
智能计算服务的需求获取方法
2022-11-30 08:39汪烨周澳回周思源姜波陈骏武宋师哲
计算机应用 2022年11期
汪烨,周澳回,周思源,姜波,陈骏武,宋师哲
智能计算服务的需求获取方法
汪烨,周澳回,周思源*,姜波,陈骏武,宋师哲
(浙江工商大学 计算机与信息工程学院,杭州 310018)(∗通信作者电子邮箱3508006105@qq.com)
智能计算服务由服务提供者通过互联网为服务消费者提供数据的分析和处理,并建立学习模型完成智能计算功能。由于服务提供者与服务消费者之间缺乏有效的沟通渠道,以及服务消费者反馈的需求描述模糊、混乱,目前缺乏一种统一的服务需求获取方法对用户持续变化的需求进行有效的分析、组织和规约,导致智能计算服务无法根据用户的需求进行快速改进。针对服务开发中需求变更的持续性和不确定性等问题,提出了一种智能计算服务的需求获取方法。该方法首先从Stack Overflow问答论坛获取智能计算服务的应用反馈和问题,然后根据服务消费者所关注的需求类型采用不同的学习模型(包括支持向量机(SVM)、朴素贝叶斯和TextCNN)对其进行知识分类和优先级排序,最后采用自定义的服务需求模板统一描述智能计算服务的需求。
服务需求工程;需求获取;智能计算服务;机器学习;神经网络
0 引言
随着Web服务技术、移动网络计算和社交网络的快速发展,服务在企业应用的开发中显得愈发重要,包括谷歌、Facebook、Netflix、eBay、LinkedIn、Foursquare、Instagram在内的很多企业都发布了公共服务。基于服务的开发通过组合调用服务来避免开发所花费的成本和精力。近年来人工智能不断地突破与创新,基于人工智能提供的相关计算服务(本文简称为“智能计算服务”)也迎来了新一轮的革新与更迭。智能计算服务由服务提供者通过互联网为服务消费者提供数据的分析和处理,通过建立学习模型完成智能计算功能[1]。
智能计算服务面临用户需求、软件资源和系统上下文环境等方面变化的挑战,其服务需求不可避免地需要持续的变更。实践研究表明,在消费者需求更多元以及服务复杂性逐步增长的情况下,服务开发中的需求并不是静态的,而是持续的、不确定性的。这些需求不仅是由服务消费者显式地向提供方提出的需求,更多的是由服务使用体验和使用过程中等隐式发现的需求[2]。智能计算服务目前在开发时往往会面临服务需求如何快速获取和改进的问题。一方面,由于服务提供者与服务消费者之间缺乏有效的沟通渠道,服务消费者难以将智能计算服务的用户体验尽快地反馈给服务提供者,从而导致服务提供者无法及时地获取服务需求;另一方面,服务消费者对于需求的描述模糊且混乱,目前缺乏一种统一的服务需求定义方法来对用户持续变化的需求进行有效的组织和规约,导致智能计算服务无法迅速地根据用户的需求获取真正有价值的用户需求从而快速改进。服务需求获取的任务就是找出更多的可以满足用户的需求并详细说明用户持续变化的需求,这是决定智能计算服务开发成败以及服务推广和应用的关键。这不仅能够增强服务提供者和消费者对智能计算服务产品特征在细节与相互依赖关系上的理解以及对需求的掌握,还可使服务涉众之间的交流更为紧密以减少交流误解与偏差,更加准确地反映服务开发情况,为服务开发决策提供依据[3]。
服务需求工程是指采用工程化方法指导网络化的服务软件需求的挖掘、建模、分析、描述和管理[4]。目前服务需求工程集中在服务需求的建模、分析阶段[1,5-7],对于获取有价值的服务需求后将其规范描述的研究很少。根据调研,尚未有工作针对智能计算服务研究其需求获取方法,因此本文提出了一种智能计算服务的需求获取方法。首先从Stack Overflow(https://stackoverflow.com/)问答论坛上爬取服务消费者关于智能计算服务的用户反馈和问题,然后对其进行知识分类、优先级排序,最后采用自定义的需求模板统一描述智能计算服务的需求。针对该问题的深入研究对提高和保障智能计算服务产品的质量具有重要的研究意义。
1 相关工作
服务需求是否准确、完整和规范将影响整个服务的开发流程与效果,越来越多的研究开始侧重于服务需求工程。服务需求工程方法包括服务需求的挖掘、建模、分析、描述和管理等具体技术,本章将针对这些技术做具体介绍。Penserini等[8]提出了一种基于Tropos的扩展方法并将其制定为服务设计,将利益相关者目标与服务集合相关联,促进服务目标的迭代。Chen等[5]提出了一种基于领域目标模型和过程模型的个性化服务需求分析法,该方法面向最终服务涉众,以服务涉众的操作为驱动,对涉众的操作进行分类,定义相应的检测类型以及流程,制定规则以满足涉众的服务需求。Mouheb等[6]提供了一种可视化方法对服务功能需求和服务质量需求进行整合建模。Wang等[1,9]提出了基于业务流程模型的服务质量需求分析方法ProQRASS以及基于工作流模式的服务需求分析法PASER,解决了服务需求中的质量需求和功能需求不一致的问题。Sun等[7]提出的QRA(Quality Requirements Analysis)方法从服务涉众的角度(即早期服务质量需求)分析服务质量需求。为了更适配服务系统的需求分析,Wang等[10]提出了一个基于本体的服务需求建模框架,由本体、角色、目标、过程以及服务五个层次组成。Garg等[11]提出了一种基于非功能性需求的云服务采用方法TrAdeCIS,建立了权衡决策,根据非功能性需求选择最佳可用的替代模型。
服务需求变更是贯穿服务整个生命流程的一种循环过程,该循环过程是由环境变化驱动的。随着服务计算系统的发展流行,面向服务的需求获取逐渐得到了研究人员的重视。Zhang等[12]提出了一个基于RGPS(Role,Goal,Process,Service,即角色、目标、过程以及服务)的面向服务需求获取框架,用于捕捉需求生成中的关键建模知识和构建管理需求的原则,确定环境变化、需求变化、观点变化和设计变化四种基本变化类型以帮助控制和监测需求的变更。
需求知识分类指对收集到的多种需求知识信息进行分类。由于传统需求分类方法在完整性、准确性以及效率方面存在缺陷,越来越多的研究工作在需求分类方法中融合人工智能技术,包括基于信息检索[13-14]、基于机器学习[15-16]以及基于深度学习的方法[17]。关键字匹配、最邻近节点算法、朴素贝叶斯、K‑means、相似度计算、逻辑回归、神经网络、TextCNN、长短期记忆(Long Short‑Term Memory, LSTM)和门控循环单元(Gate Recurrent Unit, GRU)被广泛使用。
上述算法和模型为本文的研究提供了思路,本文的主要工作如下:
1)采用知识弥补用户问题和服务需求之间的鸿沟,并明确定义了问题、知识、需求的概念。
2)针对智能计算服务需求覆盖范围广等问题,更细化地定义了11种功能和1种非功能方面的知识类别及其概念解释。
3)采用支持向量机(Support Vector Machine, SVM)、朴素贝叶斯和TextCNN等传统机器学习方法进行有效分类,发现TextCNN方法的效果最好。
4)对需求生成的情况进行了有效分析,制定了不同的需求描述模板,并通过具体例子进行解释说明。
2 方法框架

基于上述概念,本文在智能计算服务的需求获取过程中对Stack Overflow问答文档进行了分析,步骤如下:
1)面向智能计算服务的知识类别定义。综合分析已有需求分类,定义了11种功能和1种非功能方面的知识类别,同时针对智能计算服务的特点,增加可解释性作为新的知识类别。
2)面向智能计算服务问答数据的挖掘。调研已有智能计算服务市场,主要以用户问答数据的数量和质量为参考标准,选取了TensorFlow这款全球最热门的开源机器学习服务平台作为爬取对象,构建数据集,并对其进行预处理。
3)采用机器学习(SVM和朴素贝叶斯)、深度学习模型TextCNN分别对问答数据进行知识分类,同时对比三种模型,探讨不同模型在精确率(Precision)、召回率(Recall)和F1值上的分类效果。
4)根据知识分类,对问题进行优先级排序。
5)筛选排序靠前的服务需求知识,基于不同分类的需求模板对其进行扩展补充,生成新的需求。
3 智能计算服务的需求获取方法
3.1 面向智能计算服务的知识类别定义
综合考虑现有需求分类的类别[18-20]以及智能计算服务的特点,本文定义了12种知识类别:
1)功能性:智能计算服务要满足用户目标或期望应具有的条件或权能。
2)可靠性:智能计算服务在部分组件(一个或多个)发生故障时仍能正常运作的能力。
3)合法性:智能计算服务的功能是否符合法律或规定。
4)外观体验:消费者对智能计算服务操作外观或者操作界面的期望。
5)可维护性:智能计算服务可被修改的能力,包括修正、改进或该功能对环境、需求变化的适应。
6)操作性:消费者在使用智能计算服务时遇到的操作问题。
7)性能:智能计算服务是否能达到消费者的性能目标。
8)移植/兼容:智能计算服务从一个平台或环境移植到另一个平台或环境上的难易程度。
9)扩展性:智能计算服务为了应对将来需求变化而提供的一种扩展能力。
10)安全性:智能计算服务及其数据不会因偶然的或恶意的原因而遭到破坏、更改、显露。
11)易用性:服务消费者是否容易使用该智能计算服务。
12)可解释性:在特定的任务中,通过可视化、参数分析及实验解释智能计算服务中的模型行为。
3.2 面向智能计算服务问答数据的挖掘
智能计算服务问答数据是指Stack Overflow论坛关于TensorFlow服务平台的问答数据,本文采用Web Scraper工具,以数据质量、用户问题数、用户答复数、数据更新时间为导向,爬取了16 405条原始问答数据,针对每条问题,爬取包括问题编号、问题主题、问题陈述、答复、答复数、答复赞同数这六类信息,并根据用户的问答内容进行过滤。需要说明的是,服务消费者提问中的问题并不全是需求,有些是用户不会操作或者缺乏经验引发的问题,这些问题在发布版本中可能已被解决,也有可能未解决,对于已被解决的问题不列入本文考虑范围,对于未解决的问题将其视为操作性知识。通过对16 405条数据进行筛选和过滤,最终选择2 213条与需求相关的问答数据。通过对这2 213条数据进行分析后发现,用户在描述问题时经常通过粘贴代码阐述问题,过多关注代码将会影响计算机对于问题的理解。通过分析Stack Overflow上的问答数据,发现大部分问题的详细阐述会集中于问题陈述的前两句和后两句,因此本文选择问题陈述的前两句和后两句自然语言文本作为其问题陈述,将精简后的问题陈述与问题主题合并后共同作为问题数据。对上述信息进行数据清洗与过滤等预处理,去除自然语言描述中的乱码、符号等数据,构建TensorFlow用户问答数据集。
本文将2 213条数据分为1 770条训练数据和443条测试数据,由多名标注者分别进行标注,标注的类别为12种预先定义好的知识类别,并由作者对标注结果进行验证,出现分歧时,选取投票最高的结果作为最终标注结果。
3.3 基于学习模型的问答数据知识分类
目前针对文本问答数据知识分类研究工作所使用的模型主要以统计机器学习模型为主,随着深度学习的迅速发展,也出现了基于神经网络的知识分类研究,为了探索在Stack Overflow用户问答数据上的知识分类有效性,选取了在相关工作中使用最多的SVM、朴素贝叶斯和TextCNN作为主要方法。这些方法在传统软件系统的功能需求分类和非功能需求分类中已被证明效果不错,例如SVM方法在应用商店评论的分类中精确率和召回率最高可达58%和49%,基于EM的朴素贝叶斯分类算法在对功能性和非功能性需求的分类中正确率可达70%,TextCNN方法在DOORS文档数据库的需求分类中精确率和召回率最高可达73.3%和88.5%。对于统计机器学习模型,使用词频‒逆文档频率(Term Frequency‑Inverse Document Frequency, TF‑IDF)对文本特征值进行提取,它是判断某个词汇对于整个语料库中某个文档重要性的方法。本文采用的SVM和朴素贝叶斯分类方法均需先使用TF‑IDF对文本特征值进行提取。
3.3.1SVM
SVM[20]是一种基于结构风险最小化的机器学习算法,实现对线性可分的数据分类。
而在线性不可分的情况下,SVM会先将输入的向量映射到高维特征向量空间中,再在该特征空间中构造最优分类面。
3.3.2朴素贝叶斯
朴素贝叶斯[21]分类以贝叶斯定理为基础,假设特征词之间相互独立,通过训练数据集学习输入到输出的联合概率分布,获得分类模型。

3.3.3TextCNN
TextCNN[22]是一种用于文本分类的卷积神经网络模型架构,包括输入嵌入层、卷积层、池化层和全连接层。
输入嵌入层是将以自然语言描述的词语文本转换为数值形式以适配输入,实现卷积处理。由于Word2Vec模型适用性强、响应速度快,本文选择Word2Vec模型生成词向量。
卷积层实现卷积计算,TextCNN将原CNN技术处理图像应用的二维卷积计算改进为适用于一维文本数的卷积计算。由于不同尺寸的卷积核得到的特征图(Feature_Map)大小不一,对特征使用池化函数,使它们的维度相同。本文选择1‑Max‑pooling池化函数,从而更好地提取特征信息。
全连接层将上层采用池化函数池化后的结果拼接起来,使用Softmax函数得到属于每个类的概率,通过概率值即可得到所对应的知识类别。
3.4 基于知识分类的问题优先级排序

3.5 生成需求
上述步骤形成的候选需求只是用户的原始描述,并不能直接用于需求说明,因此还需对其进行扩充和规范化。需求生成分为三种情况:1)对于没有答复的问题,直接使用问题和问题陈述包含的信息来扩充需求;2)对于只有一个答复的问题,结合问题和答复包含的信息扩充需求;3)对于拥有多个答复的问题,选择问题以及同意数最多的答复扩充需求。
由于不同的需求描述方法不同,我们调研了需求工程领域相关工作[23-25],并对其进行分类和归纳,制定了不同的需求描述模板(如表1)。对于非功能需求的获取,基于其常用指标,制定了定性和定量的描述模板。例如,根据可靠性指标(如平均失效间隔(Mean Time Between Failures, MTBF)、平均恢复时间(Mean Time To Repair, MTTR)和平均无故障时间(Mean Time To Failure, MTTF)),性能指标[23](如时间、吞吐量、容量需求和其他指标),可移植性指标(如代码变更率、安装成功率、界面适应力、功能完整性),可维护性指标(如圈复杂度、代码行数、可维护性指数、继承层次数、类耦合度和单元测试覆盖率),本文分别制定了智能计算服务的可靠性、性能、可移植性和可维护性需求的描述模板,如表1所示。
对于功能和操作性需求生成,目前采用最多的描述模板是用例和用户故事,由于用例涉及的需求信息涉及具体步骤,而Stack Overflow获取的数据只能反映出用户的目标和期望,因此采用用户故事作为模板更合适。在进行需求协商确定需求后,可再由需求分析人员根据用例模板做进一步扩充。合法性、外观体验、安全性、易用性和可解释性虽然属于非功能性,但其描述特征更偏向于功能需求,因此本文对用户故事做了简单的扩展,以适配上述五个不同的非功能需求。本文结合目前使用广泛的安全性用户故事(security‑ related user story)[24]作为安全性需求的描述模板。易用性需求的描述在用户故事的基础上,扩展了易用性机制[26],包括系统状态、警告、长时间操作、中止命令、中止操作、返回、文本输入、循序渐进、用户偏好、喜爱和帮助。根据文献[25],可解释性包含两个方面:一方面是模型本身的可解释性,一方面是模型预测结果的可解释性。因此,本文设计的可解释性用户故事模板包含了这两个方面。
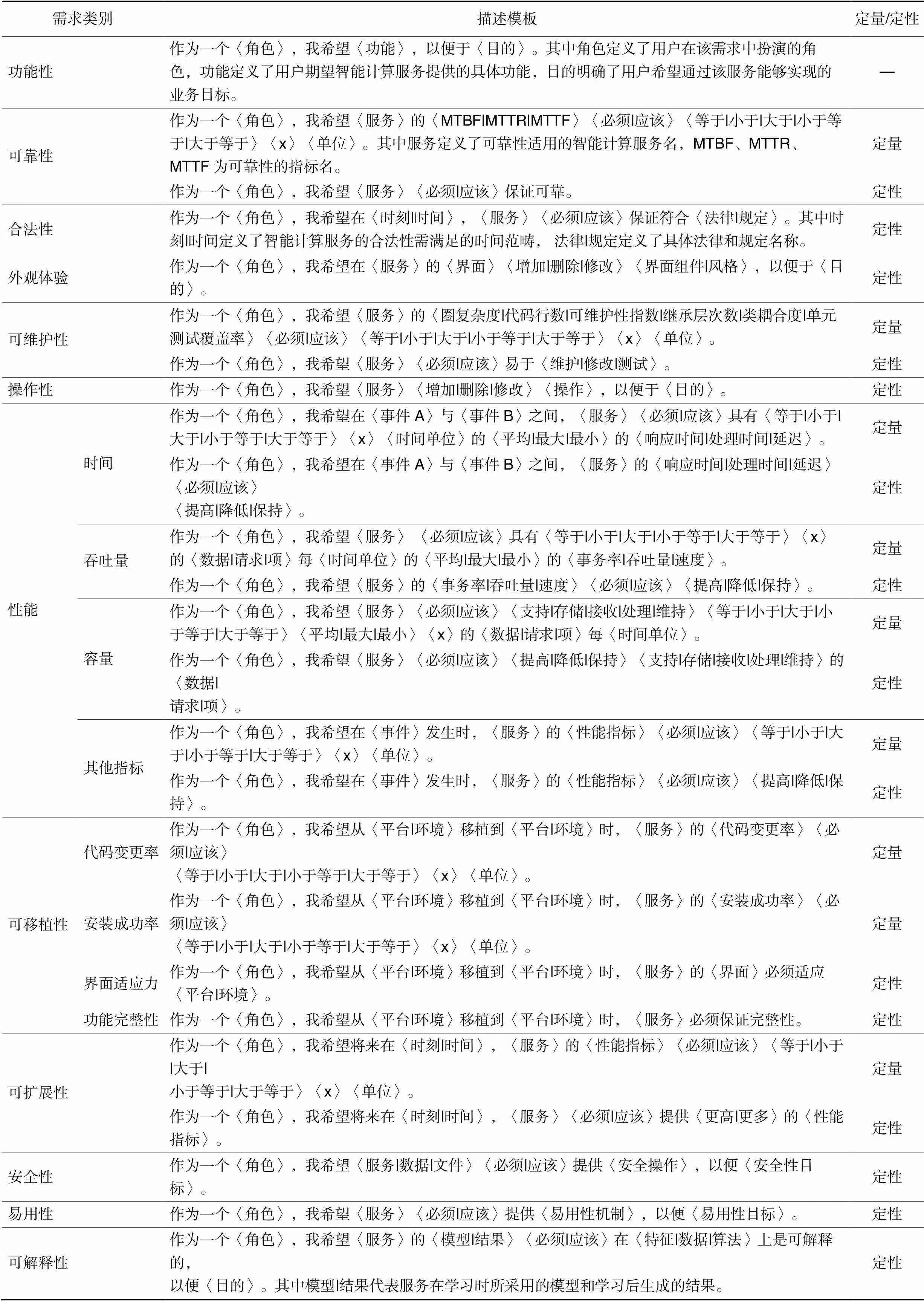
表1 服务需求描述模板
4 实验及结果分析
为了验证本文工作,以TensorFlow智能计算服务为案例。该实验主要回答以下两个研究问题:
1)Stack Overflow文档中是否包含智能计算服务的需求信息;服务消费者在使用智能计算服务时,更关注哪些需求。
2)本文在基于Stack Overflow问答数据做知识分类时哪种方法效果更好,为此选择精确率、召回率和F1值三个指标对SVM、朴素贝叶斯和TextCNN进行客观评价。
4.1 实验数据
本文选取了开源智能计算服务TensorFlow在开发人员常用网站Stack Overflow上的问答数据进行了实验验证。选择TensorFlow的原因为:应用较为广泛,在开源深度学习服务排名中位列第一,在Stack Overflow上能获取大量关于该服务的使用问答数据。
4.2 Stack Overflow文档中智能计算服务的需求信息统计
本文对TensorFlow的问答数据进行了分析和人工标注,基于得到的16 405条问答数据,从中选择2 213条需求信息较为明显的问题及回答作为实验数据,对其进行知识分类,标注结果如表2所示。从表2可以看出,用户在问答论坛上对于TensorFlow在操作性需求和功能性上的关注度更高,在安全性、合法性、外观体验和可维护性上的关注度较少,甚至无关注。
4.3 分类模型对比分析
4.3.1分类模型设置
对于统计机器学习模型,本文使用TF‑IDF方法提取文本特征作为输入。
1)SVM是一种有监督机器学习方法,是通过学习数据之间的最大超平面距离进行数据划分,同时为了解决非线性不可分问题,增加采用核函数方法将原本线性不可分数据映射到更高维的向量空间中,以帮助进行有效分类。
2)朴素贝叶斯是基于贝叶斯理论的机器学习方法,是通过假设属性之间相互独立,通过求解各个属性的概率值进行划分决策。
3)TextCNN使用了深度学习框架:TensorFlow实现深度学习模型。其超参数设置为:训练轮数(Epoch)=20,学习率(Learning Rate)=0.001,批大小(Batch Size)=32,卷积核大小分别为3、4、5,丢弃率(Dropout)=0.5,优化器为Adam。
表2标注结果
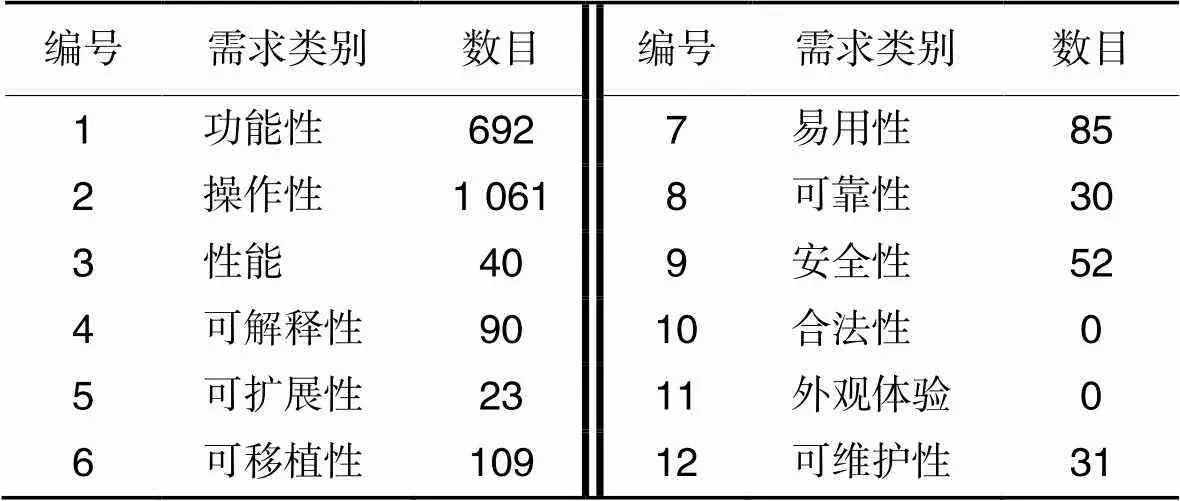
Tab.2 Result of labeling
4.3.2评价指标
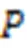

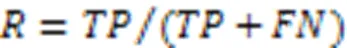

其中:为包含正确地分类到该类别的知识数量,为在该类别中不正确地分类的知识数量;为不正确地没有分类在该类别中的知识数量。
4.3.3结果分析与讨论
实验结果如图1所示,SVM在精确率上的结果最优,因为SVM适合小样本、非线性和高维模式的识别,故在一定程度上可以较好地对文本数据进行分类。TextCNN在召回率上表现较好,因为它在网络结构简单的基础上引入了已训练好的词向量,能更好地抓取文本特征,得到了较好的结果,但数据噪声大且训练数据较少,在一定程度上对结果造成影响。朴素贝叶斯效果最差,因为它对数据的表达形式敏感。

图1 实验结果
4.4 实验数据
由于TextCNN在Stack Overflow问答数据上的表现最好,因此选择TextCNN做知识分类,并采用3.4节步骤排序和3.5节步骤生成需求,结果如表3所示。
表3服务需求描述实例

Tab.3 Instances of service requirement descriptions
5 结语
本文提出了一种面向智能计算服务的需求获取方法,通过对Stack Overflow上的问答数据进行挖掘分析,及时有效地获取用户对于智能计算服务的需求反馈,采用智能化方法对其进行分类,根据分类的结果采用适当的需求模板进行新需求的定义,最后为开发人员形成可供参考的服务需求,帮助其进行服务开发。
下一步工作包括:首先,研究其他深度学习方法在Stack Overflow数据集上的表现,如BERT、循环神经网络等;同时开发自动化的服务需求定义技术,能够使需求分析人员从分类好的服务需求知识中自动提取有用信息,并映射到服务需求模板中。在实验上,我们将爬取更多智能计算服务如Pytorch在Stack Overflow上的问答数据进行验证。其次,对数据集进一步标注,区分不同的智能计算服务和用户种类,研究不同应用和用户。
[1] WANG Y, YANG X H, WANG X Y, et al. ProQRASS: a process‑ based approach to quality requirements analysis for service systems[J]. International Journal of Software Engineering and Knowledge Engineering, 2013, 23(7): 943-962.
[2] SOUZA V E S, LAPOUCHNIAN A, ANGELOPOULOS K, et al. Requirements‑driven software evolution[J]. Computer Science ― Research and Development, 2013, 28(4): 311-329.
[3] 张圣. 软件开发工程中需求分析重要性之探析[J].科技信息,2008(18):75-75(ZHANG S. Exploration of importance of requirements analysis in software development engineering[J]. Science and Technology Information, 2008(18): 75-75.)
[4] BANO M, ZOWGHI D, IKRAM N, et al. What makes service oriented requirements engineering challenging? a qualitative study[J]. IET Software, 2014, 8(4): 154-160.
[5] CHEN H F, HE K Q. A method for service‑oriented personalized requirements analysis[J]. Journal of Software Engineering and Applications, 2011, 4(1): 59-68.
[6] MOUHEB D, TALHI C, NOUH M, et al. Aspect‑oriented modeling for representing and integrating security concerns in UML[M]// Software Engineering Research, Management and Applications. Berlin: Springer, 2010: 197-213.
[7] SUN J, ZHAO L P, LOUCOPOULOS P, et al. QRA: a quality requirements analysis approach for service systems[C]// Proceedings of the 2013 IEEE International Conference on Services Computing. Piscataway: IEEE, 2013: 25-32.
[8] PENSERINI L, PERINI A, SUSI A, et al. From stakeholder needs to service requirements[C]// Proceedings of the 2006 Service‑ Oriented Computing: Consequences for Engineering Requirements. Piscataway: IEEE, 2006: No.8.
[9] WANG Y, WANG T,SUN J. PASER: a pattern‑based approach to service requirements analysis[J]. International Journal of Software Engineering and Knowledge Engineering, 2019, 29(4): 547-576.
[10] WANG J, HE K Q, LI B, et al. Meta‑models of domain modeling framework for networked software[C]// Proceedings of the 6th International Conference on Grid and Cooperative Computing. Piscataway: IEEE, 2007: 878-886.
[11] GARG R, NAUDTS B, VERBRUGGE S, et al. Modeling legal and regulative requirements for ranking alternatives of cloud‑based services[C]// Proceedings of the IEEE 8th International Workshop on Requirements Engineering and Law. Piscataway: IEEE, 2015: 25-32.
[12] ZHANG S L, YIN J S, LIU R. A RGPS‑based framework for service‑oriented requirement evolution of networked software[C]// Proceedings of the IEEE 3rd International Conference on Communication Software and Networks. Piscataway: IEEE, 2011: 321-325.
[13] CLELAND‑HUANG J, SETTIMI R, ZOU X C, et al. Automated classification of non‑functional requirements[J]. Requirements Engineering, 2007, 12(2): 103-120.
[14] SHARMA V S, RAMNANI R R, SENGUPTA S. A framework for identifying and analyzing non‑functional requirements from text[C]// Proceedings of the 4th International Workshop on Twin Peaks of Requirements and Architecture. New York: ACM, 2014: 1-8.
[15] LI C Y, HUANG L G, GE J D, et al. Automatically classifying user requests in crowdsourcing requirements engineering[J]. Journal of Systems and Software, 2018, 138: 108-123.
[16] CASAMAYOR A, GODOY D, CAMPO M. Identification of non‑ functional requirements in textual specifications: a semi‑ supervised learning approach[J]. Information and Software Technology, 2010, 52(4): 436-445.
[17] GUZMAN E, EL‑HALIBY M, BRUEGGE B. Ensemble methods for App review classification: an approach for software evolution[C]// Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering. Piscataway: IEEE, 2015: 771-776.
[18] 王莹,郑丽伟,张禹尧,等. 面向中文APP用户评论数据的软件需求挖掘方法[J]. 计算机科学, 2020, 47(12):56-64.(WANG Y, ZHENG L W, ZHANG Y Y, et al. Software requirement mining method for Chinese APP user review data[J]. Computer Science, 2020, 47(12): 56-64.)
[19] 贾一荻,刘璘. 中文非功能需求描述的识别与分类方法研究[J]. 软件学报, 2019, 30(10):3115-3126.(JIA Y D, LIU L. Recognition and classification of non‑functional requirements in Chinese[J]. Journal of Software, 2019, 30(10): 3115-3126.)
[20] KURTANOVIĆ Z, MAALEJ W. Automatically classifying functional and non‑functional requirements using supervised machine learning[C]// Proceedings of the IEEE 25th International Requirements Engineering Conference. Piscataway: IEEE, 2017: 490-495.
[21] KHAN J A, LIU L, WEN L J. Requirements knowledge acquisition from online user forums[J]. IET Software, 2020, 14(3): 242-253.
[22] KIM Y. Convolutional neural networks for sentence classification[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1746-1751.
[23] ECKHARDT J, VOGELSANG A, FEMMER H, et al. Challenging incompleteness of performance requirements by sentence patterns[C]// Proceedings of the IEEE 24th International Requirements Engineering Conference. Piscataway: IEEE, 2016: 46-55.
[24] TONDEL I A, JAATUN M G, MELAND P H. Security requirements for the rest of us: a survey[J]. IEEE Software, 2008, 25(1):20-27.
[25] KÖHL M A, BAUM K, LANGER M, et al. Explainability as a non‑functional requirement[C]// Proceedings of the IEEE 27th International Requirements Engineering Conference. Piscataway: IEEE, 2019: 363-368.
[26] DUBEY S K, GULATI A, RANA A. Usability evaluation of software systems using fuzzy multi‑criteria approach[J]. International Journal of Computer Science Issues, 2012, 9(3):404-409.
Requirement acquisition approach for intelligent computing services
WANG Ye, ZHOU Aohui, ZHOU Siyuan*, JIANG Bo, CHEN Junwu, SONG Shizhe
(,,310008,)
In intelligent computing services, data analysis and processing are provided for the service consumer by the service provider through Internet, and a learning model is established to complete intelligent computing function. Due to the lack of effective communication channels between service providers and service consumers, as well as the fuzzy and messy requirement descriptions of the service consumer feedback, there is a lack of a unified service requirement acquisition method to effectively analyze, organize and regulate the continuously changing requirement of users, which leads to the failure of intelligent computing services to make a rapid improvement according to the user’s requirements. Aiming at the problems of continuity and uncertainty of requirement changes in service development, a requirement acquisition method for intelligent computing services was proposed. The application feedback and questions of intelligent computing services were firstly obtained from Stack Overflow question and answer forum. Then, the knowledge classification and prioritization were performed on them by using different learning models (including Support Vector Machine (SVM), naive Bayes and TextCNN) according to the types of requirements concerned by the service consumer. Finally, a customized service requirement template was used to describe the requirements of intelligent computing services.
service requirement engineering; requirement acquisition; intelligent computing service; machine learning; neural network
This work is partially supported by Zhejiang Provincial Natural Science Foundation (LY21F020011).
WANG Ye, born in 1986, Ph. D., associate professor. Her research interests include requirements engineering, service computing, machine learning.
ZHOU Aohui, born in 1999, M. S. candidate. His research interests include software engineering, data mining.
ZHOU Siyuan, born in 1998, M. S. candidate. His research interests include software engineering, data mining.
JIANG Bo, born in 1970, Ph. D., professor. Her research interests include machine learning, requirements engineering, service computing.
CHEN Junwu, born in 1995, M. S. candidate. His research interests include service computing, deep learning, data mining.
SONG Shizhe, born in 1998, M. S. candidate. His research interests include service computing, machine learning, data mining.
TP311
A
1001-9081(2022)11-3486-07
10.11772/j.issn.1001-9081.2022010059
2022⁃01⁃18;
2022⁃03⁃31;
2022⁃04⁃15。
浙江省自然科学基金资助项目(LY21F020011);浙江省科技厅重点研发项目(2021C01162)。
汪烨(1986—),女,安徽滁州人,副教授,博士,CCF会员,主要研究方向:需求工程、服务计算、机器学习;周澳回(1999—),男,浙江温州人,硕士研究生,CCF会员,主要研究方向:软件工程、数据挖掘;周思源(1998—),男,上海人,硕士研究生,CCF会员,主要研究方向:软件工程、数据挖掘;姜波(1970—),女,浙江黄岩人,教授,博士,CCF理事,主要研究方向:机器学习、需求工程、服务计算;陈骏武(1995—),男,浙江金华人,硕士研究生,CCF会员,主要研究方向:服务计算、深度学习、数据挖掘;宋师哲(1998—),男,贵州遵义人,硕士研究生,CCF会员,主要研究方向:服务计算、机器学习、数据挖掘.
猜你喜欢
建材发展导向(2022年20期)2022-11-03
建材发展导向(2022年12期)2022-08-19
建材发展导向(2021年20期)2021-11-20
法律方法(2021年4期)2021-03-16
法律方法(2021年4期)2021-03-16
考试与评价·高二版(2020年2期)2020-09-10
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
