
保险丝线圈字符识别技术研究
2022-12-06 10:38:50欧阳家斌胡维平刘北北刘文扬
计算机工程与应用 2022年23期
欧阳家斌,胡维平,刘北北,2,刘文扬
1.广西师范大学 电子工程学院,广西 桂林 541000
2.中国科学院 自动化研究所 苏州研究院,江苏 苏州 215000
保险丝线圈字符是保险丝的身份证,线圈字符识别对区别其型号等有效信息有着非常重要的作用,传统识别线圈字符信息采用人眼读取,这样的操作不仅劳动强度大、效率低,随着工作时间的增长,工人们容易造成漏识别和错误识别,同时也无法满足流水线及自动化生产发展的需求[1],为了解决上述一些存在的问题,将机器视觉引入到线圈字符检测中。
目前常用于字符分割的方法有投影法、字符边缘检测分割法和基于聚类分析的字符分割法[2]。常同于字符识别的方法分为图像处理及机器学习两类。基于图像处理的识别主流方法有特征提取法[3]、模板匹配法[4]等,基于机器学习的主流方法有基于支持向量机(support vector machine,SVM)、基于多层感知机、基于误差方向传播(error back propagation,BP)神经网络[5]。其中对于前者方法原理简单,但容易受图像噪声的影响,鲁棒性差。后者方法识别效果好,泛化能力强,具有很高的鲁棒性。
文献[6]提出了一种CNN网络模型LeNet用于手写字符识别,对促进CNN在图像识别问题中的广泛应用做出重要贡献。文献[7]以SSD算法[8]为框架基础,使用多尺度图像输入进行端对端的训练,较好地解决了文字尺度识别问题,但这样的做法严重影响了模型的运行速度。文献[9]采用微分思想将Anchor的横向长度固定为16个像素点,并使用文本线将小宽度构造为文本行以此来克服预测框受长度剧烈变化的影响,但该网络对形变字体识别较差,且无法准确定位文本两端的位置。
文献[10]是Faster R-CNN的开山之作,由于该网络将字符生成了一个个候选区域再送入卷积网络中学习训练,使得计算量很大,在后续的分类和回归网络中,使用SVM分类器分别对二者进行训练,导致鲁棒性和时效性差。因此,在2015年,文献[11]在R-CNN网络的基础上提出了Fast RCNN网络,该网络可实现端到端进行训练,在训练的速度上和测试速度上较R-CNN分别快于9倍和213倍。Fast RCNN所采用Selective Search区域生成方法[12]的弊端显而易见,在特征提取耗时较大,因此这给Fast RCNN网络继续改进的机会,改进之后的网络称为Faster R-CNN[13],该网络更快更强,鲁棒性更高,对小物体的检测以及拥挤、遮挡等较难检测问题上提供了一个有效的解决方案。文献[14]创造性地使用Anchor-free完成一阶段检测任务,提出了YOLO v1网络,其思想是通过整张图作为输入,直接预测字符的类别与位置。2018年,Joseph等人继续推出了YOLO v3版本[15],该版本较之前的版本有着更精确的检测率和更为灵活的拓展空间。YOLO网络的实时性较好,但对目标相近的物体检测效果表现一般。
本文针对线圈字符的分割和识别问题,在字符分割上,使用投影法结合字符的先验知识给出阈值进行去除上下边框,再经过平滑滤波、闭运算去噪,在垂直投影中结合字符宽度解决黏连问题,从而达到切分属于同一字符块的目的,最后再对切分出来的字符进行膨胀处理,使字符清晰易识别。这样对于后续的用于字符识别操作做了很好的前处理,较大地提高字符的识别率。在字符识别中,考虑到字符背景噪声较多,部分字符结构受影响以及有字符黏连相近和压缩形变情况,因此选择改进的Faste R-CNN网络进行定位作识别,使用ResNet101[16]代替原有的VGG16基网络,使用K-means聚类算法[17]寻找最优的Anchor取值范围,将RoI Pooling替换成RoI Align,并在RCNN中损失函数进行了设计,其目的是提高网络模型的准确性和实时性。同时,将上阶段中的分割出来的字符用于该阶段中的LeNet[18]做识别,并将其与该方法和未改进网络进行对比,最后通过实验来验证该方法的有效性。
1 本文算法
1.1 字符分割
由于工业相机采集出来的图片较大,含有其他很多电路板和元器件等无用信息,不便于分析和研究,因此进行对数据集整理和清洗,统一将图片的尺寸截取为1 110×180大小。线圈的上下部分有螺纹边框,在高光的拍摄条件下,存在曝光过度的情况,对分割的结果影响极大,为了正确分割出字符,具体详细操作步骤如下:
(1)如图1所示,为本次实验操作选取的典型例图。首先对目标图像进行灰度化,在灰度化后的图像进行k-size为(3,3)的高斯滤波操作,目的是通过对邻域取得九个数的高斯分布权重矩阵与原灰度化图像进行卷积操作,从而平滑噪声。

图1 选取原图Fig.1 Selecting original image
(2)使用THRESH_BINARY_INV和Otsu’s二值化,将前景和背景进行反相操作,并自适应找到最优阈值。
(3)水平投影法,对投影的每行累和的像素值设定阈值,如若大于设定的阈值,将该行中的所有像素点置于背景色,对投影中的整个波形来说,找到波谷点,将波谷线到边界线的最小值这一段内范围的所有像素点置于背景色,完成上下边框去除。
(4)使用kernel为7×7的闭运算操作,为二值化后的图像进行先膨胀后腐蚀的过程,目的为了填充字符内的小黑点以及去除背景中的噪声点。
(5)通过前面一系列操作后,对每一列元素进行投影累加,分割出有像素值的列。对于左右无像素值的单个区域分割出来,若该区域比字符的宽度大,则选择在分出来单个区域的波谷点进行分割,此操作的目的是分割出部分因曝光过度而产生黏连问题的字符。
(6)通过对之前水平投影行分割字符中的边界保存,结合垂直投影列分割的字符区域边界,完成对字符区域块的分割操作。
为得到较为清晰分割出来的字符,再次使用THRESH_BINARY_INV和Otsu’s二值化,采用kernel为(4,4)的膨胀操作。并进行轮廓检测,计算轮廓的垂直边界最小矩形,对矩形的大小进行设置,当上边框与下面框的绝对值小于字符的高度时,选择滤去,本文设置的阈值为30像素值,最终得到膨胀反相单个字符图,如图2所示,其中图2(a)和(b)分别为图1(a)和(b)的最终结果。

图2 膨胀单个字符分割图Fig.2 Expanding single character segmentation graph
1.2 字符识别
本次实验采集图片共有620张,通常使用深度学习技术达到理想识别效果需要大量的样本数据进行学习,因此需要对数据进行扩增,为了减少标注工作量,对已标注好的样本为基本,对在真实场景可能会出现的情况进行数据增强,本文采用基础操作的上下旋转、左右置换,以及高级操作的亮度调整进行图片扩增。
1.2.1 Faster R-CNN卷积神经网络
Faster R-CNN是一个二阶(two-stage)网络,在R-CNN和Fast RCNN的基础上改进而来,由Ren等人在2016年提出,该网络可实现端对端进行训练,取得了实时的检测效果,其网络结构主要包含四个部分:特征提取网络、候选区域网络(RPN)、RoI Pooling(region of interest)模块和RCNN模块。
第一部分的特征提取网络是特征提取部分,Faster R-CNN采用的Backbone是VGG16,VGG16共有13个卷积层,3个全连接层,包含4个Pooling层,最后一个Pooling层一般在物体检测中都不使用。下采样率为16,如若输入的是三通道1 110×180图像,则经过基网络处理之后输出的特征图大小为521×69×11。
第二部分的候选区域网络为RPN模块,其主要作用是生成Propasal(建议框)。RPN模块包含了5个子模块:Anchor的产生、RPN卷积网络、计算RPN损失、生成Propasal和筛选Proposal得到RoI。
(1)Anchor的产生
Anchor在物体检测的网络中比较常用,为了使得检测准确率更高,一般的网络会选择使用提供的先验框在图像上进行框定,然后再筛选和精修从而完成精确的定位。Anchor的本质是在原图像中产生的一系列有一定比例大小的矩形框,Faster R-CNN网络将这些矩形框和基网络之后的特征图进行了关联。
(2)RPN卷积网络
RPN卷积网络在通过Backbone网络之后先进行了3×3的卷积,之后分为分类分支和回归分支。在分类分支中,首先利用1×1卷积在特征图操作,将维度的特征点进行联通,由于每个Anchor有前背景之分,并且每个特征点有9种尺寸大小,所以输出的维度为2×9=18。而分类的过程中需要经过Softmax函数,故对向量维度进行reshape操作,之后再次reshape还原。在回归分支中,同样使用1×1卷积,每个点有9种Anchor,每个Anchor有4个数据,分别为框的中心点坐标和宽高,因此输出的维度为4×9=36。
(3)计算RPN损失
从(1)中的Anchor产生可得知,其总数量将近两万个。为了解决正负样本的失衡问题,因此需要对Anchor进行筛选,一般情况下,选择最多不超过128个正样本,总共有256个Anchor送入后续的损失计算。上述的正负样本代表了预测的分类真值,而回归部分需要利用Anchor与之对应的标签求得偏移量值,将其保存在bbox_targets中。负样本为背景,不需要回归,故将bbox_outside_weights设置为0,而正样本需要回归,将bbox_inside_weights设置为1。RPN真值最后输出有标签label、偏移量值bbox_targets、正负样本的两个权重bbox_inside_weights和bbox_outside_weights。
(4)生成Proposal
首先对生成全部的Anchor进行回归偏移调整,将超过图像尺寸的Anchor去除,然后对接下来的Anchor按照confidence(置信度)排序,筛选出前12 000个得分高的Anchor,此时利用非极大值抑制(non maximum suppression,NMS)去掉一个物体可能含有多个Anchor的重叠框,最后将从建议区域中得到得分最高的2 000个框,作为后续的Proposal输出到下一阶段。
(5)筛选Proposal得到RoI
从(4)中得到2 000个框,含有很多的背景框,会造成负样本过多,使得出现正负样本不均衡,为了有效地送入后续的全连接网络,减少不必要的计算,因此还需要从Proposal中继续筛选出有效的正负样本。根据标签与Proposal的IoU值,筛选出正负样本。通常情况下,将正负样本的总数设定为256个,并对正负样本的比例进行限制,正样本和负样本的比例为1∶3。
第三部分为RoI Pooling层。顾名思义是为了将上述输入的RoI进行池化,所处理之后的特征图为固定的大小,以供后续的RCNN计算预测值与真值的损失。
第四部分为全连接RCNN模块。经过第三部分RoI Pooling操作之后,将池化后的操作送入RCNN进行训练。值得一提的是,RCNN的损失函数和RPN保持相同,在分类中,同样使用二分类,但这里共有21个类别,而不再是前背景两个类别。在回归任务中,选择不超过64个正样本进行回归,负样本则不参与计算。
1.2.2 改进的Fast R-CNN网络结构
到目前为止,在机器视觉中诞生了很多的目标检测网络,但Faster R-CNN无疑成为了一个经典的目标检测网络算法[19],尤其对小物体检测、拥挤和遮挡等困难场景提供了一个有效的解决方案,众多优秀的目标检测算法都基于Faster R-CNN的基础上改进、完善和优化而来,因此,为了准确检测(识别)保险丝字符,在以下四个方面进行改进。
(1)在特征提取阶段使用ResNet101代替原来的VGG16
如图3所示,为ResNet101的网络结构图,其一共有四个大卷积组,这四个大卷积组的Bottleneck数分别为3,4,6,3。采用ResNet101作为Faster R-CNN特征提取基网络,首先对送入的图像进行步长为2的卷积操作,此时特征图缩小至原来的1/2,通道数为64,之后连续通过三个卷积组,通道数增加一倍,而特征图减少至原来的1/2,卷积的过程直至经过第三个特征组时,将最后一次变为通道数为256的1×1卷积。因此ResNet101特征提取网络为91层卷积操作,与VGG16相同的是,输出的Feature map维度为512,下采样率为16。

图3 ResNet101网络结构图Fig.3 ResNet101 network structure diagram
(2)在RPN网络中,寻找最佳的Anchor参数
使用K-means聚类算法寻找最佳的Anchor尺寸大小,首先对Anchor Box的K个数进行初始化,对Bounding Box左上角和右下角四个坐标提取出来,用右下角横坐标与左上角横坐标之差得到框的长,用右下角纵坐标与左上角纵坐标之差得到框的宽,之后计算Bounding Box与Anchor Box的IoU值,其目的是在Box尺寸比较大的时候,能够减少相应的误差值,使其直接聚类Bounding Box的宽和高,产生K个宽高组合的Anchor Boxes。在此使用IoU值,即为Anchor Box与Bounding Box的公共部分占所有部分的比例。引入误差d,d为1减去IoU,每一个Bounding Box对于Anchor Box都有一个误差d(n,K),其中n为Bounding Box,K为Anchor Box的初始化值。经过遍历,选取误差最小的Anchor Box分类给Bounding Box。随后将属于Anchor Box的Bounding Box取平均值作为一个尺寸进行更新,直到所有的Bounding Box都能找到Anchor Box的类。最后,找到每一个Bounding Box最高的IoU值,进行取平均值输出精确度[20]。
通过加载标注的文件信息,最终聚类得出的9种Anchor,分别为:(8,219),(11,211),(13,221),(14,226),(16,214),(18,224),(20,228),(24,235),输出的图像size为416。准确率为92.53%。
(3)将RoI Pooling替换成RoI Align
由于RoI Pooling在实现的过程中,直接对特征量化取整,此操作虽然简单快捷,但连续的两次取整操作,必然会带来较大的偏差,直至影响整个网络的性能,最为直接的是导致预测框在回归物体位置中不准确。RoI Align实现的过程可从如下分析,若预测的框为280×280大小,通过下采样率16,因此进行区域生成的特征图大小为280/16=17.5,保留其浮点数,之后将得到大小为17.5×17.5的特征图处理成7×7的区域。因此需要以17.5/7=2.5的步长来选取,继而保留浮点数,得到小方格2.5×2.5的区域,在此区域内采用最大值池化,作为该特征的输出值,最终实现7×7的输出。在此过程中,对每个小方格平均分成4份,在这4份的中心作为该内区域的值,而中心点通过选取周围4个点进行双线性插值得到,再对这4个中心点取最大值,将得出来的最大值作为池化输出到7×7的特征。
(4)在RCNN中损失函数的设计
为了能在输入宽高比差异较大图像中也能达到良好的效果,因此对于本次实验,平衡分类和回归中的损失尤为重要。在经过RoI Pooling层之后,输出的Anchor通常为256个,而feature map的分辨率大小为经过特征提取网络之后所产生的值,在本次的保险丝字符定位作识别中,输入的图片为1 110×180,因此经过下采样率为16之后得到的特征图大小为(1 110/16)×(180/16)=780,而由Faster R-CNN网络的损失函数可知[21],Ncls为样本的总数量,即Anchor数量,为256,Nreg为feature map的分辨率大小,即上述求出的780,为了达到平衡损失条件,因而对参数的取值为λ=3,故损失本次使用的损失函数如式(1)所示:
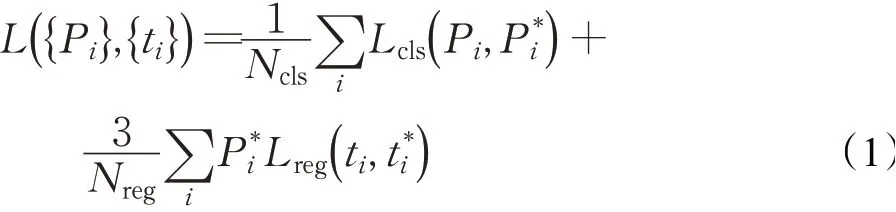
其中,Pi和分别是每个Anchor类别的真值和预测类别为分类损失为回归损失,其中ti为偏移真值,t*i为预测偏移量。具体公式如下所示:
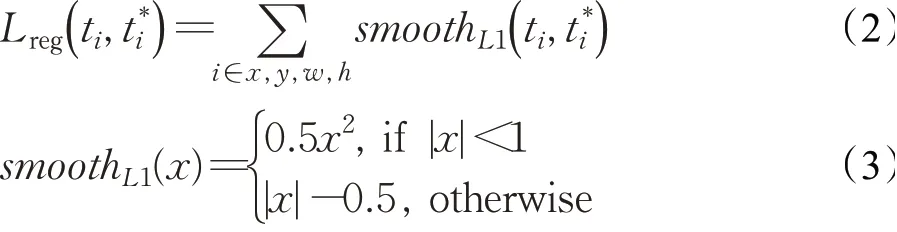
2 实验
验证改进之后的网络算法性能,将其与未改进的Faster R-CNN进行对比,并对比上一阶段分割出来的字符用于本阶段的识别,识别算法使用LeNet网络。
2.1 实验环境
平台采用Windows10(64 bit)专业版操作系统,处理器为Intel®CPU E5-2620 2.00 GHz,内存为24 GB,显卡为NVIDIA Tesla M40(24 GB),使用语言环境python3.7.6,开发框架为pytorch,OpenCV的版本为4.1.1。
2.2 数据处理
采集的图像共有620张,然后对原图像进行三种数据增强的操作,分别为:对原图像旋转180°、以y轴为中心左右翻转和对三通道中每个点加50像素值进行亮度调整。经过该操作后共得到2 480张图片,而后按比例8∶1∶1分别分配给训练集、验证集和测试集。每个保险丝线圈,采用的三个角度进行捕获,合并为一个图像,因此有的区域字符为重复的字符,保险丝的线圈字符序列中一共有13~14个字符,合并之后的图像含有的字符数有13~19个,三个对接的图像有一定的左右镜像能力,因此对一些严重模糊或曲面扭曲的图像不进行操作,如图4所示,对红线框的字符视作无效字符。另外,数字打上对应的数字标签,字符打上对应的小写字母标签,特别地,对于字符“L”的标签为“ll”。

图4 镜像图像中模糊和变形示意图Fig.4 Schematic diagram of blur and distortion in mirror image
2.3 对比实验
为了验证改进算法的有效性,与改进前的算法进行对比实验,如图5所示,为本文改进算法的训练损失曲线图,当总损失将近收敛时,暂停训练,共计5 000迭代次数。

图5 改进网络的训练损失曲线Fig.5 Training loss curve of improve network
如图6所示,为选取两组网络改进前后识别效果对比图,从第一组(a)和(b)可以看出,改进前的网络对右侧中“A”的压缩小字符未能识别,并且对能够准确识别的字符框有偏歪的现象,比如左侧的“P”字符和右侧的“T”字符;第二组中的(c)和(d),未改进的网络在图像右侧识别中对倒“V”字符出现两个框检测,并存在一个误检框,误检的结果为“A”;由对比结果图可知,改进之后的网络对曲面或部分残缺的字符能做到有效的识别,由此可见,改进后的模型,加强了网络特征提取,提取了多层有效的语义信息,并对RoI Pooling的量化造成的偏差有一定的改善。

图6 改进前后实验对比结果Fig.6 Experimental comparison results before and after improvement
对于上一阶段使用的测试数据集分割出来的单独字符送入本阶段进行识别,分割阶段得到的字符共有2 871个,将该部分字符送入LeNet网络进行训练和推断,计算其从分割后到识别的准确率,而使用定位作识别中,除去数据处理阶段一些严重模糊、曲面扭曲和主体部分缺失的字符,在测试集数据248张图像上共有3 497个有效字符。使用一阶段网络YOLO v1、SSD和二阶段未改进网络进行对比实验,其各训练参数如表1所示。
通过表1的参数进行训练,将所得模型进行推断,最终,通过实验得到的结果如表2所示。
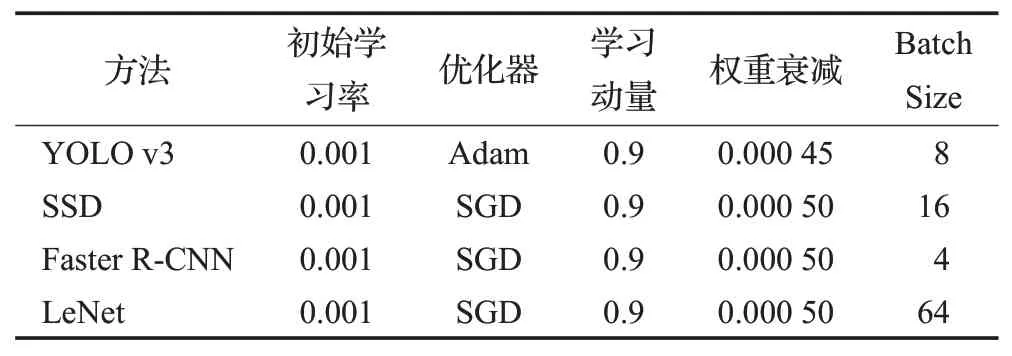
表1 对比实验网络训练参数Table 1 Contrast experimental network training parameters
从表2的实验结果对比可以看出来,在定位做识别中,YOLO v3网络实时性效果较高,每秒可推断35张图片,但对字符的正确识别率只有96.69%,难以达到高精度的要求,而改进后的网络对比未改进网络在保持帧率不变的前提下准确率提高了1.17个百分点,对比SSD和YOLO v1网络分别提高了4.03个百分点和3.22个百分点,使用分割结合LeNet识别的算法在分割率上有较大的损失,而对分割出来的字符因较多有残缺部分导致识别效果欠佳。考虑工业图像检测的识别率和实时性诉求,结合精度和速度综合考量,使用本文所采用改进的Faster R-CNN网络通过实验验证了该方法在线圈字符识别问题的有效性,并有着显著的识别效果,对这类OCR问题有一定的普适性。
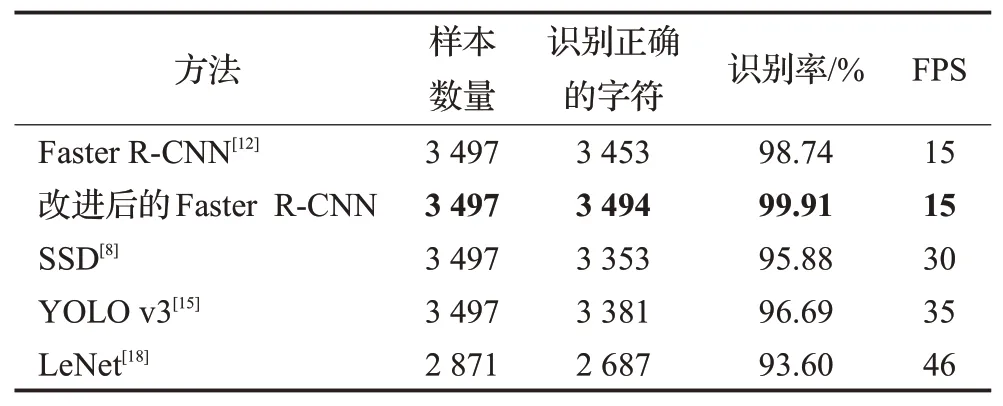
表2 实验对比结果Table 2 Results of comparative experiment
3 结束语
光学字符识别是计算机视觉中重要的研究方向之一,近年来成为了研究热点,随着中国制造不断地发展,OCR的应用场景越来越广阔。本文对保险丝线圈的字符进行了研究,采用了两种方法进行识别,一种是通过字符的先验知识使用投影法进行分割,将分割完成的字符送入LeNet网络进行识别,另一种方法是以定位作识别,将每个字符进行目标检测从而到达识别的效果。对比了一阶段网络和二阶段网络检测算法,并最终选择改进的Faster R-CNN目标检测作为识别,其主要体现在四个方面的改进,优化之后的网络让字符识别效果更理想,在后续的研究中,可以将对线圈中的字符进行去重复化,排列出正确的字符序列来,组合得到线圈中的序列字符,以识别整个图片的正确序列作为基准,以供线圈型号等信息的辨认。
通过本文的检测作识别方法,能够准确识别出曝光过度、部分残缺和曲面压缩等线圈的字符。实验表明,使用定位作识别的方法在这类光学字符识别具有一定的推广和借鉴价值。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
电子制作(2018年19期)2018-11-14 02:37:08
成都信息工程大学学报(2017年3期)2017-11-09 02:56:12
自动化学报(2017年11期)2017-04-04 02:52:58
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:38
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:29
噪声与振动控制(2015年4期)2015-01-01 07:08:21
