大数据、虚拟现实、5G等新兴技术的驱动下,有关智能导航、智能盘点、智能分拣、自助借还、参考咨询、读者分析等智能化服务已经逐步应用于图书馆业务工作中,这些智能化服务不仅提高了读者的体验满意度,而且使得图书馆在采分编工作中节省了大量人力,为更好地服务于读者提供了充分条件。人工智能作为目前全球的前沿技术之一,一旦与图书馆相结合将对未来图书馆的发展带来深刻性影响[1]。王世伟认为以智能技术为前提,通过大数据分析与应用,可以达到促进图书馆业务发展的目的[2]。基于此,笔者认为在应用人工智能等技术的基础上,图书馆将智能技术与传统采分编工作进行深度融合,将帮助馆员更好地处理相关采分编业务工作,成为图书馆采分编业务的发展趋向。本着“人机采分编协同”来实现一种人类与机器协同完成图书馆采分编业务的状态,本文基于图书馆采分编工作模式,建构了人机协同框架,并就需要注意的问题探讨了实现人机采分编协同的策略,以期提高图书馆人机采分编协同实践。
1 图书馆采分编业务概况及现状
采分编工作是图书馆文献资源建设的传统业务,也是业务性最强、复杂度最高、难度最大的一项业务工作,是图书馆提供文献保障和读者服务的基础[3]。图书馆的日常采访工作主要是采访人员依据本馆采访经费预算,结合馆藏特色,按照采访条例,期采(根据中标书商提供的书目清单采访)或现采(现场采访)图书。但伴随图书出版量剧增、图书质量良莠不齐的情况,期采或现采的图书存在学科比例失衡、低水平重复出版、同质化出版严重的问题,主要原因在于现有的采访方式经常导致书目信息的滞后性和选书范围的局限性。采访人员通常凭借经验选购图书,缺乏与读者的互动,难以把握读者需求,采购入馆的图书与读者期望存在一定差距。图书馆每年购进大量新书,而读者却经常找不到自己所需的图书,有些书甚至出现零借阅的情况。此外,一本图书从采访到阅览室上架供读者借阅,共要完成十余道工序,周期长,导致采购的新书到上架时变成了“旧书”,使很多读者无法借阅一些当时热门的图书,难以最大限度地满足读者阅读需求。
图书馆对于到馆新书主要是分编人员依据《中国图书馆分类法》和《中国分类主题词表》对图书进行分类标引,依据《新版中国机读目录格式使用手册》和《中国文献编目规则》对图书进行客观著录,从而形成书目数据,为读者提供图书检索服务。目前在分编工作流程中,图书馆的分编工作主要有三种形式:(1)在全国联合编目的背景下,图书馆多采用下载套用联编中心书目数据的方式;(2)没有下载套用到数据的,需要人工对这部分图书进行分编;(3)部分图书馆采用分编业务外包的方式。现阶段,许多图书馆采用三种形式相结合的方式进行图书分编。在这一整套的分编流程中,工作人员虽然经验丰富,但长年累月反复从事同一工作内容,难免会疲惫、厌倦和懈怠,容易出现工作效率低、差错率高等现象,抑制了工作人员的积极性和创造性;对于外包分编的图书,外包人员知识水平欠缺、流动性大,也会导致分编质量低,加大了馆员对数据审校的难度,难以提高工作效率。因此,针对目前图书馆的采分编工作现状,笔者从提高采分编工作的效率和质量的角度来构建人机采分编协同模式,以期实现采分编领域的智能化发展,提升图书馆资源建设和服务的水平。
2 人机采分编协同工作流程构建
将图像识别、大数据、云计算、物联网、人工智能等新兴技术应用到图书馆采分编业务中,利用机器翻译、自然语言处理等技术[4],快速采集、整理各类信息,精准高效匹配计算,可以实现采分编智能化操作,具体分为人机采访协同、人机分类协同和人机编目协同三部分工作流程。
2.1 人机采访协同工作流程
将人工控制与智能采访二者相结合的人机采访协同工作流程,既可以保障本馆文献资源建设特色,保证馆藏结构的系统性、科学性和合理性,同时又能够满足读者个性化需求,不仅可以提升采访效率,更能调动广大读者的积极性,吸引更多读者参与到图书采访中来,真正体现图书馆“以人为本”的服务理念,提高馆藏文献的利用率,解决馆藏资源和读者需求契合度不高的问题。在采访工作应用智能技术方面,图书馆可通过决策树、归纳逻辑程序设计、聚类分析等运算方法,利用人工智能的神经网络技术,分析图书荐购信息、读者偏好和价格等数据,建立图书订购决策模型,实现人工智能在图书采访方面的应用[5]73。
首先,采访人员可以利用用户画像、数据挖掘、云计算等技术,从本馆读者信息数据库中读者的性别、年龄、学历、职业等方面入手,通过读者的检索痕迹和阅读轨迹,实时分析解读其阅读行为和借阅情况,推测阅读偏好,评估阅读危机,获取读者个性化信息[6]。采访人员汇集这些信息并分析整合,可以快速、全面地掌握读者需求,筛选出读者满意的书目。
其次,利用VR技术[7]将书商提供的书单转换成VR虚拟书目,构建虚拟书架,供读者翻阅。每条书目都提供书名、著者、出版社、目录、前言、内容提要等信息,并配有封面、封底图片,还可以提供音频、视频等媒体资料,读者可以身临其境地像翻阅纸质书目一样随意选择感兴趣的图书,对目标书目勾选,还可以进行留言、评注、添加标签等操作。这种由读者参与采访的“VR+采访”方式,可以解决传统采访模式书目信息不直观、读者参与度低的问题,有效激发读者的热情,吸引更多读者参与到图书采访中来。
最后,采访人员将读者个性化信息与书商提供的书单相结合,利用数学模型和人工智能算法进行图书采访量化,通过深度分析,挖掘读者检索关键词,以学科读者面、学科文献利用率、学科适藏文献出版状况为影响因子,采用量化分析方法,在遵守本馆采选条例的基础上,对价格、复本量等进行综合评价,构建出一种准确、实时的智能采访模型[5]72,以便科学合理地制定采购书单。
2.2 人机分类协同工作流程
图书智能分类,即智能描述图书主题内容,让智能系统“看到”图书的内涵,对其进行揭示,并通过规范主题词和分类号呈现出来。智能分类以《中国分类主题词表》与《中国图书馆分类法》为基础,建立二者内部关联所形成的自然语言、主题语言、分类语言知识库,形成相互间的映射关系,为文本抽词、关键词提取、主题词关联、分类号匹配等一系列标引分类工作提供所需资源[8]。
目前,国内已有一些比较成熟的软件和方法用于文献的分词、特征词提取、快速聚类等,如:NLPIR分词系统,是一整套对原始文本集进行处理和加工的软件[9];基于卷积神经网络的特征词提取方法,能够准确提取到图书的特征词;LDA概率模型,是一个三层贝叶斯概率模型,它可以从粗的粒度层面实现特征词提取及快速聚类[10]103-105。另外,侯汉清教授团队研发的ST-index系统是基于中图法的自动分类系统,系统内置《中国分类主题词表》和《汉语主题词表》等,采用语义相似和字面相似相结合的匹配算法,获取主题词和分类号[11];上海交通大学研制的自动分类系统主要用于外文书刊,通过扫描图书抽取关键词,提取《美国国会图书馆分类法》的分类号,采用映射方法对应《中国图书馆分类法》的分类号[12]。《中国分类主题词表》Web版与《中国图书馆分类法》Web版,也为智能分类提供了理论基础。由此,在人机分类协同工作流程构建过程中,我们需要做好以下几个方面。
首先,将《中国分类主题词表》与《中国图书馆分类法》导入分类系统数据库中,建立二者的双向对应,即“主题词—分类号”对应与“分类号—主题词”对应。然后,运用机器人自动翻页、扫描、智能图像识别技术对图书的题名页、作者关键词、目录、前言、摘要、章节、段落、全文文本信息等可以揭示图书内涵的关键内容进行扫描,获取图片形式的PDF文件,通过OCR识别技术,再将文字、数字信息等转换为文本信息,完成图片到文本的自动转换。
其次,通过智能系统利用自然语言处理技术对图书相关内容信息进一步识别处理和数据挖掘,进行分词和降噪等一系列处理,从中抽取能够反映图书内容的特征词,其中应着重对题名和摘要进行特征词的提取。再对这些特征词进行词频统计,生成共现矩阵,分析共现关系,实现关键词的快速聚类[10]107-108,从而挖掘关键词集。
最后,借助“关键词—主题词”对应表进行映射,自动提取和计算,找到关键词相对应的主题词,再利用可视化工具ECharts中的散点图模块,生成可视化表示。在可视化图像中,观察各个主题词的空间分布情况,展示出其重要程度,揭示各主题词之间的相关性与权重[13],得到准确的主题词结果,自动录入书目数据的主题分析字段。最终,可通过“主题词—分类号”对应关系得到相匹配的分类号,自动录入分类法字段,完成智能分类操作。
2.3 人机编目协同工作流程
图书智能编目,即智能描述图书物理特征,让智能系统“看到”图书的物理信息,并将这些信息分别匹配到相应字段中,实现自动编目。20世纪70年代,OCLC的Automated Title Page Cataloguing系统应用OCR识别技术,对图书题名页进行识别,再通过编目规则进行编目,生成书目数据,正确率可达到89%;1984年,英国埃克塞特大学的Davies和James采用Prolog语言研制出第一个编目专家系统;随后,瑞典Linkkoping大学的Hjerppe研制了以选取款目检索点核心的Esscape系统;1986年,美国威斯康星大学开发了MITI/MARC编目专家系统[14]。目前,全国图书馆联合编目中心(OLCC)的数据共建共享奠定了智能编目的基础,可通过其ALEPH系统中的责任者规范库实现对图书的个人责任者和团体责任者的识别,并实现规范统一著录。
首先,利用工业机器人对图书进行翻页、测量尺寸等操作,多个CCD工业相机[15]73-74实时扫描图书的封面、题名页、版权页、封底等所有可读标识,智能收集题名、责任者、版本、语种、出版项、丛书、载体形态等图书信息。
其次,基于OCR识别技术,对获取的数据进行整合处理,通过计算机的自动数据提取、智能计算、自我分析、对比数据库已有数据等技术,将采集到的信息转换成计算机可识别的语义数据。
最后,由系统按照编目标准与相关规范,自动将语义数据导入各个对应的编目字段中,如题名与责任说明字段、版本说明字段、出版发行字段、载体形态项字段、丛编字段等,并同时做好子字段、指示符等部分的著录。最终,形成某一图书的完整且具有检索意义的书目数据,完成图书的智能编目流程。
3 人机采分编协同过程中需要注意的问题
图书馆采分编业务在人机协同过程中,也不能只依赖智能系统而忽视人员的主观能动作用,在采分编工作中需要时刻注意把握和解决以下一些问题。
3.1 在智能采访中,要以合理馆藏结构体系为依据不断调整采访书目
在智能采访过程中,必须要以采访人员制定合理的馆藏结构体系为基础,采访人员应掌握采购决策权,客观认识读者的个性化阅读需求,将其用在推荐图书上而不是决定采购上。采访人员可以先融合用户借阅信息,分析趋势与瓶颈,借此结合书单信息评估每一本图书的采购需求,然后按照本馆采选原则、购书经费比例,结合馆藏特色,科学配置图书采购资源,从而合理控制读者自主采购权限。此外,图书采购入馆供读者借阅后,采访人员还应对图书的借阅情况进行跟踪调查,收集读者反馈信息,及时了解图书利用率,根据读者评价调整采购内容,加大优质图书供给量,提高文献采访质量,实现图书采购资源的合理配置,充分发挥馆藏资源的作用。
3.2 在智能分类中,要注重系统更新并重视书目数据质量控制
在图书的智能分类工作中,为了保证图书相关信息在转换过程中正确匹配,需及时更新升级数据库。《中国图书馆分类法》Web版与《中国分类主题词表》Web版会实时修订更新,增、改、删一些分类号和主题词的相关内容。如在《中国图书馆分类法》Web版中新增了“TN929.538 第五代移动通信系统(5G)”类目;将“K555.6”对应类名由原来的“马其顿”修改为“北马其顿”;在《中国分类主题词表》Web版中将“磁场”的代项“磁力线重联”“磁场重联”删除等。因此,在前期导入数据库后,应利用物联网技术手段,设置一种自动更新机制,与二者网站相关联,实现主题词和分类号的实时更新。
同时也需重视人工干预和审校。分类法中设置了类目复分、仿分和冒号组配等,有些复杂类目甚至会涉及多层次复分、仿分,智能分类系统无法完成这些操作时需要工作人员进行干预,将这部分图书抽调出来进行人工分类标引。此外,经过智能分类的图书,工作人员也要注意做好数据的审校处理,审核主题词是否完全匹配图书本体内容,分类号是否完全匹配主题词和图书本体内容。对于不合格的数据,审校人员应进行手工修改,使之成为合格的书目数据。人机分类协同具体流程如图1所示:
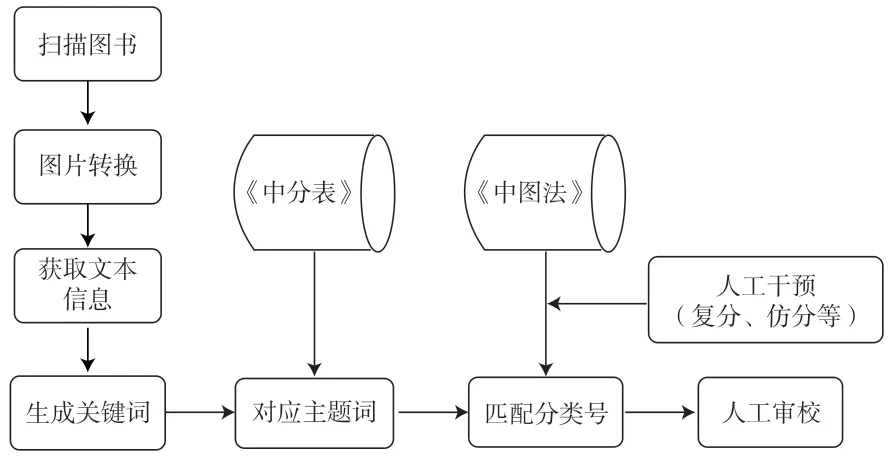
图1 人机分类协同工作流程
3.3 在智能编目中,要注重人工检查和修改数据
在智能编目系统的助力下,图书编目工作的速度和准确率虽然有所提高,规范化与智能化也得以保障,但在编目方面还有很多问题需要工作人员根据具体情况,凭借专业知识和工作经验,仔细研究,认真、反复确认进行处理,在图书实体中查找线索,才能作出正确判断,最终完成编目工作。如在下载套用联编数据时,对于同一ISBN对应多条数据的现象,若智能系统无法识别、分辨出该图书相应的正确数据,则应由人工完成数据确认工作并下载套用;此外,对于编目过程中经常会出现的跟号现象、集中著录还是分散著录的现象等,如果由智能技术直接生成索书号,而系统没有“考虑”跟号或集中、分散著录,就会造成书目数据和索书号的错误、摆架位置的混乱,给读者查找图书带来困难。
因此,图书编目在智能系统完成一条书目数据后,必须经过人工检查和修改,审校人员参照图书实体,对书目数据各个字段著录的准确度和完整度等进行审核,做好数据质量控制。人机编目协同具体流程如图2所示。
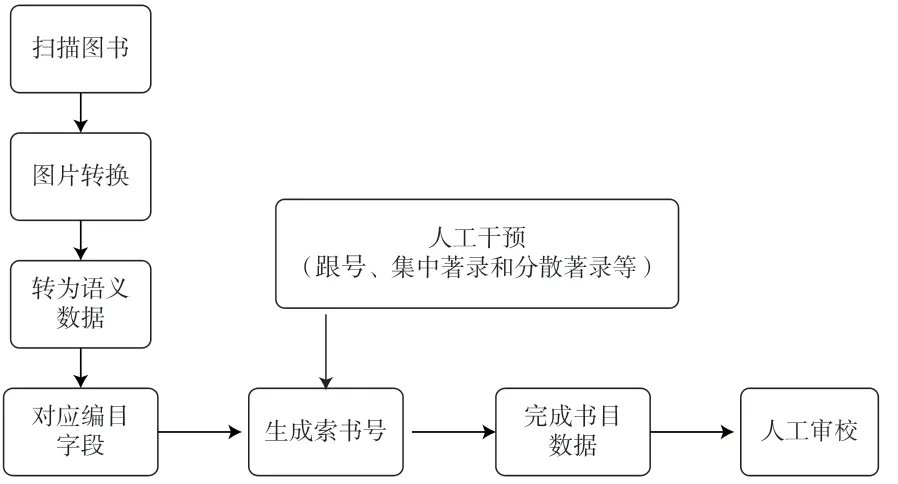
图2 人机编目协同工作流程
4 提升人机采分编协同的措施与策略
在网络环境下,面对信息时代的发展和要求,技术驱动、以人为本的人机协同,将成为未来图书馆采分编业务的常态。图书馆需要推动采分编工作在智能时代的健康、可持续发展[16]56。因此,在图书馆实现智能采分编系统的状态下,一定要做好人机采分编协同策略。
4.1 采分编人员应主动接受新兴技术,提升采分编的自动化和智能化水平
采分编人员在认识到智能技术可以提高采访效率、提升馆藏文献利用率、优化分编流程、确保数据质量等优势的基础上,客观认识自身知识储备的局限性,主动增强自我学习能力,学习先进的采分编智能技术,给采分编工作注入新鲜血液。同时,工作人员要发挥专业优势,将实践经验与系统设计相结合,将专业知识与智能技术相融合,做更有创造性的工作,如数据监控、规范控制、数据维护等[15]72,积累更强的业务能力,快速有效地应对业务方式与流程的更新,提升采分编的自动化和智能化水平,提高工作质量和效率。采分编人员还应时刻具备创新意识,主动钻研智能化采分编系统的功能和运行模式,尝试进行系统的开发设计,促进智能系统的准确、稳定、可用[17],积极转换角色,从书目数据的“制造者”转变成为“智造者”,从而具备更加专业、全面的决策能力。
4.2 发挥采分编人员主导作用,保障智能采分编的准确率
智能采分编系统来自于人类的设计,是人类智慧的产物,只有按照人类的算法、程序和要求执行,才能达到预期效果。人始终处于主导地位,发挥主导作用,承担着设计者、监管者、决策者和引导者的角色[16]60-61。因此,采分编人员在享受智能技术带来的便利与高效的同时,应清楚地认识到这些优势只有在人类充分的前期准备、中期干预、后期决策的基础上才能完美体现并发挥价值。在采访工作流程中,人工制定读者阅读特征和行为采集的规则和标准,人工设计和开发个性化精准服务,人工决策基于读者阅读需求的最终采购书单;在分类和编目工作流程中,人工设计分编流程和模式,人工干预处理复杂分编问题,人工审校书目数据、控制数据质量;在系统优化升级环节,人工通过实际操作作出评估并提出具体升级内容,指导机器深度学习,引导智能系统的发展方向。在智能技术的背景下,只有充分发挥人的主观能动性,调动其积极性和创新性,合理利用智能技术为采分编业务服务,才能真正实现智能化作业,推动传统采分编模式向智能模式转变。
4.3 加强机器深度学习,提高智能采分编的精准度
为了提高采分编智能化系统的效率,机器需要对系统内已有的数据进行大规模的反复学习和训练,不断优化人工智能算法,才能完善采分编能力。智能采分编系统的深度学习将更好地实现人工智能对采分编人员感知的模拟,并能够像采分编人员一样进行思考[18]。例如,命令智能采访系统不断学习馆藏数库中已有图书类型,通过计算与整理,分析出馆藏特色、采选规则(包括单价、复本量等)和读者需求,自动与备选采访数据进行匹配运算,经过筛选,保留符合条件的数据,最终生成最优化采购订单[19]。又如,命令智能分编系统大量学习馆藏数据库中已有书目数据,并由此产生序列实体之间语义关系和规则特征的模板,然后利用该模板进行机器预测[20]。通过反复训练分类和编目内容,提高识别、提取有效信息的能力,提高数据信息与字段之间精准对应的能力,提高筛选高频词的能力,提高关键词、主题词、分类号关联的能力。重点要对不同类型图书的分编数据和复杂情况的分编数据进行深度学习,促使智能分编系统模仿人类思维,获得近似人类大脑的综合分析能力,以解决智能分编过程中出现的各类问题。另外,加强机器深度学习,还需要通过对自动分编结果的审核与分析,发现错误集中的类型,对这部分图书重新收集实例、重点训练,完善智能分编能力。除此之外,还要注意数据的维护,不断更新学习数据,及时增补新数据,促使自主调整模型参数,保障智能分编结果的准确性。
4.4 深度融合智能技术的同时合理做好人机协同风险防控
人机采分编协同是人类智慧和机器智能之间平衡、融合的发展模式,是人类与智能技术之间的交流。在这样的智能系统中,虽然采分编工作效率和质量都有所提高,但也不可避免存在着不容忽视的风险。由于人类和机器分别具备不同性质的智能,任何一个环节出现二者对接的偏差或脱节,都有可能导致整个智能系统出现错误,甚至崩溃;智能技术收集读者信息、分析读者阅读习惯等,加大了私人信息公开化的风险;随着机器对人类行为越来越多的模仿和学习,以及深度学习效果的显现,机器逐渐呈现出一种“拟主体性”[21],这是否会冲击人类自身的价值,是否会影响人类智慧的发挥;人类过度依赖机器,将会导致自身实践能力的削弱;人类对机器过度干预与控制,将会阻碍智能技术的发展等。以上这些假设发生的现象提醒我们在智能系统实际运行过程中,要时刻做好风险防控,重视人类对规则和标准的制定,规范智能技术的操作,实时指导和监督智能机器的运行;在加强机器智能人性化发展的同时,注重人类思维和行为的严谨性,减少情绪和认知偏差带来的主观错误等。
猜你喜欢
青少年科技博览(中学版)(2022年6期)2022-08-31 09:04:00
南都周刊(2021年3期)2021-04-22 16:43:49
天一阁文丛(2020年0期)2020-11-05 08:28:36
戏曲研究(2017年3期)2018-01-23 02:51:01
海外星云(2016年7期)2016-12-01 04:17:50
太空探索(2016年5期)2016-07-12 15:17:58
西北工业大学学报(2015年1期)2015-02-22 00:29:19
西北工业大学学报(2015年1期)2015-02-22 00:29:19
沈阳医学院学报(2014年4期)2014-12-27 13:44:34
疑难病杂志(2014年12期)2014-04-16 05:19:35
