
基于数据驱动的公共建筑用电能耗短期预测
2022-11-29 13:22高晓佳王宏志
计算机仿真 2022年10期
高晓佳,王宏志
(1. 吉林建筑科技学院计算机科学与工程学院,吉林 长春 130000;2. 长春工业大学计算机科学与工程学院,吉林 长春 130000)
1 引言
可持续发展战略[1]的提出,在一定程度上加大了节能减排措施落实的力度,与此同时意味着对用电能耗精准预测的需求越来越高,现已演变成现代化电力领域的主要研究课题,特别是能耗的短期预测,更是在电力企业的生产与运行过程中具有重要的指导价值。例如:文献[2]针对配电台区的日负荷情况,利用VMD(Variational mode decomposition,变分模态分解)分解各频率尺度序列,根据环境因素,通过LSSVM(Least Square of Support Vector Machine,最小二乘支持向量机)来预测负荷;文献[3]基于Copula理论,利用KPCA(Kernel Principal Component Analysis,核主成分分析)降维解耦负荷数据,采用GRNN(Generalized Regression Neural Network,广义归回神经网络)模型完成多元负荷预测。
在城市化的发展进程中,各类建筑鳞次栉比,并逐渐成为能耗节约规划的重中之重,因此,本文面向公共建筑,构建一种基于数据驱动的用电能耗短期预测策略。随着物联网技术的进步,电力数据规模日益增加,数据驱动策略能够为用电能耗短期预测奠定夯实数据的基础;数据预处理阶段,有助于降低噪声、去除无效数据、排除异常数据以及规避因多量纲造成的建模紊乱等问题;利用模糊C均值聚类算法,减小输入空间维度;通过不断修正神经网络的权重与阈值,提升预测结果的精准度。
2 公共建筑用电能耗数据处理与降维
对比人工记录来讲,智能电表在采集用电能耗数据时具有高效的实时性,但以短期预测为目标的动态采集过程中,各类因素均将对初始能耗数据产生干扰,导致部分初始数据的遗漏,因此,需利用一系列预处理手段与特征降维策略,为用电能耗短期预测提供高质量的电能数据。
2.1 公共建筑用电能耗数据预处理
针对公共建筑用电能耗初始数据,分别采取异常滤除、遗漏补偿以及归一化等方法,完成电能数据的预处理,各处理阶段具体描述如下:
1)异常滤除:当公共建筑用电能耗被某些突发因素或特殊事件所影响时,就会形成一部分异常数据,只有合理将其滤除,才能确保用电能耗预测结果足够精准。因此,基于公共建筑用电能耗的时序性[4]与连续波动情况下,根据能耗曲线挖掘出遗漏、异常的电能数据。通常,异常数据会出现在历史能耗曲线的尖峰区域,滤除方法是:已知阈值e,假设与采样时间t相对应的能耗值是Pt,其前一时刻与后一时刻的对应能耗值分别为Pt-1、Pt+1,若能耗值Pt、Pt-1、Pt+1与阈值e之间满足下列不等式条件,则t时刻的能耗值Pt可替换为前后时刻能耗值Pt-1与Pt+1的均值,表达式如式(2)所示
max[|Pt-Pt-1|,|Pt-Pt+1|]>e
(1)
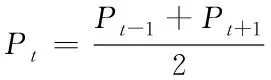
(2)
2)遗漏补偿:针对用电能耗周期性[5],采用表达式(2)(即遗漏数据前后时刻的能耗值均值)来补偿缺失数据;
3)归一化:假定初始变量数据为P,通过下列表达式在-1到1的范围区间,完成公共建筑的全部用电能耗数据转换,确保每个电能数据均处于相同维度中,实现能耗数据的归一化处理,规避因多量纲造成的建模紊乱问题
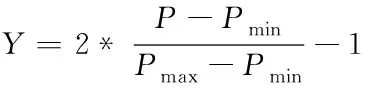
(3)
式中,经过归一化处理的电能数据是Y。
2.2 公共建筑用电能耗数据特征降维
引用PCA(Principal Component Analysis,主成分分析)方法[6],把初始多维能耗数据线性转移至多个正交坐标系内,得到一组每个维度都呈现出线性不相关关系的数据后,获得关键特征分量。
假设正交主成分向量分别为c1,c2,…,cm,标准正交线性组合系数值各是t1,t2,…,tm,则各能耗数据均可用矩阵Yn*m描述,如下所示
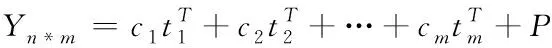
(4)
若特征向量ti的特征值为λi,对于剩下的几个能耗数据保持忽略态度,则针对前k个主成分,利用下列表达式求解用电能耗数据的方差贡献率ηi

(5)
通过对主成分分析不仅可以根据方差贡献率取得数据主成分,而且能够实现初始变量数据的非线性不相关关系表征,发现特征向量对初始数据的包含能力。
3 基于数据驱动的公共建筑用电能耗短期预测
3.1 用电能耗短期预测模型构建
将类似人脑的神经元结构作为处理器,采用加权链接形式[7]并行连接所有处理器,在各个单元中间传输信号,通过协调合作完成任务。用神经元组建的计算系统即为兼具分布式与并行性的神经网络。输入层的神经元节点负责采集、整理数据,隐藏层神经元经过激活,把整理后的数据发送至输出层神经元上。
假设三层前馈神经网络(见图1)的非线性传输函数是f(·),隐藏层非线性激励函数是h(·),输入项与输出项分别是pi、Y′,输入层与隐藏层之间的权重与阈值各为wij、ψj,隐藏层与输出层之间的权重与阈值各为bj、b0,则三层前馈神经网络的映射函数表达式如下所示
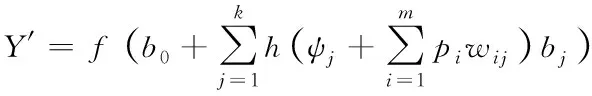
(6)
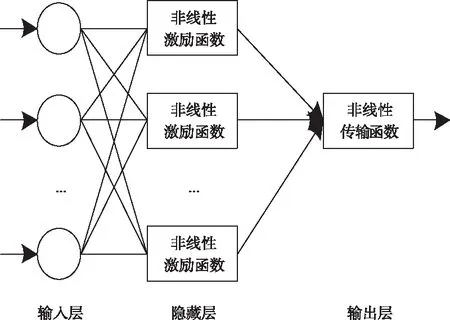
图1 三层前馈神经网络示意图
三层神经网络在面向高维数据时处理过程较为复杂,因此,通过FCM(Fuzzy C-means,模糊C均值)聚类算法[8]减小输入空间维度,构建一种IHCMAC神经网络。具体过程描述如下
1)经过归一化处理输入项,令输入空间为m维,表达式如下所示
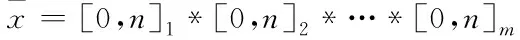
(7)
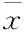
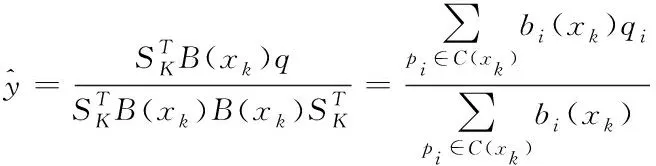
(8)
上式里,高斯基函数是bi,当节点不处于激活状态时,值为0;高斯基函数参数是σi,叠合部分系数用δ表示;权系数挑选的矢量是Sk=[SK,L]L*I,同高斯基函数,当节点不处于激活状态时,值为0;权系数矢量为q,对应于簇中心的权重是qi;基函数矩阵为B(xk),其与高斯基函数、高斯基函数参数的表达式分别如下所示
B(xk)=diag[b1(xk),b2(xk),…,bL(xk)]
(9)
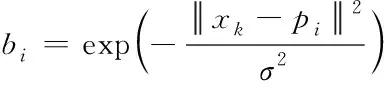
(10)
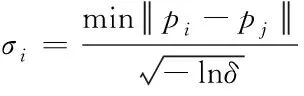
(11)
将IHCMAC神经网络运行阶段分为学习与训练两部分。其中,训练是根据期望数据与输出数据的偏差,不断修正神经网络的权重与阈值,以获得更精准的预测结果。
将估算偏差设成ek-1,利用下列表达式训练IHCMAC神经网络权重
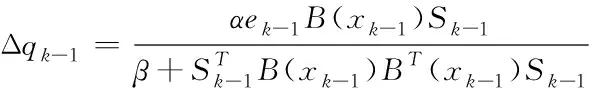
(12)
式中,α、β表示任意常数。当两个常数满足下列不等式组时,算法收敛,权重训练完成
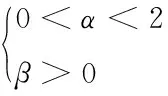
(13)
3.2 公共建筑用电能耗短期预测流程
公共建筑用电能耗短期预测即利用相对于预测时前几个时刻的温度、湿度以及用电能耗等历史数据,组建一个多维的输入空间,估计出下一时刻的能耗值。
已知预测时前两个时刻的建筑温度是Tt-2、Tt-1,湿度是Wt-2、Wt-1,用电能耗是Pt-2、Pt-1,则由这些历史数据得到的六维输入空间如下所示
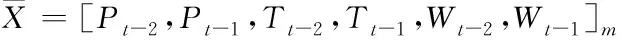
(14)
Pt=F(Pt-2,Pt-1,Tt-2,Tt-1,Wt-2,Wt-1)
(15)
基于数据驱动的公共建筑用电能耗短期预测流程如图2所示。采集建筑用电能耗数据,利用异常滤除、遗漏补偿以及归一化等策略,预处理收集到的能耗数据,提高数据有效性;通过主成分分析方法,降维处理初始的多维能耗数据,取得关键特征分量;经模糊C均值聚类算法,明确输入空间簇中心;采用经过训练的IHCMAC神经网络预测模型,结合温度、湿度以及用电能耗等历史数据,得到目标建筑的用电能耗预测结果。
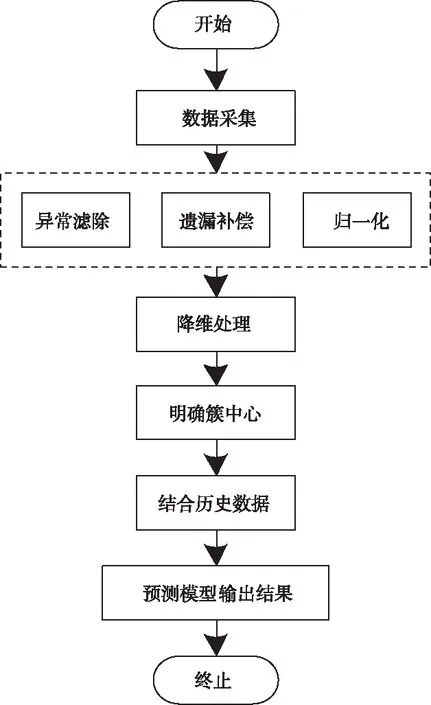
图2 用电能耗短期预测流程示意图
4 公共建筑用电能耗短期预测仿真
4.1 实验准备阶段
选取一栋三层的凹型图书馆(见图3)作为研究目标,在建筑内暖通空调、插座以及照明等各位置附近,放置温度传感器[9]、智能电力计量仪表[10]等多个计量设备,采集图书馆内不同系统的能耗数据,并在某能耗监测平台上,模拟本文模型对所选公共建筑的用电能耗短期预测。

图3 待预测公共建筑示意图
该图书馆的开放时长为12个小时,图4所示为各计量设备采集到的单位用电能耗数据。将10天内采集到的120组以小时为单位的能耗数据划分成训练集与测试集,设定训练集是前100组数据,测试集是余下20组能耗数据。

图4 采集阶段单位用电能耗数据示意图
为检验预测模型的精准性与有效性,从CV(Coefficient of Variation,变异系数)、RMSE(Root Mean Square Error,均方根误差)以及最大相对误差等角度,多方面评估本文模型的预测结果。其中,最大相对误差指标反映的是最大的预测偏差程度,均方根误差与变异系数两指标则主要用于描述实际能耗值与预测能耗值的离散程度。各指标计算公式分别如下所示
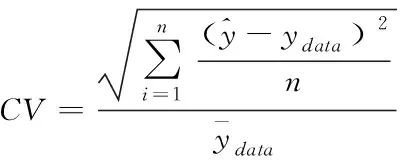
(16)
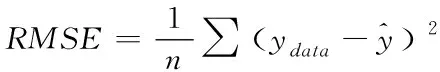
(17)
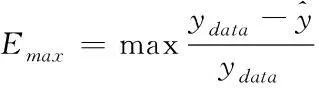
(18)
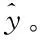
针对本文构建的IHCMAC神经网络短期预测模型,经不断修正参数与阈值,得到如表1所示的模型参数。

表1 预测模型相关参数
4.2 公共建筑用电能耗短期预测误差度分析
采用本文模型预测采集阶段后10天的用电能耗,经整理得到表2。
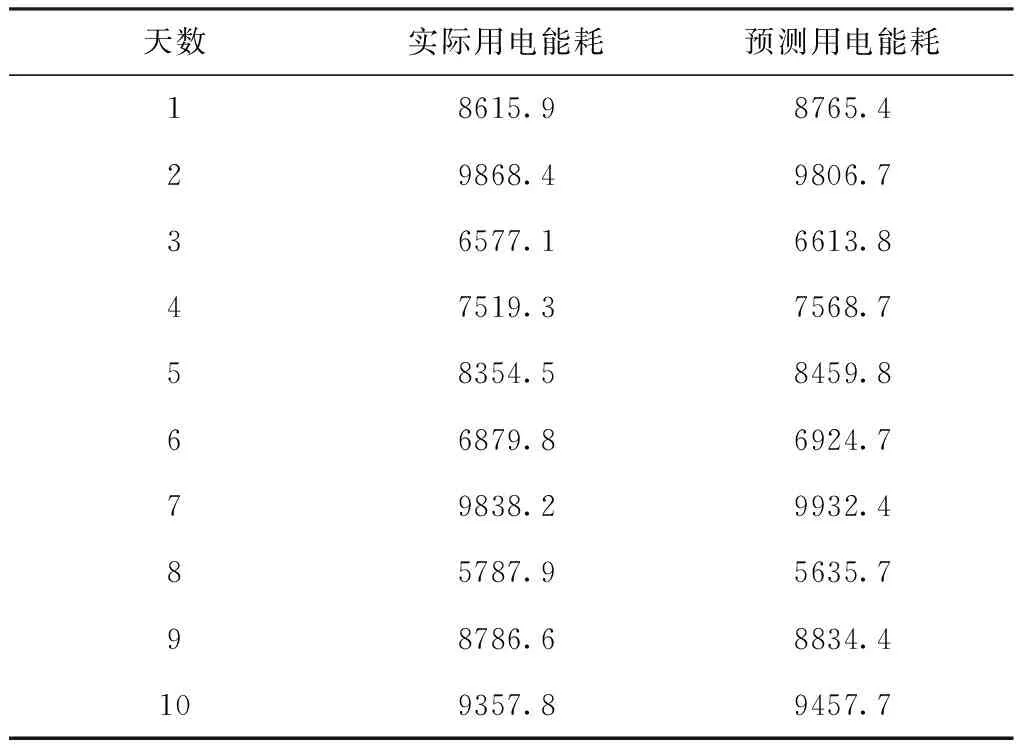
表2 图书馆10天内用电能耗结果比对表(单位:kW·h)
根据表2中能耗的实际值与预测值,利用Proteus仿真软件绘制最大相对误差,得到图5。
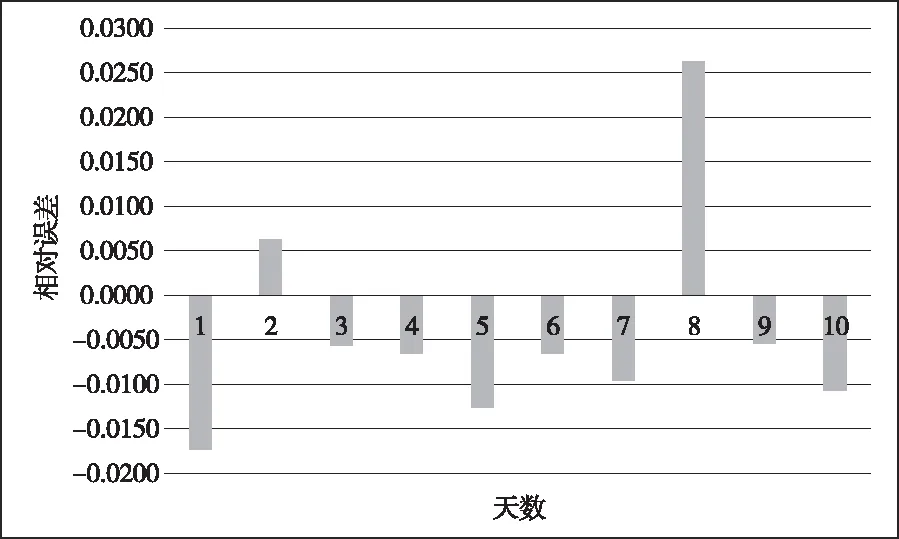
图5 预测能耗值最大相对误差示意图
结合上列图表可以看出,本文模型最大误差绝对值是152.2kW·h,最大相对误差Emax仅有0.026,且每一天的能耗预测相对误差均未超出0.03,这是因为本文利用一系列预处理手段与特征降维策略,为用电能耗短期预测提供了较高质量的电能数据,在三层前馈神经网络的基础上,引入模糊C均值聚类算法,构建了IHCMAC神经网络预测模型,结合由温度、湿度以及用电能耗等历史数据组成的多维输入空间,精准获得了下一时刻的用电能耗值。
4.3 公共建筑用电能耗短期预测离散度分析
图6所示为预测模型的变异系数与均方根误差指标的走势,由两指标分布形式可知,该模型因异常滤除、遗漏补偿以及归一化等预处理,得到了有效能耗数据,利用主成分分析方法完成初始多维能耗数据与多个正交坐标系的线性转变后,获得了关键特征分量,通过模糊C均值聚类算法,减小输入空间维度,经不断修正神经网络的权重与阈值,大幅度降低了能耗实际值与预测值的离散程度,预测精度较为理想,具备投入实际应用的必要条件。
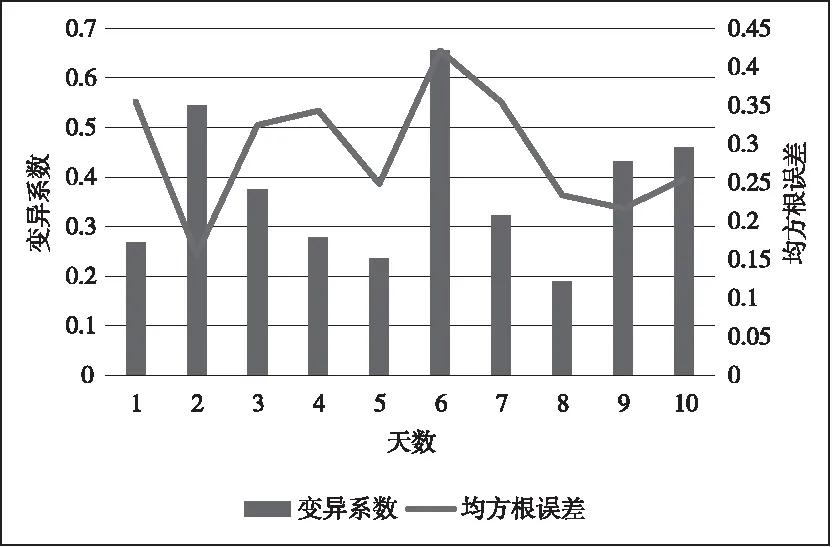
图6 变异系数与均方根误差指标示意图
5 结论
国民经济飞速增长,公共建筑不断增多,在可持续发展的战略指导下,随着电力供应压力的加剧,我国对公共建筑用电能耗的关注度越来越高,因此,降低建筑用电能耗已成为节能减排计划的主要实施对象。为有效落实节能减排措施,在数据驱动下,设计出一种公共建筑用电能耗短期预测方法。虽然本文研究成果对电力发展起到了一定的促进作用,但仍需在以下几个方面加以优化:应尝试将预测模型的批量训练模式转换为流处理模式,减小数据训练时延与误差;根据用电能耗预测特点,不断与分布式处理等新型技术相结合,从全方位完善预测性能;下一阶段应针对天气异常、工作日与节假日等特殊情况,获取更全面的电力数据,从根本上提升预测精准度;实验部分预测时长较短,不排除后期会出现个别的高误差情况,今后需就此问题对体育场等其它类型的公共建筑做进一步研究,探究预测方法的适用性。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
煤气与热力(2022年4期)2022-05-23
当代水产(2021年10期)2022-01-12
建材发展导向(2021年10期)2021-07-16
建材发展导向(2021年6期)2021-06-09
建材发展导向(2021年23期)2021-03-08
中学生数理化·中考版(2020年12期)2021-01-18
活力(2019年15期)2019-09-25
建材发展导向(2019年11期)2019-08-24
小学生必读(中年级版)(2018年10期)2019-01-04
