
基于面部图像的有无早期肺癌风险分类研究
2022-11-28 08:04:46周孟齐胡广芹林岚李斌张新峰
中国医疗设备 2022年11期
周孟齐,胡广芹,林岚,李斌,张新峰
北京工业大学 a. 环境与生命学部;b. 信息学部,北京 100124
引言
据统计,2020年我国癌症新发病例457万例,其中肺癌新发病例82万,死亡71万例,发病率和死亡率均居首位[1]。临床上,癌症可根据癌细胞的扩散程度分为5个时期:Ⅰ期为产生癌细胞,Ⅱ期为癌细胞在癌变部位发生轻微扩散,Ⅲ期为癌细胞在周边发生扩散,Ⅳ期为癌细胞转移至远端,Ⅴ期为癌细胞扩散至测量方法的极限。其中,Ⅰ期和Ⅱ期两个时期统称为癌症早期[2]。癌症早期患者可以通过化疗、放疗等方式进行治疗,达到治疗目的,因此早发现有重要意义。
中医通过望闻问切四诊合参的方式诊断,具有无创无痛的优势[3]。面诊作为望诊的内容之一,在诊断过程中发挥着重要作用,如面部为全身经络血脉汇聚之处,面部的颜色、光泽、纹理特征表现可以直接反映人体内部气血运行状态,并反映人体内部器官健康状态[4]。同时积聚患者面部皮肤状态会发生改变,积聚即为肿瘤,如果人体某一部位发生癌变,会影响全身经络气血的运行状态,体现在面部的特征参数上[5]。
目前,已有关于面诊信息化的研究,其中YCbCr颜色空间是YUV的国际标准化变种,在数字电视和图像压缩(如JPEG)方面都有应用,其中Y与YUV中的Y含义一致,指亮度,CB和CR分别指蓝色分量和红色分量[6-8]。但关于癌症风险预测评估的报道较少,基于此,本研究旨在结合面部颜色和纹理特征,使用机器学习的方法,对是否具有早期肺癌风险进行分类研究,以期为肺癌早期发现提供客观依据。
1 数据处理与方法
本研究数据处理流程图如图1所示,通过专业设备进行人面部图形的采集,并将所采集到的图像按照研究所制定的标准进行筛选、分类。通过BiSeNet 进行面部图像分割,获取无背景噪声的研究区域;对分割后的图像进行颜色空间的转换,并在YCbCr颜色空间模型中通过CB以及CR的值寻找非肤色点,利用均值滤波的方法进行降噪。对降噪后的图像通过一阶颜色矩的方法获取亮度分量、红色分量、蓝色分量3个颜色特征值,同时采用灰度共生矩阵获取ASM能量、熵、对比度3个纹理特征值;使用随机森林的算法进行分类研究,并计算6个特征对分类模型的贡献度。

图1 数据处理流程图
1.1 数据预处理
本研究数据来源于中国医学科学院肿瘤医院数据库和中国医学科学院中医药健康工程研究室面部图像数据库。采集时均使用同一厂家同一型号的面诊采集仪,并保证光照条件的一致性以及光源的稳定,对图像进行筛选,最终将图像人群划定在35~50岁的华北地区人员。在符合年龄和地区的前提下,再次进行数据筛选。
(1)患癌人群纳入标准:① 采集时医生病历诊断显示为早期肺癌;② 为首次接受治疗。
(2)未患癌人群纳入标准:体内无任何炎症感染。
(3)图像纳入结果:剔除不符合要求的图像,即非早期肺癌患者、已经治愈的患者、体内存在炎症的患者图像以及采集时有异物遮挡的图像。整理图像,最终纳入患癌图像158例,不患癌图像200例,数据分布较为均衡,并对数据进行标签分类,0表示患癌,1表示不患癌。
(4)训练集和测试集:每次试验将279例图像作为训练集,79例图像作为测试集。
1.2 面部图像获取
本研究使用BiSeNet网络进行分割,将图像中的整个面部区域作为目标前景,其他区域作为背景。BiSeNet网络是一种双路径分割网络[6-8],即通过空间路径(Space Path,SP)和上下文路径(Context Path,CP)分别获取位置信息特征和语义信息特征,将两者通过特征融合模块进行融和,筛选有效特征,从而准确分割目标区域。BiSeNet算法被广泛应用到各个领域的目标分割中,均取得了较高准确度的分割结果。
在本研究中的空间分支网络由3个隐含层组成,每个隐含层包含一个不步长为2的卷积层(conv)、批量标准化层(bn)、激活层(relu),因此SP输出特征图的尺寸为原始图像的1/8,可保存丰富的低级空间特征信息,而CP分支使用残差网络,获取最大的感受视野,进而获取上下文语义信息。BiSeNet结构如图2所示。由图2可知,注意力提取模块使用全局平均池化的方式来学习特征,特征融合模块则将SP分支与上CP分支输出的特征池化为一个特征向量,并进行权重选择,进而识别到整个人脸区域。用100幅图像进行面部区域标注,送入模型,进行学习。
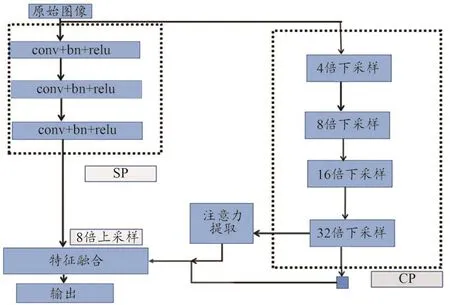
图2 BiSeNet结构模型
1.3 颜色特征提取
面部颜色是中医面诊过程中的一个重要信息,在不同的颜色空间中反映出的颜色信息也不一致。面部颜色特性在YCbCr颜色空间[亮度(Y)、蓝色分量(CB)、红色分量(CR)]上具有较好的信息反映能力,且可根据CB和CR的取值范围区分肤色点,且其取值与年龄、性别、职业等因素无关,由于YCbCr颜色空间上,具有椭圆肤色聚类的特性,需对非肤色点进行检测[6],因此本研究将面部图像转换到YCbCr颜色空间上,其转换关系如公式(1)所示,将图像转化到YCbCr颜色空间后,进行非肤色点检测。YCbCr空间使用非线性分段分割肤色区域时,近似于椭圆形状,如公式(2)~(3)所示。

式中,Y为图像在YCbCr颜色空间模型中亮度通道上的分量,CB为其蓝色通道上的分量,CR则为其红色通道上的分量。R、G、B分别代表图像在RGB颜色空间模型中红色通道、绿色通道以及蓝色通道上的分量。
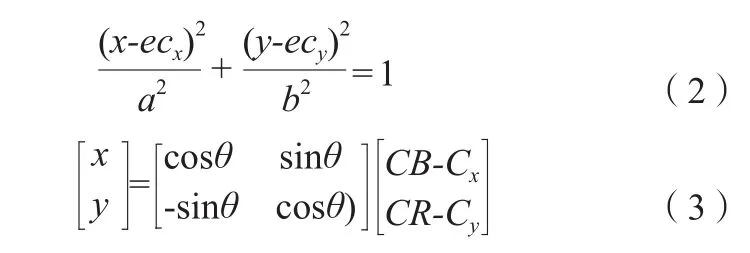
式中,x、y分别表示图像阈值的横、纵坐标;a表示在YCbCr颜色空间肤色点聚类而成的椭圆模型的长轴的值;b表示短轴的值;ecx、ecy分别表示椭圆模型中心点的横、纵坐标;θ表示坐标轴远点到中心点的角度。
根据研究计算可得[7-8],在YCbCr空间聚类区域中,θ=2.53,cx=109.38,cy=152.02,a=25.39,b=14.03,ecx=1.60,ecy=2.41。本研究通过转换公式获取图像CB和CR的值,通过公式(3)计算出x和y的值,并带入公式(2)的左侧部分,计算其结果。若大于1则表明该点不在椭圆区域内,即为非肤色点。将图像中的每一像素点的CB,CR值代入,计算对应像素点的x、y值,并入公式(2)的左侧,与1比较,发现只有当CB、CR两值同时满足133≤CB≤173、77≤CR≤127时,其结果才满足≤1,落入椭圆区域内部[7]。基于此,在本研究中,对像素点CB和CR值筛选,并将不能同时满足两值范围的点,记为非肤色点,并使用9×9的均值滤波器进行滤波,达到降噪的目的。
在YCbCr颜色空间模型中,通过获取Y、CR、CB的一阶颜色矩,即图像各像素点的均值作为其颜色特征值。
1.4 纹理特征提取
除了颜色特征,面部还包含了许多其他有用的信息。纹理特征是对图像灰度空间分布模式的分析,描述图像像素与像素之间的关系,且不受颜色和亮度的影响[8]。本研究采用灰度共生矩阵(Gray Level Co-Occurrence Matrix,GLCM)提取ASM、熵、对比度3个特性,分别反映图像灰度分布均匀程度、平均信息量和灰度反差,三者可从不同的角度描绘出图像在灰度空间上的局部特征,反映面部的纹理特征,计算公式如式(4)~(6)所示。
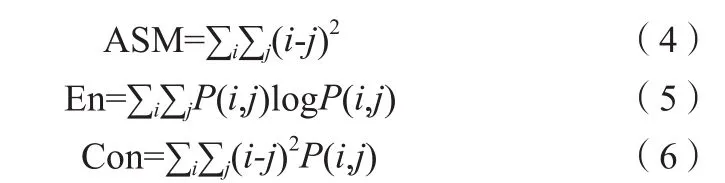
式中,P(i,j)表示在灰度空间中灰度级之间的联合条件概率密度,对于本研究,给定空间距离d=1,采用4个共生矩阵,其角度分别为 0°、45°、90°、135°时,灰度以 i(某行)为起点,出现在灰度级j(某列)上的概率。同时将所有图像二值化,获取其灰度图像,使用4个不同角度的共生矩阵,分别按公式(4)~(6)进行计算,并取4个矩阵计算结果的均值作为最终的纹理特征。
1.5 随机森林模型建立
随机森林是机器学习的一种方法,计算速度较快[9],其是通过多个决策树构造而成,最终的输出结果是由多个决策树组合而成的结果,因此优于任何一个单个决策树的输出结果[10],因此随机森林被广泛应用到分类[11]、预测[12-13]等方面。本研究在构造随机森林模型过程中使用ID3算法建立决策树,并对ID3算法进行改进,在构造时进行最大特征数的限定,通过调节最大特征数以及决策树的个数,观察两者对随机森林的分类结果的影响,寻找最优参数。随机即指样本的随机抽取和特征的随机选择。
本研究将数据集进行划分,对训练集的279个样本进行有放回地随机抽取,对抽取出的K组样本进行训练,其构造过程如下:① 确定原始训练集:D={1,2,……279};② 对训练集进行特征确定,确保所选择的特征对分类有意义;③ 对训练集D进行K次有放回地随机抽样,每次抽取N个样本,其中N小于训练集D,得到K组样本集,本研究中,K分别取值为30、0和100,即决策树的个数;④ 使用ID3算法,分别对K组样本用信息增益的方法构造决策树,进而形成有K棵决策树的随机森林;⑤ 输入待测样本,根据步骤④的决策数据计算输出结果。
研究以准确率作为模型的评价指标,准确率的计算方法如公式(7)所示,混淆矩阵示意表如1所示。

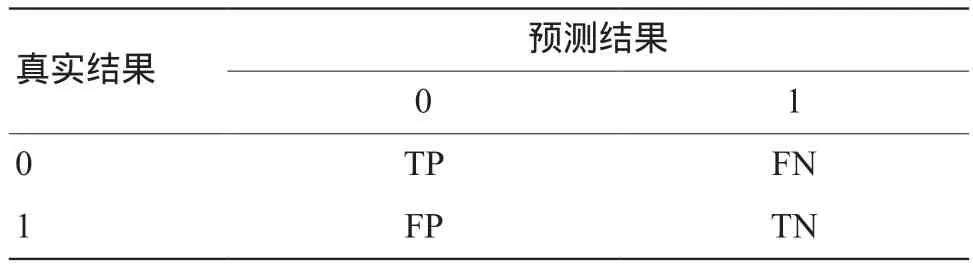
表1 混淆矩阵示意表
构造随机森林后,对特征的重要度进行分析。随机森林中的特征选择主要有3种方法:χ2检验、信息增益、Gini系数。本研究在选用信息增益的方法进行特征选择。信息增益的选择标准是按照每个子节点的纯度达到最高纯度进行的,其值越大纯度越高。
特征集合A为特征信息。由于本研究是一个二分类的数据集,故i的值有2个,并根据公式(8)计算信息量。根据式(9)~(10)分别计算出其先验熵、后验熵。
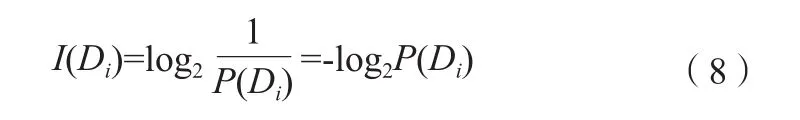
式中,数据集D作为信息,Di为D中的一种类型;P(Di)表示输出结果为第i类的概率。
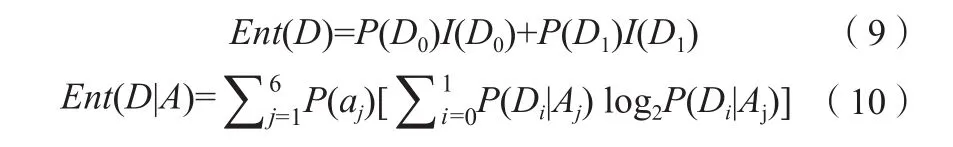
式中,P(Di|Aj)表示在特征Aj条件下取得第i类的概率。P(aj)表示随机选择样本时选择特征aj的概率,Aj为特征aj中的一种。
信息增益是指信息从先验熵到后验熵减少的部分,反映了信息消除不确定性的程度,其值越大,消除不确定性的能力越强,相关性越强,计算方式如公式(11)所示。本研究,样本集合D={Di|i=|0,1},特征集合A={Aj|j=|1,2,3,4,5,6}。
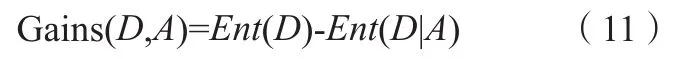
在具体进行特征选择时,信息增益计算步骤如下:① 根据公式(8)~(11)计算每个特征的信息增益;② 比较集合A中各个特征的信息增益的大小,选择信息增益最大的特征最为分割的子节点,并选择该特征下的样本的类别作为子节点;③ 对子节点重复上诉2个步骤,直至能够获取最终的分类结果。
2 结果
2.1 分割结果
经过训练学习,采用BiSeNet网络模型图像进行分割,其分割结果准确率为96.25%。每幅图像均能够较为准确的分割出人的面部区域,其分割效果如图3所示,通过分割,获取研究中的目标区域,即人的整个面部图像。去除其他与面部图像参数无关的噪声,排除其他干扰因素。
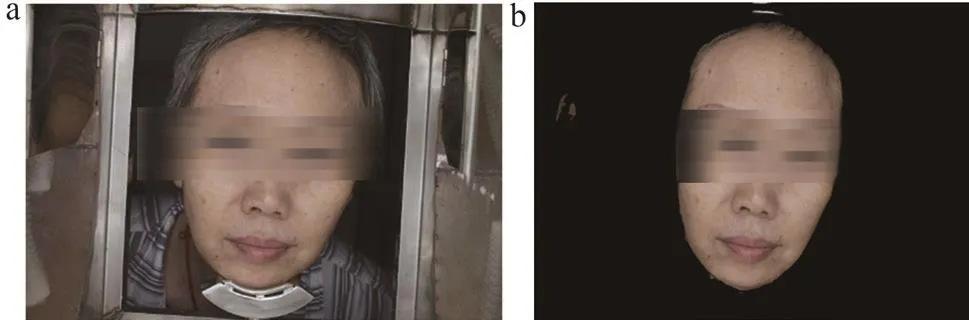
图3 分割效果图
2.2 颜色特征提取结果
将分割后的图像转化到YCbCr颜色空间中,通过CB以及CR的取值范围,寻找非肤色点,并采用9×9的滑动窗口,通过均值滤波的方法进行降噪处理,并在该颜色空间中,计算3个分量的平均值,作为其颜色特征,随机选择2组肺癌患者与未患癌人群的特征提取结果展示如表2所示,从颜色特征数值上可以看出,癌症患者面部的颜色特征与未患癌人群面部的颜色确实存在明显差异,尤其表现在红色分量上,特征选择也证实了红色分量的特征贡献度最大。
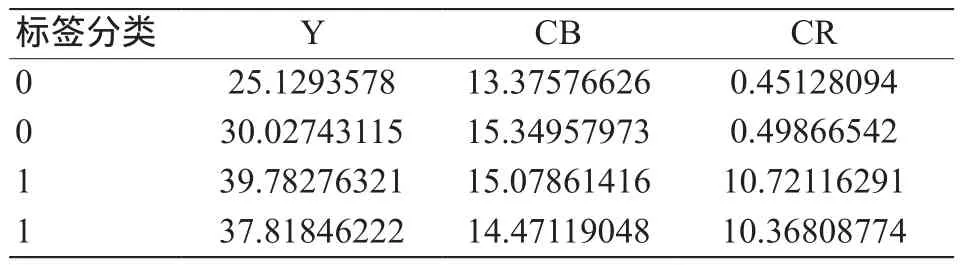
表2 部分面部颜色特征结果
2.3 纹理特征提取结果
对彩色图像进行二值转化,获取其灰度图像,并对灰度图像进行灰度级量化,量化后采用角度分别为0°、45°、90°、135°的4个共生矩阵,计算ASM、熵、对比度反映面部的纹理特性,随机选择2组肺癌患者与未患癌人群的纹理特征提取结果如表3所示,通过表3中数据对比可得出,肺癌患者面部图像的ASM值大于0.5,而未患癌人群的面部图像的ASM小于0.5,两者存在较为明显的差异;同时两者熵和对比度在数值上差异也较明显。
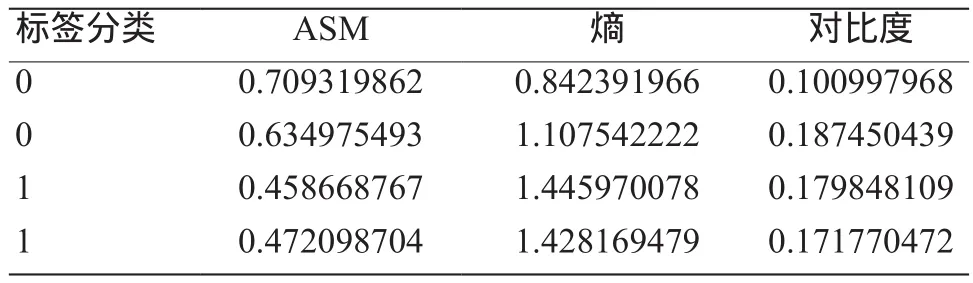
表3 部分面部纹理特征结果
2.4 随机森林预测分类结果
本研究构造随机森林,设置2个超参数,即决策人树个数和最大特征值,将决策树个数分别设置为30、50和100,最大特征等设置为2、3和4,在不同参数下,进行训练和测试,并对测试结果进行分析。首先观察混淆矩阵,并根据混淆矩阵计算模型的准确率。图4为其中1组测试结果的混淆矩阵,根据混淆矩阵,快速获得TP、FP、TN、FN的值,并根据公式(11)计算每次训练的模型所做出分类的准确率,即正确判断的数量占测试集总数的比例。分别对数据集进行了9次训练和测试,9次测试结果准确率如表4所示。通过表4可以看出,当决策树的个数一定时,随着最大特征数的增加,其预测结果的准确率也有所提升,但是所用的时间也随之增长。对比第3次和第6次实验,预测结果相同,且为本研究最高,但第3次所用的时间明显少于第6次。
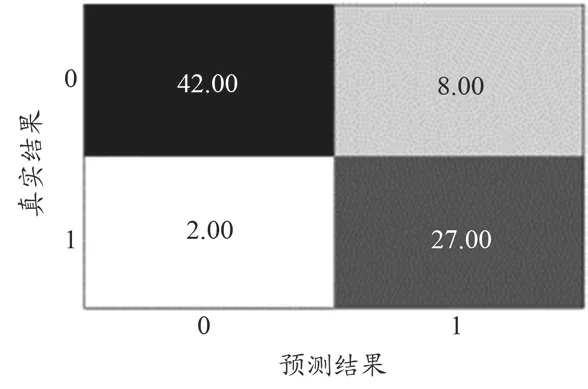
图4 1组测试结果的混淆矩阵
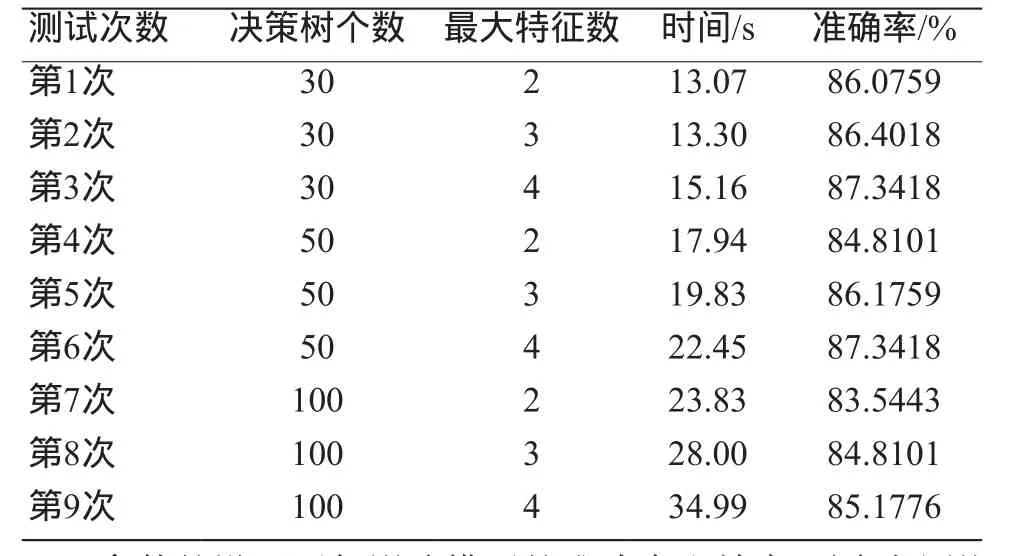
表4 随机森林预测结果
参数的设置不仅影响模型的准确率和效率,同时也影响整个模型的拟合程度,设置不当会造成整个模型欠拟合和过拟合。经过多次实验调整,将决策树个数设置为30,最大特征数设为4时,模型拟合程度最好,同时具有最高效率和最佳准确率。随机森林的准确度为87.3418%,高于SVM的64.7200%。在该参数条件下的模型最优,在该参数条件下,对特征选择进行评估,其结果如图5所示,可以看到6个特征中,红色分量的贡献度最大,其次是ASM。

图5 特征重要度
3 讨论与结论
本研究从中医望诊法中的面诊法出发,通过分析面部颜色和纹理信息,针对肺部是否存在早期癌风险进行了研究。在早期关面诊的研究中,对面部的颜色特征信息进行研究而忽略了纹理特征的研究[12-13]。相关文献[6-7]虽然是针对肠癌进行的,但也仅是在颜色特征对比上进行,而本研究中除了颜色特征外还引入了纹理特征,从灰度空间反映患者表现在面部上的信息。
在面部分割的过程中,使用BiSeNet算法获取到完整的目标区域。近年来人脸识别分割算法不断发展,但仍然存在效率低、分割不准确等问题,相关文献[12-24]分别用不同的深度学习方法进行面部区域的分割,其分割准确率在93%~95%,且耗时近3 min。而本研究所采用的双边语义分割结构模型分别从空间路径和上下文路径2个方面获取图像中面部位置信息和语义信息,在分割过程中保存了丰富的信息和最大感受视野,准确率为96.25%,且耗时为1 min左右。
本研究中,转换颜色空间模型,获取更为精确的颜色信息。通过YCbCr颜色空间寻找非肤色点,并使用均值滤波进行降噪处理,排除了化妆等因素导致的影响,从而使最终的分类结果更为可靠[25-27]。于婧洁[5]对早期肺癌与面诊的相关研究中,通过梯度决策树对面部颜色特征进行训练,对是否患有早期肺癌进行预测研究,但仅对额部进行研究,忽略了口唇的颜色特征,因此准确率仅在60%左右。而本研究不仅使用了在整个面部的颜色特征信息,还融入了纹理特征信息,而随机森林的使用也提升精准度至87.3418%。为早期肺癌的发现提供辅助依据,表明研究中的面部分割模块融入面诊仪中,实现高精确度的分割,用于后续的面诊分析,减少噪声干扰。
本研究首先对面部图像进行分割,并在YCbCr颜色空间模型中检测非肤色点并降噪,最大可能的减少环境带来的影响。通过颜色特征和纹理特征,使用ID3算法构造随机森林。通过准确率、召回率、精确度是对随机森林模型进行评估,并调整最大特征数和决策树个数寻找最优模型。根据结果,针对本研究,当决策树个数设置为50,最大特征数设为4时,参数最优,模型最优。
本研究未对舌部信息进行分析,未来将增大数据集并融合舌部信息进行研究,以获取更高准确率的分类模型。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
中国交通信息化(2018年5期)2018-08-21 03:37:40
少儿科学周刊·儿童版(2017年2期)2017-03-29 21:38:30
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
少儿科学周刊·儿童版(2015年11期)2015-12-17 03:39:38
儿童绘本(2015年8期)2015-05-25 17:55:54
