
分数阶傅里叶变换联合支持向量机的建筑物变形预测
2022-11-30 09:49陈代果
大地测量与地球动力学 2022年12期
古 巍 李 倩 陈代果
1 四川大学锦江学院, 四川省眉山市锦江大道1号, 620860 2 西南科技大学土木工程与建筑学院,四川省绵阳市青龙大道中段59号,621010
目前,建筑物变形预测方法以统计学方法和人工智能算法为主。其中,统计学方法是在对变形数据进行分析处理的基础上,提取其中的规律性信息,并利用确定的数学模型对其建模,常用的有ARMA、ARIMA等时间序列模型及灰色理论模型和卡尔曼滤波等[1-2]。不同于统计学方法,人工智能算法不需要建立精确的数学模型,直接采用数据驱动的方式将时间序列中的变形信息转化为网络结构参数,通过自适应自学习能力对未来的变形趋势进行预测,经典的人工智能算法包括反向传播(back propagation, BP)神经网络[3]、长短时记忆神经网络(long short-term memory neural network, LSTM)[4]和支持向量机(support vector machine, SVM)[5]等方法。其中,BP神经网络具有任意非线性函数逼近能力,其预测性能优于时间序列模型;而SVM采用核函数的方式将低维空间中的非线性问题转化为高维空间中的线性问题,从而提升模型的计算效率及对小样本、非线性问题的适应能力。但BP神经网络和LSTM神经网络的预测性能受网络初值影响较大,且对噪声敏感[6]。
针对建筑物变形数据非平稳和波动性特征,本文基于分解-预测-重构的思想,提出一种基于分数阶傅里叶变换(FrFT)和支持向量机(SVM)的组合预测模型,用于建筑变形趋势预测。实验结果表明,该组合模型相对于单一预测模型能够获得更高的预测精度。
1 组合预测模型
建筑物的变形过程具有非线性、非平稳和波动性特征,单一模型无法在预测过程中准确捕捉这些信息,因此预测精度不高,且噪声稳健性较差。本文结合FrFT处理非平稳时间序列的优势和SVM对小样本、非线性问题的泛化能力,提出一种FrFT-SVM建筑物变形组合预测模型。该组合预测模型首先利用FrFT将复杂时间序列分解为多个简单子序列,同时引入相关向量机(relevance vector machine, RVM)自动确定最优FrFT阶次,并利用SVM对每个子序列分别进行建模预测;同时为了提升预测性能,提出一种改进的果蝇优化算法(improved fruit fly optimization algorithm, IFOA)对SVM核参数和惩罚因子进行全局寻优;最后将每个子序列的预测结果进行综合叠加,得到最终预测结果。
1.1 基于FrFT的变形时间序列分解
FrFT又称为广义傅里叶变换,在保留传统傅里叶变换性质的同时又具备其特有优势,能够同时对时域和频域信息进行分析处理,是非线性、非平稳时间序列分析的强有力工具[7]。
图1在时间-频率二维坐标平面中给出传统傅里叶变换和FrFT之间的关系示意图,其中横坐标代表时间t,纵坐标表示频率f。传统傅里叶变换可以看作是将时间轴按逆时针方向旋转π/2,得到频率轴的一种线性变化,即在(t,f)二维平面内的一种时间序列分析手段;而FrFT可以看作是将时间序列沿逆时针方向旋转任意α角度,得到分数谱f(u)和F(v)的过程,随着α的取值从0变化到π/2,FrFT可以呈现出时间序列从时域向频域逐渐转变的过程。对于(t,f)平面内的非平稳信号,通过将其转换到合适的(u,v)平面能够有效消除交叉项。
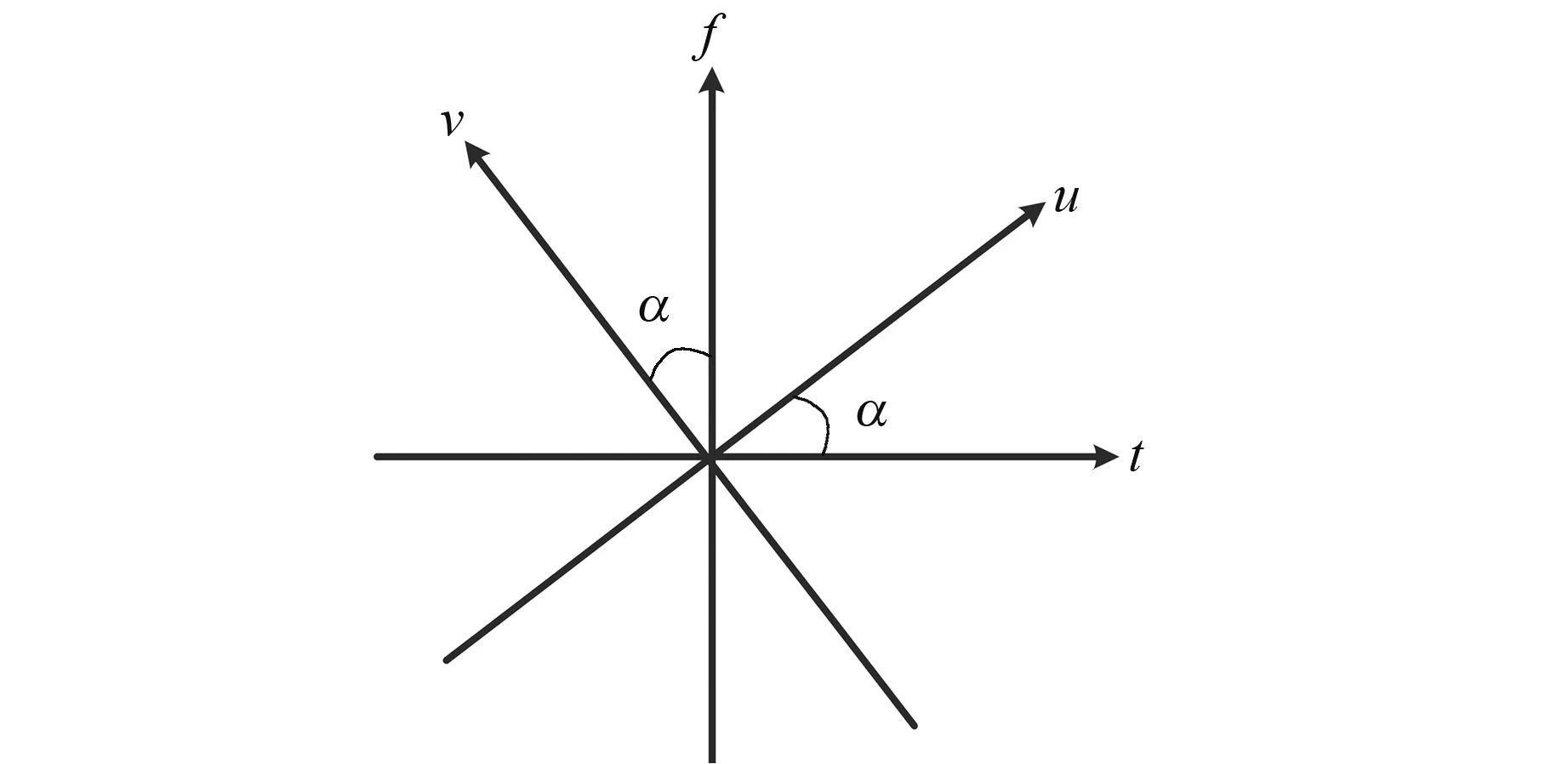
图1 FrFT与传统傅里叶变换关系示意图Fig.1 Schematic diagram of the relationship between FrFT and traditional Fourier transform
对于连续时间序列f(t),对其进行p阶FrFT变换的表达式为:

(1)

由于实际工程实践中处理的都是经采样后的离散序列,因此要对式(1)进行离散化处理,从而得到离散分数阶傅里叶变换(discrete FrFT, DFrFT)。常用的一种FrFT离散化方法为Ozaktas采样方法,首先对原始信号进行时域展开,然后根据Shannon采样定理进行插值,最后得到FrFT的离散化处理结果。对式(1)展开得:

(2)
利用Shannon定理对式(2)中积分项f(t)exp[jπt2cotα]进行插值处理,可将其转化为:
(3)
最后,将式(3)代入式(2),得到原始时间序列f(t)的p阶DFrFTfp(m)为:
(4)
式中,n和m分别为原始时间序列和p阶DFrFT的采样点数,N为时间序列总长度,1/Δx为时间序列采样间隔。
1.2 最优FrFT阶次的确定
根据式(1)~式(4),当DFrFT阶次p=0时,得到的结果为原始时间序列;当p=1时,得到的结果为原始时间序列的频谱。利用DFrFT进行时间序列分析时,通常将p的取值在0.1~0.9范围内按0.1间隔进行遍历,分别得到不同阶次的DFrFT结果。遍历方法虽然简单,但是得到的DFrFT中有些阶次会获得较好的时-频能量聚集特点,能够有效反映时间序列的趋势性和周期性等有用信息,另外一些阶次(例如噪声分量)能量会均匀分布在整个平面内,不包含对趋势预测的有用信息,因此需要一种方法能够自动确定DFrFT中的最优阶次。
相关向量机(relevance vector machine, RVM)是一种贝叶斯框架下的最优分类器,与SVM类似,RVM同样采用核函数的方式将低维空间中的非线性问题映射为高维空间中的线性问题,但同时又具备特有的优势:1)RVM通过引入共轭先验分布的方式增加了模型的稀疏性,因而具有自动特征选择能力;2)RVM模型将特征选择与分类器设计统一为同一个优化问题,具备更强的泛化能力;3)RVM能够提供概率式预测结果,相当于提供了更多的信息;4)RVM核函数的选择不受摩西准则约束。
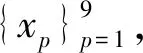
(5)
式中,K(x,xp)为核函数,wp代表不同的权重,ε为0均值高斯白噪声(方差为τ-1)。
RVM通过向分类模型中引入Sigmoid函数的方式实现对目标值的概率预测,此时输入特征向量的似然函数可以表示为:
p(t|w)=
(6)
式中,tp为xp对应的类别标号。
为了构建完整的贝叶斯框架,对模型权值wp引入先验分布,常用的分布形式为高斯分布,即假设wn服从0均值、方差为α-1的高斯分布。由于高斯分布的共轭先验分布为伽马分布,因此采用伽马分布定义α-1和τ-1的超先验值:
(7)
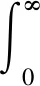
上述RVM模型常用的求解方法为变分贝叶斯期望最大(variational bayesian expectation maximization, VBEM)算法[8],在求解过程中会发现,大部分α会随着迭代的进行逐渐趋于无穷大,对应的w则趋于0,从而实现了权值向量的稀疏化;迭代终止时,不为0的权值对应的特征向量即为要选择的特征。
1.3 改进的IFOA-SVM预测模型
对FrFT分解得到的子序列建立SVM回归模型并进行预测,SVM回归模型具有预测精度高、算法复杂度低及适合于小样本应用等众多优点,利用SVM对变形时间序列进行回归预测的模型可以表示为:
y=ωTφ(x)+b
(8)
式中,φ(x)为非线性映射函数,ω为权值,b为线性偏移量。
SVM采用结构风险最小化准则,将式(8)中模型参数ω和b的求解过程转化为如下优化问题:
(9)
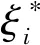
采用拉格朗日乘子法将式(9)转化为:
(10)
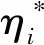
(11)
式中,γ为核参数。
对式(10)进行求解,可以得到最终的SVM回归模型:
(12)
SVM回归模型的预测精度和泛化能力与惩罚因子c及核参数γ的取值密切相关,目前常用的交叉验证法存在运算量大、自动化程度不高等问题。因此,本文将果蝇优化算法(fruit fly optimization algorithm, FOA)[9]与SVM相结合,利用FOA的全局搜索能力对SVM参数进行寻优,提升模型预测性能。同时,考虑到传统FOA采用固定搜索步长,在迭代过程中存在灵活性不足的问题,提出自适应搜索步长方法对其进行改进,得到IFOA算法。利用IFOA算法对SVM进行优化的步骤为:
1)初始化SVM回归模型,设定惩罚因子与核参数的取值范围。
2)设置果蝇种群数量N和最大迭代次数T,将惩罚因子c和核参数γ作为果蝇群体的位置坐标,即
(13)
3)根据式(14)随机赋予果蝇个体搜寻食物的方向和位置:
(14)

4)计算当前果蝇个体与原点之间的距离Di及对应味道浓度判定值Pi:
(15)
5)利用Pi计算得到果蝇所在位置的味道浓度值Si,将当前果蝇群体中味道浓度值最小的果蝇作为最优个体,并记录Si和对应的位置坐标[Xi,Yi]。
6)重复上述步骤,并记录每次迭代过程中最优个体的味道浓度值和空间位置信息,即
(16)
式中,(Xi_best,Yi_best)为第i次迭代果蝇群体中最优个体所处位置,Si_best为对应的味道浓度值。
7)当迭代次数达到最大值T时,步骤6)记录数据中最小浓度值对应的位置信息即为SVM的最优参数组合,即
(17)
1.4 综合预测
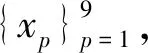
xp=DFrFT(s)p,p=0.1~0.9
(18)

(19)
1.5 组合预测模型的算法流程
组合预测模型首先对时间序列进行0.1~0.9阶次的FrFT分解,并结合RVM的稀疏性和特征选择能力实现对最优K个FrFT阶次的选取,将原始时间序列转化为K个不同时频尺度下的子序列,实现序列关键信息的有效提取;然后分别采用SVM对各个子序列进行训练建模,并通过IFOA算法优化模型参数;最后通过对测试数据的预测结果进行叠加综合,得到实际的预测结果。本文组合模型的算法流程如图2所示,具体步骤可以总结为:
1)将建筑物变形时间序列划分为训练集和测试集;初始化模型参数:FrFT阶次p=0.1,…,0.9,SVM惩罚因子c及核参数γ的取值区间,果蝇种群数量N和最大迭代次数T;
2)在离线模型训练阶段,利用FrFT对时间序列进行分解,并结合RVM特征选择获取最优阶次对应的子序列,利用IFOA选取各子序列的最优参数,训练SVM模型;
3)在在线迭代预测阶段,利用FrFT方法和步骤2)得到的最优阶次,获得K个最优子序列,利用训练阶段获得的最优IFOA-SVM回归模型,对每个子序列进行预测,最后根据式(19)对各子序列预测值进行综合累加,得到真实的建筑物变形预测值。
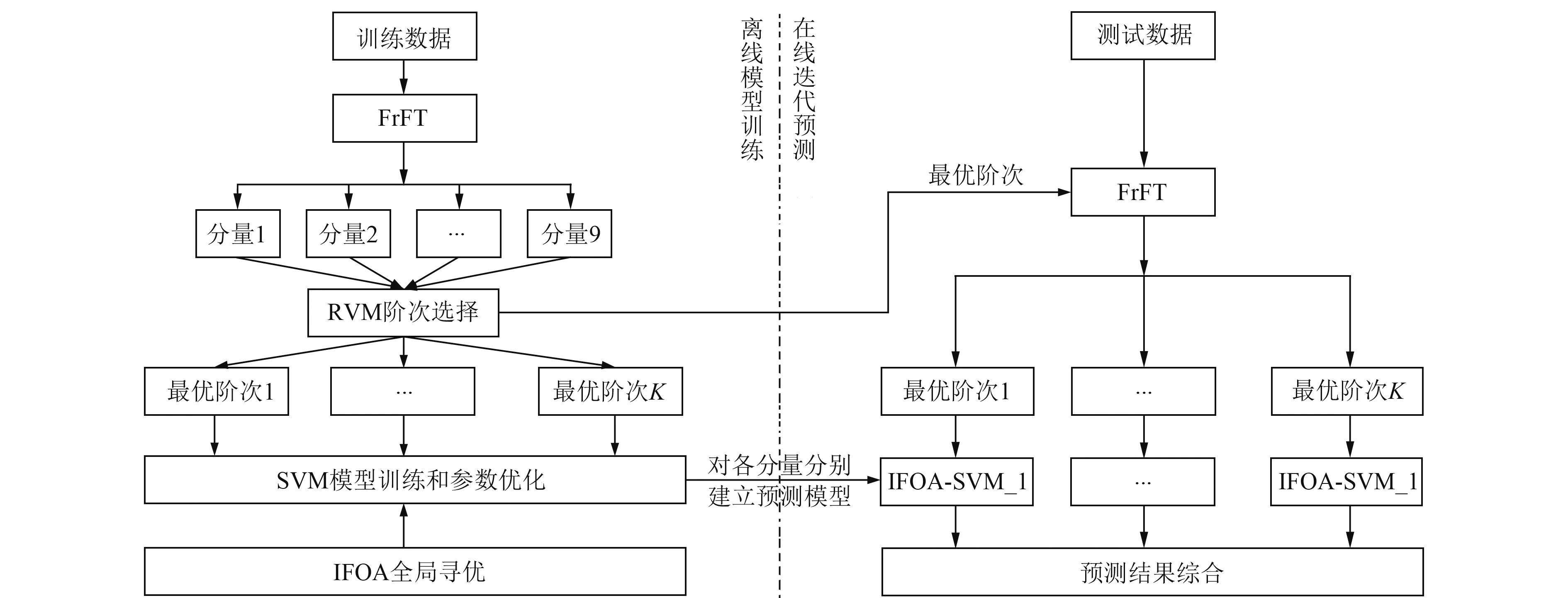
图2 组合预测模型流程Fig.2 Flow chart of combined forecasting model
2 实验及结果分析
2.1 实验数据及模型评估指标
为验证本文组合预测模型在实际使用过程中的预测性能,选用我国西南地区某混凝土大坝2003-01~2005-02期间水平位移数据开展实验,采样检测1月/期。该大坝总共布设6个水平位移监测点,经过数据分析发现各监测点的水平位移变化规律大致相同,因此本文选择具有代表性的3号监测点记录的数据进行分析(图3)。可以看出,在前5期和第8~15期观测周期内,大坝位移变化较为平缓,其余时间变化较大,呈现出典型的非线性、非平稳和波动性特征。
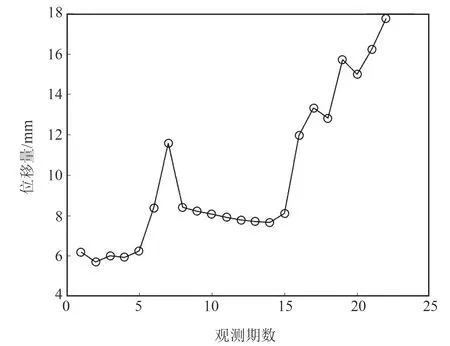
图3 大坝变形原始时间序列Fig.3 Original time series of dam deformation
为定量评估本文组合模型的变形预测精度,采用预测值与真实值之间的相对误差(relative error, RE)和均方根误差(root mean square error, RMSE)作为评估指标:
(20)
(21)
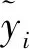
2.2 组合模型预测结果
根据图2所示流程,首先需要对变形时间序列进行0.1~0.9阶次的FrFT分解,并结合RVM的稀疏性和特征选择能力实现对最优K个FrFT阶次的选取。图4给出利用VBEM算法求解RVM模型,在迭代终止时权值向量的取值结果,可以看出,经RVM特征选择后,阶次为0.3、0.7和0.8的3个子序列对应的权值较大,其余阶次子序列对应的权值均接近于0。图5给出0.3阶、0.7阶和0.8阶子序列波形,对比图4和5可以看出,RVM选出的3个子序列都包含了原始序列中的不同维度信息:0.3阶子序列波形变化比较剧烈,且数据之间的关联性较弱,反映出原始序列中的波动性特性;0.7阶子序列呈现出较明显的上升趋势,反映原始序列中的趋势性信息;0.8阶子序列表现出一定的周期性,反映原始序列中隐含的周期性信息。上述结果表明,经过FrFT分解后,每个子序列都从不同维度反映了原始序列中的变形信息,对原始序列进行FrFT分解的过程有效弱化了对不同信息进行分析时的相互干扰和相互影响,且每个子序列的波形变化曲线相对于原始曲线更加简单平滑,降低了后续预测模型的复杂度。

图4 RVM阶次选择结果Fig.4 Order selection results of RVM
根据图2所示算法流程,在FrFT完成时间序列分解后,利用IFOA-SVM对每个子序列分别进行建模预测。实验中,将前12期数据作为训练样本用于IFOA-SVM建模和参数优化,剩余9期数据作为测试样本,得到的预测结果如图6(a)~6(c)所示,图6(d)给出对每个子序列结果综合叠加后得到的最终预测结果。
从图6可以看出,组合模型通过FrFT分解能够深度挖掘数据中隐含的物理规律信息,使分解后的每个子序列呈现出较为简单平滑的变化趋势,从而明显降低后续预测难度,提升预测性能。根据式(20)和式(21)可以计算得到预测结果的最大RE为1.33%,RMSE为0.072 9。
2.3 与其他预测方法比较分析
表1给出在相同条件下分别采用组合预测模型、SVM、GM(1,1)和LSTM四种模型进行预测得到的结果和对应的预测残差。对表1所示结果进行分析可知,传统灰色GM(1,1)预测模型在初期能够获得较高的预测精度,但随着预测时间的增长,其预测性能出现了较大波动,预测模型的最大RE为8.46%,RMSE为0.634 1;SVM模型的预测精度要略高于GM(1,1)模型,其预测结果的最大RE为3.17%,RMSE为0.343 3;LSTM在进行变形预测时会加入对前期位移数据的回忆,具备动态预测能力,因此相对于GM(1,1)模型和SVM模型的预测性能出现明显提升,其预测结果的最大RE为2.65%,RMSE为0.230 8,能够满足实际工程应用要求的预测精度,而本文组合模相对于LSTM模型性能提升超过120%,具有更好的应用前景。
图5 FrFT分解结果Fig.5 FrFT decomposition results

图6 组合模型预测结果Fig.6 Predictionresults of the combined model
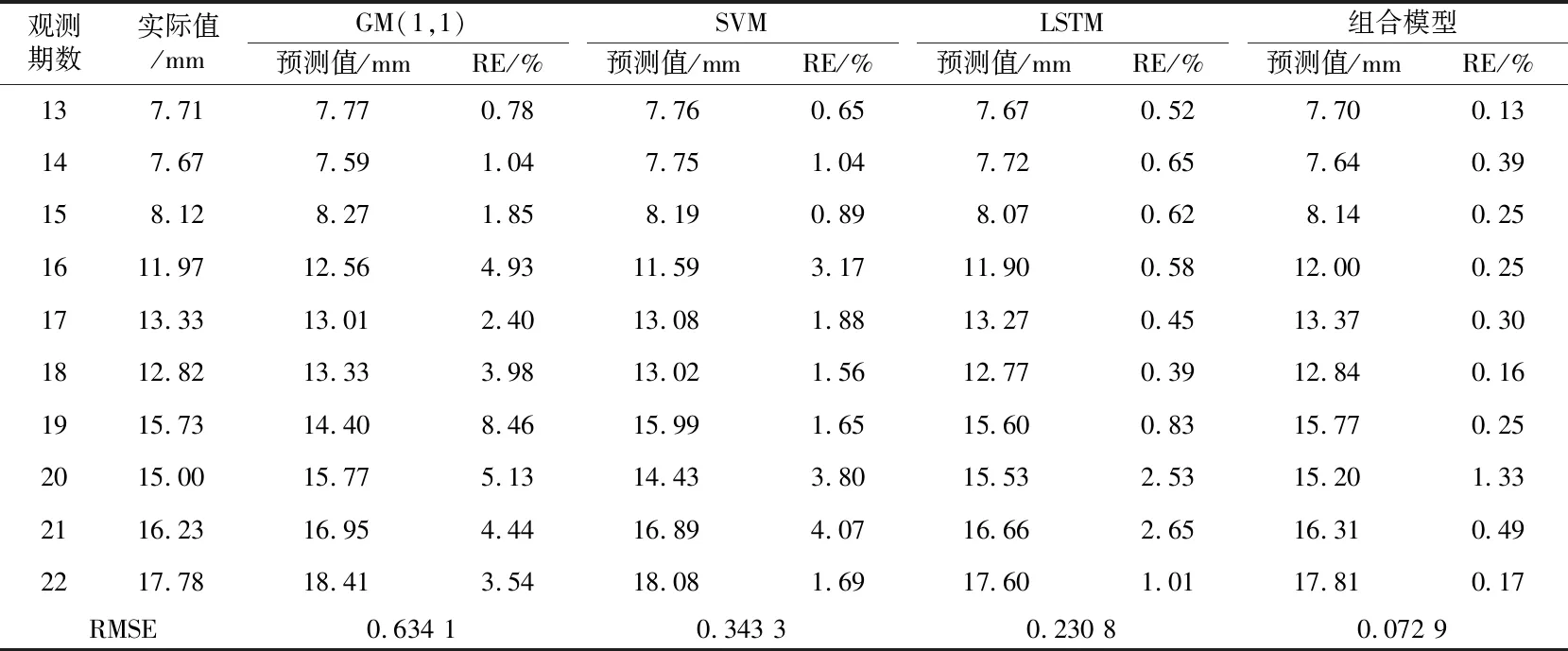
表1 不同方法的预测结果
3 结 语
建筑物变形数据是一种典型的非线性、非平稳和波动性时间序列,传统基于单一模型的预测方法由于无法充分挖掘数据中的隐含信息,存在预测精度低、噪声稳健性差的问题。本文基于分解-预测-重构的思路,利用FrFT结合RVM将复杂变形数据分解为K个结构简单子序列,进而利用IFOA-SVM对每个子序列进行建模预测,通过叠加综合获得最终预测结果。实验结果表明,组合预测方法能够获得更高的预测精度和噪声稳健性,相对于单一模型具有更为广阔的应用前景。
猜你喜欢
学苑创造·A版(2022年3期)2022-03-29
烟台果树(2021年2期)2021-07-21
智慧少年·故事叮当(2020年10期)2020-11-06
中华诗词(2020年1期)2020-09-21
汽车实用技术(2019年24期)2019-12-27
组合机床与自动化加工技术(2019年7期)2019-08-06
学苑创造·A版(2019年6期)2019-07-11
福建基础教育研究(2019年2期)2019-05-28
小学生作文(中高年级适用)(2018年5期)2018-06-11
价值工程(2017年28期)2018-01-23
