
采用多通道浅层CNN 构建的多降噪器最优组合模型
2022-12-03 14:31徐少平林珍玉陈孝国李芬杨晓辉
自动化学报 2022年11期
徐少平 林珍玉 陈孝国 李芬 杨晓辉
图像在获取、存储和传输过程中,外界干扰或 设备固有缺陷会使图像受到不同程度的噪声干扰[1-3].这些噪声(常被假设为高斯白噪声)会导致图像中纹理边缘细节被破坏,使得图像质量下降[4-5].早期,研究者通常采用高/低通滤波器处理噪声图像,利用相邻像素点亮度值的线性、非线性组合,实现对中心像素点的最佳估计,以达到去除噪声的目的.这种方法实现简单、执行效率高,然而由于在降噪过程中未充分考虑图像局部结构特点,会导致降噪后的图像边缘细节被模糊甚至丢失.2005 年,Buades等[6]提出了具有里程碑意义的非局部均值(Non local means,NLM)降噪算法.NLM 降噪算法基于自然图像中具有大量重复的局部结构性质,即所谓的非局部自相似性(Nonlocal self-similarity,NSS),获得了比滤波类降噪算法更好的降噪效果.但是由于需要在图像内大量搜索与待复原图块相似的图块以提高降噪效果,因此导致NLM 降噪算法的执行时间较长.2007 年,Dabov等[7]提出一种BM3D (Block matching and 3D-filtering)降噪算法.该算法充分利用图像的NSS 和稀疏特性,采用图块堆叠和协同滤波技术实现了降噪效果和执行效率之间的较好平衡.因其良好的综合性能,BM3D降噪算法常被研究者们列为基准对比算法.近十年来,研究者们为进一步提高降噪效果,多利用关于自然的某种先验知识构建目标函数,通过求解目标函数的最优解来达到降噪目的.依据所使用的自然图像先验知识的不同,基于稀疏表示[8-10]和基于低秩最小化[11-14]的图像降噪算法被相继提出,比较经典的工作有2013 年提出的NCSR (Non-local centralized sparse representation)[8],2014 年提出的WNNM (Weighted nuclear norm minimization)[11]等.虽然这些降噪算法的降噪效果优于BM3D 降噪算法,但最优目标函数值的求解通常以复杂的迭代优化过程实现,使得算法的时间复杂度非常高.
近年来,深度学习技术因其强大的特征学习和非线性映射能力在图像降噪领域取得巨大成功[15-23],其中尤以基于深度卷积神经网络(Deep convolutional neural network,DCNN)构建的降噪模型发展迅速[22-25].较典型的工作有:2017 年提出的DnCNN(Denoising convolutional neural network)[22],2018年提出的FFDNet (Fast and flexible denoising convolutional neural network)[23]等.在大量噪声图像–无失真图像训练数据集上,基于DCNN 构建的降噪模型以网络输出图像与原始无失真图像之间的Loss 函数最小值为目标驱动,学习并调整DCNN模型中的网络参数完成图像降噪任务.基于DCNN的降噪模型依赖网络结构隐式地学习图像中先验知识,展现出强大的图像先验知识建模能力(非线性映射能力),能够避免基于稀疏和低秩模型等优化降噪模型中构建目标函数困难的问题,进一步提高了复原图像的质量.此外,受高性能图形处理单元(Graphic processing unit,GPU)并行计算技术的支持,基于DCNN 进行图像降噪能够获得极高的执行效率.然而,这类本质上基于数据驱动的降噪模型,其降噪性能也同时受所采用技术路线内在固有特性的制约,即必须保证待降噪图像与用于训练模型的图像集合在受噪声干扰程度上是近似的,才能获得最佳的降噪效果,存在数据依赖缺陷[4].
图像降噪作为图像处理领域的基础性问题,追求更好的图像复原效果(更高的图像质量)一直是推动研究者研究新型降噪算法的动力.迄今为止,虽然已提出了很多不同类型的图像降噪算法,并且在降噪效果上不断改进,但提升幅度越来越小.而且,目前很难找到某个单一降噪算法能够对各种不同图像内容、不同程度的噪声图像都能获得较好的降噪效果[2].例如,BM3D、NCSR、WNNM 等算法对于含有丰富纹理细节的自然图像可以获得比较好的降噪效果,但对于无太多重复性局部结构内容的自然图像则表现不佳;而DnCNN、FFDNet 等基于深度学习的降噪模型则能在无太多重复性局部结构图像上获得较好的降噪效果,但也要求待降噪图像与训练降噪模型所用图像集合中的图像存在类似结构.Chatterjee等[26]对主流降噪算法的降噪效果所能达到的极限展开了研究,其研究结果表明目前各个降噪算法的降噪性能虽然在不断改进,但是离理论上的极限值尚有一定距离.换言之,各个降噪算法的降噪效果仍有较大改进空间.然而,目前仅依靠单个降噪算法对降噪效果的提升越来越困难.
最近,Choi等[2]提出一种被称为一致性神经网络(Consensus neural network,CsNet)的最优组合模型,该模型采用将多个降噪算法(降噪器)输出的降噪后图像进行优化组合(融合)的方式,实现了降噪效果较大幅度的提升.具体而言,CsNet 模型首先利用MSE (Mean square error)估计器来估计各个降噪器输出图像关于无失真图像的MSE 估计值,通过求解凸优化问题确定各个降噪器输出图像在组合图像中所占的最优权重值;然后采用加权组合的方式,将各个降噪器输出图像加权融合为一张初步优化图像;在此基础上,CsNet 模型再通过图像质量提升(Booster)模块对初步优化图像的图像质量进行多次级联提升.虽然CsNet 模型实现了图像降噪效果的提升,但是初步融合阶段对多个降噪器输出图像所设置的权重值是针对整张图像(所有像素点的权重值完全相同),加权处理的粒度非常粗糙(未考虑图像局部细节各种复杂的变化结构模式),导致其初步优化图像的图像质量并不高.因此CsNet组合优化模型需要多次使用Booster 模块对图像质量进行级联提升,才能达到令人满意的降噪效果.这使得CsNet 组合优化模型设计、训练的复杂度非常高,导致执行时间比较长.
受CsNet 模型启发,本文提出一种新的基于多通道浅层CNN (Multi-channel shallow convolutional neural network,MSCNN)构建的多降噪器最优组合(Optimal combination of image denoisers,OCID)模型.与CsNet 组合优化模型的实现策略不同,OCID 模型没有显式的权重值设置过程,也无需后期的图像质量提升过程,而是将CsNet 模型中的优化组合和图像质量提升两个模块有机集成到MSCNN 模型中,利用多通道网络结构直接接收由多个降噪器获得的输出图像.采用残差学习技术提升图像质量,经过模型处理后直接获得残差图像,将多个降噪器输出图像的均值图像减去残差图像即可得到优化组合后的图像.
1 相关工作
1.1 CsNet 模型
图1 给出了CsNet 多降噪器最优组合模型的架构图.对于给定的噪声图像y,假定有k个降噪算法(降噪器)D1,D2,···,Dk可用,利用这些降噪器对噪声图像y进行降噪可获得降噪后图像{z1,z2,···,zk}. 利用MSE 估计器M来估计各个降噪算法输出图像关于无失真图像的最小均方误差(MSE),然后通过求解凸优化问题来确定各个降噪器输出图像的最优权重w1,w2,···,wk.这样可以获得初步优化图像

图1 文献[2]中提出的CsNet 模型架构图Fig.1 The architecture of CsNet model proposed in reference [2]


1.2 存在问题
CsNet 模型在降噪过程中,首先利用MSE 估计器对各个降噪器降噪后的图像关于原始无失真图像的MSE 值进行估计,在得到各降噪器的MSE 值之后,通过Solver 求解一个凸优化问题来确定各个降噪后图像{z1,z2,···,zk}的最优权重w1,w2,···,wk.但是这些权重值是针对整个噪声图像进行设置的(每个像素点的加权系数值均相同,加权粒度是像素级),没有考虑图像中不同局部区域内的图像结构对最终融合结果的影响,导致其降噪效果一般.所以,CsNet 模型需要使用Booster 模块对初步优化图像进行再次优化增强,而且需要多次执行增强过程才能获得较优的降噪效果.总体而言,尽管CsNet 模型充分利用了多个降噪器D1,D2,···,Dk互补性的信息,所获得的输出图像能得到一定的质量提升,但是实现过程比较复杂,导致其算法执行时间长,图像质量提升幅度也受到一定的限制.
2 OCID 模型
2.1 基本思想
近年来,CNN 由于具有强大的非线性映射能力,被研究者们广泛应用于图像处理领域并取得了巨大的成功.受CsNet 模型通过组合优化多个降噪器输出(降噪后)图像从而提升降噪效果的思想启发,为获得更好的图像降噪效果,本文提出一种基于MSCNN的OCID 模型.所提出的OCID 模型试图采用多通道CNN 技术同时接收由若干个降噪器D1,D2,···,Dk对给定噪声图像y进行降噪后的图像{z1,z2,···,zk},充分利用CNN 所具有的局部连接和共享权重特性,更为合理地设置融合权重.改在图块粒度上完成初步降噪图像{z1,z2,···,zk}的优化融合,以获得更好的图像降噪效果.同时,采用浅层的网络结构,试图显著提高组合优化模型的执行效率.
2.2 多通道融合网络模型
本文提出的OCID 模型如图2 所示.OCID 模型的网络核心结构与主流的DCNN 类似[22],主要区别有:

图2 多通道神经网络OCID 模型架构Fig.2 The architecture of OCID model with multi-channel neural network
1)采用浅层结构.它的深度仅有d=3 层.第1层(Conv+ReLU)使用64 个大小为3×3× n的滤波器对输入图像执行局部加权组合,然后通过ReLU[27]激活函数输出64 个特征映射图;第2 层(Conv+BN+ReLU)使用64 个大小为3×3×1的滤波器,在第1 层的基础上增加了BN[28]操作,以缓解SGD (Stochastic gradient descent)训练算法产生的内部协变量转移现象;第3 层(Conv)只用了一个卷积层重构残差图像.与主流的DCNN 相比,本文的Conv+BN+ReLU 结构仅重复一次.表1、表2列出了使用不同重复次数的Conv+BN +ReLU 网络层的实验数据,实验数据表明使用多层结构并不能使降噪效果得到显著提升,反而会增加执行时间,故本文仅重复一次.

表1 不同网络层数下的MSCNN 模型在10 张常用图像上的PSNR 均值(dB)Table 1 PSNR performance of different MSCNN models on 10 commonly used images (dB)

表2 不同网络层数下的MSCNN 模型在10 张常用图像上的平均执行时间(s)Table 2 Execution time performance of different MSCNN models on 10 commonly used images (s)
2)多通道的输入结构.由于OCID 模型的主要任务是将多个降噪算法的输出图像融合为一张图像质量更高的图像,故与一般的DCNN 模型不同,采用了多通道的输入结构.这样,就可以利用多个降噪器D1,D2,···,Dk分别对给定噪声图像y进行降噪,得到多张初步降噪图像{z1,z2,···,zk},然后将图像集{z1,z2,···,zk}连接后同时输入网络.
3)残差图像的构成方式不同.为提高网络的映射能力,许多DCNN的输出并不是无失真图像而是残差图像.假定噪声图像的定义为

其中,y为噪声图像,x为原始无失真图像,n为噪声.为提高预测效果,DCNN 利用残差学习[29]训练网络模型R(y)≈n,模型的输出为残差图像.根据式(4)即可得到关于原始无失真图像x=y-R(y)的最佳估计.在训练模型的过程中,期望残差图像与预测残差图像之间的均方误差(MSE)为

所提出的OCID 模型本质上是基于MSCNN的多通道优化组合模型,即利用浅层CNN 对输入的多张图像进行融合.该模型一旦训练完成,在使用时无需用户设置任何参数,所提出的MSCNN 中网络参数的作用相当于一步实现了CsNet 模型中的加权和Booster 两个模块的功能.由于OCID 模型采用MSCNN 结构,使得其在提升降噪效果和执行效率之间达到较好的平衡.相较于CsNet 模型,OCID 模型具有显著优势.
2.3 网络训练
为训练所提出的OCID 模型,可对原始无失真图像添加各个级别的高斯噪声获得噪声图像集合.对于噪声图像集合中的每一张噪声图像,利用多个降噪器获得初步降噪图像{z1,z2,···,zk}及其均值图像 ¯z,将均值图像减去该噪声图像所对应的无失真图像获得残差图像R(y),即可准备好用于训练模型的输入与输出训练数据对.具体而言,从BSD数据库[30]中随机选取100 张图像,并对这100 张图像依次分别加上噪声水平值σ范围为[5,60],间隔为5的高斯噪声,将这1 200 条记录Y={y1,y2,···,yj},j=1 200利用多个基准降噪器分别进行降噪,可得其初步降噪后图像将多个降噪算法得到的降噪后图像的均值图像和相应的残差图像组成的训练数据对输入MSCNN 模型中进行训练.本文采用SGD 算法完成模型的训练.需要说明的是,网络模型实际训练是在图块级别上进行的.网络训练所采用的参数为:输入图块大小为40 × 40 像素,学习率为0.0001,动量为0.9,批量训练样本大小为128.
2.4 多通道模型网络层数分析
为确定OCID 模型的最佳网络深度,分别构建核心网络层Conv+BN+ReLU 重复次数为1 次、3 次、5 次、7 次、9 次、11 次、13 次和15 次的网络模型.通过训练σ为20、40、60 时的降噪模型,以BM3D 和DnCNN 作为基础降噪器,并使用图3中的常用图像来测试网络层数对图像质量提升效果以及相应执行效率的影响.这里仅以BM3D和DnCNN 组合模式为例,其他降噪器组合模式结论与该组合模式相同(限于篇幅,不再给出其他组合模式下的实验数据).如表1 所示,通过对比PSNR(Peak signal to noise ratio)指标可以看出,随着CNN 网络层数的增加,OCID 模型的降噪效果仅在高水平噪声条件下会有小幅度提升.总体而言,核心网络层Conv+BN+ReLU 重复1 次就可达到比较好的降噪效果.而由表2 可知,随着网络层数的增加,模型的执行时间(在CPU 环境下测得)显著增加.故综合考虑图像质量提升效果和执行效率,本文将Conv+BN+ReLU 层重复次数设置为1,所提出的OCID 模型为MSCNN.

图3 各类文献中常用的图像集合Fig.3 Commonly used images in the literature
2.5 降噪器组合分析
所提出的OCID 模型允许输入多个不同的初步降噪图像,而目前已提出的降噪算法非常多,因此具体使用哪些降噪算法作为降噪器以及它们之间的组合搭配模式是非常值得研究的问题.为确定各降噪器的最佳组合模式,选择BM3D[7]、NCSR[8]、WNNM[11]、DnCNN[22]和FFDNet[23]5 种有代表性的降噪算法进行研究,它们分别主要是基于NLM、稀疏表示、低秩和深度学习技术实现的主流降噪算法,各自的降噪效果在各类降噪算法中都是比较突出的.故从它们中能挑出2~5 种降噪算法作为降噪器使用.实验数据表明,采用含4 种、5 种降噪算法的组合模式并不能显著提升降噪效果(限于篇幅,不再给出实验数据),本文仅给出含2 种、3 种降噪算法组合模式的实验数据,所有可能的组合模式如表3所示.从BSD 纹理图像集中选取50 张图像对各种组合模式下的降噪效果分别进行测试,以在50 张图像上所获得的PSNR 均值作为评价提升效果好坏的标准,实验数据列在表4、表5 中.从表4、表5中可知:在含2 种降噪器的组合模式中,降噪效果最好的是Case 3 (FFDNet+NCSR),其PSNR均值为29.56 dB;在含3 种降噪器的组合模式中,降噪效果最好的是Case 11 (BM3D+DnCNN +NCSR),其PSNR 均值为29.86 dB.理论上,组合模式中含降噪器的个数越多,其降噪效果可能越好.但在实际测试过程中,对比表4、表5 中的PSNR均值可以看出,3 种降噪器组合模式的平均降噪效果仅比2 种降噪器组合模式好一点,提升幅度并不是很大.

表3 2 种和3 种降噪器组合模式列表Table 3 List of combination of 2 and 3 denoisers
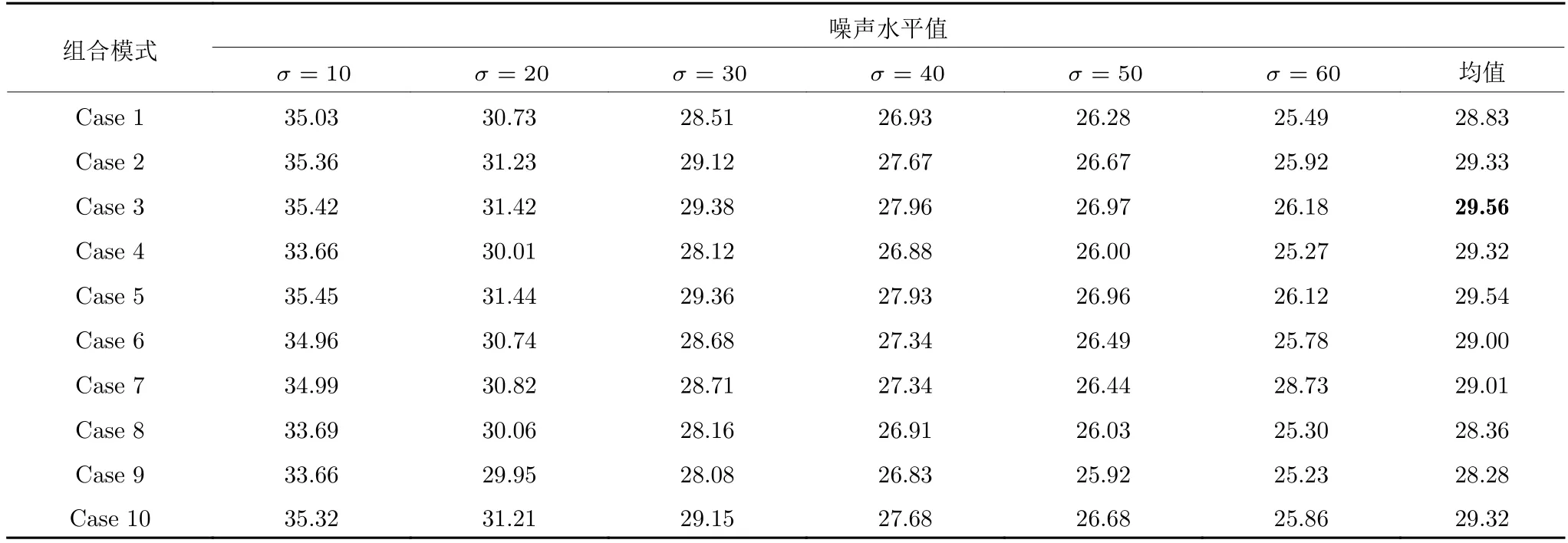
表4 2 种降噪器组合模式在50 张纹理图像集上所获得的PSNR 均值(dB)Table 4 Performance comparison of two denoisersin terms of PSNR on 50 texture images (dB)

表5 3 种降噪器组合模式的50 张纹理图像集上所获得的PSNR 均值(dB)Table 5 Performance comparison of three denoisers on 50 texture images (dB)
表6、表7 分别为2 种降噪器融合和3 种降噪器融合下的50 张纹理图像集上平均执行时间.从表6、表7 中的数据可以看出,在含2 种降噪器的组合模式中,Case 6 (BM3D+DnCNN)的执行时间最短,其平均执行时间为5.28 s,与执行时间最长的Case 10 (NCSR+WNNM)相比,执行时间相差约200 倍,其主因是NCSR 算法执行时间过长.而在含3 种降噪器的组合模式中,Case 13 (BM3D +DnCNN+FFDNet)的执行时间最短,平均执行时间为21.81 s.结合表4、表5 可以得出,使用3 种降噪器组合与2 种降噪器组合分别降噪后的PSNR值相差不大,但需要花费更长的执行时间.
2.6 组合方案选择
综合考虑降噪效果和执行效率两方面性能,本文选用BM3D 和DnCNN 2 个降噪算法作为OCID模型的基础降噪器(即组合模式Case 6).其原因如下:
1)降噪算法作为各类后继图像处理任务的预处理模块,首要考虑的是其执行效率,以保证整个图像处理系统的整体性能.在目前所提出的具有代表性的算法中,BM3D 和DnCNN的执行效率均排在前列,降噪效果表现最好的NCSR 算法因其过长的执行时间未作为OCID 模型的降噪器.需要说明的是,表6、表7 中的实验数据均是在CPU 环境下获得的.文献[31]提出一种将BM3D 算法卷积网络化的实现方法,即BM3D-Net 模型.如此,BM3D-Net 和DnCNN 均可以利用GPU 实现加速,其在GPU 上执行时间为150 ms 左右,能达到实时的要求.

表6 2 种降噪器融合下的50 张纹理图像集上的平均执行时间(s)Table 6 Execution time of two denoisers on 50 texture images (s)

表7 3 种降噪器融合下的50 张纹理图像集上的平均执行时间(s)Table 7 Execution time of three denoisers on 50 texture images (s)
2)在保证降噪算法执行效率的同时还要保证算法的降噪效果.BM3D 算法对具有较多重复结构的自然图像能得到很好的降噪效果,对重复细节内容不多的图像其降噪性能会受到一定的影响.而DnCNN 是一种基于深度学习的降噪算法,即便是图像中无较多重复结构,只要是训练图像集合中存在的结构模式,DnCNN 算法就可获得较好的降噪效果.因此BM3D 与DnCNN 组合后可形成最佳的优势互补.第3 节对比实验中,OCID 最优组合模型所列出的实验数据均是采用BM3D+DnCNN组合模式获得的.
3 实验与分析
3.1 测试环境
为验证所提出的基于MSCNN的OCID 模型对降噪效果的提升作用,选取采用不同代表性技术路线实现的BM3D[7]、NCSR[8]、WNNM[11]、DnCNN[22]、FFDNet[23]、RedNet[32]、VDNet[33]、TWSC[34]和CsNet[2](主要将文献[2]中第三组实验与OCID 模型进行比较)共9 种降噪算法作为对比算法.测试图像数据集包含常用图像集、BSD 纹理图像集[30]、DIV2K 图像集[35]和Waterloo 图像集[36].其中,常用图像集包含各种文献中常出现的10 张公知图像,如图3 所示;BSD 纹理图像集是从BSD数据库中随机抽取50 张图像构成(不同于训练时所使用的图像),其中10 张有代表性的图像如图4所示;DIV2K 图像集是广泛使用的超分辨率测试图像数据集,该数据集中图像的空间分辨率较高,从中随机选取50 张图像用于测试;Waterloo 图像集是用于图像质量评价算法测试的图像库,其图像内容主题较为广泛,从中随机选取50 张图像用于测试.所有的实验都是在统一环境下(硬件平台为Inter (R)Core (TM)i7-3 770 CPU @ 3.40GHz 16 GB RAM,GPU NVIDIA Quadro M4000;软件环境为Win10 操作系统,MATLAB R2017b,Python 3.7)完成的.

图4 BSD 测试图像集合中有代表性的10 张图像Fig.4 Ten representative images on BSD database
3.2 单个图像上的性能比较
首先,为验证所提出的OCID 模型对降噪效果的提升作用,对Lena 图像添加不同噪声水平值的高斯噪声,用各种参与对比的降噪算法对噪声图像进行降噪,并计算降噪后图像的PSNR 值和SSIM(Structural similarity)值,实验数据见表8、表9.由表8、表9 可知,所提出的OCID 模型在各个噪声水平值时两种评价指标均为最高,比单个BM3D和DnCNN 降噪算法提升了很多.这表明OCID 模型能将原本弱于FFDNet、VDNet的BM3D 和DnCNN 2 个算法的优势进行有效组合,其降噪效果比当前主流的FFDNet、VDNet 降噪算法要好,组合后的优势明显.
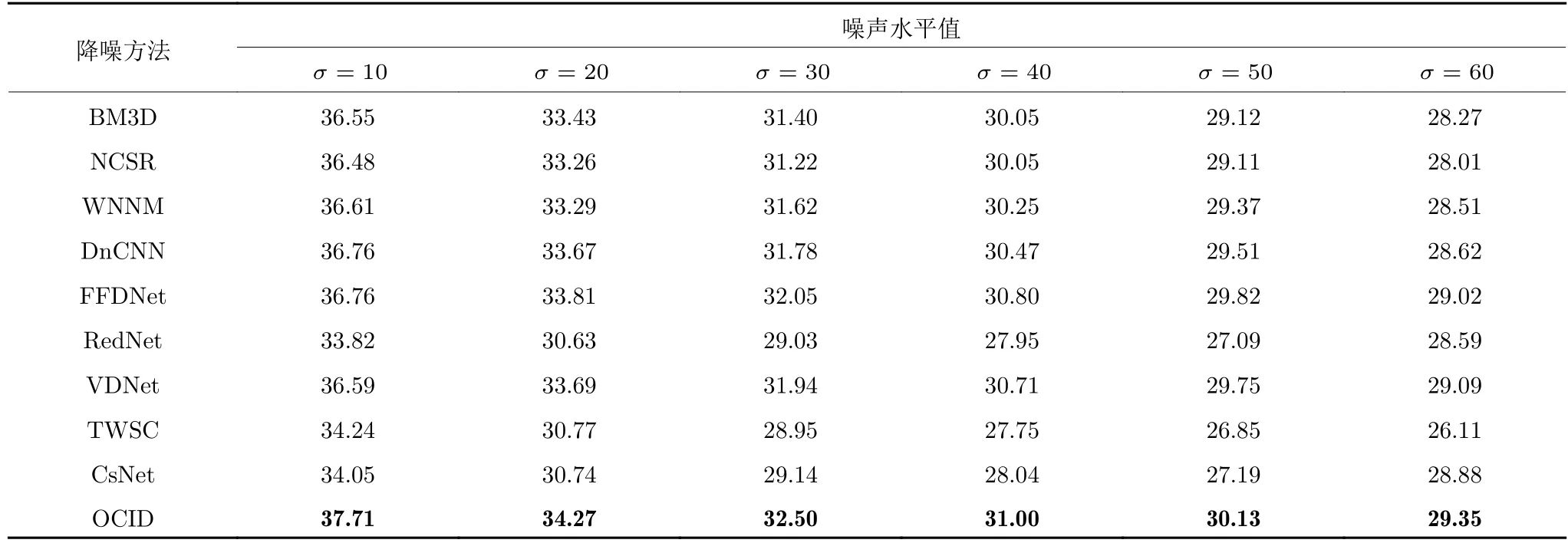
表8 各算法在Lena 图像上所获得的PSNR 值(dB)Table 8 Performance comparison of the competing algorithms in terms of PSNR on Lena image (dB)

表9 各算法在Lena 图像上所获得的SSIM值Table 9 Performance comparison of the competing algorithms in terms of SSIM on Lena image
然后,为更加直观地比较所提出的OCID 模型的降噪效果,利用各个对比算法对施加了σ=30 高斯噪声后的Boat 噪声图像进行降噪,并计算各降噪后图像相应的PSNR 值.图像整体降噪及对应的局部放大区域(右下角矩形框)的视觉效果如图5所示.由图5 可知,基于图像自相似、稀疏和低秩特性构建的BM3D、NCSR 和WNNM 算法在处理像Boat 这类缺乏重复内容的自然图像时能力较弱,而基于深度学习构建的DnCNN、FFDNet 和VDNet算法则相对更具优势,这是因为这类算法可以利用在训练图像集上学习的先验知识更好地完成降噪.通过比较PSNR 值可以发现,OCID 模型比CsNet模型高出0.6 dB,图像质量提升明显.另外,通过局部放大区域的细节可以发现,虽然用BM3D 算法处理后图像的图像质量比较差,模糊程度比较严重,但是一旦它与用DnCNN 算法处理的图像组合后,所获得的图像(即用OCID 模型获得的图5(l))便具有了更好的降噪效果.图5(l)的PSNR 值显著优于图5(g)和图5(c),并且比降噪性能较好的单个VDNet 算法还要高0.6 dB.在视觉感觉上,图5(l)中船尾部“缆绳”的边缘细节保护得比较好.这说明OCID 模型充分利用了降噪能力相对较弱的BM3D 和DnCNN 2 个算法各自互补性的优势,获得了更好的降噪效果.

图5 各算法在Boat 图像上降噪效果对比Fig.5 Denoising effect comparison of the competing algorithms on Boat image
3.3 图像数据集整体性能比较
为进一步验证所提出的OCID 模型对降噪效果提升作用的稳定性和鲁棒性,在常用图像集、BSD纹理图像集、DIV2K 图像集和Waterloo 图像集上与当前主流降噪算法进行对比测试,以各个算法所获得性能指标的平均值作为衡量算法优劣的标准.
首先,对图3 所示的10 幅常用图像分别添加噪声水平值σ为 10、20、30、40、50、60的高斯噪声,表10、表11 列出了各对比算法在PSNR 和SSIM两个指标上的实验数据.由表10 可知,FFDNet 作为近年提出的一种降噪性能非常不错的基于深度学习构建的降噪算法,它的降噪性能虽比其他主流算法要好,但是优势不多(在PSNR 指标上,最多比WNNM 高0.24 dB),某些噪声水平值时的测试结果还要差一些.而OCID 组合模型所获得的PSNR指标值最高且很稳定,比FFDNet 降噪器的性能指标高0.7 dB~1.6 dB.这说明将多个降噪器的输出图像经OCID 模型优化组合后,比单个降噪器输出的图像在图像质量上确实提升不少.与CsNet 模型相比,OCID 组合模型在PSNR 指标上提高了0.6 dB~1.8 dB.此外,OCID 组合模型在SSIM 指标上的对比数据也是最优的.需要特别指出的是,尽管OCID组合模型所使用的BM3D 和DnCNN 降噪器,单个的降噪效果并不是最优的,但是经过优化组合后却可以获得非常大的改进.这说明OCID 组合模型能够有效结合BM3D 和DnCNN 2 种降噪算法输出图像中互补性的局部结构化信息,从而能显著提升降噪效果.

表10 各算法在10 张常用图像上所获得的PSNR 均值(dB)Table 10 Performance comparison of the competing algorithms in terms of PSNR on 10 commonly used images (dB)
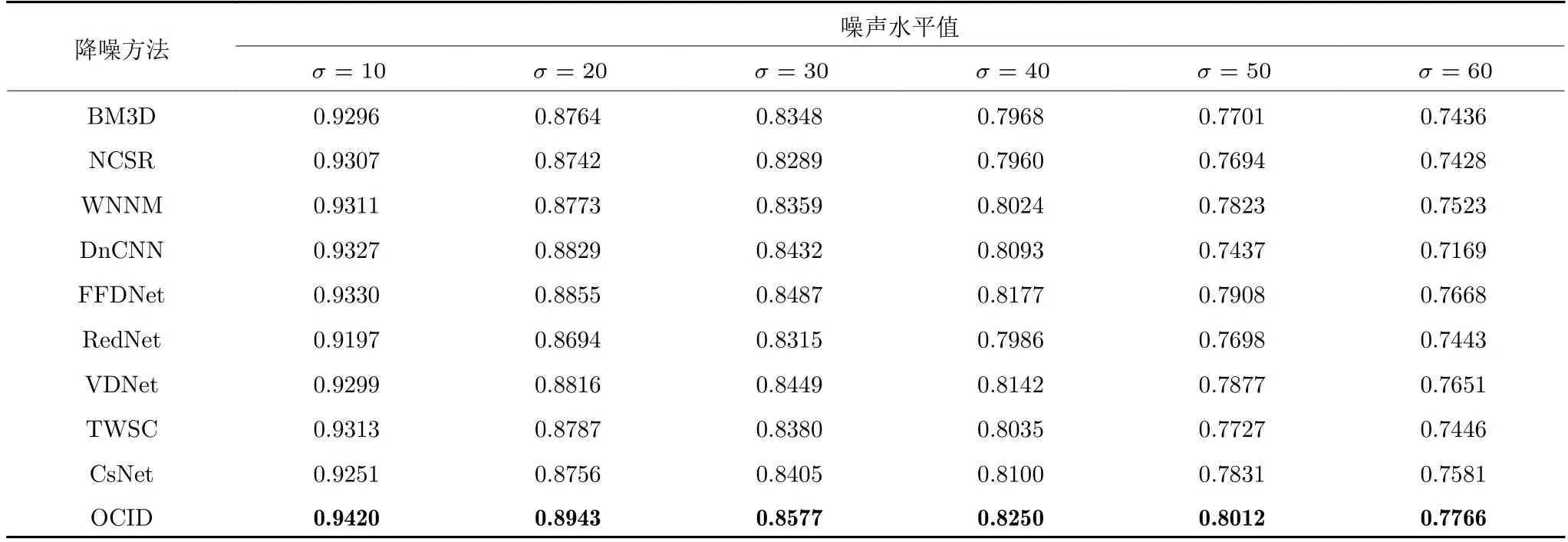
表11 各算法在10 张常用图像上所获得的SSIM 均值Table 11 Performance comparison of the competing algorithms in terms of SSIM on 10 commonly used images
其次,为对比各算法在图像细节内容更为复杂图像上的降噪效果,在BSD 纹理图像集上完成测试.表12 给出了各个算法在BSD 纹理图像集上的测试结果(限于篇幅,仅给出PSNR 指标数据).由表12 可知,虽然相较于表10 中的数据,所提出的OCID 模型的降噪效果有所下降(因处理的图像内容更加困难导致),但其性能仍然是所有参与比较的算法中最好的,比单一FFDNet 算法的降噪效果有显著提升,提升幅度在0.4 dB~1.4 dB 之间,提升量非常可观.OCID 模型所获得的PSNR 指标较CsNet 模型提升了0.5 dB~1.3 dB.OCID 模型使用的基本降噪器是BM3D 和DnCNN,单一BM3D和DnCNN 降噪算法的降噪效果均不是最优,但是将两者同时输入到OCID 组合模型后,却能在降噪质量上有显著提升.这说明OCID 组合模型能充分利用两种降噪算法输出图像各自的互补性优势,从而获得更好的降噪效果.

表12 各算法在BSD 纹理图像集上所获得的PSNR 均值(dB)Table 12 Performance comparison of the competing algorithms in terms of PSNR on BSD database (dB)
再次,为测试OCID 模型能否较好地应用于高分辨率图像的降噪,使用50 张DIV2K 超分辨率图像进行测试,各个对比算法所获得的PSNR 均值见表13.由表13 可知,在所有参与对比的算法中,所提出的OCID 模型的PSNR 指标排名仍然是第一,比CsNet 模型的PSNR 值提高了0.4 dB~1.3 dB,表明所提出的OCID 模型在处理高分辨率图像时仍然具有显著的降噪提升效果.

表13 各算法DIV2K 图像集上所获得的PSNR 均值(dB)Table 13 Performance comparison of the competing algorithms in terms of PSNR on DIV2K database (dB)
最后,为测试各对比算法处理不同图像主题内容时的降噪能力,在图像主题内容更为丰富的Waterloo 图像质量评价测试图像集上完成测试,测试结果见表14.由表14 可知,在各个噪声水平值下,所提出的OCID 模型的PSNR 指标值均为最佳,再次展现出所提出的OCID 模型在降噪效果提升方面的优势,其对不同的图像主题内容均具有很好的普适性.

表14 各算法在Waterloo 图像集上所获得的PSNR 均值(dB)Table 14 Performance comparison of the competing algorithms in terms of PSNR on Waterloo database (dB)
3.4 执行效率
所提出的OCID 模型与CsNet 模型一样,均是利用多个降噪算法作为初步降噪器,将它们输出的图像经优化组合后实现更好的降噪效果,故与单一降噪算法相比它们的执行时间均会显著增加,这里不再给出具体实验数据.相对而言,OCID 模型仅使用BM3D 和DnCNN 2 个算法作为初步降噪器,而CsNet 则使用了BM3D、DnCNN、REDNet 和FFDNet 4 个算法作为降噪器,故OCID 模型在初步降噪阶段的执行时间比CsNet 模型要短.为比较OCID 与CsNet 两个模型在融合阶段的执行效率,分别利用两个模型处理具有不同噪声水平值,大小为512 × 512 像素的Lena 噪声图像,执行10 次,并记录各自在融合阶段的平均执行时间(在GPU环境下测得)于表15.由表15 可知,在融合阶段,OCID模型的执行时间具有显著优势.其原因在于,OCID模型仅采用了结构极为简单的浅层CNN 结构(仅含三层卷积层)实现图像融合,且得到GPU 硬件支持,使得其运行时间可以满足实时应用的要求.而CsNet 模型的融合过程则使用了网络结构非常复杂的MSE 估计器和Booster 模块,网络深度更深,且Booster 模块还需要迭代多次执行才能获得最佳的图像质量,所以即使在GPU 硬件执行条件下,其执行时间仍远远长于OCID 模型.
总之,结合表10~表15 所列数据,OCID 模型在保证获得更好降噪效果的同时最大限度地降低了对计算资源的需求,综合性能更优.

表15 CsNet 与OCID 模型在融合阶段的执行时间对比(ms)Table 15 Execution timein fusion stage of CsNet and OCID model (ms)
4 结论
受Choi等[2]组合多个降噪器提升单一降噪算法降噪效果思想的启发,本文提出一种基于MSCNN的OCID 模型.对于给定的噪声图像,该模型首先利用多个降噪器对其进行降噪以获得多个初步降噪图像,然后由预训练的MSCNN 模型接收这些初步降噪图像并自动完成最优组合(融合),高质量输出优化后的降噪图像.与Choi 等提出的CsNet 组合模型相比,本文所提出的OCID 模型结构更为简单,图像质量提升更为明显,且执行效率更高.需要说明的是,目前OCID 模型使用BM3D 与DnCNN 2种降噪算法作为基本降噪器,而经典BM3D 算法并没有使用GPU 硬件加速能力,这在一定程度上降低了OCID 模型整体的执行效率.未来可将BM3D算法用CNN 卷积化技术实现[31],这样OCID 模型在初步降噪和图像融合两个阶段均可以利用GPU硬件加速能力,可实现实时降噪,这将会使OCID模型较现有的单一降噪算法在降噪效果和执行效率两个方面均具有显著优势.
猜你喜欢
大学数学(2022年6期)2023-01-14
舰船科学技术(2022年21期)2022-12-12
四川大学学报(自然科学版)(2021年6期)2021-12-27
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
劳动保护(2019年3期)2019-05-16
文苑(2015年9期)2015-09-10
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
郑州大学学报(理学版)(2014年4期)2014-03-01
客车技术与研究(2014年6期)2014-02-28
