
不同目标函数对水文模型模拟效果的影响比较
2022-11-29 06:23陈开治
陕西水利 2022年9期
陈开治
(华南农业大学水利与土木工程学院,广东 广州 510642)
水文模型是用运用物理公式描述复杂自然界水文过程的工具[1]。模型的基本假设以及输入数据的误差和分辨率带来模型参数计算真值偏差,大多数模型参数不可直接测量或通过物理公式推求,因此部分模型参数需要通过率定确定[2,3]。水文模型的参数率定是根据目标函数,通过不断调试参数,使得模拟值接近于观测值。目标函数影响着水文模型参数的率定,从而影响水文模型的模拟效果[4]。国内外学者对比了不同目标函数的模拟效果。张如强[5]等发现纳什系数(E)和开方形式(Esqrt)的模拟效果差别不大,但后者对洪峰流量的模拟略好。Legates[6]等的研究表明,平均绝对误差在模拟中表现更好。尽管学者已经深入研究了很多变形形式,但仍有一些目标函数研究相对较少。
本文以梅江流域为研究对象,采用BTOPMC分布式水文模型,通过将简单最小二乘误差(SLSE)、时错最小误差(Shife SLE)、对数试错最小误差(Shift SLE Log)和平衡时错最小误差(Bal Shift SLE)设定为目标函数,以Nash系数、模拟与实测径流总量之比Vol和均方根误差RMSE作为评定指标,比较不同目标函数对模拟效果的影响。
1 研究区域概况及数据来源
梅江流域位于广东省东部。梅江发源于乌突山七星崇,上游称琴江,流经五华县水寨与五华河汇流后称梅江。梅江干流全长307 km,流域集雨面积为13929 km2,河床比降为0.59‰。在地貌上表现为低山、丘陵、盆地相间分布。
本文地形数据选取美国宇航局提供的SRTM3 DEM数据,土地覆被数据和归一化指数数据分别选用美国国家航天局提供的MODIS MOD12 Q1 和MODIS MOD13 A3 数据,土壤数据采用联合国粮食及农业组织提供的全球数字土壤图像;潜在蒸散发数据利用CRU TS4.03 数据计算;日降雨资料采用流域内87 个雨量站的实测数据和逐日径流量资料采用横山站实测数据。研究区域水文站、雨量站、分块情况见图1。

图1 梅江流域水文站、雨量站、分块情况
2 BTOPMC模型
BTOPMC模型是一种适用于大流域、具有物理基础的分布式水文模型[7]。模型包括了地形子模型、汇流子模型与产流子模型。地形子模型用于计算网格单元水利特性,汇流子模型考虑了多种产流状况的产流模型及选用马斯京根——康吉算法,汇流子模型选用的马斯京根——康吉算法具有水力学基础。
2.1 地形子模型
BTOPMC模型从大到小将流域划分成流域、子流域、参数块和网格4种空间模型。流域是最大的空间模型。子流域是流域的一部分,每个子流域以分水岭为边界并有唯一出口。由于模拟需要一定时间序列的径流资料,故通常将河道上的水文站作为子流域出口。每个子流域由若干参数块组成,块与块之间只有并行关系,每个块只有一个水流出口。参数块是人为划分的参数单元,即每一块都有一组水文参数;网格是最小的模拟单位,所有水文过程都是在网格上进行模拟。
BTOPMC中的地形子模型包括数字高程模型处理模块、洼地消除模块、生成数字河网模块和其他模型需要的相关地形信息[8]。数字高程模型处理模块根据水流的合理性,采用 “D8”法确定水流方向;洼地消除模块根据流域地形倾斜状况,采用空间分布式逐步小量增高洼地高程的方法,使得洼地的水流坡降与流域地貌坡度基本一致,以消除DEM中非真实存在的洼地;地形子模型主要根据水文站的分布及水文站所在河流水系的水力关系来进行子流域分级。
2.2 产流子模型
产流子模型包括可能蒸散发模型、积雪融雪模型等,产流过程是以分块的方式对TOPMODEL模型进行应用。BTOPMC的最小计算单元是栅格,当栅格单元尺寸足够小时,可以认为该栅格单元上的土壤和植被类型相似。TOPMODEL模型把栅格单元从上到下划分为四层:植被层、根系层、不饱和层和饱和层。
栅格上的降雨首先被植被截留、洼地存储和渗入初始土壤含水量低于饱和含水量的根系区,直到根系区的最大蓄水容量全部蓄满,即达到田间持水量,且还有多余降雨量时,降雨才能在重力作用下渗透到非饱和层,补充非饱和层土壤水分的动态部分。
2.3 汇流子模型
河道中的洪水波属于非恒定流,质量守恒和动量守恒定律可推导出河道中非恒定流的基本微分方程组——圣维南方程组。由于圣维南方程组在数学求解十分困难,故常将其简化为运动波或扩散波方程。
3 目标函数与精度评定
3.1 目标函数
本文对比以下4种目标函数:
1)截割头静止情况下,本系统的抬升角在0.3°以内跳动,回转角跳动在0.25°以内;截割头运动情况下,测量值与截割头实际摆动趋势一致,曲线近似呈线性关系且稳定性良好。
(1)简单最小二乘误差(Simple Least Square Error,简称 SLSE)

式中:Qobs,j为水文站实测流量,m3/s;Qsim,i为模拟流量,m3/s;i为时段序号;n为总时段数。
(2)时错最小误差(Sift Simple Least Error,简称Shift SLE)
由于降雨和洪水观测资料有一定几率存在时间误差,所以Shift SLE允许模拟流量和实测流量存在时间误差。在此次日径流模拟中仅仅考虑模拟流量和实测流量错开一个时间段。但是在时间步长较短的时洪水模拟中,由于记录资料的时间误差可能达到好几个时段,所以可以考虑放宽模拟流量与实测流量错开的时间段数。

式中:min(…)为表示3个数中取最小的一个。
(3)对数时错最小误差(Shift Simple Least Logarithmic Error,简称 Shift SLE Log)
相对枯水时期,洪水时期模拟流量的误差会更大。SLSE和Shift SLE采用观测流量与模拟流量之差的平方形式进行计算,更加强调洪水期间的水文过程。为了使枯水时期的水文过程更加准确,可采用流量的对数形式构造函数,即对数时错最小误差目标函数。式中:“log()”是取10为底的对数,必要时也可以取其他数为底。
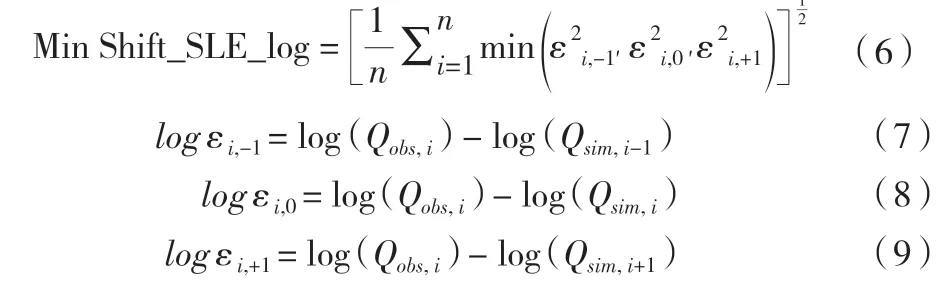
(4)平衡时错最小误差(Balanced Shift Simple Least Error, 简称 Bal Shift SLE)
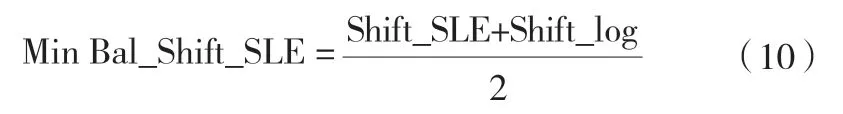
3.2 精度评定
本选用Nash效率系数、模拟与实测流量总量之比Vol和均方根误差RMSE作为评价模拟效果的指标:
(1)Nash系数,计算式为:

(2)模拟与实测径流总量之比Vol,计算式为:

(3)模拟与实测流量平方根误差RMSE,计算式为:

式中:Qobs为时段i的水文站实测流量;Qsimi为时段i的模拟流量;Qobs为在平均实测流量;N为流量序列长度。
4 实例应用
本文以2002年~2005年为率定期, 2006年~2009年为验证期。
BTOPMC模型需要率定的产流参数包括饱和土壤剖面侧向出流系数T0、出流系数随土壤深层的衰减系数m和计算实际蒸散发的土壤干燥函数系数αET,汇流参数包括应用马斯京根-康吉法的空间离散段数nΔx和时间离散格式nΔx和参数块曼宁糙率系数n0[4]。其中,由于饱和土壤剖面侧向出流系数T0对水文模拟过程不敏感[7],根据水文模拟经验确定饱和土壤剖面侧向出流系数(T0,clay、T0,sand、T0,silt),其余参数在参数块上率定。参数取值结果见表1。

表1 不同目标函数的日径流模拟参数取值结果
4.1 总体模拟效果分析
不同目标函数的日径流模拟结果见表2。

表2 不同目标函数在梅江流域的模拟结果
由表2可以看出,无论是率定期还是验证期,Shift SLSE和Bal Shift SLE的Nash系数更接近1,表现比其他两个目标函数好。从水量平衡的角度来看,SLSE、Shift SLE和Shift SLE Log的Vol均接近1。总的来说,Bal Shift SLE的模拟效果最好,原因是Bal Shift SLE更能平衡洪水期间和枯水期间的水文模拟。
4.2 不同流量级模拟效果对比
为对比4个目标函数在不同流量级别的模拟效果,本研究将实测流量从小向大排序,流量最小的25%序列作为枯水流量,25%~75%序列作为平水流量,流量最大的75%~100%序列作为丰水流量,以模拟与实测流量总量之比Vol和均方根误差RMSE作为评价指标,对比各目标函数在不同流量级别的模拟效果,见表3、表4。

表3 不同流量级模拟效果对比(率定期)
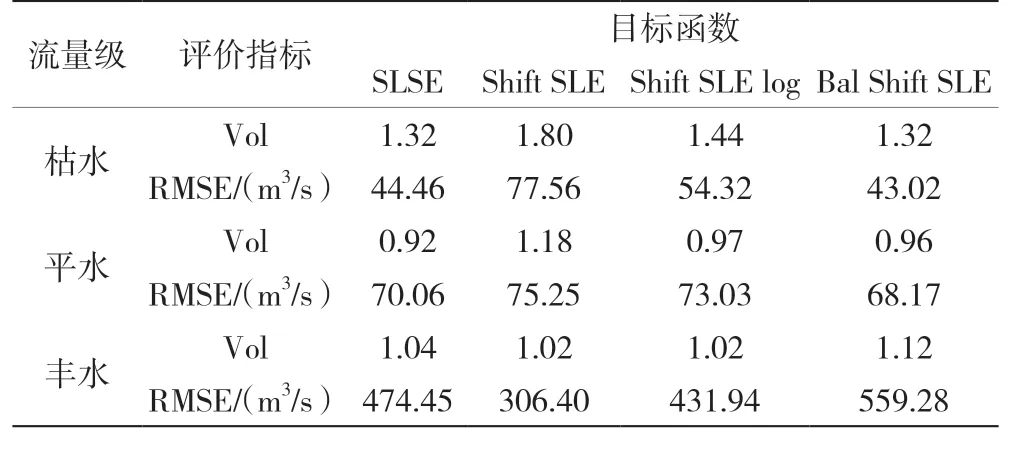
表4 不同流量级模拟效果对比(验证期)
从表3和表4可以看出,枯水期,四个目标函数的的Vol均远大于1.00,这说明小流量模拟时四个目标函数的水量模拟效果普遍偏大。SLSE率定期和验证期的 RMSE分别为57.86 m3/s、70.06 m3/s,与其他目标函数相比有着相对较小的RMSE。Bal Shift SLE的验证期Vol与RMSE误差比其他目标函数小,说明在此次模拟中,Bal Shitf SLE的模拟效果更接近实测情况,总体模拟效果比其他目标函数更平衡。
平水期,在模拟径流总量方面,SLSE、Shift SLE log、Bal Shift SLE的Vol均接近1.00,说明中等流量的水量平衡模拟效果较好。在RMSE方面,Bal Shift SLE的整体误差最小,分别为76.19 m3/s、68.17 m3/s。
丰水期,四个目标函数的Vol误差在15%以内,说明大流量模拟时四个目标函数的水量模拟效果较好。Shift SLE验证期的水量平衡系数最接近1,且RMSE值最小,说明Shift SLE在丰水期时比其他目标函数表现更好。
5 结语
本文以梅江流域为研究对象,采用BTOPMC分布式水文模型,通过设定不同目标函数,从总体模拟效果及不同流量级模拟效果两个方面分别对比模拟效果,得出以下结论:
(1)目标函数SLSE、Shift SLE 、Shift SLE log和Bal Shift SLE总体上都能较好地反映梅江流域日径流过程。
(2)以Bal Shift SLE为目标函数的时候,整体模拟效果较好;以Shift SLE为目标函数的时候,丰水期的模拟效果较好;以Bal Shift SLE为目标函数的时候,平水期与枯水期的模拟效果较好。
猜你喜欢
现代经济信息(2021年3期)2021-11-23
成都信息工程大学学报(2021年3期)2021-11-22
陕西档案(2021年2期)2021-05-21
娃娃乐园·3-7岁综合智能(2017年9期)2018-02-01
娃娃乐园·3-7岁综合智能(2017年8期)2018-02-01
娃娃乐园·3-7岁综合智能(2017年7期)2018-02-01
人大建设(2017年6期)2017-09-26
黄河黄土黄种人·水与中国(2017年2期)2017-03-16
中国科技术语(2016年4期)2016-11-19
初中生·作文(2004年11期)2004-11-25
